
Бандлы и минификация
Введение в бандлы и минификацию
Данное руководство устарело. Актуальное руководство: Руководство по ASP.NET Core
В ASP.NET MVC 4 была введена концепция бандлов, которая помогает организовать файлы скриптов и стилей более эффективным путем для снижения издержек при передаче клиенту. Посмотрим, что представляют собой бандлы.
В предыдущих версиях MVC мы могли стандартным образом подключать скрипты и стили, например:
Фреймворк MVC для настройки путей предлагает нам использовать URL-хелперы:
Использование бандлов представляет совсем другой подход к использованию скриптов и стилей. При создании нового проекта MVC4 по шаблону Basic или Internet Application функциональность бандлов уже по умолчанию включается в приложение. Если вы посмотрите на стандартный код мастер-страницы _Layout.cshtml, то увидите совсем иной способ подключения скриптов и стилей:
В конструктор ScriptBundle передается виртуальный путь бандла. А с помощью метода Include уже включаются в данный бандл конкретные файлы скриптов.
/Scripts/jquery-
Однако само объявление бандлов в файле BundleConfig.cs еще не подключает автоматически их в проект. Для этого в файле Global.asax прописывается соответствующая директива:
Таким образом, мы и регистрируем бандлы для нашего приложения.
Минификация
Ключевым моментом концепции бандлов является минификация. Ее суть состоит в том, что при развертывании приложения клиенту отдается не полная, а минимизированная версия скриптов или стилей. За счет чего экономятся ресурсы сервера, так как идет отдача файла с меньшим объемом. В то же время в процессе отладки приложения мы приложение отдает обычную версию, поскольку благодаря ей, нам проще разобраться в возможных ошибках. Посмотрим на примере. Вот у меня есть некоторая мастер-страничка, которая подключает кучу бандлов:
В данном случае я подключаю пять бандлов. Если запустить теперь приложение, то через средства разработчика в IE10 я могу увидеть скрипты, которые несут бандлы:
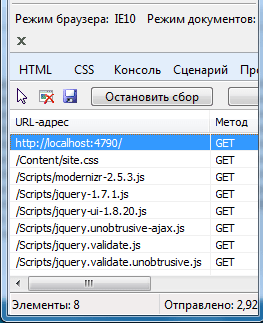
В данном случае у нас по умолчанию приложение находится в режиме отладки. В файле web.config можно найти следующую секцию:
Параметр debug=»true» указывает, что приложение запускается в режиме отладки. Теперь изменим его значение на false: debug=»false» и перезапустим проект. Теперь мы увидим несколько иной результат:
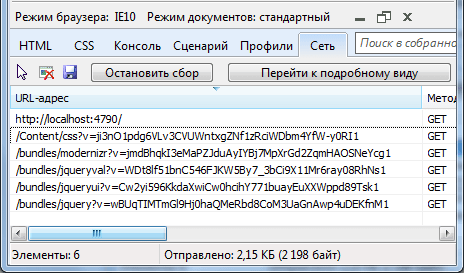
И если вы посмотрите, например, в том же IE10 в средствах разработчика заголовки ответа, то вы увидите, что в этот раз в режиме развертывания сервер отдает нам минимизированный файл:
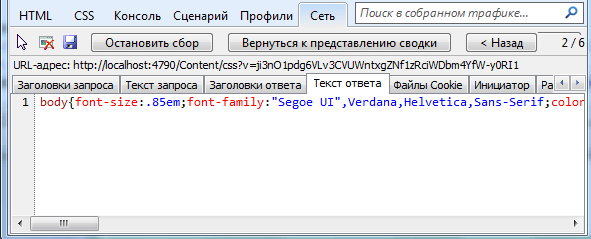
Таким образом, использование бандлов в проектах MVC4 повышает эффективность веб-приложения.
Бандлинг JavaScript-кода и производительность: передовые методики
Сейчас, на рубеже десятилетий, самое время критически переоценить то, что считалось правильным в недалёком прошлом, и выяснить, не потеряло ли оно актуальности в наши дни. Иногда вчерашние передовые методики разработки становятся сегодняшними антипаттернами.

