
Простая модель планировщика ОС
Не так давно пытался найти здесь какую-нибудь информацию о планировщике Windows и к своему удивлению не нашёл ничего конкретного о планировщиках вообще, поэтому решил запостить вот этот пример планировщика, надеюсь кому-то он окажется полезен. Код написан на Turbo Pascal со вставками ассемблера 8086.
Что собственно планирует планировщик?
Алгоритмы планирования
Критические секции
C процессорным временем или стеком вроде бы всё просто, а что если потоку требуется например напечатать на принтере котёнка? А что если таких потоков два? При невытесняющей многозадачности всё пройдёт как по маслу: один поток отпечатает котёнка, завершится и отдаст управление планировщику, который позволит печатать второму потоку. Но если многозадачность вытесняющая, планировщик может переключить потоки в момент, когда те ещё не завершили печать и получится что-то вроде этого: 
Чтобы такого не происходило вводится механизм критических секций. Поток, которой хочет занять некий неразделяемый ресурс, сообщает об этом планировщику. Если ресурс ещё не занят другим потоком — планировщик разрешает потоку продолжить работу, а сам помечает ресурс, как занятый. Если же ресурс занят — поток помещается в очередь, где он ожидает, когда тот освободится. По завершении работы с таким ресурсом поток должен сообщить планировщику о том что ресурс теперь могут использовать другие потоки. Эти два действия: попытка захватить ресурс и сообщение о прекращении работы с ним называются критическими скобками. Кстати при неумелой их расстановке может возникнуть ситуация взаимной блокировки потоков, которая не всегда хорошо и быстро диагностируется и может вызвать неиллюзорный батхёрт у разработчика и пользователя уже после релиза продукта.
Взаимная блокировка
Допустим у нас есть неразделяемые ресурсы А и Б и потоки Х, Y, которые хотят задействовать эти ресурсы. Если некий криворукий недостаточно компетентный программист расставит критические скобки вот так:
…
Поток X
Занять Ресурс(А)
Занять Ресурс(Б)
…
Отдать Ресурс(А)
Отдать Ресурс(Б)
Поток Y
Занять Ресурс(Б)
Занять Ресурс(А)
…
Отдать Ресурс(Б)
Отдать Ресурс(А)
через некоторое время возникнет вот такая ситуация: 
Сладенькое
Ну и собственно то ради чего это всё писалось. Как уже было сказано код нашего планировщика будет выполнен на языке Turbo Pascal.
Механизм критических секций реализован в процедурах EnterCritical(), LeaveCritical(). Вспомним ещё раз: чтобы войти в критическую секцию — нужно проверить не занята ли она, и по результату — либо занять её и разрешить потоку ей пользоваться, либо поставить поток в очередь и передать управление кому-то другому.
C LeaveCritical() вроде бы и так всё ясно:
Сама процедура переключения потоков написана с использованием ассемблерных вставок, поэтому можно увидеть момент переключения потоков от одного к другому с точностью до машинной команды:
Сама процедура скомпилирована с директивой interrupt, то есть является обработчиком прерывания. Которое может быть спровоцировано как аппаратно, так и программно вызовом int 08h, вот так:
Так же необходимо описать сами процедуры регистрации, включения и остановки потоков. Если кому-то интересно — можно посмотреть в исходниках процедуры RegistrThread, RunThread, StopThread.
Вот и всё! Наш планировщик готов.
Исходники вместе примером многопоточной программы написаной под этот планировщих и досовским турбиком можно скачать здесь. Можно поиграться и посмотреть как по разному будут выполняться потоки при вытесняющей и невытесняющей многозадачности (процедура ExecuteRegisterThreads(true/false)), смоделировать ситуацию взаимной блокировки и убедиться в том, что она не всегда диагностируема (я однажды минуту ждал пока возникнет дедлок).
Запускать в системах новее Win98 советую из под DOSbox.
Простой планировщик задач на PHP
В процессе эволюции более-менее крупного проекта может настать ситуация, когда количество запланированных задач (cron jobs) становится настолько большим, что поддержка их становится ночным кошмаром devops’ов. Для решения этой проблемы мне пришла в голову идея создать реализацию планировщика на PHP, тем самым сделав его частью проекта, а сами задачи — частью его конфигурации. В этом случае необходимое и достаточное количество cron jobs будет равно единице.
Некоторое время назад мне довелось разрабатывать модуль для планирования событий. Некое упрощенное подобие Google/Apple Calendar для пользователей приложения. Для хранения дат и правил повторения событий было решено использовать формат iCalendar (RFC 5545), позволяющий одной строкой описать график повторения какого-либо события с учетом дней недели, месяцев, количества повторений и многого другого. Несколько примеров:
FREQ=WEEKLY;BYDAY=SU,WE — Еженедельно в субботу и среду
FREQ=MONTHLY;COUNT=5 — Каждый месяц, пять раз
FREQ=YEARLY;INTERVAL=2;BYMONTH=1;BYDAY=SU — Каждый второй год в каждую субботу января
Как видите данный стандарт позволяет описать правила повторения события гораздо более гибко, чем предлагает cron.
