
MS-DOS и TASM 2.0. Часть 18. Ещё раз об указателе.

Указатель в программировании.
В статье MS-DOS и TASM 2.0. Часть 9. Указатель просто и понятно было рассмотрено, что такое указатель в программировании (pointer). Сейчас мы перейдём к вопросу практического использования указателя. Ещё раз напомним, что указатель в ассемблере — более широкое понятие, чем в Си и С++, где указатель определён как переменная, значением которой является адрес ячейки памяти. Указатель — не только переменная. Указатель в программировании на ассемблере — адрес определённой ячейки памяти. Жёсткой привязки к понятию «переменной» нет.
Преимущество указателя — простая возможность обращаться к определённой части исполняемого кода либо данных, избегая их дублирования. Например, один раз написав код функции, мы можем обращаться к нему неоднократно, осуществляя вызов указанной функции. Кстати, вызов функции — это переход исполнения кода по указателю, который для удобства «обозвали» понятным для человека названием (ну, например, «MyBestFunc»).
Указатель в программировании используется также для получения и передачи входных-выходных значений функций. С этим применением мы встретимся при Windows программировании.
Указатель — адрес ячейки памяти.
Указатель в программировании на ассемблере — адрес ячейки памяти, содержащей определённые последовательности цифр — блоки кода и данных. Блоки кода и данных называются значениями указателя, например: строка, массив, структура, функция, переменная, константа.
 Указатель — адрес ячейки памяти, содержащей блоки кода и данных.
Указатель — адрес ячейки памяти, содержащей блоки кода и данных.
Указателю можно присвоить условное обозначение (const_a, const_b, my_mass_1, MY_STRUCT_1, BitMask, my_prnt_func), определив тип данных или кода, на которые он указывает (db, dd, STRUC, RECORD, proc). Практически мы уже проделывали эти операции, создавая исходники наших простейших программ:
Работа с указателями.
Основная проблема начинающего программиста — это различие между указателем и значением, расположенным по адресу памяти, на которую указывает указатель.
Получение значения, на которое указывает указатель в Си и C++ называется «разыменование указателя». Это понятие можно употреблять и в ассемблере.
Получать адрес ячейки памяти (значение указателя) при программировании на ассемблере можно двумя способами, назовём их «статический» и «динамический». Реализовано это с помощью инструкций OFFSET и LEA.
При «статическом» способе указатель будет вычислен во время компиляции. Он не меняется и не вычисляется в процессе выполнения программы. В очень упрощённой форме: его значение равно смещению в байтах от начала программы, спроецированной в память, плюс адрес в оперативной памяти — «точка входа», адрес загрузки программы в память, который задаётся во время компиляции и записывается в заголовке (в начале) файла. Таким образом полученное значение фактически является константой.
OFFSET (Offset — смещение).
Получить «статическим способом» указатель в программировании на ассемблере можно с помощью оператора OFFSET (оператор — команда компилятору — подпрограмме, которая собирает исполняемый файл из исходного кода, написанного языком программирование). Offset возвращает значение метки в памяти. Меткой является любое именованное значение кода и данных. Например, имя переменной, константы или массива (именованное обозначение блока данных). Имя функции — фактически также является меткой (именованным обозначением блока кода).
LEA (Load Effective Address — загрузить эффективный адрес).
При «динамическом» способе адрес вычисляется в процессе исполнения программы. Для этого используется команда LEA (Load Effective Address).
lea операнд1, операнд2
Операнд 1 — это регистр-приёмник (ax, bx, dx и т.д.), куда будет перемещён эффективный адрес (указатель) ячейки памяти, в которой расположен операнд2.
Для начала, необходимо усвоить, что результат оба способа дают одинаковый, но иногда компилятор не имеет возможности определить указатель во время сборки программы. Например, при выделении динамической памяти (столкнёмся в 32 битном Windows программировании), не известно, по какому адресу она будет выделена. Если по этому адресу у нас будет находиться структура, то определить указатель на поля структуры возможно с использованием команды LEA.