Автор статьи, перевод которой мы сегодня публикуем, собирается исследовать три подхода к бандлингу JavaScript-проектов на примере простого Hello World-приложения, созданного с помощью React. Некоторые из приводимых им примеров подразумевают знание читателем основ сборщиков модулей, таких, как Webpack, который, похоже, является сегодня самым популярным среди подобных инструментов.
Подход №1: в бандл попадает абсолютно всё (это похоже на большой клубок ниток)
Главная мысль: не пользуйтесь этим подходом.
До выхода HTTP/2 этот паттерн можно было признать, в некотором роде, вполне приемлемым, так как его использование сокращает количество HTTP-запросов, выполняемых браузером при загрузке материалов страниц. Но учитывая то, что большинство сайтов в наши дни используют HTTP/2, этот паттерн стал антипаттерном.
Почему? Дело в том, что при использовании HTTP/2 выполнение множества запросов больше не создаёт такой же нагрузки на систему, как раньше. В результате упаковка кода в единственный большой бандл больше не даёт проекту существенных преимуществ.
При таком подходе усложняется эффективная организация браузерного кэширования. Например, изменение всего одной строчки кода в простейшем приложении приводит к изменению хэша бандла и к инвалидации кэша, хранящего весь код проекта. В результате всем возвращающимся посетителям приходится снова загружать весь код сайта, даже учитывая то, что этот код на 99% не отличается от того, который они загружали при предыдущем визите. Тут мы имеем дело с нерациональным использованием сетевых ресурсов за счёт многократной передачи от сервера клиенту одних и тех же данных.
HTTP/2 в наши дни поддерживают более 95% клиентов. В 2019 году этот протокол был реализован большинством серверов. Здесь можно найти более подробные сведения об использовании HTTP/2 в 2019 году.
Подход №2: раздельная упаковка кода проекта и кода сторонних библиотек (разделение кода)
Главная мысль: пожалуйста, используйте этот подход.
Вот каким стал код подключения скриптов:
А вот как выглядит водопадный график загрузки страницы, при работе с которой используется HTTP/2.

Водопадный график загрузки страницы
Мне подобный уровень разделения кода всё ещё кажется довольно-таки непростым делом. Это пока выглядит как экспериментальная технология (и как нечто такое, в чём вполне могут проявиться трудноуловимые ошибки). Но мне совершенно ясно то, что сильное разделение кода — это то направление, в котором двигается индустрия веб-разработки. Возможно, благодаря поддержке браузерами JavaScript-модулей, мы в итоге сможем полностью отказаться от бандлеров вроде Webpack и просто отдавать клиентам отдельные модули кода. Интересно будет понаблюдать за тем, куда всё это нас приведёт!
Подход №3: использование общедоступных CDN для кода некоторых зависимостей
Главная мысль: не пользуйтесь этим подходом.
На первый взгляд всё это выглядит вполне здраво, но у такого подхода есть некоторые минусы, которые я предлагаю рассмотреть.
▍Минус №1: использование разными сайтами одних и тех же файлов зависимостей? Уже нет…
Разработчики старой школы хранят в себе надежду на то, что если все сайты ссылаются на один и тот же CDN-ресурс и используют ту же версию React, что и наш сайт, то посетители нашего сайта, если в кэше их браузеров уже есть код React, не будут тратить время на его повторную загрузку. Это серьёзно повысило бы скорость вывода страниц нашего сайта в рабочий режим. Да и документация React, посвящённая этому вопросу, выглядит многообещающе. Поэтому, наверняка, некоторые разработчики используют этот паттерн. Правильно?
Хотя раньше подобное вполне могло работать, недавно в браузерах, ради повышения безопасности, начали реализовывать механизм разделения кэшей. Речь идёт о том, что даже в идеальных условиях, когда два сайта используют одну и ту же библиотеку, загружаемую по одной и той же CDN-ссылке, код независимо загружается для каждого домена, а кэш, из соображений приватности, попадает в «песочницу», выделенную конкретному домену. Как оказалось, этот механизм уже реализован в Safari (по-видимому, он существует с 2013 года?!). А если говорить о Chrome 77, то для включения разделения кэша пока нужно использовать особый флаг.
