
Параллельное программирование и библиотека TPL
Задачи и класс Task
Для определения и запуска задачи можно использовать различные способы. Первый способ создание объекта Task и вызов у него метода Start:
В качестве параметра объект Task принимает делегат Action, то есть мы можем передать любое действие, которое соответствует данному делегату, например, лямбда-выражение, как в данном случае, или ссылку на какой-либо метод. То есть в данном случае при выполнении задачи на консоль будет выводиться строка «Hello Task!».
А метод Start() собственно запускает задачу.
В качестве результата метод возвращает запущенную задачу.
Третий способ определения и запуска задач представляет использование статического метода Task.Run() :
Определим небольшую программу, где используем все эти способы:
Ожидание задачи
Важно понимать, что задачи не выполняются последовательно. Первая запущенная задача может завершить свое выполнение после последней задачи.
Или рассмотрим еще один пример:
Однако в данном случае консольный вывод может выглядеть следующим образом:
То есть мы видим, что даже когда основной код в методе Main уже отработал, запущенная ранее задача еще не завершилась.
Чтобы указать, что метод Main должен подождать до конца выполнения задачи, нам надо использовать метод Wait :
Свойства класса Task
Класс Task имеет ряд свойств, с помощью которых мы можем получить информацию об объекте. Некоторые из них:
AsyncState : возвращает объект состояния задачи
CurrentId : возвращает идентификатор текущей задачи
Exception : возвращает объект исключения, возникшего при выполнении задачи
Часть 1. MPI — Введение и первая программа
Введение. Зачем все это?
В этом цикле статей речь пойдет о параллельном программировании.
В бой. Введение
Довольно часто самые сложные алгоритмы требуют огромного количества вычислительных ресурсов в реальных задачах, когда программист пишет код в стандартном его понимании процедурного или Объектно Ориентированного Программирования(ООП), то для особо требовательных алгоритмических задач, которые работают с большим количеством данных и требуют минимизировать время выполнения задачи, необходимо производить оптимизацию.
В основном используют 2 типа оптимизации, либо их смесь: векторизация и распараллеливание
вычислений. Чем же они отличаются?
Вычисления производятся на процессоре, процессор пользуется специальными «хранилищами» данных называемыми регистрами. Регистры процессора напрямую подключены к логическим элементам и требуют гораздо меньшее время для выполнения операций над данными, чем данные из оперативной памяти, а тем более на жестком диске, так как для последних довольно большую часть времени занимает пересылка данных. Так же в процессорах существует область памяти называемая Кэшем, в нем хранятся те значения, которые в данный момент участвуют в вычислениях или будут участвовать в них в ближайшее время, то есть самые важные данные.
Задача оптимизации алгоритма сводится к тому, чтобы правильно выстроить последовательность операций и оптимально разместить данные в Кэше, минимизировав количество возможных пересылок данных из памяти.
Параллелизация же позволяет пользоваться не только вычислительными возможностями одного процессора, а множеством процессоров, в том числе и в системах с распределенной памятью, и т.п. В подобных системах как правило намного больше вычислительных мощностей, но этим всем нужно уметь управлять и правильно организовывать параллельную работу на конкретных потоках.
Основная часть
Если сильно упростить, то первая модель берет разные исходные коды программы и выполняет их на разных потоках, а вторая модель берет один исходный код и запускает его на всех выделенных потоках. Программы написанные под стиль MIMD довольно сложно отлаживаются из-за своей архитектуры, поэтому чаще используется модель SPMD. В MPI возможно использовать и то и то, но по стандарту(в зависимости от реализации, разумеется) используется модель SPMD.
Установка
В командной строке вводим следующие команды:
Первая команда обновляет менеджер пакетов, вторая устанавливает компилятор GCC, если его нет в системе, третья программа устанавливает компилятор через который мы собственно и будем работать с C\С++&MPI кодом.
Первые шаги.
