
Конвертер текста в юникод
Конвертер для перевода любого текста (не только кириллицы) в Юникод. Набирайте текст — он будет автоматически преобразован по мере его набора. Либо вставьте текст из буфера и нажмите кнопку. Ограничение на длину текста — 3000 символов.
Что такое Юникод?
Юникод — это стандарт универсальной кодировки символов, который используется для поддержки символов, не входящих в набор ASCII. Изначально Интернет был создан на базе кодировки ASCII, которая содержит символы английского алфавита и состоит всего из 128 символов.
Юникод обеспечивает поддержку всех языков мира и их уникальных наборов символов — Юникод может поддерживать более 1 миллиона символов!
Причина в том, что в Юникоде для представления символа может использоваться больше бит (от английского binary digit — двоичное число), которые представляют собой единицы информации в компьютерах. Символы ASCII требуют только 7 бит, а Юникод может использовать 16 бит. Это необходимо, потому что для таких языков, как китайский, арабский и русский, требуется больше бит.
Кодовое пространство
Кодовое пространство разбито на 17 плоскостей по 216 (65536) символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей. Плоскости 16 и 17 выделены для частного употребления.
Для обозначения символов Unicode используется запись вида « U+xxxx » (для кодов 0…FFFF) или « U+xxxxx » (для кодов 10000…FFFFF) или « U+xxxxxx » (для кодов 100000…10FFFF),
где xxx — шестнадцатеричные цифры.
Например, символ «я» (U+044F) имеет код 044F16 = 110310.
Состоит стандарт из двух главных разделов:
Универсальным набором символов задаётся однозначная пропорциональность кодам символов. Коды в этом случае представляют собой элементы кодовой сферы, являющиеся неотрицательными целыми числами. Функция семейства кодировок – определение машинного представления последовательности UCS-кодов.
Под кириллицу определены следующие области символов с кодами:
Представление символов, таблицы кодировок
Содержание
Представление символов в вычислительных машинах [ править ]
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Таблицы кодировок [ править ]
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти [math]32[/math] символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение [math]256[/math] символов: [math]128[/math] основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) [math]256[/math] символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII [ править ]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа [math]n = 8[/math] бит. |
Кодировки стандарта ASCII ( [math]8[/math] бит):
Структурные свойства таблицы [ править ]
Кодировки стандарта UNICODE [ править ]
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей. Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство [ править ]
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до [math]2^<31>[/math] [math](2\ 147\ 483\ 648)[/math] кодовых позиций, было принято решение использовать лишь [math]1\ 112\ 064[/math] для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее [math]110\ 000[/math] кодовых позиций ( [math]109\ 242[/math] графических и [math]273[/math] прочих символов).
Кодовое пространство разбито на [math]17[/math] плоскостей (англ. planes) по [math]2^<16>[/math] [math](65\ 536)[/math] символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости [math]15[/math] и [math]16[/math] выделены для частного употребления.
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы [ править ]
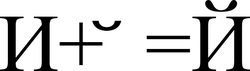
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления [ править ]
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8 [ править ]
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0x00000000 — 0x0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0x00000080 — 0x000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
| 0x00000800 — 0x0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0x00010000 — 0x001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
| 111111xx | служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования [ править ]
Правила записи кода одного символа в UTF-8 [ править ]
1. Если размер символа в кодировке UTF-8 = [math]1[/math] байт
Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 [math]\gt 1[/math] байт (то есть от [math]2[/math] до [math]6[/math] ):
2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления; 2.2 «0» — бит терминатор, означающий завершение кода размера 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
Определение длины кода в UTF-8 [ править ]
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
| [math]1[/math] | [math]7[/math] |
| [math]2[/math] | [math]11[/math] |
| [math]3[/math] | [math]16[/math] |
| [math]4[/math] | [math]21[/math] |
| [math]5[/math] | [math]26[/math] |
| [math]6[/math] | [math]31[/math] |
[math]C = 7[/math] при [math]n=1[/math]
[math]C = n\cdot5+1[/math] при [math]n\gt 1[/math]
UTF-16 [ править ]
UTF-16LE и UTF-16BE [ править ]
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32 [ править ]
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно [math]32[/math] бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Порядок байт [ править ]
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
[math]M = \sum_
Варианты записи [ править ]
Порядок от старшего к младшему [ править ]
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему [ править ]
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок [ править ]
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок [ править ]
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия [ править ]

Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт [ править ]
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
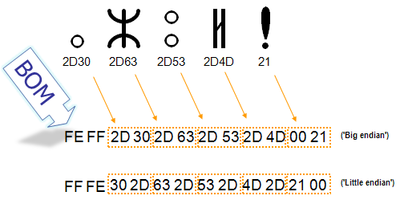
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) | FE FF |
| UTF-16 (LE) | FF FE |
| UTF-32 (BE) | 00 00 FE FF |
| UTF-32 (LE) | FF FE 00 00 |
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его [math]2[/math] или [math]4[/math] байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода [ править ]
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры [ править ]
FoxTools v.2.0
Привет, Гость! Ваш IP: 31.184.215.237
Таблица символов Юникода
DEC: 
HEX:
Html:
Что такое Юникод?
В отличие от ASCII, один символ кодируется двумя байтами, что позволяет использовать 65 536 символов, против 256.
Символы Юникода разделены на секции. Первые 128 символов повторяют таблицу ASCII.
Как пользоваться таблицей?
Символы представлены по 16 штук на строке. Сверху вы можете видеть шестнадцатеричное число от 0 до 16. Слева аналогичные числа в шестнадцатеричном виде от 0 до FFF.
Соединив число слева с числом сверху, можно узнать код символа. Например: английская буква F расположена на строке 004, в столбике 6: 004 + 6 = код символа 0046.
Впрочем, вы можете просто навести курсор на конкретный символ в таблице, чтобы узнать код символа. Либо нажать на символ, чтобы скопировать его, или его код в одном из форматов.
В поисковое поле можно ввести ключевые слова поиска, например: стрелки, солнце, сердце. Либо можно указать код символа в любом формате, например: 1123, 04BC, چ. Или сам символ, если требуется узнать код символа.
