Многие сегодня хотят стать программистами. Хотят. Но ничего не делают для этого. Не делают даже простых вещей. Не хотят даже прочитать книжку из 10 страниц. В итоге так и остаются никем. Потому что мечты не сбываются никогда. Сбываются только планы… Подробнее.
Наверняка вы уже задавались вопросом, как сохранить какие-то данные программы на диске, а потом прочитать их. Очень часто в файлах хранятся разные настройки программы. На первых этапах файлы также можно использовать для обмена данными между программами.
Итак, начнём с того, что понятие файл в Паскале имеет дав смысла:
Чтобы начать работать с внешним файлом, нужно установить связь между внутренним и внешним файлом. И тогда, всё что будет происходить с внутренним файлом, будет также происходить и с внешним файлом.
Говоря по простому, для того, чтобы начать работать с файлом в вашей программе, нужно
связать с внешним файлом файловую переменную
Делается это так. Сначала объявляем файловую переменную:
iFile : file of integer;
Теперь с этой переменной можно работать. Например, так:
Здесь мы связываем объявленную ранее файловую переменную iFile с реальным файлом на диске. Этого файла на диске может и не быть, но имя файла должно быть правильным именем файла, допустимым в операционной системе, для которой создаётся программа.
Далее мы открываем файл для записи, а затем записываем в него число 100.
После завершения работы с файлом его нужно обязательно закрыть. Иначе могут возникнуть утечки памяти и другие проблемы.
Функция Rewrite не только открывает файл для записи, но и создаёт его, если этого файла раньше не было. Если файл был, то он будет перезаписан. Поэтому будьте внимательны. По идее, надо сначала проверить существование файла, и только потом принимать решения, что делать дальше.
В нашем примере мы создаём файл с именем iFile.txt в той же папке, откуда была запущена программа. Если нужно создать файл в другом месте, то нужно указывать полный путь к файлу. Если вы не знаете, что такое полный путь к файлу, то рекомендую прочитать книгу Компьютер для чайника.
Итак, мы умеем создавать файлы и записывать в них информацию. Теперь научимся читать файл.
Открываем файл с помощью функции Reset. Читаем данные из файла с помощью функции Read и сохраняем их в переменной i.
Записывать в файл всего одно число конечно можно. А иногда этого вполне достаточно. Однако может возникнуть необходимость записать несколько однотипных чисел. Сделать это можно так:
Прочитать такой файл можно так:
Но как быть, если вам не нужно читать все значения? Как получить доступ к конкретному значению в файле?
Есть специальная функция, которая может переместить указатель файла в любое его место.
Функция Seek перемещает указать на заданную позицию. Обратите внимание, что в нашем примере мы начинаем отсчёт с нуля, поэтому 8-я позиция содержит число 8, хотя фактически это 9-е число в файле.
Тип файловой переменной может быть любым, кроме файлового. В том числе пользовательским. Это означает, что вы можете хранить в файле сложные структуры данных, такие как записи, массивы и т.п.
Это, в свою очередь, означает, что вы таким образом можете сохранять в файлах (а затем читать), например, какие-то настройки программы.
Объявляется нетипизированная файловая переменная, например, так:
Записать данные в файл можно так:
Обратите внимание, что здесь мы используем функцию WriteLn, для того, чтобы записывать каждое число с новой строки. Разумеется, можно использовать и Write, но тогда всё будет записано в одну строку, а в некоторых случаях это неудобно.
Теперь прочитаем все строки файла и выведем их на экран.
Перед тем, как использовать этот пример, надо объявить переменную str строкового типа.
Затем открываем файл для чтения, читаем каждую его строку и выводим на экран.
Поскольку мы можем не знать, сколько строк имеется в файле, то мы используем функцию Eof, которая возвращает TRUE, когда достигнут конец файла.
Есть ещё один момент, который может оказаться вам полезным. Если вам не нужно полностью перезаписывать файл, а достаточно добавить только одну строку, то можно использовать функцию Append, которая открывает файл для добавления данных. При этом все старые данные сохраняются, а новые данные добавляются в конец файла. Пример:
Ну что же, на этом остановимся, дабы не перегружать начинающих избыточной информацией. Для многих случаев этих знаний о работе с файлами вам будет вполне достаточно. Во всяком случае на начальном этапе обучения программированию.
Если файл поддерживает произвольный доступ, открытие файла инициализирует индикатор позиции файла на начало файла. По мере чтения или записи символов в файл индикатор позиции увеличивается, обеспечивая тем самым продвижение по файлу.