Для работы с форматом iCalendar была найдена замечательная библиотека (не пожалейте звезду):
https://github.com/simshaun/recurr
Имея инструмент для работы с RRULE (Recurrence Rule) дело осталось за малым. Написать несколько классов, позволяющих планировать и запускать задачи (являющиеся каким угодно проявлением PHP callable типа).
Установка библиотеки:
composer require hutnikau/job-scheduler
Планирование и запуск задач:
\Scheduler\Job\Job — Класс, представляющий задачу
Для создания его экземпляра потребуется правило его повторения (RRULE) и экземпляр типа callable :
Альтернативный вариант — использовать \Scheduler\Job\Job::createFromString() :
Не забывайте о временных зонах. Настоятельно советую всегда указывать их явно (не только при работе с этой библиотекой, а с \DateTime в целом) во избежание неприятных сюрпризов.
Добавляем задачу в планировщик:
Так же можно передать массив задач в конструктор:
Запускаем запланированные задачи:
Последний параметр определяет, будут ли выполнены задачи, время выполнения которых попало точно на пограничные значения (‘2017-12-12 20:00:00’ и ‘2017-12-12 20:10:00’ из примера выше).
$jobRunner->run(. ) возвращает массив результатов выполненных задач (массив объектов типа \Scheduler\Action\Report ).
Вызвав \Scheduler\Action\Report::getReport() можно получить результат выполнения callable (возвращенное им значение).
В случае, если при выполнении задачи было брошено исключение, \Scheduler\Action\Report::getReport() вернет то самое исключение.
Вот, пожалуй, и все. Библиотека действительно мала, но надеюсь окажется кому-либо полезной.
Конструктивная критика и помощь в развитии приветствуются.
Что такое Core Scheduling и кому он будет полезен?

Не за горами выход новой версии ядра Linux 5.14. За последние несколько лет это обновление ядра является самым многообещающим и одно из самых крупных. Была улучшена производительность, исправлены ошибки, добавлен новый функционал. Одной из новых функций ядра стал Core Scheduling, которому посвящена наша статья. Это нововведение горячо обсуждали в интернете последние несколько лет, и наконец-то оно было принято в ядро Linux 5.14.
Если вы работаете с Linux или занимаетесь информационной безопасностью, вам интересны новые технологии, то добро пожаловать под кат.
▍Введение
Для того чтобы понять Core Scheduling и для чего он нужен, стоит разобраться, как работают многозадачные системы, и как они развивались.
На современных компьютерах одновременно могут работать сотни, а то и тысячи программ одновременно. Монопольный доступ к процессору и памяти остались в прошлом, и на данный момент практически нигде не используется кроме микроконтроллеров и RT(Real Time) задач.
Изначально все процессоры были одноядерными, и могли выполнять только одну задачу одновременно. Практически сразу появилась необходимость выполнять несколько задач одновременно на одноядерном процессоре. Для этого был придуман scheduler, он же планировщик в операционных системах, который занимается переключением задач и управляет ресурсами компьютера. Ядро операционной системы всегда работает с большими привилегиями, чем пользовательские программы, такой режим работы называют Ring 0. Поэтому планировщик может в любой момент приостанавливать выполнение одной задачи и перейти к выполнению следующей. В нём существует специальная очередь задач, в которую добавляются все работающие программы и обработчики ядра, например, обработчик прерываний. Изначально эта очередь была простая, как очередь в магазине, и каждая программа выполнялась по очереди, как бы подходя к кассе в магазине. Каждая задача, после того, как выполнила свою работу, должна была явно уведомить планировщик, что задача завершила свою работу и планировщик может переключиться на следующую задачу. Такую очередь называют FIFO — First In First Out первым пришёл, первым ушёл. А такую многозадачность называют совместной или кооперативной многозадачностью.

Со временем системы стали многоядерными и имели количество потоков выполнения — равное количеству ядер процессора или количеству процессоров, в случае с одноядерными процессорами, что, в свою очередь, повысило возможности компьютеров и количество выполняемых задач одновременно. Чтобы уменьшить накладные расходы переключения задач в ОС, разработчики процессоров придумали простое и элегантное решение, переложили часть функций на процессор. Так были придуманы Intel Hyper-Threading (Intel HT) и AMD Simultaneous Multithreading (AMD SMT).
Технологии очень простые: Теперь вместо реальных ядер процессор начал показывать виртуальные ядра в количестве реальных ядер умноженных на 2. Процессоры с 1 ядром начали иметь 2 виртуальных процессора (2 потока выполнения), которые видит ОС. Теперь в процессоре, имея два потока выполнения на каждое ядро, ядро процессора может не простаивать, когда один из потоков спит, а переключится на второй поток. Тем самым процессор будет переключаться между потоками с минимальными задержками, и по максимуму использовать возможности каждого ядра.