Guide Чтож вы такое, Оффсеты? Thread starter bot Start date Dec 18, 2020
Очень часто на форуме встречаются посты, из которых видно, что многие не могут понять, что такое офсеты.
И я подумал, если попробовать «разжевать» данную тему, вопросов будет меньше.
Я не профессионал в программировании(просто хобби), потому, если будут недочёты, прошу извинить и поправить.
Для понимания попробуем подробно рассмотреть небольшой пример. Я думаю все понимают, что почти в любой программе существует динамическое выделение памяти.
Примером может быть программа, которая работает с различными массивами, размерность которых не всегда одна и та же. Например с массивом типа «вектор», в котором может быть заранее неизвестное количество элементов, и которые будут туда добавляться и удаляться динамически.
Для работы с динамически созданными экземплярами данных и нужны указатели.
Предлагаю написать простенькую программу, и на примере её разобрать что к чему.
Я буду использовать C++Builder6.
Создадим новый проект и сохраним в отдельную папку. Так же для удобства создадим два файла в папке проекта с названиями structs.h и structs.cpp. В них напишем наши тестовые структуры, которые и будем рассматривать.
Тут тестовая структура Party, содержащая указатель на цепочку добавляемых элементов, описывающих параметры членов пати PartyMember.
Тут же в главном модуле объявим глобальную переменную paty.
В событии создания формы мы должны добавить туда к примеру 3 члена, и вывести инфо о них.
Тестовая программка будет представлять собой примерно такое. 
Теперь давайте запустим её, подцепимся к ней с помощью Cheat Engine и попытаемся найти базовый адрес (и не только).
Сначала найдём ХП последнего члена в списке(если не с первого раза нашли, кнопкой уменьшаем ХП и отсеиваем, пока не останется одно значение).
В поле Description лучше сразу писать те значения, которые прибавляются к значениям регистров в окошке MoreInformation 
И далее как в вышеуказаной теме ищем адреса, пока не доберёмся до базового адреса(в данном случае базового адреса модуля Project1.exe, который кстати меняется после перезапуска).
Получится примерно такая картина. 
В итоге мы добравшись до базового адреса нашли эту самую цепочку офсетов(смещений), которая ведёт до значения ХП третьего члена пати.
BA + 48C4 + 8 + 8 + 4 = HP
Но что это за значения, и откуда они взялись? Давайте разбираться.
Чтоб было нагладнее, можно проилюстрировать наш примёр.
MS SQL 2011 – новый оператор Offset
Offset
Использование данной команды позволяет пропустить указанное количество строк перед тем как выводить результаты запроса. Что под этим подразумевается: Допустим, у нас есть 100 записей в таблице и нужно пропустить первые 10 строк и вывести строки с 11 по 100. Теперь это легко решается следующим запросом:
Ситуации, в которых может быть использовано выражение Offset
Во всех последующих примерах на Offset будет использовать набор данных построенных в результате данного скрипта:
Задача 1. Пропустить первые 10 записей и показать остальные.
Скрипт будет простой.
Вывод результатов будет таким:
Неважно, какое слово использовать после указания количества строк: Row или Rows – они синонимы в данном случае.
Задача 2. Передать количество строк для пропуска в виде переменной
Задача 3. Задать количество строк для пропуска в виде выражения
Выражение select MAX(number)/99999999 from master..spt_values вернет число 14.
Задача 4. Задать количество строк для пропуска в виде пользовательской функции
Код для скалярной пользовательской функции
Задача 5. Использование Offset с Order by внутри представлений (view), функций, подзапросах, вложенных таблицах, общих выражениях для таблиц (Common Table Expressions — CTE).
Например, использование в общих выражениях.
Пример ниже показывает использование Offset и Order by внутри вложенной таблицы.
И еще пример на работу Offset и Order с представлениями.
Когда Offset не будет работать
1. Так как это «метод расширения», то без выражения order by ничего работать не будет.
Msg 102, Level 15, State 1, Line 21 Incorrect syntax near ’10’.
2. Нельзя задавать отрицательное значение для Offset.
Движок SQL сервера выдаст
Msg 10742, Level 15, State 1, Line 22 The offset specified in a OFFSET clause may not be negative.
3. Нельзя задавать значения отличные от целочисленного типа.
Msg 10743, Level 15, State 1, Line 24 The number of rows provided for a OFFSET clause must be an integer.
4. Не может быть использован внутри выражения Over().
Во время выполнения запроса получим сообщение
Msg 102, Level 15, State 1, Line 22 Incorrect syntax near ‘Offset’.
Использование Fetch First / Fetch Next
Эти ключевые слова используются для уточнения количества возвращаемых строк после пропуска массива строк по выражению Offset. Представьте, что у нас есть 100 строк и нам надо пропустить первые 10 и получить следующие 5 строк. Т.е. надо получить строки с 11 по 15.
Далее рассмотрим ситуации, где можно применить эти ключевые слова.
Задача 1. Пропустить первые 10 записей и получить следующие 5
Результат будет таким:
Задача 2. Задать количество строк для вывода с помощью переменной
В целом и общем, с этими ключевыми словами можно делать все то же самое, что и с Offset. Подзапросы, представления, функции и т.д.
Когда Fetch First / Fetch Next не будут работать
Ограничения на эти ключевые слова полностью совпадают с ограничениями на Offset.
Симуляция Offset и Fetch Next для Sql Server 2005/2008
В предыдущих версиях SQL сервера можно было получить тот же функционал путем применения функции ранжирования Row_Number(). Конечно код получался не такой изящный и лаконичный, например:
Внутри CTE идет генерация служебной колонки которая просто нумерует строки, после чего строки фильтруются по этому полю. Способ не самый быстрый как вы понимаете.
Симуляция Offset и Fetch Next для Sql Server 2000
Для этих древних серверов не было функций ранжирования, но и тогда можно было повторить обсуждаемый функционал. Тогда в ход шли временные таблицы с авто инкрементальным полем. Пример скрипта:
В этом скрипте сначала создается временная таблица, куда перезаписываются данные из целевой таблицы. Причем во временной таблице есть автоинкрементальное поле, по которому потом и осуществляется запрос нужных строк.
Практическое применение Offset и Fetch с замерами времени и ресурсов
Я уверен, что всё предыдущее объяснение об использовании и назначении Offset и Fetch подвело вас к ясному пониманию, зачем они нужны и где их можно использовать. Родились идеи по оптимизации существующего кода. Далее мы рассмотрим пример из реальной практики, когда может пригодиться Offset. Так же будут приведены результаты замеров производительности на разных SQL серверах. Тесты будут прогоняться на выборке из 1 миллиона строк.
Для начала создадим счет-таблицу по следующему скрипту.
Постраничный просмотр данных на стороне сервера
Постраничный просмотр является наиболее часто встречающейся функцией в системах просмотра записей из каких-либо баз. Теперь это возможно проделывать как на стороне клиента, так и на стороне сервера. Пэйджинг на стороне клиента подразумевает загрузку всей таблицы или же очень большой ее части в память, с тем, чтобы программными средствами делать постраничный просмотр. С другой стороны это может быть произведено на стороне сервера, тогда приложение получит только те данные, которые оно запросило для отображения нужной страницы. При таком подходе сокращается время на пересылку данных, постобработку и хранение их в памяти. Т.е. происходит существенное ускорение производительности приложения.
В целях эксперимента мы пропустим первые 20 000 записей и возьмем следующие 50 000.
Подход для SQL Server 2000
Я думаю что предыдущих примеров и комментариев хватает, чтобы понять работу скрипта.
Время выполнения:
SQL Server Execution Times:
CPU time = 110 ms, elapsed time = 839 ms.
Статистика ввода\вывода:
Scan count 1,
logical reads 8037,
physical reads 0,
read-ahead reads 0,
lob logical reads 0,
lob physical reads 0,
lob read-ahead reads 0.
Подход для SQL Server 2005/2008
Время выполнения:
SQL Server Execution Times:
CPU time = 78 ms, elapsed time = 631 ms.
Статистика ввода\вывода:
Scan count 1,
logical reads 530,
physical reads 0,
read-ahead reads 1549,
lob logical reads 0,
lob physical reads 0,
lob read-ahead reads 0.
Подход для SQL Server 2011
Время выполнения:
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 626 ms.
Статистика ввода\вывода:
Scan count 1,
logical reads 530,
physical reads 0,
read-ahead reads 1549,
lob logical reads 0,
lob physical reads 0,
lob read-ahead reads 0.
Наиболее интересен результат по использованию процессорного времени (CPU Time) и время выполнения (Elapsed Time — время потребовавшееся запросу на выполнение). Сравнение замеров представлено ниже:
| Sql Server Version | CPU Time | Elapsed Time |
| 2000 | 110ms | 839 ms |
| 2005/2008 | 78ms | 631 ms |
| 2011 | 46ms | 626 ms |
В таблице наглядно представлено, что новый SQL Server работает заметно быстрее по сравнению с предыдущими версиями. Естественно, что для вашей машины замеры времени могут отличаться, но производительность нового сервера будет всегда выше.
Альтернатива выражению TOP
Новые возможности Denali в некоторых ситуациях могут стать заменой выражению TOP.
Для примера возьмем ситуацию, когда необходимо получить первые 10 записей отсортированные по убыванию какого-либо параметра.
Подходы на предыдущих версиях
Подход возможный в SQL Server Denali
Как заметили в комментариях это неверный код и вернет результат обратный Top(10).
Что такое фиксации смещений и почему они так важны для Kafka
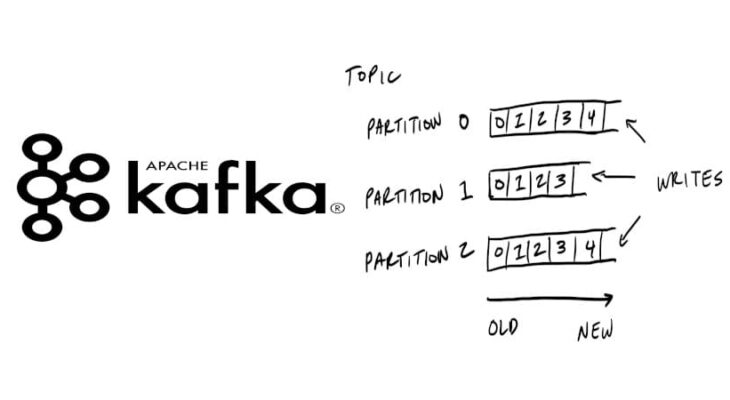
В прошлый раз мы говорили про потоки событий в брокере Kafka. Сегодня поговорим про фиксации смещений в Kafka. Читайте далее про особенности фиксаций смещений, благодаря которым брокер Kafka может легко добавлять новые записи Big Data в топики, а также получать доступ к старым.
Как работают фиксации смещений в брокере Apache Kafka: особенности обработки записей Big Data
Каждый из этих видов мы подробнее рассмотрим далее.
Синхронная фиксация смещений
Синхронная фиксация смещений — это автоматическая фиксация текущего смещения записи в момент ее появления. Как только смещение успешно фиксируется, выполнение процедуры завершается. В случае сбоя синхронной фиксации генерируется исключение, и фиксация возобновляется, выполняясь до тех пор, пока смещение не зафиксируется. Следующий код на языке Java отвечает за выполнение синхронной фиксации смещений записей с помощью метода commitSync() [2]:
Из кода видно, что фиксация смещения происходит после получения приложением каждой записи (с помощью метода poll() ). Метод commitSync() будет повторять фиксацию каждой новой записи до тех пор, пока не возникнет непоправимая ошибка типа CommitFailedException (например, полный выход из строя Kafka-сервера). Если произойдет такая ошибка, сведения о ней автоматически запишутся в журнал логирования (logging), который содержит информацию об этапах выполнения программы.
Асинхронная фиксация смещений
При синхронной фиксации смещений приложение блокируется (остальные функции и запросы становятся недоступны) до тех пор, пока брокер Kafka не подтвердит успешную фиксацию. Это ограничивает пропускную способность (количество информации, передаваемое в единицу времени) приложения. В этом случае можно использовать асинхронную фиксацию. Асинхронная фиксация смещений — это фиксация, которая выполняется независимо (параллельно) от выполнения остальных функций приложения и не требует обязательного подтверждения факта успешной фиксации от Kafka-сервера. Следующий код на языке Java отвечает за выполнение асинхронной фиксации смещения записей в топике с помощью метода commitAsync() [2]:
Главное отличие между асинхронной и синхронной фиксациями состоит в том, что синхронная фиксация будет повторять попытку фиксации смещения до тех пор, пока она не завершится успешно (за исключением полного выхода из строя сервера Kafka). Асинхронная фиксация, в случае возникновения ошибочной ситуации (например, истечение времени ожидания или временный сбой Kafka-сервера), не станет повторять попытку фиксации смещения текущей записи, а сразу перейдет к фиксации смещения следующей доступной (или поступившей) записи [2].
Таким образом, благодаря механизму управления фиксациями, брокер Kafka может весьма эффективно регистрировать новые записи Big Data в топиках, обращаться к старым, а также удалять из топиков записи, которые более не используются. Это делает Apache Kafka универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений. В следующей статье мы поговорим про перебалансировку разделов в Kafka.
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Не стоит пользоваться OFFSET и LIMIT в запросах с разбиением на страницы
Прошли те дни, когда не надо было беспокоиться об оптимизации производительности баз данных. Время не стоит на месте. Каждый новый бизнесмен из сферы высоких технологий хочет создать очередной Facebook, стремясь при этом собирать все данные, до которых может дотянуться. Эти данные нужны бизнесу для более качественного обучения моделей, которые помогают зарабатывать. В таких условиях программистам необходимо создавать такие API, которые позволяют быстро и надёжно работать с огромными объёмами информации.

Если вы уже некоторое время занимаетесь проектированием серверных частей приложений или баз данных, то вы, вероятно, писали код для выполнения запросов с разбиением на страницы. Например — такой:
Но если разбиение на страницы вы выполняли именно так, я с сожалением могу отметить, что вы делали это далеко не самым эффективным образом.
Хотите мне возразить? Можете не тратить время. Slack, Shopify и Mixmax уже применяют приёмы, о которых я хочу сегодня рассказать.
Назовите хотя бы одного разработчика бэкендов, который никогда не пользовался OFFSET и LIMIT для выполнения запросов с разбиением на страницы. В MVP (Minimum Viable Product, минимальный жизнеспособный продукт) и в проектах, где используются небольшие объёмы данных, этот подход вполне применим. Он, так сказать, «просто работает».
Но если нужно с нуля создавать надёжные и эффективные системы, стоит заблаговременно позаботиться об эффективности выполнения запросов к базам данных, используемых в таких системах.
Сегодня мы поговорим о проблемах, сопутствующих широко используемым (жаль, что это так) реализациям механизмов выполнения запросов с разбиением на страницы, и о том, как добиться высокой производительности при выполнении подобных запросов.
Что не так с OFFSET и LIMIT?
Как уже было сказано, OFFSET и LIMIT отлично показывают себя в проектах, в которых не нужно работать с большими объёмами данных.
Проблема возникает в том случае, если база данных разрастается до таких размеров, что перестаёт помещаться в памяти сервера. Но при этом в ходе работы с этой базой данных нужно использовать запросы с разбиением на страницы.
Для того чтобы эта проблема себя проявила, нужно, чтобы возникла ситуация, в которой СУБД прибегает к неэффективной операции полного сканирования таблицы (Full Table Scan) при выполнении каждого запроса с разбиением на страницы (в то же время могут происходить операции по вставке и удалению данных, и устаревшие данные нам при этом не нужны!).
Что такое «полное сканирование таблицы» (или «последовательный просмотр таблицы», Sequential Scan)? Это — операция, в ходе которой СУБД последовательно считывает каждую строку таблицы, то есть — содержащиеся в ней данные, и проверяет их на соответствие заданному условию. Известно, что этот тип сканирования таблиц является самым медленным. Дело в том, что при его выполнении выполняется много операций ввода/вывода, задействующих дисковую подсистему сервера. Ситуацию ухудшают задержки, сопутствующие работе с данными, хранящимися на дисках, и то, что передача данных с диска в память — это ресурсоёмкая операция.
Скажем, это может выглядеть так: «выбрать строки от 50000 до 50020 из 100000». То есть, системе для выполнения запроса нужно будет сначала загрузить 50000 строк. Видите, как много ненужной работы ей придётся выполнить?
Если не верите — взгляните на пример, который я создал, пользуясь возможностями db-fiddle.com.
Пример на db-fiddle.com
А второй, который представляет собой эффективное решение той же задачи, так:
Для того чтобы выполнить эти запросы, достаточно нажать на кнопку Run в верхней части страницы. Сделав это, сравним сведения о времени выполнения запросов. Оказывается, что на выполнение неэффективного запроса уходит, как минимум, в 30 раз больше времени, чем на выполнение второго (от запуска к запуску это время различается, например, система может сообщить о том, что на выполнение первого запроса ушло 37 мс, а на выполнение второго — 1 мс).
А если данных будет больше, то всё будет выглядеть ещё хуже (для того чтобы в этом убедиться — взгляните на мой пример с 10 миллионами строк).
То, что мы только что обсудили, должно дать вам некоторое понимание того, как, на самом деле, обрабатываются запросы к базам данных.
Учитывайте, что чем больше значение OFFSET — тем дольше будет выполняться запрос.
Что стоит использовать вместо комбинации OFFSET и LIMIT?
Вместо комбинации OFFSET и LIMIT стоит использовать конструкцию, построенную по такой схеме:
Это — выполнение запроса с разбиением на страницы, основанное на курсоре (Cursor based pagination).
Почему? Дело в том, что в явном виде указывая идентификатор последней прочитанной строки, вы сообщаете своей СУБД о том, где ей нужно начинать поиск нужных данных. Причём, поиск, благодаря использованию ключа, будет осуществляться эффективно, системе не придётся отвлекаться на строки, находящиеся за пределами указанного диапазона.
Давайте взглянем на следующее сравнение производительности различных запросов. Вот неэффективный запрос.
А вот — оптимизированная версия этого запроса.
Оба запроса возвращают в точности один и тот же объём данных. Но на выполнение первого уходит 12,80 секунд, а на второй — 0,01 секунда. Чувствуете разницу?
Возможные проблемы
Для обеспечения эффективной работы предложенного метода выполнения запросов нужно, чтобы в таблице присутствовал бы столбец (или столбцы), содержащий уникальные, последовательно расположенные индексы, вроде целочисленного идентификатора. В некоторых специфических случаях это может определять успех применения подобных запросов ради повышения скорости работы с базой данных.
Естественно, конструируя запросы, нужно учитывать особенности архитектуры таблиц, и выбирать те механизмы, которые наилучшим образом покажут себя на имеющихся таблицах. Например, если нужно работать в запросах с большими объёмами связанных данных, вам может показаться интересной эта статья.
Если вам интересна эта тема — вот, вот и вот — несколько полезных материалов.
Итоги
Главный вывод, который мы можем сделать, заключаются в том, что всегда, о каких бы размерах баз данных ни шла речь, нужно анализировать скорость выполнения запросов. В наше время крайне важна масштабируемость решений, и если с самого начала работы над некоей системой спроектировать всё правильно, это, в будущем, способно избавить разработчика от множества проблем.
Как вы анализируете и оптимизируете запросы к базам данных?