
Как создать снимок системы в Linux Mint? Создание резервной копии системы и ее восстановление
Сегодня я расскажу, как можно создать снимок системы, т.е. резервную копию системы в дистрибутиве Linux Mint, а также мы разберем процесс восстановления системы из резервной копии.
Если Вы часто вносите изменения в настройки операционной системы Linux Mint или устанавливаете различные программы, неважно с какой целью, то скорей всего Вы хотите в случае какого-либо сбоя в работе системы иметь возможность откатиться назад, т.е. восстановить систему на определённый момент времени до Ваших действий, которые и стали причиной этого сбоя, это могут быть некорректные настройки или установленное приложение.

В Linux Mint есть такая возможность, благодаря приложению TimeShift, которое умеет создавать снимки системы (включая личные файлы) и восстанавливать ее из этих снимков.
TimeShift – это что-то наподобие компонента System Restore («Восстановление системы») в Windows, которое также создает копию системы и восстанавливает систему из этой копии.
В дистрибутиве Linux Mint TimeShift установлен по умолчанию, поэтому если у Вас операционная система Linux Mint, Вы можете пользоваться этим инструментом, иными словами, дополнительно устанавливать ничего не нужно.
На самом деле иметь возможность восстановить систему из резервной копии — это просто здорово, и я рекомендую периодически делать резервные копии (снимки) системы, чтобы в случае какого-либо сбоя откатиться назад. Даже разработчики дистрибутива Linux Mint перед любым обновлением системы рекомендуют сначала создать снимок системы, а уже потом переходить, казалось бы, к безобидной стандартной процедуре обновления.
Итак, давайте я на примере покажу, как создать снимок системы в Linux Mint с помощью приложения TimeShift.
Запуск и настройка TimeShift
Примечание! В примере используется версия Linux Mint 19.1 со средой Cinnamon. О том, как установить операционную систему Linux Mint на компьютер, можете почитать в материале «Linux Mint 19 – установка и обзор дистрибутива».
Данная процедура требует прав администратора, поэтому после запуска сразу появится окно для ввода пароля администратора. Вводим и жмем «Authenticate».
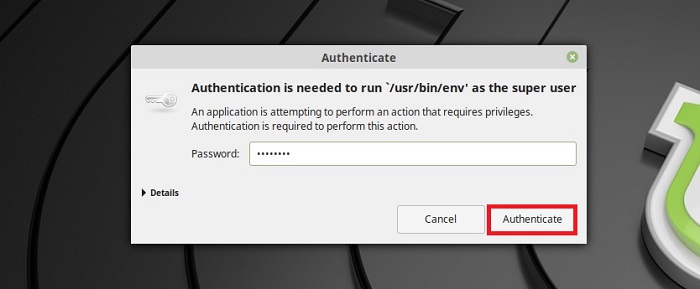
Если Вы впервые запускаете инструмент создания снимков TimeShift, то у Вас сразу запустится мастер, который поможет Вам настроить приложение на создание снимков системы.
Сначала выбираем тип снимков, если у Вас файловая система Ext4, то выбирайте первый тип «RSYNC», а если Вы используете файловую систему BTRFS, то выбирайте одноименной пункт. Нажимаем «Далее».
Потом программа проанализирует систему.
Затем необходимо указать место для хранения снимков, точнее, раздел диска, лучше указывать не системный раздел, а тот, на котором побольше места. Рекомендовано даже хранить снимки на отдельных внешних дисках, для особо важных систем, это, конечно же, правильно. Выбираем и нажимаем «Далее».
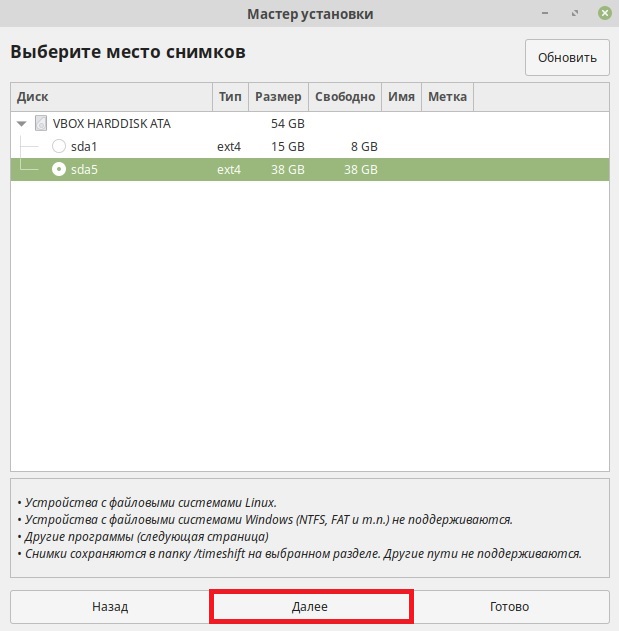
Далее нам предлагают настроить расписание создания снимков, например, ежедневно или раз в неделю, эта возможность позволяет в автоматическом режиме создавать снимки системы Linux Mint на постоянной основе. Здесь Вы также можете указать, сколько снимков нужно хранить, т.е., например, если указать 5, то тогда, когда будет создаваться 6 снимок, самый первый будет удален, таким образом, инструмент будет хранить 5 самых последних снимков, что позволяет контролировать занимаемое место снимками на диске.
Вносим настройки, которые Вас устраивают, и нажимаем «Далее».
