
Случалось ли вам при воспроизведении какого-то музыкального трека или видеоролика видеть на экране программного плеера название композиции, альбома или имя исполнителя? Конечно же, да. Так вот! Для отображения такой информации используются метаданные. Это описание является как бы сопутствующим и включено в основную архитектуру воспроизводимого файла. Но на самом деле понятие метаданных намного шире, нежели в приведенном примере. Далее рассмотрим, как любая информационная система может использовать такие данные и что это такое в принципе. В качестве примеров для лучшего понимания будут приведены технологии мультимедиа и программы управления предприятиями на основе 1С.
Если исходить из того, что предлагает в качестве основной трактовки этого понятия такой уважаемый ресурс, как Wikipedia, объяснить этот термин можно достаточно просто. По сути своей метаданные – это в некоторым смысле информация о другой информации.
Иными словами, в понятие метаданных вкладывается дополнительное описание какого-то объекта или процесса. Объект метаданных, например, в программе 1С может иметь разные формы и классифицироваться по какому-то признаку взаимодействия системы с пользователем (чаще всего визуальному). В некотором смысле такие объекты распределяются в программном пакете по видам и ролям (письма, отчеты, сообщения, вызываемые процедуры и т. д.). Но это лишь частный случай. На самом деле понятие метаданных несколько шире.
Разновидности и типы метаданных
Для того чтобы в полной мере понять смысл, вкладываемый в этот термин, необходимо знать применяемую классификацию. Их несколько.
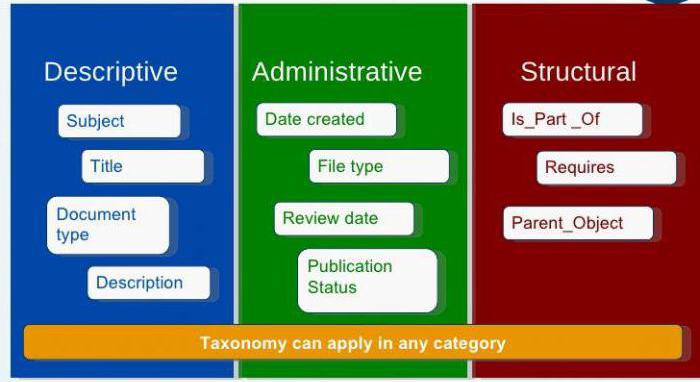
Во-первых, метаданные можно классифицировать по следующим признакам:
Во-вторых, любая информационная система предполагает еще и классификацию по другим признакам, среди которых можно выделить три большие группы метаданных:
Различие и сходство между данными и метаданными
В понимании такой информационной структуры весьма интересным является и тот факт, что обычные данные и метаданные могут меняться ролями.
В качестве самого простого примера можно взять заголовок статьи. Если рассматривать его как часть всего текста, он относится к данным. Но если рассматривать его применительно ко всему текстовому файлу, это метаданные.
Точно так же можно взять в качестве примера обычное стихотворение. Само по себе оно изначально является данными. Но если написать на него музыку, то есть прикрепить текст к сопровождению, стихотворение уже начинает выступать в роли метаданных.

Форматы метаданных
Собственно, формат метаданных представляет собой некую унифицированную форму описания свойств какого-то объекта, на основании которого о нем можно получить полное представление. Как правило, такие формы включают в себя несколько полей для ввода атрибутов, описания свойств объекта, их сути и т. д.

Самыми распространенными являются следующие:
Список можно продолжать до бесконечности, поскольку для любого аспекта человеческой деятельности сегодня можно найти какой-то единый подход в описании.
Что касается прикладного программирования, метаданные можно позиционировать как инструмент инкапсуляции или определения логики работы с таблицами, входящими в состав единой СУБД (например, 1С). Их применение позволяет произвести изоляцию работу с одной отдельно взятой таблицей от всех данных, содержащихся в основной базе.
Простейшие примеры использования метаданных
Приведенные выше примеры дают несколько отвлеченное понятие метаданных. Точное понимание можно получить, если привести в пример ID3-теги, которые в большинстве своем присутствуют в MP3-файлах, соответствующих официальным трекам каких-то исполнителей.
