
MySql-миграции: что это и как реализовать простым php-скриптом
Когда разрабатываешь веб-приложение не один, а в команде и/или на нескольких машинах, рано или поздно сталкиваешься с проблемой синхронизации кода проекта и базы данных. Для управления кодом есть системы контроля версий, в частности, git, а для СУБД придуманы миграции.
Есть много готовых разнообразных инструментов, которые занимаются миграциями, но!
Поэтому всех, кому интересно узнать, как самим сделать простую утилиту миграций, написав полсотни строк php-кода, прошу в статью.
Идея миграций
Идея довольно проста: в проекте создаем отдельную папку sql, куда складываем sql-файлы с миграциями, то есть, со скриптами, которые меняют содержимое базы, а также один php-файл, который эти миграции и накатывает.
Нужно учесть 2 вещи: во-первых, каждая миграция должна выполняться строго один раз, а во-вторых, в строго определенном порядке. Это разумно и обязательно, потому как если нам прилетают от коллеги 2 миграции, одна из которых создает таблицу users, а другая добавляет в нее тестовых пользователей, то мы хотим выполнить эти скрипты именно в таком порядке и не добавить при этом данные в базу больше одного раза.
Проблему повторных выполнений миграций мы решим, записывая в отдельную таблицу уже отработавшие скрипты, а порядок выполнения установим четкими правилами именования sql-файлов. Как это решается в коде, увидим чуть позже, а пока займемся подготовкой самих тестовых миграций (исходники всех миграций и php-скрипта в конце статьи)
Создаем тестовые sql-скрипты
Пусть у нас есть тестовая база данных под названием test. Мы работаем с ней какое-то время и решили внедрить миграции. Есть разумное правило: самая первая миграция должна содержать в себе полный дамп уже существующих сущностей в базе. Уточню: миграции помогают не только последовательно расширять уже существующую базу, но еще и накатить эту самую базу с нуля, например, для новых людей в команде.
Перед началом выполнения миграций я предполагаю, что указанная база данных уже существует, поэтому в миграции нигде не указывается название базы. На мой взгляд, это хорошо в том плане, что на одной машине программист может работать с разными базами и с разными их версиями. Поэтому у нас скрипта создания базы не будет.
Напишем первую миграцию: дамп базы и таблица versions. Пусть на момент внедрения миграций у нас есть таблица goods с парой товаров. Их нужно скинуть в скрипт и в тот же скрипт добавить таблицу versions. В итоге файл будет выглядеть так.
0000_base.sql
На заметку: возможно, Вам не удобно писать sql-скрипты руками, Вы привыкли создавать и заполнять таблицы через phpMyAdmin или другой инструмент. Спешу успокоить, все известные мне утилиты позволяют генерировать такой sql-код автоматически. То есть Вы можете работать с базой, как удобно, а при подготовке файла-миграции вытащить нужный скрипт из условного phpMyAdmin-a в режиме copy-paste.
Порядковые номера в начале каждого файла нужны, чтобы правильно отсортировать файлы. Только в этом случае миграции будут выполняться в правильном порядке. После _ идет краткое описание миграции, которое нужно исключительно для нашего удобства, чтобы понимать, что делает тот или иной скрипт, не заглядывая в него.
Пишем php-код для запуска миграций
Каркас migration.php, базовые константы и функции
Нам нужно написать фунцию подключения к базе данных и общую логику работы скрипта. Создадим файл migration.php, кинем его в папку sql рядом с миграциями и напишем в нем следующее:
Дальше функция glob вытащит все файлы из указанной папки по нужной маске *.sql.
Еще немного о миграциях. Версия для PHP
Миграции — это удобный способ управления структурой и изменениями схемы БД.
Конечно, можно вести дела по старинке, оперируя множеством SQL-файлов, или, о ужас!, редактируя куски SQL-кода в одном большом файле, который представляет собой актуальную схему БД.
Однако следить за этими изменениями, начиная с некоторого момента, становится очень сложно, не говоря уже о применении соответствующих изменений на продакшен-машине: тут нужно обладать ловкостью гепарда, силой медведя и мудростью всех восточных мудрецов, вместе взятых, чтобы все сделать правильно и ничего не уронить.