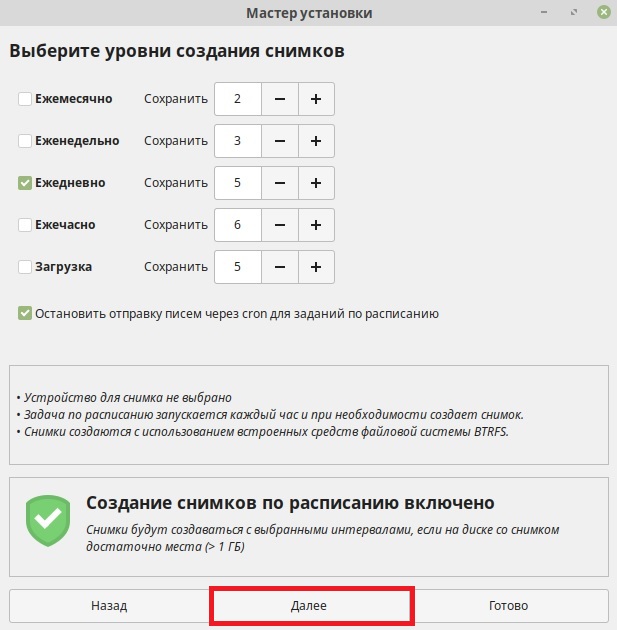
После идут настройки, с помощью которых мы можем указать, что в снимки необходимо включать домашние каталоги пользователей, так как по умолчанию данная возможность не используется, ведь многие пользовательские файлы изменяются с течением времени, а в случае восстановления мы можем потерять эти корректные изменения, да и просто, если включать в снимок все пользовательские файлы, размер снимка может быть очень большим. Поэтому здесь решать Вам, если хотите — включайте, если не хотите — оставляйте по умолчанию.
Настройка TimeShift закончена, нажимаем «Готово».
Создание снимка системы в Linux Mint
После того как TimeShift мы настроили, можно создать свой первый снимок системы Linux Mint. Для этого нажимаем на кнопку «Создать».
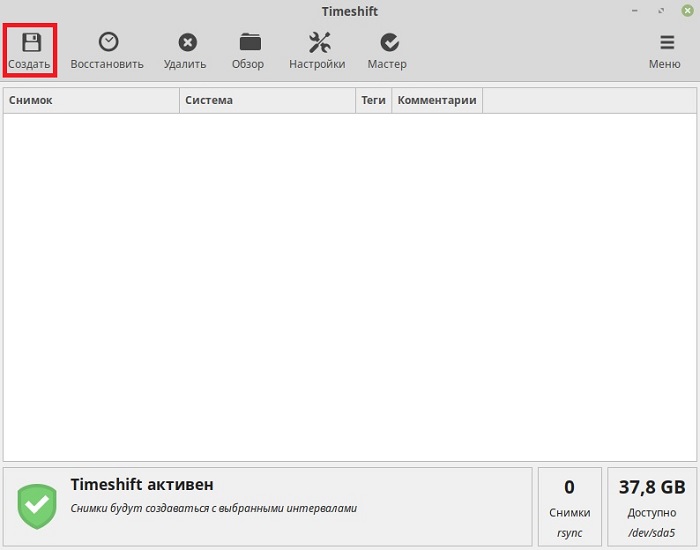
Начнется процесс создания снимка системы.
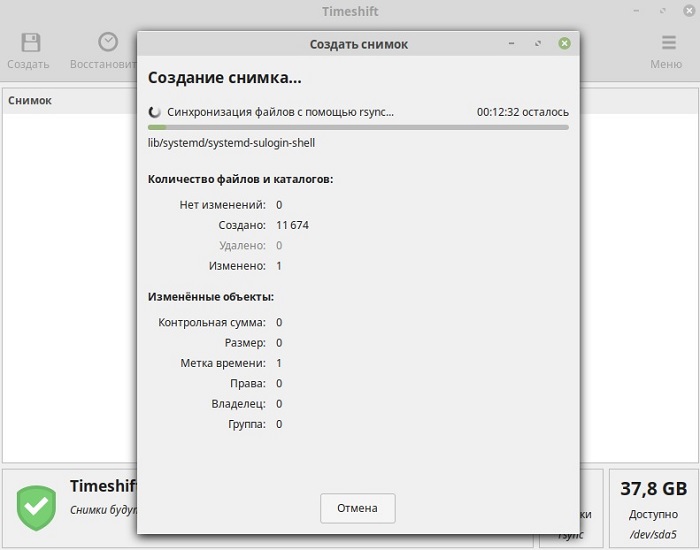
Когда данный процесс будет завершен, в программе TimeShift в списке снимков отобразится новый пункт.
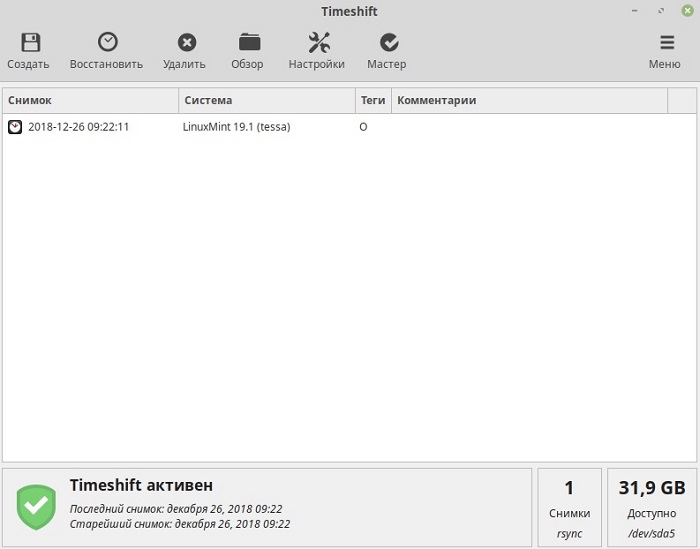
Восстановление системы Linux Mint из резервной копии
Теперь давайте я покажу, как восстановить систему из снимка. Для этого выбираем нужный снимок в списке и нажимаем кнопку «Восстановить».