Поиск по ключевым словам в данный момент находится на стадии разработки, поэтому может не выдавать результатов. Но многие популярные символы уже можно найти.
К сожалению, в данный момент таблица не работает на мобильных устройствах.
В Application Programming Interface этот сервис не реализован. В популярных языках программирования можно легко работать с символами Юникода. Если у вас возникнут какие-либо вопросы, обращайтесь на форум для программистов.
Сайт построен на HTML5
Для корректной работы данного сайта требуется HTML5.
Пожалуйста, воспользуйтесь браузером, который поддерживает HTML5. Многие современные браузеры поддерживают HTML5. Например:
Таблица символов Юникода
Популярные наборы символов



![]()

Юникод
Юникод (по-английски Unicode) — это стандарт кодирования символов. Проще говоря, это таблица соответствия текстовых знаков (цифр, букв, элементов пунктуации ) двоичным кодам. Компьютер понимает только последовательность нулей и единиц. Чтобы он знал, что именно должен отобразить на экране, необходимо присвоить каждому символу свой уникальный номер. В восьмидесятых, знаки кодировали одним байтом, то есть восемью битами (каждый бит это 0 или 1). Таким образом получалось, что одна таблица (она же кодировка или набор) может вместить только 256 знаков. Этого может не хватить даже для одного языка. Поэтому, появилось много разных кодировок, путаница с которыми часто приводила к тому, что на экране вместо читаемого текста появлялись какие-то странные кракозябры. Требовался единый стандарт, которым и стал Юникод. Самая используемая кодировка — UTF-8 (Unicode Transformation Format) для изображения символа задействует от 1 до 4 байт.
Символы
Символы в таблицах Юникода пронумерованы шестнадцатеричными числами. Например, кириллическая заглавная буква М обозначена U+041C. Это значит, что она стоит на пересечении строки 041 и столбца С. Её можно просто скопировать и потом вставить куда-либо. Чтобы не рыться в многокилометровом списке следует воспользоваться поиском. Зайдя на страницу символа, вы увидите его номер в Юникоде и способ начертания в разных шрифтах. В строку поиска можно вбить и сам знак, даже если вместо него отрисовывается квадратик, хотя бы для того, чтобы узнать, что это было. Ещё, на этом сайте есть специальные (и не специальные — случайные) наборы однотипных значков, собранные из разных разделов, для удобства их использования.
Стандарт Юникод — международный. Он включает знаки почти всех письменностей мира. В том числе и тех, которые уже не применяются. Египетские иероглифы, германские руны, письменность майя, клинопись и алфавиты древних государств. Представлены и обозначения мер и весов, нотных грамот, математических понятий.
Сам консорциум Юникода не изобретает новых символов. В таблицы добавляются те значки, которые находят своё применение в обществе. Например, знак рубля активно использовался в течении шести лет прежде чем был добавлен в Юникод. Пиктограммы эмодзи (смайлики) тоже сначала получили широкое применение в Япониии прежде чем были включены в кодировку. А вот товарные знаки, и логотипы компаний не добавляются принципиально. Даже такие распространённые как яблоко Apple или флаг Windows. На сегодняшний день, в версии 8.0 закодировано около 120 тысяч символов.
© Таблица символов Юникода, 2012–2021.
Юникод® — это зарегистрированная торговая марка консорциума Юникод в США и других странах. Этот сайт никак не связан с консорциумом Юникод. Официальный сайт Юникода располагается по адресу www.unicode.org.
Мы используем 🍪cookie, чтобы сделать сайт максимально удобным для вас. Подробнее
Этот восхитительный Юникод

Перед вами обновляемый список самых замечательных «вкусностей» Юникода, а также пакетов и ресурсов
Юникод — это потрясающе! До его появления международная коммуникация была изнурительной: каждый определял свой отдельный расширенный набор символов в верхней половине ASCII (так называемые кодовые страницы). Это порождало конфликты. Просто подумайте, что немцам приходилось договариваться с корейцами, где чья кодовая страница. К счастью, появился Юникод и ввёл общий стандарт. Юникод 8.0 охватывает более 120 000 символов из более 129 письменностей. И современные, и древние, и до сих пор не расшифрованные. Юникод поддерживает текст слева направо и справа налево, наложение символов и включает самые разные культурные, политические, религиозные символы и эмодзи. Юникод потрясающе человечен, а его возможности сильно недооцениваются.
Содержание
Краткое введение
Какие символы входят в Стандарт Юникод?
Стандарт Юникод определяет коды для символов основных современных языков. Это европейские алфавитные письменности, ближневосточные письменности справа налево и многие письменности Азии.
Стандарт также содержит знаки пунктуации, диакритические знаки, математические символы, технические символы, стрелки, дингбаты, эмодзи и т. д. Он предоставляет коды для диакритических знаков, изменяющих знаки символов, такие как тильда (
). Они используются в сочетании с основными для представления акцентированных символов (например, ñ). В целом, Юникод версии 9.0 предоставляет коды для 128 172 символов из мировых алфавитов, наборов идеограмм и коллекций символов.
Большинство символов общего пользования помещаются в первые 64K кодовых точек, область кодового пространства, которая называется основной многоязычной плоскостью, или BMP для краткости. Есть ещё шестнадцать других дополнительных плоскостей, доступных для кодирования других символов, с более чем 850 000 неиспользуемых кодовых точек. Они могут пригодиться для добавления новых символов в будущие версии стандарта.
Стандарт Юникод также резервирует кодовые точки для частного использования. Вендоры или конечные пользователи могут назначать их в своих собственных системах для своих символов или использовать со специализированными шрифтами. На BMP находится 6400 кодовых точек для частного использования и ещё 131 068 дополнительных кодовых точек частного использования, если 6400 недостаточно для конкретных приложений.
Кодировки символов Юникода
Стандарты кодирования символов определяют не только идентичность каждого символа и его числовое значение или кодовую точку, но и то, как это значение представлено в битах.