Но как быть, если Вы не обладаете какими-либо из вышеперечисленных качеств? Правильно, нужно систематизировать и автоматизировать процесс, переложив большую часть работы на машину.
Если Вы уже заинтересовались, или все еще не уверены, но перспектива иметь прозрачную историю изменений и возможность с помощью одной-двух консольных команд откатиться на любою версию схемы, звучит заманчиво, прошу под кат.
Начав работать с Ruby on Rails довольно быстро знакомишься с механизмом миграций, а уже через некоторое время не понимаешь, как можно вообще было обходиться без этого невероятно удобного инструмента.
Придя в проект, который разрабатывался на PHP, я постарался привнести в него хотя бы минимальный набор полезных инструментов, знакомых по опыту общения с Ruby on Rails. Одним из пунктов была система для поддержки миграций.
После некоторого поиска выбор был сделан в пользу Ruckusing Migrations, как наиболее похожего на то, что я видел в рельсах. Рапортую, что по прошествии более полугода полет нормальный!
Установка
Предполагается, что Вы используете Composer для управления зависимостями. Если нет, обязательно попробуйте, оно того стоит!
Также при желании Вы можете клонировать с GitHub репозиторий с примером: github.com/ArtemPyanykh/php_migrations_example
Для начала добавьте в свой composer.json:
Далее, я советую поступить следующим образом:
Это просто небольшой скрипт, который я позволил себе написать, дабы упростить работу с Ruckusing Migrations.
Все, больше никаких настроек не требуется, Вы успешно интегрировали себе систему миграций!
Использование
В целом все очень просто. Давайте начнем с того, что сгенерируем миграцию:
Вы можете заметить, что в каталоге db/migrations/main после этого добавится файл примерно с таким же названием (timestamp будет другой) следующего содержания:
Миграции обладают тем свойством, что могут быть не только применены, но и отменены, если существует адекватный способ отката изменений. Именно такова семантика методов up() (применение изменений) и down() (откат изменений). Давайте создадим таблицу test с несколькими полями и парой индексов. Дополним файл следующим образом:
и запустим миграции:
Вы заметите, что помимо создания таблицы test, которая полностью соответствует описанной выше спецификации, также создалась таблица schema_migrations. Это нормально — именно здесь Ruckusing Migrations хранит информацию о том, какие миграции были применены, а какие не были.
Также просто можно откатиться или запустить миграции для другого окружения:
Это лишь небольшая демонстрация возможностей системы. Однако, я думаю уже сейчас понятно, насколько проще и удобнее становится версионирование БД с применением правильного механизма миграций.
Замечания
Миграция баз данных: зачем и почему

Со временем в ИT-ландшафте большинства компаний, долго существующих на рынке, собирается большое количество разнотипных информационных систем (ИС) для автоматизации и поддержки бизнес-процессов, в том числе базы данных (БД). Эти системы «живут» в компаниях годами, а иногда и десятилетиями. Такое множество ИС ИТ-специалисты в шутку называют зоопарком. В какой-то момент его сопровождение становится очень дорогим, а технологические ограничения не позволяют развивать ИС в соответствии с новыми бизнес-требованиями. Тогда компании стремятся обезопасить устаревшие БД от внешних вторжений, утечек и минимизировать риск утраты ценных данных (коммерческой, конфиденциальной информации). Сделать это можно при помощи миграции БД.
Зачем компаниям мигрировать данные, как организовать процесс без потерь и почему это выгодно в долгосрочной перспективе? Рассказываю в статье.
Когда у компаний возник интерес к миграции БД и с чем это связано
Направление миграции БД было популярно за рубежом 15 лет назад. В России на него обратили внимание только в 2014 году, когда появилась необходимость импортозамещения систем, лицензируемых зарубежными производителями и подпадающих под санкции. Что и послужило драйвером роста количества заказов на миграцию и значительно увеличило спрос на полную или частичную замену БД. На тот момент именно импортозамещение оказалось главной целью миграции перехода от устаревших систем к новым. Затем стало ясно, что с помощью миграции БД можно изменить ИT-ландшафт компании – сократить затраты на сопровождение ИС и получить принципиально новые возможности, например, работу с BigData.