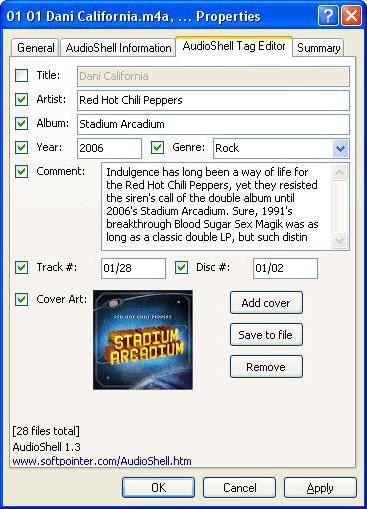
Эта информация как раз и содержит данные о композиции, альбоме, самом исполнителе, годе выпуска и т. д. Собственно, загрузка метаданных в любом программном плеере или аудиоредакторе сложностей не представляет. Но в плеерах информацию нужно сохранить или обновить, а вот в редакторах вроде Adobe Audition (бывшее приложение Cool Edit Pro) такие сведения после ввода прикрепляются к треку автоматически, и повторное сохранение не требуется.
В некотором смысле к метаданным можно отнести и файлы формата XML, в которых сохраняется либо информация с тегами, либо настройки программ, к которым они прикреплены.
Ошибки чтения
Как раз с XML-данными зачастую могут возникать проблемы, когда появляется ошибка метаданных. О чем это говорит? Да только о том, что теги, если они вводились вручную, были прописаны некорректно.
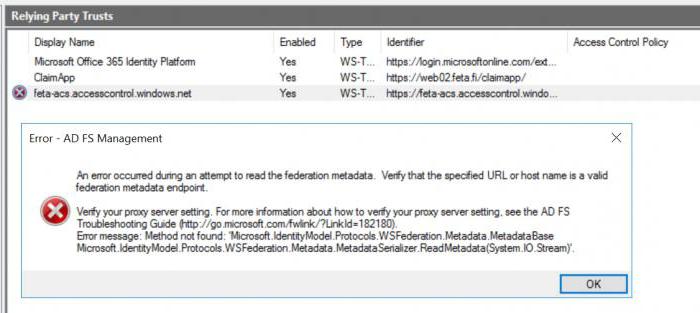
Но сбой может быть связан еще и с повреждением самого описательного файла. Как правило, редактирование, причем даже файлов запроса лицензий и ключей в таком формате, можно произвести в обычном «Блокноте», если знать, что именно удалять или изменять.
В той же системе 1С, как правило, ошибка подгрузки метаданных связана с повреждением базы данных, а точнее – с их загрузкой со съемных носителей, когда пользователи пытаются перезаписать существующий MD-файл собственными силами. Иногда причиной такой ситуации может стать внезапное отключение электроэнергии. В принципе, для восстановления можно использовать распаковщшик GComp, при помощи которого сначала нужно извлечь данные, а потом упаковать их снова. Можно проверить содержимое файла в HEX-редакторе и, если оно не соответствует оригиналу, просто заменить файл, скопировав его из аналогичной версии 1С.
Вместо итога
Вот, собственно, и все, что мы хотели вам поведать о метаданных. Как видите, суть самого понятия сводится к простому информационному описанию другой информации, объектов, их свойств, сути и т. д. И с такой информацией человек сталкивается чуть ли не ежедневно, даже не придавая этому значения. А стоило бы…
Метапрограммирование с примерами на JavaScript
 Эта статья, еще одна попытка переосмысления метапрограммирования, которые я периодически предпринимаю. Идея каждый раз уточняется, но в этот раз удалось подобрать достаточно простых и понятных примеров, которые одновременно очень компактны и иллюстративны, имеют реальное полезное применение и не тянут за собой библиотек и зависимостей. В момент публикации я буду докладывать эту тему на ОдессаJS, поэтому, статью можно использовать, как место для вопросов и комментариев к докладу. Формат статьи дает возможность более полно изложить материал, чем в докладе, слушатели которого, не освобождаются от прочтения.