Стандарт Юникод определяет три формы кодирования, которые позволяют передавать одни и те же данные: это байт, слово и двойное слово (то есть 8, 16 или 32 бит на единицу кода). Все три формы кодируют один и тот же общий набор символов и могут быть эффективно преобразованы друг в друга без потери данных. Консорциум Юникод полностью одобряет использование любой из этих форм кодирования в качестве согласованного способа реализации Стандарта Юникод.
UTF-8 популярен для HTML и подобных протоколов. UTF-8 — это способ преобразования всех символов Юникода в кодировку переменной байтовой длины. Его преимущество в том, что символы Юникода, соответствующие знакомому набору ASCII, имеют те же байтовые значения, что и ASCII, а символы Юникода, преобразованные в UTF-8, могут использоваться с большим количеством существующего программного обеспечения без серьёзной доработки ПО.
UTF-16 популярен во многих средах, где необходимо сбалансировать эффективный доступ к символам с экономичным хранением. Он достаточно компактен, и все часто используемые символы помещаются в один 16-битный кодовый блок, в то время как все остальные символы доступны через пары 16-битных кодовых блоков.
UTF-32 полезен там, где объём памяти не вызывает беспокойства, но требуется доступ к символам по единому коду фиксированной ширины. Здесь каждый символ Юникода кодируется в одном 32-разрядном кодовом блоке.
Все три формы кодирования требуют для каждого символа не более 4 байт (или 32 бит).
Поговорим о цифрах
Набор символов Юникода разделён на 17 основных сегментов (плоскостей), которые далее делятся на блоки. В каждой плоскости есть место для 65 536 (2 16 ) кодовых точек, что создаёт в сумме 1 114 112 кодовых точек. Есть две «плоскости частного использования» (№ 16 и № 17), которые выделяются для использования на усмотрение компаний/пользователей. В них 131 072 кодовые точки.
| № | Название | Диапазон |
|---|---|---|
| 1. | Основная многоязычная плоскость | (от U+0000 до U+FFFF) |
| 2. | Дополнительная многоязычная плоскость | (от U+10000 до U+1FFFF) |
| 3. | Дополнительная идеографическая плоскость | (от U+20000 до U+2FFFF) |
| 4. | Третичная идеографическая плоскость | (от U+30000 до U+3FFFF) |
| 5. | Плоскость 5 (не используется) | (от U+40000 до U+4FFFF) |
| 6. | Плоскость 6 (не используется) | (от U+50000 до U+5FFFF) |
| 7. | Плоскость 7 (не используется) | (от U+60000 до U+6FFFF) |
| 8. | Плоскость 8 (не используется) | (от U+70000 до U+7FFFF) |
| 9. | Плоскость 9 (не используется) | (от U+80000 до U+8FFFF) |
| 10. | Плоскость 10 (не используется) | (от U+90000 до U+9FFFF) |
| 11. | Плоскость 11 (не используется) | (от U+A0000 до U+AFFFF) |
| 12. | Плоскость 12 (не используется) | (от U+B0000 до U+BFFFF) |
| 13. | Плоскость 13 (не используется) | (от U+C0000 до U+CFFFF) |
| 14. | Плоскость 14 (не используется) | (от U+D0000 до U+DFFFF) |
| 15. | Специализированная дополнительная плоскость | (от U+E0000 до U+EFFFF) |
| 16. | Дополнительная область для частного использования — A | (от U+F0000 до U+FFFFF) |
| 17. | Дополнительная область для частного использования — B | (от U+100000 до U+10FFFF) |
Первая плоскость называется основной многоязычной плоскостью или BMP. Она содержит кодовые точки от U+0000 до U+FFFF, то есть наиболее часто используемые символы. Остальные шестнадцать плоскостей (U+010000 → U+10FFFF) называются дополнительными или астральными.
Суррогатные пары UTF-16
Символы вне основной плоскости, как тетраграмматон, означающий центр (U+1D306), можно закодировать в UTF-16 только двумя 16-битными кодовыми единицами: 0xD834 0xDF06. Это называется суррогатной парой. Обратите внимание, что суррогатная пара представляет только один символ.
Первая кодовая единица суррогатной пары всегда находится в диапазоне от 0xD800 до 0xDBFF и называется верхней частью пары.
Вторая кодовая единица суррогатной пары всегда находится в диапазоне от 0xDC00 до 0xDFFF и называется нижней частью пары.
Суррогатная пара: представление одного абстрактного символа, состоящего из последовательности двух 16-разрядных кодовых единиц, где первое значение пары является верхней суррогатной кодовой единицей, а второе — нижней суррогатной кодовой единицей. Суррогатные пары используются только в UTF-16.
Вычисление суррогатных пар
Юникодовский символ «Куча дерьма» (U+1F4A9) в UTF-16 придётся кодировать как суррогатную пару, т. е. два суррогата. Чтобы преобразовать любую кодовую точку в суррогатную пару, используйте такой алгоритм (на JavaScript). Имейте в виду, что мы используем шестнадцатеричную нотацию.

Композиция и декомпозиция
Юникод включает в себя механизм для изменения формы символа, который значительно расширяет поддерживаемый набор глифов. Это касается комбинируемых диакритических знаков. Они вставляются после главного знака. На один и тот же знак можно наложить несколько комбинируемых диакритических знаков. Юникод также содержит предварительно составленные версии большинства таких комбинаций для нормального использования.
Некоторые последовательности символов также можно представить в виде одного символа, который называется предварительно составленным символом (precomposed character), он же составной символ (composite character). Например, символ [ü] можно закодировать как единственную кодовую точку U+00FC или как базовый символ U+0075 (u), за которым следует несамостоятельный знак U+0308 (¨). Стандарт Юникод кодирует составные символы для совместимости с установленными стандартами, такими как Latin 1, который включает в себя множество составных символов, таких как [ü] и [ñ].
Составные символы можно разложить для согласованности или анализа. Например, при сортировке имён по алфавиту символ [ü] можно разложить на [u], за которым следует несамостоятельный знак [¨]. После такой декомпозиции алгоритму проще работать с последовательностью символов. Это позволяет упростить сортировку в языках, где модификаторы символов не влияют на алфавитный порядок. Стандарт Юникод устанавливает порядок декомпозиции для всех составных символов. Он также определяет формы нормализации для обеспечения уникальных представлений символов.