Зачем мигрировать
Выгоду постепенной миграции БД можно отследить только в долгосрочной перспективе. Рассматривая вариант ухода от старой системы посредством модернизации на имеющейся платформе, компания сталкивается с трудностями – это дорогостоящий и многоступенчатый процесс. В таком случае новая система будет получать нужные данные из старых БД, которые также будут работать. В итоге бизнесу приходится платить за обе платформы, когда требуется лишь одна. Возрастает стоимость оборудования, необходимого для функционирования всей совокупности ИT-систем, сопровождения. Вдобавок трудовых ресурсов потребуется больше, а специалистов по устаревшим системам мало. Получается, что экономически эффективнее мигрировать все данные, ценные для принятия решений и прогнозирования, на одну платформу.
Миграция БД не только гарантирует экономию средств, но и может стать триггером роста эффективности всего ИT-подразделения. Если правильно подойти к процессу перехода от устаревших систем к новым, он сможет стать началом цифровой трансформации в компании. Если осуществить миграцию в тщательно отработанную целевую архитектуру, можно получить принципиально новые функции, например возможность работы с большими данными. Вот еще несколько причин, почему миграция БД нужна бизнесу.
Говоря о стоимости миграции для бизнеса, следует заметить, что она заметно варьируется для различных систем и может составлять от десятков миллионов рублей для средних компаний до сотен миллионов – для крупных.
Ценообразование процесса зависит от следующих факторов:
Сегодня цель миграции БД – в сокращении издержек на обслуживание ИT-инфраструктуры в долгосрочной перспективе. Более того, последние несколько лет заметен активный интерес к миграции не только БД, но и серверов приложений на российское ПО, что отвечает стратегии импортозамещения, и ПО с открытым кодом.
Процесс миграции БД: с чем вы столкнетесь
Миграция должна быть четко организованной и непрерывной, независимо от способа переноса информации. Без грамотной структуры и продуманного плана компании придется выйти за рамки запланированного бюджета и столкнуться с тем, что целевая система будет работать не так, как планировалось. Во время миграции БД может возникнуть несколько проблем.
В процессе миграции данные преобразуются и перемещаются из одной среды в другую. При этом информация, извлеченная из старой системы, должна «подготовиться» к переносу в целевое местоположение, чтобы команде удалось избежать ошибок, перечисленных выше. Процесс миграции не всегда проходит гладко.
Наиболее неудачный сценарий миграции БД – появление в ИT-ландшафте очередной недоработанной системы, которой нельзя будет пользоваться. Это «эффект второй системы», описанный экспертом в области теории вычислительных систем Фредериком Бруксом. Такой эффект увеличит сложность сопровождения ИС и создаст дополнительную финансовую нагрузку на компанию. Например, в подобной БД будут присутствовать ошибки на уровне данных, которых можно избежать при корректном составлении сценариев или на стадии разработки стратегии миграции. Из возможных технологических ошибок надо отметить неправильный выбор целевой архитектуры, а именно наследование неудачных решений исходной системы.
Более мягкий сценарий неудачной миграции – необходимость обращения к старой системе при наличии новой. Его суть в том, что новая СУБД станет выполнять бизнес-функции, но устаревшую нельзя будет полностью вывести из эксплуатации, поскольку в ней заложены архивные данные для исполнения некоторых бизнес-процессов. И хотя такой тип миграции исключает риск простоев, он довольно сложный – работать нужно будет буквально на два фронта. К тому же компании придется не только выделить бюджет на новую систему, но и платить за обслуживание старой.
Самый оптимальный вариант миграции – комбинированный, плавный. Его суть в том, что в целевой системе готовится платформа со всем необходимым функционалом и данные переносятся постепенно. В новой системе сначала реализуются бизнес-процессы, требующие вовлечения старых систем, затем новая СУБД постепенно принимает на себя функционал не в исходном виде, а с новыми возможностями. Такой вариант миграции предполагает, что у команды есть стратегия переноса данных. В ней должны быть прописаны следующие условия, критические для корректной миграции.
Подходы к миграции БД: какой выбрать
Мигрировать данные из исходной системы в целевую можно несколькими способами – с помощью автоматизации или вручную. Применение той или иной методики зависит от вводных условий и состояния исходной системы. На следующих примерах объясняю суть каждого из подходов.
