
Что такое куча
Это зависит от содержимого.
В программировании есть два разных понятия, которые обозначаются одним и тем же словом «куча». Одно про выделение памяти, второе — про организацию данных. Разберём оба и закроем этот вопрос.
Это про данные
Эта статья из цикла про типы данных. Уже было:
Ещё бывают связанные списки, очереди, множества, хеш-таблицы, карты и кучи. Вот сегодня про кучи.
Куча и работа с памятью
Каждая запущенная программа использует собственную область оперативной памяти. Эта область делится на несколько частей: в одной хранятся данные, в другой — сам код программы, в третьей — константы. Ещё в эту область входят стек вызовов и куча. Про стек вызовов мы уже рассказывали в отдельной статье, теперь поговорим про кучу.
В отличие от стека, который строго упорядочен и все элементы там идут друг за другом, данные в куче могут храниться как угодно. Технически куча — это область памяти, которую компьютер выделяет программе и говорит: вот тебе свободная память для переменных, делай с ней что хочешь.
То, как программист распорядится этой памятью и каким образом будет с ней работать, влияет на быстродействие и работоспособность всей программы.
Аналогия со стройплощадкой
Представьте, что мы строим дом, а куча — это огромная площадка для хранения стройматериалов. Площадка может быть большой, но она не безграничная, поэтому важно как-то по-умному ей пользоваться. Например:
На стройке: мы выгрузили кирпич на один участок, использовали этот кирпич. Теперь нужно сказать, что этот участок можно снова использовать под стройматериалы. Новый кирпич можно разгрузить сюда же, а не искать новое место на площадке.
В программе: мы выделили память для переменной, использовали переменную, она больше не нужна. Можно сказать «Эта память свободна» и использовать её снова.
На стройке: мы храним определённый вид труб на палете №53. Мы говорим крановщику: «Поднимайте на этаж то, что лежит на палете 53». Если мы ошибёмся с номером, то крановщик поднимет на этаж не те трубы.
В программе: в некоторых языках мы можем обратиться к куче напрямую через специальный указатель. Если мы ошиблись и сказали обратиться не к тому участку памяти, программа заберёт не те данные, а дальше будет ошибка.
👉 Прямой доступ к памяти есть не во всех языках программирования. Многие компиляторы и интерпретаторы ставят между программистом и памятью своеобразного администратора — диспетчера памяти. Он сам решает, какие переменные нужны, а какие нет; когда чистить память; сколько памяти на что выделить.
С одной стороны, это удобно: программист просто говорит «храни данные». А где они будут храниться и как их получить — это вопрос другой системы.
С другой стороны, автоматические диспетчеры памяти бывают менее эффективными, чем если управлять памятью вручную. Поэтому драйвера или софт для высоконагруженных систем чаще пишут в «ручном режиме».
Куча и организация данных
Второй вид кучи в программировании — это организация данных.
Куча — это такой вид дерева, у которого есть одно важное свойство:
если узел A — это родитель узла B, то ключ узла A больше ключа узла B (или равен ему).
