
Регулярные выражения: начало работы с RegExp
Авторизуйтесь
Регулярные выражения: начало работы с RegExp
Что такое регулярные выражения?
Регулярные выражения представляют собой похожий, но гораздо более сильный инструмент для поиска строк, проверки их на соответствие какому-либо шаблону и другой подобной работы. Англоязычное название этого инструмента — Regular Expressions или просто RegExp. Строго говоря, регулярные выражения — специальный язык для описания шаблонов строк.
Реализация этого инструмента различается в разных языках программирования, хоть и не сильно. В данной статье мы будем ориентироваться в первую очередь на реализацию Perl Compatible Regular Expressions.
Основы синтаксиса
13–15 декабря, Онлайн, Беcплатно
Набор символов
Предположим, мы хотим найти в тексте все междометия, обозначающие смех. Просто Хаха нам не подойдёт — ведь под него не попадут «Хехе», «Хохо» и «Хихи». Да и проблему с регистром первой буквы нужно как-то решить.
Здесь нам на помощь придут наборы — вместо указания конкретного символа, мы можем записать целый список, и если в исследуемой строке на указанном месте будет стоять любой из перечисленных символов, строка будет считаться подходящей. Наборы записываются в квадратных скобках — паттерну [abcd] будет соответствовать любой из символов «a», «b», «c» или «d».
Внутри набора большая часть спецсимволов не нуждается в экранировании, однако использование \ перед ними не будет считаться ошибкой. По прежнему необходимо экранировать символы «\» и «^», и, желательно, «]» (так, [][] обозначает любой из символов «]» или «[», тогда как [[]х] – исключительно последовательность «[х]»). Необычное на первый взгляд поведение регулярок с символом «]» на самом деле определяется известными правилами, но гораздо легче просто экранировать этот символ, чем их запоминать. Кроме этого, экранировать нужно символ «-», он используется для задания диапазонов (см. ниже).
Предопределённые классы символов

Комикс про регулярные выражения с xkcd.ru
Диапазоны
Квантификаторы
Вернёмся к нашему примеру. Что, если в «смеющемся» междометии будет больше одной гласной между буквами «х», например «Хаахаааа»? Наша старая регулярка уже не сможет нам помочь. Здесь нам придётся воспользоваться квантификаторами.
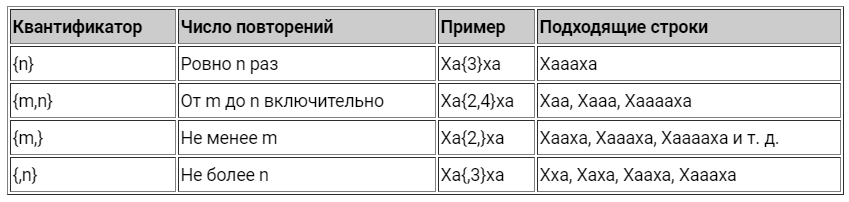
Примеры использования квантификаторов в регулярных выражениях
Обратите внимание, что квантификатор применяется только к символу, который стоит перед ним.
Некоторые часто используемые конструкции получили в языке RegEx специальные обозначения:

Спецобозначения квантификаторов в регулярных выражениях.
Ленивая квантификация
Предположим, перед нами стоит задача — найти все HTML-теги в строке
Очевидное решение здесь не сработает — оно найдёт всю строку целиком, т.к. она начинается с тега абзаца и им же заканчивается. То есть содержимым тега будет считаться строка
Ревнивая квантификация
Чуть больше о жадном, сверхжадном и ленивом режимах квантификации вы сможете узнать из статьи о регулярных выражениях в Java.
Скобочные группы
Таким образом, наше выражение превращается в [Хх]([аиое]х?)+ — сначала идёт заглавная или строчная «х», а потом произвольное ненулевое количество гласных, которые (возможно, но не обязательно) перемежаются одиночными строчными «х». Однако это выражение решает проблему лишь частично — под это выражение попадут и такие строки, как, например, «хихахех» — кто-то может быть так и смеётся, но допущение весьма сомнительное. Очевидно, мы можем использовать набор из всех гласных лишь единожды, а потом должны как-то опираться на результат первого поиска. Но как?…
Запоминание результата поиска по группе
Результат поиска по всему регексу: «
».
Результат поиска по первой группе: «p», «b», «/b», «i», «/i», «/i», «/p».