Эта статья, еще одна попытка переосмысления метапрограммирования, которые я периодически предпринимаю. Идея каждый раз уточняется, но в этот раз удалось подобрать достаточно простых и понятных примеров, которые одновременно очень компактны и иллюстративны, имеют реальное полезное применение и не тянут за собой библиотек и зависимостей. В момент публикации я буду докладывать эту тему на ОдессаJS, поэтому, статью можно использовать, как место для вопросов и комментариев к докладу. Формат статьи дает возможность более полно изложить материал, чем в докладе, слушатели которого, не освобождаются от прочтения.
UPD: Обновленная видеоверсия статьи на Youtube (лекция записана в Киевском политехническом институте 18 апреля 2019 года в рамках курса «100 видео-лекций по программированию»):
Что такое моделирование?
Понятие метапрограммирования тесно связано с моделированием, потому, что сам метод подразумевает повышение уровня абстракции моделей за счет вынесения метаданных из модели. В результате чего мы получаем метамодель и метаданные. Во время раннего или позднего связывания (при компиляции, трансляции или работе программы) мы из метамодели и метаданных опять получаем модель автоматическим программным способом. Созданная модель может меняться многократно, без изменения программного кода метамодели, а часто, даже без остановки программы.
Удивительно, но человек способен успешно решать задачи, сложность которых превышает возможности его памяти и мышления, при помощи построения моделей и абстракций. Точность этих моделей определяет их пользу для принятия решений и выработки управляющих воздействий. Модель всегда не точна и отображает только малую часть реальности, одну или несколько ее сторон или аспектов. Однако, в ограниченных условиях использования, модель может быть неотличимой от реального объекта предметной области. Есть физические, математические, имитационные и другие виды моделей, но нас будут интересовать, в первую очередь, информационные модели данных и модели программной логики. Парадигмы программирования, это и есть модели программной логики, например, императивное, декларативное, функциональное, событийное. Нашей же задачей, как программистов, можем обозначить не написание кода, а, в первую очередь, построение моделей и абстракций. Таким образом, метапрограммирование позволяет нам поднять уровень абстракции в моделях, что делает их универсальнее, а нашу работу значительно интереснее.
Что такое метапрограммирование?
Метапрограммирование — это не что-то новое, вы всегда его использовали, если имеете опыт практического программирования на любом языке и в любой прикладной сфере применения. Все парадигмы программирования, по крайней мере, для ЭВМ фоннеймановской архитектуры, так или иначе наследуют основные принципы моделирования от этой архитектуры. Самый важный принцип архитектуры фон Неймана, это смешивание данных и команд, определяющих логику обработки данных, в одной универсальной памяти. То есть, отсутствие принципиальной разницы между программой и данными. Это дает множество последствий, во-первых, машине нужно различать где команда, а где число и какая его разрядность и тип, где адрес, а где массив, где строка, а где длина этой строки, в какой кодировке она представлена и т.д., вплоть до сложных конструкций, как объекты и области видимости. Все это определяется метаданными, без метаданных вообще ничего не происходит в языках программирования для фоннеймановской архитектуры. Во-вторых, программа получает доступ к памяти, в которой хранится она сама, другие программы, их исходный код, и может обрабатывать код как данные, что позволяет делать трансляцию и интерпретацию, автоматизированное тестирование и оптимизацию, интроспекцию и отладку, динамическое связывание и многое другое.
Определения:
Метаданные — это данные, о данных. Например тип переменной, это метаданные переменной, а названия и типы параметров функции, это метаданные этой функции.
Интроспекция — механизм, позволяющий программе во время работы получать метаданные о структурах памяти, включая метаданные о переменных и функциях, типах и объектах, классах и прототипах.
Динамическое связывание (или позднее связывание) — это обращение к функции через идентификатор, который превращается в адрес вызова только на этапе исполнения.
Метамодель — модель высокого уровня абстрактности, из которой вынесены метаданные, и которая динамически порождает конкретную модель при получении метаданных.