Как работают Intel HT и AMD SMT можно понять по картинкам ниже. Первая картинка показывает, как занята очередь процессора при выполнении двух задач, а на второй картинке показана временная диаграмма, и что в случае с Intel HT и AMD SMT на обе задачи суммарно было потрачено меньше времени.


На самом деле, в некоторых случаях это решение является очень спорным и не даёт какого-либо выигрыша производительности. Но в некоторых задачах всё же есть заметный выигрыш, например, в виртуализации. Ничего не предвещало беды, но, как говорится, беда подкралась неожиданно…
Долгое время никто не замечал главной проблемы этой технологии. Все потоки используют одни и те же кэши и аппаратные возможности процессора. Это открыло уязвимость, что один процесс может извлекать данные, наблюдая за изменениями кэша другим процессом. Только с ростом потребностей бизнеса и популяризации виртуализации, такая уязвимость стала чаще обсуждаться. Единственным способом безопасно запускать два процесса не доверяющих друг-другу стало отключение Intel HT и AMD SMT. С появлением уязвимостей класса Spectre данная проблема ещё больше усугубилась и поставила облачных провайдеров перед очень тяжелым выбором: отключить Intel HT и AMD SMT? И даже вызывало сильное раздражение, так как клиенты — бизнес требуют безопасности их данных. Но что же это для них значило? Конечно же, увеличение затрат и миллионные потери прибыли. Если при наличии Intel HT и AMD SMT они могли иметь больше клиентов чем ядер, и клиенты могли балансироваться между ядрами и выравнивать нагрузку на процессор, то теперь все облачные технологии готовы были заключить в жесткие рамки количества реальных ядер. И тут облачные провайдеры задумались не на шутку, как сделать так чтобы оставить включенными Intel HT и AMD SMT, сделать данные клиента безопаснее, например, закрытые ключи шифрования и пароли. Так появился на свет Core Scheduling, который безопасно может выполнять потоки.
▍Core Scheduling

Для управления процессами или потоками используется системный вызов prctl:
В случае с Core Scheduling системный вызов принимает вид:
Где PR_SCHED_CORE говорит, что это операция с Core Scheduling, command это команда которую надо выполнить, pid process id — цифровой идентификатор процесса, pid_type тип pid, cookie — беззнаковое 32 битное число метки.
Для работы с Core Scheduling существует 4 команды:
К сожалению первые версии Core Scheduling имели большой недостаток — высокие накладные расходы, падала производительность системы т.к. в некоторые моменты времени Core Scheduling заставлял процессор бездействовать, что в итоге стало ещё хуже чем отключение Intel HT и AMD SMT. Но со временем удалось улучшить алгоритм и решать большую часть проблем, но всё же не бесплатно. Поэтому Core Scheduling не подходит каждому т.к. немного снижает производительность системы, а только тем, кому очень важна безопасность, например облачным провайдерам. Так же Core Scheduling не подходит задачам которым важна скорость реакции, так называемые Real Time задачи, для них вовсе рекомендуется отключить Intel Hyper-Threading(Intel HT) и AMD SMT.
Как можно понять из статьи не бывает ложки меда без капли дегтя. Но развитие технологий идет и старые проблемы решаются, хоть не всё всегда идеально. Изначально Core Scheduling был протестирован мною на ядре 5.13-rc с патчами, и в принципе в нём не сложно включить Core Scheduling, но в одном из обновлений ядра 5.13 перестали работать патчи, и их надо было много править, что не имело уже большого смысла для меня и ядро 5.14 уже было более интересно для изучения. Мой актуальный набор патчей для ядра вы всегда можете скачать по ссылке, там всегда актуальные и стабильные патчи, которые не влияют на стабильность системы, но приносят ряд улучшений.
Моя прошлая статья LTO оптимизация ядра Linux вызвала у читателей много вопросов. Было много доброжелателей, которые мне писали лично и благодарили. Были и такие которые писали, чтобы поругаться и даже катали жалобы на мои проекты. Конечно же доброжелателей было значительно больше. Поэтому дам краткий ответ на частые вопросы:
При подготовке статьи использовалась переписка разработчиков ядра Linux — Linux Kernel Mailing List.
Уважаемые читатели, спасибо за прочтение. Так как ваше мнение очень важно, вы можете оставить свои замечания по статье в комментариях. Тем самым вы поможете сделать контент для вас более качественным и интересным.
4.1 Основные понятия планирования процессов
Ситуации, когда необходимо планирование:
Когда создается процесс
Когда процесс завершает работу
Когда процесс блокируется на операции ввода/вывода, семафоре, и т.д.
При прерывании ввода/вывода.
Необходимость алгоритма планирования зависит от задач, для которых будет использоваться операционная система.
