
Дерево
Дерево – структура данных, представляющая собой древовидную структуру в виде набора связанных узлов.
Способ представления бинарного дерева: 
Корень дерева расположен на уровне с минимальным значением.
Если элемент не имеет потомков, он называется листом или терминальным узлом дерева.
Остальные элементы – внутренние узлы (узлы ветвления).
Бинарное дерево применяется в тех случаях, когда в каждой точке вычислительного процесса должно быть принято одно из двух возможных решений.
Имеется много задач, которые можно выполнять на дереве.
Распространенная задача — выполнение заданной операции p с каждым элементом дерева. Здесь p рассматривается как параметр более общей задачи посещения всех узлов или задачи обхода дерева.
Если рассматривать задачу как единый последовательный процесс, то отдельные узлы посещаются в определенном порядке и могут считаться расположенными линейно.
Способы обхода дерева
Пусть имеем дерево, где A — корень, B и C — левое и правое поддеревья.

Существует три способа обхода дерева:
Реализация дерева
Узел дерева можно описать как структуру:
При этом обход дерева в префиксной форме будет иметь вид
Обход дерева в инфиксной форме будет иметь вид
Обход дерева в постфиксной форме будет иметь вид
Бинарное (двоичное) дерево поиска – это бинарное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска):
Данные в каждом узле должны обладать ключами, на которых определена операция сравнения меньше.
Как правило, информация, представляющая каждый узел, является записью, а не единственным полем данных.
Для составления бинарного дерева поиска рассмотрим функцию добавления узла в дерево.
Добавление узлов в дерево
Удаление поддерева
Пример Написать программу, подсчитывающую частоту встречаемости слов входного потока.
Поскольку список слов заранее не известен, мы не можем предварительно упорядочить его. Неразумно пользоваться линейным поиском каждого полученного слова, чтобы определять, встречалось оно ранее или нет, т.к. в этом случае программа работает слишком медленно.
Один из способов — постоянно поддерживать упорядоченность уже полученных слов, помещая каждое новое слово в такое место, чтобы не нарушалась имеющаяся упорядоченность. Воспользуемся бинарным деревом.
В дереве каждый узел содержит:
Рассмотрим выполнение программы на примере фразы
now is the time for all good men to come to the aid of their party
При этом дерево будет иметь следующий вид 
Результат выполнения 
Бинарные деревья поиска и рекурсия – это просто
Существует множество книг и статей по данной теме. В этой статье я попробую понятно рассказать самое основное.
Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. Узел, находящийся на самом верхнем уровне (не являющийся чьим либо потомком) называется корнем. Узлы, не имеющие потомков (оба потомка которых равны NULL) называются листьями.

Рис. 1 Бинарное дерево
Бинарное дерево поиска — это бинарное дерево, обладающее дополнительными свойствами: значение левого потомка меньше значения родителя, а значение правого потомка больше значения родителя для каждого узла дерева. То есть, данные в бинарном дереве поиска хранятся в отсортированном виде. При каждой операции вставки нового или удаления существующего узла отсортированный порядок дерева сохраняется. При поиске элемента сравнивается искомое значение с корнем. Если искомое больше корня, то поиск продолжается в правом потомке корня, если меньше, то в левом, если равно, то значение найдено и поиск прекращается.
Рис. 2 Бинарное дерево поиска
Сбалансированное бинарное дерево поиска — это бинарное дерево поиска с логарифмической высотой. Данное определение скорее идейное, чем строгое. Строгое определение оперирует разницей глубины самого глубокого и самого неглубокого листа (в AVL-деревьях) или отношением глубины самого глубокого и самого неглубокого листа (в красно-черных деревьях). В сбалансированном бинарном дереве поиска операции поиска, вставки и удаления выполняются за логарифмическое время (так как путь к любому листу от корня не более логарифма). В вырожденном случае несбалансированного бинарного дерева поиска, например, когда в пустое дерево вставлялась отсортированная последовательность, дерево превратится в линейный список, и операции поиска, вставки и удаления будут выполняться за линейное время. Поэтому балансировка дерева крайне важна. Технически балансировка осуществляется поворотами частей дерева при вставке нового элемента, если вставка данного элемента нарушила условие сбалансированности.