Связь потока с файлом уничтожается с помощью операции закрытия. Закрытие потока вызывает принудительный сброс всего содержимого буфера во внешнее устройство (если необходимо, информация будет дополнена для создания полного сектора). Данный процесс, как правило, называется очисткой буфера, и он гарантирует, что в буфере не останется информации. Все файлы закрываются автоматически, когда программа нормальным образом завершает работу, выходя из функции main() или с помощью вызова exit(). Тем не менее, лучше самому закрыть файлы, используя fclose() в тот момент, когда файл уже не нужен, поскольку некоторые события могут помешать записи буфера на диск. Например, файл не записывается, если программа завершает работу вызовом abort(), если она разрушается или если пользователь выключает компьютер перед завершением программы.
В начале работы программы открыты пять предопределенных текстовых потоков: stdin, stdout, stderr, stdaux и stdprn. Они соответствуют следующим стандартным устройствам ввода/вывода:
Поток
Устройство
stdin stdout stderr stdaux stdprn
Клавиатура Экран Экран Первый последовательный порт Принтер
Каждый поток, ассоциированный с файлом, имеет структуру управления файлом типа FILE. Данная структура определена в заголовочном файле stdio.h. Не следует модифицировать данную структуру.
Для новичков в программировании разделение потоков и файлов в С может показаться надуманным. Просто надо помнить, что основная цель состоит в предоставлении постоянного интерфейса. В С следует думать в терминах потоков и использовать только одну файловую систему для выполнения операций ввода/вывода. Система ввода/вывода С автоматически преобразует необработанную информацию, поступающую со входа или на выход, в легко управляемый поток.
Для удобства обращения информация в запоминающих устройствах хранится в виде файлов.
Файл – именованная область внешней памяти, выделенная для хранения массива данных. Данные, содержащиеся в файлах, имеют самый разнообразный характер: программы на алгоритмическом или машинном языке; исходные данные для работы программ или результаты выполнения программ; произвольные тексты; графические изображения и т. п.
Файловой системой называется функциональная часть операционной системы, обеспечивающая выполнение операций над файлами. Примерами файловых систем являются FAT (FAT – File Allocation Table, таблица размещения файлов), NTFS, UDF (используется на компакт-дисках).
Существуют три основные версии FAT: FAT12, FAT16 и FAT32. Они отличаются разрядностью записей в дисковой структуре, т.е. количеством бит, отведённых для хранения номера кластера. FAT12 применяется в основном для дискет (до 4 кбайт), FAT16 – для дисков малого объёма, FAT32 – для FLASH-накопителей большой емкости (до 32 Гбайт).
Рассмотрим структуру файловой системы на примере FAT32.
Файловая структура FAT32
Устройства внешней памяти в системе FAT32 имеют не байтовую, а блочную адресацию. Запись информации в устройство внешней памяти осуществляется блоками или секторами.
Сектор – минимальная адресуемая единица хранения информации на внешних запоминающих устройствах. Как правило, размер сектора фиксирован и составляет 512 байт. Для увеличения адресного пространства устройств внешней памяти сектора объединяют в группы, называемые кластерами.
Кластер – объединение нескольких секторов, которое может рассматриваться как самостоятельная единица, обладающая определёнными свойствами. Основным свойством кластера является его размер, измеряемый в количестве секторов или количестве байт.
Файловая система FAT32 имеет следующую структуру. Нумерация кластеров, используемых для записи файлов, ведется с 2. Как правило, кластер №2 используется корневым каталогом, а начиная с кластера №3 хранится массив данных. Сектора, используемые для хранения информации, представленной выше корневого каталога, в кластеры не объединяются. Минимальный размер файла, занимаемый на диске, соответствует 1 кластеру.
Загрузочный сектор начинается следующей информацией:
Кроме того, загрузочный сектор содержит следующую важную информацию:
Сектор информации файловой системы содержит:
Таблица FAT содержит информацию о состоянии каждого кластера на диске. Младшие 2 байт таблицы FAT хранят F8 FF FF 0F FF FF FF FF (что соответствует состоянию кластеров 0 и 1, физически отсутствующих). Далее состояние каждого кластера содержит номер кластера, в котором продолжается текущий файл или следующую информацию:
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:
В случае работы с длинными именами файлов (включая русские имена) кодировка имени файла производится в системе кодировки UTF-16. При этого для кодирования каждого символа отводится 2 байта. При этом имя файла записывается в виде следующей структуры:
Далее следует запись, включающая имя файла в формате 8.3 в обычном формате.
