
О стеке простыми словами — для студентов и просто начинающих
Привет, я студент второго курса технического университета. После пропуска нескольких пар программирования по состоянию здоровья, я столкнулся с непониманием таких тем, как «Стек» и «Очередь». Путем проб и ошибок, спустя несколько дней, до меня наконец дошло, что это такое и с чем это едят. Чтобы у вас понимание не заняло столько времени, в данной статье я расскажу о том что такое «Стек», каким образом и на каких примерах я понял что это такое. Если вам понравится, я напишу вторую часть, которая будет затрагивать уже такое понятие, как «Очередь»
Теория
На Википедии определение стека звучит так:
Стек (англ. stack — стопка; читается стэк) — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Поэтому первое, на чем бы я хотел заострить внимание, это представление стека в виде вещей из жизни. Первой на ум мне пришла интерпретация в виде стопки книг, где верхняя книга — это вершина.

На самом деле стек можно представить в виде стопки любых предметов будь то стопка листов, тетрадей, рубашек и тому подобное, но пример с книгами я думаю будет самым оптимальным.
Итак, из чего же состоит стек.
Стек состоит из ячеек(в примере — это книги), которые представлены в виде структуры, содержащей какие-либо данные и указатель типа данной структуры на следующий элемент.
Сложно? Не беда, давайте разбираться.
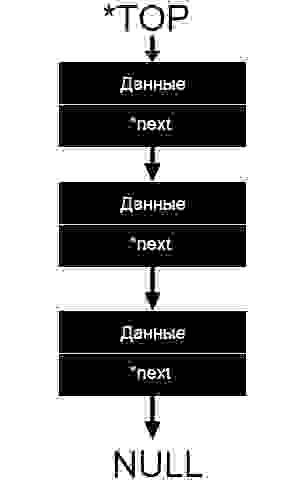
На данной картинке схематично изображен стек. Блок вида «Данные/*next» и есть наша ячейка. *next, как мы видим, указывает на следующий элемент, другими словами указатель *next хранит адрес следующей ячейки. Указатель *TOP указывает на вершину стек, то есть хранит её адрес.
С теорией закончили, перейдем к практике.
Практика
Для начала нам нужно создать структуру, которая будет являться нашей «ячейкой»
Новичкам возможно будет не понятно, зачем наш указатель — типа comp, точнее сказать указатель типа структуры comp. Объясню, для того чтобы указатель *next мог хранить структуру comp, ей нужно обозначить тип этой структуры. Другими словами указать, что будет хранить указатель.
После того как у нас задана «Ячейка», перейдем к созданию функций.
Функции
Функция создания «Стека»/добавления элемента в «Стек»
При добавлении элемента у нас возникнет две ситуации:
Разберем чуть чуть по-подробнее.
Во-первых, почему функция принимает **top, то есть указатель на указатель, для того чтобы вам было наиболее понятно, я оставлю рассмотрение этого вопроса на потом. Во-вторых, по-подробнее поговорим о q->next = *top и о том, что же означает ->.
-> означает то, что грубо говоря, мы заходим в нашу структуру и достаем оттуда элемент этой структуры. В строчке q->next = *top мы из нашей ячейки достаем указатель на следующий элемент *next и заменяем его на указатель, который указывает на вершину стека *top. Другими словами мы проводим связь, от нового элемента к вершине стека. Тут ничего сложного, все как с книгами. Новую книгу мы кладем ровно на вершину стопки, то есть проводим связь от новой книги к вершине стопки книг. После этого новая книга автоматически становится вершиной, так как стек не стопка книг, нам нужно указать, что новый элемент — вершина, для этого пишется: *top = q;.
Функция удаления элемента из «Стека» по данным
Данная функция будет удалять элемент из стека, если число Data ячейки(q->Data) будет равна числу, которое мы сами обозначим.
Здесь могут быть такие варианты:
Для лучшего понимания удаления элемента проведем аналогии с уже привычной стопкой книг. Если нам нужно убрать книгу сверху, мы её убираем, а книга под ней становится верхней. Тут то же самое, только в начале мы должны определить, что следующий элемент станет вершиной *top = q->next; и только потом удалить элемент free(q);
Если книга, которую нужно убрать находится между двумя книгами или между книгой и столом, предыдущая книга ляжет на следующую или на стол. Как мы уже поняли, книга у нас-это ячейка, а стол получается это NULL, то есть следующего элемента нет. Получается так же как с книгами, мы обозначаем, что предыдущая ячейка будет связана с последующей prev->next = q->next;, стоит отметить что prev->next может равняться как ячейке, так и нулю, в случае если q->next = NULL, то есть ячейки нет(книга ляжет на стол), после этого мы очищаем ячейку free(q).
Так же стоит отметить, что если не провести данную связь, участок ячеек, который лежит после удаленной ячейки станет недоступным, так как потеряется та самая связь, которая соединяет одну ячейку с другой и данный участок просто затеряется в памяти
Функция вывода данных стека на экран
Самая простая функция:
Здесь я думаю все понятно, хочу сказать лишь то, что q нужно воспринимать как бегунок, он бегает по всем ячейкам от вершины, куда мы его установили вначале: *q = top;, до последнего элемента.
Главная функция
Хорошо, основные функции по работе со стеком мы записали, вызываем.
Посмотрим код:
Вернемся к тому, почему же в функцию мы передавали указатель на указатель вершины. Дело в том, что если бы мы ввели в функцию только указатель на вершину, то «Стек» создавался и изменялся только внутри функции, в главной функции вершина бы как была, так и оставалась NULL. Передавая указатель на указатель мы изменяем вершину *top в главной функции. Получается если функция изменяет стек, нужно передавать в нее вершину указателем на указатель, так у нас было в функции s_push,s_delete_key. В функции s_print «Стек» не должен изменяться, поэтому мы передаем просто указатель на вершину.