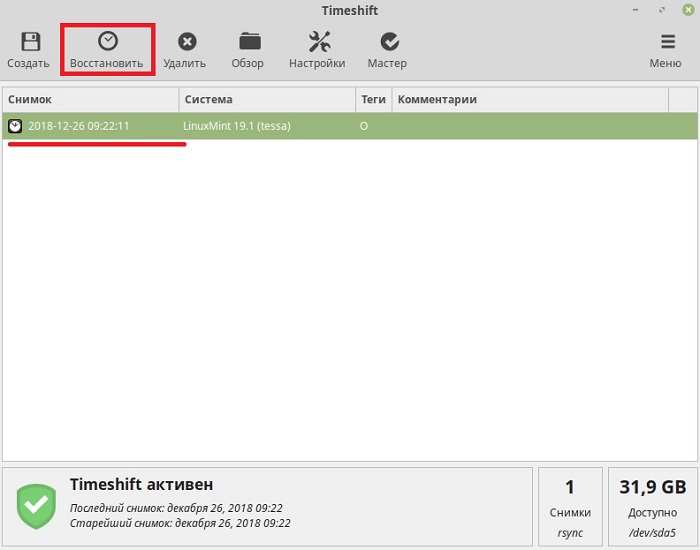
Указываем раздел для восстановления и раздел, на котором расположен снимок. По умолчанию указаны разделы, с которых был создан снимок, т.е. в нашем случае так и оставляем. Нажимаем «Далее».
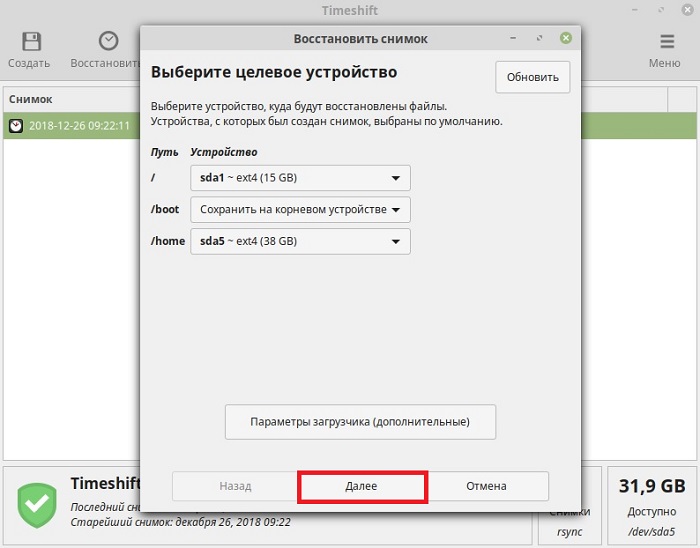
Затем программа проанализирует снимок и изменения в системе.
После чего нажимаем на кнопку «Далее».
Далее нас предупреждают, что никаких гарантий, что система восстановится, программа TimeShift не дает, мы это понимаем и нажимаем «Далее».
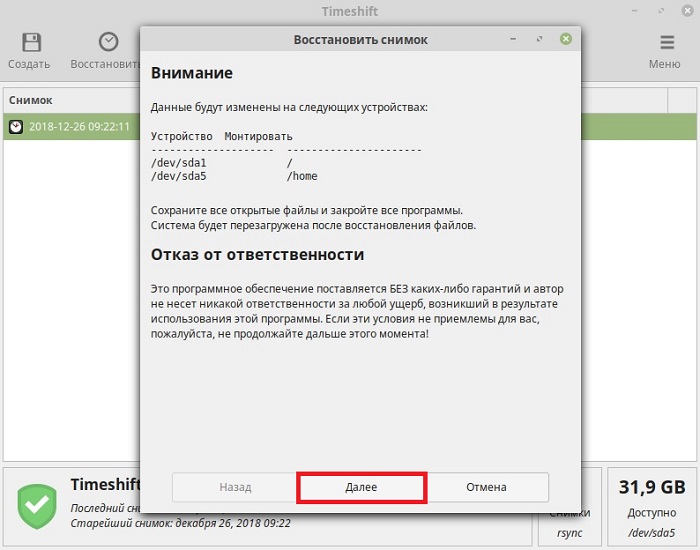
Начнется процесс восстановления системы, когда он будет завершен, Linux Mint перезагрузится, и можно будет пользоваться уже восстановленной системой.

На заметку! Для более тесного знакомства с Linux рекомендую почитать мою книгу « Linux для обычных пользователей » – в этой книге я максимально простым языком рассказываю про основы операционной системы Linux
Видео-инструкция о том, как создать снимок системы в Linux Mint
У меня все, надеюсь, материал был Вам полезен, пока!
Снапшоты, клоны и реплики в ZFS on Linux
Ramadoni: оригинал
Перевод: Алексей Федорчук
Пошаговое руководство по работе со снапшотами, клонами и репликами ZFS — самыми мощными её функциями.
Снапшоты ZFS: обзор
Снапшот — моментальная копия файловой системы или тома, не требующая дополнительного места в пуле ZFS. Дисковое пространство требуется только для записи изменённых блоков: записываются только различия между текущим набором данных и предыдущей его версией.
Типичный пример использования снапшота — быстрое получение резервной копии файловой системы перед выполнением рискованных действий вроде установки нового софта или обновления системы.
Создание и удаление снапшотов
Снимки томов напрямую недоступны, но их можно клонировать, бэкапить и восстанавливать. Для создания и удаления снапшотов используются команды zfs snapshot и zfs destroy
Создаём пул с именем datapool :
Для создания снапшота используется команда zfs snapshot с указанием имени пула и имени снапшота. Имя снапшота должно выглядеть так:
Теперь снапшот datapool/docs создан.
Для удаления снапшота используется команда zfs destroy :
Откат снапшота
Для моделирования процесса нужно создать тестовый файл в каталоге /docs :
Теперь изменим содержимое файла data.txt :
И теперь можно вернуть файловую систему в то состояние, в котором она была в момент создания предыдущей копии:
Из вывода последней команды можно видеть, что содержимое файла data.txt стало прежним (то есть соответствует версии 1).