Тут делается обоснованное предположение, касающееся того, что использование общедоступных CDN снизится по мере того, как во всё большем количестве браузеров будет реализовано разделение кэша.
▍Минус №2: трата ресурсов системы на вспомогательные операции (для каждого домена)
Здесь озвучена мысль о том, что использование CDN приводит к повышению нагрузки на системы, так как даже ещё до отправки HTTP-запроса браузеру нужно решить множество задач: DNS-разрешение имени, TCP-соединение, SSL-рукопожатие. Браузеру, для подключению к сайту, в любом случае приходится выполнять эти действия, но если он вынужден подключаться и к CDN — это увеличивает нагрузку на него.
Вот водопадный график, иллюстрирующий процесс загрузки страницы, на которой используются скрипты с общедоступного CDN-ресурса.
Водопадный график загрузки страницы, использующей общедоступные CDN-ресурсы
Красными овалами выделены области, в которых происходят операции, предшествующие выполнению запросов. Кажется, что для простого Hello World-приложения это уже чересчур.
По мере того, как мой простой пример будет развиваться и расти, настанет момент, когда мне захочется использовать в нём собственный шрифт. Например — взятый из Google Fonts. А это означает, что число подобных задержек лишь увеличится, так как для загрузки шрифтов придётся подключаться к соответствующему домену. Тут начинает казаться весьма привлекательной идея хостинга всех ресурсов сайта на собственном основном домене (который, конечно, расположен за собственным CDN-ресурсом проекта, основанным на Cloudflare или Cloudfront).
Если в нашем примере переключиться на загрузку двух React-зависимостей с основного домена сайта — это приведёт к тому, что водопадный график загрузки страницы станет гораздо более аккуратным.
Водопадный график загрузки страницы, не использующей общедоступные CDN-ресурсы
▍Минус №3: использование разных версий зависимостей различными сайтами
Я, на скорую руку, провёл не особенно научное исследование 32 крупнейших сайтов, использующих React. К своему сожалению, я выяснил, что лишь 10% из них используют общедоступные CDN-ресурсы для загрузки React. Оказалось, правда, учитывая то, какие версии React используют все исследованные сайты, что это особого значения не имеет. В идеальном мире не было бы разделения браузерного кэша, а все сайты могли бы организоваться и использовали бы одни и те же версии скриптов с одних и тех же общедоступных CDN. В реальности же наблюдается чрезвычайно сильный разброс версий React, используемых разными сайтами. Это уничтожает идею общего браузерного кэша.
Версии React, используемые разными сайтами
Если сначала открыть один популярный сайт, использующий React, а потом — другой, то окажется, что шансы того, что оба эти сайта используют одну и ту же версию React, весьма невелики.
Я, в ходе исследования, обнаружил ещё некоторые любопытные сведения об этих React-сайтах. Возможно, они покажутся интересными и вам:
▍Минус №4: проблемы, не касающиеся производительности
К несчастью, в наши дни тот, кто использует общедоступные CDN-ресурсы, сталкивается не только с проблемами, касающимися скорости загрузки страниц, но и с некоторыми другими неприятностями:
Итоги
Совершенно очевидно то, что будущее лежит за подходом №2.
Размещайте перед своими серверами собственные CDN-ресурсы, использующие HTTP/2 (вроде Cloudflare или Cloudfront). Разбивайте код на небольшие фрагменты для того, чтобы эффективно использовать браузерный кэш. В будущем те фрагменты, на которые разделяют код сайта, могут стать ещё меньше, достигнув размеров отдельных JavaScript-модулей, благодаря тому, что в браузерах начата реализация поддержки данной технологии.
Уважаемые читатели! Пользуетесь ли вы технологиями разделения кода в своих веб-проектах?
