
Linux pipes tips & tricks
Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман Дугласом Макилроем для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
Простой дебаг
Исходный код, уровень 1, shell
Т. к. лучшая документация — исходный код, обратимся к нему. Bash использует Yacc для парсинга входных команд и возвращает ‘command_connect()’, когда встречает символ ‘|’.
parse.y:
Также здесь мы видим обработку пары символов ‘|&’, что эквивалентно перенаправлению как stdout, так и stderr в конвеер. Далее обратимся к command_connect():make_cmd.c:
где connector это символ ‘|’ как int. При выполнении последовательности команд (связанных через ‘&’, ‘|’, ‘;’, и т. д.) вызывается execute_connection():execute_cmd.c:
PIPE_IN и PIPE_OUT — файловые дескрипторы, содержащие информацию о входном и выходном потоках. Они могут принимать значение NO_PIPE, которое означает, что I/O является stdin/stdout.
execute_pipeline() довольно объемная функция, имплементация которой содержится в execute_cmd.c. Мы рассмотрим наиболее интересные для нас части.
execute_cmd.c:
Таким образом, bash обрабатывает символ конвейера путем системного вызова pipe() для каждого встретившегося символа ‘|’ и выполняет каждую команду в отдельном процессе с использованием соответствующих файловых дескрипторов в качестве входного и выходного потоков.
Исходный код, уровень 2, ядро
Обратимся к коду ядра и посмотрим на имплементацию функции pipe(). В статье рассматривается ядро версии 3.10.10 stable.
fs/pipe.c (пропущены незначительные для данной статьи участки кода):
Если вы обратили внимание, в коде идет проверка на флаг O_NONBLOCK. Его можно выставить используя операцию F_SETFL в fcntl. Он отвечает за переход в режим без блокировки I/O потоков в конвеере. В этом режиме вместо блокировки процесс чтения/записи в поток будет завершаться с errno кодом EAGAIN.
Максимальный размер блока данных, который будет записан в конвейер, равен одной странице памяти (4Кб) для архитектуры arm:
arch/arm/include/asm/limits.h:
Для ядер >= 2.6.35 можно изменить размер буфера конвейера:
Максимально допустимый размер буфера, как мы видели выше, указан в файле /proc/sys/fs/pipe-max-size.
Tips & trics
Перенаправление и stdout, и stderr в pipe
или же можно использовать комбинацию символов ‘|&’ (о ней можно узнать как из документации к оболочке (man bash), так и из исходников выше, где мы разбирали Yacc парсер bash):
Перенаправление _только_ stderr в pipe
Shoot yourself in the foot
Важно соблюдать порядок перенаправления stdout и stderr. Например, комбинация ‘>/dev/null 2>&1′ перенаправит и stdout, и stderr в /dev/null.
Получение корректного кода завершения конвейра
По умолчанию, код завершения конвейера — код завершения последней команды в конвеере. Например, возьмем исходную команду, которая завершается с ненулевым кодом:
И поместим ее в pipe:
Теперь код завершения конвейера — это код завершения команды wc, т.е. 0.
Обычно же нам нужно знать, если в процессе выполнения конвейера произошла ошибка. Для этого следует выставить опцию pipefail, которая указывает оболочке, что код завершения конвейера будет совпадать с первым ненулевым кодом завершения одной из команд конвейера или же нулю в случае, если все команды завершились корректно:
Shoot yourself in the foot
Следует иметь в виду “безобидные” команды, которые могут вернуть не ноль. Это касается не только работы с конвейерами. Например, рассмотрим пример с grep:
Здесь мы печатаем все найденные строки, приписав ‘new_’ в начале каждой строки, либо не печатаем ничего, если ни одной строки нужного формата не нашлось. Проблема в том, что grep завершается с кодом 1, если не было найдено ни одного совпадения, поэтому если в нашем скрипте выставлена опция pipefail, этот пример завершится с кодом 1:
В больших скриптах со сложными конструкциями и длинными конвеерами можно упустить этот момент из виду, что может привести к некорректным результатам.
Pipes: Программные каналы в Linux
Статья из цикла HuMan
Выбор термина
Предисловие
Предлагаемая вашему вниманию статья как раз для тех, кто недавно открыл для себя командную строку Линукс.
Введение в программные каналы
Того же результата можно достичь, если сначала перенаправить вывод команды dmesg во временный файл, а затем просмотреть содержимое этого файла на экране монитора.
Очевидно, что такая схема менее производительна: во-первых, необходимо давать две команды, во-вторых потому, что следующая команда может начать работать только после завершения первой.
Необходимо пояснить понятия, которые я походя назвал «вводом» и «выводом» программы.