Вместо цифр 1,2,3,4,5 можно так-же использовать переменные типа int.
Заключение
Полный код программы:
Так как в стек элементы постоянно добавляются на вершину, выводиться элементы будут в обратном порядке
В заключение хотелось бы поблагодарить за уделенное моей статье время, я очень надеюсь что данный материал помог некоторым начинающим программистам понять, что такое «Стек», как им пользоваться и в дальнейшем у них больше не возникнет проблем. Пишите в комментариях свое мнение, а так же о том, как мне улучшить свои статьи в будущем. Спасибо за внимание.
Основные принципы программирования: стек и куча
Мы используем всё более продвинутые языки программирования, которые позволяют нам писать меньше кода и получать отличные результаты. За это приходится платить. Поскольку мы всё реже занимаемся низкоуровневыми вещами, нормальным становится то, что многие из нас не вполне понимают, что такое стек и куча, как на самом деле происходит компиляция, в чём разница между статической и динамической типизацией, и т.д. Я не говорю, что все программисты не знают об этих понятиях — я лишь считаю, что порой стоит возвращаться к таким олдскульным вещам.
Сегодня мы поговорим лишь об одной теме: стек и куча. И стек, и куча относятся к различным местоположениям, где происходит управление памятью, но стратегия этого управления кардинально отличается.
Стек — это область оперативной памяти, которая создаётся для каждого потока. Он работает в порядке LIFO (Last In, First Out), то есть последний добавленный в стек кусок памяти будет первым в очереди на вывод из стека. Каждый раз, когда функция объявляет новую переменную, она добавляется в стек, а когда эта переменная пропадает из области видимости (например, когда функция заканчивается), она автоматически удаляется из стека. Когда стековая переменная освобождается, эта область памяти становится доступной для других стековых переменных.
Из-за такой природы стека управление памятью оказывается весьма логичным и простым для выполнения на ЦП; это приводит к высокой скорости, в особенности потому, что время цикла обновления байта стека очень мало, т.е. этот байт скорее всего привязан к кэшу процессора. Тем не менее, у такой строгой формы управления есть и недостатки. Размер стека — это фиксированная величина, и превышение лимита выделенной на стеке памяти приведёт к переполнению стека. Размер задаётся при создании потока, и у каждой переменной есть максимальный размер, зависящий от типа данных. Это позволяет ограничивать размер некоторых переменных (например, целочисленных), и вынуждает заранее объявлять размер более сложных типов данных (например, массивов), поскольку стек не позволит им изменить его. Кроме того, переменные, расположенные на стеке, всегда являются локальными.
В итоге стек позволяет управлять памятью наиболее эффективным образом — но если вам нужно использовать динамические структуры данных или глобальные переменные, то стоит обратить внимание на кучу.
Куча — это хранилище памяти, также расположенное в ОЗУ, которое допускает динамическое выделение памяти и не работает по принципу стека: это просто склад для ваших переменных. Когда вы выделяете в куче участок памяти для хранения переменной, к ней можно обратиться не только в потоке, но и во всем приложении. Именно так определяются глобальные переменные. По завершении приложения все выделенные участки памяти освобождаются. Размер кучи задаётся при запуске приложения, но, в отличие от стека, он ограничен лишь физически, и это позволяет создавать динамические переменные.
27–29 декабря, Онлайн, Беcплатно
Вы взаимодействуете с кучей посредством ссылок, обычно называемых указателями — это переменные, чьи значения являются адресами других переменных. Создавая указатель, вы указываете на местоположение памяти в куче, что задаёт начальное значение переменной и говорит программе, где получить доступ к этому значению. Из-за динамической природы кучи ЦП не принимает участия в контроле над ней; в языках без сборщика мусора (C, C++) разработчику нужно вручную освобождать участки памяти, которые больше не нужны. Если этого не делать, могут возникнуть утечки и фрагментация памяти, что существенно замедлит работу кучи.
В сравнении со стеком, куча работает медленнее, поскольку переменные разбросаны по памяти, а не сидят на верхушке стека. Некорректное управление памятью в куче приводит к замедлению её работы; тем не менее, это не уменьшает её важности — если вам нужно работать с динамическими или глобальными переменными, пользуйтесь кучей.
Заключение
Вот вы и познакомились с понятиями стека и кучи. Вкратце, стек — это очень быстрое хранилище памяти, работающее по принципу LIFO и управляемое процессором. Но эти преимущества приводят к ограниченному размеру стека и специальному способу получения значений. Для того, чтобы избежать этих ограничений, можно пользоваться кучей — она позволяет создавать динамические и глобальные переменные — но управлять памятью должен либо сборщик мусора, либо сам программист, да и работает куча медленнее.
Что такое стек в программировании