Мифы о Юникоде
Из слайдов презентации Марка Дэвиса «Мифы Юникода».
Прикладные кодировки Юникода
| Тип кодирования | Пример |
|---|---|
| Объект HTML (десятичный) | |
| Объект HTML (hex) | |
| Управляющий код URL | %F0%9F%96%96 |
| UTF-8 (hex) | 0xF0 0x9F 0x96 0x96 (f09f9696) |
| UTF-8 (бинарный) | 11110000:10011111:10010110:10010110 |
| UTF-16/UTF-16BE (hex) | 0xD83D 0xDD96 (d83ddd96) |
| UTF-16LE (hex) | 0x3DD8 0x96DD (3dd896dd) |
| UTF-32/UTF-32BE (hex) | 0x0001F596 (0001f596) |
| UTF-32LE (hex) | 0x96F50100 (96f50100) |
| Восьмеричная управляющая последовательность | \360\237\226\226 |
Исходный код
| Тип кодирования | Пример |
|---|---|
| JavaScript | \u1F596 |
| JSON | \u1F596 |
| C | \u1F596 |
| C++ | \u1F596 |
| Java | \u1F596 |
| Python | \u1F596 |
| Perl | \x |
| Ruby | \u |
| CSS | \01F596 |
Список удивительных символов
Совместный доступ к документу может быстро превратить редактирование в письменную рэп-битву, ведущуюся все более запутанной расстановкой управляющих от U+202a до U+202e
Специальные символы
Консорциум Unicode опубликовал диаграмму общей пунктуации, где можете найти более подробную информацию.
| Символ | Название | Описание |
|---|---|---|
| ‘’ | U+FEFF Неразрывный пробел нулевой ширины (Byte Order Mark — BOM) | Обладает важным свойством однозначности при изменении порядка байтов. У него также нулевая ширина и невидимость. В неподходщем программном обеспечении (например, интерпретаторе PHP) это приводит к всевозможным примерам забавного поведения. |
| ‘’ | ‘\uFFEF’ Обратный BOM | Не приравнивается к символу, кроме начала текста. |
| ‘’ | ‘\u200B’ Неразрывное пространство нулевой ширины | Символ без внешнего вида и без эффекта, кроме предотвращения образования лигатур. |
| ‘ ‘ | U+00A0 Неразрывный пробел | Заставляет соседние символы держаться вместе. Хорошо известен как в HTML. |
| ‘’ | U+00AD Мягкий дефис | В HTML работает как пространство нулевой ширины, но при встрече с концом строки (и только в этом случае) показывает дефис. |
| ‘’ | U+200D Знак нулевой ширины (с объединением) | Заставляет соединяться соседние символы (например, арабские символы или поддерживаемые эмодзи). Можно использовать для последовательно скомбинированных эмодзи. |
| ‘’ | U+2060 Соединитель слов | То же самое, что и U+00A0, но совершенно невидимый. Хорошо подходит для @font-face в Twitter. |
| ‘ ‘ | U+1680 Огам знак пробела | Отмечает пробел, который выглядит как тире. Отлично подходит, чтобы приблизить программистов к безумию: 1 + 2 === 3. |
| ‘;’ | U+037E Греческий знак вопроса | Похож на точку с запятой. Также забавный способ троллить разработчиков. |
| ‘’ | U+202D | Изменяет направление текста слева-направо. |
| ‘’ | U+202E | Изменяет направление текста справа-налево. |
| ‘ꓸ’ | U+A4F8 Лису буква tone mya ti | Двойник для точки. |
| ‘ꓹ’ | U+A4F9 Лису буква tone na po | Двойник для запятой. |
| ‘ꓼ’ | U+A4FC Лису буква tone mya na | Двойник для точки с запятой. |
| ‘ꓽ’ | U+A4FD Лису буква tone mya jeu | Двойник для двоеточия. |
| ‘︀’ | Вариантные селекторы (от U+FE00 до U+FE0F и от U+E0100 до U+E01EF) | Блок из 256 символов нулевой ширины, которые обладают свойством ID_Continue, то есть могут использоваться в именах переменных (не первая буква). Что делает их особенными, так это то, что над ними проходит курсор мыши, поскольку они объединяют символы, в отличие от большинства других символов нулевой ширины. |
| ‘ᅟ’ | U+115F Заполнитель хангыль чхосон | По сути, заполняет пространство. Визуализируется как символ нулевой ширины (невидимый), если явно не поддерживается при визуализации. Обозначен как ID_Start |
| ‘ᅠ’ | U+1160 Заполнитель чунсон | Возможно, заполняет пространство? Визуализируется как символ нулевой ширины (невидимый), если явно не поддерживается при визуализации. Обозначен как ID_Start |
| ‘ㅤ’ | U+3164 Заполнитель хангыль | В целом, заполняет пространство. Визуализируется как символ нулевой ширины (невидимый), если явно не поддерживается при визуализации. Обозначен как ID_Start |
Подожди… что я только что прочитал?
Идентификаторы переменных могут включать пробелы!
U+3164 Заполнитель хангыль отображается в виде широкого пробела. Если символ явно не поддерживается в рендеринге, то отображается как полностью невидимый (и не занимает место, т. е. «нулевой ширины»). Это означает, что вы никогда не увидите уродливый символ замены символов (�).
Я пока не уверен, почему U+3164 указано вести себя таким образом. Интересно, что U+3164 был добавлен в Юникод в версии 1.1 (1993) — так что у специалистов Консорциума было много времени, чтобы его продумать. Во всяком случае, вот несколько примеров.
**Примечание:** я тестировал рендеринг U+3164 на Ubuntu и OS X со следующими параметрами: `node`, `php`, `ruby`, `python3.5`, `scala`, `vim`, `cat`, `chrome`+`github gist’. Atom — единственная система, которая терпит неудачу, (некорректно) отображая пустые поля. Мне ещё предстоит проверить код в Emacs и Sublime. Насколько я понимаю, Консорциум Юникод не будет переназначать или переименовывать символы или кодовые точки, но его можно убедить изменить свойства символов, таких как ID_Start и ID_Continue.