Бандлы
Стандартный flow использования werf предполагает запуск команды werf-converge для выката новой версии приложения в kubernetes. Во время работы werf-converge:
werf позволяет разделить процесс выпуска новой версии приложения готовой к выкату и сам процесс выката в kubernetes с помощью так называемых бандлов.
Бандл — это коллекция образов и конфигурационных файлов деплоя некоторой версии приложения, опубликованная в container registry и готовая к выкату в kubernetes. Выкат приложения с помощью бандлов предполагает 2 шага:
Бандлы позволяют организовать гибридный подход push-pull к выкату приложения. Push в данном случае — это про публикацию бандла, pull — про выкат приложения в kubernetes.
Примечание. На данный момент не поддерживается, но в дальнейшем планируется добавить оператор бандлов для kubernetes, для полностью автоматизированного выката в kubernetes, а также автовыкат новой версии по маске semver.
Публикация бандлов
Публикация бандла осуществляется с помощью команды werf-bundle-publish. Команда принимает параметры по аналогии с werf-converge и требует запуска в git проекта.
Во время работы werf bundle publish :
Версионирование при публикации
При публикации бандла по уже существующему тегу — он будет переопубликован с обновлениями в container registry. Данная возможность может быть использована для организации автоматических обновлений приложения при наличии новой версии в container registry. Подробнее см. автообновление бандлов.
Выкат бандлов
Бандл, опубликованный в container registry, можно выкатить в kubernetes с помощью werf.
Переданные values для helm chart, аннотаций и лейблов для ресурсов будут объединены с теми values, аннотациями и лейблами, которые были указаны при публикации бандлов и зашиты в него.
Версионирование при выкате
При выкате бандла werf проверит наличие обновления в container registry для указанного тега (или latest ) и обновит приложение в кластере до последней версии. Данная возможность может быть использована для организации автоматических обновлений приложения при наличии новой версии в container registry. Подробнее см. автообновление бандлов.
Другие команды для работы с бандлами
Экспорт бандла в директорию
Команда werf bundle export позволяет создать директорию чарта в том виде, в котором он будет опубликован в container registry.
Команда работает по аналогии с командой werf bundle publish имеет те же параметры и требует запуска в git проекта.
Данную команду можно использовать для того, чтобы узнать, из чего состоит публикуемый бандл, а также для дебага.
Скачивание опубликованного бандла
Команда werf bundle download позволяет скачать ранее опубликованный бандл в директорию.
Команда работает по аналогии с командой werf bundle apply имеет те же параметры и не требует доступа к git.
Данную команду можно использовать для того, чтобы узнать, из чего состоит публикуемый бандл, а также для дебага.
Примеры использования
Опубликуем бандл для приложения по определённой версии, запускаем в git директории проекта:
Автообновление бандлов
Со стороны выката этого бандла при каждом вызове команды выката будет использоваться последняя актуальная версия по указанному тегу.
Выкат по маске semver
На данный момент не поддерживается, но планируется добавить возможность выката бандла по маске semver:
Поддерживаемые container registries
Для работы с бандлами достаточно поддержки спецификации формата образов Open Container Initiative (OCI) в container registry.
Подробнее про поддерживаемые container registries можно прочитать в отдельной статье.
Собираем бандл мечты с помощью Webpack
JS-приложения, сайты и другие ресурсы становятся сложнее и инструменты сборки — это реальность веб-разработки. Бандлеры помогают упаковывать, компилировать и организовывать библиотеки. Один из мощных и гибких инструментов с открытым исходным кодом, который можно идеально настроить для сборки клиентского приложения — Webpack.
Максим Соснов (crazymax11) — Frontend Lead в N1.RU внедрил Webpack в несколько больших проектов, на которых до этого была своя кастомная сборка, и контрибьютил с ним несколько проектов. Максим знает, как с Webpack собрать бандл мечты, сделать это быстро и конфигурировать так, чтобы конфиг оставался чистым, поддерживаемым и модульным.
