
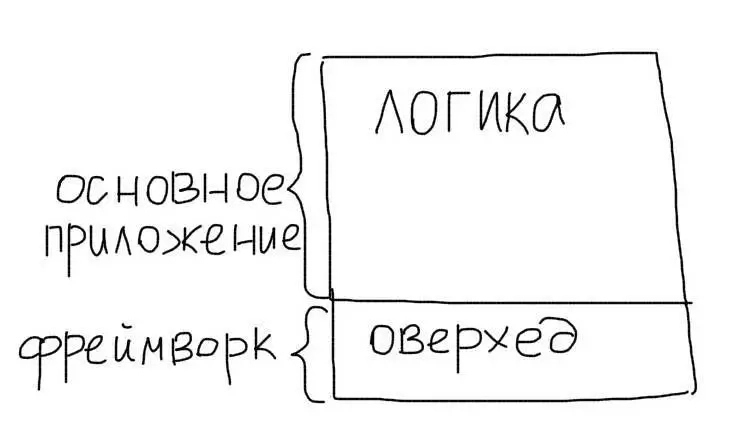
Что такое оверхед (overhead)?



Overhead (оверхед) – это дополнительное время, которое занимает выполнение используемой функции. Например, если Вы используете Фреймворк, он обладает каким-то оверхедом по сравнению с чистым кодом без Фреймворка (т.е. одинаковая логика будет работать медленнее с Фреймворком и быстрее без него). Оверхед характеризует какой-то инструмент (библиотеку, Фреймворк, функцию). Чем больше оверхед, тем хуже.
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Как исправить ошибку доступа к базе 1045 Access denied for user
Как перезапустить nginx после обновления конфигурации
Основные понятия о шардинге и репликации
Устройство колоночных баз данных
Настройка Master-Master репликации на MySQL за 6 шагов
Примеры ad-hoc запросов и технологии для их исполнения
Включение и использование log-файлов для проверки работы Nginx
Пример управления фоновыми процессами в supervisor’e
Анализ медленных PHP скриптов с помощью XHprof
Как создать и использовать составной индекс в Mysql
Рекомендации по настройке Redis для оптимизации ресурсов и повышения стабильности на производственном сервере
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Как проверить работу сайта под нагрузками
Уменьшение размера картинок при сохранении качества
Как и зачем используется заголовок Cache-control
Виртуальность и оверхед
Я думаю, все знают, что такое наследование или хотя бы слышали о нём. Часто мы используем наследование ради полиморфного поведения объектов. Но задумываемся ли мы о той цене, которую приходится платить за виртуальность? Поставлю вопрос по-другому: каждый ли знает эту цену? Давайте попробуем разобраться в этой проблеме.

В общем случае, выглядит наследование так:
При этом, как мы прекрасно знаем, класс Сhild наследует все члены класса Base. Т.е. с точки зрения размеров объектов, сейчас у нас sizeof(Base) = sizeof(Child) и составляет 4 (поскольку sizeof(int) = 4).
Не помешает сразу напомнить, что такое выравнивание. У нас есть два класса:
Вроде бы они ничем не отличаются друг от друга. Однако их размеры не одинаковы: sizeof(A2) = 16, sizeof(A1) = 24.
Всё дело в расположении переменных внутри класса. Если они имеют разный тип, то их расположение может серьёзно повлиять на размер объекта. В данном случае sizeof(double = 8), т.е 8 + 4 + 4 = 16, но класс A1 при этом имеет больший размер. А всё потому, что:
В итоге мы видим лишние 8 байт, которые добавились из-за того, что double оказался посередине. Во втором же случае картина будет примерно такая:
Но, скорее всего, вы и так это знали.
Теперь давайте вспомним, как мы расплачиваемся за виртуальные функции в классе. Вы, возможно, помните о таблицах виртуальных методов. Стандарт С++ не предусматривает какой-то единой реализации для вычисления адреса функции во время выполнения. Всё сводится к тому, что у нас появляется указатель в каждом классе, где есть хотя бы одна виртуальная функция.