Перечисление
С помощью этого оператора мы сможем добавить к нашему регулярному выражению для поиска междометий возможность распознавать смех вида «Ахахаах» — единственной усмешке, которая начинается с гласной: [Хх]([аоие])х?(?:\1х?)*|[Аа]х?(?:ах?)+
Полезные сервисы
Потренироваться и/или проверить регулярное выражение на каком-либо тексте без написания кода можно с помощью таких сервисов, как RegExr, Regexpal или Regex101. Последний, вдобавок, приводит краткие пояснения к тому, как регулярка работает.
Разобраться, как работает регулярное выражение, которое попало к вам в руки, можно с помощью сервиса Regexper — он умеет строить понятные диаграмы по регуляркам.
RegExp Builder — визуальный конструктор функций JavaScript для работы с регулярными выражениями.
Больше инструментов можно найти в нашей подборке.
Задания для закрепления
Найдите время
Время имеет формат часы:минуты. И часы, и минуты состоят из двух цифр, пример: 09:00. Напишите RegEx выражение для поиска времени в строке: «Завтрак в 09:00». Учтите, что «37:98» – некорректное время.
Регулярные выражения, пособие для новичков. Часть 1
Регулярные выражения (РВ) это, по существу, крошечный язык программирования, встроенный в Python и доступный при помощи модуля re. Используя его, вы указывается правила для множества возможных строк, которые вы хотите проверить; это множество может содержать английские фразы, или адреса электронной почты, или TeX команды, или все что угодно. С помощью РВ вы можете задавать вопросы, такие как «Соответствует ли эта строка шаблону?», или «Совпадает ли шаблон где-нибудь с этой строкой?». Вы можете также использовать регулярные выражения, чтобы изменить строку или разбить ее на части различными способами.
Шаблоны регулярных выражений компилируются в серии байт-кода, которые затем исполняются соответствующим движком написанным на C. Для продвинутого использования может быть важно уделять внимание тому, как движок будет выполнять данное регулярное выражение, и писать его так, чтобы получался байт-код, который работает быстрее. Оптимизация не рассматривается в этом документе, так как она требует от вас хорошего понимания внутренних деталей движка.
Язык регулярных выражений относительно мал и ограничен, поэтому не все возможные задачи по обработке строк можно сделать с помощью регулярных выражений. Также существуют задачи, которые можно сделать с помощью регулярных выражений, но выражения оказываются слишком сложными. В этих случаях может быть лучше написать обычный Python код, пусть он будет работать медленнее, чем разработанное регулярное выражение, но будет более понятен.
Простые шаблоны
Мы начнем с изучения простейших регулярных выражений. Поскольку регулярные выражения используются для работы со строками, мы начнем с наиболее распространенной задачи — соответствия символов.
За подробным объяснением технической стороны регулярных выражений (детерминированных и недетерминированных конечных автоматов) вы можете обратиться к практически любому учебнику по написанию компиляторов.
Соответствие символов
Из этого правила есть исключения; некоторые символы это специальные метасимволы, и сами себе не соответствуют. Вместо этого они указывают, что должна быть найдена некоторая необычная вещь, или влияют на другие части регулярного выражения, повторяя или изменяя их значение. Большая часть этого пособия посвящена обсуждению различных метасимволов и тому, что они делают.
Вот полный список метасимволов; их значения будут обсуждаться в остальной части этого HOWTO.
Некоторые из специальных последовательностей, начинающихся с ‘\’ представляют предопределенные наборы символов, часто бывающие полезными, такие как набор цифр, набор букв, или множества всего, что не является пробелами, символами табуляции и т. д. (whitespace). Следующие предопределенные последовательности являются их подмножеством. Полный список последовательностей и расширенных определений классов для Юникод-строк смотрите в последней части Regular Expression Syntax.
Эти последовательности могут быть включены в класс символов. Например, [\s,.] является характер класс, который будет соответствовать любому whitespace-символу или запятой или точке.
Повторяющиеся вещи
Возможность сопоставлять различные наборы символов это первое, что регулярные выражения могут сделать и что не всегда можно сделать строковыми методами. Однако, если бы это было единственной дополнительной возможностью, они бы не были так интересны. Другая возможность заключается в том, что вы можете указать какое число раз должна повторяться часть регулярного выражения.
