
О репозиториях замолвите слово

В последнее время на хабре, и не только, можно наблюдать интерес GO сообщества к луковой/чистой архитектуре, энтерпрайз паттернам и прочему DDD. Читая статьи на данную тему и разбирая примеры кода, постоянно замечаю один момент — когда дело доходит до хранения сущностей предметной области — начинается изобретение своих велосипедов, которые зачастую еле едут. Код вроде бы состоит из набора паттернов: сущности, репозитории, value object’ы и так далее, но кажется, что они для того там “чтобы были”, а не для решения поставленных задач.
В данной статье я бы хотел не только показать, что, по моему мнению, не так с типичными DDD-примерами на GO, но также продемонстрировать собственную ORM для реализации персистентности доменных сущностей.
Дисклеймер
Прежде чем приступить к теме статьи, есть несколько моментов, которые необходимо осветить:
А теперь — можно начинать.
Энтерпрайз паттерны в GO и что с ними не так
Речь здесь пойдет о таких паттернах как: репозиторий, сущность, агрегат и способах их приготовления. Для начала, давайте разберемся, что же это за паттерны такие. Я не буду придумывать определения в стиле “от себя”, а буду использовать слова признанных мастеров: Ерика Эванса и Мартина Фаулера.
Сущность
Начнем с сущности. По Эвансу:
Entity: Objects that have a distinct identity that runs through time and different representations. You also hear these called «reference objects».
Ну тут вроде бы ничего сложного, сущности в GO можно реализовать, используя структуры. Вот типичный пример:
Агрегат
А вот про этот шаблон как то незаслуженно забывают, особенно в контексте GO. А забывают, между прочим, абсолютно зря. Чуть позже мы разберем почему агрегаты намеренно не используются в различных примерах DDD проектов на GO. Итак, определение по Эвансу:
Cluster the entities and value objects into aggregates and define boundaries around each. Choose one entity to be the root of each aggregate and control all access to the objects inside the boundary through the root
Рассмотрим пример aggregate root:
Тут у нас агрегат “пользователь”, который включает в себя сущность User, а также набор желаний этого пользователя и набор друзей.
Ну пока все ок, скажете вы, разве есть какие-то проблемы с реализацией? Я считаю — есть, перейдем к репозиториям.
Репозиторий
A Repository mediates between the domain and data mapping layers, acting like an in-memory domain object collection. Client objects construct query specifications declaratively and submit them to Repository for satisfaction. Objects can be added to and removed from the Repository, as they can from a simple collection of objects, and the mapping code encapsulated by the Repository will carry out the appropriate operations behind the scenes. Conceptually, a Repository encapsulates the set of objects persisted in a data store and the operations performed over them, providing a more object-oriented view of the persistence layer. Repository also supports the objective of achieving a clean separation and one-way dependency between the domain and data mapping layers.
Определение емкое, поэтому выделю основные моменты:
Давайте рассмотрим типичный для GO пример репозитория и как он используется:
Вопросы, которые сразу же возникают для таких репозиториев:
Обычно в примерах GO кода такие вопросы принято “обходить” всеми возможными способами:
А как насчет схожести интерфейса репозитория к интерфейсу GO-коллекций? Ниже представлен пример работы с коллекцией пользователей реализованной через slice:
Как видите, эквивалент методу Update для слайса users просто не требуется, потому, что изменения внесенные в агрегат User применяются сразу же.
Обобщим проблемы, которые не дают DDD-like GO коду быть достаточно выразительным, тестируемым и вообще классным:
D3 ORM. Зачем оно мне?
Хм, похоже что написать свою ORM не самая плохая идея, что я и сделал. Рассмотрим как же она помогает решить описанные выше проблемы. Для начала, как выглядит сущность Wish и агрегат User:
Как видите изменений не много, но они есть. Во первых — появились аннотации, с помощью которых описывается мета-информация (имя таблицы в БД, маппинг полей структуры на поля в БД, индексы). Во вторых — вместо обычных для GO коллекций — slice’ов D3 ORM накладывает требования на использование своих коллекций. Данное требование исходит из желания иметь фичу lazy/eager loading. Можно сказать, что, если не брать в расчет кастомные коллекции, то описание бизнес сущностей делается полностью нативными средствами.