Давайте допишем одну виртуальную функцию классу Base и посмотрим, как изменятся размеры:
Размер стал равным 16. 8 — размер указателя 4 — int плюс выравнивание. В 32-х разрядной архитектуре размер будет равен 8. 4 — указатель + 4 int без выравнивания.
Чтобы вам не приходилось верить на слово, приводим код, который сгенерировал Hopper Disassembler v4:
Без виртуальной функции ассемблерный код выглядит так:
Можно увидеть, что во втором случае у нас нет записи какого-либо адреса и переменная записывается без смещения на 8 байт.
Для тех, кто не любит ассемблер, давайте выведем, как это примерно будет выглядеть в памяти:
Раскомментим виртуальную функцию и полюбуемся на результат:
Теперь, когда мы это всё вспомнили, поговорим о виртуальном наследовании. Ни для кого не секрет, что в С++ возможно множественное наследование. Это мощная функция, которую лучше не трогать неумелыми руками — это не приведёт ни к чему хорошему. Но не будем о грустном. Самая известная проблема при множественном наследовании — это проблема ромба.
В классе D мы получим дублирующиеся члены класса А. Что в этом плохого? Даже если не брать в расчет, что размер класса увеличится на лишние n байт размера класса А, плохо то, что у нас получаются неоднозначности при вызове функций класса А — непонятно, какие именно вызывать: B::A::func или C::A::func. Мы всегда можем устранить подобные неоднозначности явными вызовами, но это не очень удобно. Вот здесь-то в игру и вступает виртуальное наследование. Чтобы не получать дубликат класса А, мы виртуально наследуемся от него:
Теперь всё хорошо. Или нет? Какой размер будет у класса D, если у нас в классе А всего один виртуальный метод?
Это интересный вопрос, потому тут всё что зависит от компилятора. Например, Visual Studio 2015 с настройками проекта по умолчанию выдаст: 4 8 8 12.
То есть мы имеем 4 байта на указатель в классе А (далее я буду сокращенно обозначать эти указатели, например, vtbA), дополнительно 4 байта на указатель из-за виртуального наследования для класса B и С (vtbB и vtbC). Наконец в D: 8 + 8 — 4, так как vtbA не дублируется, выходит 12.
А вот gcc 4.2.1 выдаст 8 8 8 16.
Давайте рассмотрим сначала случай без виртуального наследования, потому что результат будет таким же.
8 байт на vtbA, в классах B и С хранятся указатели только на виртуальные таблицы этих классов. Получается, что мы дублируем виртуальные таблицы, но зато не надо хранить vtbA в наследниках. В классе D хранится два адреса: для vtbB и vtbC.
Ничего не понятно? Смотрите: мы сохраняем два адреса в 0f95 и 0f98. Рассчитываются они исходя из того адреса, что лежит в 1018, плюс 0x28 в первом случае и 0x10 во втором. Итого мы получаем 10b0 и 10d0.
Теперь рассмотрим случай, когда наследование виртуальное.
В плане ассемблерного кода мало что меняется, у нас также хранится два адреса, но виртуальные таблицы для B, C и D стали значительно больше. Например, таблица для класса D увеличилась более чем в 7 раз!
Сэкономили на размере объекта, но увеличили размеры таблиц. А что если мы будем использовать виртуальное наследование повсюду, как советуют некоторые авторы?
Не приведём уже точных ссылок, но где-то читали, что если допускается мысль о множественном наследовании, то всегда нужно использовать виртуальное наследование, дабы уберечься от дублирования.
Итак, начинаем следовать совету в лоб:
Насколько изменится размер D?
Visual Studio 2015 выведет 4 8 8 16, т. е. добавился еще один указатель в классе D. Путём экспериментов мы выяснили, что, если наследоваться виртуально от каждого класса, то студия добавит еще один указатель в текущий класс. Например, если бы мы написали так:
то размер остался бы 12 байт.
Не подумайте, что студия экономит память, это вовсе не так. Для стандартных настроек размер указателя 4 байта, а не 8, как в gcc. Так что умножайте результат на 2.
А что gcc 4.2.1? Он вообще не изменит размер объектов, вывод все тот же — 8 8 8 16. Но представляете, что стало с таблицей для D?!