Модификаторы
Объединитель нулевой ширины (ZWJ) является непечатным символом в компьютерном наборе некоторых сложных шрифтов, таких как арабский или любой индийский шрифт. При помещении между двумя символами, которые в противном случае не были бы связаны, ZWJ заставляет их печататься в объединённой форме.
Разъединитель нулевой ширины (ZWNJ) — это непечатный символ в компьютерных наборах письменностей с лигатурами. При размещении между двумя символами, которые в противном случае были бы соединены в лигатуру, ZWNJ заставляет их печататься в их окончательной и первоначальной формах, соответственно. Действует как пробел, но используется в том случае, когда желательно удерживать слова рядом друг с другом или соединить слово с его морфемой.
Коллизии преобразований в верхнем регистре
| Символ | Кодовая точка | Результат |
|---|---|---|
| ß | 0x00DF | SS |
| ı | 0x0131 | I |
| ſ | 0x017F | S |
| ff | 0xFB00 | FF |
| fi | 0xFB01 | FI |
| fl | 0xFB02 | FL |
| ffi | 0xFB03 | FFI |
| ffl | 0xFB04 | FFL |
| ſt | 0xFB05 | ST |
| st | 0xFB06 | ST |
Коллизии преобразований в нижнем регистре
Причуды и устранение неполадок
Сопоставления одного ко многим
Большинство нижеприведенных символов выражают свои сопоставления «один ко многим» в верхнем регистре, а другие в нижнем. В принципе, список можно разделить на две части.
Отличные пакеты и библиотеки
Эмодзи
Многообразие
Консорциум Unicode приложил огромные усилия для лучшего отражения человеческого многообразия (diversity), включая культурные практики. Вот отчёт Консорциума о многообразии.
Теперь доступны эмодзи для разных гендерных ситуаций, включая однополые семьи, держащиеся руки и поцелуи. Последний функционал — это составные последовательности эмодзи. Основные примеры:
| Кодовые точки | Рецепт | Сочетание |
|---|---|---|
| U+1F469 U+200D U+2764 U+FE0F U+200D U+1F469 | | |
| U+1F468 U+200D U+1F468 U+200D U+1F467 U+200D U+1F466 |  | |
Кроме того, эмодзи теперь поддерживают модификаторы цвета кожи.
В Юникоде версии 8.0 (середина 2015 года) появилось пять символов-модификаторов символов для оттенков человеческой кожи. Эти символы основаны на шести оттенках по шкале Фицпатрика, признанного стандарта в дерматологии (в интернете много примеров этой шкалы, таких как FitzpatrickSkinType.pdf). Точные оттенки зависят от реализации.
| Код | Название | Примеры |
|---|---|---|
| U+1F3FB | Модификатор эмодзи для шкалы Фицпатрика типы-1-2 | |
| U+1F3FC | Модификатор эмодзи для шкалы Фицпатрика тип-3 | |
| U+1F3FD | Модификатор эмодзи для шкалы Фицпатрика тип-4 | |
| U+1F3FE | Модификатор эмодзи для шкалы Фицпатрика тип-5 | |
| U+1F3FF | Модификатор эмодзи для шкалы Фицпатрика тип-6 | |
Просто выбирайте нужный эмодзи, указав один из модификаторов цвета кожи \u<1F466>\u <1F3FE>.
+
→
Переменные и методы с креативными названиями
Примеры на JavaScript (ES6)
Обычно символы, обозначенные свойством ID_START, можно ставить в начале названия переменной. Символы, обозначенные свойством ID_CONTINUE, можно ставить после первого символа в имени переменной.
А вот некоторые юникодовские классы CSS от Дэвида Уолша.
Скрипт рекурсивного переименования тегов HTML
Если вы хотите переименовать все свои HTML-теги в нечто невидимое, вот скрипт, который вам нужен.
Только обратите внимание, что HTML поддерживает не все символы Юникода.
Вот что он поддерживает:
А вот некоторые результаты:
Шрифты Юникода
Ни один шрифт TrueType или OpenType не способен охватить все символы UTF-8, поскольку есть жёсткое ограничение на 65 535 символов в шрифте. Если у нас более 1,1 миллиона глифов UTF-8, то для полного покрытия придётся делать семейство шрифтов.
Дополнительные ресурсы
Более глубокое исследование самого Юникода
Общая карта
Карта основной многоязычной плоскости
Каждое нумерованное поле представляет собой 256 кодовых точек.
Китайские, японские и корейские (ККЯ) письменности объединены одним цветом как символы ККЯ (CJK). В процессе, который называется унификацией Хань, распознаются общие символы и составляется список «унифицированных идеограмм ККЯ».
Блоки Юникода
Стандарт Юникод объединяет группы символов в блоки. Вот полный список блоков по всем 17-ти плоскостям.