Работа с файлами в языке Си
Чтение символа из файла:
Запись символа в файл:
Функции fgets() и fputs() предназначены для ввода-вывода строк, они являются аналогами функций gets() и puts() для работы с файлами.
Результат выполнения — 2 файла Работа с файлами в C++ описана здесь.
Компьютерный файл используется для хранения данных в цифровом формате, таких как обычный текст, данные изображений или любой другой контент. Компьютерные файлы могут быть организованы в разных каталогах. Файлы используются для хранения цифровых данных, а каталоги — для хранения файлов.
Ввод / вывод файла
Обычно вы создаете файлы с помощью текстовых редакторов, таких как блокнот, MS Word, MS Excel или MS Powerpoint и т. Д. Однако, часто нам также нужно создавать файлы с помощью компьютерных программ. Мы можем изменить существующий файл с помощью компьютерной программы.
Ввод файла означает данные, которые записываются в файл, а вывод файла означает данные, которые считываются из файла. На самом деле, условия ввода и вывода больше связаны с вводом и выводом экрана. Когда мы отображаем результат на экране, он называется выводом. Точно так же, если мы предоставляем некоторый ввод нашей программе из командной строки, то это называется ввод.
Пока достаточно вспомнить, что запись в файл — это ввод файла, а чтение чего-либо из файла — вывод файла.
Режимы работы с файлами
Прежде чем мы начнем работать с любым файлом с помощью компьютерной программы, нам нужно либо создать новый файл, если он не существует, либо открыть уже существующий файл. В любом случае мы можем открыть файл в следующих режимах:
Режим только для чтения — если вы собираетесь просто прочитать существующий файл и не хотите записывать в него какой-либо другой контент, то вы откроете файл в режиме только для чтения. Почти все языки программирования предоставляют синтаксис для открытия файлов в режиме только для чтения.
Режим только для записи — если вы собираетесь записывать либо в существующий файл, либо во вновь созданный файл, но не хотите читать какой-либо записанный контент из этого файла, тогда вы откроете файл в режиме только для записи. Все языки программирования предоставляют синтаксис для открытия файлов в режиме только для записи.
Режим чтения и записи — если вы собираетесь читать и писать в один и тот же файл, то вы откроете файл в режиме чтения и записи.
Режим добавления — когда вы открываете файл для записи, он позволяет начать запись с начала файла; однако он перезапишет существующий контент, если таковой имеется. Предположим, мы не хотим перезаписывать какой-либо существующий контент, затем мы открываем файл в режиме добавления. Режим добавления, в конечном счете, является режимом записи, который позволяет добавлять содержимое в конец файла. Почти все языки программирования предоставляют синтаксис для открытия файлов в режиме добавления.
Режим только для чтения — если вы собираетесь просто прочитать существующий файл и не хотите записывать в него какой-либо другой контент, то вы откроете файл в режиме только для чтения. Почти все языки программирования предоставляют синтаксис для открытия файлов в режиме только для чтения.
Режим только для записи — если вы собираетесь записывать либо в существующий файл, либо во вновь созданный файл, но не хотите читать какой-либо записанный контент из этого файла, тогда вы откроете файл в режиме только для записи. Все языки программирования предоставляют синтаксис для открытия файлов в режиме только для записи.
Режим чтения и записи — если вы собираетесь читать и писать в один и тот же файл, то вы откроете файл в режиме чтения и записи.
Режим добавления — когда вы открываете файл для записи, он позволяет начать запись с начала файла; однако он перезапишет существующий контент, если таковой имеется. Предположим, мы не хотим перезаписывать какой-либо существующий контент, затем мы открываем файл в режиме добавления. Режим добавления, в конечном счете, является режимом записи, который позволяет добавлять содержимое в конец файла. Почти все языки программирования предоставляют синтаксис для открытия файлов в режиме добавления.
В следующих разделах мы узнаем, как открыть новый новый файл, как записать в него, а позже, как читать и добавлять больше содержимого в тот же файл.
Открытие файлов
Здесь имя файла является строковым литералом, который вы будете использовать для именования вашего файла, а режим доступа может иметь одно из следующих значений:
Sr.No
Режим и описание
1
Открывает существующий текстовый файл для чтения.
Открывает текстовый файл для записи. Если он не существует, то создается новый файл. Здесь ваша программа начнет писать содержимое с начала файла.
