
Что такое кодировки?
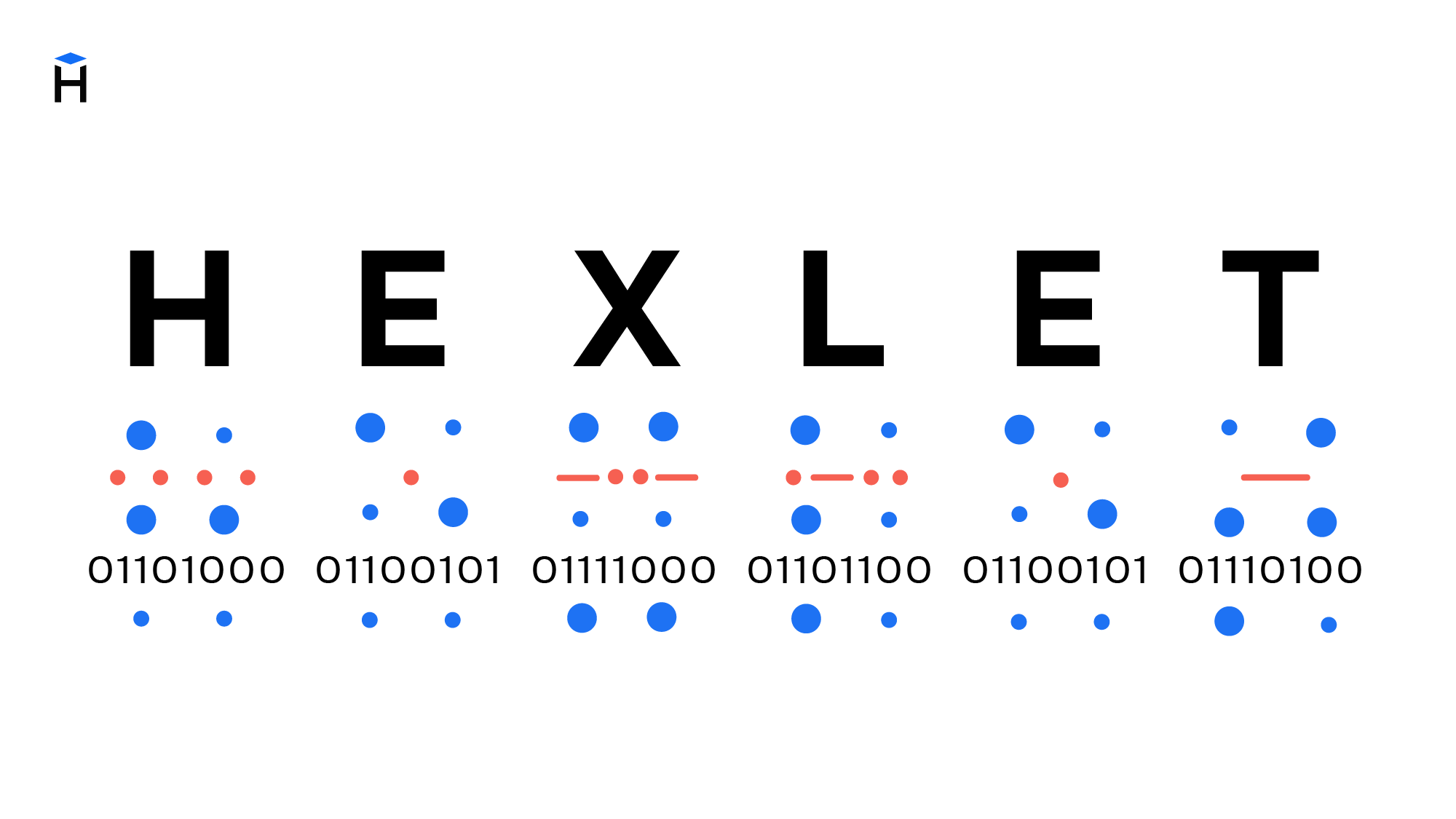
Компьютеры постоянно работают с текстами: это ленты новостных сайтов, фондовые биржи, сообщения в социальных сетях и мессенджерах, банковские приложения и многое другое. Сегодня мы не можем представить жизнь без передачи информации. Но так было не всегда. Компьютеры научились работать с текстом благодаря появлению кодировок. Кодировки прошли большой путь от таблиц символов, созданных отдельно для каждого компьютера, до единой кодировки, принятой во всём мире.