Метапрограммирование — это парадигма программирования, построенная на программном изменении структуры и поведения программ.
Итак, нельзя начать применять метапрограммирование с сегодняшнего дня, но можно осознать, проанализировать и применять инструмент осознанно. Это парадоксально, но многие стремятся разделить данные и логику, используя фоннеймановскую архитектуру. Между тем, их следует не разделять, а правильным способом объединить. Есть и другие архитектуры, например, аналоговые решатели, цифровые сигнальные процессоры (DSP), программируемые логические интегральные схемы (ПЛИС), и другие. В этих архитектурах, вычисления производятся не императивно, то есть, не последовательностью операций обработки, заданной алгоритмом, а параллельно работающими цифровыми или аналоговыми элементами, в реальном времени реализующими множество математических и логических операций и имеющими уже готовый ответ в любой момент. Это аналоги реактивного и функционального программирования. В ПЛИС коммутация схем происходит при перепрограммировании, а в DSP императивная логика управляет мелкой перекоммутацией схем в реальном времени. Метапрограммирование возможно и для систем с неимперативной или гибридной логикой, например, я не вижу причины, чтобы одна ПЛИС не могла перепрограммировать другую.
Теперь рассмотрим обобщенную модель, показанную на схеме программного модуля. Каждый модуль обязательно имеет внешний интерфейс и программную логику. А такие компоненты, как конфигурация, состояние и постоянная память, могут как отсутствовать, так и играть основную роль. Модуль получает запросы от других модулей, через интерфейс и отвечают на них, обмениваясь данными в определенных протоколах. Модуль посылает запросы к интерфейсам других модулей из любого места своей программной логики, поэтому входящие связи объединены интерфейсом, а исходящие рассеяны по телу модуля. Модули входят в состав более крупных модулей и сами строятся из нескольких или многих подмодулей. Обобщенная модель подходит для модулей любого масштаба, начиная от функций и объектов, до процессов, серверов, кластеров и крупных информационных систем. При взаимодействии модулей, запросы и ответы — это данные, но они обязательно содержат метаданные, которые влияют на то, как модуль будет обрабатывать данные или как он указывает другому модулю обрабатывать данные. Обычно, набор метаданных ограничивается тем, что протокол обязательно требует для считывания структуры передаваемых данных. В двоичных форматах метаданных меньше, чем в синтаксических форматах, применяемых для сериализации данных (как, например, JSON и MIME). Информация о структуре двоичных форматов, по большей части находится у принимающего модуля в виде struct (структур для C, C++, C# и др. языках) или «зашита» в логику интерпретирующего модуля другим способом. Разделить, где заканчивается обработка данных с использованием метаданных и начинается метапрограммирование, достаточно сложно. Условно, можно определить такой критерий: когда метаданные не просто описывают структуры, а повышают абстракцию программного кода в модуле, интерпретирующем данные и метаданные, вот тут начинается метапрограммирование. Другими словами, когда происходит переход от модели, к метамодели. Основным признаком такого перехода, является расширение универсальности модуля, а не расширение универсальности протокола или формата данных. На схеме справа показано, как из данных выделяются метаданные и заходят в модуль, меняя его поведение при обработке данных. Таким образом, абстрактная метамодель, содержащаяся в модуле на этапе исполнения превращается в конкретную модель.
Обычно, набор метаданных ограничивается тем, что протокол обязательно требует для считывания структуры передаваемых данных. В двоичных форматах метаданных меньше, чем в синтаксических форматах, применяемых для сериализации данных (как, например, JSON и MIME). Информация о структуре двоичных форматов, по большей части находится у принимающего модуля в виде struct (структур для C, C++, C# и др. языках) или «зашита» в логику интерпретирующего модуля другим способом. Разделить, где заканчивается обработка данных с использованием метаданных и начинается метапрограммирование, достаточно сложно. Условно, можно определить такой критерий: когда метаданные не просто описывают структуры, а повышают абстракцию программного кода в модуле, интерпретирующем данные и метаданные, вот тут начинается метапрограммирование. Другими словами, когда происходит переход от модели, к метамодели. Основным признаком такого перехода, является расширение универсальности модуля, а не расширение универсальности протокола или формата данных. На схеме справа показано, как из данных выделяются метаданные и заходят в модуль, меняя его поведение при обработке данных. Таким образом, абстрактная метамодель, содержащаяся в модуле на этапе исполнения превращается в конкретную модель.