Если мы представим какой-то набор данных в виде кучи, он может выглядеть, например, так:
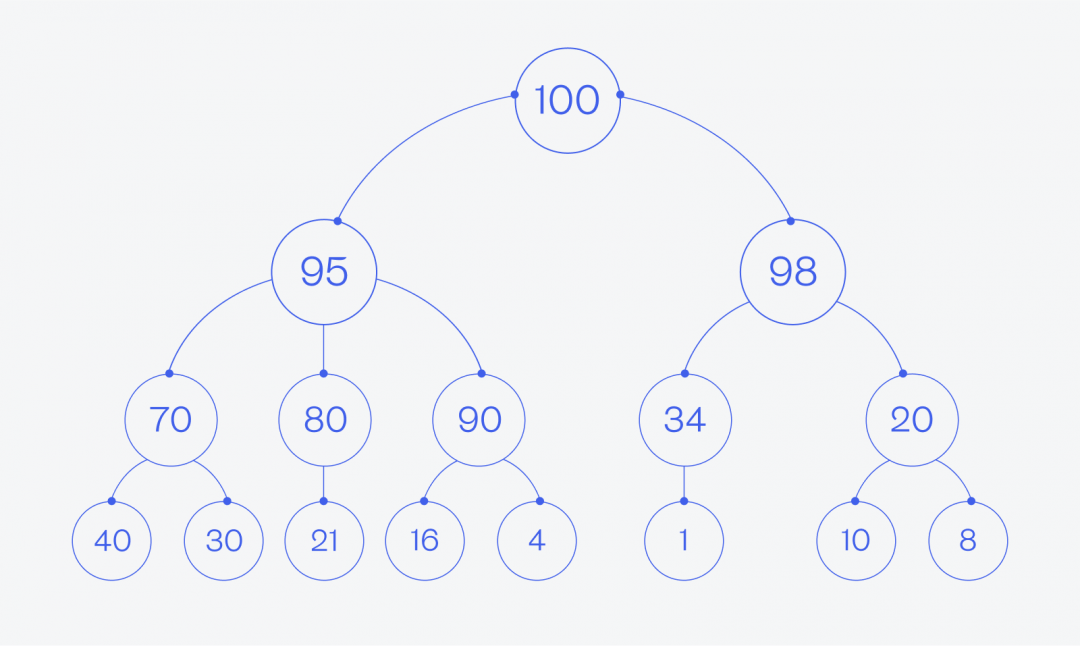
У кучи нет ограничений на число потомков у каждого родителя, но на практике чаще всего используются бинарные кучи. Бинарные — значит, у каждого родителя может быть не больше двух потомков.
Для чего нужны кучи данных
Так как данные в куче упорядочены заранее понятным образом, то их можно использовать для быстрого нахождения нужного элемента или оптимальной последовательности действий, например:
Зачем это знать
Если вы просто пишете веб-приложения на JS — в принципе, это знать не нужно. Вы не можете из JS напрямую управлять памятью, а для простых задач вам вряд ли придётся часто обходить деревья и делать сложные сортировки.
Понимание структур данных нужно для глубокой экспертной работы с софтом. Это как понимание принципов работы механизма внутреннего сгорания. Вам необязательно в этом разбираться, если вы просто хотите водить автомобиль, но обязательно — если хотите собирать гоночные болиды.
Урок №105. Стек и Куча
На этом уроке мы рассмотрим стек и кучу в языке C++.
Сегменты
Память, которую используют программы, состоит из нескольких частей — сегментов:
Сегмент кода (или «текстовый сегмент»), где находится скомпилированная программа. Обычно доступен только для чтения.
Сегмент bss (или «неинициализированный сегмент данных»), где хранятся глобальные и статические переменные, инициализированные нулем.
Сегмент данных (или «сегмент инициализированных данных»), где хранятся инициализированные глобальные и статические переменные.
Куча, откуда выделяются динамические переменные.
Стек вызовов, где хранятся параметры функции, локальные переменные и другая информация, связанная с функциями.
Сегмент кучи (или просто «куча») отслеживает память, используемую для динамического выделения. Мы уже немного поговорили о куче на уроке о динамическом выделении памяти в языке С++.
В языке C++ при использовании оператора new динамическая память выделяется из сегмента кучи самой программы:
Адрес выделяемой памяти передается обратно оператором new и затем он может быть сохранен в указателе. О механизме хранения и выделения свободной памяти нам сейчас беспокоиться незачем. Однако стоит знать, что последовательные запросы памяти не всегда приводят к выделению последовательных адресов памяти!
При удалении динамически выделенной переменной, память возвращается обратно в кучу и затем может быть переназначена (исходя из последующих запросов). Помните, что удаление указателя не удаляет переменную, а просто приводит к возврату памяти по этому адресу обратно в операционную систему.