Ну что ж, а теперь перейдем непосредственно к тому, как выглядят работа с репозиториями в D3ORM:
Итого получаем решение которое, на сколько это возможно, повторяет интерфейс встроенных в GO коллекций. С одной маленькой ремаркой: после того, как мы выполнили все манипуляции, необходимо синхронизировать изменения с базой данных:
Если вы работали с такими инструментами как: hybernate или doctrine то, для вас это не будет неожиданностью. Так же для вас не должно быть неожиданностью то, что вся работа выполняется в рамках логических транзакций — сессий. Для удобства работы с сессиями в D3 ORM есть ряд функций, которые позволяют положить и вынуть их из контекста.
Разберем еще некоторые примеры кода для демонстрации тех или иных фич:
Подробно о том, как работать с ORM, есть документация, а также демо проект. Краткий список фич:
А зачем оно вам?
Резюмируя, чем вам может быть полезна D3 ORM:
В противном случае не могу советовать использовать D3 ORM.
А еще бы хотел описать случаи, где, по моему мнению, использовать любую ORM плохая идея:
Заключение
Надеюсь данной статьей мне удалось хотя бы немного поставить под сомнение типичный GO-style написания бизнес логики. Кроме того, я постарался показать и альтернативу этому подходу. В любом случае решать, как писать код, вам, ну что ж, удачи в этом нелегком деле!
GitHub
GitHub — это сервис для совместной разработки и хостинга проектов. C помощью GitHub над кодом проекта может работать неограниченное количество программистов из любых точек мира. В GitHub есть система контроля (управления) версий Git: сервис позволяет просматривать и контролировать любые изменения кода любым разработчиком и возвращаться к состоянию до изменений.
В целом GitHub — это социальная сеть для разработчиков, в которой можно найти проекты с открытым кодом от других разработчиков, практиковаться в написании кода и хранить свое портфолио.
Проекты в GitHub
Проект в GitHub хранится в репозитории (repository) — коллекции всех изменений создаваемого кода. Если вы будете работать над проектом в одиночку — вам нужно создать новый репозиторий. Если в вашем проекте несколько разработчиков — каждый из них будет клонировать репозиторий первоначального создателя проекта.
Внутри репозитория изменения кода хранятся в виде веток и коммитов.

Коммит (commit) — основной объект разработки, в котором хранятся все изменения кода за итерацию. По сути, это список со всеми актуальными изменениями и ссылка на предыдущую версию коммита. У каждого коммита есть атрибуты: имя, дата создания, автор и комментарии к текущей версии (например, «Создал страницу courses.html» при разработке сайтов с видеокурсами).
Ветка (branch) — указатель на коммит с определенными изменениями. Например, два разработчика взяли коммит, и каждый из них сделал свои изменения в коде, создав по новому коммиту («Создал страницу coursеs.html c личным кабинетом» и «Создал страницу courses.html со свободным доступом на курсы»). Так в проекте появились две ветки с разным кодом: разработчик может выбрать, над каким коммитом ему работать дальше.
Основной веткой проекта, как правило, считается ветка main или master — разработчики создают новые ветки на ее основе. Также можно создать неограниченное количество веток, чтобы вносить новые изменения, не мешая основному проекту.
Слияние веток
Часто разработчики делают параллельные изменения кода. Например, один разработчик работает над внешним видом сайта, а другой занимается размещением контента на нем. По окончании работы ветки каждого из них можно объединить в одну, чтобы создать коммит со всеми внесенными разработчиками изменениями.
Для этого в Git используют функцию pull request (pr). Pull request — это заявка на слияние кода из разных веток. В процессе слияния Git создаст коммит и покажет все изменения в файле кода: добавленные до разветвления строки подсветятся зеленым цветом, удаленные — красным. Так каждый из разработчиков и менеджер проекта увидят, что произошло с кодом после совместной работы над коммитом. Перед окончательным слиянием (merge) все разработчики должны просмотреть изменения кода (code review) и принять их.
Изучите с нуля алгоритмы и структуры данных, поработайте с Git и станьте востребованным специалистом. Дополнительная скидка 5% по промокоду BLOG.
Процесс pull request
Теперь посмотрим на процесс со стороны владельца проекта, который получил новый pull request. Владельцу нужно его обработать и объединить ветку sme-review с master.

Пример ревью кода, где есть разрешение на слияние в главную ветку

Пример ревью кода, где нет разрешения на слияние

Ревью кода
Ревью кода (code review) — процесс обсуждения изменений кода после совместного создания коммита и перед окончательным слиянием. В ревью разработчики оставляют комментарии к строкам с измененным кодом, а в случае ошибок или упущенных моментов предлагают решения по улучшению кода.