Основные три системы:
Задачи алгоритмов планирования:
4.2 Планирование в системах пакетной обработки
Процессы ставятся в очередь по мере поступления.
Справедливость (как в очереди покупателей, кто последний пришел, тот оказался в конце очереди)
Процесс, ограниченный возможностями процессора может затормозить более быстрые процессы, ограниченные устройствами ввода/вывода.

Нижняя очередь выстроена с учетом этого алгоритма
Уменьшение оборотного времени
Справедливость (как в очереди покупателей, кто без сдачи проходит в перед)
Длинный процесс занявший процессор, не пустит более новые краткие процессы, которые пришли позже.
4.2.3 Наименьшее оставшееся время выполнение
Аналог предыдущего, но если приходит новый процесс, его полное время выполнения сравнивается с оставшимся временем выполнения текущего процесса.
4.3 Планирование в интерактивных системах
4.3.1 Циклическое планирование
Самый простой алгоритм планирования и часто используемый.
Каждому процессу предоставляется квант времени процессора. Когда квант заканчивается процесс переводится планировщиком в конец очереди. При блокировке процессор выпадает из очереди.

Пример циклического планирования
Справедливость (как в очереди покупателей, каждому только по килограмму)
4.3.2 Приоритетное планирование
Каждому процессу присваивается приоритет, и управление передается процессу с самым высоким приоритетом.
Приоритет может быть динамический и статический.
Динамический приоритет может устанавливаться так:
П=1/Т, где Т- часть использованного в последний раз кванта
Если использовано 1/50 кванта, то приоритет 50.
Если использован весь квант, то приоритет 1.
Т.е. процессы, ограниченные вводом/вывода, будут иметь приоритет над процессами ограниченными процессором.
Часто процессы объединяют по приоритетам в группы, и используют приоритетное планирование среди групп, но внутри группы используют циклическое планирование.

Приоритетное планирование 4-х групп
4.3.3 Методы разделения процессов на группы
Группы с разным квантом времени
Сначала процесс попадает в группу с наибольшим приоритетом и наименьшим квантом времени, если он использует весь квант, то попадает во вторую группу и т.д. Самые длинные процессы оказываются в группе наименьшего приоритета и наибольшего кванта времени.

Процесс либо заканчивает работу, либо переходит в другую группу
Группы с разным назначением процессов

Процесс, отвечающий на запрос, переходит в группу с наивысшим приоритетом.
Такой механизм позволяет повысить приоритет работы с клиентом.
В системе с n-процессами, каждому процессу будет предоставлено 1/n времени процессора.
Процессам раздаются «лотерейные билеты» на доступ к ресурсам. Планировщик может выбрать любой билет, случайным образом. Чем больше билетов у процесса, тем больше у него шансов захватить ресурс.
Процессорное время распределяется среди пользователей, а не процессов. Это справедливо если у одного пользователя несколько процессов, а у другого один.
4.4 Планирование в системах реального времени
Системы реального времени делятся на:
Внешние события, на которые система должна реагировать, делятся:
Что бы систему реального времени можно было планировать, нужно чтобы выполнялось условие:

Т.е. перегруженная система реального времени является не планируемой.
4.4.1 Планирование однородных процессов
В качестве однородных процессов можно рассмотреть видео сервер с несколькими видео потоками (несколько пользователей смотрят фильм).
Т.к. все процессы важны, можно использовать циклическое планирование.
Но так как количество пользователей и размеры кадров могут меняться, для реальных систем он не подходит.
4.4.2 Общее планирование реального времени
Используется модель, когда каждый процесс борется за процессор со своим заданием и графиком его выполнения.
Планировщик должен знать:
частоту, с которой должен работать каждый процесс
объем работ, который ему предстоит выполнить
ближайший срок выполнения очередной порции задания
Рассмотрим пример из трех процессов.
Процесс А запускается каждые 30мс, обработка кадра 10мс
Процесс В частота 25 кадров, т.е. каждые 40мс, обработка кадра 15мс
Процесс С частота 20 кадров, т.е. каждые 50мс, обработка кадра 5мс

Три периодических процесса
Проверяем, можно ли планировать эти процессы.
10/30+15/40+5/50=0.808 4.4.3 Статический алгоритм планирования RMS (Rate Monotonic Scheduling)
Процессы должны удовлетворять условиям:
Процесс должен быть завершен за время его периода
Один процесс не должен зависеть от другого
Каждому процессу требуется одинаковое процессорное время на каждом интервале
У непериодических процессов нет жестких сроков
Прерывание процесса происходит мгновенно
Приоритет в этом алгоритме пропорционален частоте.
Процессу А он равен 33 (частота кадров)
Процессу В он равен 25
Процессу С он равен 20
Процессы выполняются по приоритету.

Статический алгоритм планирования RMS (Rate Monotonic Scheduling)
4.4.4 Динамический алгоритм планирования EDF (Earliest Deadline First)
Наибольший приоритет выставляется процессу, у которого осталось наименьшее время выполнения.