Для переименования снапшота можно использовать команду zfs rename :
Клоны ZFS: обзор
Клон — это том или файловая система, доступные для записи, содержимое которых совпадает с набором данных, из которых они были созданы.
Создание и удаление клонов
Создание файловой системы:
Создание её контента:
Создание клона снапшота datapool/docs@today :
После клонирования снапшота его нельзя удалить, пока не удалён клон:
Теперь, наконец, можно удалить снапшот:
Реплики ZFS: обзор
Репликация ZFS основана на снапшотах, которые можно создавать в любое время и в любом количестве. Постоянно создавая, перемещая и восстанавливая снапшоты, можно обеспечить синхронизацию между одной или несколькими машинами. ZFS предоставляет встроенную функцию сериализации, которая может отправлять потоковое представление данных на стандартный вывод.
Конфигурирование реплик
Создание нового пула с именем backuppool :
Проверка статуса пулов:
Создание набора данных для репликации:
Настало время репликации:
Реплицирование набора данных на другую машину выполняется так:
Заключение
Снапшоты, ктоны и реплиуи — самые мощные функции ZFS. Снапшоты используются для периодического создания копий файловых систем, клоны — для создания дублирующих наборов данных, реплики — для переноса набора данных из одного пула данных в другой на той же машине, или для переноса между машинами.
Оставьте комментарий Отменить ответ
Для отправки комментария вам необходимо авторизоваться.
Снапшоты дисков
Снапшоты — это слепки состояния диска. Они хранят разницу между изменяющимися данными на диске виртуальной машины и состоянием диска на момент создания снапшота. Это позволяет копировать диски для создания клона виртуальной машины и изменения типа диска. Снапшот не является резервной копией диска виртуальной машины, так как хранится на том же оборудовании и требует доступности основного хранилища для выполнения любой операции.
Просмотр снапшотов
Просмотр снапшотов в панели управления
Для просмотра снапшотов в разделе Диски в проекте раскройте карточку диска и перейдите на вкладку Снапшоты. Отобразится список существующих снапшотов этого диска с именем и датой создания.
Просмотр снапшотов с помощью CLI
Для просмотра списка всех снапшотов:
Ответ будет выглядеть следующим образом:
Для просмотра снапшотов конкретного диска введите команду:
Для просмотра информации о снапшоте:
Ответ будет выглядеть следующим образом:
Создание снапшота
Снапшоты создаются только для сетевых дисков. Для локальных дисков снапшот создать нельзя.
Для диска можно создать только один снапшот – большое количество снапшотов замедляет работу диска.
Создание снапшота в панели управления
Чтобы создать снапшот в панели управления:
Примечание: также вы можете создать снапшот в разделе Серверы. Для этого на странице сервера на вкладке Сетевые диски в меню (⋮) нужного диска нажмите Создать снапшот.
Создание снапшота с помощью CLI
Для создания снапшота введите команду:
Изменение параметров снапшота
Для снапшотов доступно только изменение имени.
Изменение параметров снапшота в панели управления
Для изменения имени снапшота в панели управления:
Изменение параметров снапшота с помощью CLI
Для изменения имени снапшота введите:
Создание облачного сервера из снапшота
Чтобы быстро клонировать облачный сервер, можно создать новый сервер из снапшота. Для этого:
Удаление снапшотов
После выполнения операций со cнапшотом рекомендуется его удалить, чтобы была возможность создать новый снапшот, а также из-за того, что большое количество снапшотов замедляет работу диска.
Для долговременного хранения состояния диска создайте диск из снапшота.
Удаление снапшота в панели управления
Для удаления снапшота в панели управления:
Удалить все снапшоты одного диска одновременно можно двумя способами:
CYA – Утилита Snapshot и восстановления системы для Linux

CYA, означает Cover Your Assets, представляет собой бесплатный инструмент с открытым исходным кодом и утилиту восстановления для любых Unix-подобных операционных систем, в которых используется оболочка BASH.
Cya переносится и поддерживает множество популярных файловых систем, таких как EXT2 / 3/4, XFS, UFS, GPFS, reiserFS, JFS, BtrFS и ZFS и т. д.
Обратите внимание, что Cya не будет копировать фактические данные пользователя.
Он только создает резервные копии и восстанавливает саму операционную систему, а не ваши фактические данные пользователя.
Cya – это утилита восстановления системы.
По умолчанию он будет копировать все ключевые каталоги, такие как / bin /, / lib /, / usr /, / var / и несколько других.
Однако вы можете определить свой собственный каталог и путь к файлам для включения в резервную копию, поэтому Cya также подберет их.
Кроме того, можно указать некоторые каталоги / файлы для перехода из резервной копии.
Например, вы можете пропустить / var / logs / если вы не регистрируете эти файлы.
Cya фактически использует метод резервного копирования Rsync под капотом.
Тем не менее, Cya намного проще, чем Rsync при создании резервных копий.
При восстановлении вашей операционной системы Cya откатится от ОС, используя ваш профиль резервного копирования, который вы создали ранее.
Вы можете либо восстановить всю систему, либо только определенные каталоги.
Кроме того, вы можете легко получить доступ к файлам резервных копий даже без полного отката, используя ваш терминал или файловый менеджер.
Еще одна заметная особенность заключается в том, что мы можем создать специальный скрипт восстановления для автоматизации установки ваших системных разделов при восстановлении образа Live CD, USB или сети.
В двух словах, CYA может помочь вам восстановить вашу систему в предыдущих состояниях, когда вы закончите с нарушенной системой, вызванной обновлением программного обеспечения, изменениями конфигурации, вторжениями / хаками и т. д.
Установка CYA
Установка CYA очень проста. Все, что вам нужно сделать, это загрузить бинарный файл Cya и поместить его в свой системный путь.