Любая программа командной оболочки (шелла) оперирует с тремя потоками данных: стандартным вводом (stdin), стандартным выводом (stdout), и стандартным сообщением об ошибке (stderr). (Подробно об этом можно прочесть в статье «Перенаправление стандартных потоков данных»).
Такая цепочка вовсе не ограничивается двумя программами, но может продолжаться сколь угодно долго.
Как это работает
Даже если посылающая программа производит 5000 байт в секунду, а принимающая программа может обработать только 100 байт в секунду, все равно никакой потери информации не произойдет, так как программные каналы имеют буферы. Вывод посылающей программы собирается в буфере, ставится в очередь. Когда принимающая программа готова считывать данные, операционная система посылает порцию данных из буфера. В случае переполнения буфера, посылающая программа приостанавливается (блокируется), до тех пор, пока принимающая программа не сможет снова считывать данные, тем самым освобождая буфер.
Механизм этого свойства командной оболочки довольно сложен, в данной статье мы не станем его рассматривать, а будем просто пользоваться этой замечательной способностью шелла.
Как пользоваться программными каналами
Для пробы проделайте такой пример:
Понятно, что найти «вручную» что-либо в таком списке проблематично, и тут на помощь снова придут программные каналы.
Команда grep найдет нужные вам строки, если вы зададите образец для поиска:
Команды, входящие в состав программных каналов, часто называются командами-фильтрами, так как они пропускают через себя потоки данных.
Среди команд-фильтров самая употребительная, без сомнения, grep. Она применяется везде, где нужно выбрать искомое из большого объема данных. Скажем, просмотреть все, что касается USB в выводе команды dmesg:
Чтобы найти в этом списке интересующие вас процессы, следует канализировать команду ps с командой grep. Допустим, вас интересуют процессы hald:
С таким коротким списком уже легче работать. (Обратите внимание на последнюю строчку, там представлен сам запущенный нами процесс grep hald ).
Другие распространенные команды-фильтры
В этот список я включил только несколько команд-фильтров, освоив которые, можно вдоволь насладиться составлением самых замысловатых программных каналов.
Сложные программные каналы
Примечание: Символ (\) используется для объединения всех шести строк в одну командную строку.
Команда первая: wget получает содержимое HTML web страницы.
Команда вторая: sed удаляет из текста страницы все символы, не являющиеся пробелами или буквами и заменяет их пробелами.
Команда третья: tr переводит все символы верхнего регистра в нижний регистр (заглавные буквы в строчные), а также конвертирует пробелы в строках в символы новой строки, так что теперь каждое «слово» является новой строкой.
Команда четвертая: grep оставляет только строки, содержащие хотя бы один алфавитный символ (попросту букву), удаляя все пустые строки.
Немного истории
Понятие именованного канала
В отличие от анонимного программного канала, автоматически создаваемого шеллом, именованный канал обладает именем, и создается явно при помощи команд mknod или mkfifo. Создадим именованный канал fifo1:
Теперь запустим процесс, обращающийся к данному каналу:
Несмотря на нажатие клавиши ENTER ничего не происходит, что не удивительно, ведь файл fifo1 пока пуст, и команде grep нечего обрабатывать. Однако консоль оказывается занята ждущим процессом, и разблокировать ее можно только прервав процесс (скажем, нажатием клавиш CTRL+c).
Чтобы наполнить именной канал содержимым, нужно чтобы к нему обратился второй процесс. Для этого мы должны открыть вторую консоль и запустить какую-либо команду, передающую данные в файл fifo1. Например:
Немедленно в первой консоли сработает команда grep:
Совершенно ясно, что пользоваться таким неудобным механизмом в пользовательских целях никто не будет, ведь гораздо проще запустить один программный канал:
и получить тот же результат.
Этот пример я привел лишь для демонстрации создания и работы именованного канала. Другое дело, когда именованные каналы создаются самими процессами для обмена информацией друг с другом. Но повторюсь, что тема эта непростая и в данной статье рассматриваться не будет.
Команда Pipe, Grep и Sort в Linux / Unix с примерами
Что такое пайп в Linux?
Pipe — это команда в Linux, которая позволяет вам использовать две или более команд, так что вывод одной команды служит вводом для следующей. Короче говоря, вывод каждого процесса непосредственно в качестве ввода для следующего, как конвейер.
Символ ‘|’ обозначает трубу.
Каналы помогают объединять две или более команд одновременно и запускать их последовательно. Вы можете использовать мощные команды, которые могут мгновенно выполнять сложные задачи.
Давайте разберемся в этом на примере.