При больших загрузках системы EDF имеет преимущества.
Проверяем, можно ли планировать эти процессы.
Что умеет планировщик заданий в Postgres Pro
Планировщик заданий (scheduler) не во все времена считался обязательным инструментом в мире баз данных. Все зависело от назначения и происхождения СУБД. Классические коммерческие СУБД (Oracle, DB2, MS SQL) представить себе без планировщика решительно невозможно. С другой стороны, трудно вообразить потенциального пользователя MongoDB, который откажется от выбора этой модной NoSQL-СУБД из-за отсутствия планировщика. (Кстати, термин «планировщик заданий» в русском контексте СУБД употребляют, чтобы отличить его от планировщика запросов — query planner, мы же для краткости будем звать его здесь планировщиком).
PostgreSQL, будучи Open Source и впитав традиции сообщества с образом жизни DIY («сделай сам»), в наше время регулярно претендует на место как минимум заместителя коммерческой СУБД. Из этого автоматически следует, что PostgreSQL просто обязана иметь планировщик, и что этот планировщик должен быть удобен для администратора базы и для пользователя. И что желательно воспроизвести полностью функциональные возможности коммерческих СУБД, хотя неплохо было бы и добавить что-то свое.
Необходимость в планировщике очевиднее всего проявляется при работе с базой в промышленной эксплуатации. Разработчику, которому выделили сервер для экспериментов с БД, планировщик, в общем-то и ни к чему: если нужно, он сам, средствами ОС (cron или at в Unix) распланирует все необходимые операции. Но к рабочей базе его в серьезной фирме не подпустят на пушечный выстрел. Есть и важный административный нюанс, то есть уже не нюанс, а серьезная, если не решающая причина: администратор базы данных и сисадмин не просто разные люди с разными задачами. Не исключено, что они принадлежат к разным подразделениям компании, и, может быть, даже сидят на разных этажах. В идеале администратор базы поддерживает ее жизнеспособность и следит за ее эволюцией, а зона ответственности сисадмина — жизнеспособность ОС и сети.
Следовательно, у администратора базы должен быть инструмент для выполнения необходимого набора возможных работ на сервере. Недаром в материалах о планировщике Oracle сказано, что «Oracle Scheduler отменяет необходимость использовать специфичные для разных платформ планировщики заданий ОС (cron, at) при построении БД-центричного приложения». То есть админ базы может всё, тем более, что трудно себе представить админа Oracle, не ориентирующегося в механизмах ОС. Ему не надо каждый раз бежать к сисадмину или писать ему письма, когда требуются рутинные операции средствами ОС.
Вот требования к планировщику, типичные для коммерческих СУБД, таких как Oracle, DB2, MS SQL:
Планировщик должен уметь
PostgreSQL и его агент
Решать поставленные задачи можно по-разному: «вне» и «внутри» самой СУБД. Самая серьезная попытка сделать полнофункциональный планировщик — это pgAgent, распространяемый вместе с pgAdmin III/IV. В коммерческом варианте — в дистрибутиве EnterpriseDB — он интегрирован в графический интерфейс pgAdmin и может использоваться кроссплатформенно.
У такого подхода есть недостатки. Среди них важные:
Все задания, запущенные pgAgent, будут исполняться с правами пользователя, запустившего агента. SQL-запросы будут исполняться с правами пользователя, соединившегося с базой. Скрипты shell будут исполняться с правами пользователя, от имени которого запущен демон (или сервис в Windows) pgAgent. Поэтому для безопасности придется контролировать пользователей, которые могут создавать и запускать задания. Кроме того, пароль нельзя включать в строку конфигурации соединения (connection string), так как в Unix он будет виден в выводе команды ps и в скрипте старта БД, а в Windows будет хранится в реестре как незашифрованный текст.
(из документации pgAdmin 4 1.6).
В этом решении pgAgent через заданные промежутки времени опрашивает сервер базы (поскольку информация о работах хранится в таблицах базы): нет ли в наличии работ. Поэтому, если по каким-то причинам агент не будет работать в момент, когда работа должна запуститься, она не запустится до тех пор, пока агент не заработает.
К тому же любое подключение к серверу расходует пул возможных соединений, максимальное количество которых определяется конфигурационным параметром max_connections. Если агент порождает много процессов, а администратор не проявил должную бдительность, это может стать проблемой.
Создание планировщика целиком интегрированного в СУБД («внутри» СУБД) избавляет от этих проблем. И особенно удобно это тем пользователям, которые привыкли к минималистским интерфейсам для обращения к базе, таким как psql.
pgpro_scheduler и его расписание
В конце 2016 года в компании Postgres Professional приступили к созданию собственного планировщика, полностью интегрированного в СУБД. Сейчас он используется заказчиками и подробно документирован. Планировщик был создан как расширение (дополнительный модуль), получил название pgpro_scheduler и поставляется в составе коммерческой версии Postgres Pro Enterprise начиная с первой же ее версии. Разработчик — Владимир Ершов.
С самого начала решено было создавать pgpro_scheduler в современном стиле, органичном для компании — с записью конфигурации в JSON. Это удобно, например, для создателей Web-сервисов, которые смогут интегрировать планировщик в свои приложения. Но для не желающих использовать JSON, есть функции, принимающие параметры в виде обычных переменных. Планировщик поставляется вместе с дистрибутивом СУБД и он кросс-платформенный.
pgpro_scheduler не запускает внешних демонов или сервисов, а создает дочерние по отношению к postmaster процессы background worker — фоновые процессы. Количество «рабочих» задается в конфигурации pgpro_scheduler, но ограничивается общей конфигурацией сервера. На вход планировщика фактически поступают самые обычные команды SQL, без всяких ограничений, поэтому можно запускать функции на любых доступных Postgres языках. Если в структуру JSON входит несколько SQL-запросов, то они могут (при следовании определенному синтаксису) исполняться внутри единой транзакции:
SELECT schedule.create_job( ‘<"commands": [ "SELECT 1", "SELECT 2", "SELECT 3" ], "cron": "23 23 */2 * *" >‘ ); — то есть без последнего параметра, по умолчанию.
Допустим, во второй по списку команде произойдет ошибка (конечно, в SELECT 2 она произойдет вряд ли, но вообразим себе какой-нибудь «стремный» запрос). В случае исполнения в одной транзакции все результаты откатятся, но в логе планировщика появится сообщение о крахе второй команды. То же сообщение появится и в случае исполнения раздельных транзакций, но результат первой будет сохранен (третья транзакция не будет исполнена).
При запуске pgpro_scheduler всегда приступает к работе группа фоновых процессов-рабочих (background workers) со своей иерархией: один рабочий, в чине супервизора планировщика, контролирует рабочих в чине менеджеров баз данных — по одному на каждую базу данных, прописанную в строке конфигурации. Менеджеры, в свою очередь, контролируют рабочих, непосредственно обслуживающих задания. Супервизор и менеджеры довольно легкие процессы, поэтому если планировщик обслуживают даже десятки баз, это не сказывается на общей загрузке системы. И далее рабочие запускаются в каждой базе по потребностям в обработке запросов. В сумме они должны укладываться в ограничение СУБД max_worker_processes. Группа команд для мгновенного исполнения заданий пользуется ресурсами по-другому, но об этом позже.

Рис.1 Основной режим работы pgpro_scheduler
pgpro_scheduler это расширение (extension) Postgres. Следовательно, оно устанавливается на конкретную базу данных. При этом создается несколько системных таблиц в схеме schedule, по умолчанию они не видны пользователю. База данных знает теперь 2 новых, специальных типа данных: cron_rec и cron_job, с которыми можно будет работать через SQL-запросы. Есть таблица-лог, которая не дублирует журнал СУБД. Информация об успешной или неуспешной работе заданий планировщика доступна только через функции расширения pgpro_scheduler. Это сделано для того, чтобы один пользователь планировщика не знал о деятельности другого пользователя планировщика. Функции дают возможность избирательного просмотра лога, начиная с определенной даты, например:
Этот объект может содержать следующие ключи, некоторые из которых могут быть опущены:
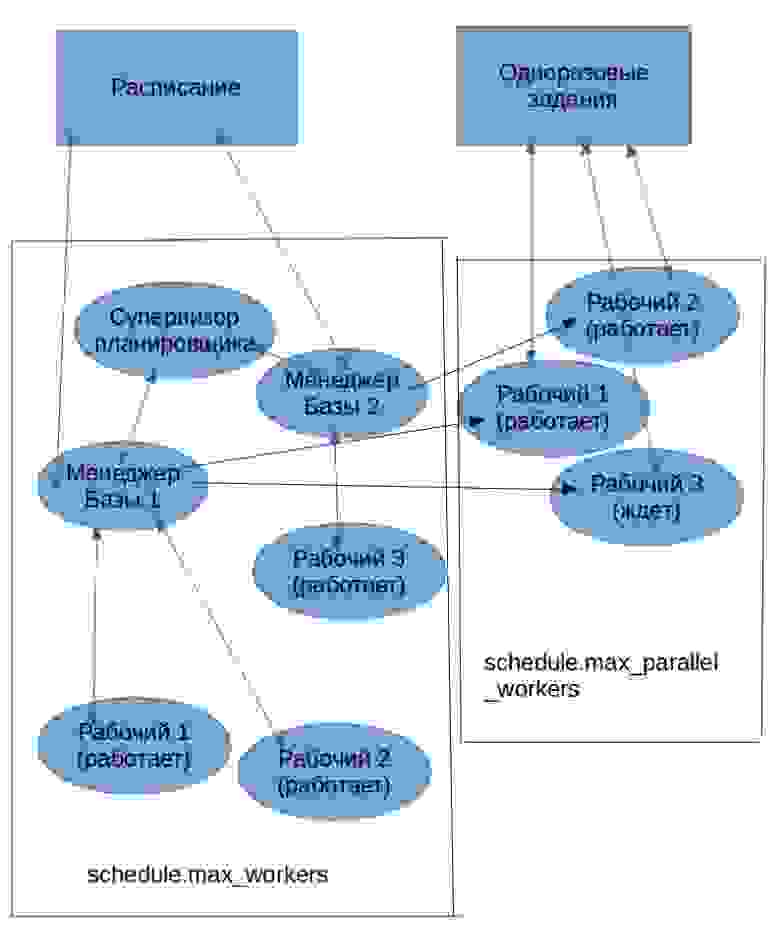
Схема 1. Иерархия процессов планировщика
Поле next_time_statement может содержать SQL-запрос, который будет выполняться после основной транзакции для вычисления времени следующего запуска. Если этот ключ определён, время первого запуска задания будет рассчитано по методам, описанным выше, но следующий запуск будет запланирован на то время, которое вернёт этот запрос. Данный запрос должен вернуть запись, содержащую в первом поле значение типа timestamp with time zone. Если возвращаемое значение имеет другой тип или при выполнении запроса происходит ошибка, задание помечается как давшее сбой, и дальнейшее его выполнение отменяется.
Этот запрос будет выполняться при любом состоянии завершения основной транзакции. Получить состояние завершения транзакции в нём можно из переменной Postgres Pro Enterprise schedule.transaction_state:
Один раз, зато без очереди
Как говорилось, есть еще важный класс задач для планировщика: формирование отдельных, непериодических заданий, использующих механизм one-time job. Если не задан параметр run_after, то в этом режиме планировщик умеет приступать к выполнению задания сразу в момент поступления — с точностью до временного интервала опроса таблицы, в которую записывается задание. В текущей реализации интервал фиксирован и равен 1 секунде. background worker-ы запускаются заранее и ждут «под парАми» появления задания, а не запускаются по мере необходимости, как в режиме расписания. Их количество определено параметром schedule.max_parallel_workers. Соответствующее число запросов может обрабатываться параллельно.

Рис.2 Режим one-time job.
Основная функция, формирующая задание, выглядит так:
schedule.submit_job(query text [options. ])
У этой функции есть, в соответствии с ее спецификой, о которой было в начале, тонкие настройки. Параметр max_duration задает максимальное время исполнения. Если за отведенное время работа не сделана, задание снимается (по умолчанию время исполнения неограниченно). max_wait_interval относится не к времени работы, а к времени ожидания начала работы. Если СУБД не находит за этот промежуток времени «рабочих», готовых взяться за исполнение, задание снимается. Интересный параметр depends_on задает массив работ (в режиме one-time), после завершения которых надо запустить данную работу.
Полезный параметр — resubmit_limit — устанавливает максимальное количество попыток перезапуска. Скажем, задание запускает процедуру, которая начинает высылать сообщение на почту. Почтовый сервер, однако, не торопится его принимать, и по таймауту или вообще из-за отсутствия связи процесс завершается, чтобы возобновиться вновь сразу или через заданное время. Без ограничения в resubmit_limit попытки будут продолжаться до победного конца.
Приправы и десерты
В начале были упомянуты отсоединенные задания — detached jobs. В текущей версии процесс, запустивший одноразовое задание, влачит свое существование в ожидании результата. Накладные расходы на работу background worker невелики, останавливать его нет смысла. Важно, что исполнение или неисполнение задания не пройдет бесследно, о его судьбе мы сможем узнать из запроса к логу планировщика, доступного нам, а не только администратору базы. Это не единственный способ выследить транзакцию даже в случае ее отката: в Postgres Pro Enterprise работает механизм автономных транзакций, который можно использовать для тех же целей. Но в этом случае результат запишут в лог СУБД, а не в «личный» лог пользователя, запустившего планировщик.
Если пользователю планировщика понадобится запланировать или просто запустить некоторые команды ОС с теми правами, которые доступны ему внутри ОС, он может легко сделать это через планировщик, воспользовавшись доступными ему языками программирования. Допустим, он решил воспользоваться untrusted Perl:
CREATE LANGUAGE plperlu;
После этого в можно записать как обычный запрос такую, например, функцию:
Пример из жизни: 1. складирование неактуальных логов
Для начала упрощенный пример управления секциями (партициями) из планировщика. Допустим, мы разбили логи посещения сайта на секции по месяцам. Мы не хотим хранить на дорогих быстрых дисках секции двухлетней свежести и моложе, а остальные сбрасываем в другое табличное пространство, соответствующее другим, более дешевым носителям, сохраняя, однако, полноценные возможности поиска и других операций по всем логам (с не поделенной на секции таблицей такое невозможно). Используем удобные функции управления секциями в расширении pg_pathman. В файле postgresql.conf должна быть строка shared_preload_libraries = ‘pg_pathman, pgpro_scheduler’.
CREATE EXTENSION pg_pathman; CREATE EXTENSION pgpro_scheduler;
ALTER SYSTEM SET schedule.enabled = on ;
ALTER SYSTEM SET schedule.database = ‘test_db’ ;
Баз может быть несколько. В этом случае они перечисляются через запятую внутри кавычек.
SELECT pg_reload_conf(); — перечитать изменения в конфигурации, не перезапуская Postgres.
Только что мы создали родительскую таблицу, которую будем разбивать на секции. Это дань традиционному синтаксису PostgreSQL, основанному на наследовании таблиц. Сейчас, в Postgres Pro Enterprise можно создавать секции не в 2 этапа (сначала пустую родительскую таблицу, потом задавать секции), а сразу определять секции. В данном случае мы воспользуемся удобной функцией pg_pathman, позволяющей сначала задавать приблизительное количество секций. По мере заполнения нужные секции будут создаваться автоматически:
Мы задали 10 начальных секций по одной на месяц, начиная с 1 янв. 2015. Заполним их каким-то количеством данных.
INSERT INTO partitioned_log SELECT i, ‘2015-01-01’ :: date + 60*60*i*random():: int * ‘1 second’ :: interval visit FROM generate_series(1,24*365) AS g(i);
Следить за количеством секций можно так:
SELECT count (*) FROM pathman_partition_list WHERE parent=’partitioned_log’:: regclass ;
Создаем каталог в ОС и соответствующее табличное пространство, куда будут складироваться устаревшие логи:
CREATE TABLESPACE archive LOCATION ‘/tmp/archive’ ;
И, наконец, функцию, которую ежедневно будет запускать планировщик:
Для разминки поставим одноразовое задание:
Ее можно запустить тоже из планировщика, но используя параметр run_after, который задает время задержки в секундах — чтобы у нас осталось время подумать, правильно ли мы поступили:
а если неправильно, то можно отменить ее функцией schedule.cancel_job(id) ;
Убедившись, что всё работает так, как задумано, можно поместить задание (теперь в синтаксисе JSON) уже в расписание:
То есть каждое утро в без пяти минут восемь планировщик будет проверять, не пора ли переместить устаревшие партиции в «холодный» архив и перемещать, если пора. Статус на этот раз можно проверять по логу планировщика: schedule.get_log() ;
Пример из жизни: 2. раскладываем баннеры по серверам
Покажем, как решается одна из типичных задач, в которых требуется выполнение работ по расписанию и используются одноразовые задания.
У нас есть сеть доставки контента (CDN). Мы собираемся разложить по нескольким входящим в нее сайтам баннеры, которые пользователи из рекламных агентств автоматически сгрузили в отведенный для них каталог.
DROP SCHEMA IF EXISTS banners CASCADE ;
CREATE SCHEMA banners;
SET search_path TO ‘banners’ ;
CREATE INDEX banner_on_cdn_banner_server_idx ON banner_on_cdn (banner_id, server_id);
CREATE INDEX banner_on_cdn_url_idx ON banner_on_cdn (url);
Создадим функцию, которая инициализирует загрузку баннера на сервера. Для каждого сервера она создает задачу загрузки, а также задачу, которая ожидает все созданные загрузки и проставляет правильный статус баннеру, когда загрузки завершатся:
А эта функция имитирует посылку баннера на сервер (на самом деле просто какое-то время спит):
RETURN TRUE ;
END ;
$BODY$
LANGUAGE plpgsql set search_path FROM CURRENT ;
Эта функция на основе статусов загрузок баннера на сервер будет определять какой статус поставить баннеру:
Эта функция будет по расписанию проверять, есть ли необработанные баннеры. И, если нужно, запускать обработку баннера:
CREATE FUNCTION check_banners () RETURNS int AS
$BODY$
DECLARE
r record ;
N int ;
BEGIN
N := 0;
FOR r IN SELECT * from banners WHERE status = ‘submitted’ FOR UPDATE LOOP
PERFORM start_banner_upload(r.id);
N := N + 1;
END LOOP ;
RETURN N;
END ;
$BODY$
LANGUAGE plpgsql SET search_path FROM CURRENT ;
Теперь займемся данными. Создадим список серверов:
Создадим пару баннеров:
И, наконец, поставим в расписание задачу по проверке вновь поступивших баннеров, которые надо разложить на сервера. Задача будет выполняться каждую минуту:
Вот и всё, картинки будут разложены по сайтам, можно отдохнуть.
Послесловие
В качестве Post Scriptum сообщаем, что планировщик pgpro_scheduler работает не только на отдельном сервере, но и в конфигурации кластера multimaster. Но это тема отдельного разговора.
А в качестве Post Post Scriptum — что в дальнейших планах встраивание планировщика в создаваемую сейчас графическую оболочку администрирования.