Открывает текстовый файл для записи в режиме добавления. Если он не существует, то создается новый файл. Здесь ваша программа начнет добавлять содержимое в существующий файл содержимого.
Открывает текстовый файл для чтения и записи как.
Открывает текстовый файл для чтения и записи. Сначала он обрезает файл до нулевой длины, если он существует; в противном случае создает файл, если он не существует.
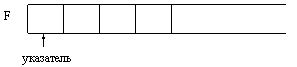
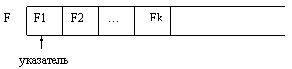
Существенной особенностью всех рассмотренных до сих пор значений производных типов является наличие в них конечного, наперед заданного числа компонент. Так, в значении многомерного массива это число можно определить, зная количество компонент по каждому измерению, а в значении записи это число определяется количеством и типом полей. Таким образом, заранее, еще до выполнения программы, по этому описанию можно выделить необходимый объем памяти машины для хранения значений переменных этих типов. Но существует определенный класс задач и определенные ситуации, когда количество компонент (пусть даже одного и того же из известных уже типов) заранее определить невозможно, оно выясняется только в процессе решения задачи. Поэтому возникает необходимость в специальном типе значений, которые представляют собой произвольные последовательности элементов одного и того же типа, причем длина этих последовательностей заранее не определяется, а конкретизируется в процессе выполнения программы. Этот тип значений получил название файлового типа. Условно файл в Паскале можно изобразить как некоторую ленту, у которой есть начало, а конец не фиксируется. Элементы файла записываются на эту ленту последовательно друг за другом:
где F – имя файла, а F1, F2, F3, F4 – его элементы. Файл во многом напоминает магнитную ленту, начало которой заполнено записями, а конец пока свободен. В программировании существует несколько разновидностей файлов, отличающихся методом доступа к его компонентам:файлы последовательного доступа и файлы произвольного доступа.
Простейший метод доступа состоит в том, что по файлу можно двигаться только последовательно, начиная с первого его элемента, и, кроме этого, всегда существует возможность начать просмотр файла с его начала. Таким образом, чтобы добраться до пятого элемента файла, необходимо, начав с первого элемента, пройти через предыдущие четыре. Такие файлы называют файлами последовательного доступа. У последовательного файла доступен всегда лишь очередной элемент. Если в процессе решения задачи необходим какой-либо из предыдущих элементов, то необходимо вернуться в начало файла и последовательно пройти все его элементы до нужного.
Файлы произвольного доступа Паскаля позволяют вызывать компоненты в любом порядке по их номеру.
Важной особенностью файлов является то, что данные, содержащиеся в файле, переносятся на внешние носители. Файловый тип Паскаля – это единственный тип значений, посредством которого данные, обрабатываемые программой, могут быть получены извне, а результаты могут быть переданы во внешний мир. Это единственный тип значений, который связывает программу с внешними устройствами ЭВМ.
Работа с файлами в Паскале
Любой файл имеет три характерные особенности. Во-первых, у него есть имя, что дает возможность программе работать одновременно с несколькими файлами. Во-вторых, он содержит компоненты одного типа. Типом компонентов может быть любой тип Паскаля, кроме файлов. Иными словами, нельзя создать «файл файлов». В-третьих, длина вновь создаваемого файла никак не оговаривается при его объявлении и ограничивается только емкостью устройств внешней памяти.
Файловый тип или переменную файлового типа в Паскале можно задать одним из трех способов:
Здесь – имя файлового типа (правильный идентификатор); File, of – зарезервированные слова (файл, из); – любой тип Паскаля, кроме файлов.
Пример описания файлового типа в Паскале
В зависимости от способа объявления можно выделить три вида файлов Паскаля:
Следует помнить, что физические файлы на магнитных дисках и переменные файлового типа в программе на Паскале – объекты различные. Переменные файлового типа в Паскале могут соответствовать не только физическим файлам, но и логическим устройствам, связанным с вводом/выводом информации. Например, клавиатуре и экрану соответствуют файлы со стандартными именами Input, Output.
Как известно, каждый тип данных в Паскале, вообще говоря, определяет множество значений и множество операций над значениями этого типа. Однако над значениями файлового типа Паскаля не определены какие-либо операции, в том числе операции отношения и присваивания, так что даже такое простое действие, как присваивание значения одной файловой переменной другой файловой переменной, имеющей тот же самый тип, запрещено. Все операции могут производиться лишь с элементами (компонентами) файлов. Естественно, что множество операций над компонентами файла определяется типом компонент.
Переменные файлового типа используются в программе только в качестве параметров собственных и стандартных процедур и функций.
Основные процедуры и функции для работы с файлами
1.До начала работы с файлами в Паскале необходимо установить связь между файловой переменной и именем физического дискового файла:
Следует помнить, что имя дискового файла при необходимости должно содержать путь доступа к этому файлу, включая имя дисковода. При этом имя дискового файла – строковая величина, т.е. должна быть заключена в апострофы. Например:
Пример процедуры Assign в Паскале
Если путь не указан, то программа будет искать файл в своем рабочем каталоге и по указанным путям в autoexec.bat.
Вместо имени дискового файла можно указать имя логического устройства, каждое из которых имеет стандартное имя:
CON – консоль, т.е. клавиатура-дисплей;
PRN – принтер. Если к компьютеру подключено несколько принтеров, доступ к ним осуществляется по именам LPT1, LPT2, LPT3.
Не разрешается связывать с одним физическим файлом более одной файловой переменной.
2.После окончания работы с файлами на Паскале, они должны быть закрыты.
При выполнении этой процедуры закрываются соответствующие физические файлы и фиксируются сделанные изменения. Следует иметь в виду, что при выполнении процедуры close связь файловой переменной с именем дискового файла, установленная ранее процедурой assign, сохраняется, следовательно, файл можно повторно открыть без дополнительного использования процедуры assign.
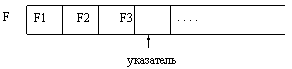
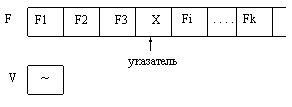
Работа с файлами заключается, в основном, в записи элементов в файл и считывании их из файла. Для удобства описания этих процедур введем понятие указателя, который определяет позицию доступа, т.е. ту позицию файла, которая доступна для чтения (в режиме чтения), либо для записи (в режиме записи). Позиция файла, следующая за последней компонентой файла (или первая позиция пустого файла) помечается специальным маркером, который отличается от любых компонент файла. Благодаря этому маркеру определяется конец файла.
3.Подготовка к записи в файл Паскаля
Процедура Rewrite(f) (где f – имя файловой переменной) устанавливает файл с именем f в начальное состояние режима записи, в результате чего указатель устанавливается на первую позицию файла. Если ранее в этот файл были записаны какие-либо элементы, то они становятся недоступными. Результат выполнения процедуры rewrite(f); выглядит следующим образом:
4.Запись в файл Паскаля
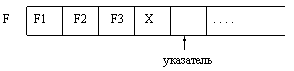
При выполнении процедуры write(f, x) в ту позицию, на которую показывает указатель, записывается очередная компонента, после чего указатель смещается на следующую позицию. Естественно, тип выражения х должен совпадать с типом компонент файла. Результат действия процедуры write(f, x) можно изобразить так:
Состояние файла f до выполнения процедуры
Состояние файла f после выполнения процедуры
Для типизированных файлов выполняется следующее утверждение: если в списке записи перечислено несколько выражений, то они записываются в файл, начиная с первой доступной позиции, а указатель смещается на число позиций, равное числу записываемых выражений.
5.Подготовка файла к чтению Паскаля
Эта процедура ищет на диске уже существующий файл и переводит его в режим чтения, устанавливая указатель на первую позицию файла. Результат выполнения этой процедуры можно изобразить следующим образом:
Если происходит попытка открыть для чтения не существующий еще на диске файл, то возникает ошибка ввода/вывода, и выполнение программы будет прервано.
6.Чтение из файла в Паскале
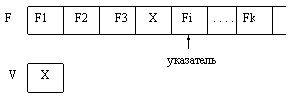
Рассмотрим результат действия процедуры read(f, v):
Состояние файла f и переменной v до выполнения процедуры:
Состояние файла f и переменной v после выполнения процедуры:
Для типизированных файлов при выполнении процедуры read() последовательно считывается, начиная с текущей позиции указателя, число компонент файла, соответствующее числу переменных в списке, а указатель смещается на это число позиций.
В большинстве задач, в которых используются файлы, необходимо последовательно перебрать компоненты и произвести их обработку. В таком случае необходимо иметь возможность определять, указывает ли указатель на какую-то компоненту файла, или он уже вышел за пределы файла и указывает на маркер конца файла.
7.Функция определения достижения конца файла в Паскале
Название этой функции является сложносокращенным словом от end of file. Значение этой функции имеет значение true, если конец файла уже достигнут, т.е. указатель стоит на позиции, следующей за последней компонентой файла. В противном случае значение функции – false.