Куча имеет свои преимущества и недостатки:
Выделение памяти в куче сравнительно медленное.
Выделенная память остается выделенной до тех пор, пока не будет освобождена (остерегайтесь утечек памяти) или пока программа не завершит свое выполнение.
Доступ к динамически выделенной памяти осуществляется только через указатель. Разыменование указателя происходит медленнее, чем доступ к переменной напрямую.
Поскольку куча представляет собой большой резервуар памяти, то именно она используется для выделения больших массивов, структур или классов.
Стек вызовов
Стек вызовов (или просто «стек») отслеживает все активные функции (те, которые были вызваны, но еще не завершены) от начала программы и до текущей точки выполнения, и обрабатывает выделение всех параметров функции и локальных переменных.
Стек вызовов реализуется как структура данных «Стек». Поэтому, прежде чем мы поговорим о том, как работает стек вызовов, нам нужно понять, что такое стек как структура данных.
Стек как структура данных
Структура данных в программировании — это механизм организации данных для их эффективного использования. Вы уже видели несколько типов структур данных, например, массивы или структуры. Существует множество других структур данных, которые используются в программировании. Некоторые из них реализованы в Стандартной библиотеке C++, и стек как раз является одним из таковых.
Например, рассмотрим стопку (аналогия стеку) тарелок на столе. Поскольку каждая тарелка тяжелая, а они еще и сложены друг на друге, то вы можете сделать лишь что-то одно из следующего:
Посмотреть на поверхность первой тарелки (которая находится на самом верху).
Взять верхнюю тарелку из стопки (обнажая таким образом следующую тарелку, которая находится под верхней, если она вообще существует).
Положить новую тарелку поверх стопки (спрятав под ней самую верхнюю тарелку, если она вообще была).
В компьютерном программировании стек представляет собой контейнер (как структуру данных), который содержит несколько переменных (подобно массиву). Однако, в то время как массив позволяет получить доступ и изменять элементы в любом порядке (так называемый «произвольный доступ»), стек более ограничен.
В стеке вы можете:
Посмотреть на верхний элемент стека (используя функцию top() или peek() ).
Вытянуть верхний элемент стека (используя функцию pop() ).
Добавить новый элемент поверх стека (используя функцию push() ).
Стек — это структура данных типа LIFO (англ. «Last In, First Out» = «Последним пришел, первым ушел»). Последний элемент, который находится на вершине стека, первым и уйдет из него. Если положить новую тарелку поверх других тарелок, то именно эту тарелку вы первой и возьмете. По мере того, как элементы помещаются в стек — стек растет, по мере того, как элементы удаляются из стека — стек уменьшается.
Например, рассмотрим короткую последовательность, показывающую, как работает добавление и удаление в стеке:
Stack: empty
Push 1
Stack: 1
Push 2
Stack: 1 2
Push 3
Stack: 1 2 3
Push 4
Stack: 1 2 3 4
Pop
Stack: 1 2 3
Pop
Stack: 1 2
Pop
Stack: 1
Стопка тарелок довольно-таки хорошая аналогия работы стека, но есть лучшая аналогия. Например, рассмотрим несколько почтовых ящиков, которые расположены друг на друге. Каждый почтовый ящик может содержать только один элемент, и все почтовые ящики изначально пустые. Кроме того, каждый почтовый ящик прибивается гвоздем к почтовому ящику снизу, поэтому количество почтовых ящиков не может быть изменено. Если мы не можем изменить количество почтовых ящиков, то как мы получим поведение, подобное стеку?