1. При автоматизированном подходе вмешательство человека в структуру БД минимизируется. Технической группе, занимающейся миграцией БД, нужно создать комбинацию методик и инструментов, которые позволят наладить непротиворечивое и повторяемое управление изменениями в структуре БД и в самих данных. Это гибкий способ миграции, поскольку любой участник команды сможет внести изменения в БД как в общий сервер, так и на локальную версию в различных программных средах без обработки данных вручную.
Несколько лет назад мы мигрировали базу данных для крупного российского банка с платформы Microsoft SQL Server 2008 на Oracle 11g. Заказчик хотел централизовать ИС различных территориальных подразделений в единую систему, выбрал одну из целевых архитектур и решил перенести туда все существующие решения. Основной сложностью было то, что система не могла простаивать более 72 часов и дорабатывалась в процессе миграции.
2.Подобные требования к проекту наложили очень серьезные ограничения на подход к решению. Мигрировать с применением ручных техник было невозможно из-за жестких требований по времени самой миграции. Поэтому мы разработали систему, которая автоматизировала перевод системы заказчика (включая перевод всех данных, хранимого кода, проведения тестирования и анализа производительности) на новую платформу. Мы проводили большое число тестовых миграций как отдельных модулей, так и всей системы, тестирование и доработку системы миграции, что позволило выполнить всю процедуру без сбоев и в требуемое время. Также техническая группа по миграции разработала методику тестирования, основанную на записи и воспроизведении взаимодействия БД с внешними приложениями и связанными системами.Ручной подход предполагает, что команда разработки вносит изменения в структуру целевой БД и переносит данные вручную. Мы осуществляли миграцию медицинской системы с устаревшей версии СУБД на новую от другого поставщика. В этом случае исходная система уже не модифицировалась, и перед нами стояла сложная задача по восстановлению информации о ней. Так как документации не осталось, а разработчики системы были недоступны для консультаций, мы применили ручной подход и начали миграцию с разбора функциональности существующего решения и проведения соответствия с бизнес-требованиями к процессам.
В результате удалось мигрировать данные и встроить систему в новые бизнес-процессы, при этом объем кода уменьшился более чем в два раза. Кроме того, получилось исключить уже не используемые модули и функциональные возможности.
Миграция БД – комплексный и важный для компании процесс. Необходимость сохранения целостности данных требует, чтобы он выполнялся правильно, а техническая группа осознавала целеполагание и следовала четко проработанной стратегии.
Проводя миграцию БД, компания уменьшает расходы на сопровождение не актуальных систем в частности и ИT-инфраструктуры в целом, оптимизирует ИС, перемещая все данные в одно место, и создает дополнительный барьер от атак злоумышленников. В эпоху big data необходимо использовать инновационные и эффективные методы хранения информации, особенно если речь идет о сложной ветвящейся СУБД. Миграция БД – это серьезный шаг, который позволит компании перейти не только на новую технологию, но и выйти на новый уровень ИТ-инфраструктуры.
Использование миграций базы данных

Три программиста пишут код проекта. И с кодом у них нет проблем. Есть три рабочих машины, центральный репозиторий и главный рабочий сервер, берущий файлы из этого же репозитория. Работа кипит. у каждого на своём компьютере установлен PhpMyAdmin, что им позволяет время от времени вносить изменения в свою базу данных.
Программный код спокойно держится в VCS. Любой из троих разработчиков делает pull и сливает к себе из центрального репозитория последнюю версию файлов, что-то дописывает, коммитит и отправляет обратно через push. Теперь остальные два разработчика сливают эти изменения к себе, дорабатывают свои дела и отправляют назад. Такими темпами движется разработка. В репозитории видна история изменения каждого файла и общая цепь правок, оформленных в коммиты. И всё хорошо.
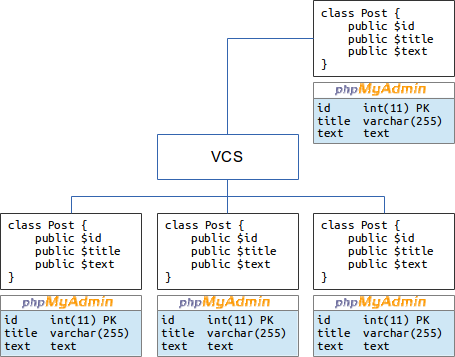
Там же среди файлов лежит SQL файл с дампом исходной базы. Любой новый программист свободно может склонировать проект на свой компьютер и присоединиться к разработке. Актуальную базу данных он может попросить и кого-то ещё или сдампить с тестового сервера. Ну или если после каждого изменения вручную правится и коммитится дамп со схемой, то взять его последнюю версию.