Интеграция Webpack в типичный проект
Обычно порядок внедрения такой: разработчик где-то прочитал статью про Webpack, решает его подключить, начинает встраивать, как-то это получается, все заводится, и какое-то время webpack-config работает — полгода, год, два. Локально все хорошо — солнце, радуга и бабочки. А потом приходят реальные пользователи:
— С мобильных устройств ваш сайт не загружается.
— У нас все работает. Локально все хорошо!
На всякий случай разработчик идет все профилировать и видит, что для мобильных устройств бандл весит 7 Мбайт и грузится 30 секунд. Это никого не устраивает и разработчик начинает искать, как решить проблему — может подключить лоадер или найти волшебный плагин, который решит все проблемы. Чудесным образом такой плагин находится. Наш разработчик идет в webpack-config, пытается установить, но мешает строчка кода:
Строчка переводится так: «Если config собирается для production, то возьми седьмое правило, и поставь там опцию magic = true ». Разработчик не знает, что с этим делать и как решать. Это ситуация, когда нужен бандл мечты.
Как собрать бандл мечты?
Для начала определим, что это такое. Прежде всего, у бандла мечты две основные характеристики:
Оценить размер бандла
Самое популярное решение — это плагин WebpackBundleAnalyzer. Он собирает статистику сборки приложения и рендерит интерактивную страничку, на которой можно посмотреть расположение и вес каждого модуля.
Если этого мало, можно построить граф зависимостей с помощью другого плагина.

Если и этого недостаточно, и вы хотите продать Webpack маркетологам, то можно построить целую вселенную, где каждая точка — это модуль, как звезда во Вселенной.
Инструментов, которые оценивают размер бандла и следят за ним, очень много. Есть опция в конфиге Webpack, которая рушит сборку, если бандл слишком много весит, например. Есть плагин duplicate-package-checker-webpack-plugin который не даст собрать бандл, если у вас 2 npm-пакета разных версий, например, Lodash 4.15 и Lodash 4.14.
Как уменьшить бандл
Выкинуть лишнее
Оказывается, когда вы добавляете в дате день, час или просто хотите поставить ссылку «через 15 минут» с помощью moment.js, вы подключаете целых 230 Кбайт кода! Почему так происходит и как это решается?
Загрузка локали в moment
В moment.js есть функция, которая устанавливает локали:
Из кода видно, что локаль загружается по динамическому пути, т.е. вычисляется в рантайме. Webpack поступает умно и пытается сделать так, чтобы ваш бандл не упал во время выполнения кода: находит все возможные локали в проекте, и бандлит их. Поэтому приложение весит так много.
Решение очень простое — берем стандартный плагин из Webpack и говорим ему: «Если увидишь, что кто-то хочет загрузить много локалей, потому что не может определить какую, — возьми только русскую!»
Webpack возьмет только русскую, а WebpackBundleAnalyzer покажет 54 Кb, что уже на 200 Kb легче.
Dead code elimination
Следующая оптимизация, которая нас интересует — Dead code elimination. Рассмотрим следующий код.
Теперь перейдем к более продвинутому способу Dead code elimination — Tree shaking.
Tree shaking
Допустим, у нас есть приложение, которое использует Lodash. Я сильно сомневаюсь, что кто-то применяет весь Lodash целиком. Скорее всего, эксплуатируется несколько функций типа get, IsEmpty, unionBy или подобных.
Когда мы делаем Tree shaking, мы хотим от Webpack, чтобы он «потряс» ненужные модули и выкинул их, а у нас остались только необходимые. Это и есть Tree shaking.
Как работает Tree shaking в Webpack
Допустим, у вас есть такой код:
Код очень простой: из какого-то модуля импортируете переменную a и выводите ее. Но в этом модуле есть две переменные: a и b. Переменная b нам не нужна, и мы хотим ее убрать.
Когда придет Webpack, он преобразует код с импортом в такой:
Зависимость Webpack преобразует в следующий код:
Webpack оставил экспорт переменной a, и убрал экспорт переменной b, но саму переменную оставил, пометив её специальным комментарием. В преобразованном коде переменная b не используется, и UglifyJS может ее удалить.
Tree shaking в Webpack работает, только если у вас есть какой-нибудь минификатор кода, например, UglifyJS или babel-minify.