Во-первых, мы используем наклейку для обозначения того, где находится самый нижний пустой почтовый ящик. Вначале это будет первый почтовый ящик, который находится на полу. Когда мы добавим элемент в наш стек почтовых ящиков, то мы поместим этот элемент в почтовый ящик, на котором будет наклейка (т.е. в самый первый пустой почтовый ящик на полу), а затем переместим наклейку на один почтовый ящик выше. Когда мы вытаскиваем элемент из стека, то мы перемещаем наклейку на один почтовый ящик ниже и удаляем элемент из почтового ящика. Всё, что находится ниже наклейки — находится в стеке. Всё, что находится в ящике с наклейкой и выше — находится вне стека.
Сегмент стека вызовов
Сегмент стека вызовов содержит память, используемую для стека вызовов. При запуске программы, функция main() помещается в стек вызовов операционной системой. Затем программа начинает свое выполнение.
Когда программа встречает вызов функции, то эта функция помещается в стек вызовов. При завершении выполнения функции, она удаляется из стека вызовов. Таким образом, просматривая функции, добавленные в стек, мы можем видеть все функции, которые были вызваны до текущей точки выполнения.
Наша аналогия с почтовыми ящиками — это действительно то, как работает стек вызовов. Стек вызовов имеет фиксированное количество адресов памяти (фиксированный размер). Почтовые ящики являются адресами памяти, а «элементы», которые мы добавляем или вытягиваем из стека, называются фреймами (или «кадрами») стека. Кадр стека отслеживает все данные, связанные с одним вызовом функции. «Наклейка» — это регистр (небольшая часть памяти в ЦП), который является указателем стека. Указатель стека отслеживает вершину стека вызовов.
Единственное отличие фактического стека вызовов от нашего гипотетического стека почтовых ящиков заключается в том, что, когда мы вытягиваем элемент из стека вызовов, нам не нужно очищать память (т.е. вынимать всё содержимое из почтового ящика). Мы можем просто оставить эту память для следующего элемента, который и перезапишет её. Поскольку указатель стека будет ниже этого адреса памяти, то, как мы уже знаем, эта ячейка памяти не будет находиться в стеке.
Стек вызовов на практике
Давайте рассмотрим детально, как работает стек вызовов. Ниже приведена последовательность шагов, выполняемых при вызове функции:
Программа сталкивается с вызовом функции.
Создается фрейм стека, который помещается в стек. Он состоит из:
адреса инструкции, который находится за вызовом функции (так называемый «обратный адрес»). Так процессор запоминает, куда ему возвращаться после выполнения функции;
памяти для локальных переменных;
сохраненных копий всех регистров, модифицированных функцией, которые необходимо будет восстановить после того, как функция завершит свое выполнение.
Процессор переходит к точке начала выполнения функции.
Инструкции внутри функции начинают выполняться.
После завершения функции, выполняются следующие шаги:
Регистры восстанавливаются из стека вызовов.
Фрейм стека вытягивается из стека. Освобождается память, которая была выделена для всех локальных переменных и аргументов.
Обрабатывается возвращаемое значение.
ЦП возобновляет выполнение кода (исходя из обратного адреса).
Возвращаемые значения могут обрабатываться разными способами, в зависимости от архитектуры компьютера. Некоторые архитектуры считают возвращаемое значение частью фрейма стека, другие используют регистры процессора.
Знать все детали работы стека вызовов не так уж и важно. Однако понимание того, что функции при вызове добавляются в стек, а при завершении выполнения — удаляются из стека, дает основы, необходимые для понимания рекурсии, а также некоторых других концепций, которые полезны при отладке программ.
Структуры данных: 2-3 куча (2-3 heap)
Вопрос эффективного способа реализации очереди с приоритетом некоторой структурой данных остается актуальным в течении долгого времени. Ответ на данный вопрос всегда является неким компромиссом между объёмом памяти, необходимым для хранения данных и временем работой операций над очередью.
В компьютерных науках для эффективной реализации очереди с приоритетом используются структуры в виде кучи.