После ревью разработчики должны закрыть комментарии и принять предлагаемые изменения (функция approve). Git объединит ветки с помощью функции merge и перенесет созданный коммит в основную ветку main. В истории коммитов останется отметка о проведенном слиянии веток.

Как учиться работе в GitHub
GitHub — самый популярный сервис для разработки проектов в команде и хранения портфолио собственных проектов. Научиться работе с Git и GitHub необходимо каждому разработчику. Вот несколько материалов, которые помогут новичкам в разработке освоить GitHub:
Освойте перспективную профессию с нуля за 14 месяцев.
Core Data + Repository pattern. Детали реализации
Немного про репозиторий
Таким образом, к его преимуществам можно отнести:
отсутствие зависимостей от реализации репозитория. Под капотом может быть все, что угодно: коллекция в оперативной памяти, UserDefaults, KeyChain, Core Data, Realm, URLCache, отдельный файл в tmp и т.п.;
разделение зон ответственности. Репозиторий выступает прослойкой между бизнес-логикой и способом хранения данных, отделяя одно от другого;
формирование единого, более структурированного подхода в работе с данными.
В конечном итоге, все это благоприятно сказывается на скорости разработки, возможностях масштабирования и тестируемости проектов.
Ближе к деталям
Рассмотрим самый неблагоприятный сценарий использования Core Data.
1. Core Data как один большой репозиторий с NSManagamentObject
Идея оперировать NSManagedObject в качестве доменного объекта самая простая, но не самая удачная. При таком подходе перед нами встают сразу несколько проблем:
Используя единый репозиторий для всех Data Provider, он будет разрастаться с появлением новых доменных объектов;
В худшем случае, логика работы с объектами начнет пересекаться между собой и это может превратиться в один большой непредсказуемый magic.
2. Core Data + DB Client
Первое, что приходит на ум, для решения проблем из предыдущего примера, это вынести логику работы с объектами в отдельный класс (назовем его DB Client), тогда наш Repository будет только сохранять и доставать объекты из хранилища, в то время, как вся логика по работе с объектами ляжет в DB Client. На выходе должно получиться что-то такое:
 Рисунок 2
Рисунок 2
Обе схемы решают проблему №1. (Core Data ограничивается DB Client и Repository), и частично могут решить проблему №2 и №3 на небольших проектах, но не исключают их полностью. Продолжая мысль дальше, возможно придти к следующей схеме:
Рисунок 3
Core Data можно ограничить только репозиторием. DB Client конвертирует доменные объекты в NSManagedObject и обратно;
Repository больше не единый и он не разрастается;
Логика работы с данными более структурирована и консолидирована
Подготовка к реализации
В первую очередь, таким я вижу репозиторий:
Доменный объект, которым оперирует репозиторий;
Возможность подписаться на отслеживание изменений в репозитории;
Сохранение объектов в репозиторий;
Сохранение объектов с возможностью очистки старых данных в рамках одного контекста;
Загрузка данных из репозитория;
Удаление объектов из репозитория;
Удаление всех данных из репозитория.
Возможно, ваш набор требований к репозиторияю будет отличаться, но концептуально ситуацию это не изменит.
К сожалению, возможность работать с репозиторием через AccessableRepository отсутствует, о чем свидетельствует ошибка на рисунке 4:
Рисунок 4
В таком случае, хорошо подходит Generic-реализация репозитория, которая выглядит следующим образом:
NSObject нужен для взаимодействия с NSFetchResultController;
FatalError играет роль предохранителя, чтобы всяк сюда входящий не использовал то, что не реализовано;
Данное решение позволяет не привязываться к конкретной реализации, а также обойти предыдущую проблему:
Рисунок 5
Для работы с выборкой объектов потребуются объект с двумя свойствами:
Контекст, с которым работает main Queue, необходим для использования NSFetchedResultsController;
Требуется для выполнения операций с данными в фоновом потоке. Можно заменить на newBackgroundContext(). Про различия в работе этих двух методов можно прочитать тут.
Также, потребуются объекты, которые будут осуществлять конвертацию (мапинг) доменных моделей в объекты репозитория (NSManagedObject) и обратно:
Позволяет конвертировать NSManagedObject в доменную модель;
Позволяет обновить NSManagedObject с помощью доменной модели;
Когда-то, я использовал доменный объект, в качестве инициализатора NSManagedObject. С одной стороны, это было удобно, с другой стороны накладывало ряд ограничений. Например, когда использовались связи между объектами и один NSManagedObject создавал несколько других NSManagedObject. Такой подход размывал зоны ответственности и негативно сказывался на общей логике работы с данными.
Во время работы с репозиторием потребуется обрабатвать ошибки, для этого достаточно enum:
Реализация
Для данного примера, подойдет простая реализация DBContextProvider (без каких-либо дополнительных параметров):
Раньше такой подход избавлял от утечек памяти;
Основная составляющая репозитория выглядит следующим образом:
Cвойство, которое будет использовать при работе с NSFetchRequest;
Чтобы не порождать однотипный код для работы с контекстом, потребуется вспомогательный метод:
Сохранение изменений в persistent store;
Если изменения объектов отсутствуют, в completion-блок передается соответствующая ошибка.
Сохранение объектов реализовано следующим образом:
Используется при необходимости удалить объекты, перед сохранением новых (в рамках текущего контекста);
Выполняется выгрузка объектов, которые существуют в репозитории, для их дальнейшего изменения;
Если объект с нужным entityAccessorKey отсутствует, создается новый экземпляр NSManagedObject;
Выполнение мапинга свойств из доменного объекта в NSManagedObject;
Применение выполненных изменений.
Важно: Возможно вас смутил п.2., данное решение оптимально на небольших наборах данных. Я выполнял замеры (ExampleCase3 в демо-проекте) на 10 000 записей, iPhone 6s Plus IOS 12.4.1 и получил следующие результаты:
время записи/перезаписи данных от 0,9 до 1.8 сек, cкачок потребления оперативной памяти в пике до 33 мб;
если убрать код в п2 и оставить только вставку новых объектов, то время записи/перезаписи данных +- 20 сек, cкачок потребления оперативной памяти в пике до 50 мб.
Для больших наборов данных я бы рекомендовал разделять их на части, использовать batchUpdate и batchDelete, а начиная с IOS 13 появился batchInsert.
Таким образом, реализация методов save cводится к вызову метода saveIn:
Методы present, delete, eraseAllData завязаны на работе с NSFetchRequest. В их реализации нет ничего особенного, поэтому не вижу смысла заострять на них внимание:
Выборка объектов и их обработка;
Вовзрат результата операции.
Для реализации возможности отслеживания изменений данных в реальном времени, потребуется FetchedResultsController. Для его конфигурации используется следующий метод:
Формирование запроса, на основании которого будут отслеживаться изменения;
Создание экземпляра класса NSFetchedResultsController;
performFetch() позволяет выполнить запрос и получить данные, не дожидаясь изменений в базе. Например, это может быть полезно при реализации Ofline First;
Изменение свойства searchedData, в свою очередь уведомляет подписчиков (если такие имеются) об изменении.
Заключение
На этом этапе реализация всех основных методов для работы с репозиторием подходит к концу. Для меня основными преимуществами данного подхода стало следующее:
логика работы репозитория с Core Data стала везде единая;
для добавления новых объектов в репозиторий, достаточно создать только EntityMapper (новое Entity требуется создать в любом случае). Вся логика по мапингу свойств также собрана в одном месте;
Data слой стал более структурированным. Теперь можно точно гарантировать, что репозиторий не выполняет 100500 запросов в методе сохранения, чтобы проставить связи между объектами;
репозиторий легко можно подменить, например для тестов, или для отладки.
Спасибо за внимание! Легкого кодинга, поменьше багов, побольше фич!
Скользящая ответственность паттерна Репозиторий
В ходе многих дискуссий о применимости паттерна Repository я заметил, что люди разделены на два лагеря. В рамках этого текста я, условно, их назову абстракционистами и конкретистами. Разница между ними заключается в том, как они относятся к значению паттерна. Первые считают, что репозиторй стоит иметь, т.к. он позволяет абстрагироваться от деталей хранения данных. Вторые считают, что мы не можем полностью абстрагироваться от этих деталей, поэтому сама идея репозитория бессмыслена, а его использование пустая трата времени. Спор между ними обычно превращается в холивар.
Что не так с репозиторием? Очевидно, что с самим паттерном все нормально, но разница в его понимании разработчиками. Я попробовал исследовать это и наткнулся на два основных момента, которые, на мой взгляд, являются причиной разного к нему отношения. Одним из них является «скользящая» ответственность репозитория, а другой связан с недооценкой unit testing. Под катом я объясню первый.
Скользящая Ответственность Репозитория
Когда речь заходит о построении архитектуры приложения у всех в голове сразу возникает представление о трех слоях: слой представления (Presentation Layer), бизнес логики (Business Layer) и слой данных (Data Layer) (см MSDN). В таких системах объекты бизнес логики используют репозитории для извлечения данных из физических хранилищ. Репозитории возвращают бизнес-сущности вместо сырых рекордсетов. Очень частно это обосновывается тем, что если бы нам нужно было заменить тип физического хранилища (база, файл или сервис), то мы сделали бы абстрактный класс репозитория и реализовали бы специфичный для нужного нам хранилища. Выглядит примерно так:
О таком же разделении говорит Мартин Фаулер и MSDN. Как обычно, описание — это, всего лишь, упрощенная модель. Поэтому, хотя это выглядит правильно для небольшого проекта, это вводит в заблуждение, когда вы пытаетесь перенести этот паттерн на более сложный. Существующие ORM еще сильнее сбивают с толку, т.к. реализуют многие вещи из коробки. Но представим, что разработчик знает только как использовать Entity Framework (или другой ORM) только для получения даных. Куда, например, он должен поместить кеш второго уровня, или логирование всех бизнес-операций? В попытке сделать это, очевидно, что он будем стараться разделить модули по функционалу, следую SPR из SOLID, и построить из них композицию, которая, возможно, будет выглядеть так:
Выполняет ли репозиторий ту же роль, что и ранее? Очевидный ответ «НЕТ», так как теперь он не извлекает данные из хранилища. Эта ответственность была перенесена в другой объект. На этой почве возникает первая нестыковка между лагерями абстракционистов и конкретистов.
Вместо анализа
Если принять за правило, что все термины должна сохранять свое значение вне зависимости от модификаций кода, то было бы правильно на первом этапе не называть репозиторием объект, который просто возвращает данные. Это DAO паттерн чистой воды, т.к. его задача спрятать конкретный интерфейс доступа к данным (ling, ADO.NET, или что-то еще). В то же время репозиторий может не знать о таких деталях вообще ничего, собирая в единую композицию все подсистемы доступа к данным.
Считаете ли вы, что такая проблема существет?
Паттерн Репозиторий – Object-Relational Metadata Mapping Patterns (PoEAA)
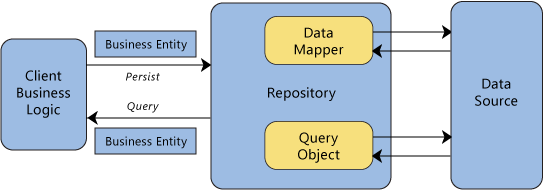
Репозиторий — это посредник между domain слоем и mapping слоем, используя интерфейс, схожий с коллекциями для доступа к объектам области определения.
Стоит отметить, что есть 2 подхода к реализации репозитория, первый из них GenericRepository который выступает посредником достаточного уровня абстракции для всех данных (таблиц базы данных). И репозиторий для каждого типа данных который еще часто реализуется вместе с Unit of Work паттерном.
GenericRepository
Реализация GenericRepository выглядит так:
Какие плюсы от GenericRepository?
В чем минусы такого подхода?
Если вы пишите что-то больше чем просто CRUD операции, то каждый из бизнес-объектов будет обладать своим списком доступного функционала. Например метод удаления объекта, или добавления, может быть недоступен для этого типа объектов, при реализации через GenericRepository мы даем доступ всех Crud операций для этого типа объектов. Так же стоит отметить, что если нам нужно кастомизировать наш запрос, вызывая FindBy у нас может быть довольно большая простыня LINQ. Иногда очень сложно разобраться в таком запросе. Конечно можно называть переменную так, чтобы она наталкивала на мысль что делает тот или иной запрос, но все же гораздо лучше использовать специализированный репозиторий для каждого из типов данных.
Repository
Реализация интерфейса такого типа данных может выглядеть вот так:
Такого типа репозиторий часто еще используют в связке с другим паттерном PoeAA — Unit of Work
Репозиторий и спецификация
Еще один паттерн с которым связывают репозиторий, паттерн который пришел к нам с парадигмы DDD — спецификация.
Подробнее паттерн спецификация я раскрываю в этой статье, по этому не будем сейчас останавливаться на деталях, лишь скажу что этот паттерн призван решить проблему с DRY и структурировать работу с фильтрами.
Итоги:
Как всегда нет универсального решения для всего. Каждый подход имеет свои преимущества и недостатки, если вы строите CRUD систему (например админку) GenericRepository может стать хорошим решением. Если же у вас bounded context, или бизнес-логика требует более точечной реализации, то репозиторий, или репозиторий в комбинации спецификацией может стать тем решением которое вам нужно.