Рассмотрим случаи интереснее — когда Tree shaking не работает.
Когда Tree shaking не работает
Кейс № 1. Вы пишете код:
Прогоняете код через Webpack, и он остается таким же. Все потому, что бандлер организует Tree shaking, только если вы используете ES6 модули. Если применяете CommonJS модули, то Tree shaking работать не будет.
Кейс № 2. Вы пишете код с ES6 модулями и именованными экспортами.
Если ваш код прогоняется через Babel и вы не выставили опцию modules в false, то Babel приведет ваши модули к CommonJS, и Webpack опять же не сможет выполнить Tree shaking, ведь он работает только с ES6 модулями.
Соответственно, нам нужно быть уверенными, что никто в нашем пайплане сборки не будет транспайлить ES6 модули.
Когда вы пишете классы и прогоняете их через Babel, они никогда не вырезаются. Как это исправляется? Есть стандартизованный хак — добавить коммент /*#__PURE__*/ перед функцией:
Тогда UglifyJS поверит на слово, что следующая функция чистая. К счастью, сейчас это делает Babel 7, а в Babel 6 до сих пор ничего не удаляется.
Правило: если у вас где-то есть сайд-эффект, то UglifyJS ничего не сделает.
Загружаем только нужный функционал
Эту часть разобьем на две. В первой части загружается только код, который требует пользователь: если пользователь заходит на главную страницу вашего сайта, он не загружает страницы личного кабинета. Во второй, правки в коде приводят к минимально возможной перезагрузке ресурсов.
Загружаем только необходимый код
Рассмотрим структуру воображаемого приложения. В нем есть:
Первая проблема, которую мы хотим решить — это вынесение общего кода. Обозначим красным квадратиком общий код для всех страниц, зеленым кружком — для главной и страницы поиска. Остальные фигуры не особо важны.
Когда пользователь придет на поиск с главной страницы, он будет перезагружать и квадратик, и кружок второй раз, хотя они у него уже есть. В идеале мы хотели бы видеть примерно это.
Хорошо, что в Webpack 4 уже есть встроенный плагин, который это делает за нас — SplitChunksPlugin. Плагин выносит код приложения или код node modules, который используется несколькими чанками в отдельный чанк, при этом гарантирует, что чанк с общим кодом будет больше 30 Kb, а для загрузки страницы требуется загрузить не больше 5 чанков. Стратегия оптимальна: слишком маленькие чанки загружать невыгодно, а загрузка слишком большого количества чанков — долго и не так эффективно, как загрузка меньшего количества чанков даже на http2. Чтобы повторить такое поведение на 2 или 3 версии Webpack, приходилось писать 20–30 строк с не документированными фичами. Сейчас это решается одной строкой.
Вынос CSS
Было бы прекрасно, если бы мы еще вынесли CSS для каждого чанка в отдельный файл. Для этого есть готовое решение — Mini-Css-Extract-Plugin. Плагин появился только в Webpack 4, а до него не было адекватных решений для такой задачи — только хаки, боль и простреленные ноги. Плагин выносит CSS из асинхронных чанков и создан специально для этой задачи, которую выполняет идеально.
Минимально возможная перезагрузка ресурсов
Разберемся, как бы нам сделать так, чтобы при релизе, например, нового промо-блока на главной странице пользователь перезагружал бы минимально возможную часть кода.
Если бы у нас было версионирование — всё было бы хорошо. Вот у нас главная страница версии N, а после релиза промо-блока — версии N+1. Webpack предоставляет подобный механизм прямо из коробки с помощью хэширования. После того, как Webpack соберет все ассеты, — в данном случае app.js, — то посчитает его контент-хэш, и добавит его к имени файла, чтобы получилось app.[hash].js. Это и есть версионирование, которое нам нужно.
Давайте теперь проверим как это работает. Включим хэши, внесем правки на главной странице, и посмотрим — действительно ли изменился код только главной страницы.Мы увидим, что изменились два файла: main и app.js.