Рис. 3 Сбалансированное бинарное дерево поиска
Сбалансированное бинарное дерево поиска применяется, когда необходимо осуществлять быстрый поиск элементов, чередующийся со вставками новых элементов и удалениями существующих. В случае, если набор элементов, хранящийся в структуре данных фиксирован и нет новых вставок и удалений, то массив предпочтительнее. Потому что поиск можно осуществлять алгоритмом бинарного поиска за то же логарифмическое время, но отсутствуют дополнительные издержки по хранению и использованию указателей. Например, в С++ ассоциативные контейнеры set и map представляют собой сбалансированное бинарное дерево поиска.
Рис. 4 Экстремально несбалансированное бинарное дерево поиска
Теперь кратко обсудим рекурсию. Рекурсия в программировании – это вызов функцией самой себя с другими аргументами. В принципе, рекурсивная функция может вызывать сама себя и с теми же самыми аргументами, но в этом случае будет бесконечный цикл рекурсии, который закончится переполнением стека. Внутри любой рекурсивной функции должен быть базовый случай, при котором происходит выход из функции, а также вызов или вызовы самой себя с другими аргументами. Аргументы не просто должны быть другими, а должны приближать вызов функции к базовому случаю. Например, вызов внутри рекурсивной функции расчета факториала должен идти с меньшим по значению аргументом, а вызовы внутри рекурсивной функции обхода дерева должны идти с узлами, находящимися дальше от корня, ближе к листьям. Рекурсия может быть не только прямой (вызов непосредственно себя), но и косвенной. Например А вызывает Б, а Б вызывает А. С помощью рекурсии можно эмулировать итеративный цикл, а также работу структуры данных стек (LIFO).
Кратко обсудим деревья с точки зрения теории графов. Граф – это множество вершин и ребер. Ребро – это связь между двумя вершинами. Количество возможных ребер в графе квадратично зависит от количества вершин (для понимания можно представить турнирную таблицу сыгранных матчей). Дерево – это связный граф без циклов. Связность означает, что из любой вершины в любую другую существует путь по ребрам. Отсутствие циклов означает, что данный путь – единственный. Обход графа – это систематическое посещение всех его вершин по одному разу каждой. Существует два вида обхода графа: 1) поиск в глубину; 2) поиск в ширину.
Поиск в ширину (BFS) идет из начальной вершины, посещает сначала все вершины находящиеся на расстоянии одного ребра от начальной, потом посещает все вершины на расстоянии два ребра от начальной и так далее. Алгоритм поиска в ширину является по своей природе нерекурсивным (итеративным). Для его реализации применяется структура данных очередь (FIFO).
Поиск в глубину (DFS) идет из начальной вершины, посещая еще не посещенные вершины без оглядки на удаленность от начальной вершины. Алгоритм поиска в глубину по своей природе является рекурсивным. Для эмуляции рекурсии в итеративном варианте алгоритма применяется структура данных стек.
С формальной точки зрения можно сделать как рекурсивную, так и итеративную версию как поиска в ширину, так и поиска в глубину. Для обхода в ширину в обоих случаях необходима очередь. Рекурсия в рекурсивной реализации обхода в ширину всего лишь эмулирует цикл. Для обхода в глубину существует рекурсивная реализация без стека, рекурсивная реализация со стеком и итеративная реализация со стеком. Итеративная реализация обхода в глубину без стека невозможна.
Асимптотическая сложность обхода и в ширину и в глубину O(V + E), где V – количество вершин, E – количество ребер. То есть является линейной по количеству вершин и ребер. Записи O(V + E) с содержательной точки зрения эквивалентна запись O(max(V,E)), но последняя не принята. То есть, сложность будет определятся максимальным из двух значений. Несмотря на то, что количество ребер квадратично зависит от количества вершин, мы не можем записать сложность как O(E), так как если граф сильно разреженный, то это будет ошибкой.
DFS применяется в алгоритме нахождения компонентов сильной связности в ориентированном графе. BFS применяется для нахождения кратчайшего пути в графе, в алгоритмах рассылки сообщений по сети, в сборщиках мусора, в программе индексирования – пауке поискового движка. И DFS и BFS применяются в алгоритме поиска минимального покрывающего дерева, при проверке циклов в графе, для проверки двудольности.
Обходу в ширину в графе соответствует обход по уровням бинарного дерева. При данном обходе идет посещение узлов по принципу сверху вниз и слева направо. Обходу в глубину в графе соответствуют три вида обходов бинарного дерева: прямой (pre-order), симметричный (in-order) и обратный (post-order).