Прежде чем приступить к рассмотрению техник и приемов метапрограммирования, я бы хотел привести одну цитату, которую всегда привожу, если речь заходит о метапрограммировании. Она наталкивает на мысль, что метапрограммирование, это отражение такого фундаментального закона, на котором основаны вообще все кибернетические системы. То есть системы «живые», в которых происходит управление, коррекция поведения и параметров деятельности при помощи регулирования с обратной связью. Это позволяет системам воспроизводить свое состояние и структуру в разных условиях и с разными модификациями, сохраняя существенное и варьируя поведение, в том числе и порождая производные системы для этого.
«Вот что я имею в виду под производящим произведением или, как я называл его в прошлый раз, «opera operans». В философии существует различение между «natura naturata» и «natura naturans» – порожденная природа и порождающая природа. По аналогии можно было бы образовать – «cultura culturata» и «cultura culturans». Скажем, роман «В поисках утраченного времени» строится не как произведение, а как «cultura culturans» или «opera operans». Это и есть то, что у греков называлось Логосом.»
// Мераб Мамардашвили «Лекции по античной философии»
Как работает метапрограммирование?
Для чего нам нужно метапрограммирование?
Пример 1
Рассмотрим самый простой пример выделения метаданных из модели и построения метамодели (см. пример на github). Сначала определим задачу примера: есть массив строк, нужно отфильтровать их по определенным правилам: длина подходящих строк должна быть от 10 до 200 символов включительно, но исключая строки длиной от 50 до 65 символов; строка должна начинаться на «Mich» и не начинаться на «Abu»; строка должна содержать «V» и не содержать «Lev»; строка должна заканчиваться на «ov» и не должна заканчиваться на «iov». Определим данные для примера:
Реализуем логику без метапрограммирования:
Выделяем метаданные из модели решения задачи и формируем их в отдельную структуру:
Преимущество решения задачи при помощи метапрограммирования очевидно, мы получили универсальный фильтр строк, с конфигурируемой логикой. Если фильтрацию нужно провести не один раз, а несколько, на одной и той же конфигурации метаданных, то метамодель можно обернуть в замыкание и получить кеширование индивидуированной функции для ускорения работы.
Пример 2
Второй пример мы будем сразу писать при помощи метапрограммирования (см. пример на github), потому, что если я представлю себе его размеры в размеры в говнокоде, то мне становится страшно. Описание задачи: нужно делать HTTP GET/POST запросы с определенных URLов или загружать данные из файлов и передавать полученные или считанные данные через HTTP PUT/POST на другие URLы и/или сохранять их в файлы. Таких операций будет несколько и их нужно производить с различными интервалами времени. Задачу можно описать в виде метаданных следующим образом:
Решаем задачу при помощи метапрограммирования:
Видим, что мы написали «красивые столбики» и можно произвести еще одну свертку, вынеся метаданные уже внутри метамодели. Как будет выглядеть метамодель, конфигурируемая метаданными:
Замечу, что в примере используются замыкания для индивидуации тасков.
Пример 3
Во втором примере используется функция duration, возвращающая значение в миллисекундах, которую мы не рассмотрели. Эта функция интерпретирует значение интервала, заданное как строка в формате: «Dd Hh Mm Ss», например «1d 10h 7m 13s», каждый компонент которого опциональный, например «1d 25s», если функция получает число, то она его и отдает, это нужно для удобства задания метаданных, если мы задаем интервал напрямую в миллисекундах.