Почему так произошло, ведь это нелогично? Чтобы понять почему, давайте разберем app.js. Он состоит из трех частей:
В Webpack 3 и 2 мы бы написали 5-6 строк, вместо одной. Это не сильно больше, но все равно лишнее неудобство.
Все здорово, мы научились выносить ссылки и рантайм! Давайте напишем новый модуль в main, зарелизим, и — оп! — теперь вообще все перезагружается.
Почему так? Давайте разберемся, как работают модули в webpack.
Модули в webpack
Допустим, есть такой код, в котором вы добавляете модули a, b, d и e:
Webpack преобразует импорты в require: a, b, d и e заменились на require(0), require (1), require (2) и require (3).
Представим картину, которая очень часто случается: вы пишете новый модуль c import c from ‘c’; и вставляете его где-то посередине:
Когда Webpack будет все обрабатывать, то преобразует импорт нового модуля в require(2):
Модули d и e, которые были 2 и 3, получат цифры 3 и 4 — новые id. Из этого следует простой вывод: использовать порядковые номера как id немного глупо, но Webpack это делает.
Не используйте порядковый номер как уникальный id
Для исправления проблемы есть встроенное решение Webpack — HashedModuleIdsPlugin:
Этот плагин вместо цифровых id использует 4 символа md4-хэша от абсолютного пути до файла. С ним наши require превратятся в такие:
Вместо цифр появились буквы. Конечно, есть скрытая проблема — это коллизия хэшей. Мы на нее натыкались один раз и можем советовать использовать 8 символов, вместо 4. Настроив хэши правильно, все будет работать так, как мы изначально и хотели.
Мы теперь знаем, как собирать бандл мечты.
Как собрать бандл мечты быстро?
У нас в N1.RU самое большое приложение состоит из 10 000 модулей и без оптимизаций собирается 28 минут. Мы смогли ускорить сборку до двух минут! Как же мы это сделали? Существует 3 способа ускорения любых вычислений, и все три применимы к Webpack.
Параллелизация сборки
Первое, что мы сделали — распараллелили сборку. Для этого у нас есть:
Кэширование результатов сборки
Кэшировать результаты сборки — наиболее эффективный способ ускорения сборки Webpack.
Первое решение, которое у нас есть — cache-loader. Это лоадер, который встает в цепочку лоадеров и сохраняет на файловую систему результат сборки конкретного файла для конкретной цепочки лоадеров. При следующей сборке бандла, если этот файл есть на файловой системе и уже обрабатывался с этой цепочкой, cache-loader возьмет результаты и не будет вызывать те лоадеры, которые стоят за ними, например, Babel-loader или node-sass.
На графике представлено время сборки. Синий столбик — 100% время сборки, без cache-loader, а с ним — на 7% медленнее. Это происходит потому что cache-loader тратит дополнительное время на сохранение кэшей на файловую систему. Уже на а второй сборке мы получили ощутимый профит — сборка прошла в 2 раза быстрее.
Второе решение более навороченное — HardSourcePlugin. Основное отличие: cache-loader — это просто лоадер, который может оперировать только в цепочке лоадеров кодом или файлами, а HardSourcePlugin имеет почти полный доступ к экосистеме Webpack, умеет оперировать другими плагинами и лоадерами, и сам немного расширяет экосистему для кэширования. На графике выше видно, что на первом запуске время сборки увеличилось на 37%, но ко второму запуску со всеми кэшами мы ускорились в 5 раз.
Самое приятное, что можно использовать оба решения вместе, что мы в N1.RU и делаем. Будьте осторожны, потому что с кэшами есть проблемы, о которых я расскажу чуть позже.
В уже используемых вами плагинах/лоадерах могут быть встроенные механизмы кэширования. Например, в babel-loader очень эффективная система кэширования, но почему-то по умолчанию она выключена. Такой же функционал есть в awesome-typeScript-loader. В UglifyJS плагине тоже есть кэширование, которое замечательно работает. Нас он ускорил на несколько минут.
Проблемы кэширования
На чем сэкономить в production?