И вот новый программист для выполнения своей задачи добавил в таблицу базы постов блога новое поле public и изменил выборку постов на сайте так, чтобы отображались только открытые записи. Изменение кода модели Post он сохранил в новую ревизию и отправил в центральный репозиторий:
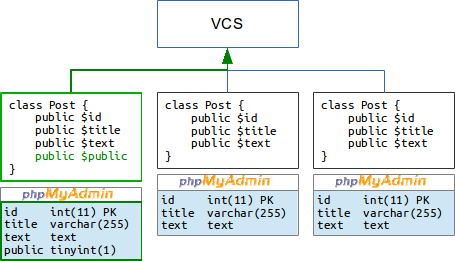
Теперь ему надо открыть скайп, зайти в конференцию и попросить всех добавить в свои базы это поле. Иначе после загрузки изменений у них просто-напросто не обнаружится поле public и блог работать не будет:
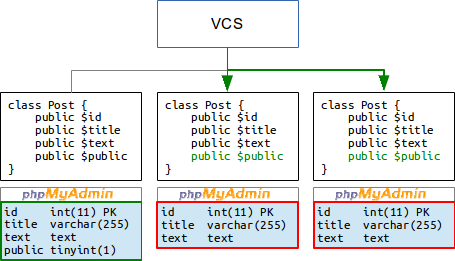
Ну а старший программист при очередной выкладке изменений на рабочий сервер откроет историю переписки в скайпе и сделает то же самое на рабочем сайте.
Хранение изменений в системе контроля версий
Но вдруг менеджер проекта говорит, что в скайпе искать изменения неинтересно, что вручную переименовывать десятки колонок и переносить в них значения слишком муторно, и лучше записывать правки базы SQL-запросами где-то внутри проекта.
Тогда все договариваются либо записывать SQL-запросы с изменениями прямо в сообщения коммитов:
либо создать текстовый файлик и записывать все правки в него.
Потом кто-то ещё захочет переименовать пару полей в какой-то таблице и снова запишет там что он сделал. В конце недели старший разработчик через diff в системе контроля версий посмотрит, какие запросы добавились и одним махом выполнит их на рабочем сервере. Это же теперь будут делать и сами разработчики при приёме свежей версии репозитория.
В Виллабаджио всё ещё пишут SQL-запросы в коммитах, а в Вилларибо уже замучились бегать по спискам и придумали сделать в проекте папку changes и просто добалять туда отдельные файлики с SQL-запросами. Да не просто по одному файлику, а по два! У них уже несколько раз был случай, когда нужно было на тестовом сервере откатить изменения на предыдущее состояние, и в связи с этим возвращать базу данных назад вручную. Теперь они решили для любой операции создавать по два симметричных SQL-файла: для применения изменения (up) и для отката его назад (down).
Переименование поля таблицы у них выглядит так:
Теперь для применения изменений на любом сервере нужно всего лишь выполнить нужный запрос:
Также отпала необходимость хранить свежую версию базы в репозитории. Теперь любому новому разработчику достаточно установить исходную схему и применить все изменения:
и база данных у него станет актуальной версии.
А если нечаянно появилась ошибка, то для её поиска кто-то сможет откатить пару последних изменений базы и вернуть состояние кода на вчерашнюю версию, а когда найдёт ошибку применить изменения и вернуть всё назад.
Все изменения базы данных хранятся в файлах вместе с кодом в репозитории. Внутри SQL файлов теперь можно записывать запросы любой сложности. Теперь ошибки при ручном внесении изменений фактически исключены.
Теперь всё работало как надо, базу можно было откатывать на любое число шагов назад и возвращать вперёд. Стоило лишь запоминать, сколько так называемых «миграций» было выполнено и в каком состоянии база сейчас находится.
Определение текущего состояния БД
Если в любой момент посмотреть на отдельно взятую от кода базу, то довольно сложно оценить, свежая она или нет, какие изменения произведены и какие пропущены. Сейчас этого не видно.