Куча — это специализированная структура данных типа дерево, которая удовлетворяет свойству кучи: если B является узлом-потомком узла A, то ключ(A) ≥ ключ(B). Из этого следует, что элемент с наибольшим ключом всегда является корневым узлом кучи, поэтому иногда такие кучи называют max-кучами (в качестве альтернативы, если сравнение перевернуть, то наименьший элемент будет всегда корневым узлом, такие кучи называют min-кучами). Не существует никаких ограничений относительно того, сколько узлов-потомков имеет каждый узел кучи, хотя на практике их число обычно не более двух. Кучи имеют решающее значение в некоторых эффективных алгоритмах на графах, таких как алгоритм Дейкстры и сортировка методом пирамиды.
Одними из наиболее изученных и хорошо зарекомендовавших себя структур данных для хранения и работой с очередью с приоритетом являются Бинарная Куча (Binary Heap) и Куча Фибоначчи (Fibonacci Heap). Но данные структуры обладают некоторыми особенностями.
Например, бинарная куча для основных операций имеет трудоемкость Θ(logn), кроме нахождения минимального, а для слияния таких куч потребуется линейное время (!). Зато для хранения такой кучи необходимо мало памяти по сравнению с другими кучами.
Куча Фибоначчи обладает балансировкой при извлечении узла из кучи, что позволяет сократить трудоемкость основных операций. При большом количестве последовательных операций добавления Фибоначчиева куча растет в ширину и балансировка происходит лишь при операции удаления минимума, поэтому операция получения минимума может потребовать значительных затрат времени!
Решением над этой проблемой занялся Тадао Такаока (Tadao Takaoka), опубликовав свою работу «2-3 heap» в 1999 году…
Немного о структуре «2-3 Heap»
2-3 куча (2-3 heap) — это структура данных типа дерево, которая удовлетворяет свойству кучи (min-heap, max-heap). Является альтернативой кучи Фибоначчи (Fibonacci heap). Состоит из 2-3 деревьев.
Решение, которое предлагает 2-3 heap, заключается в том, что в отличии от Кучи Фибоначчи, 2-3 куча выполняет балансировку не только при удалении, но и при добавлении новых элементов, снижая вычислительную нагрузку при извлечении минимального узла из кучи.
Количество детей вершины t произвольного дерева T назовем степенью (degree) этой вершины, а степенью дерева назовем степень его корня.
Деревьями 2-3 кучи назовем деревья H[i]. Дерево H[i] — это либо пустое 2-3 дерево, либо одно, либо два 2-3 дерева степени i, соединенные аналогично деревьям Ti.
2-3 куча – это массив деревьев H[i] (i=0..n), для каждого из которых выполняется свойство кучи.
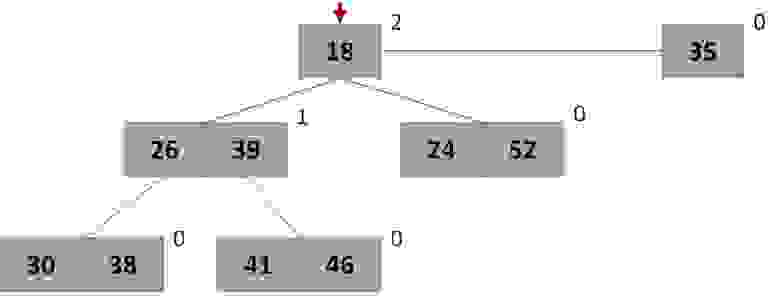
рис. Визуальное представление кучи
Структура узла
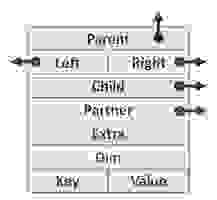 | Каждый узел имеет указатели на другие узлы (поля имеющие стрелки), служебные поля и пара ключ (приоритет) – значение. |
Основные операции
Поиск минимального в 2-3 heap (FindMin)
Минимальный элемент кучи находится в корне одного из деревьев кучи. Чтобы найти минимальный узел, нужно пройтись по деревьям.