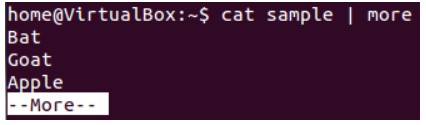
Когда вы используете команду cat для просмотра файла, который занимает несколько страниц, приглашение быстро переходит к последней странице файла, и вы не видите содержимое в середине.
Чтобы избежать этого, вы можете перенаправить вывод команды ‘cat’ в ‘less’, что покажет вам только одну длину прокрутки содержимого за раз.
cat filename | less
Иллюстрация прояснила бы это:

Команды ‘pg’ и ‘more’
Вместо «меньше» можно также использовать.
И вы можете просмотреть файл в удобоваримых битах и прокрутить вниз, просто нажав клавишу ввода.
Команда ‘grep’
Предположим, вы хотите найти конкретную информацию по почтовому индексу из текстового файла.
Вы можете вручную просмотреть содержимое, чтобы отследить информацию. Лучшим вариантом является использование команды grep. Он просканирует документ для получения необходимой информации и представит результат в желаемом формате.
Синтаксис:
Посмотрим на это в действии:
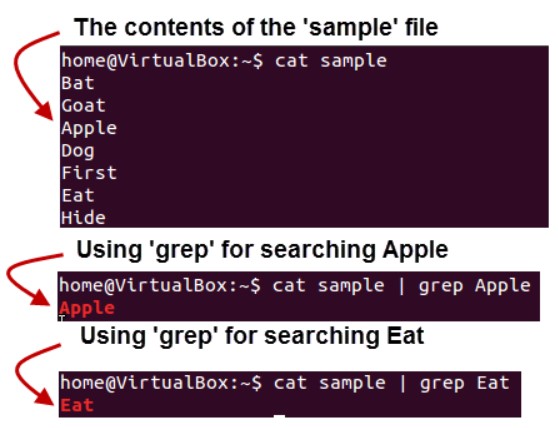
Здесь команда grep провела поиск в файле «sample» по строке «Apple» и «Eat».
С этой командой можно использовать следующие параметры.
| Вариант | Функция |
| -v | Показывает все строки, которые не соответствуют искомой строке |
| -c | Отображает только количество совпадающих строк |
| -n | Показывает соответствующую строку и ее номер |
| -i | Учитывать оба регистра (верхний и нижний) |
| -l | Показывает только имя файла со строкой |
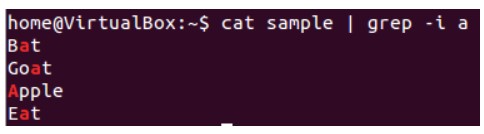
Давайте попробуем первый вариант ‘-i’ для того же файла, использованного выше —
Используя параметр «i», grep отфильтровал строку «a» (без учета регистра) из всех строк.
Команда sort
Эта команда помогает отсортировать содержимое файла по алфавиту.
Синтаксис этой команды:
Рассмотрим содержимое файла.
Использование команды сортировки
| Вариант | Функция |
| -р | Обратная сортировка |
| -n | Сортировка численно |
| -f | Сортировка без учета регистра |
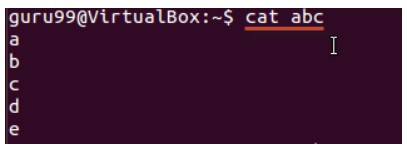
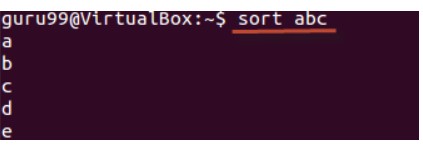
Пример ниже показывает обратную сортировку содержимого в файле «abc».
Linux / Unix конвейеры, команда Grep & Sort
Что такое фильтр?
В Linux есть множество команд фильтрации, таких как awk, grep, sed, spell и wc. Фильтр принимает входные данные от одной команды, выполняет некоторую обработку и выдает выходные данные.
Когда вы передаете две команды по конвейеру, «отфильтрованный» вывод первой команды передается следующей.
Давайте разберемся в этом на примере.
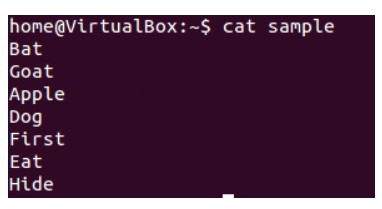
У нас есть следующий файл ‘sample’
Мы хотим выделить только те строки, которые не содержат символа «а», но результат должен быть в обратном порядке.
Для этого можно использовать следующий синтаксис.