Каждому разработчику нужно каждый раз смотреть на историю добавленных файлов и следить, чтобы все новые миграции были применены, чтобы ни одну не пропустить и чтобы не применить случайно любую старую второй раз.
Как это можно упростить? Как определить состояние любой попавшей к нам базы не глядя в код файлов? Для этого достаточно хранить список применённых миграций в самой базе!
Итак, добавим в базу отдельную таблицу migration :
Теперь при применении любой миграции будем добавлять её идентификатор в данную таблицу. А при откате аналогично удалять. Для автоматизации этого процесса достаточно добавить по одному соответствующему запросу в каждый файл:
Автоматизация процесса
Вот тимлид вернулся из отпуска и начал смотреть репозиторий, чтобы узнать, какие файлики изменений добавились. После этого начал их применять, импортируя в консоли одну за одной. А потом пришёл домой, прочёл о консольных командах и сказал: «Чёрт его побери! Мне же можно написать консольный скрипт, который делал бы всё сам!»
Итак, посмотрим, что тут можно сделать. Попробуем сделать скрипт миграций для PHP проектов.
Система миграций для PHP проектов
Первым делом заменим нативные SQL-файлы на продвинутые PHP-классы. Создадим базовый шаблон с методами up и down :
и будем наследовать наши файлы с миграциями от него.
Файл migrations/m130627_124312.php может выглядеть так:
Использование классов вместо SQL-файлов даёт преимущество, так как в них мы можем выполнять любые преобразования и организовывать любую логику с помощью PHP.
Проекты могут быть разными: на разных базах и с разными префиксами таблиц.
Всё изменчивое и касающееся различий баз лучше инкапсулировать в что-то более независимое. Можно взять тот же PDO или любой другой объектный инструмент для доступа к базе данных.
Для примера не будем брать PDO, «свелосипедим» свой класс на основе MySQL:
Здесь мы позаботились о выводе исключений при ошибках в запросах. Теперь если что-то пойдёт не так с запросом, то мы явно увидим ошибку.
Обратим также внимание на то, что мы добавили метод для автоподстановки префиксов к именам таблиц в поступаюших SQL запросов:
Это позволит нам вместо ручного указания префикса:
переложить эту обязанность на систему и использовать условную запись имён таблиц в фигурных скобках:
Это декоративный, но всё же приятный момент.
Это позволяет помимо обычного подхода с условным циклом while :
использовать обход с помощью цикла foreach :
Сделаем теперь компонент, который будет запускать миграции и вести их историю.
Итак, реализация может быть такой:
В конструкторе данный класс принимает объект доступа к базе данных и вызовом checkEnvironment сам создаёт папку и таблицу миграций, если они отсутствуют.
Код вспомогательных методов здесь не приведён для сокращения сути.
Полный комплект файлов: migrations.zip.
В методе create создаётся новый файл миграции с пустым классом. В качестве имени задаётся текущая дата и время по UTC. Так что даже если разработчики находятся в разных часовых поясах их миграции будут всегда следовать в правильном алфавитном порядке.
Рассмотрим подробнее метод up :
Если новых миграций не нашлось, то выведется сообщение об их отсутствии. Иначе их список выведется на экран и появится запрос подтверждения действия. Если пользователь ответит утвердительно, то для каждого элемента запустится метод migrateUp :
Метод down работает аналогично, но только по умолчанию откатывает только одну последнюю применённую миграцию и удаляет пометку о её версии из базы.
Теперь осталось только написать консольный скрипт-контроллер, который бы принимал пользовательские параметры, конфигурировал все компоненты и запускал нужное действие.
Теперь достаточно создать тестовую базу с таблицей tbl_post :
зайти в консоли в нашу папку и попробовать «погонять» миграции туда-сюда:
Теперь любой разработчик может создать новую миграцию, выполнив:
записать в созданный класс свой функционал и попробовать применить и откатить пару раз у себя. Теперь нужно добавить этот файл в репозиторий проекта и отправить на центральный сервер.
Другие разработчики после скачивания изменений должны запустить у себя:
и все новые изменения произведутся в их базах. Сразу после применения можно продолжать работу.
Таким образом, мы тепеть можем написать вполне самодостаточный компонент для поддержки миграций для любой самописной или готовой CMS.