Теперь реализуем интерпретацию, конфигурируемую метаданными:
Пример 4
Теперь посмотрим на метапрограммирование с интроспекцией, примененное для интеграции модулей. Сначала определим удаленные методы на клиенте при помощи такой структуры и покажем, как использовать данные вызовы при написании прикладной логики:
Теперь проведем инициализацию из метаданных, получаемых из другого модуля и покажем, что прикладная логика не изменилась:
В слудующем примере мы создадим локальный источник данных с таким же интерфейсом, как и у удаленного и покажем, что прикладная логика так же не изменилась:
Мета-данные. На пути к идеалам управления моделями данных
О чём этот пост
Определения и ограничения
Предполагается, что читатель является (или когда-нибудь станет) разработчиком Enterprise Application, которому часто нужно писать быстро и качественно, но не боящегося лезть в дебри JPA/JTA/RMI чтобы «подкрутить напильником» особо тонкие места.
Данные — то, что хранится в базе данных приложения. Данные о клиентах, пользователях, заказах и т.п.
Метаданные — описание структуры данных. Описание того, какие типы объектов хранятся в базе данных, какие у них есть поля (аттрибуты, элементы), описание зависимостей между объектами. В общем случает типы могут наследовать атрибуты родительского типа, а один атрибут в общем случае может присутствовать у двух и более типов, несвязанных отношением наследования.
Enterprise Application работает с использованием (чаще всего) Application Server’а (WebLogic, JBOSS) и некоторой РСУБД (Oracle, Informix, MySQL). Хотя автор не видит ничего зазорного в самостоятельной сборке AS на основе Tomcat/Hibernate/JOTM/DBCP/etc, это очень и очень интересно, но за рамками данного топика.
В качестве РСУБД предполагается одна из тех стандартных, которая поддерживается Hibernate/OpenJPA.
В топике используются термины из XML Schema: пространство имён, тип, атрибут. Последним двум в некоторой степени соответствуют понятия Java класс (объект класса, бин) и свойство (property, aka get+set, также иногда просто поле, field).
Введение. Простейший случай
Большие приложения — чаще всего это не только приложения с большим объёмом данных. Чаще всего это приложения работающие с большим количеством разнородных данных, имеющих разную структуру с точки зрения бизнес-логики. (Кстати, последнее важно — структура данных может быть различной на уровне СУБД, на уровне приложения и даже внутри него)
Заметьте в последнем предложении важное уточнение — «бизнес-логики». Речь идёт об описании процессов взаимодействия структур данных, их изменении и пр. — то есть кода, который должен знать и знает о структуре данных. Но если, например, мы говорим про редактирование бинов через WEB-интерфейс (или любым другим способом), то для написания редактора, который может редактировать 80% объектов, не зная заранее их структуры (т.н. generalized), нам придётся разбираться с Reflection/Beans/etc и другими, в принципе, не очень страшными словами. (Страшные — в конце топика).
Современные средства проектирования позволяют автоматизировать часть процессов связанных с обновлением, например, структуры базы данных по коду, либо наоборот — сгенерировать или обновить код по описанию структуры данных. Не уверен, но, думаю, существуют средства создания одновременно и кода, и структуры базы данных на основе некой абстрактной схемы данных, записанной, например, в виде XML Schema. (Код так точно можно сгенерировать — см. XML Beans и пр.). Однако все эти средства работают в «offline» и не затрагивают работающее приложение (если вы, конечно, не сделаете обновление прямо по «живому», но ничего хорошего из этого не бывает).
Кстати, некоторые из вспомогательных утилит можно заставить и формочки для каждого типа объектов нарисовать.
Гибкие структуры данных
Самой гибкой можно считать структуру, в которой каждый объект хранится как запись в базе данных в виде, ну, например, XML. То есть большая-большая таблица, в которой две колонки — ID объекта и его содержание в виде XML. Как вы правильно догадываетесь, основной недостаток подобной структуры — очень низкая производительность базы данных в тот момент, когда нам нужно будет вычислить, ну например, всех клиентов из города «Москва». Для этого придётся базе данных распарсить каждое значение.