Стек (от англ. stack — стопка) — структура данных, представляющая из себя упорядоченный набор элементов, в которой добавление новых элементов и удаление существующих производится с одного конца, называемого вершиной стека. Притом первым из стека удаляется элемент, который был помещен туда последним, то есть в стеке реализуется стратегия «последним вошел — первым вышел» (last-in, first-out — LIFO). Примером стека в реальной жизни может являться стопка тарелок: когда мы хотим вытащить тарелку, мы должны снять все тарелки выше. Вернемся к описанию операций стека:
Реализации [ править ]
Для стека с [math]n[/math] элементами требуется [math]O(n)[/math] памяти, так как она нужна лишь для хранения самих элементов.
На массиве [ править ]
Перед реализацией стека выделим ключевые поля:
Каждую операцию над стеком можно легко реализовать несколькими строками кода:
На саморасширяющемся массиве [ править ]
Возможна реализация стека на динамическом массиве, в результате чего появляется существенное преимущество над обычной реализацией: при операции push мы никогда не сможем выйти за границы массива, тем самым избежим ошибки исполнения.
На списке [ править ]
Стек можно реализовать и на списке. Для этого необходимо создать список и операции работы стека на созданном списке. Ниже представлен пример реализации стека на односвязном списке. Стек будем «держать» за голову. Добавляться новые элементы посредством операции [math] \mathtt
Заведем конструктор вида ListItem(next : ListItem, data : T)
Для чего нужны стеки?

Jul 3, 2019 · 4 min read
Когда я узнал, что такое стек, мне стало интересно его практическое применение. Оказалось, что чаще всего эта структура используется для имплементации операции “Отмена” ( то есть, ⌘+ Z или Ctrl+ Z).
Чтобы понять, как это работает, разберемся с определением стека.
Что такое стек?
Стек — список элементов, который может быть изменён лишь с одной стороны, называющейся вершиной стека.

Представьте приспособление для раздачи тарелок, в котором тарелки стоят в стопке. Новые тарелки можно добавлять только поверх уже имеющихся, а брать можно лишь сверху. Таким образом, чем позже тарелку положат в стопку, тем раньше её оттуда возьмут. В рамках структур данных это называется LIFO-принципом (последним пришёл — первым ушёл).
Если использовать терминологию, то стек поддерживает операции добавления ( push) и удаления ( pop) элементов на его вершине.
Зачем использовать стек для отмены?
Потому что обычно мы хотим отменить последнее действие.
Стек позволяет добавлять элементы к его вершине и удалять тот элемент, который был последним.
Что произойдёт, если ни одно действие не будет отменено? Стек ведь станет огромным!
Верно. Если не удалять элементы из стека отмены, то есть не использовать операцию отмены, то он станет очень большим. Именно поэтому такие приложения, как Adobe Photoshop, с увеличением времени работы над файлом используют всё больше и больше оперативной памяти. Стек отмены хранит все действия, произведённые над файлом, в памяти до тех пор, пока вы не сохраните и не закроете файл.
Имплементация стека
Стек можно реализовать, используя либо связные списки, либо массивы. Я приведу пример реализации стека на обеих структурах на Python и расскажу о плюсах и минусах каждой.
Стек на связном списке:
Стек на массиве:
Что лучше?
В коде я указал сложность каждой из операций, используя “О” большое. Как видите, имплементации мало чем отличаются.
Однако есть некоторые нюансы, которые стоит учесть.

Массив
Это непрерывный блок памяти. Из-за этого при маленьком размере стека массив будет занимать лишнее место. Ещё один недостаток в том, что каждый раз при увеличении размера массива придётся копировать все уже существующие элементы в новую ячейку памяти.
Связный список
Он состоит из отдельных блоков в памяти и может увеличиваться бесконечно. Поэтому, с одной стороны, имплементация стека с использованием этой структуры немного лучше с точки зрения сложности алгоритма. С другой стороны, каждый элемент должен хранить адреса предыдущего и следующего элемента, что требует больше памяти.
Заключение
Так как динамический массив увеличивается в два раза при заполнении очереди, необходимость выделить дополнительную память будет возникать всё реже и реже. Кроме того, так как указатели не занимают много места, дополнительные данные в связных списках не критичны.
Как видим, между этими двумя реализациями стека практически нет различий — используйте ту, что нравится вам.
Алгоритмы и структуры данных для начинающих: стеки и очереди

В предыдущих частях мы рассматривали базовые структуры данных, которые, по сути, являлись надстройками над массивом. В этой статье мы добавим к коллекциям простые операции и посмотрим, как это повлияет на их возможности.
Стек — это коллекция, элементы которой получают по принципу «последний вошел, первый вышел» (Last-In-First-Out или LIFO). Это значит, что мы будем иметь доступ только к последнему добавленному элементу.
27–29 декабря, Онлайн, Беcплатно
Наиболее часто встречающаяся аналогия для объяснения стека — стопка тарелок. Вне зависимости от того, сколько тарелок в стопке, мы всегда можем снять верхнюю. Чистые тарелки точно так же кладутся на верх стопки, и мы всегда будем первой брать ту тарелку, которая была положена последней.

Если мы положим, например, красную тарелку, затем синюю, а затем зеленую, то сначала надо будет снять зеленую, потом синюю, и, наконец, красную. Главное, что надо запомнить — тарелки всегда ставятся и на верх стопки. Когда кто-то берет тарелку, он также снимает ее сверху. Получается, что тарелки разбираются в порядке, обратном тому, в котором ставились.
Теперь, когда мы понимаем, как работает стек, введем несколько терминов. Операция добавления элемента на стек называется «push», удаления — «pop». Последний добавленный элемент называется верхушкой стека, или «top», и его можно посмотреть с помощью операции «peek». Давайте теперь посмотрим на заготовку класса, реализующего стек.
Класс Stack
Метод Push
Поскольку мы используем связный список для хранения элементов, можно просто добавить новый в конец списка.
Метод Pop
Push добавляет элементы в конец списка, поэтому забирать их будет также с конца. В случае, если список пуст, будет выбрасываться исключение.
Метод Peek
Метод Count
Зачем нам знать, сколько элементов находится в стеке, если мы все равно не имеем к ним доступа? С помощью этого поля мы можем проверить, есть ли элементы на стеке или он пуст. Это очень полезно, учитывая, что метод Pop кидает исключение.
Пример: калькулятор в обратной польской записи
Классический пример использования стека — калькулятор в обратной польской, или постфиксной, записи. В ней оператор записывается после своих операндов. То есть, мы пишем:
Другими словами, вместо «4 + 2» мы запишем «4 2 +». Если вам интересно происхождение обратной польской записи и ее названия, вы можете узнать об этом на Википедии или в поисковике.
То, как вычисляется обратная польская запись и почему стек так полезен при ее использовании, хорошо видно из следующего алгоритма:
То есть, для выражения «4 2 +» действия будут следующие:
В конце на стеке окажется одно значение — 6.
Очередь
Очереди очень похожи на стеки. Они также не дают доступа к произвольному элементу, но, в отличие от стека, элементы кладутся (enqueue) и забираются (dequeue) с разных концов. Такой метод называется «первый вошел, первый вышел» (First-In-First-Out или FIFO). То есть забирать элементы из очереди мы будем в том же порядке, что и клали. Как реальная очередь или конвейер.
Очереди часто используются в программах для реализации буфера, в который можно положить элемент для последующей обработки, сохраняя порядок поступления. Например, если база данных поддерживает только одно соединение, можно использовать очередь потоков, которые будут, как ни странно, ждать своей очереди на доступ к БД.
Класс Queue
Метод Enqueue
Новые элементы очереди можно добавлять как в начало списка, так и в конец. Важно только, чтобы элементы доставались с противоположного края. В данной реализации мы будем добавлять новые элементы в начало внутреннего списка.
Метод Dequeue
Поскольку мы вставляем элементы в начало списка, убирать мы их будем с конца. Если список пуст, кидается исключение.
Метод Peek
Метод Count
Двусторонняя очередь
Двусторонняя очередь (Double-ended queue), или дек (Deque), расширяет поведение очереди. В дек можно добавлять или удалять элементы как с начала, так и с конца очереди. Такое поведение полезно во многих задачах, например, планирование выполнения потоков или реализация других структур данных. Позже мы рассмотрим вариант реализации стека с помощью двусторонней очереди.
Класс Deque
Метод EnqueueFirst
Метод EnqueueLast
Метод DequeueFirst
Метод DequeueLast
Метод PeekFirst
Метод PeekLast
Метод Count
Пример: реализация стека
Двусторонняя очередь часто используется для реализации других структур данных. Давайте посмотрим на пример реализации стека с ее помощью.
У вас, возможно, возник вопрос, зачем реализовывать стек на основе очереди вместо связного списка. Причины две: производительность и повторное использование кода. У связного списка есть накладные расходы на создание узлов и нет гарантии локальности данных: элементы могут быть расположены в любом месте памяти, что вызывает большое количество промахов и падение производительности на уровне процессоров. Более производительная реализация двусторонней очереди требует массива для хранения элементов.
Тем не менее, реализация стека или очереди с помощью массива — непростая задача, но такая реализация двусторонней очереди и использование ее в качестве основы для других структур данных даст нам серьезный плюс к производительности и позволит повторно использовать код. Это снижает стоимость поддержки.
Позже мы посмотрим на вариант очереди с использованием массива, но сначала давайте взглянем на класс стека с использованием двусторонней очереди:
Хранение элементов в массиве
Как уже было упомянуто, у реализации очереди с использованием массива есть свои преимущества. Она выглядит простой, но на самом деле есть ряд нюансов, которые надо учесть.
Давайте посмотрим на проблемы, которые могут возникнуть, и на их решение. Кроме того, нам понадобится информация об увеличении внутреннего массива из прошлой статьи о динамических массивах.
При создании очереди у нее внутри создается массив нулевой длины. Красные буквы «h» и «t» означают указатели _head и _tail соответственно.
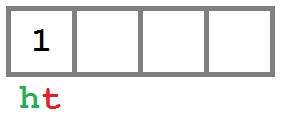
Добавляем элемент в начало
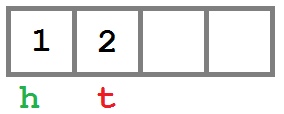
Добавляем элемент в конец

Добавляем еще один элемент в начало
Обратите внимание: индекс «головы» очереди перескочил в начало списка. Теперь первый элемент, который будет возвращен при вызове метода DequeueFirst — 0 (индекс 3).

И еще один в конец
Массив заполнен, поэтому при добавлении элемента произойдет следующее:

Добавляем значение в конец расширенного массива
Теперь посмотрим, что происходит при удалении элемента:

Удаляем элемент из начала
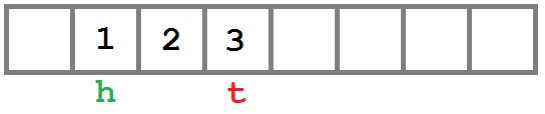
Удаляем элемент с конца
Ключевой момент: вне зависимости от вместимости или заполненности внутреннего массива, логически, содержимое очереди — элементы от «головы» до «хвоста» с учетом «закольцованности». Такое поведение также называется «кольцевым буфером».
Теперь давайте посмотрим на реализацию.
Класс Deque (с использованием массива)
Интерфейс очереди на основе массива такой же, как и в случае реализации через связный список. Мы не будем его повторять. Однако, поскольку список был заменен на массив, у нас добавились новые поля — сам массив, его размер и указатели на «хвост» и «голову» очереди.
Алгоритм роста
Когда свободное место во внутреннем массиве заканчивается, его необходимо увеличить, скопировать элементы и обновить указатели на «хвост» и «голову». Эта операция производится при необходимости во время добавления элемента. Параметр startingIndex используется, чтобы показать, сколько полей в начале необходимо оставить пустыми (в случае добавления в начало).
Обратите внимание на то, как извлекаются данные, когда приходится переходить в начало массива при проходе от «головы» к «хвосту».
Метод EnqueueFirst
Метод EnqueueLast
Метод DequeueFirst
Метод DequeueLast
Метод PeekFirst
Метод PeekLast
Метод Count
Продолжение следует
Вот мы и закончили четвертую часть нашего цикла статей. В ней мы рассмотрели стеки и очереди. В следующий раз мы перейдем к бинарным деревьям поиска.