Это приведет к клонированию последней версии cya в каталоге cya в вашем текущем рабочем каталоге.
Затем скопируйте двоичный файл cya на свой путь или куда захотите.
CYA теперь успешно установлен.
Теперь давайте продолжим и создадим снэпшоты.
Создание снэпшотов
Перед созданием снэпшотов / резервных копий создайте скрипт восстановления с помощью команды:
Сохраните полученный файл recovery.sh на USB-накопителе, который мы будем использовать позже при восстановлении резервных копий.
Этот скрипт поможет вам настроить chrooted среду и смонтировать диски при откате вашей системы.
Теперь давайте создадим снэпшоты
Чтобы создать стандартное резервное копирование, выполните:
Вышеупомянутая команда сохранит три резервных копии перед перезаписью.
Вы можете просмотреть содержимое недавно созданного моментального снимка в разделе /home/cya/points/location.
Чтобы создать резервную копию с настраиваемым именем, которое не будет перезаписано, запустите:
Замените BACKUP_NAME на свое имя.
Чтобы создать резервную копию с пользовательским именем, которое будет перезаписано, выполните следующие действия:
Чтобы создать резервную копию и архивировать и сжать ее, запустите:
Эта команда сохранит резервные копии в местоположении / home / cya / archives.
По умолчанию CYA сохранит свою конфигурацию в каталоге / home / cya /, а моментальные снимки с настраиваемым именем будут сохранены в / home / cya / points / BACKUP_NAME.
Однако вы можете изменить эти параметры, отредактировав файл конфигурации CYA, хранящийся в /home/cya/cya.conf.
Как я уже сказал, CYA по умолчанию не будет делать резервные копии пользовательских данных.
Он будет создавать резервные копии важных системных файлов.
Однако вы можете включить свои собственные каталоги или файлы вместе с системными файлами.
Скажем, например, если вы хотите добавить каталог с именем / home / sk / Downloads в резервную копию, отредактируйте файл /home/cya/cya.conf:
Определите путь к каталогам, который вы хотите включить в резервную копию, как показано ниже.
Помните, что как исходные, так и целевые каталоги должны заканчиваться конечной косой чертой.
В соответствии с приведенной выше конфигурацией CYA скопирует все содержимое каталога / home / sk / Downloads / и сохранит их в каталоге / mnt / backup / sk / (если вы уже создали этот).
Здесь mybackup – это имя профиля.
Сохраните и закройте файл.
Теперь для резервного копирования содержимого каталога / home / sk / Downloads / вам нужно ввести имя профиля (например, mybackup в моем случае) с помощью команды cya mydata, как показано ниже:
Аналогичным образом, вы можете включить несколько пользовательских данных с разными именами профилей.
Все имена профилей должны быть уникальными.
Исключить каталоги
В некоторых случаях вам может не потребоваться резервное копирование всех системных файлов.
Вы можете исключить некоторые несущественные, такие как файлы журналов.
Например, если вы не хотите включать / var / tmp / и / var / logs / directories, добавьте следующее в файл /home/cya/cya.conf.
Аналогичным образом вы можете указать все каталоги по одному, которые вы хотите исключить из резервной копии. После этого сохраните и закройте файл.
Добавление определенных файлов в резервную копию
Вместо резервного копирования целых каталогов вы можете включать определенные файлы из каталога.
Для этого добавьте путь к файлам по одному в файле /home/cya/cya.conf.
Восстановите свою систему
Помните, мы уже создали скрипт восстановления с именем recovery.sh и сохранили его на USB-накопителе?
Да, нам он нужен будет сейчас, чтобы восстановить нашу сломанную систему.
Загрузите свою систему с любого загрузочного CD / DVD-диска, USB-накопителя. Разработчик CYA рекомендует использовать загрузочную среду с той же основной версией, что и ваша установленная среда! Например, если вы используете систему Ubuntu 18.04, используйте live-носители Ubuntu 18.04.
После того, как вы находитесь в живой системе, подключите USB-накопитель, содержащий скрипт recovery.sh.
После установки диска (ов) ваша система / и / home будет смонтирована в каталоге / mnt / cya. Это делается очень легко и обрабатывается автоматически с помощью скрипта recovery.sh для пользователей Linux.
Затем запустите процесс восстановления с помощью команды:
Просто следуйте инструкциям на экране. Как только восстановление будет завершено, удалите живые медиафайлы и отключите диски и, наконец, перезагрузите систему.
Что делать, если у вас нет или потерял сценарий восстановления? Нет проблем, мы все равно можем восстановить нашу сломанную систему.
Загрузите live медиа.
С live сеанса создайте каталог для монтирования дисков.
Затем смонтируйте свой / и / home (если на другом разделе) в каталог / mnt / cya.
Наконец, запустите процесс восстановления с помощью команды:
Бэкап для Linux, или как создать снапшот
Всем привет! Я работаю в Veeam над проектом Veeam Agent for Linux. С помощью этого продукта можно бэкапить машину с ОС Linux. «Agent» в названии означает, что программа позволяет бэкапить физические машины. Виртуалки тоже бэкапит, но располагается при этом на гостевой ОС.
Вдохновением для этой статьи послужил мой доклад на конференции Linux Piter, который я решил оформить в виде статьи для всех интересующихся хабражителей.
В статье я раскрою тему создания снапшота, позволяющего произвести бэкап и поведаю о проблемах, с которыми мы столкнулись при создании собственного механизма создания снапшотов блочных устройств.
Всех заинтересовавшихся прошу под кат!

Немного теории в начале
Исторически так сложилось, что есть два подхода к созданию бэкапов: File backup и Volume backup. В первом случае мы копируем каждый файл как отдельный объект, во втором – копируем всё содержимое тома в виде некоего образа.