| Название | От | До | # кодовых точек |
|---|---|---|---|
| Основная латиница | U+0000 | U+007F | 128 |
| Дополнение к латинице — 1 | U+0080 | U+00FF | 128 |
| Расширенная латиница — A | U+0100 | U+017F | 128 |
| Расширенная латиница — B | U+0180 | U+024F | 208 |
| Расширения МФА | U+0250 | U+02AF | 96 |
| Модификаторы букв | U+02B0 | U+02FF | 80 |
| Комбинируемые диакритические знаки | U+0300 | U+036F | 112 |
| Греческое и коптское письмо | U+0370 | U+03FF | 135 |
| Кириллица | U+0400 | U+04FF | 256 |
| Дополнение к кириллице | U+0500 | U+052F | 48 |
| Армянское письмо | U+0530 | U+058F | 89 |
| Еврейское письмо | U+0590 | U+05FF | 87 |
| Арабское письмо | U+0600 | U+06FF | 255 |
| Сирийское письмо | U+0700 | U+074F | 77 |
| Дополнение к арабскому письму | U+0750 | U+077F | 48 |
| Тана | U+0780 | U+07BF | 50 |
| Нко | U+07C0 | U+07FF | 59 |
| Самаритянское письмо | U+0800 | U+083F | 61 |
| Мандейское письмо | U+0840 | U+085F | 29 |
| Расширенное арабское письмо — A | U+08A0 | U+08FF | 50 |
| Девангари | U+0900 | U+097F | 128 |
| Бенгальское письмо | U+0980 | U+09FF | 93 |
| Гурмукхи | U+0A00 | U+0A7F | 79 |
| Гуджарати | U+0A80 | U+0AFF | 85 |
| Ория | U+0B00 | U+0B7F | 90 |
| Тамильское письмо | U+0B80 | U+0BFF | 72 |
| Телугу | U+0C00 | U+0C7F | 96 |
| Каннада | U+0C80 | U+0CFF | 87 |
| Малаялам | U+0D00 | U+0D7F | 100 |
| Сингальское письмо | U+0D80 | U+0DFF | 90 |
| Тайское письмо | U+0E00 | U+0E7F | 87 |
| Лаосское письмо | U+0E80 | U+0EFF | 67 |
| Тибетское письмо | U+0F00 | U+0FFF | 211 |
| Бирманское письмо | U+1000 | U+109F | 160 |
| Грузинское письмо | U+10A0 | U+10FF | 88 |
| Элементы хангыля | U+1100 | U+11FF | 256 |
| Эфиопское письмо | U+1200 | U+137F | 358 |
| Дополнение к эфиопскому письму | U+1380 | U+139F | 26 |
| Чероки | U+13A0 | U+13FF | 92 |
| Канадское слоговое письмо | U+1400 | U+167F | 640 |
| Огамическое письмо | U+1680 | U+169F | 29 |
| Руны | U+16A0 | U+16FF | 89 |
| Байбайин | U+1700 | U+171F | 20 |
| Хануноо | U+1720 | U+173F | 23 |
| Бухид | U+1740 | U+175F | 20 |
| Тагбанва | U+1760 | U+177F | 18 |
| Кхмерское письмо | U+1780 | U+17FF | 114 |
| Старомонгольское письмо | U+1800 | U+18AF | 156 |
| Расширенное канадское слоговое письмо | U+18B0 | U+18FF | 70 |
| Лимбу | U+1900 | U+194F | 68 |
| Лы | U+1950 | U+197F | 35 |
| Ныа | U+1980 | U+19DF | 83 |
| Кхмерские символы | U+19E0 | U+19FF | 32 |
| Лонтара | U+1A00 | U+1A1F | 30 |
| Ланна | U+1A20 | U+1AAF | 127 |
| Расширенные комбинируемые диакритические знаки | U+1AB0 | U+1AFF | 15 |
| Балийское письмо | U+1B00 | U+1B7F | 121 |
| Сунданское письмо | U+1B80 | U+1BBF | 64 |
| Батакское письмо | U+1BC0 | U+1BFF | 56 |
| Лепча | U+1C00 | U+1C4F | 74 |
| Ол-чики | U+1C50 | U+1C7F | 48 |
| Дополнение к сунданскому письму | U+1CC0 | U+1CCF | 8 |
| Расширения Веды | U+1CD0 | U+1CFF | 41 |
| Фонетические расширения | U+1D00 | U+1D7F | 128 |
| Дополнение к фонетическим расширениям | U+1D80 | U+1DBF | 64 |
| U+1DFF Дополнение к комбинируемым диакритическим знакам | U+1DC0 | U+1DFF | 58 |
| Дополнительная расширенная латиница | U+1E00 | U+1EFF | 256 |
| Расширенное греческое письмо | U+1F00 | U+1FFF | 233 |
| Основная пунктуация | U+2000 | U+206F | 111 |
| Надстрочные и подстрочные знаки | U+2070 | U+209F | 42 |
| Знаки валют | U+20A0 | U+20CF | 31 |
| Комбинируемые диакритические знаки для символов | U+20D0 | U+20FF | 33 |
| Буквоподобные символы | U+2100 | U+214F | 80 |
| Числовые формы | U+2150 | U+218F | 60 |
| Стрелки | U+2190 | U+21FF | 112 |
| Математические операторы | U+2200 | U+22FF | 256 |
| Разные технические знаки | U+2300 | U+23FF | 251 |
| Пиктограммы управляющих символов | U+2400 | U+243F | 39 |
| Оптическое распознавание символов | U+2440 | U+245F | 11 |
| Обрамлённые буквы и цифры | U+2460 | U+24FF | 160 |
| Псевдографика | U+2500 | U+257F | 128 |
| Блочные элементы | U+2580 | U+259F | 32 |
| Геометрические фигуры | U+25A0 | U+25FF | 96 |
| Разные символы | U+2600 | U+26FF | 256 |
| Dingbats | U+2700 | U+27BF | 192 |
| Разные математические символы — A | U+27C0 | U+27EF | 48 |
| Дополнительные стрелки — A | U+27F0 | U+27FF | 16 |
| Шрифт Брайля | U+2800 | U+28FF | 256 |
| Дополнительные стрелки — B | U+2900 | U+297F | 128 |
| Разные математические символы — B | U+2980 | U+29FF | 128 |
| Дополнительные математические операторы | U+2A00 | U+2AFF | 256 |
| Разные символы и стрелки | U+2B00 | U+2BFF | 206 |