Поддерживая указатель на минимальный узел в куче мы можем находить этот узел за константное время ( Θ(1) )
Вставка в 2-3 heap (Insert)

рис. Анимация последовательного добавления элементов в 2-3 кучу
Удаление минимального элемента из кучи
Минимальный элемент кучи находится в корне одного из деревьев кучи, допустим в H[i] – найдем его с помощью FindMin. Извлечем дерево H[i] из кучи и удалим его корень, при этом дерево распадется на поддеревья, которые мы впоследствии добавим в кучу.
Будем удалять корень рекурсивно: если дерево состоит из одной вершины, то просто удалим её; иначе отсоединяем от корня самого правого ребенка и продолжим удаление. 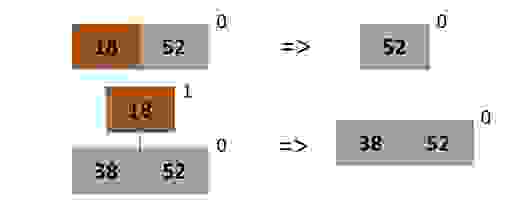
Уменьшение ключа у элемента
Первым делом мы можем свободно уменьшить ключ у необходимого узла. После этого необходимо проверить: если узел находится в корне дерева, то более ничего делать не нужно, иначе нужно будет извлечь этот узел со всеми поддеревьями и вставить его обратно в кучу (с уже измененным ключом). 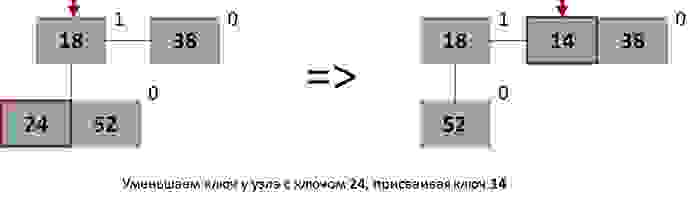
Объединение двух куч в одну
Имеется две кучи, которые нужно объединить в одну. Для этого мы будем по очереди извлекаем все 2-3 деревья из второй кучи и вставлять их в первую кучу. После нужно будет поправить счетчик количества узлов: суммируем количество элементов в первой и во второй куче и записываем результат в счетчик в первой куче, а во второй куче устанавливаем счетчик в 0.
Сравнение трудоемкостей операций с другими алгоритмами
В таблице приведены трудоемкости операций очереди с приоритетом (в худшем случае, worst case)
Символом ‘*’ отмечена амортизированная сложность операций
| Операция | Binary Heap | Binomial Heap | Fibonacci Heap | 2-3 Heap |
|---|---|---|---|---|
| FindMin | Θ(1) | O(logn) | Θ(1)* | Θ(1)* |
| DeleteMin | Θ(logn) | Θ(logn) | O(logn)* | O(logn)* |
| Insert | Θ(logn) | O(logn) | Θ(1)* | Θ(1)* |
| DecreaseKey | Θ(logn) | Θ(logn) | Θ(1)* | Θ(1)* |
| Merge/Union | Θ(n) | Ω(logn) | Θ(1) | Θ(1)* |
Спасибо за уделенное внимание!
Исходный код реализации на C++, основанной на статье автора 2-3 Heap доступен на GitHub под MIT.
PS: При написании курсового проекта по этой теме, я понял, что информации в Рунете практически нет, поэтому решил внести свои пару копеек в это дело, рассказав заинтересованному сообществу об этом алгоритме.
Основные принципы программирования: стек и куча
Авторизуйтесь
Основные принципы программирования: стек и куча
Мы используем всё более продвинутые языки программирования, которые позволяют нам писать меньше кода и получать отличные результаты. За это приходится платить. Поскольку мы всё реже занимаемся низкоуровневыми вещами, нормальным становится то, что многие из нас не вполне понимают, что такое стек и куча, как на самом деле происходит компиляция, в чём разница между статической и динамической типизацией, и т.д. Я не говорю, что все программисты не знают об этих понятиях — я лишь считаю, что порой стоит возвращаться к таким олдскульным вещам.
Сегодня мы поговорим лишь об одной теме: стек и куча. И стек, и куча относятся к различным местоположениям, где происходит управление памятью, но стратегия этого управления кардинально отличается.
Стек — это область оперативной памяти, которая создаётся для каждого потока. Он работает в порядке LIFO (Last In, First Out), то есть последний добавленный в стек кусок памяти будет первым в очереди на вывод из стека. Каждый раз, когда функция объявляет новую переменную, она добавляется в стек, а когда эта переменная пропадает из области видимости (например, когда функция заканчивается), она автоматически удаляется из стека. Когда стековая переменная освобождается, эта область памяти становится доступной для других стековых переменных.
Из-за такой природы стека управление памятью оказывается весьма логичным и простым для выполнения на ЦП; это приводит к высокой скорости, в особенности потому, что время цикла обновления байта стека очень мало, т.е. этот байт скорее всего привязан к кэшу процессора. Тем не менее, у такой строгой формы управления есть и недостатки. Размер стека — это фиксированная величина, и превышение лимита выделенной на стеке памяти приведёт к переполнению стека. Размер задаётся при создании потока, и у каждой переменной есть максимальный размер, зависящий от типа данных. Это позволяет ограничивать размер некоторых переменных (например, целочисленных), и вынуждает заранее объявлять размер более сложных типов данных (например, массивов), поскольку стек не позволит им изменить его. Кроме того, переменные, расположенные на стеке, всегда являются локальными.
В итоге стек позволяет управлять памятью наиболее эффективным образом — но если вам нужно использовать динамические структуры данных или глобальные переменные, то стоит обратить внимание на кучу.
Куча — это хранилище памяти, также расположенное в ОЗУ, которое допускает динамическое выделение памяти и не работает по принципу стека: это просто склад для ваших переменных. Когда вы выделяете в куче участок памяти для хранения переменной, к ней можно обратиться не только в потоке, но и во всем приложении. Именно так определяются глобальные переменные. По завершении приложения все выделенные участки памяти освобождаются. Размер кучи задаётся при запуске приложения, но, в отличие от стека, он ограничен лишь физически, и это позволяет создавать динамические переменные.
3–5 декабря, Онлайн, Беcплатно
Вы взаимодействуете с кучей посредством ссылок, обычно называемых указателями — это переменные, чьи значения являются адресами других переменных. Создавая указатель, вы указываете на местоположение памяти в куче, что задаёт начальное значение переменной и говорит программе, где получить доступ к этому значению. Из-за динамической природы кучи ЦП не принимает участия в контроле над ней; в языках без сборщика мусора (C, C++) разработчику нужно вручную освобождать участки памяти, которые больше не нужны. Если этого не делать, могут возникнуть утечки и фрагментация памяти, что существенно замедлит работу кучи.
В сравнении со стеком, куча работает медленнее, поскольку переменные разбросаны по памяти, а не сидят на верхушке стека. Некорректное управление памятью в куче приводит к замедлению её работы; тем не менее, это не уменьшает её важности — если вам нужно работать с динамическими или глобальными переменными, пользуйтесь кучей.
Заключение
Вот вы и познакомились с понятиями стека и кучи. Вкратце, стек — это очень быстрое хранилище памяти, работающее по принципу LIFO и управляемое процессором. Но эти преимущества приводят к ограниченному размеру стека и специальному способу получения значений. Для того, чтобы избежать этих ограничений, можно пользоваться кучей — она позволяет создавать динамические и глобальные переменные — но управлять памятью должен либо сборщик мусора, либо сам программист, да и работает куча медленнее.