Прямой обход идет в следующем порядке: корень, левый потомок, правый потомок. Симметричный — левый потомок, корень, правый потомок. Обратный – левый потомок, правый потомок, корень. В коде рекурсивной функции соответствующего обхода сохраняется соответствующий порядок вызовов (порядок строк кода), где вместо корня идет вызов данной рекурсивной функции.
Если нам дано изображение дерева, и нужно найти его обходы, то может помочь следующая техника (см. рис. 5). Обводим дерево огибающей замкнутой кривой (начинаем идти слева вниз и замыкаем справа вверх). Прямому обходу будет соответствовать порядок, в котором огибающая, двигаясь от корня впервые проходит рядом с узлами слева. Для симметричного обхода порядок, в котором огибающая, двигаясь от корня впервые проходит рядом с узлами снизу. Для обратного обхода порядок, в котором огибающая, двигаясь от корня впервые проходит рядом с узлами справа. В коде рекурсивного вызова прямого обхода идет: вызов, левый, правый. Симметричного – левый, вызов, правый. Обратного – левый правый, вызов.
Рис. 5 Вспомогательный рисунок для обходов
Для бинарных деревьев поиска симметричный обход проходит все узлы в отсортированном порядке. Если мы хотим посетить узлы в обратно отсортированном порядке, то в коде рекурсивной функции симметричного обхода следует поменять местами правого и левого потомка.
Надеюсь Вы не уснули, и статья была полезна. Скоро надеюсь последует продолжение банкета статьи.
Дерево как структура данных

Какую выгоду можно извлечь из такой структуры данных, как дерево? В этой статье мы расскажем о данных в виде дерева, рассмотрим основные определения, которые следует знать, а также узнаем, как и зачем используется дерево в программировании. Спойлер: бинарные деревья часто применяют для поиска информации в базах данных, для сортировки данных, для проведения вычислений, для кодирования и в других случаях. Но давайте обо всем по порядку.
Основные термины
Дерево — это, по сути, один из частных случаев графа. Древовидная модель может быть весьма эффективна в случае представления динамических данных, особенно тогда, когда у разработчика стоит цель быстрого поиска информации, в тех же базах данных, к примеру. Еще древом называют структуру данных, которая представляет собой совокупность элементов, а также отношений между этими элементами, что вместе образует иерархическую древовидную структуру.
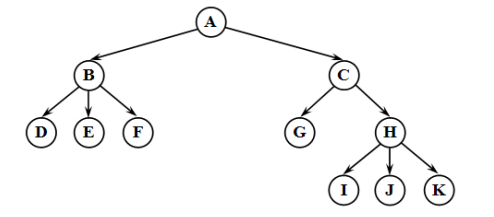
Каждый элемент — это вершина или узел дерева. Узлы, соединенные направленными дугами, называются ветвями. Начальный узел — это корень дерева (корневой узел). Листья — это узлы, в которые входит 1 ветвь, причем не выходит ни одной.
Общую терминологию можно посмотреть на левой и правой части картинки ниже:
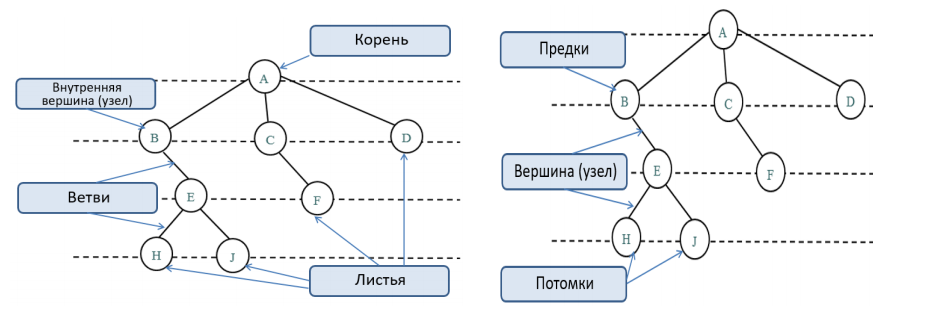
Какие свойства есть у каждого древа:
— существует узел, в который не входит ни одна ветвь;
— в каждый узел, кроме корневого узла, входит 1 ветвь.
На практике деревья нередко применяют, изображая различные иерархии. Очень популярны, к примеру, генеалогические древа — они хорошо известны. Все узлы с ветвями, исходящими из единой общей вершины, являются потомками, а сама вершина называется предком (родительским узлом). Корневой узел не имеет предков, а листья не имеют потомков.