А теперь посмотрим устройство команды migrate в Yii, а также рассмотрим некоторые примеры применения и дадим несколько общих советов.
Миграции в Yii Framework
Недавно мы разбирали консольные команды в Yii и создавали минимизатор файлов стилей. Так вот, в списке стандартных команд при запуске:
Отличие в командах
В отличие от реализованного нами функционала с добавлением времени:
для миграци в Yii нужно указывать любое текстовое имя, например:
Его нужно передавать при создании миграции:
При поиске новых миграций, применениях, откатах и других операциях это имя не учитывается, поэтому при необходимости (при опечатках или не очень подходящем названии) миграции можно переименовывать, сохраняя неизменным номер версии.
Также в Yii имеются несколько не только разобранные нами, но и ещё несколько дополнительных действий. Общий их список таков:
Поддержка транзакций
Предположим, что в одной миграции выполняется несколько последовательных запросов переносом данных. На случай, если в течение выполнения миграции что-то пойдёт не так, лучше бы было иметь возможность отменять изменения.
Если ваша база данных поддерживает транзакции (например, таблицы в MySQL вместо MyISAM созданы c движком InnoDB), то для защиты от неполностью завершённой серии запросов достаточно просто переименовать методы up() и down() в safeUp() и safeDown() соответственно:
Обратите внимание, что в MySQL транзакции работают только с данными (изменения данных командами INSERT, UPDATE, DELETE). Для операций добавления, переименования и удаления таблиц и их полей командами ALTER TABLE, BEGIN, CREATE INDEX, DROP DATABASE, DROP TABLE, RENAME TABLE и TRUNCATE транзакции не отменяются. Применение методов safeUp с safeDown для переименования колонки бесполезно.
Вспомогательные методы
В миграциях можно использовать свои модели ActiveRecord или работать напрямую с базой через DAO. Вместо Yii::app()->db эффективнее обращаться к соединению вызвав метод getDbConnection самой транзакции, так как в конфигурационном файле config/console.php может быть настроено какое-угодно соединение.
Получив текущее соединение, мы можем добавить колонку прямо его методом:
Такие же декораторы имеются и для других методов. Их удобно использовать вместо простых SQL-запросов.
Также плюсом классов-миграций против SQL-файлов является возможность программировать в них любую логику.
Это может пригодиться, например, для миграции, добавляющей поддержку нескольких категорий для товара в магазине (связи многие-ко многим) вместо одной (один-ко многим) с сохранением всех предыдущих связей:
Ещё для миграций можно задавать свои настройки, запускать их так, чтобы они не требовали от нас подтверждения, хотим ли мы что-то сделать.
Достаточно подробно о других возможностях написано в статье о миграциях официального руководства.
Рекомендации к использованию
Теперь мы знаем, что миграции служат не только для обмена изменениями, но и для двустороннего перевода базы данных в состояние на любую дату. То есть если нам надо откатиться на вчерашнюю версию нашего сайта, то мы отменяем сегодняшние миграции и для возврата вчерашнего состояния файлов переключаемся на любую вчерашнюю резервную точку системы контроля версий. При этом должна быть возможность беспрепятственно передвигаться по истории в любую сторону на любое число шагов.
В связи с этим желательно соблюдать главные рекомендации:
По первому пункту: Можете, конечно, во время разработки потренироваться вручную в PhpMyAdmin, но всё равно потом верните всё «как было» и запишите все необходимые изменения в программный код.
По второму: На боевом сервере свои данные, на тестовом вторые, на рабочем – третьи. На большом сайте новые комментарии добавляются каждую секунду. Не обращайте внимания на пользовательские данные.
Если в базе данных хранятся системные настройки модулей сайта, то можете включить их изменение в миграцию. Остальные же данные (пользователи, комментарии или записи блога) не фиксируйте.
И по третьему: Создавайте всегда новую миграцию для исправления недочётов, а не исправляйте старую. За исключением случаев, когда старая содержит очень вредную ошибку. Миграции всегда должны уметь выполняться последовательно.