Например, ca*t будет соответствовать ct (0 символов a ), cat (1 символ a ), caaat (3 символа a ), и так далее. Движок регулярных выражений имеет различные внутренние ограничения вытекающие из размера int типа для C, что не позволяет проводить ему сопоставление более 2 миллиардов символов ‘a’. (Надеюсь, вам это не понадобится).
Повторения, такие как * называют жадными (greedy); движок будет пытаться повторить его столько раз, сколько это возможно. Если следующие части шаблона не соответствуют, движок вернется назад и попытается попробовать снова с несколькими повторами символа.
Использование регулярных выражений
Теперь, когда мы рассмотрели несколько простых регулярных выражений, как мы можем использовать их в Python? Модуль re предоставляет интерфейс для регулярных выражений, что позволяет компилировать регулярные выражения в объекты, а затем выполнять с ними сопоставления.
Компиляция регулярных выражений
Регулярные выражения компилируются в объекты шаблонов, имеющие методы для различных операций, таких как поиск вхождения шаблона или выполнение замены строки.
re.compile() также принимает необязательные аргументы, использующихся для включения различных особенностей и вариаций синтаксиса:
>>> p = re.compile(‘ab*’, re.IGNORECASE)
Передача регулярных выражений в виде строки позволяет Python быть проще, но имеет один недостаток, который является темой следующего раздела.
Бэкслеш бедствие
(Или обратная косая чума  )
)
 )
)Как было отмечено ранее, в регулярных выражениях для того, чтобы обозначить специальную форму или позволить символам потерять их особую роль, используется символ бэкслеша ( ‘\’ ). Это приводит к конфликту с использованием в строковых литералах Python такого же символа с той же целью.
Решение заключается в использовании для регулярных выражений «сырых» строк (raw string); в строковых литералах с префиксом ‘r’ слэши никак не обрабатываются, так что r»\n» это строка из двух символов (‘\’ и ‘n’), а «\n» — из одного символа новой строки. Поэтому регулярные выражения часто будут записываться с использованием сырых строк.
| Regular String | Raw string |
| ‘ab*’ | r’ab*’ |
| ‘\\\\section’ | r’\\section*’ |
| ‘\\w+\\s+\\1’ | r’\w+\s+\1′ |
Выполнение сопоставлений
| Метод/атрибут | Цель |
| match() | Определить, начинается ли совпадение регулярного выражения с начала строки |
| search() | Сканировать всю строку в поисках всех мест совпадений с регулярным выражением |
| findall() | Найти все подстроки совпадений с регулярным выражением и вернуть их в виде списка |
| finditer() | Найти все подстроки совпадений с регулярным выражением и вернуть их в виде итератора |
В этом пособии мы используем для примеров стандартный интерпретатор Python:
>>> m = p. match ( ‘tempo’ )
>>> print m
_sre. SRE_Match object at 0x. >
Теперь вы можете вызывать MatchObject для получения информации о соответствующих строках. Для MatchObject также имеется несколько методов и атрибутов, наиболее важными из которых являются:
| Метод/атрибут | Цель |
| group() | Вернуть строку, сошедшуюся с регулярным выражением |
| start() | Вернуть позицию начала совпадения |
| end() | Вернуть позицию конца совпадения |
| span() | Вернуть кортеж (start, end) позиций совпадения |
Так как метод match() проверяет совпадения только с начала строки, start() всегда будет возвращать 0. Однако метод search() сканирует всю строку, так что для него начало не обязательно в нуле:
Два метода возвращают все совпадения для шаблона. findall() возвращает список совпавших подстрок:
Метод findall() должен создать полный список, прежде чем он может быть возвращен в качестве результата. Метод finditer() возвращает последовательность экземпляров MatchObject в качестве итератора.
Функции на уровне модуля
Эти функции просто создают для вас объект шаблона и вызывают соответствующий метод. Они также хранят объект в кэше, так что будущие вызовы с использованием того же регулярного выражения будут быстрее.
Должны вы использовать эти функции или шаблоны с методами? Это зависит от того, как часто будет использоваться регулярное выражение и от вашего личного стиля кодинга. Если регулярное выражение используется только в одном месте кода, то такие функции, вероятно, более удобны. Если программа содержит много регулярных выражений, или повторно использует одни и те же в нескольких местах, то будет целесообразно собрать все определения в одном месте, в разделе кода, который предварительно компилирует все регулярные выражения. В качестве примера из стандартной библиотеки, вот кусок из xmllib.py :
Сам я предпочитаю работать со скомпилированными объектами, даже для одноразового использования, но мало кто окажется таким же пуристом в этом, как я.
Флаги компиляции
IGNORECASE, I
Сопоставление без учета регистра; Например, [A-Z] будет также соответствовать и строчным буквам, так что Spam будет соответствовать Spam, spam, spAM и так далее.
LOCALE, L
Делает \w, \W, \b, \B зависящими от локализации. Например, если вы работаете с текстом на французском, и хотите написать \w+ для того, чтобы находить слова, но \w ищет только символы из множества [A-Za-z] и не будет искать ‘é’ или ‘ç’. Если система настроена правильно и выбран французский язык, ‘é’ также будет рассматриваться как буква.
UNICODE, U
Делает \w, \W, \b, \B, \d, \D, \s, \S соответствующими таблице Unicode.
Пример того, как РВ становится существенно проще читать:
Без verbose это выглядело бы так:
На этом месте мы пока завершим наше рассмотрение. Советую немного отдохнуть перед второй половиной, содержащей рассказ о других метасимволах, методах разбиения, поиска и замены строк и большое количество примеров использования регулярных выражений.
Регулярные выражения для самых маленьких
Меня зовут Виталий Котов и я немного знаю о регулярных выражениях. Под катом я расскажу основы работы с ними. На эту тему написано много теоретических статей. В этой статье я решил сделать упор на количество примеров. Мне кажется, что это лучший способ показать возможности этого инструмента.
Некоторые из них для наглядности будут показаны на примере языков программирования PHP или JavaScript, но в целом они работают независимо от ЯП.
Из названия понятно, что статья ориентирована на самый начальный уровень — тех, кто еще ни разу не использовал регулярные выражения в своих программах или делал это без должного понимания.
В конце статьи я в двух словах расскажу, какие задачи нельзя решить регулярными выражениями и какие инструменты для этого стоит использовать.

Вступление
Регулярные выражения — язык поиска подстроки или подстрок в тексте. Для поиска используется паттерн (шаблон, маска), состоящий из символов и метасимволов (символы, которые обозначают не сами себя, а набор символов).
Это довольно мощный инструмент, который может пригодиться во многих случая — поиск, проверка на корректность строки и т.д. Спектр его возможностей трудно уместить в одну статью.
В PHP работа с регулярными выражениями заключается в наборе функций, из которых я чаще всего использую следующие:
Функции на match возвращают число найденных подстрок или false в случае ошибок. Функция на replace возвращает измененную строку/массив или null в случае ошибки. Результат можно привести к bool (false, если не было найдено значений и true, если было) и использовать вместе с if или assertTrue для обработки результата работы.
В JS чаще всего мне приходится использовать:
Пример использования функций
В PHP регулярное выражение — это строка, которая начинается и заканчивается символом-разделителем. Все, что находится между разделителями и есть регулярное выражение.
Часто используемыми разделителями являются косые черты “/”, знаки решетки “#” и тильды “
”. Ниже представлены примеры шаблонов с корректными разделителями:
Создать регулярное выражение можно так:
Или более короткий вариант:
Пример самого простого регулярного выражения для поиска:
В этом примере мы просто ищем все символы “o”.
В PHP разница между preg_match и preg_match_all в том, что первая функция найдет только первый match и закончит поиск, в то время как вторая функция вернет все вхождения.
Пример кода на PHP:
Пробуем то же самое для второй функции:
В последнем случае функция вернула все вхождения, которые есть в нашем тексте.
Тот же пример на JavaScript:
Модификаторы шаблонов
Для регулярных выражений существует набор модификаторов, которые меняют работу поиска. Они обозначаются одиночной буквой латинского алфавита и ставятся в конце регулярного выражения, после закрывающего “/”.
О том, какие вообще бывают модификаторы, можно почитать тут.
Пример предыдущего регулярного выражения с модификатором на JavaScript:
Метасимволы в регулярных выражениях
Примеры по началу будут довольно примитивные, потому что мы знакомимся с самыми основами. Чем больше мы узнаем, тем ближе к реалиям будут примеры.
Чаще всего мы заранее не знаем, какой текст нам придется парсить. Заранее известен только примерный набор правил. Будь то пинкод в смс, email в письме и т.п.