| Глаголица | U+2C00 | U+2C5F | 94 |
| Расширенная латиница — C | U+2C60 | U+2C7F | 32 |
| Коптское письмо | U+2C80 | U+2CFF | 123 |
| Дополнение к грузинскому письму | U+2D00 | U+2D2F | 40 |
| Древнеливийское письмо | U+2D30 | U+2D7F | 59 |
| Расширенное эфиопское письмо | U+2D80 | U+2DDF | 79 |
| Расширенная кириллица — A | U+2DE0 | U+2DFF | 32 |
| Дополнительная пунктуация | U+2E00 | U+2E7F | 67 |
| Дополнение к ключам ККЯ | U+2E80 | U+2EFF | 115 |
| Ключи Канси | U+2F00 | U+2FDF | 214 |
| Идеографические пояснительные символы | U+2FF0 | U+2FFF | 12 |
| Символы и пунктуация ККЯ | U+3000 | U+303F | 64 |
| Хирагана | U+3040 | U+309F | 93 |
| Катакана | U+30A0 | U+30FF | 96 |
| Чжуинь фухао | U+3100 | U+312F | 41 |
| Совместимые элементы хангыля | U+3130 | U+318F | 94 |
| Камбун | U+3190 | U+319F | 16 |
| Расширенное чжуинь фухао | U+31A0 | U+31BF | 27 |
| Черты ККЯ | U+31C0 | U+31EF | 36 |
| Фонетические расширения катаканы | U+31F0 | U+31FF | 16 |
| Обрамлённые буквы и месяцы ККЯ | U+3200 | U+32FF | 254 |
| Совместимые элементы ККЯ | U+3300 | U+33FF | 256 |
| Унифицированные идеограммы ККЯ — расширение A | U+3400 | U+4DBF | 6191 |
| Гексаграммы «Книги Перемен» | U+4DC0 | U+4DFF | 64 |
| Унифицированные идеограммы ККЯ | U+4E00 | U+9FFF | 20941 |
| Слоговое письмо и | U+A000 | U+A48F | 1165 |
| Ключи письма и | U+A490 | U+A4CF | 55 |
| Лису | U+A4D0 | U+A4FF | 48 |
| Ваи | U+A500 | U+A63F | 300 |
| Расширенная кириллица — B | U+A640 | U+A69F | 96 |
| Бамум | U+A6A0 | U+A6FF | 88 |
| Символы изменения тона | U+A700 | U+A71F | 32 |
| Расширенная латиница — D | U+A720 | U+A7FF | 159 |
| Силхетское нагари | U+A800 | U+A82F | 44 |
| Общеиндийские числовые формы | U+A830 | U+A83F | 10 |
| Монгольское квадратное письмо | U+A840 | U+A87F | 56 |
| Саураштра | U+A880 | U+A8DF | 81 |
| Расширенное деванагари | U+A8E0 | U+A8FF | 30 |
| Кая-ли | U+A900 | U+A92F | 48 |
| Реджанг | U+A930 | U+A95F | 37 |
| Расширенные элементы хангыля — A | U+A960 | U+A97F | 29 |
| Яванское письмо | U+A980 | U+A9DF | 91 |
| Расширенное бирманское письмо — B | U+A9E0 | U+A9FF | 31 |
| Чамское письмо | U+AA00 | U+AA5F | 83 |
| Расширенное бирманское письмо — A | U+AA60 | U+AA7F | 32 |
| Тай-вьет | U+AA80 | U+AADF | 72 |
| Расширения манипури | U+AAE0 | U+AAFF | 23 |
| Расширенное эфиопское письмо — A | U+AB00 | U+AB2F | 32 |
| Расширенная латиница — E | U+AB30 | U+AB6F | 54 |
| Дополнение к чероки | U+AB70 | U+ABBF | 80 |
| Манипури | U+ABC0 | U+ABFF | 56 |
| Слоговое письмо хангыля | U+AC00 | U+D7AF | 2 |
| Расширенные элементы хангыля — B | U+D7B0 | U+D7FF | 72 |
| Верхняя часть суррогатных пар | U+D800 | U+DB7F | 2 |
| Верхняя часть суррогатных пар для частного использования | U+DB80 | U+DBFF | 2 |
| Нижняя часть суррогатных пар | U+DC00 | U+DFFF | 2 |
| Область для частного использования | U+E000 | U+F8FF | 2 |
| Совместимые идеограммы ККЯ | U+F900 | U+FAFF | 472 |
| Алфавитные формы представления | U+FB00 | U+FB4F | 58 |
| Арабские формы представления — A | U+FB50 | U+FDFF | 643 |
| Вариантные селекторы | U+FE00 | U+FE0F | 16 |
| Вертикальные формы | U+FE10 | U+FE1F | 10 |
| Комбинируемые полузнаки | U+FE20 | U+FE2F | 16 |
| Совместимые формы ККЯ | U+FE30 | U+FE4F | 32 |
| Малые вариантные формы | U+FE50 | U+FE6F | 26 |
| Арабские формы представления — B | U+FE70 | U+FEFF | 141 |
| Полуширинные и полноширинные формы | U+FF00 | U+FFEF | 225 |
| Специальные символы | U+FFF0 | U+FFFF | 7 |
| Слоги линейного письма Б | U+10000 | U+1007F | 88 |
| Идеограммы линейного письма Б | U+10080 | U+100FF | 123 |
| Эгейские цифры | U+10100 | U+1013F | 57 |
| Древнегреческие цифры | U+10140 | U+1018F | 77 |
| Древние символы | U+10190 | U+101CF | 13 |
| Фестский диск | U+101D0 | U+101FF | 46 |
| Ликийское письмо | U+10280 | U+1029F | 29 |
| Карийское письмо | U+102A0 | U+102DF | 49 |
| Коптские цифры епакты | U+102E0 | U+102FF | 28 |
| Древнеиталийское письмо | U+10300 | U+1032F | 36 |
| Готское письмо | U+10330 | U+1034F | 27 |
| Древнепермское письмо | U+10350 | U+1037F | 43 |
| Угаритское письмо | U+10380 | U+1039F | 31 |
| Древнеперсидское письмо | U+103A0 | U+103DF | 50 |
| Дезеретское письмо | U+10400 | U+1044F | 80 |
| Алфавит Шоу | U+10450 | U+1047F | 48 |
| Сомалийское письмо | U+10480 | U+104AF | 40 |
| Эльбасанское письмо | U+10500 | U+1052F | 40 |
| Агванское письмо | U+10530 | U+1056F | 53 |