Pipes: Программные каналы в Linux
Содержание
Предисловие
Предлагаемая вашему вниманию статья как раз для тех, кто недавно открыл для себя командную строку Линукс.
Выбор термина
Термин pipe (труба) чрезвычайно органично вошел в англоязычный компьютерный жаргон. Этим словом называется не только способ передачи вывода одной команды на ввод другой, но и оператор, которым обозначается это действие: | (вертикальная черта). Кроме того, то же слово служит глаголом, означающим данное действие.
Введение в программные каналы
Программным каналом называется использование вывода одной команды в качестве ввода для другой программы. Например:
Того же результата можно достичь, если сначала перенаправить вывод команды dmesg во временный файл, а затем просмотреть содержимое этого файла на экране монитора.
Очевидно, что такая схема менее производительна: во-первых, необходимо давать две команды, во-вторых потому, что следующая команда может начать работать только после завершения первой.
Необходимо пояснить понятия, которые я походя назвал «вводом» и «выводом» программы.
Любая программа командной оболочки (шелла) оперирует с тремя потоками данных: стандартным вводом (stdin), стандартным выводом (stdout), и стандартным сообщением об ошибке (stderr). (Подробно об этом можно прочесть в статье «Перенаправление стандартных потоков данных»).
Такая цепочка вовсе не ограничивается двумя программами, но может продолжаться сколь угодно долго.
Как это работает
В большинстве Юниксовидных систем все процессы в программном канале начинаются одновременно, их потоки соответственно соединяются и управляются планировщиком вместе со всеми остальными процессами, идущими в системе.
Даже если посылающая программа производит 5000 байт в секунду, а принимающая программа может обработать только 100 байт в секунду, все равно никакой потери информации не произойдет, так как программные каналы имеют буферы. Вывод посылающей программы собирается в буфере, ставится в очередь. Когда принимающая программа готова считывать данные, операционная система посылает порцию данных из буфера. В случае переполнения буфера, посылающая программа приостанавливается (блокируется), до тех пор, пока принимающая программа не сможет снова считывать данные, тем самым освобождая буфер.
Механизм этого свойства командной оболочки довольно сложен, в данной статье мы не станем его рассматривать, а будем просто пользоваться этой замечательной способностью шелла.
Как пользоваться программными каналами
Чаще всего употребляются программные каналы, заканчивающиеся командами less и more. Эти две команды схожи по своему действию, однако less новее и имеет ряд дополнительных функций, включая возможность вернуться к предыдущим «страницам» вывода. Многие пользуются этими программными каналами, не подозревая, что занимаются столь мудреными вещами.
Для пробы проделайте такой пример:
Понятно, что найти «вручную» что-либо в таком списке проблематично, и тут на помощь снова придут программные каналы.
Команда grep найдет нужные вам строки, если вы зададите образец для поиска:
Команды, входящие в состав программных каналов, часто называются командами-фильтрами, так как они пропускают через себя потоки данных.
Среди команд-фильтров самая употребительная, без сомнения, grep. Она применяется везде, где нужно выбрать искомое из большого объема данных. Скажем, просмотреть все, что касается USB в выводе команды dmesg:
Чтобы найти в этом списке интересующие вас процессы, следует канализировать команду ps с командой grep. Допустим, вас интересуют процессы hald:
С таким коротким списком уже легче работать. (Обратите внимание на последнюю строчку, там представлен сам запущенный нами процесс grep hald).
Другие распространенные команды-фильтры
Кроме команды grep (или вместе с ней) часто употребляются следующие команды:
В этот список я включил только несколько команд-фильтров, освоив которые, можно вдоволь насладиться составлением самых замысловатых программных каналов.
Сложные программные каналы
Примечание: Символ (\) используется для объединения всех шести строк в одну командную строку.
Команда первая: wget получает содержимое HTML web страницы.
Команда вторая: sed удаляет из текста страницы все символы, не являющиеся пробелами или буквами и заменяет их пробелами.
Команда третья: tr переводит все символы верхнего регистра в нижний регистр (заглавные буквы в строчные), а также конвертирует пробелы в строках в символы новой строки, так что теперь каждое «слово» является новой строкой.
Команда четвертая: grep оставляет только строки, содержащие хотя бы один алфавитный символ (попросту букву), удаляя все пустые строки.
Немного истории
Идею программных каналов и значок вертикальной черты как их обозначение придумал Douglas McIlroy, один из авторов ранних командных оболочек. Он обратил внимание на то, сколько времени уходит на обработку вывода одной программы в качестве ввода другой. Его идеи были внедрены в жизнь, когда в 1973 Ken Thompson добавил программные каналы в операционную систему Юникс. Идея была со временем позаимствована другими ОС, такими как DOS, OS/2, Microsoft Windows, и BeOS, часто даже с тем же обозначением.