8.Изменение имени файла в Паскале
Здесь новое_ имя_ файла – строковое выражение, содержащее новое имя файла, возможно с указанием пути доступа к нему.
Перед выполнением этой процедуры необходимо закрыть файл, если он ранее был открыт.
9.Уничтожение файла в Паскале
Перед выполнением этой процедуры необходимо закрыть файл, если он ранее был открыт.
10.Уничтожение части файла от текущей позиции указателя до конца в Паскале
11.Файл Паскаля может быть открыт для добавления записей в конец файла
Типизированные файлы Паскаля. Длина любого компонента типизированного файла строго постоянна, т.к. тип компонент определяется при описании, а, следовательно, определяется объем памяти, отводимый под каждую компоненту. Это дает возможность организовать прямой доступ к каждой компоненте (т.е. доступ по порядковому номеру).
Перед первым обращением к процедурам ввода/вывода указатель файла стоит в его начале и указывает на его первый компонент с номером 0. После каждого чтения или записи указатель сдвигается к следующему компоненту файла. Переменные и выражения в списках ввода и вывода в процедурах read() и write() должны иметь тот же тип, что и компоненты файла Паскаля. Если этих переменных или выражений в списке несколько, то указатель будет смещаться после каждой операции обмена данными на соответствующее число позиций.
Для облегчения перемещения указателя по файлу и доступа к компонентам типизированного файла существуют специальные процедуры и функции:
fileSize( ) – функция Паскаля, определяющая число компонентов в файле;
filePos( ) – функция Паскаля, значением которой является текущая позиция указателя;
Текстовые файлы Паскаля. Текстовые файлы предназначены для хранения текстовой информации. Именно в таких файлах хранятся, например, исходные тексты программ. Компоненты текстовых файлов могут иметь переменную длину, что существенно влияет на характер работы с ними. Доступ к каждой строке текстового файла Паскаля возможен лишь последовательно, начиная с первой. К текстовым файлам применимы процедуры assign, reset, rewrite, read, write и функция eof. Процедуры и функции seek, filepos, filesize к ним не применяются. При создании текстового файла в конце каждой записи (строки) ставится специальный признак EOLN(end of line – конец строки). Для определения достижения конца строки существует одноименная логическая функция EOLN( ), которая принимает значение true, если конец строки достигнут.
Форма обращения к процедурам write и read для текстовых и типизированных файлов одинакова, но их использование принципиально различается.
В списке записываемых в текстовый файл элементов могут чередоваться в произвольном порядке числовые, символьные, строковые выражения. При этом строковые и символьные элементы записываются непосредственно, а числовые из машинной формы автоматически преобразуются в строку символов.
Так, в типизированном файле числа 6, 65 и 165 как целые будут представлены одним и тем же числом байт. А в текстовых файлах, после преобразования в строку, они будут иметь разную длину. Это вызывает проблемы при расшифровке текстовых файлов. Пусть в текстовый файл пишутся подряд целые числа (типа byte): 2, 12, 2, 128. Тогда в файле образуется запись 2122128. При попытке прочитать из такого файла переменную типа byte программа прочитает всю строку и выдаст сообщение об ошибке, связанной с переполнением диапазона.
Но, вообще-то, такой файл не понимает не только машина, а и человек.
Чтобы избежать этой ошибки, достаточно вставить при записи в файл после каждой переменной пробел. Тогда программа при каждом чтении берет символы от пробела до пробела и правильно преобразует текстовое представление в число.
Кроме процедур read и write при работе с текстовыми файлами используются их разновидности readln и writeln. Отличие заключается в том, что процедура writeln после записи заданного списка записывает в файл специальный маркер конца строки. Этот признак воспринимается как переход к новой строке. Процедура readln после считывания заданного списка ищет в файле следующий признак конца строки и подготавливается к чтению с начала следующей строки.
Пример решения задачи с файлами Паскаля
Пусть нам необходимо сформировать текстовый файл с помощью Паскаля, а затем переписать из данного файла во второй только те строки, которые начинаются с буквы «А» или «а».
Пояснения: нам понадобятся две файловые переменные f1 и f2, поскольку оба файла текстовые, то тип переменных будет text. Задача разбивается на два этапа: первый – формирование первого файла; второй – чтение первого файла и формирование второго.
Для завершенности решения задачи есть смысл добавить еще одну часть, которая в задаче явно не указана – вывод на экран содержимого второго файла.