Последний способ ускорить какой-либо процесс — не делать какие-то части процесса. Давайте подумаем, на чем можно сэкономить в production? Что мы можем не делать? Ответ короткий — мы ничего не можем не делать! Мы не вправе отказаться от чего-то в production, но можем хорошо сэкономить в dev.
Ускорение сборки — это параллелизация, кэширование и отказ от вычислений. Выполнив эти три простых шага, вы можете ускориться очень сильно.
Как конфигурировать Webpack?
Эволюция конфига в проекте
Типичный путь webpack-конфиг в проекте начинается с простого конфига. Сначала вы просто вставляете Webpack, Babel-loader, sass-loader и все хорошо. Потом, неожиданно, появляются какие-то условия на process.env, и вы вставляете условия. Одно, второе, третье, все больше и больше, пока не добавляется условие с «магической» опцией. Вы понимаете, что все уже совсем плохо, и лучше просто продублировать конфиги для dev и production, и сделать правки два раза. Все будет понятнее. Если у вас мелькнула мысль: «Что-то здесь не так?», то единственный работающий совет — держать конфиг в порядке. Расскажу, как мы это делаем.
Держать конфиг в порядке
Мы используем пакет webpack-merge. Это npm-пакет, который создан, чтобы объединять несколько конфигов в один. Если вас не устраивает стратегия объединения по умолчанию, то можно кастомизировать.
Структура проекта с конфигом
У нас есть 4 основные папки:
Plugin/Loader
Это папки, которые содержат файлы для каждого лоадера и плагина, с подробной документацией и более человеческим API, чем тот, что предоставляют разработчики плагинов и лоадеров.
Выглядит это примерно так:
Есть модуль, он экспортирует функцию, которая имеет опции, и есть документация. На словах выглядит хорошо, а в реальности наши доки к url-loader выглядят так:
Мы рассказываем в простой форме, что он делает, как работает, описываем, какие параметры принимают функции, что создает лоадер, и даем ссылку на доки. Я надеюсь, что тот, кто сюда зайдет, точно поймет, как работает url-loader. Сама функция выглядит так:
Мы принимаем два параметра и возвращаем описание от лоадера. Не следует бояться того, что папка Loader будет громоздкой и на каждый лоадер будет по файлу.
Preset
Это набор опций webpack. Они отвечают за одну функциональность, при этом оперируют лоадерами и плагинами, которые мы уже описали, и настройками webpack, которые у него есть. Самый простой пример — это пресет, который говорит, как правильно загружать scss-файлы:
Он использует уже преподготовленные лоадеры.
Части — это то, что уже лежит в самом приложении. Они настраивают точку входа и выхода вашего приложения, и могут регулировать или подключать специфичные плагины, лоадеры и опции. Типичный пример, где мы объявляем точку входа и выхода:
В своей практике мы используем:
Webpack-merge просто выдает нам готовый конфиг. С этим подходом у нас всегда есть документация к конфигурации, в которой достаточно просто разобраться. С webpack-merge мы не лазим по 3-7 конфигам, чтобы поправить везде Babel-loader, потому что у нас есть консистентная конфигурация отдельных частей по всему проекту. А еще интуитивно понятно, где делать правку.
Управление конфигом
Подведем итоги. Используйте готовые инструменты, а не стройте велосипеды. Документируйте решения, потому что webpack конфиги правятся редко и разными людьми — поэтому документация там очень важна. Разделяйте и переиспользуйте то, что пишете.
Теперь вы знаете, как собирать бандл мечты!
Это доклад — один из лучших на Frontend Conf. Понравилось, и хотите больше — подпишитесь на рассылку, в которой мы собираем новые материалы и даем доступ к видео, и приходите на Frontend Conf РИТ++ в мае.
Хотите рассказать миру что-то крутое по фронтенду из своего опыта? Подавайте доклады на FrontenConf РИТ++, который пройдет 27 и 28 мая в Сколково. Присылайте тезисы до 27 марта, а до 15 апреля ПК примет решение о включении доклада в программу конференции. Мы ждем ваш опыт — откликайтесь!