Сейчас Unicode — это основной стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. Unicode применяется везде, где есть текст. Информация на страницах в социальных сетях, записи в базах данных, компьютерные программы и мобильные приложения — всё это работает с использованием Unicode.
В этом гайде мы рассмотрим, как появился Unicode и какие проблемы он решает. Узнаем, как хранилась и передавалась информация до введения единого стандарта кодирования символов, а также рассмотрим примеры кодировок, основанных на Unicode.
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
Компьютеры и числа
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
Постепенно компьютеры начинают применяться для решения не только вычислительных или математических задач. Возникает необходимость обработки текстовой информации, но с буквами и другими символами ситуация обстоит сложнее, чем с числами. Символы — это визуальный объект. Даже одна и та же буква «а» может быть представлена двумя различными символами «а» и «А» в зависимости от регистра.
Также число «один» можно представить в виде различных символов. Это может быть арабская цифра 1 или римская цифра I. Значение числа не меняется, но символы используются разные.
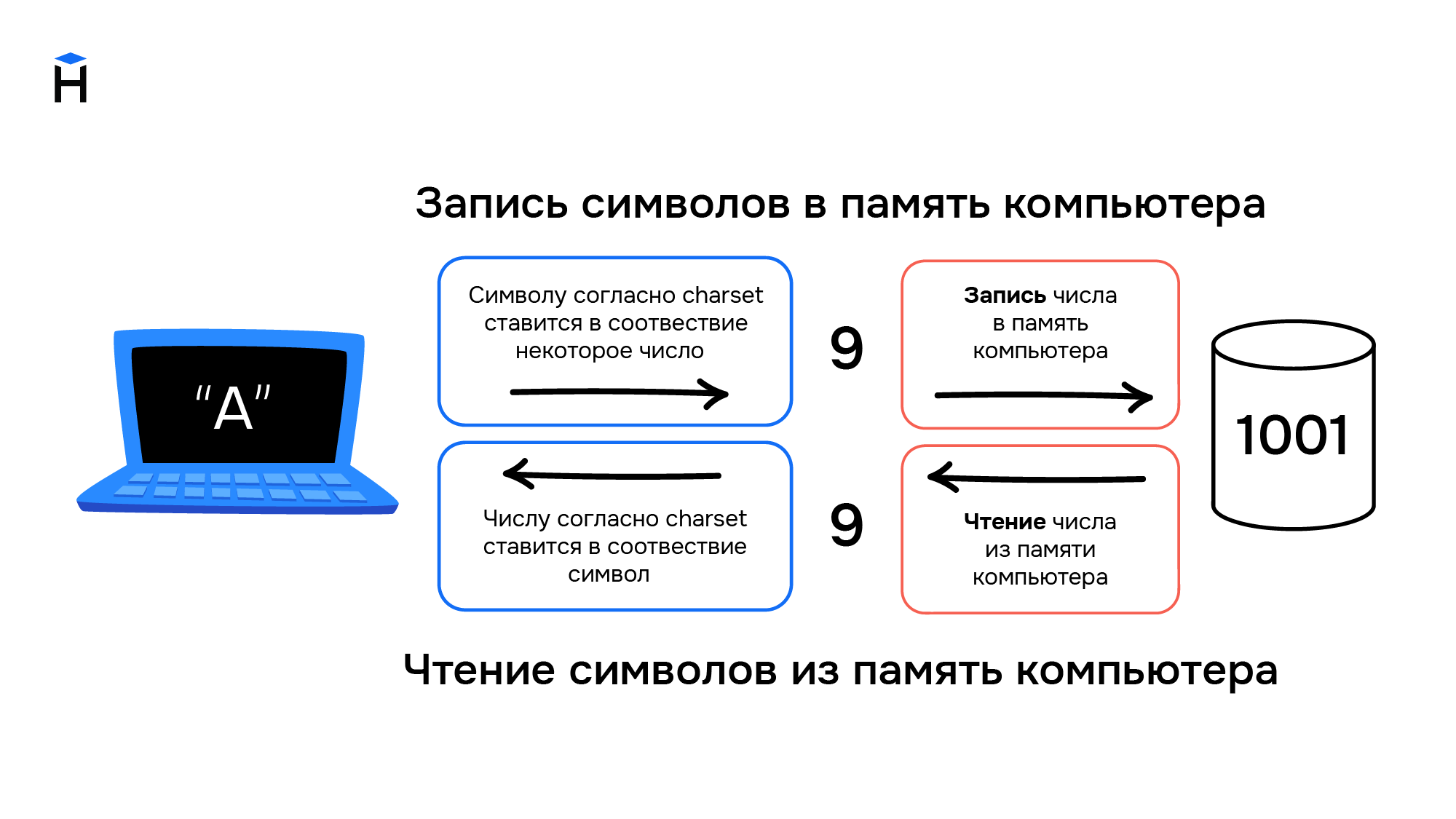
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).
Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Параллельно с этим развивались телетайпы. Телетайп — это система передачи текстовой информации на расстоянии. Два принтера и две клавиатуры (на самом деле электромеханические печатные машинки) попарно соединялись друг с другом проводами. Текст, набранный на клавиатуре у первого пользователя, печатается на принтере у второго пользователя и наоборот. Таким образом, например, была организована «горячая линия» между президентом США и руководством СССР вплоть до начала 1970-х годов.
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
На основе телетайпов разработали терминалы доступа к компьютерам. Такой телетайп отправлял сообщения не второму пользователю, а информация вводилась на некоторый удалённый компьютер, который после обработки указанных команд, возвращал результат в виде ответного сообщения. Это нововведение позволило использовать тогда ещё очень дорогие вычислительные мощности компьютеров, не имея физического доступа к самому компьютеру. Например, компьютер мог размещаться в отдельном вычислительном центре корпорации или института, а сотрудники из других филиалов или городов получали доступ к вычислительным мощностями компьютера посредством установленных у них терминалов.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).
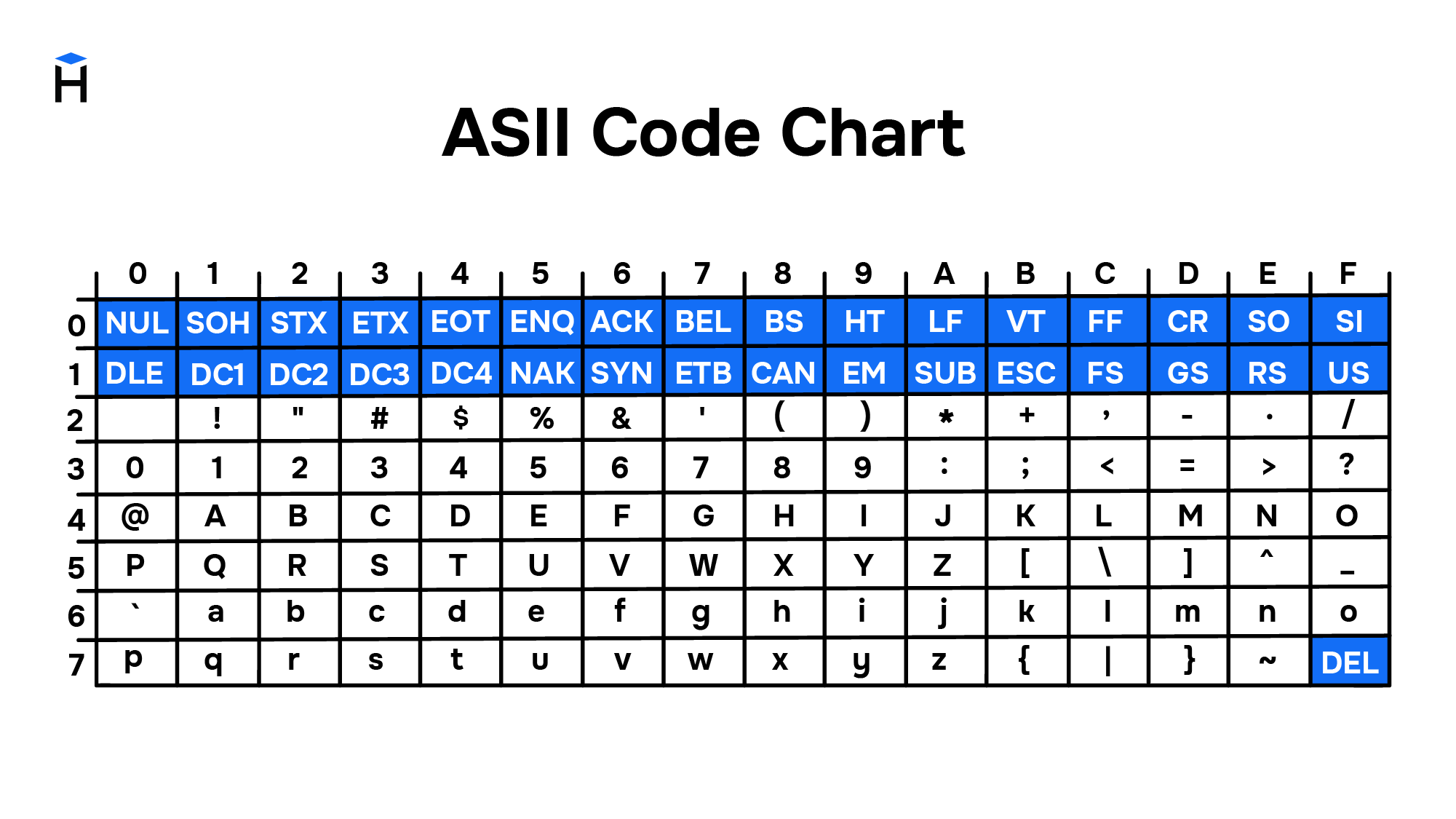
Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.
Свои кодировки необходимы и для других стран с уникальным набором символов. Это приводило к путанице и сложностям в обмене информацией. Ниже приведён пример текста, который написали в кодировке KOI8-R, а читают в cp851.
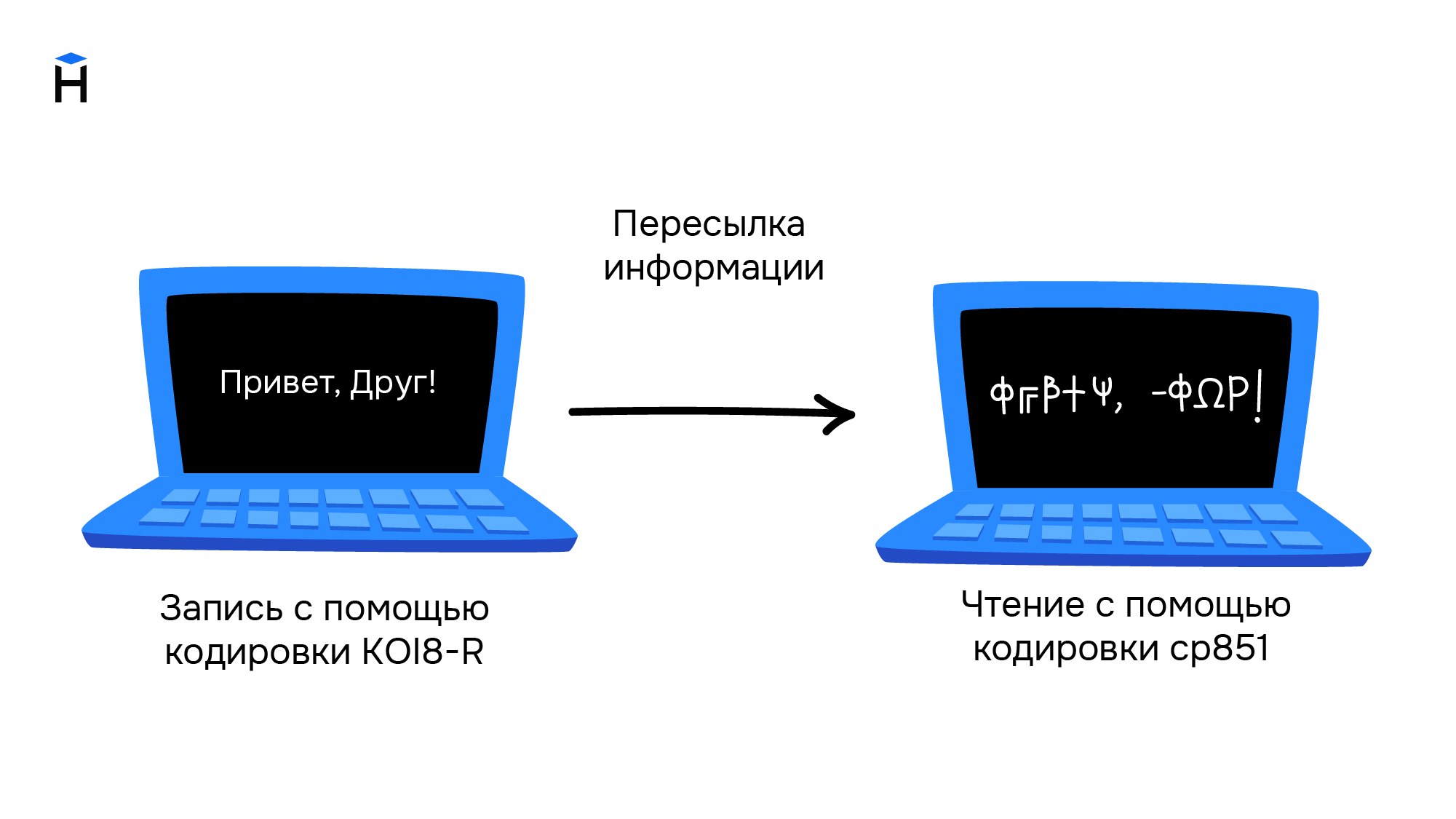
Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text
Если вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
Чтобы с помощью битов представлять нечно полезное, нам нужны правила. Надо сконвертировать последовательность бит в что-то похожее на буквы, числа и изображения, используя схему кодирования, или, коротко, кодировку. Вот так, например:
01100010 01101001 01110100 01110011
b i t s
В этой кодировке, 01100010 представляет из себя ‘b’, 01101001 — ‘i’, 01110100 — ‘t’, 01110011 — ‘s’. Конкретная последовательность бит соответствует букве, а буква – конкретной последовательности битов. Если вы можете запомнить последовательности для 26 букв или умеете действительно быстро находить нужное соответствие, то вы сможете читать биты, как книги.
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
01000001 A
01000010 B
01000011 C
01000100 D
01000101 E
01000110 F
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие. В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded form
code |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.
Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский. И, прежде чем вы спросите, да, есть кодировки только для упрощенного китайского. А разве одной недостаточно?
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
GB18030 покрывает довольно большой диапазон символов, включая большую часть латинских символов, но в конце концов, это всего лишь еще одна кодировка среди многих других.
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер. Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Итак, и сколько же байт использует Unicode для кодирования? Нисколько. Потому что Unicode – это не кодировка.
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все. Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂
characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Какого черта мой текст нечитаем?
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 01011011
10000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант. Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
Большинство браузеров предоставляют возможность указать кодировку страницы с помощью специального пункта меню. Иные программы тоже имеют аналогичные пункты.
У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.