Для понимания того что происходит дальше нужно определиться с несколькими терминами:
В данном примере не будем использовать пересылку данных, а лишь ознакомимся с основами процедур MPI.ения возможности использования большинства процедур MPI в любой программе должны быть следующие процедуры:
Первая процедура предназначения для инициализации параллельной части программы, все другие процедуры, кроме некоторых особых, могут быть вызваны только после вызова процедуры MPI_Init, принимает эта функция аргументы командной строки, через которые система может передавать процессу некоторые параметры запуска. Вторая процедура же предназначена для завершения параллельной части программы.
Для того чтобы проверить работу программы реализуем самую примитивную программку на С++ с применением MPI.
Чтобы запустить эту программу сохраним нашу запись в файле с любым названием и расширением *.cpp, после чего выполним следующие действия в консоли (В моем случае код лежит в файле main.cpp):
В этой краткой статье мы на примере наипростейшей программы научились запускать файлы C++ с MPI кодом и разобрались что за зверь вообще MPI и с чем его едят. В дальнейших туториалах мы рассмотрим уже более полезные программы и наконец перейдем ко коммуникации между процессами.
Введение в параллелизм
Сейчас почти невозможно найти современную компьютерную систему без многоядерного процессора. Даже недорогие мобильные телефоны предлагают пару ядер под капотом. Идея многоядерных систем проста: это относительно эффективная технология для масштабирования потенциальной производительности процессора. Эта технология стала широкодоступной около двадцати лет назад, и теперь каждый современный разработчик способен создать приложение с параллельным выполнением для использования такой системы. На наш взгляд, сложность параллельного программирования часто недооценивается.
В этой статье мы попробуем разработать простейшее приложение, использующее для распараллеливания средства C++ и сравнить его с версией, использующей Intel oneTBB.
Операционные системы и язык C++ предоставляют интерфейсы для создания потоков, которые потенциально могут выполнять один и тот же или различные наборы инструкций одновременно.
Основными источниками проблем многопоточного выполнения являются data races (гонки данных) и race conditions (состояние гонки). Простыми словами, C++ определяет data race как одновременные и несинхронизированные доступы к одной и той же ячейке памяти, при этом один из доступов модифицирует данные. В то время как race conditions является более общим термином, описывающим ситуацию, когда результат выполнения программы зависит от последовательности или времени выполнения потоков.
Основная проблема race conditions заключается в том, что они могут быть незаметны во время разработки программного обеспечения и могут исчезнуть во время отладки. Такое поведение часто приводит к ситуации, когда приложение считается законченным и корректным, но у конечного пользователя периодически возникают проблемы, часто неясного характера. Для решения проблемы data race, C++ предоставляет набор интерфейсов, таких как атомарные операции и примитивы для создания критических секций (мьютексы).
Атомарные операции — это мощный инструмент, который позволяет избежать data races и создавать эффективные алгоритмы синхронизации. Однако, это создает замысловатую модель памяти C++, которая представляет собой еще один уровень сложности.
Давайте попытаемся распараллелить простую задачу вычисления суммы элементов массива. Решение этой проблемы в однопоточной программе может выглядеть следующим образом:
int summarize(const std::vector & vec) <
Выполнение алгоритма в однопоточной программе:

Для того чтобы исполнить алгоритм параллельно, нам нужно разделить его на независимые части, которые могут обрабатываться независимо друг от друга. Самый простой подход состоит в том, чтобы разделить обрабатываемые элементы на несколько частей и обработать каждую часть в своем собственном потоке.

Однако в этом коде есть сложность, которая не позволяет нам просто разделить массив на две равные части и обрабатывать его параллельно. Все элементы суммируются в одну переменную, доступ к которой приведёт к data race, потому что один из потоков может записывать эту переменную одновременно с другим потоком, считывающим или записывающим в данную переменную.
Составной оператор (оператор +=), по сути, состоит из трех операций: чтение из памяти, операция сложения и сохранение результата в памяти. Эти операции могут выполняться параллельно разными потоками, что может привести к неожиданным результатам. На следующем рисунке показан возможный порядок операций на временной шкале двух потоков. Основная сложность заключается в том, что оба потока могут не получить результат операций другого потока и перезаписать данные. C++ трактует такие ситуации как data race, и поведение программы, в таких случаях, не определено. Например, в результате мы можем получить четыре, ожидая шесть (как показано на рисунке). В худшем случае данные могут быть в непредсказуемом состоянии.

Мьютекс имеет два основных интерфейса: блокировка (lock) и разблокировка (unclock). Блокировка переводит мьютекс в эксклюзивное владение, а разблокировка освобождает его, делая доступным для других потоков. Поток, который не может заблокировать мьютекс, будет остановлен, ожидая, пока другой поток освободит данный мьютекс.

Код, защищенный мьютексом, также называется критической секцией. Важное наблюдение состоит в том, что второй поток, который не смог заблокировать мьютекс, не будет делать ничего полезного, во время того, пока первый поток находится в критической секции. Таким образом, размер критической секции может значительно повлиять на общую производительность системы.
Давайте попробуем сделать наш последовательный пример параллельным. Для создания потоков используем библиотеку
int summarize(const std::vector & vec) <
int num_threads = 2;
auto thread_func = [&sum, &vec, &m] (int thread_id) <
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i
// Используем lock_guard, имплементирующий RAII идиому:
// (т.е. вызван mutex.lock())
for (int thread_id = 0; thread_id
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
for (int thread_id = 0; thread_id
// Нам нужно дождаться всех потоков
// до разрушения std::vector
int summarize(const std::vector & vec) <
int num_threads = 2;
auto thread_func = [&sum, &vec, &m] (int thread_id) <
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i
// Используем lock_guard, имплементирующий RAII идиому:
// (т.е. вызван mutex.lock())
// (т.е. вызван mutex.unlock())
for (int thread_id = 0; thread_id
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
for (int thread_id = 0; thread_id
// Нам нужно дождатьсявсех потоков до
auto thread_func = [&sum, &vec, &m] (int thread_id) <
// Делим origin rangeитерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i
// Используем lock_guard, имплементирующий RAII идиому:
// (т.е. вызван mutex.lock())
// (т.е. вызван mutex.unlock())
int summarize(const std::vector & vec) <
int sum = tbb::parallel_reduce(tbb::blocked_range <0, vec.size()>, 0,
[&vec] (const auto& r, int init) <
oneTBB использует подход, основанный на work stealing алгоритме распределения задач, предоставляя обобщенные параллельные алгоритмы, применимые для широкого спектра приложений. Основное преимущество подхода oneTBB заключается в том, что он позволяет легко создавать параллелизм в различных независимых компонентах приложения.
В нашей серии статей мы продемонстрируем, как oneTBB можно использовать для динамической балансировки нагрузки и распараллеливания графов. Помимо параллелизма задач на процессоре, мы покажем, как oneTBB можно использовать в качестве уровня абстракции для балансировки вычислений между несколькими разнородными устройствами, такими как GPU.
ПРОГРАММИРОВАНИЕ ПАРАЛЛЕЛЬНОЕ
раздел программирования, связанный с изучением и разработкой методов и средств для: а) адекватного описания в программах естественного параллелизма моделируемых в ЭВМ и управляемых ЭВМ систем и процессов, б) распараллеливания обработки информации в многопроцессорных и мультипрограммных ЭВМ с целью ускорения вычислений и эффективного использования ресурсов ЭВМ.
В отличие от программирования последовательных вычислений, концептуальную основу к-рого составляет понятие алгоритма, реализуемого по шагам строго последовательно во времени, в П. п. программа порождает совокупность параллельно протекающих процессов обработки информации, полностью независимых или связанных между собой статическими или динамическими пространственно-временными или причинно-следственными отношениями.
Вычислительный параллелизм выступает в разных конкретных формах в зависимости от этапа программирования, от сложности параллельных фрагментов и характера связей между ними.
В текстах, описывающих задачи и программы, можно выделить уровни сложности фрагментов, для к-рых задача распараллеливания, т. е. составления параллельной программы, решается по-разному: выражения со скалярными данными; выражения над структурными данными (векторы, матрицы, деревья и т. п.), записываемые в алгоритмич. языках с помощью операторов цикла; подзадачи и подпрограммы; независимые задачи и программы в мультипроцессорных системах.
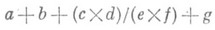
преобразуется в эквивалентное выражение
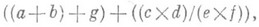
исполнение к-рого осуществляется за 3 параллельных шага. Отношение числа параллельных шагов исполнения к числу последовательных шагов наз. ускорением распараллеливания. Любое арифметич. выражение с поперандами может быть вычислено параллельно за О(log n).шагов с использованием п процессоров. Относительная простота алгоритмов распараллеливания выражений позволяет реализовать их автоматически в ЭВМ с помощью специальных программ или аппаратными средствами.
при исполнении к-рых тело цикла копируется по определенным правилам на параллельно исполняемые итерации. Эти языки снабжаются также более развитыми средствами описания структурных данных и средствами управления размещением их в памяти для обеспечения быстрого параллельного доступа к структурным данным. Дальнейшее повышение уровня языков программирования состоит в использовании групповых операций над структурными данными таких, как покомпонентное умножение и сложение векторов и матриц, скалярное и векторное произведение, обращение матриц и т. п. Применение таких языков позволяет заменить автоматич. распараллеливание последовательных циклов, к-рое на практике осуществимо, но относительно сложно, на непосредственное задание параллельных групповых операций.
Распараллеливание на уровне подзадач и подпрограмм существенно сложнее. В этом случае параллельные процессы могут иметь сложную внутреннюю структуру. длительность их выполнения не фиксирована; процессы взаимодействуют, обмениваясь данными и обращаясь к общим ресурсам (общие данные и программы в памяти, внешние устройства и т. п.). Автоматич. распараллеливание на этом уровне требует сложных алгоритмов анализа задач и учета динамич. ситуаций в системе. В связи с этим особое значение имеет создание языков П. п., позволяющих программисту непосредственно описывать сложные взаимодействия параллельных процессов.
Чисто асинхронное П. п. используется для организации вычислений в распределенных вычислительных системах, в к-рых полностью исключены конфликты по ресурсам. Стремление упростить организацию взаимодействий между процессами с общими ресурсами привлекает внимание к асинхронным методам вычислений, в к-рых разрешен нерегламентированный доступ параллельных процессов к общим ресурсам. Напр., разрабатываются асинхронные алгоритмы, в к-рых параллельные процессы обмениваются данными с общей памятью, причем неупорядоченный доступ к памяти не мешает достижению однозначного результата.
Параллелизм против многопоточности против асинхронного программирования: разъяснение
В последние время, я выступал на мероприятиях и отвечал на вопрос аудитории между моими выступлениями о Асинхронном программировании, я обнаружил что некоторые люди путали многопоточное и асинхронное программирование, а некоторые говорили, что это одно и тоже. Итак, я решил разъяснить эти термины и добавить еще одно понятие Параллелизм. Здесь есть две концепции и обе они совершенно разные, первая синхронное и асинхронное программирование и вторая – однопоточные и многопоточные приложения. Каждая программная модель (синхронная или асинхронная) может работать в однопоточной и многопоточной среде. Давайте обсудим их подробно.
Синхронная программная модель – это программная модель, когда потоку назначается одна задача и начинается выполнение. Когда завершено выполнение задачи тогда появляется возможность заняться другой задачей. В этой модели невозможно останавливать выполнение задачи чтобы в промежутке выполнить другую задачу. Давайте обсудим как эта модель работает в одно и многопоточном сценарии.
Однопоточность – если мы имеем несколько задач, которые надлежит выполнить, и текущая система предоставляет один поток, который может работать со всеми задачами, то он берет поочередно одну за другой и процесс выглядит так:

Здесь мы видим, что мы имеем поток (Поток 1) и 4 задачи, которые необходимо выполнить. Поток начинает выполнять поочередно одну за одной и выполняет их все. (Порядок, в котором задачи выполняются не влияет на общее выполнение, у нас может быть другой алгоритм, который может определять приоритеты задач.
Многопоточность – в этом сценарии, мы использовали много потоков, которые могут брать задачи и приступать к работе с ними. У нас есть пулы потоков (новые потоки также создаются, основываясь на потребности и доступности ресурсов) и множество задач. Итак, поток может работать вот так:
Здесь мы можем видеть, что у нас есть 4 потока и столько же задач для выполнения, и каждый поток начинает работать с ними. Это идеальный сценарий, но в обычных условиях мы используем большее количество задач чем количество доступных потоков, таким образом освободившийся поток получает другое задание. Как уже говорилось создание нового потока не происходит каждый раз потому что для этого требуются системные ресурсы такие как процессор, память и начальное количество потоков должно быть определенным.
Теперь давайте поговорим о Асинхронной модели и как она ведет себя в одно и многопоточной среде.
Асинхронная модель программирования – в отличии от синхронной программной модели, здесь поток однажды начав выполнение задачи может приостановить выполнение сохранив текущее состояние и между тем начать выполнение другой задачи.
Здесь мы можем видеть, что один поток отвечает за выполнение всех задач и задачи чередуются друг за другом.
Если наша система способно иметь много потоков тогда все потоки могут работать в асинхронной модели как показано ниже:
Здесь мы можем видеть, что одна и та же задача скажем Т4, Т5, Т6 … обрабатывается несколькими потоками. Это красота этого сценария. Как мы можем видеть, что задача Т4 начала выполнение первой Потоком 1 и завершен Потоком 2. Подобным образом задча Т6 выполнена Потоком 2, Потоком 3 и Потоком 4. Это демонстрирует максимальное использование потоков.
Итак, до сих пор мы обсудили 4 сценария:
Проще говоря параллелизм способ обработки множественных запросом одновременно. Так как мы обсуждали два сценария когда обрабатывались множественные запросы, многопоточное программирование и асинхронная модель (одно и многопоточная). В случае асинхронной модели будь она однопоточной или многопоточной, в то время, когда выполняются множество задач, некоторые из них приостанавливаются, а некоторые выполняются. Существует много особенностей, но это выходит за рамки этой публикации.
Как обсуждалось ранее новая эпоха за асинхронным программированием. Почему это так важно?
Преимущества асинхронного программирования
Существует две вещи очень важные для каждого приложения – удобство использования и производительность. Удобство использования потому что пользователь нажав кнопку чтобы сохранить некоторые данные что в свою очередь требует выполнения множества задач таких как чтение и заполнение данных во внутреннем объекте, установление соединения с SQL и сохранения его там. В свою очередь SQL запускается на другой машине в сети и работает под другим процессом, это может потребовать много время. Таким образом если запрос обрабатывается одним процессом экран будет находится в зависшем состоянии до тех пор, пока процесс не завершится. Вот почему сегодня многие приложения и фреймворки полностью полагаются на асинхронную модель.
Производительность приложения и системы также очень важны. Было замечено в то время как выполняется запрос, около 70-80% из них попадают в ожидании зависимых задач. Таким образом, это может быть максимально использовано в асинхронном программирование, где, как только задача передается другому потоку (например, SQL), текущий поток сохраняет состояние и доступен для выполнения другого процесса, а когда задача sql завершается, любой поток, который является свободным, может заняться этой задачей.
Асинхронность в ASP.NET
Асинхронность в ASP.NET может стать большим стимулом для повышения производительности вашего приложения. Вот, как IIS обрабатывает запрос:
Когда запрос получен IIS, он берет поток из пула потоков CLR (IIS не имеет какого-либо пула потоков, а сам вместо этого использует пул потоков CLR) и назначает его ему, который далее обрабатывает запрос. Поскольку количество потоков ограничено, и новые могут быть созданы с определенным пределом, тогда если поток будет находится большую часть времени в состоянии ожидания, то это сильно ударит по вашему серверу, вы можете предположить, что это реальность. Но если вы пишете асинхронный код (который теперь становится очень простым и может быть написан почти аналогично синхронному при использовании новых ключевых слов async / await), то он будет работать намного быстрее, и пропускная способность вашего сервера значительно возрастет, потому что вместо ожидания какого-нибудь завершения, он будет доступен пулу потоков, для нового запроса. Если приложение имеет множество зависимостей и длительный процесс выполнения, то для этого приложения асинхронное программирование будет не меньшем благом.
Итак, теперь мы поняли разницу многопоточного, асинхронного программирования и преимущества, которые мы можем получить, используя асинхронную модель программирования.