Первый пример, нам надо получить все числа из текста:
Чтобы выбрать любое число, надо собрать все числа, указав “[0123456789]”. Более коротко можно задать вот так: “3”. Для всех цифр существует метасимвол “\d”. Он работает идентично.
Но если мы укажем регулярное выражение “/\d/”, то нам вернётся только первая цифра. Мы, конечно, можем использовать модификатор “g”, но в таком случае каждая цифра вернется отдельным элементом массива, поскольку будет считаться новым вхождением.
Для того, чтобы вывести подстроку единым вхождением, существуют символы плюс “+” и звездочка “*”. Первый указывает, что нам подойдет подстрока, где есть как минимум один подходящий под набор символ. Второй — что данный набор символов может быть, а может и не быть, и это нормально. Помимо этого мы можем указать точное значение подходящих символов вот так: “
Сейчас будет пара примеров, чтобы это уложилось в голове:
Примерно так же мы работает с буквами, не забывая, что у них бывает регистр. Вот так можно задавать буквы:
Такое выражение выберет все слова, которые есть в предложении и написаны кириллицей. Нам нужно третье слово.
Помимо букв и цифр у нас могут быть еще важные символы, такие как:
Если мы точно знаем, что искомое слово последнее, мы ставим “$” и результатом работы будет только тот набор символов, после которого идет конец строки.
То же самое с началом строки:
Прежде, чем знакомиться с метасимволами дальше, надо отдельно обсудить символ “^”, потому что он у нас ходит на две работы сразу (это чтобы было интереснее). В некоторых случаях он обозначает начало строки, но в некоторых — отрицание.
Это нужно для тех случаев, когда проще указать символы, которые нас не устраивают, чем те, которые устраивают.
Допустим, мы собрали набор символов, которые нам подходят: “[a-z0-9]” (нас устроит любая маленькая латинская буква или цифра). А теперь предположим, что нас устроит любой символ, кроме этого. Это будет обозначаться вот так: “[^a-z0-9]”.
Выбираем все “не пробелы”.
Итак, вот список основных метасимволов:
Операторы [] и ()
По описанному выше можно было догадаться, что [] используется для группировки нескольких символов вместе. Так мы говорим, что нас устроит любой символ из набора.
Тут мы собрали в группу (между символами []) все латинские буквы и пробел. При помощи <> указали, что нас интересуют вхождения, где минимум 2 символа, чтобы исключить вхождения из пустых пробелов.
Аналогично мы могли бы получить все русские слова, сделав инверсию: “[^A-Za-z\s]<2,>”.
В отличие от [], символы () собирают отмеченные выражения. Их иногда называют “захватом”.
Они нужны для того, чтобы передать выбранный кусок (который, возможно, состоит из нескольких вхождений [] в результат выдачи).
Существует много решений. Пример ниже — это приближенный вариант, который просто покажет возможности регулярных выражений. На самом деле есть RFC, который определяет правильность email. И есть “регулярки” по RFC — вот примеры.
Мы выбираем все, что не пробел (потому что первая часть email может содержать любой набор символов), далее должен идти символ @, далее что угодно, кроме точки и пробела, далее точка, далее любой символ латиницы в нижнем регистре…
Получилось! Но что, если теперь нам надо по отдельности получить домен и имя по email? И как-то использовать дальше в коде? Вот тут нам поможет “захват”. Мы просто выбираем, что нам нужно, и оборачиваем знаками (), как в примере:
В массиве match нулевым элементом всегда идет полное вхождение регулярного выражения. А дальше по очереди идут “захваты”.
В PHP можно именовать “захваты”, используя следующий синтаксис:
Тогда массив матча станет ассоциативным:
Это сразу +100 к читаемости и кода, и регулярки.
Примеры из реальной жизни
Парсим письмо в поисках нового пароля:
Есть письмо с HTML-кодом, надо выдернуть из него новый пароль. Текст может быть либо на английском, либо на русском:
Сначала мы говорим, что текст перед паролем может быть двух вариантов, использовав “или”.
Вариантов можно перечислять сколько угодно:
Далее у нас знак двоеточия и один пробел:
А дальше нас интересует все, что не символ “
Регулярные выражения
Сейчас регулярные выражения используются многими текстовыми редакторами и утилитами для поиска и изменения текста на основе выбранных правил. Многие языки программирования уже поддерживают регулярные выражения для работы со строками. Например, Perl и Tcl имеют встроенный в их синтаксис механизм обработки регулярных выражений. Набор утилит (включая редактор sed и фильтр grep), поставляемых в дистрибутивах Unix, одним из первых способствовал популяризации понятия регулярных выражений.
Содержание
Базовые понятия [ править ]
Регулярные выражения используются для сжатого описания некоторого множества строк с помощью шаблонов, без необходимости перечисления всех элементов этого множества. При составлении шаблонов используется специальный синтаксис, поддерживающий обычно следующие операции:
Конкретный синтаксис регулярных выражений зависит от реализации.
В теории формальных языков [ править ]
Регулярные выражения состоят из констант и операторов, которые определяют множества строк и множества операций на них соответственно. На данном конечном алфавите Σ определены следующие константы:
и следующие операции:
Многие книги используют символы ∪, + или ∨ для перечисления вместо вертикальной черты.
Синтаксис [ править ]
Традиционные регулярные выражения в Unix [ править ]
Синтаксис «базовых» регулярных выражений Unix на данный момент определён POSIX как устаревший, но он до сих пор широко распространён из соображений обратной совместимости. Многие Unix-утилиты используют такие регулярные выражения по умолчанию.
В этом синтаксисе большинство символов соответствуют сами себе («a» соответствует «a» и т. д. ). Исключения из этого правила называются метасимволами:
| . | Соответствует любому единичному символу. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| [ ] | Соответствует любому единичному символу из числа заключённых в скобки. Символ «-» интерпретируется буквально только в том случае, если он расположен непосредственно после открывающей или перед закрывающей скобкой: [abc-] или [-abc]. В противном случае, он обозначает интервал символов. Например, [abc] соответствует «a», «b» или «c». [a-z] соответствует буквам нижнего регистра латинского алфавита. Эти обозначения могут и сочетаться: [abcq-z] соответствует a, b, c, q, r, s, t, u, v, w, x, y, z. Чтобы установить соответствие символам «[» или «]», достаточно, чтобы закрывающая скобка была первым символом после открывающей: [][ab] соответствует «]», «[», «a» или «b». Различные реализации регулярных выражений интерпретируют обратную косую черту перед метасимволами по-разному. Например, egrep и Perl интерпретируют скобки и вертикальную черту как метасимволы, если перед ними нет обратной косой черты и воспринимают их как обычные символы, если черта есть. Многие диапазоны символов зависят от выбранных настроек локализации. POSIX стандартизовал объявление некоторых классов и категорий символов, как показано в следующей таблице:
Защита метасимволов [ править ]«Жадные» выражения [ править ]Квантификаторам в регулярных выражениях соответствует максимально длинная строка из возможных (квантификаторы являются «жадными», англ. greedy). Это может оказаться значительной проблемой. Например, часто ожидают, что выражение ( ) найдёт в тексте теги HTML. Однако этому выражению соответствует целиком строка Википедия — свободная энциклопедия, в которой каждый может изменить или дополнить любую статью Эту проблему можно решить двумя способами. Первый состоит в том, что в регулярном выражении учитываются символы, не соответствующие желаемому образцу ( ]*> для вышеописанного случая). Второй заключается в определении квантификатора как нежадного (ленивого, англ. lazy)— большинство реализаций позволяют это сделать, добавив после него знак вопроса. Например, выражению ( ) соответствует не вся показанная выше строка, а отдельные теги (выделены цветом): Википедия — свободная энциклопедия, в которой каждый может изменить или дополнить любую статью Использование «ленивых» квантификаторов, правда, может повлечь за собой обратную проблему, когда выражению соответствует слишком короткая строка. Также существуют квантификаторы повышения жадности, то, что захвачено ими однажды, назад уже не отдается. Сверхжадные квантификаторы (possessive quantifiers) Современные (расширенные) регулярные выражения в POSIX [ править ]Регулярные выражения в POSIX аналогичны традиционному Unix-синтаксису, но с добавлением некоторых метасимволов:
Также было отменено использование обратной косой черты: \ <…\>становится <…>и \(…\) становится (…). Perl-совместимые регулярные выражения (PCRE) [ править ]Регулярные выражения в Perl имеют более богатый и в то же время предсказуемый синтаксис, чем даже в POSIX. По этой причине очень многие приложения используют именно Perl-совместимый синтаксис регулярных выражений. Не пропустите наши новые статьи: Подписаться авторизуйтесь 0 комментариев Старые |