Пример усложнения жизни
А теперь представим, что в понедельник мы добавили первую миграцию tbl_posts→tbl_post, а во вторник откатили, переименовали и переделали эту же в tbl_posts→tbl_entry и применили заново. То есть теперь у нас в истории имеется два экземпляра одной миграции с разным функционалом. Теперь не зная таких особенностей сложно угадать, что чтобы попасть из среды во вторник нужно откатить миграцию вторника с кодом среды (попав на понедельник) → переключить файлы на состояние вторника → применить вроде бы эту же миграцию, но уже с кодом вторника. То есть надо как-то всем объяснить, что со среды на вторник можно попасть только двумя шагами через понедельник. Такую игру разума даже прочесть сложно, не то что запомнить.
Пример халатного поведения
Через полгода новый разработчик клонирует себе репозиторий, применяет миграции и получает свежую рабочую базу. Заказчик заново задумался внедрить систему рейтингов. Программист пишет новую миграцию:
тестирует её у себя и всё происходит нормально. На следующий день эту миграцию применяют на рабочем сервере и. она не применяется со словами «Колонка ‘rating’ уже существует». А наш разработчик даже не знал, что в его личную базу это поле не добавилось, так как в коде одной из миграций оно было заботливо закомментировано полгода назад.
Это просто неприятный безобидный пример. Но что было бы, если б кто-то забыл убрать или лишний раз убрал что-то более важное? Была бы остановка сервера на час с аварийным восстановлением из резервной копии.
Пользовательские настройки
Миграции для модулей
В публичном доступе уже имеется доработанный класс EMigrateCommand, который позволяет работать с папками migrations внутри каждого модуля любого проекта на Yii. В минимальном варианте достаточно сконфигурировать модули и заменить им класс команды:
для создания миграции в папке migrations модуля блога следует вызывать:
То есть в командах просто указывать имя модуля. Это изменение касается и некоторых других команд.
При этом можно и дальше пользоваться командами:
как и раньше. Не забудьте только создать папки для миграций в модулях.
Борьба с кэшированием
Предположим, что при работе приложения используется кэширование. Например, в настройках соединения указано кэширование схемы базы 3600 секунд опцией schemaCachingDuration или как-то ещё. В этом случае после каждого изменения желательно очищать кэш. Для этого можно добавить новую команду:
после применения миграций.
Но рассмотрим другую ситуацию. В один прекрасный момент мы применяем миграцию с добавлением новой колонки alias для перевода блога на ЧПУ. В модели мы добавили заполнение этого поля транслитом наименования в методе beforeSave :
Здесь могли бы быть другие преобразования, но это сейчас не важно.
Для избежания таких недоразумений нужно не только отключить кэширование для консольного режима (не указывая schemaCachingDuration и используя заглушку CDummyCache ), но и в теле самой миграции выполнить при необходимости очистку кэша (если он включен) и перзагрузить схему:
Теперь какое бы кэширование ни было включено, проблем с изменёнными полями не возникнет. Можно коммитить миграцию с новой моделью Post и отправлять на центральный сервер.
Другие инструменты и возможности
Вот так мы ознакомились с назначением миграций базы данных, вместе написали свою систему и перешли к управлению изменениями базы в Yii Framework. Но мы не рассмотрели другие готовые инструменты.
Тот же компонент Doctrine Migration, используемый обычно как компонент Doctrine в Symfony Framework, немного отличается по своим доступным операциям для управления миграциями. Все модели в Doctrine (а именно название таблиц, имена и типы полей) дополнительно описываются в конфигурациюнных файлах, что дополнительно даёт нам возможность автоматически генерировать запросы в миграциях. Например, мы добавили новое поле в нашу модель (или сделали индексным существующее) и вызываем команду diff :
Данная консольная команда сравнит схему из конфигурационного файла каждой модели с текущими таблицами в самой базе и сгенерирует миграцию, в которой сама запишет запросы по изменению/добавлению/удалению поля или индекса. Это полезная возможность, но полагаться полностью на неё не стоит, так как вместо переименования одной колонки может сгенерироваться два запроса: на удаление старой и добавление новой, что приведёт к потере значений.
В других языках используются свои инструменты, например rake в Ruby on Rails. Каждый имеет свой синтаксис и спроетирован под свой фреймворк, но общие принципы действия с ними остаются прежними.
На этом пока всё. Если есть какие-либо вопросы или предложения, то напишите их в комментариях.
Не пропускайте новые статьи, бонусы и мастер-классы: