
Что такое потоки ввода вывода в linux
Программа обычно ценна тем, что может обрабатывать данные: принимать одно, на выходе выдавать другое, причём в качестве данных может выступать практически что угодно: текст, числа, звук, видео. Потоки входных и выходных данных для команды называются ввод и вывод. Потоков ввода и вывода у каждой программы может быть и по несколько. В Linux каждый процесс, при создании в обязательном порядке получает так называемые стандартный ввод (standard input, stdin) и стандартный вывод (standard output, stdout) и стандартный вывод ошибок (standard error, stderr).
Стандартные потоки ввода/вывода предназначены в первую очередь для обмена текстовой информацией. Тут даже не важно, кто общается с помощью текстов: человек с программой или программы междй собой — главное, чтобы у них был канал передачи данных и чтобы они говорили « на одном языке ».
При работе с командной строкой, стандартный ввод командной оболочки связан с клавиатурой, а стандартный вывод и вывод ошибок — с экраном монитора (или окном эмулятора терминала). Покажем на примере простейшей команды — cat. Обычно команда cat читает данные из всех файлов, которые указаны в качестве её параметров, и посылает считанное непосредственно в стандартный вывод (stdout). Следовательно, команда
Приведём другой пример. Команда sort читает строки вводимого текста (также из stdin, если не указано ни одного имени файла) и выдаёт набор этих строк в упорядоченном виде на stdout. Проверим её действие.
Перенаправление ввода и вывода
Однако можно поступить иначе, перенаправив не только стандартный вывод, но и стандартный ввод утилиты из файла, используя для этого символ :
Введём понятие фильтра. Фильтром является программа, которая читает данные из стандартного ввода, некоторым образом их обрабатывает и результат направляет на стандартный вывод. Когда применяется перенаправление, в качестве стандартного ввода и вывода могут выступать файлы. Как указывалось выше, по умолчанию, stdin и stdout относятся к клавиатуре и к экрану соответственно. Программа sort является простым фильтром — она сортирует входные данные и посылает результат на стандартный вывод. Совсем простым фильтром является программа cat — она ничего не делает с входными данными, а просто пересылает их на выход.
Использование состыкованных команд (конвейер)
Теперь перенаправляем выход команды ls в файл с именем file-list
Эта команда короче, чем совокупность команд, и её проще набирать.
Рассмотрим другой полезный пример. Команда
выдаёт длинный список файлов. Большая часть этого списка пролетает по экрану слишком быстро, чтобы содержимое этого списка можно было прочитать. Попробуем использовать команду more для того, чтобы выводить этот список частями:
Теперь можно этот список « перелистывать ».
Недеструктивное перенаправление вывода
Эффект от использования символа > для перенаправления вывода файла является деструктивным; иными словами, команда
Linux: перенаправление
Если вы уже освоились с основами терминала, возможно, вы уже готовы к тому, чтобы комбинировать изученные команды. Иногда выполнения команд оболочки по одной вполне достаточно для решения некоей задачи, но в некоторых случаях вводить команду за командой слишком утомительно и нерационально. В подобной ситуации нам пригодятся некоторые особые символы, вроде угловых скобок.

Для оболочки, интерпретатора команд Linux, эти дополнительные символы — не пустая трата места на экране. Они — мощные команды, которые могут связывать воедино различные фрагменты информации, разделять то, что было до этого цельным, и делать ещё много всего. Одна из самых простых, и, в то же время, мощных и широко используемых возможностей оболочки — это перенаправление стандартных потоков ввода/вывода.
Три стандартных потока ввода/вывода
Для того, чтобы понять то, о чём мы будем тут говорить, важно знать, откуда берутся данные, которые можно перенаправлять, и куда они идут. В Linux существует три стандартных потока ввода/вывода данных.
Первый — это стандартный поток ввода (standard input). В системе это — поток №0 (так как в компьютерах счёт обычно начинается с нуля). Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности — инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры.
Второй поток — это стандартный поток вывода (standard output), ему присвоен номер 1. Это поток данных, которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление.
И, наконец, третий поток — это стандартный поток ошибок (standard error), он имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок.
Как вы, вероятно, уже догадались, перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные.
Перенаправление стандартного потока вывода
Перенаправление стандартного потока ввода
Используя знак вместо > мы можем перенаправить стандартный ввод, заменив его содержимым файла.
Перенаправление стандартного потока ошибок
И, наконец, поговорим о перенаправлении стандартного потока ошибок. Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.
Обычно, когда обычный пользователь запускает команду find по всей системе, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2> (напомним, 2 — это дескриптор стандартного потока ошибок). В результате на экран попадёт только то, что команда отправляет в стандартный вывод:
Как быть, если нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках? Так как потоки можно перенаправлять независимо друг от друга, в конец нашей конструкции можно добавить команду перенаправления стандартного потока вывода в файл:
И, наконец, если нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &> :
Итоги
Уважаемые читатели! Знаете ли вы интересные примеры использования перенаправления потоков в Linux, которые помогут новичкам лучше освоиться с этим приёмом работы в терминале?
Перенаправление ввода/вывода в Linux
Введение
Стандартные потоки ввода и вывода в Linux являются одним из наиболее распространенных средств для обмена информацией процессов, а перенаправление >, >> и | является одной из самых популярных конструкций командного интерпретатора.
В данной статье мы ознакомимся с возможностями перенаправления потоков ввода/вывода, используемых при работе файлами и командами.
Требования
Потоки
Стандартный ввод при работе пользователя в терминале передается через клавиатуру.
Стандартный вывод и стандартная ошибка отображаются на дисплее терминала пользователя в виде текста.
Ввод и вывод распределяется между тремя стандартными потоками:
Потоки также пронумерованы:
Из стандартного ввода команда может только считывать данные, а два других потока могут использоваться только для записи. Данные выводятся на экран и считываются с клавиатуры, так как стандартные потоки по умолчанию ассоциированы с терминалом пользователя. Потоки можно подключать к чему угодно: к файлам, программам и даже устройствам. В командном интерпретаторе bash такая операция называется перенаправлением:
Стандартный ввод
Стандартный входной поток обычно переносит данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства типа клавиатура. Стандартный ввод прекращается по достижении EOF (конец файла), который указывает на то, что данных для чтения больше нет.
EOF вводится нажатием сочетания клавиш Ctrl+D.
Рассмотрим работу со стандартным выводом на примере команды cat (от CONCATENATE, в переводе «связать» или «объединить что-то»).
Cat обычно используется для объединения содержимого двух файлов.
Cat отправляет полученные входные данные на дисплей терминала в качестве стандартного вывода и останавливается после того как получает EOF.
Пример
В открывшейся строке введите, например, 1 и нажмите клавишу Enter. На дисплей выводится 1. Введите a и нажмите клавишу Enter. На дисплей выводится a.
Дисплей терминала выглядит следующим образом:
Для завершения ввода данных следует нажать сочетание клавиш Ctrl + D.
Стандартный вывод
Стандартный вывод записывает данные, сгенерированные программой. Когда стандартный выходной поток не перенаправляется в какой-либо файл, он выводит текст на дисплей терминала.
При использовании без каких-либо дополнительных опций, команда echo выводит на экран любой аргумент, который передается ему в командной строке:
Аргументом является то, что получено программой, в результате на дисплей терминала будет выведено:
При выполнении echo без каких-либо аргументов, возвращается пустая строка.
Пример
Команда объединяет три файла: file1, file2 и file3 в один файл bigfile:
Команда cat по очереди выводит содержимое файлов, перечисленных в качестве параметров на стандартный поток вывода. Стандартный поток вывода перенаправлен в файл bigfile.
Стандартная ошибка
Стандартная ошибка записывает ошибки, возникающие в ходе исполнения программы. Как и в случае стандартного вывода, по умолчанию этот поток выводится на терминал дисплея.
Пример
Рассмотрим пример стандартной ошибки с помощью команды ls, которая выводит список содержимого каталогов.
При запуске без аргументов ls выводит содержимое в пределах текущего каталога.
Введем команду ls с каталогом % в качестве аргумента:
В результате должно выводиться содержимое соответствующей папки. Но так как каталога % не существует, на дисплей терминала будет выведен следующий текст стандартной ошибки:
Перенаправление потока
Linux включает в себя команды перенаправления для каждого потока.
Пример
В приведенном примере команда cat используется для записи в файл file1, который создается в результате цикла:
Для завершения цикла нажмите сочетание клавиш Ctrl + D.
Если файла file1 не существует, то в текущем каталоге создается новый файл с таким именем.
Для просмотра содержимого файла file1 введите команду:
В результате на дисплей терминала должно быть выведено следующее:
Для перезаписи содержимого файла введите следующее:
Для завершения цикла нажмите сочетание клавиш Ctrl + D.
В результате на дисплей терминала должно быть выведено следующее:
Предыдущего текста в текущем файле больше не существует, так как содержимое файла было переписано командой >.
Для добавления нового текста к уже существующему в файле с помощью двойных скобок >> выполните команду:
Для завершения цикла нажмите сочетание клавиш Ctrl + D.
Откройте file1 снова и в результате на дисплее монитора должно быть отражено следующее:
Каналы
Каналы используются для перенаправления потока из одной программы в другую. Стандартный вывод данных после выполнения одной команды перенаправляется в другую через канал. Данные первой программы, которые получает вторая программа, не будут отображаться. На дисплей терминала будут выведены только отфильтрованные данные, возвращаемые второй командой.
Пример
В результате каждый файл текущего каталога будет размещен на новой строке:
Перенаправлять данные с помощью каналов можно как из одной команды в другую, так и из одного файла к другому, а перенаправление с помощью > и >> возможно только для перенаправления данных в файлах.
Пример
Для сохранения имен файлов, содержащих строку «LOG», используется следующая команда:
Вывод команды dir отсылается в команду-фильтр find. Имена файлов, содержащие строку «LOG», хранятся в файле loglist в виде списка (например, Config.log, Logdat.svd и Mylog.bat).
При использовании нескольких фильтров в одной команде рекомендуется разделять их с помощью знака канала |.
Фильтры
Фильтры представляют собой стандартные команды Linux, которые могут быть использованы без каналов:
Как правило, все нижеприведенные команды работают как фильтры, если у них нет аргументов (опции могут быть):
Если в качестве аргумента передается файл, команда-фильтр считывает данные из этого файла, а не со стандартного потока ввода (есть исключения, например, команда tr, обрабатывающая данные, поступающие исключительно через стандартный поток ввода).
Пример
Команда tee, как правило, используется для просмотра выводимого содержимого при одновременном сохранении его в файл.
Пример
Допускается перенаправление нескольких потоков в один файл:
В результате сообщение о неверной опции «z» в команде ls будет записано в файл t2, поскольку stderr перенаправлен в файл.
Для просмотра содержимого файла file3 введите команду cat:
В результате на дисплее терминала отобразиться следующее:
Заключение
Мы рассмотрели возможности работы с перенаправлениями потоков >, >> и |, использование которых позволяет лучше работать с bash-скриптами.
Записки IT специалиста
Технический блог специалистов ООО»Интерфейс»
 После того, как вы освоили базовые принципы работы с Linux, позволяющие более-менее уверенно чувствовать себя в среде этой операционной системы, следует начать углублять свои знания, переходя к более глубоким и фундаментальным принципам, на которых основаны многие приемы работы в ОС. Одним из важнейших является понятие потоков, которые позволяют передавать данные от одной программы к другой, а также конвейера, позволяющего выстраивать целые цепочки из программ, каждая из которых будет работать с результатом действий предыдущей. Все это очень широко используется и понимание того, как это работает важно для любого Linux-администратора.
После того, как вы освоили базовые принципы работы с Linux, позволяющие более-менее уверенно чувствовать себя в среде этой операционной системы, следует начать углублять свои знания, переходя к более глубоким и фундаментальным принципам, на которых основаны многие приемы работы в ОС. Одним из важнейших является понятие потоков, которые позволяют передавать данные от одной программы к другой, а также конвейера, позволяющего выстраивать целые цепочки из программ, каждая из которых будет работать с результатом действий предыдущей. Все это очень широко используется и понимание того, как это работает важно для любого Linux-администратора.
Стандартные потоки
Данное приложение все также эмулирует оконечное устройство, предназначенное для взаимодействия пользователя с компьютером. Точно также мы можем запустить сразу несколько терминалов, каждый из которых будет работать независимо. Кроме того, следует понимать, что терминал может быть запущен как локально, так и удаленно, способ подключения к компьютеру может быть разным, но свойства терминала от этого не изменяются.
Для взаимодействия запускаемых в терминале программ и пользователя используются стандартные потоки ввода-вывода, имеющие зарезервированный номер (дескриптор) зарезервированный на уровне операционной системы. Всего существует три стандартных потока:
Перенаправление потоков
Которая через стандартный поток ввода будет доставлена командному интерпретатору, тот запустит указанную программу и передаст ей требуемые аргументы, а результат вернет через стандартный поток вывода на устройство отображения информации.
На экран теперь не будет выведено ничего, но весь вывод команды окажется в файле result, который мы можем прочитать следующим образом:

Немного изменим последовательность команд:
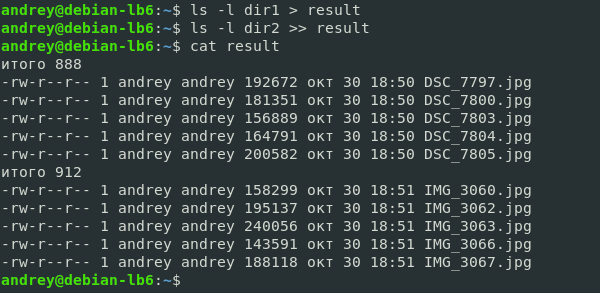
Теперь в файл попал вывод сразу двух команд, при этом, обратите внимание, первой командой мы перезаписали файл, а второй добавили в него содержимое из стандартного потока вывода.
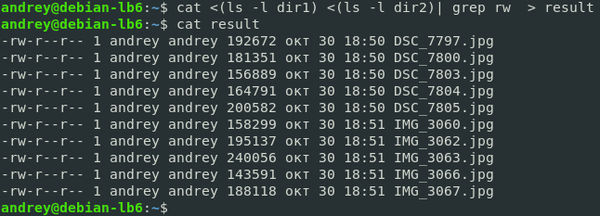
Пойдем дальше. Как видим в выводе кроме списка файлов присутствуют строки «итого», нам они не нужны, и мы хотим от них избавиться. В этом нам поможет утилита grep, которая позволяет отфильтровать строки согласно некому выражению. Например, можно сделать так:
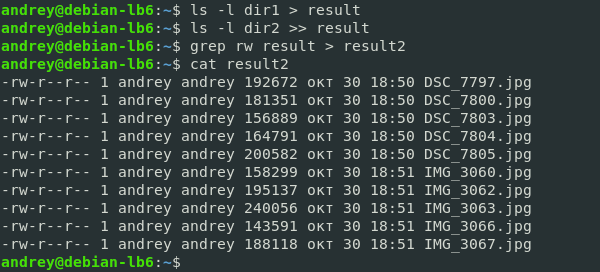 В целом результат достигнут, но ценой трех команд и наличием одного промежуточного файла. Можно ли сделать проще?
В целом результат достигнут, но ценой трех команд и наличием одного промежуточного файла. Можно ли сделать проще?
Но это ничего не изменит, поэтому мы пойдем другим путем и перенаправим на ввод одной команды вывод другой:
На первый взгляд выглядит несколько сложно, но обратимся к man по grep:
В качестве паттерна мы используем rw, который есть в каждой интересующей нас строке, а в качестве файлов отдаем стандартный файл потока ввода, содержимого которого является результатом работы команды, указанной в скобках. А можно направить результат этой команды в файл? Конечно, можно:
Немного особняком стоит стандартный поток вывода ошибок, допустим мы хотим получить список файлов несуществующей директории с перенаправлением вывода в файл, но сообщение об ошибке мы все равно получим на экран.
 Почему так? Да потому что вывод ошибок производится в отдельный поток, который мы никуда не перенаправляли. Если мы хотим подавить вывод сообщений об ошибках на экран, то можно использовать конструкцию:
Почему так? Да потому что вывод ошибок производится в отдельный поток, который мы никуда не перенаправляли. Если мы хотим подавить вывод сообщений об ошибках на экран, то можно использовать конструкцию:
В данном примере весь вывод стандартного потока ошибок будет перенаправлен в пустое устройство /dev/null.
Но можно пойти и другим путем, перенаправив поток ошибок в стандартный поток вывода:
 В этом случае мы перенаправили поток вывода об ошибках в стандартный поток вывода и сообщение об ошибке не было выведено на экран, а было записано в файл, куда мы перенаправили стандартный поток вывода.
В этом случае мы перенаправили поток вывода об ошибках в стандартный поток вывода и сообщение об ошибке не было выведено на экран, а было записано в файл, куда мы перенаправили стандартный поток вывода.
Конвейер
В предыдущих примерах мы научились перенаправлять стандартные потоки ввода-вывода и даже частично коснулись вопроса о направлении вывода одной команды на вход другой. А почему бы и нет? Потоки стандартные, это позволяет использовать вывод одной команды как ввод другой. Это еще один очень важный механизм, позволяющий раскрыть всю мощь Linux в реализации очень сложных сценариев достаточно простым способом.
Самый простой пример:
Первая команда выведет список всех установленных пакетов, вторая отфильтрует только те, в наименовании которых есть строка «gnome».
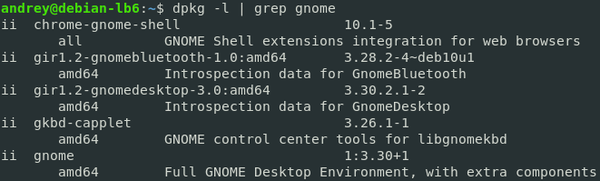 Длинна конвейера ограничена лишь нашей фантазией и здравым смыслом, никаких ограничений со стороны системы в этом нет. Но также в Linuх нет и единственно верных путей, каждую задачу можно решить самыми различными способами. Возвращаясь к получению списка файлов двух директорий мы можем сделать так:
Длинна конвейера ограничена лишь нашей фантазией и здравым смыслом, никаких ограничений со стороны системы в этом нет. Но также в Linuх нет и единственно верных путей, каждую задачу можно решить самыми различными способами. Возвращаясь к получению списка файлов двух директорий мы можем сделать так:
 Какой из этих способов лучше? Любой, Linux ни в чем не ограничивает пользователей и предоставляет им много путей для решения одной и той же задачи.
Какой из этих способов лучше? Любой, Linux ни в чем не ограничивает пользователей и предоставляет им много путей для решения одной и той же задачи.
Еще один важный момент, если вы повышаете права с помощью команды sudo, то данное повышение прав через конвейер не распространяется. Например, если мы решим выполнить:
То первая команда будет выполнена с правами суперпользователя, а вторая с правами запустившего терминал пользователя.
Дополнительные материалы:
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:

Или подпишись на наш Телеграм-канал: 
Что такое потоки ввода вывода в linux
С точки зрения модели КИС (Клиент-Интерфейс-Сервер), сервером стандартных механизмов ввода вывода языка C (printf, scanf, FILE*, fprintf, fputc и т. д.) является библиотека языка. А сервером низкоуровневого ввода-вывода в Linux, которому посвящена эта глава книги, является само ядро операционной системы.
Пользовательские программы взаимодействуют с ядром операционной системы посредством специальных механизмов, называемых системными вызовами (system calls, syscalls). Внешне системные вызовы реализованы в виде обычных функций языка C, однако каждый раз вызывая такую функцию, мы обращаемся непосредственно к ядру операционной системы. Список всех системных вызовов Linux можно найти в файле /usr/include/asm/unistd.h. В этой главе мы рассмотрим основные системные вызовы, осуществляющие ввод-вывод: open(), close(), read(), write(), lseek() и некоторые другие.
5.2. Файловые дескрипторы
Вы уже знаете из предыдущей главы, что при запуске программы в системе создается новый процесс (здесь есть свои особенности, о которых пока говорить не будем). У каждого процесса (кроме init) есть свой родительский процесс (parent process или просто parent), для которого новоиспеченный процесс является дочерним (child process, child). Каждый процесс получает копию окружения (environment) родительского процесса. Оказывается, кроме окружения дочерний процесс получает в качестве багажа еще и копию таблицы файловых дескрипторов.
Возникает вопрос: сколько файлов может открыть процесс? В каждой системе есть свой лимит, зависящий от конфигурации. Если вы используете bash или ksh (Korn Shell), то можете воспользоваться внутренней командой оболочки ulimit, чтобы узнать это значение. Если вы работаете с оболочкой C-shell (csh, tcsh), то в вашем распоряжении команда limit:
В командной оболочке, в которой вы работаете (bash, например), открыты три файла: стандартный ввод (дескриптор 0), стандартный вывод (дескриптор 1) и стандартный поток ошибок (дескриптор 2). Когда под оболочкой запускается программа, в системе создается новый процесс, который является для этой оболочки дочерним процессом, следовательно, получает копию таблицы дескрипторов своего родителя (то есть все открытые файлы родительского процесса). Таким образом программа может осуществлять консольный ввод-вывод через эти дескрипторы. На протяжении всей книги мы будем часто играть с этими дескрипторами.
Таблица дескрипторов, помимо всего прочего, содержит информацию о текущей позиции чтения-записи для каждого дескриптора. При открытии файла, позиция чтения-записи устанавливается в ноль. Каждый прочитанный или записанный байт увеличивает на единицу указатель текущей позиции. Мы вернемся к этой теме в разделе 5.7.
5.3. Открытие файла: системный вызов open()
Чтобы получить возможность прочитать что-то из файла или записать что-то в файл, его нужно открыть. Это делает системный вызов open(). Этот системный вызов не имеет постоянного списка аргументов (за счет использования механизма va_arg); в связи с этим существуют две «разновидности» open(). Не только в С++ есть перегрузка функций  Если интересно, то о механизме va_arg можно прочитать на man-странице stdarg (man 3 stdarg) или в книге Б. Кернигана и Д. Ритчи «Язык программирования Си». Ниже приведены адаптированные прототипы системного вызова open().
Если интересно, то о механизме va_arg можно прочитать на man-странице stdarg (man 3 stdarg) или в книге Б. Кернигана и Д. Ритчи «Язык программирования Си». Ниже приведены адаптированные прототипы системного вызова open().
Системный вызов open() объявлен в заголовочном файле fcntl.h. Ниже приведен общий адаптированный прототип open().
5.4. Закрытие файла: системный вызов close()
Системный вызов close() закрывает файл. Вообще говоря, по завершении процесса все открытые файлы (кроме файлов с дескрипторами 0, 1 и 2) автоматически закрываются. Тем не менее, это не освобождает нас от самостоятельного вызова close(), когда файл нужно закрыть. К тому же, если файлы не закрывать самостоятельно, то соответствующие дескрипторы не освобождаются, что может привести к превышению лимита открытых файлов. Простой пример: приложение может быть настроено так, чтобы каждую минуту открывать и перечитывать свой файл конфигурации для проверки обновлений. Если каждый раз файл не будет закрываться, то в моей системе, например, приложение может «накрыться медным тазом» примерно через 17 часов. Автоматически! Кроме того, файловая система Linux поддерживает механизм буферизации. Это означает, что данные, которые якобы записываются, реально записываются на носитель (синхронизируются) только через какое-то время, когда система сочтет это правильным и оптимальным. Это повышает производительность системы и даже продлевает ресурс жестких дисков. Системный вызов close() не форсирует запись данных на диск, однако дает больше гарантий того, что данные останутся в целости и сохранности.
Системный вызов close() объявлен в файле unistd.h. Ниже приведен его адаптированный прототип.
Теперь можно написать простенкую программу, использующую системные вызовы open() и close(). Мы еще не умеем читать из файлов и писать в файлы, поэтому напишем программу, которая создает файл с именем, переданным в качестве аргумента (argv[1]) и с правами доступа 0600 (чтение и запись для пользователя). Ниже приведен исходный код программы.
Обратите внимание, если запустить программу дважды с одним и тем же аргументом, то на второй раз open() выдаст ошибку. В этом виноват флаг O_EXCL (см. Таблицу 4 Приложения 2), который «дает добро» только на создание еще не существующих файлов. Наглядности ради, флаги открытия и флаги режима мы занесли в отдельные переменные, однако можно было бы сделать так: Или так:
5.5. Чтение файла: системный вызов read()
Системный вызов read(), объявленный в файле unistd.h, позволяет читать данные из файла. В отличие от библиотечных функций файлового ввода-вывода, которые предоставляют возможность интерпретации считываемых данных. Можно, например, записать в файл следующее содержимое:
Теперь, используя библиотечные механизмы, можно читать файл по-разному:
Системный вызов read() читает данные в «сыром» виде, то есть как последовательность байт, без какой-либо интерпретации. Ниже представлен адаптированный прототип read().
Теперь напишем программу, которая просто читает файл и выводит его содержимое на экран. Имя файла будет передаваться в качестве аргумента (argv[1]). Ниже приведен исходный код этой программы.
Как можно заметить, в нашем примере системный вызов read() вызывается ровно столько раз, сколько байт содержится в файле. Иногда это действительно нужно; но не здесь. Чтение-запись посимвольным методом (как в нашем примере) значительно замедляет процесс ввода-вывода за счет многократных обращений к системным вызовам. По этой же причине возрастает вероятность возникновения ошибки. Если нет действительной необходимости, файлы нужно читать блоками. О том, какой размер блока предпочтительнее, будет рассказано в последующих главах книги. Ниже приведен исходный код программы, которая делает то же самое, что и предыдущий пример, но с использованием блочного чтения файла. Размер блока установлен в 64 байта.
Теперь можно примерно оценить и сравнить скорость работы двух примеров. Для этого надо выбрать в системе достаточно большой файл (бинарник ядра или видеофильм, например) и посмотреть на то, как быстро читаются эти файлы:
5.6. Запись в файл: системный вызов write()
Для записи данных в файл используется системный вызов write(). Ниже представлен его прототип.
В этом примере нам уже не надо изощеряться в попытках вставить нуль-терминатор в строку для записи, поскольку системный вызов write() не запишет большее количество байт, чем мы ему указали. В данном случае для демонстрации write() мы просто записывали данные в файл с дескриптором 1, то есть в стандартный вывод. Но прежде, чем переходить к чтению следующего раздела, попробуйте самостоятельно записать что-нибудь (при помощи write(), естественно) в обычный файл. Когда будете открывать файл для записи, обратите пожалуйста внимание на флаги O_TRUNC, O_CREAT и O_APPEND. Подумайте, все ли флаги сочетаются между собой по смыслу.
5.7. Произвольный доступ: системный вызов lseek()
Как уже говорилось, с каждым открытым файлом связано число, указывающее на текущую позицию чтения-записи. При открытии файла позиция равна нулю. Каждый вызов read() или write() увеличивает текущую позицию на значение, равное числу прочитанных или записанных байт. Благодаря этому механизму, каждый повторный вызов read() читает следующие данные, и каждый повторный write() записывает данные в продолжение предыдущих, а не затирает старые. Такой механизм последовательного доступа очень удобен, однако иногда требуется получить произвольный доступ к содержимому файла, чтобы, например, прочитать или записать файл заново.
Для изменения текущей позиции чтения-записи используется системный вызов lseek(). Ниже представлен его прототип.
Первый вызов устанавливает текущую позицию в начало файла. Второй вызов смещает позицию вперед на 20 байт. В третьем случае текущая позиция перемещается на 10 байт назад относительно конца файла.
Я долго думал, какой бы пример придумать, чтобы продемонстрировать работу lseek() наглядным образом. Наиболее подходящим примером мне показалась идея создания программы рисования символами. Программа оказалась не слишком простой, однако если вы сможете разобраться в ней, то можете считать, что успешно овладели азами низкоуровневого ввода-вывода Linux. Ниже представлен исходный код этой программы.
Функция init_draw() пишет в файл N_ROWS строк, каждая из которых содержит N_COLS пробелов, заканчивающихся переводом строки. Это процедура подготовки «холста».
Функция draw_point() вычисляет позицию (исходя из значений координат), перемещает туда текущую позицию ввода-вывода файла, и записывает в эту позицию символ (FG_CHAR), которым мы рисуем «картину».
Функция draw_hline() заполняет часть строки символами FG_CHAR. Так получается горизонтальная линия. Функция draw_vline() работает иначе. Чтобы записать вертикальную линию, нужно записывать по одному символу и каждый раз «перескакивать» на следующую строку. Эта функция работает медленнее, чем draw_hline(), но иначе мы не можем.
Полученное изображение записывается в файл image. Будьте внимательны: чтобы разгрузить исходный код, из программы исключены многие проверки (read(), write(), close(), диапазон координат и проч.). Попробуйте включить эти проверки самостоятельно.