На самом деле, она, конечно, увеличилась, но незначительно. Другой вопрос, как это всё повлияет на последующие иерархии.
В качестве чистого эксперимента (не будем думать, есть ли в этом практическая польза) проверим, что случится с такой иерархией:
В студии размер класса E возрастет на 4, это мы уже выяснили, а в gcc размер D и E составит 16 байт.
Но при этом размер виртуальной таблицы для класса E (а она и так немаленькая, если убрать все виртуальное наследование) возрастёт в 4 раза! Если я правильно всё посчитал, то он уже достигнет половины килобайта или около того.
Какой же вывод можно сделать? Такой же, как и раньше: множественное наследование стоит использовать очень аккуратно, виртуальное наследование не панацея и, так или иначе, мы за него расплачиваемся. Возможно, стоит подумать в сторону интерфейсов и отказаться от виртуального наследования вообще.
overhead
Смотреть что такое «overhead» в других словарях:
Overhead — may be: Overhead (business), the ongoing operating costs of running a business Engineering overhead, ancillary design features required by a component of a device Computational overhead, ancillary computation required by an algorithm or program… … Wikipedia
Overhead — (v. engl.: over über; head Kopf) ist ein in verschiedenen Bereichen verwendeter Anglizismus, den man oft mit „Mehraufwand“ übersetzen kann. Overhead bezeichnet: allgemein (evtl. entbehrlichen) Mehraufwand, der nicht direkt Nutzen erzeugt Overhead … Deutsch Wikipedia
overhead — over·head / ō vər ˌhed/ n: business expenses (as rent or insurance) not chargeable to a particular part of the work or product Merriam Webster’s Dictionary of Law. Merriam Webster. 1996. overhead … Law dictionary
overhead — [ō′vər hed΄; ] for adv. [ ō΄vər hed′] adj. 1. a) located or operating above the level of the head ☆ b) designating a door, as of a garage, that moves into place overhead when opened 2. in the sky 3. on a higher level, with reference to related… … English World dictionary
overhead — ► ADVERB ▪ above one s head; in the sky. ► ADJECTIVE 1) situated overhead. 2) (of a driving mechanism) above the object driven. 3) (of an expense) incurred in the upkeep or running of premises or a business. ► NOUN 1) an overhead cost or expense … English terms dictionary
overhead — 1530s, above one s head (adv.), from OVER (Cf. over) + HEAD (Cf. head). The adjective is attested from 1874. As a noun, short for overhead costs, etc., it is attested from 1914 … Etymology dictionary
overhead — [adj/adv] up above above, aerial, aloft, atop, hanging, in the sky, on high, over, overhanging, roof, skyward, upper, upward; concept 586 Ant. below, underfoot overhead [n] general, continuing costs of operation budget, burden, cost, depreciation … New thesaurus
Overhead — Cost; in die deutsche wirtschaftliche Umgangssprache übernommene Bezeichnung für ⇡ fixe Kosten bzw. ⇡ Gemeinkosten … Lexikon der Economics
overhead — cost An indirect cost of an organization. Overheads are usually classified as manufacturing overheads, administration overheads, selling overheads, distribution overheads, and research and development costs … Accounting dictionary
Что такое оверхед в программировании
Все, что вы разрабатываете, не будучи зависимыми от третьих сторон, более предсказуемо по финансовым и временным затратам. При интеграции же «мяч» почти постоянно находится на стороне команды сервиса. Непрерывность хода и стоимость проекта обусловлены их уровнем вовлеченности в сотрудничество, а также состоянием документации к API.
Мы в Axmor осуществили 100+ интеграций с различными веб-сервисами и аппаратными решениями, и можем сказать, что практически каждая интеграция в плане управления проектом — это путь, полный мелких и крупных подводных камней. Тем не менее, все решаемо, вопрос лишь в количестве рисков, которые нужно учесть на старте.
В статье мы предложим 2 чек-листа действий — для случаев интеграции с публичными и непубличными сервисами. Эти подготовительные мероприятия помогут минимизировать перерасходы по времени или бюджету и спрогнозировать объем рисков в целом.
Статья будет полезна менеджерам проектов, тимлидам и разработчикам.
Интеграция с публичным сервисом
Поскольку такие сервисы, как правило, платные или условно бесплатные, то для привлечения и удержания пользователей владельцы заботятся об их удобстве, публикуя официальную документацию, а также предоставляя возможность обратиться за помощью в службу поддержки.
Если бы мы жили в идеальном мире, на этом история об интеграции с публичным сервисом и закончилась бы. В реальности же качество документации может варьироваться, из-за чего нередко возникают следующие проблемы:
Полнота: документация неполная и описаны не все случаи использования сервиса;
Актуальность: фактический функционал сервиса отличается от функционала, описанного в документации;
Стабильность: функционал на практике может оказаться нестабильным или лимитированным;
Доступность: необходимая часть функционала может быть платной. Например, плату потребуют после 10 000 запроса к сервису — это лучше выяснить заранее и заложить в проектный бюджет.
Случай из нашей практики — с хорошим концом
Один из наших заказчиков — владелец сайта, на котором регистрируют компании в Австралии. Перед нами была поставлена задача по интеграции этого сайта с публичным австралийским государственным сервисом — ASIC Business Name Registration Service.
Первая проблема заключалась в том, что документация, размещенная на сайте сервиса, представляла собой описание функционала еще не выпущенной версии 3.1, хотя в продакшне находилась версия 1.5.
После безуспешных попыток настроить работу сервиса по имеющимся инструкциям мы решили обратиться за помощью в службу поддержки, и началась долгая переписка с ее сотрудником.
Он любезно предоставил соответствующую версии сервиса документацию, но на этом сложности не закончились. В ней описывались основные методы взаимодействия с сервисом в «идеальных» условиях, однако, при работе с реальными данными возникали ситуации, которых не было в документации, а сами запросы возвращали лишь «400 Bad Request» без описания причины проблемы. В каждой такой ситуации приходилось писать сотруднику саппорта и вместе искать решение. Некоторые проблемы были настолько специфичными, что он сам несколько раз обращался в свой IT-отдел за консультацией.
Третьей проблемой была разница часовых поясов между Новосибирском и Мельбурном. К тому времени, как у нас возникал вопрос к документации или по использованию сервиса, рабочий день в Австралии подходил к концу, и ответ мы получали только на следующий день утром. Вопросы возникали часто, а скорость ответов составляла приблизительно день.
В конечном итоге мы справились с поставленной задачей (спасибо саппортеру!), и интегрировали необходимый сервис в продукт, однако, на это ушло в
3 раза больше времени (
300 часов против предполагаемых
100 часов). Но, как сказал сотрудник поддержки ASIC, мы были первыми, кому это удалось.
Чек-лист при интеграции с публичным сервисом
Убедиться в актуальности предоставленной документации.
Выявить недостающую информацию заранее и уточнить детали интеграции.
Не пытаться экспериментировать самостоятельно (хотя в разумных пределах можно) — лучше заручиться помощью у специалиста поддержки, причем желательно найти конкретного специалиста и с ним поддерживать связь по всем вопросам.
Проявлять активность и использовать все возможные варианты, в том числе не стесняться подключать непосредственного заказчика к решению проблем и переговорам со службой поддержки.
Интеграция с непубличным сервисом
Непубличные сервисы — это внутрикорпоративные или отраслевые системы, доступные сотрудникам компании, либо партнерам. Интеграции с ними несколько сложнее, так как документированность у них традиционно ниже — задачи постоянного роста количества пользователей нет, роль сервиса в создании прибыли не проанализирована или является опосредованной, поэтому у владельца нет серьезной мотивации для его усовершенствования.
Интеграции без подробной документации сложны и часто вызывают большой перерасход в проектах. Наилучшим подходом к их реализации является тщательная проработка требований и составление документации непосредственно перед стартом разработки.
Случай из нашей практики — с плохим концом
Один из наших проектов в какой-то момент зашел в тупик из-за невозможности интеграции с внутренним сервисом заказчика. Несмотря на то, что перед стартом новой фазы разработки специалисты со стороны клиента предоставляли краткое описание реализации и интеграции новой функциональности, на деле выяснилось, что подобный подход не работоспособен. Часто новые договоренности — по набору и структуре запросов, а также применяемой логики для расчета тех или иных параметров системы — осуществлялись на прямой связи с разработчиком, никак не документировались.
Бизнес торопил со сроками, бюрократический аппарат на стороне заказчика работал медленно, четкие требования отсутствовали. Лучшим вариантом было бы приостановить проект, пока не появится документация, но складывалось впечатление, что вот сейчас еще немного, доделаем, и можно будет закончить проект и вздохнуть с облегчением, но проект так и не был доведен до его логического завершения и в итоге был приостановлен.
Чек-лист при интеграции с непубличным сервисом
Если вы имеете дело с внутренним, незадокументированным сервисом, нужно запросить исходный код у владельца:
в случае интеграции по протоколу SOAP — запросить WSDL-файл;
в случае, если есть доступ к документации API сервиса (Swagger, RAML и др.) — получить доступ и изучить существующий API;
если есть возможность «прикрутить» систему автодокументации, то прикрутить ее и затем изучить API сервиса;
в случае, когда есть уже реализованный пример интеграции с сервисом, запросите и изучите его.
Изучить API и получить все необходимые уточнения от команды, ответственной за работоспособность сервиса, поддерживать связь и стараться как можно раньше поднять вопрос или проблему.
Если API не совсем готов, заложить календарное время на коммуникации по наполнению до требуемого уровня.
Вывод
Глобальный рынок API растет со среднегодовой скоростью 33%. В ближайшие три года этот сегмент будет занимать лидерские позиции. Уже сейчас многие сервисы успешны настолько, насколько удачно они образовали единую экосистему с другими.
Интеграция со сторонним решением похожа на поиск черной кошки в темной комнате с разложенными по полу граблями. В идеале, чтобы обойти грабли и поймать кошку, вам нужен «фонарик», в роли которого здесь выступают документация или код. В случае, когда фонарика нет, может помочь человек с «картой разложенных граблей», который будет направлять вас в темноте на слух. Если у вас уже есть некоторый опыт, делайте гипотезы и разбивайте проект на фазы, где возможно объективно оценить трудоемкость интеграции (где вероятность возникновения риска мала), и фазы, которые требуют дополнительных уточнений (с высоким уровнем вероятности срабатывания рисков) и адекватно оценить стоимость реализации пока не предоставляется возможным.
Если же вы проводите интеграцию впервые, ищите «фонарик» или человека с «картой».
Ищете исполнителя для реализации проекта?
Проведите конкурс среди участников CMS Magazine
Узнайте цены и сроки уже завтра. Это бесплатно и займет ≈5 минут.
Типобезопасная работа с регистрами без оверхеда на С++17: value-based метапрограммирование
С++, благодаря своей строгой типизации, может помочь программисту на этапе компиляции. На хабре уже довольно много статьей, описывающих как, используя типы, добиться этого, и это прекрасно. Но во всех, что я читал, есть один изъян. Сравним с++ подход и си подход с использованием CMSIS, привычный в мире программирования микроконтроллеров:
Сразу видно, что с++ подход более читаем, и, поскольку каждая функция принимает конкретный тип, нельзя ошибиться. Си подход не проверяет валидность данных, это ложится на плечи программиста. Как правило, об ошибке узнают только при отладке. Но с++ подход не бесплатен. Фактически, каждая функция имеет своё обращение к регистру, в то время как на си сначала собирается маска из всех параметров на этапе компиляции, так как это всё константы, и записывается в регистр разом. Далее я расскажу, как попытался совместить типобезопасность с++ с минимизацией обращений к регистру. Вы увидите, это значительно проще, чем кажется.
Сначала приведу пример, как бы я хотел, чтобы это выглядело. Желательно, чтобы это не сильно отличалось от уже привычного с++ подхода.
Каждый параметр в методе set — отдельный тип, по которому можно понять, в какой регистр надо записать значение, а значит во время компиляции можно оптимизировать обращение к регистрам. Метод вариадический, поэтому аргументов может быть любое количество, но при этом должна присутствовать проверка, что все аргументы относятся к данной периферии.
Ранее эта задача казалась мне довольно сложной, пока я не наткнулся на это видео о value-based метапрограммировании. Данный подход к метапрограммированию позволяет писать обобщённые алгоритмы, как будто это обычный плюсовый код. В данной статье я приведу только самое необходимое из видео для решения поставленной задачи, там куда больше обобщённых алгоритмов.
Решать задачу буду абстрактно, не для конкретной периферии. Итак, есть несколько полей регистров, условно запишу их в качестве перечислений.
Первые три будут относиться к одной периферии, четвертое к другой. Таким образом, если вписать значение четвёртого перечисления в метод первой периферии, должна быть ошибка компиляции, желательно понятная. Так же первые 2 перечисления будут относиться к одному регистру, третье к другому.
Поскольку значения перечислений не хранят в себе ничего, кроме собственно значений, нужен дополнительный тип, который будет хранить, к примеру, маску, чтобы определять, в какую часть регистра это перечисление будет записываться.
Осталось связать эти 2 типа. Тут пригодится фишка уже 20 стандарта, но она довольно тривиальна и можно реализовать её самому.
Суть в том, что можно из любого типа сделать значение и передать его в функцию в качестве аргумента. Это главный кирпичик value-based подхода в метапрограммировании, в котором надо стараться передавать информацию о типе через значения, а не в качестве параметра шаблона. Тут я определил макрос, но являюсь противником их в с++. Но он позволяет далее писать меньше. Далее приведу связывающую перечисление и его свойства функцию и ещё один макрос, позволяющий уменьшить количество копипасты.
Адрес, где находится регистр, хранится в виде смещения относительно начала периферии.
Для этого списка можно реализовать множество constexpr функций. Их реализация значительно проще в понимании, чем знаменитые списки типов Александреску (библиотека Loki). Далее будут примеры.
Вторым важным свойством периферии должна быть возможность расположить ее как по конкретному адресу (в микроконтроллере), так и передать адрес динамически для тестов. Поэтому структура периферии будет шаблонной, и в качестве параметра принимать тип, который в поле value будет хранить конкретный адрес периферии. Параметр шаблона будем определять из конструктора. Ну и метод set, о котором говорилось ранее.
Всё, что делает метод set — вызывает свободную функцию, передавая в неё всю необходимую для обобщенного алгоритма информацию.
Приведу примеры типов, предоставляющих адрес на периферию.
Вся информацию для обобщенного алгоритма подготовлена, осталось его реализовать. Приведу текст этой функции.
Для проверки, что все аргументы относятся к переданным регистрам, а значит конкретной периферии, необходимо реализовать алгоритм all_of. По аналогии со стандартной библиотекой алгоритм принимает на вход список типов и функцию-предикат. В качестве функции используем лямбду.
Применяя новый алгоритм над списком регистров, в новом списке оставлются лишь те, в которые надо записать переданные аргументы.
Функция позволяет добраться до каждого из регистров, куда надо писать. В лямбде вычисляется значение для записи в регистр, определяется адрес, куда необходимо записать, и непосредственно запись в регистр.
Для того, чтобы вычислить значение одного регистра, вычисляется значение для каждого аргумента, к которому относится этот регистр, и объединяется результат по ИЛИ.
Вычисление значения для конкретного поля должно выполняться только для аргументов, от которых этот регистр наследуется. Для аргумента достаем из его свойства маску, по маске определяем смещение значения внутри регистра.
Алгоритм, определяющий смещение по маске, можно написать самому, но я воспользовался уже существующей builtin функцией.
Осталась последняя функция, которая пишет значение по конкретному адресу.
Для проверки выполнения задачи написан небольшой тест:
Всё тут написанное объединил вместе и скомпилировал в godbolt. Там любой может поэксперементировать с подходом. Видно, что поставленная цель выполнена: нет лишних обращений к памяти. Значение, которое необходимо записать в регистры, вычисляется на этапе компиляции:
P.S.:
Спасибо всем за комментарии, благодаря им, я немного доработал подход. Новый вариант можно посмотреть тут