У обоих способов есть масса своих плюсов и минусов, но мы рассмотрим их через призму восстановления после сбоя:
Как же нам взять и сохранить весь том целиком? Само собой, простым копированием мы ничего хорошего не добьёмся. Во время копирования на томе будет происходить какая-то активность с данными, в итоге в бэкапе окажутся несогласованные данные. Структура файловой системы будет нарушена, файлы баз данных повреждены, как и прочие файлы, с которыми во время копирования будут производиться операции.
Чтобы избежать всех этих проблем, прогрессивное человечество придумало технологию моментального снимка – снапшота. В теории всё просто: создаём неизменную копию – снапшот – и бэкапим данные с него. Когда бэкап окончен – снапшот уничтожаем. Звучит просто, но, как водится, есть нюансы.
Из-за них было рождено множество реализаций этой технологи. Например, решения на основе device mapper, такие, как LVM и Thin provisioning, обеспечивают полноценные снапшоты томов, но требуют специальной разметки дисков ещё на этапе установки системы, а значит, в общем случае не подходят.
BTRFS и ZFS дают возможность создавать моментальные снимки подструктур файловой системы, что очень здорово, но на данный момент их доля на серверах невелика, а мы пытаемся сделать универсальное решение.
Предположим, на нашем блочном девайсе есть банальная EXT. В этом случае мы можем использовать dm-snap (кстати, сейчас разрабатывается dm-bow), но тут — свой нюанс. Нужно иметь на готове свободное блочное устройство, чтобы было куда отбрасывать данные снапшота.
Обратив внимание на альтернативные решения для бэкапа, мы заметили что они, как правило, используют свой модуль ядра для создания снапшотов блочных устройств. Этим путём решили пойти и мы, написав свой модуль. Решено было распространять его по GPL лицензии, так что в открытом доступе он доступен на github.
How it works — в теории
Снапшот под микроскопом
Итак, теперь рассмотрим общий принцип работы модуля и более подробно остановимся на ключевых проблемах.
По сути, veeamsnap (так мы назвали свой модуль ядра) – это фильтр драйвера блочного устройства.
Его работа заключена в перехвате запросов к драйверу блочного устройства.
Перехватив запрос на запись, модуль производит копирование данных с оригинального блочного устройства в область данных снапшота. Назовём эту область снапсторой.
А что такое сам снапшот? Это виртуальное блочное устройство, копия оригинального устройства на конкретный момент времени. При обращении к блокам данных на этом устройстве они могут быть считаны либо со снапсторы, либо с оригинального устройства.
Хочу отметить, что снапшот – это именно блочное устройство, полностью идентичное оригинальному на момент снятия снапшота. Благодаря этому мы можем смонтировать файловую систему на снапшоте и произвести необходимый предпроцессинг.
Например, мы можем получить карту занятых блоков от файловой системы. Самый простой способ это сделать – воспользоваться ioctl GETFSMAP.
Данные о занятых блоках позволяют читать со снапшота только актуальные данные.
Также, можно исключить некоторые файлы. Ну, и совсем опциональное действие: проиндексировать файлы, которые попадают в бэкап, для возможности гранулярного рестора в будущем.
CoW vs RoW
Давайте немного остановимся на выборе алгоритма работы снапшота. Выбор тут не особо обширен: Copy-on-Write или Redirect-on-Write.
Redirect-on-Write при перехвате запроса на запись перенаправит его в снапстору, после чего все запросы на чтение этого блока будут уходить туда же. Замечательный алгоритм для систем хранения, построенных на базе В+ деревьев, таких, как BTRFS, ZFS и Thin Provisioning. Технология стара как мир, но особенно хорошо она проявляет себя в гипервизорах, где можно создать новый файл и писать туда новые блоки на время жизни снапшота. Производительность – отличная, по сравнению с CoW. Но есть жирный минус – структура оригинального устройства меняется, а при удалении снапшота надо скопировать все блоки из снапсторы в оригинальное место.
Copy-on-Write при перехвате запроса копирует в снапстору данные, которые должны подвергнуться изменению, после чего позволяет их перезаписать в оригинальном месте. Используется для создания снапшотов для LVM томов и теневых копий VSS. Очевидно, для создания снапшотов блочных устройств он подходит больше, т.к. не меняет структуру оригинального устройства, и при удалении (или аварии) снапшот можно просто отбросить, не рискуя данными. Минус такого подхода – снижение производительности, так как на каждую операцию записи добавляется пара операций чтение/запись.
Поскольку обеспечение сохранности данных для нас основной приоритет, мы остановились именно на CoW.
Пока всё выглядит просто, поэтому давайте пройдёмся по проблемам из реальной жизни.
How it works — на практике
Согласованное состояние
Ради него всё и задумывалось.
Например, если в момент создания снапшота (в первом приближении можно считать, что создаётся он моментально) в какой-то файл будет производиться запись, то в снапшоте файл окажется недописанным, а значит — повреждённый и бессмысленный. Аналогичная ситуация и с файлам баз данных и самой файловой системой.
Но мы же в 21-м веке живём! Есть же механизмы журналирования, предохраняющие от подобных проблем! Замечание верное, правда, есть важное “но”: эта защита не от сбоя, а от его последствий. При восстановлении в согласованное состояние по журналу незавершённые операции будут отброшены, а значит — потеряны. Поэтому важно сместить приоритет на защиту от причины, а не лечить последствия.
Систему можно предупредить о том, что сейчас будет создан снапшот. Для этого в ядре есть функции freeze_bdev и thaw_bdev. Они дёргают функции файловой системы freeze_fs и unfreeze_fs. При вызове первой система должна сбросить кэш, приостановить создание новых запросов к блочному устройству и дождаться завершения всех ранее сформированных запросов. А при вызове unfreeze_fs файловая система восстанавливает своё нормальное функционирование.
Получается, что файловую систему мы можем предупредить. А что с приложениями? Тут, к сожалению, всё плохо. В то время, как в Windows существует механизм VSS, который с помощью Writer-ов обеспечивает взаимодействие с другими продуктами, в Linux каждый идёт своим путём. На данный момент это привело к ситуации, что задача администратора системы самостоятельно написать (скопировать, украсть, купить, etc) pre-freeze и post-thaw скрипты, которые будут подготавливать их приложение к снапшоту. Со своей стороны, в ближайшем релизе мы внедрим поддержку Oracle Application Processing, как наиболее часто запрашиваемую нашими клиентами функцию. Потом, возможно, будут поддержаны и другие приложения, но в целом ситуация довольно печальна.
Где расположить снапстору?
Это вторая встающая на нашем пути проблема. С первого взгляда проблема не очевидна, но, немного разобравшись, увидим, что это та ещё заноза.
Конечно же, самое простое решение — расположить снапстору в RAM. Для разработчика вариант просто отличный! Всё быстро, очень удобно делать отладку, но есть косяк: оперативка — ресурс ценный, и расположить там большую снапстору нам никто не даст.
ОК, давайте сделаем снапстору обычным файлом. Но возникает другая проблема – нельзя бэкапить том, на котором расположена снапстора. Причина проста: мы перехватываем запросы на запись, а значит, будем и перехватывать свои собственные запросы на запись в снапстору. Кони бегали по кругу, по-научному — deadlock. Следом возникает острое желание использовать для этого отдельный диск, но никто ради нас в сервера диски добавлять не будет. Работать надо уметь на том что есть.
Расположить снапстору удалённо — идея отличная, но реализуема в очень уж узких кругах сетей с большой пропускной способностью и микроскопических латенси. Иначе во время удержания снапшота на машине будет пошаговая стратегия.
Значит, надо как-то хитро расположить снапстору на локальном диске. Но, как правило, всё место на локальных дисках уже распределено между файловыми системами, и заодно надо крепко подумать, как обойти проблему deadlock’a.
Направление для раздумий, в принципе, одно: надо как-то аллоцировать у файловой системы пространство, но с блочным устройством работать напрямую. Решение этой проблемы было реализовано в user-space коде, в сервисе.
Существует системный вызов fallocate, который позволяет создать пустой файл нужного размера. При этом фактически на файловой системе создаются только метаданные, описывающие расположение файла на томе. А ioctl FIEMAP позволяет нам получить карту расположения блоков файла.
И вуаля: мы создаём файл под снапстору с помощью fallocate, FIEMAP отдаёт нам карту расположения блоков этого файла, которую мы можем передать для работы в наш модуль veeamsnap. Далее при обращении к снапсторе модуль делает запросы напрямую к блочному устройству в известные нам блоки, и никаких deadlock’ов.
Но тут есть нюанс. Системный вызов fallocate поддерживается только XFS, EXT4 и BTRFS. Для остальных файловых систем вроде EXT3 для аллокации файла его приходится полностью записывать. На функционале это сказывается увеличением времени на подготовку снапсторы, но выбирать не приходится. Опять таки, работать надо уметь на том что есть.
А что, если ioctl FIEMAP тоже не поддерживается? Это реальность NTFS и FAT32, где нет даже поддержки древнего FIBMAP. Пришлось реализовать некий generic алгоритм, работа которого не зависит от особенностей файловой системы. В двух словах алгоритм такой:
Переполнение снапшота
Вернее, заканчивается место, которые мы выделили под снапстору. Суть проблемы в том, что новые данные некуда отбрасывать, а значит, снапшот становится непригоден для использования.
Что делать?
Очевидно, надо увеличивать размер снапсторы. А насколько? Самый простой способ задания размера снапсторы – это определить процент от свободного места на томе (как сделано для VSS). Для тома в 20 TB 10% будет 2TB – что очень много для ненагруженного сервера. Для тома в 200 GB 10% составит 20GB, что может оказаться слишком мало для сервера, интенсивно обновляющего свои данные. А есть ещё тонкие тома…
В общем, заранее прикинуть оптимальный размер требуемой снапсторы может только системный администратор сервера, то есть придётся заставить человака подумать и выдать своё экспертное мнение. Это не соотвествует принципу «It just work».
Для решения этой проблемы мы разработали алгоритм stretch snapshot. Идея состоит в разбиении снапсторы на порции. При этом, новые порции создаются уже после создания снапшота по мере необходимости.
Опять же коротенько алгоритм:
Что делать в других случаях? Пытаемся угадать необходимый размер и создаём всю снапстору целиком. Но по нашей статистике, подавляющее большинство Linux серверов сейчас используют EXT4 и XFS. EXT3 встречается на старых машинах. Зато в SLES/openSUSE можно наткнуться на BTRFS.
Change Block Tracking (CBT)
Инкрементальный или дифференциальный бэкап (кстати, слаще хрен редьки или нет, предлагаю читать тут) – без него нельзя представить ни один взрослый продукт для бэкапа. А чтобы это работало, нужен CBT. Если кто-то пропустил: CBT позволяет отслеживать изменения и записывать в бэкап только изменённые с последнего бэкапа данные.
Свои наработки в этой области есть у многих. Например, в VMware vSphere эта функция доступна с 4-ой версии в 2009 году. В Hyper-V поддержка внедрена с Windows Server 2016, а для поддержки более ранних релизов был разработотан собственный драйвер VeeamFCT ещё в 2012-м. Поэтому, для нашего модуля мы не стали оригинальничать и использовали уже работающие алгоритмы.
Коротенько о том, как это работает.
Весь отслеживаемый том разбит на блоки. Модуль просто отслеживает все запросы на запись, помечая изменившиеся блоки в таблице. Фактически, таблица CBT – это массив байт, где каждый байт соответствует блоку и содержит номер снапшота, в котором он был изменён.
Во время бэкапа номер снапшота записывается в метаданные бэкапа. Таким образом, зная номера текущего снапшота и того, с которого был сделан предыдущий успешный бэкап, можно вычислить карту расположения изменившихся блоков.
Тут есть два нюанса.
Как я сказал, под номер снапшота в таблице CBT выделен один байт, значит, максимальная длина инкрементальной цепочки не может быть больше 255. При достижении этого порога таблица сбрасывается и происходит полный бэкап. Может показаться неудобным, но на самом деле цепочка в 255 инкрементов – далеко не самое лучшее решение при создании бэкап-плана.
Вторая особенность – это хранение CBT таблицы только в оперативной памяти. А значит, при перезагрузке целевой машины или выгрузке модуля она будет сброшена, и опять-таки, понадобится создавать полный бэкап. Такое решение позволяет не решать проблему старта модуля при старте системы. Кроме того, отпадает необходимость сохранять CBT таблицы при выключении системы.
Проблема производительности
Бекап — это всегда хорошая такая нагрузка на IO вашего оборудования. Если на нём и так хватает активных задач, то процесс резервного копирования может превратить вашу систему в этакого ленивца.
Давайте посмотрим, почему.
Представим, что сервер просто линейно пишет какие-то данные. Скорость записи в таком случае максимальна, все задержки минимизированы, производительность стремится к максимуму. Теперь добавим сюда процесс бэкапа, которому при каждой записи надо ещё успеть выполнить алгоритм Copy-on-Write, а это дополнительная операция чтения с последующей записью. И не забывайте, что для бэкапа надо ещё читать данные с этого же тома. Словом, ваш красивый linear access превращается в беспощадный random access со всеми вытекающими.
С этим явно надо что-то делать, и мы реализовали конвейер, чтобы обрабатывать запросы не по одному, а целыми пачками. Работает это так.
При перехвате запросов они укладываются в очередь, откуда их порциями забирает специальный поток. В это время создаются CoW-запросы, которые также обрабатываются порциями. При обработке CoW-запросов вначале производятся все операции чтения для всей порции, после чего выполняются операции записи. Только после завершения обработки всей порции CoW-запросов выполняются перехваченные запросы. Такой конвейер обеспечивает обращения к диску крупными порциями данных, что минимизирует временные потери.
Throttling
Уже на стадии отладки всплыл ещё нюанс. Во время бэкапа система становилась неотзывчивой, т.е. системные запросы ввода-вывода начинали выполняться с большими задержками. Зато, запросы на чтение данных со снапшота выполнялись на скорости, близкой к максимальной.
Пришлось немного придушить процесс бэкапа, реализовав механизм тротлинга. Для этого читающий из образа снапшота процесс переводится в состояние ожидания, если очередь перехваченных запросов не пуста. Ожидаемо, система ожила.
В результате, если нагрузка на систему ввода-вывода резко возрастает, то процесс чтения со снапшота будет ждать. Тут мы решили руководствоваться принципом, что лучше мы завершим бэкап ошибкой, чем нарушим работу сервера.
Deadlock
Я думаю, надо немного подробней объяснить, что это такое.
Уже на этапе тестирования мы стали сталкиваться с ситуациями полного повисания системы с диагнозом: семь бед – один ресет.
Стали разбираться. Выяснилось, что такую ситуацию можно наблюдать, если например создать снапшот блочного устройства, на котором расположен LVM-том, а снапстору расположить на том же LVM-томе. Напомню, что LVM использует модуль ядра device mapper.
В данной ситуации при перехвате запроса на запись, модуль, копируя данные в снапстору, отправит запрос на запись LVM-тому. Device mapper перенаправит этот запрос на блочное устройство. Запрос от device mapper-а снова будет перехвачен модулем. Но новый запрос не может быть обработан, пока не обработан предыдущий. В итоге, обработка запросов заблокирована, вас приветствует deadlock.
Чтобы не допустить подобной ситуации, в самом модуле ядра предусмотрен таймаут для операции копирования данных в снапстору. Это позволяет выявить deadlock и аварийно завершить бэкап. Логика здесь всё та же: лучше не сделать бэкап, чем подвесить сервер.
Round Robin Database
Это уже проблема, подкинутая пользователями после релиза первой версии.
Оказалось, есть такие сервисы, которые только и занимаются тем, что постоянно перезаписывают одни и те же блоки. Яркий пример – сервисы мониторинга, которые постоянно генерируют данные о состоянии системы и перезаписывают их по кругу. Для таких задач используют специализированные циклические базы данных (RRD).
Выяснилось, что при бэкапе таких баз снапшот гарантированно переполнится. При детальном изучении проблемы мы обнаружили недочёт в реализации CoW алгоритма. Если перезаписывался один и тот же блок, то в снапстору каждый раз копировались данные. Результат: дублирование данных в снапсторе.
Естественно, алгоритм мы изменили. Теперь том разбит на блоки, и данные копируются в снапстору блоками. Если блок уже был один раз скопирован, то повторно этот процесс не производится.
Выбор размера блока
Теперь, когда снапстора разбита на блоки встает вопрос: а какого, собственно, размера делать блоки для разбиения снапсторы?
Проблема двоякая. Если блок сделать большим, им легче оперировать, но при изменении хотя-бы одного сектора, придётся отправить весь блок в снапостору и, как следствие, повышаются шансы на переполнение снапсторы.
Очевидно, что чем меньше размер блока, тем больший процент полезных данных отправляется в снапстору, но как это ударит по производительности?
Правду искали эмпирическим путём и пришли в результату в 16KiB. Также отмечу, что в Windows VSS тоже используются блоки в 16 KiB.
Вместо заключения
На этом пока всё. За бортом оставлю множество других, не менее интересных проблем, таких, как зависимость от версий ядра, выбор вариантов распространения модуля, kABI совместимость, работа в условиях бекпортов и т.д. Статья и так получилась объёмной, поэтому я решил остановиться на самых интересных проблемах.
Сейчас мы готовим к релизу версию 3.0, код модуля лежит на github, и каждый желающий может использовать его в рамках GPL лицензии.