Чтобы структура осталось гибкой, но поменьше нагружать базу данных, объект разбивают на кусочки и выносят в отдельные таблицы. Например,
— Объекты: ID, обязательное поле 1, обязательное поле 2
— Значения: ID объекта, идентификатор аттрибута, значение
Можно пойти дальше и, без ограничения гибкости, разделить атрибуты разных типов по разным таблицам или колонкам. Подобная схема успешно применяется в приложении (вырезано) для обработки данных в несколько терабайт.
Ещё недостатки:
За гибкость нужно платить. Во-первых, слой работы с данными придётся писать самостоятельно. Во-вторых, возникает большое желание сэкономить и оставить для бизнес-логики API, который бы отражал структуру базы данных:
— дай объект ID такой-то
— дай аттрибут ID такой-то
— обнови значение
— запиши аттрибут ID такой-то объекта такой-то
— обнови версию объекта (+1)
Конечно, с точки зрения программиста generalized редактора данных очень удобно иметь методы вроде getAllAttributes(). Однако с точки зрения бизнес-логики это неудобно, особенно если нужно помнить все ID нужных атрибутов (они могут быть и числовыми).
Нужно отметить, однако, что API в общем случае не обязан совпадать со структурой базы данных. Главное — чтобы 80% действий выполнялись самым простым и очевидным способом. То есть если у нас в базе хранятся клиенты, получение имени клиента или его адреса должна быть одна строка кода вроде client.getAddress(). Однако для гибких структур написание таких оболочек может сильно подорвать производительность, во-вторых, структуры имеют обыкновение меняться…
Однако если такие оболочки не пишет тот, кто отвечает за написание процедур доступа к данным, будьте готовы, что через пару лет у вас будет столько оболочек «упрощённого» доступа к данным, сколько инициативных программистов работают со «стандартным» API.
Структуры с ограниченными возможностями
В этом разделе хочется рассказать ещё об одном подходе, которая используется в одной малоизвестной CMS.
С точки зрения кода доступ к атрибутам объекта осуществляется таким же образом, как и у гибких структур — через методы вроде getAttribute / getAllAttributes / etc. Однако для CMS, основная задача которой редактировать объекты по отдельности (без relations между объектами), а также просто вывести объект в XML для дальнейшей обработки — данного API вполне хватает.
Интересно то, что список типов данных хранится в некотором конфигурационном файле. Также в этом файле для каждого типа хранится список аттрибутов и их тип. На основании конфигурационного файла при запуске создаётся или обновляется структура таблиц. В дальнейшем «на лету» при изменении структуры данных таблицы обновляются.
Плюсы:
— очевидная модель данных для СУБД
— гибкость «на лету»
Минусы
— с точки бизнес-логики API слишком гибкий (см. предыдущий раздел)
— нужно писать свою систему доступа к данным, которая в настоящий момент, к сожалению, в отличии от системных объектов (пользователи, группы, etc) игнорирует транзакции, кеши и прочие прелести
Классификация… попытка
Хочу… идеальная для автора
Из предыдущего пункта легко выводятся требования к идеальной (с точки зрения автора) системе описания и оперирования моделями данных:
— описание структуры данных должно быть в базе данных, что позволит оперативно изменять описание модели, возможно — через само приложение
— сами данные при этом должны хранится в нормализованной (вплоть до 3-4 формы) базе данных, где каждому типу соответствует своя таблица данных. Система управления должна сама заботится о поддержании схемы базы данных в соответствии с мета-данными.
— доступ к данным должен осуществляться через стандартные интерфейсы JPA / EntityManager.
— с точки зрения бизнес-логики основные поля основных объектых типов должны быть доступны через простой API без дополнительного resolving / casting / narrowing (т.е. сразу после загрузки из EntityManager)
— но система должна также обеспечивать доступ к мета-данным. В том числе для конкретного объекта — получения списка всех полей.
В настоящее время автор занимается написанием подобной системы, используя:
— Hibernate — как драйвер доступа к данным
— CGLIB / ASM — для динамического конструирования классов на основе их описания, включая аннотации для Hibernate
— XML Schema — для описания типов данных и их атрибутов