| Линейное письмо А | U+10600 | U+1077F | 341 |
| Кипрское письмо | U+10800 | U+1083F | 55 |
| Имперское арамейское письмо | U+10840 | U+1085F | 31 |
| Пальмирское письмо | U+10860 | U+1087F | 32 |
| Набатейское письмо | U+10880 | U+108AF | 40 |
| Хатран | U+108E0 | U+108FF | 26 |
| Финикийское письмо | U+10900 | U+1091F | 29 |
| Лидийское письмо | U+10920 | U+1093F | 27 |
| Мероитские иероглифы | U+10980 | U+1099F | 32 |
| Мероитский курсив | U+109A0 | U+109FF | 90 |
| Кхароштхи | U+10A00 | U+10A5F | 65 |
| Древнее южноаравийское письмо | U+10A60 | U+10A7F | 32 |
| Древнее северноаравийское письмо | U+10A80 | U+10A9F | 32 |
| Манихейское письмо | U+10AC0 | U+10AFF | 51 |
| Авестийское письмо | U+10B00 | U+10B3F | 61 |
| Парфянское эпиграфическое письмо | U+10B40 | U+10B5F | 30 |
| Пахлевийское эпиграфическое письмо | U+10B60 | U+10B7F | 27 |
| Псалтирь пахлеви | U+10B80 | U+10BAF | 29 |
| Древнетюркское руническое письмо | U+10C00 | U+10C4F | 73 |
| Венгерские руны | U+10C80 | U+10CFF | 108 |
| Цифры руми | U+10E60 | U+10E7F | 31 |
| Брахми | U+11000 | U+1107F | 109 |
| Кайтхи | U+11080 | U+110CF | 66 |
| Соранг-сомпенг | U+110D0 | U+110FF | 35 |
| Чакма | U+11100 | U+1114F | 67 |
| Махаджани | U+11150 | U+1117F | 39 |
| Шарада | U+11180 | U+111DF | 94 |
| Сингальские архаические цифры | U+111E0 | U+111FF | 20 |
| Ходжики | U+11200 | U+1124F | 61 |
| Мултани | U+11280 | U+112AF | 38 |
| Худабади | U+112B0 | U+112FF | 69 |
| Грантха | U+11300 | U+1137F | 85 |
| Тирхута | U+11480 | U+114DF | 82 |
| Сиддхаматрика | U+11580 | U+115FF | 92 |
| Моди | U+11600 | U+1165F | 79 |
| Такри | U+11680 | U+116CF | 66 |
| Ахом | U+11700 | U+1173F | 57 |
| Варанг-кшити | U+118A0 | U+118FF | 84 |
| По Чин Хо | U+11AC0 | U+11AFF | 57 |
| Клинопись | U+12000 | U+123FF | 922 |
| Клинописные цифры и пунктуация | U+12400 | U+1247F | 116 |
| Раннединастическая клинопись | U+12480 | U+1254F | 196 |
| Египетские иероглифы | U+13000 | U+1342F | 1071 |
| Анатолийские иероглифы | U+14400 | U+1467F | 583 |
| Дополнение к бамуму | U+16800 | U+16A3F | 569 |
| Мро | U+16A40 | U+16A6F | 43 |
| Басса | U+16AD0 | U+16AFF | 36 |
| Пахау | U+16B00 | U+16B8F | 127 |
| Мяо | U+16F00 | U+16F9F | 133 |
| Дополнение к кане | U+1B000 | U+1B0FF | 2 |
| Стенография Дюплойе | U+1BC00 | U+1BC9F | 143 |
| Форматирующие символы стенографии | U+1BCA0 | U+1BCAF | 4 |
| Византийские музыкальные символы | U+1D000 | U+1D0FF | 246 |
| Музыкальные символы | U+1D100 | U+1D1FF | 231 |
| Древнегреческая нотопись | U+1D200 | U+1D24F | 70 |
| Символы «Канона великого сокровенного» | U+1D300 | U+1D35F | 87 |
| Цифры счётных палочек | U+1D360 | U+1D37F | 18 |
| Математические буквы и цифры | U+1D400 | U+1D7FF | 996 |
| SignWriting | U+1D800 | U+1DAAF | 672 |
| Кикакуи | U+1E800 | U+1E8DF | 213 |
| Арабские математические алфавитные символы | U+1EE00 | U+1EEFF | 143 |
| Кости для маджонга | U+1F000 | U+1F02F | 44 |
| Кости для домино | U+1F030 | U+1F09F | 100 |
| Игральные карты | U+1F0A0 | U+1F0FF | 82 |
| Дополнение к обрамлённым буквам и цифрам | U+1F100 | U+1F1FF | 173 |
| Дополнение к обрамлённым идеографическим символам | U+1F200 | U+1F2FF | 57 |
| Разные символы и пиктограммы | U+1F300 | U+1F5FF | 766 |
| Эмотиконы | U+1F600 | U+1F64F | 80 |
| Орнаментные символы | U+1F650 | U+1F67F | 48 |
| Транспортные и картографические символы | U+1F680 | U+1F6FF | 98 |
| Алхимические символы | U+1F700 | U+1F77F | 116 |
| Расширенные геометрические фигуры | U+1F780 | U+1F7FF | 85 |
| Дополнительные стрелки — C | U+1F800 | U+1F8FF | 148 |
| Дополнительные символы и пиктограммы | U+1F900 | U+1F9FF | 15 |
| Унифицированные идеограммы ККЯ — расширение B | U+20000 | U+2A6DF | 42676 |
| Унифицированные идеограммы ККЯ — расширение C | U+2A700 | U+2B73F | 60 |
| Унифицированные идеограммы ККЯ — расширение D | U+2B740 | U+2B81F | 27 |
| Унифицированные идеограммы ККЯ — расширение E | U+2B820 | U+2CEAF | 2 |
| Дополнение к совместимым иероглифам ККЯ | U+2F800 | U+2FA1F | 542 |
| Tags | U+E0000 | U+E007F | 97 |
| Дополнение к вариантным селекторам | U+E0100 | U+E01EF | 240 |
| Дополнительная область для частного использования — A | U+F0000 | U+FFFFF | 4 |
| Дополнительная область для частного использования — B | U+100000 | U+10FFFF | 4 |
Принципы Стандарта Юникод
Стандарт Юникод устанавливает следующие фундаментальные принципы: