
Content provider (Контент-провайдер)
Что такое контент-провайдер
Поставщик содержимого применяется лишь в тех случаях, когда вы хотите использовать данные совместно с другими приложениями, работающих в устройстве. Но даже если вы не планируете сейчас делиться данными, то всё-равно можно подумать об реализации этого способа на всякий случай.

Чтобы получить из библиотеки конкретную книгу (например, книгу №23), будет использоваться следующий URI (отдельный ряд таблицы):
Любая программа, работающая в устройстве, может использовать такие URI для доступа к данным и осуществления с ними определенных операций. Следовательно, поставщики содержимого играют важную роль при совместном использовании данных несколькими приложениями.
Встроенные поставщики
В Android используются встроенные поставщики содержимого (пакет android.provider). Вот неполный список поставщиков содержимого:
Создание собственного контент-провайдера
Для создания собственного контент-провайдера нужно унаследоваться от абстрактного класса ContentProvider:
В классе необходимо реализовать абстрактные методы query(), insert(), update(), delete(), getType(), onCreate(). Прослеживается некоторое сходство с созданием обычной базы данных.
А также его следует зарегистрировать в манифесте с помощью тега provider с атрибутами name и authorities. Тег authorities служит для описания базового пути URI, по которому ContentResolver может найти базу данных для взаимодействия. Данный тег должен быть уникальным, поэтому рекомендуется использовать имя вашего пакета, чтобы не произошло путаницы с другими приложениями, например:
Источник поставщика содержимого аналогичен доменному имени сайта. Если источник уже зарегистрирован, эти поставщики содержимого будут представлены гиперссылками, начинающимися с соответствующего префикса источника:
Итак, поставщики содержимого, как и веб-сайты, имеют базовое доменное имя, действующее как стартовая URL-страница.
В поставщиках содержимого также встречаются REST-подобные гиперссылки, предназначенные для поиска данных и работы с ними. В случае описанной выше регистрации унифицированный идентификатор ресурса, предназначенный для обозначения каталога или коллекции записей в базе данных NotePadProvider, будет иметь имя:
URI для идентификации отдельно взятой записи будет иметь вид:
Символ # соответствует конкретной записи (ряд таблицы). Ниже приведено еще несколько примеров URI, которые могут присутствовать в поставщиках содержимого:
Структура унифицированных идентификаторов содержимого (Content URI)
Для получения данных из поставщика содержимого нужно просто активировать URI. Однако при работе с поставщиком содержимого найденные таким образом данные представлены как набор строк и столбцов и образуют объект Android cursor. Рассмотрим структуру URI, которую можно использовать для получения данных.
Унифицированные идентификаторы содержимого (Content URI) в Android напоминают HTTP URI, но начинаются с content и строятся по следующему образцу:
Вот пример URI, при помощи которого в базе данных идентифицируется запись, имеющая номер 23:
После content: в URI содержится унифицированный идентификатор источника, который используется для нахождения поставщика содержимого в соответствующем реестре. Часть URI ru.alexanderklimov.provider.notepad представляет собой источник.
UriMatcher
Провайдер имеет специальный объект класса UriMatcher, который получает данные снаружи и на основе полученной информации создаёт нужный запрос к базе данных.
| URI pattern | Code | Contant name |
|---|---|---|
| content://ru.alexanderklimov.provider.notepad/notes | 100 | NOTES |
| content://ru.alexanderklimov.provider.notepad/notes/# | 101 | NOTES_ID |
Приложение может быть сложным и иметь несколько таблиц. Тогда и констант будет больше. Например, так.
| URI pattern | Code | Contant name |
|---|---|---|
| content://com.android.contacts/contacts | 1000 | CONTACTS |
| content://com.android.contacts/contacts/# | 1001 | CONTACTS_ID |
| content://com.android.contacts/lookup/* | 1002 | CONTACTS_LOOKUP |
| content://com.android.contacts/lookup/*/# | 1003 | CONTACTS_LOOKUP_ID |
| . | . | . |
| content://com.android.contacts/data | 3000 | DATA |
| content://com.android.contacts/data/# | 3001 | DATA_ID |
| . | . | . |
Символ решётки (#) отвечает за число, а символ звёздочки (*) за строку.
Метод query()
Метод query() является обязательным для класса ContentProvider. Если мы используем контент-провайдер для обращения к базе данных, то в нём вызывает одноимённый метод SQLiteDatabase. Состав метода практически идентичен.
Вам нужно программно получить необходимые данные для аргументов метода. Обратите внимание на метод ContentUris.parseId(uri), который возвращает последний сегмент адреса, в нашем случае число 3, для Selection Args.
Метод insert()
Для вставки используется вспомогательный метод insertGuest().
Структурирование МIМЕ-типов в Android
Как веб-сайт возвращает тип MIME для заданной гиперссылки (это позволяет браузеру активировать программу, предназначенную для просмотра того или иного типа контента), так и в поставщике содержимого предусмотрена возможность возвращения типа MIME для заданного URI. Благодаря этому достигается определенная гибкость при просмотре данных. Если мы знаем, данные какого именно типа получим, то можем выбрать одну или несколько программ, предназначенных для представления таких данных. Например, если на жестком диске компьютера есть текстовый файл, мы можем выбрать несколько редакторов, которые способны его отобразить.
Типы MIME работают в Android почти так же, как и в НТТР. Вы запрашиваете у контент-провайдера тип MIME определенного поддерживаемого им URI, и поставщик содержимого возвращает двухчастную последовательность символов, идентифицирующую тип MIME в соответствии с принятыми стандартами.
Обозначение MIME состоит из двух частей: типа и подтипа. Ниже приведены примеры некоторых известных пар типов и подтипов MIME:
text/html
text/css
text/xml
image/jpeg
audio/mp3
video/mp4
application/pdf
application/msword
Основные зарегистрированные типы содержимого:
application
audio
image
message
model
multipart
text
video
В Android применяется схожий принцип для определения типов MIME. Обозначение vnd в типах MIME в Android означает, что данные типы и подтипы являются нестандартными, зависящими от производителя. Для обеспечения уникальности в Android типы и подтипы разграничиваются при помощи нескольких компонентов, как и доменные имена. Кроме того, типы MIME в Android, соответствующие каждому типу содержимого, существуют в двух формах: для одиночной записи и для нескольких записей.
ContentResolver
Каждый объект Content, принадлежащий приложению, включает в себя экземпляр класса ContentResolver, который можно получить через метод getContentResolver().
Подробно о пакете Provider для Flutter
В наших среднесрочных планах — выход книги по Flutter. Относительно языка Dart как темы мы пока занимаем более осторожную позицию, поэтому попробуем оценить ее актуальность по результатам этой статьи. Речь в ней пойдет о пакете Provider и, следовательно, об управлении состоянием в Flutter.
Provider – это пакет для управления состояниями, написанный Реми Русле и взятый на вооружение в Google и в сообществе Flutter. Но что такое управление состоянием? Для начала, что такое состояние? Напомню, что состояние – это просто данные для представления UI в вашем приложении. Управление состоянием – это подход к созданию этих данных, доступа к ним, обращению с ними и избавления от них. Чтобы лучше понять пакет Provider, кратко обрисуем историю управления состоянием в Flutter.
1. StatefulWidget
2. InheritedWidget
3. ScopedModel
Чтобы предоставить наш объект состояния, мы оборачиваем этот объект в виджет ScopedModel в корне нашего приложения:
Теперь любые виджеты-потомки смогут обращаться к MyModel при помощи виджета ScopedModelDescendant. Экземпляр модели передается в параметр builder :
Любой виджет-потомок также сможет обновлять модель, что автоматически спровоцирует перестройку любых ScopedModelDescendants (при условии, что наша модель правильно вызывает notifyListeners() ):
ScopedModel приобрел популярность во Flutter в качестве инструмента для управления состоянием, но его использование ограничено предоставлением объектов, наследующих класс Model и использующих данный паттерн уведомления об изменениях.
4. BLoC
На конференции Google I/O ’18 был представлен паттерн Business Logic Component (BLoC), служащий в качестве еще одного инструмента, позволяющего вынести состояние из виджетов. Классы BLoC – это долгоживущие компоненты, не относящиеся к UI, сохраняющие состояние и предоставляющие его в виде потоков и приемников. Вынося состояние и бизнес-логику за пределы UI, можно реализовать виджет как простой StatelessWidget и использовать StreamBuilder для автоматической перестройки. В результате виджет «глупеет», и его становится проще тестировать.
Пример класса BLoC:
5. Provider
Provider построен “с виджетами, для виджетов.” Provider позволяет поместить любой объект, обладающий состоянием, в дерево виджетов и открыть к нему доступ для любого другого виджета (потомка). Также Provider помогает управлять временем жизни объектов состояний, инициализируя их с данными и выполняя очистку после того, как они будут удалены из дерева виджетов. Поэтому Provider подходит даже для реализации компонентов BLoC или может служить основой для других решений по управлению состоянием! Либо просто применяться для внедрения зависимостей — причудливый термин, подразумевающий передачу данных в виджеты таким образом, который позволяет ослабить связанность и улучшить тестируемость кода. Наконец, Provider поставляется с набором специализированных классов, благодаря которым использовать его еще удобнее. Далее мы подробнее рассмотрим каждый из этих классов.
Установка
Затем импортируем пакет Provider там, где это нужно:
Создадим базовый Provide r в корне нашего приложения; здесь будет содержаться экземпляр нашей модели:
Теперь, что нам делать, если мы хотим обновить данные в нашей модели? Допустим, у нас есть другой виджет, где при нажатии кнопки должно обновляться свойство foo :
Это еще одна прелесть, предоставляемая в пакете Provider просто так.
Затем потребить дочерний виджет, как это обычно делается при помощи Provider :
Аналогично вышеприведенному примеру, FutureProvider – это альтернатива стандартному FutureBuilder при работе с виджетами. Вот пример:
ValueListenable – это интерфейс Dart, реализуемый классом ValueNotifier, который принимает значение и уведомляет слушатели, когда оно меняется на другое значение. В него можно, например, обернуть целочисленный счетчик в простом классе модели:
Вот как слушать свойство counter из любого виджета-потомка:
MultiProvider позволяет объявить их все на одном уровне. Это просто синтаксический сахар: на внутрисистемном уровне все они все равно остаются вложенными.
Как одновременно слушать множество провайдеров
Объекты ADO (продолжение)
Провайдеры
Провайдер ODBC
Провайдер ODBC, являясь Провайдером по умолчанию, поддерживает все зависящие от Провайдера свойства и методы объектов ADO. Он поддерживает транзакции, в том числе и гнездованные транзакции. Однако различные СУБД могут обеспечивать различный уровень поддержки транзакций, например, Microsoft Access поддерживает гнездованные транзакции на глубину не более пяти уровней.
Для этого Провайдера аргумент Provider свойства ConnectionString следует установить как MSDASQL. Типичная строка соединения имеет вид:
Аргумент DSN (Data Source Name), задает имя источника данных. Это имя должно быть зарегистрировано в Администраторе источников данных ODBC, добраться до которого можно из панели управления. Вот как выглядит окно Администратора, в котором я установил DSN для тестовой базы данных.
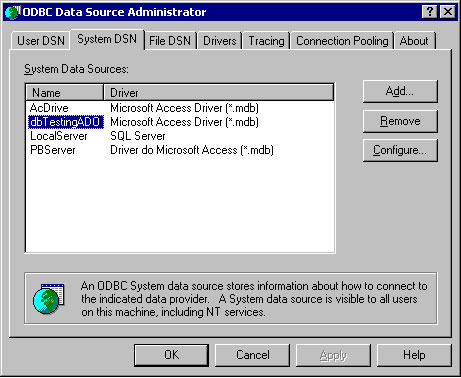
Приведу пример работы с этой базой данных:
Хочу обратить внимание на два момента:
Провайдер Microsoft Jet
Этот Провайдер позволяет получить доступ к Microsoft Jet базам данных, а, следовательно, к базам данных, созданным в приложении Access. В большинстве приведенных примерах использовался именно этот Провайдер. Типичная строка соединения имеет вид:
Провайдер Internet Publishing
Примеры использования этого Провайдера уже были приведены.
Провайдер SQL Server
Провайдер Oracle
Другие Провайдеры
Краткие данные о других Провайдерах приведу в таблице.
Почему контекст не является «инструментом для управления состоянием»

Context и Redux — это одно и тоже?
Нет. Это разные инструменты, делающие разные вещи и используемые в разных целях.
Является ли контекст инструментом «управления состоянием»?
Нет. Контекст — это форма внедрения зависимостей (dependency injection). Это транспортный механизм, который ничем не управляет. Любое «управление состоянием» осуществляется вручную, как правило, с помощью хуков useState()/useReducer().
Являются ли Context и useReducer() заменой Redux?
Нет. Они в чем-то похожи и частично пересекаются, но сильно отличаются в плане возможностей.
Когда следует использовать контекст?
Когда вы хотите сделать некоторые данные доступными для нескольких компонентов, но не хотите передавать эти данные в виде пропов на каждом уровне дерева компонентов.
Когда следует использовать Context и useReducer()?
Когда вам требуется управление состоянием умеренно сложного компонента в определенной части приложения.
Когда следует использовать Redux?
Redux наиболее полезен в следующих случаях:
Понимание Context и Redux
Для правильного использования инструмента критически важно понимать:
Неразбериха вокруг Context и Redux связана, в первую очередь, с непониманием того, для чего данные инструменты предназначены, и какие задачи они решают. Поэтому, прежде чем говорить о том, когда их следует использовать, необходимо определить, что они из себя представляют и какие проблемы решают.
Что такое контекст?
Начнем с определения контекста из официальной документации:
«Контекст позволяет передавать данные через дерево компонентов без необходимости передавать пропы на промежуточных уровнях.
В типичном React-приложении данные передаются сверху вниз (от предка к потомку) с помощью пропов. Однако, этот способ может быть чересчур громоздким для некоторых типов пропов (например, выбранный язык, тема интерфейса), которые необходимо передавать во многие компоненты в приложении. Контекст предоставляет способ распределять такие данные между компонентами без необходимости явно передавать пропы на каждом уровне дерева компонентов».
Обратите внимание, в данном определении ни слова не говорится об «управлении», только о «передаче» и «распределении».
Текущее API контекста (React.createContext()) впервые было представлено в React 16.3 в качестве замены устаревшего API, доступного в ранних версиях React, но имеющего несколько недостатков дизайна. Одной из главных проблем являлось то, что обновления значений, переданных через контекст, могли быть «заблокированы», если компонент пропускал рендеринг через shouldComponentUpdate(). Поскольку многие компоненты прибегали к shouldComponentUpdate() в целях оптимизации, передача данных через контекст становилась бесполезной. createContext() был спроектирован для решения этой проблемы, поэтому любое обновление значения отразится на дочерних компонентах, даже если промежуточный компонент пропускает рендеринг.
Использование контекста
Использование контекста в приложении предполагает следующее:
Обычно, значением контекста является состояние компонента:
После этого дочерний компонент может вызвать хук useContext() и прочитать значение контекста:
Цель и случаи использования контекста
Концептуально, это является формой внедрения зависимостей. Мы знаем, что потомок нуждается в данных определенного типа, но он не пытается создавать или устанавливать эти данные самостоятельно. Вместо этого, он полагается на то, что некоторый предок передаст эти данные во время выполнения (runtime).
Что такое Redux?
Вот о чем гласит определение из «Основ Redux»:
«Redux — это паттерн проектирования и библиотека для управления и обновления состояния приложения, использующая события, именуемые операциями (действиями, actions). Redux выступает в роли централизованного хранилища состояния приложения, следюущего правилам, позволяющим обеспечить предсказуемое обновление состояние.
Redux позволяет управлять „глобальным“ состоянием — состоянием, которое трубется нескольким частям приложения.
Паттерны и инструменты, предоставляемые Redux, позволяют легче определять где, когда, почему и как было обновлено состояние, и как отреагировало приложение на это изменение».
Обратите внимание, что данное описание указывает на:
Архитектурно, Redux подчеркнуто использует принципы функционального программирования, что позволяет писать код в форме предсказуемых «функций-редукторов» (reducers), и обособлять идею «какое событие произошло» от логики, определяющей «как обновляется состояние при возгникновении данного события». В Redux также используется промежуточное программное обеспечение (middleware) как способ расширения возможностей хранилища, включая обработку побочных эффектов (side effects).
Redux также предоставляет инструменты разработчика, позволяющие изучать историю операций и изменение состояния в течение времени.
Redux и React
Сам по себе Redux не зависит от UI — вы можете использовать его с любым слоем представления (view layer) (React, Vue, Angular, ванильный JS и т.д.) либо без UI вообще.
Однако, чаще всего, Redux используется совместно с React. Библиотека React Redux — это официальный связывающий слой UI, позволяющий React-компонентам взаимодействовать с хранилищем Redux, получая значения из состояния Redux и инициализируя выполнение операций. React-Redux использует контекст в своих внутренних механизмах. Тем не менее, следует отметить, что React-Redux передает через контекст экземпляр хранилища Redux, а не текущее значение состояния! Это пример использования контекста для внедрения зависимостей. Мы знаем, что наши подключенные к Redux компоненты нуждаются во взаимодействии с хранилищем Redux, но мы не знаем или нам неважно, что это за хранилище, когда мы определяем компонент. Настоящее хранилище Redux внедряется в дерево во время выполнения с помощью компонента
Цель и случаи использования (React-)Redux
Основное назначение Redux согласно официальной документации:
«Паттерны и инструменты, предоставляемые Redux, облегчают понимание того, когда, где, почему и как произошло изменение состояния, а также того, как на это отреагировало приложение».
Существует еще несколько причин использования Redux. Одной из таких причин является предотвращение «бурения».
Другие случаи использования:
Почему контекст не является инструментом «управления состоянием»?
Состояние — это любые данные, описывающие поведение приложения. Мы можем разделить состояние на такие категории, как состояние сервера, состояние коммуникаций и локальное состояние, если хотим, но ключевым аспектом является хранение, чтение, обновление и использование данных.
«Управление состоянием — это изменение состояния в течение времени».
Таким образом, мы можем сказать, что «управление состоянием» означает следующее:
React-хуки useState() и useReducer() являются отличными примерами управления состоянием. С помощью этих хуков мы можем:
React Context не соответствует названным критериям. Поэтому он не является инструментом управления состоянием
«Контекст — это то, как существующее состояние распределяется между компонентами. Контекст ничего не делает с состоянием».
«Полагаю, контекст — это как скрытые пропы, абстрагирующие состояние».
Все, что делает контекст, это позволяет избежать «бурения».
Сравнение Context и Redux
Сравним возможности контекста и React+Redux:
Context и useReducer()
Одной из проблем в дискуссии «Context против Redux» является то, что люди, зачастую, на самом деле имеют ввиду следующее: «Я использую useReducer() для управления состоянием и контекст для передачи значения». Но, вместо этого, они просто говорят: «Я использую контекст». В этом, на мой взгляд, кроется основная причина неразберихи, способствующая поддержанию мифа о том, что контекст «управляет состоянием».
Рассмотрим комбинацию Context + useReducer(). Да, такая комбинация выглядит очень похоже на Redux + React-Redux. Обе эти комбинации имеют:
«Мое личное мнение состоит в том, что новый контекст готов к использованию для маловероятных обновлений с низкой частотой (таких как локализация или тема). Он также может использоваться во всех тех случаях, в которых использовался старый контекст, т.е. для статических значений с последующим распространением обновления по подпискам. Он не готов к использованию в качестве замены Flux-подобных „распространителей“ состояния».
В сети существует много статей, рекомендующих настройку нескольких отдельных контекстов для разных частей состояния, что позволяет избежать ненужных повторных рендерингов и решить проблемы, связанные с областями видимости. Некоторые из постов также предлагают добавлять собственные «компоненты по выбору контекста», что требует использования сочетания React.memo(), useMemo() и аккуратного разделения кода на два контекста для каждой части приложения (одна для данных, другая для функций обновления). Безусловно, код можно писать и так, но в этом случае вы заново изобретаете React-Redux.
Таким образом, несмотря на то, что Context + useReducer() — это легкая альтернатива Redux + React-Redux в первом приближении… эти комбинации не идентичны, контекст + useReducer() не может полностью заменить Redux!
Выбор правильного инструмента
Для выбора правильного инструмента очень важно понимать, какие задачи решает инструмент, а также какие задачи стоят перед вами.
Обзор случаев использования
Рекомендации
Как же решить, что следует использовать?
Для этого вам всего лишь нужно определить, какой инструмент наилучшим образом решает задачи вашего приложения.
Часто можно услышать, что «использование Redux предполагает написание большого количества шаблонного кода», однако, «современный Redux» значительно облегчает изучение данного инструмента и его использование. Официальный пакет Redux Toolkit решает проблему шаблонизации, а хуки React-Redux упрощают использование Redux в компонентах React.
Разумеется, добавление RTK и React-Redux в качестве зависимостей увеличивает «бандл» приложения по сравнению с контекстом + useReducer(), которые являются встроенными. Но преимущества такого подхода перекрывают недостатки — лучшая трассировка состояния, простая и более предсказуемая логика, улучшенная оптимизация рендринга компонентов.
Также важно отметить, что одно не исключает другого — вы можете использовать Redux, Context и useReducer() вместе. Мы рекомендуем хранить «глобальное» состояние в Redux, а локальное — в компонентах и внимательно подходить к определению того, какая часть приложения должна храниться в Redux, а какая — в компонентах. Так что вы можете использовать Redux для хранения глобального состояния, Context + useReducer() — для хранения локального состояния, и Context — для статических значений, одновременно и в одном приложении.
Еще раз: я не утверждаю, что все состояние приложения должно храниться в Redux или что Redux — это всегда лучшее решение. Я утверждаю лишь, что Redux — хороший выбор, существует много причин использовать Redux, и плата за его использование не так высока, как многие думают.
Наконец, контекст и Redux не единственные в своем роде. Существует множество других инструментов, решающих иные аспекты управления состоянием. MobX — популярное решение, использующее ООП и наблюдаемые объекты (observables) для автоматического обновления зависимостей. Среди других подходов к обновлению состояния можно назвать Jotai, Recoil и Zustand. Библиотеки для работы с данными, вроде React Query, SWR, Apollo и Urql, предоставляют абстракции, упрощающие применение распространенных паттернов для работы с состоянием, кэшируемым сервером (скоро похожая библиотека (RTK Query) появится и для Redux Toolkit).
Надеюсь, данная статья помогла вам понять разницу между контекстом и Redux, а также какой инструмент и в каких случаях следует использовать. Благодарю за внимание.