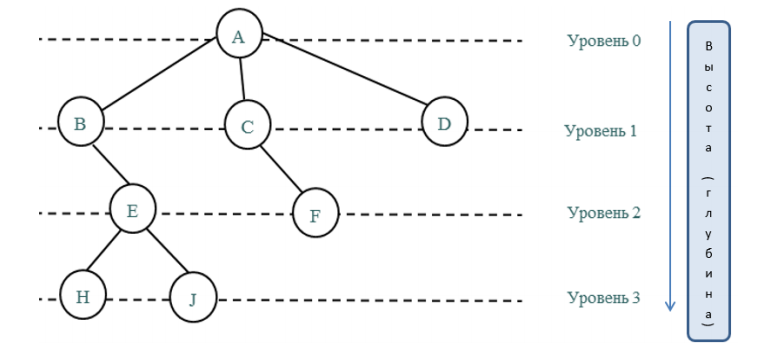
Также у дерева есть высота (глубина). Она определяется числом уровней, на которых располагаются узлы дерева. Глубина пустого древа равняется нулю, а если речь идет о дереве из одного корня, тогда единице. В данном случае на нулевом уровне может быть лишь одна вершина – корень, на 1-м – потомки корня, на 2-м – потомки потомков корня и т. д.
Ниже изображен графический вывод древа с 4-мя уровнями (дерево имеет глубину, равную четырем):
Следующий термин, который стоит рассмотреть, — это поддерево. Поддеревом называют часть древообразной структуры, которую можно представить в виде отдельного дерева.
Идем дальше. Древо может быть упорядоченным — в данном случае ветви, которые исходят из каждого узла, упорядочены по некоторому критерию.
Степень вершины в древе — это число ветвей (дуг), выходящих из этой вершины. Степень равняется максимальной степени вершины, которая входит в дерево. В этом случае листьями будут узлы, имеющие нулевую степень. По величине степени деревья бывают:
— двоичные (степень не больше двух);
— сильноветвящиеся (степень больше двух).
Деревья — это рекурсивные структуры, ведь каждое поддерево тоже является деревом. Каждый элемент такой рекурсивной структуры является или пустой структурой, или компонентом, с которым связано конечное количество поддеревьев.
Когда мы говорим о рекурсивных структурах, то действия с ними удобнее описывать посредством рекурсивных алгоритмов.
Обход древа
Чтобы выполнить конкретную операцию над всеми вершинами, надо все эти узлы просмотреть. Данную задачу называют обходом дерева. То есть обход представляет собой упорядоченную последовательность узлов, в которой каждый узел встречается лишь один раз.
В процессе обхода все узлы должны посещаться в некотором, заранее определенном порядке. Есть ряд способов обхода, вот три основные:
— прямой (префиксный, preorder);
— симметричный (инфиксный, inorder);
— обратный (постфиксный, postorder).
Существует много древовидных структур данных: двоичные (бинарные), красно-черные, В-деревья, матричные, смешанные и пр. Поговорим о бинарных.
Бинарные (двоичные) деревья
Бинарные имеют степень не более двух. То есть двоичным древом можно назвать динамическую структуру данных, где каждый узел имеет не большое 2-х потомков. В результате двоичное дерево состоит из элементов, где каждый из элементов содержит информационное поле, а также не больше 2-х ссылок на различные поддеревья. На каждый элемент древа есть только одна ссылка.
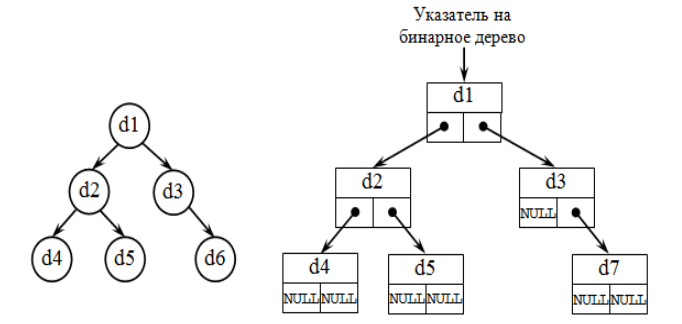
У бинарного древа каждый текущий узел — это структура, которая состоит из 4-х видов полей. Какие это поля:
— информационное (ключ вершины);
— служебное (включена вспомогательная информация, однако таких полей может быть несколько, а может и не быть вовсе);
— указатель на правое поддерево;
— указатель на левое поддерево.
Самый удобный вид бинарного древа — бинарное дерево поиска.
Что значит древо в контексте программирования?
Мы можем долго рассуждать о математическом определении древа, но это вряд ли поможет понять, какие именно выгоды можно извлечь из древовидной структуры данных. Тут важно отметить, что древо является способом организации данных в форме иерархической структуры.
В каких случаях древовидные структуры могут быть полезны при программировании:
— поиск данных в базах данных (специально построенных деревьях);
Структуры данных. Деревья
Статья познакомит вас с понятием дерева как структуры данных, пояснит в каких случаях и для чего можно их применять:
1 Что такое деревья (в программировании)?
Математическое определение дерева — «граф без петель и циклов» вряд-ли пояснит рядовому человеку какие выгоды можно извлечь из такой структуры данных.
В некоторых книгах, посвященным разработке алгоритмов, деревья определяются рекурсивно. Дерево является либо пустым, либо состоит из узла (корня), являющегося родительским узлом для некоторого количества деревьев (это количество определяет арность дерева) [1, 2].
Рабочее определение (в рамках этой статьи): дерево — это способ организации данных в виде иерархической структуры.
Когда применяются древовидные структуры:
Двоичный поиск [3] выполняется над отсортированным массивом. На каждом шаге искомый элемент сравнивается со значением, находящимся посередине массива. В зависимости от результатов сравнения — либо левая, либо правая части могут быть «отброшены».
Иерархия — способ упорядочивания объектов, соответственно применять ее можно для ускорения поиска. Именно этому посвящена остальная часть статьи.
2 Деревья и другие структуры данных
Итак, у нас есть много данных — возможно это информация о температуре за несколько лет, а может быть — данные о фирмах в вашем городе. Как хранить их внутри вашего приложения? — Правильный ответ зависит от того, как именно вы будете пользоваться этими данными.
В таблице приведены асимптотические оценки часто используемых операций над некоторыми структурами данных. На случай если вы еще не освоили асимптотический анализ, в таблице показано примерное значение количества действий, необходимых для выполнения операции над контейнером из 10 тысяч элементов.
| Операция | неупорядоченный массив | упорядоченный массив | неупорядоченный двусвязный список | сбалансированное дерево поиска |
|---|---|---|---|---|



4 Kd-деревья
Во многих программах появляется необходимость хранения и эффективной обработки объектов на плоскости. Это не только картографические приложения, но и все двумерные игры. Задумывались ли вы о том, как эту задачу решают игровые движки?

Мы уже разобрались с тем, что для эффективной реализации поиска объекты нужно хранить упорядоченными. Однако, как хранить точки? — ведь у них есть две (или три) координаты, а сортировка по одной из них не обеспечит приемлемую скорость поиска. Именно эти проблемы решают Kd-деревья.
Общая идея kd-деревьев заключается в разделении плоскости, содержащей объекты на части (прямоугольные области) таким образом, что в каждой области содержится один объект. При этом, между областями можно выстроить иерархические зависимости, за счет которых можно существенно повысить эффективность поиска. Существуют различные типы kd-деревьев, отличающиеся выбором секущей плоскости.
Задача: есть множество точек, находящихся на плоскости, нужно выстроить объекты в иерархическую структуру, исходя из их координат для обеспечения эффективного поиска. Описанные ниже подходы можно обобщить до более сложных геометрических объектов (не точек) и пространств больших размерностей.
Первый вариант решения:

С такой структурой данных, алгоритм вывода всех точек, входящих в Прямоугольник может выглядеть так:
Цветом на приведенной выше схеме обозначена область поиска. Она не пересекается с областью B (расположенной левее А ). Даже если бы в этой области были миллионы точек — мы «отсекли» бы их за одну итерацию алгоритма — то есть мы получили полноценный двоичный поиск на плоскости. Визуализация алгоритма: 
При перемещении объектов может возникать необходимость перестроения дерева — если объект переместился из одной области «родительского» объекта в другую.
Описанный подход называется Kd-деревья с циклическим проходом по измерениям. Возможны и другие варианты выбора секущей плоскости — например каждый узел квадрадерева делит свою часть плоскости на 4 части (левая верхняя, левая нижняя, правая верхняя, права нижняя). Если в какой-то части оказывается более 1 объекта — то она делится дальше. Октадеревья адаптируют эту идею к трехмерному пространству.