Понятие именованного канала
В отличие от анонимного программного канала, автоматически создаваемого шеллом, именованный канал обладает именем, и создается явно при помощи команд mknod или mkfifo. Создадим именованный канал fifo1:
Теперь запустим процесс, обращающийся к данному каналу:
Несмотря на нажатие клавиши ENTER ничего не происходит, что не удивительно, ведь файл fifo1 пока пуст, и команде grep нечего обрабатывать. Однако консоль оказывается занята ждущим процессом, и разблокировать ее можно только прервав процесс (скажем, нажатием клавиш CTRL+c).
Чтобы наполнить именной канал содержимым, нужно чтобы к нему обратился второй процесс. Для этого мы должны открыть вторую консоль и запустить какую-либо команду, передающую данные в файл fifo1. Например:
Немедленно в первой консоли сработает команда grep:
Совершенно ясно, что пользоваться таким неудобным механизмом в пользовательских целях никто не будет, ведь гораздо проще запустить один программный канал:
и получить тот же результат.
Этот пример я привел лишь для демонстрации создания и работы именованного канала. Другое дело, когда именованные каналы создаются самими процессами для обмена информацией друг с другом. Но повторюсь, что тема эта непростая и в данной статье рассматриваться не будет.
Резюме
Каналы (pipe,fifo)
Можно представить себе канал как небольшой кольцевой буфер в ядре операционной системы. С точки зрения процессов, канал выглядит как пара открытых файловых дескрипторов – один на чтение и один на запись (можно больше, но неудобно). Мы можем писать в канал до тех пор пока есть место в буфере, если место в буфере кончится – процесс будет заблокирован на записи. Можем читать из канала пока есть данные в буфере, если данных нет – процесс будет заблокирован на чтении. Если закрыть дескриптор отвечающий за запись, то попытка чтения покажет конец файла. Если закрыть дескриптор отвечающий за чтение, то попытка записи приведет к доставке сигнала SIGPIPE и ошибке EPIPE.
При использовании канала в программировании на языке shell
блокировки чтения/записи обеспечивают синхронизацию скорости выполнения двух программ и их одновременное завершение.
Понятия позиции чтения/записи для каналов не существует, поэтому запись всегда производится в хвост буфера, а чтение с головы.
Неименованные каналы
Неименованный канал создается вызовом pipe, который заносит в массив int [2] два дескриптора открытых файлов. fd[0] – открыт на чтение, fd[1] – на запись (вспомните STDIN == 0, STDOUT == 1). Канал уничтожается, когда будут закрыты все файловые дескрипторы ссылающиеся на него.
Оставлять оба дескриптора незакрытыми плохо по двум причинам:
Родитель после записи не может узнать считал ли дочерний процесс данные, а если считал то сколько. Соответственно, если родитель попробует читать из pipe, то, вполне вероятно, он считает часть собственных данных, которые станут недоступными для потомка.
Если один из процессов завершился или закрыл свои дескрипторы, то второй этого не заметит, так как pipe на его стороне по-прежнему открыт на чтение и на запись.
Если надо организовать двунаправленную передачу данных, то можно создать два pipe.
Именованные каналы
Именованный канал FIFO доступен как объект в файловой системе. При этом, до открытия объекта FIFO на чтение, собственно коммуникационного объекта не создаётся. После открытия открытия объекта FIFO в одном процессе на чтение, а в другом на запись, возникает ситуация полностью эквивалентная использованию неименованного канала.
Правила обмена через канал
При обмене данными через канал существуют два особых случая:
Первый случай интерпретируется как конец файла и вызов read вернёт 0. Второй случай не имеет аналогов при работе с обычными файлами, а потому вызывает доставку сигнала SIGPIPE. Программы-фильтры, которые работают с STDOUT по сигналу SIGPIPE обычно завершают работу. Если программа расcчитана на работу с каналами, то для корректной обработки этой ситуации она должна явно изменить стандартный обработчик SIGPIPE, установив его в игнорирование сигнала или переназначив на свою функцию.
Для защиты от этих особых случаев при открытии именованного канала FIFO вызов open() на чтение или на запись блокируется, пока кто-нибудь не откроет канал с другой стороны. Если открывать FIFO с опцией O_NONBLOCK, то одиночное открытие на чтение пройдёт успешно, а попытка открыть на запись FIFO без читателей вернёт ошибку ENXIO (устройство не существует). Открытие FIFO одновременно на чтение и на запись в POSIX не определено. В Linux такой вариант сработает и в блокирующем и в неблокирующем режимах.