
Код ответа сервера на HTTP запросы
Запросы бывают различных типов, запросы на получение данных — это обычно GET. HEAD запросы предназначены для того чтобы получить только заголовки.
Проверяются заголовки при помощи консольной утилиты curl или путем отправки запросов предварительно подключившись к серверу с использованием telnet (в конце статьи содержится ссылка на сервис, позволяющий проверять заголовки в браузере) 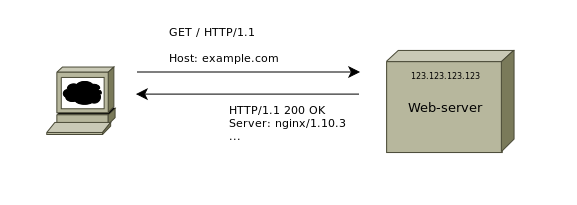
Проверка ответа сервера — telnet
Trying ::1…
Connected to localhost.
Escape character is ‘^]’.
Теперь дважды нужно нажать Enter на клавиатуре
В консоль будет выведен HTTP ответ — в нем интерес представляет первая строка, а которой и содержится нужная информация
HTTP/1.1 200 OK
Server: nginx/1.10.3
Date: Thu, 01 Mar 2018 16:26:59 GMT
Content-Type: text/html
Content-Length: 612
…
Код ответа 200 говорит о том, что ответ нормальный и сервер успешно отдал запрашиваемый клиентом контент.
Проверка ответа сервера — curl
HTTP/1.1 301 Moved Permanently
Server: nginx/1.10.3
Date: Thu, 01 Mar 2018 16:46:19 GMT
Content-Type: text/html
Content-Length: 185
Connection: keep-alive
Location: https://server-gu.ru/
Если выполнить запрос к сайту с https ответ будет 200.
Коды ответа сервера, которые можно встретить чаще всего:
Все коды, начинающиеся на 2хх означают, что запрос успешно обработан, на 3хх, что выполняется переадресация, на 4хх — произошла ошибка на стороне клиента, на 5хх — произошла ошибка на стороне сервера.
Проверить код ответа сервера также можно воспользовавшись специализированным инструментом. Он проверяет кэширование данных, но в выводе присутствует также код ответа.
Инструменты командной строки для веб-разработчика
Жизнь веб-разработчика омрачена сложностями. Особенно неприятно, когда источник этих сложностей неизвестен. То ли это проблема с отправкой запроса, то ли с ответом, то ли со сторонней библиотекой, то ли внешний API глючит? Существует куча различных прилад, способных упростить нам жизнь. Вот некоторые инструменты командной строки, которые лично я считаю бесценными.
cURL
cURL — программа для передачи данных по различным протоколам, похожая на wget. Основное отличие в том, что по умолчанию wget сохраняет в файл, а cURL выводит в командную строку. Так можно очень просто посмотреть контент веб-сайта. Например, вот как быстро получить свой текущий внешний IP:
Параметры -i (показывать заголовки) и -I (показывать только заголовки) делают cURL отличным инструментом для дебаггинга HTTP-ответов и анализа того, что конкретно сервер вам отправляет:
Параметр -L тоже полезный, он заставляет cURL автоматически следовать по редиректам. cURL поддерживает HTTP-аутентификацию, cookies, туннелирование через HTTP-прокси, ручные настройки в заголовках и многое, многое другое.
Siege
Siege — инструмент для нагрузочного тестирования. Плюс, у него есть удобная опция -g, которая очень похожа на curl –iL, но вдобавок показывает вам ещё и заголовки http-запроса. Вот пример с google.com (некоторые заголовки удалены для краткости):
Но для чего Siege действительно великолепно подходит, так это для нагрузочного тестирования. Как и апачевский бенчмарк ab, он может отправить множество параллельных запросов к сайту и посмотреть, как он справляется с трафиком. В следующем примере показано, как мы тестируем Google с помощью 20 запросов в течение 30 секунд, после чего выводится результат:
Одна из самых полезных функций Siege — то, что он может работать не только с одним адресом, но и со списком URL’ов из файла. Это отлично подходит для нагрузочного тестирования, потому что можно моделировать реальный трафик на сайте, а не просто жать один и тот же URL снова и снова. Например, вот как использовать Siege, чтобы нагрузить сервер, используя адреса из вашего лога Apache:
Для веб-трафика вы почти всегда захотите использовать параметр -W, чтобы сохранить форматирование строк, а также параметр -q, который скрывает избыточную информацию о неподходящих пакетах. Вот пример команды, которая перехватывает все пакеты с командой GET или POST:
Написание HTTP-запросов с помощью Curl
Эта статья предполагает, что вам известны основы построения сетей и язык HTML.
Увеличивающееся число приложений, которые переходят на веб, привело к тому, что тема HTTP-скриптов становится все более востребованной. Важными задачами в этой области являются автоматическое извлечение информации из интернета, отсылание или загрузка данных на web-сервера и т.п.
для получения информации о curl.
Curl не является инструментом, который будет делать все за вас. Он создает запросы, принимает данные и отсылает данные. Возможно, вам потребуется какой-то «клей» для объединения всего, возможно какой-то скриптовый язык (например bash) или несколько ручных вызовов.
1. Протокол HTTP
2. URL
3. Получить (GET) страницу
вы получите web-страницу, выведенную в ваше терминальное окно. Полный HTML-документ, который содержится по этому адресу URL.
4. Формы
4.1 GET
GET-форма использует метод GET, например следующим образом:
Если вы откроете этот код в вашем браузере, вы увидите форму с текстовым полем и кнопку с надписью «OK». Если вы введете ‘1905’ и нажмете OK, браузер создаст новый URL, по которому и проследует. URL будет представляться строкой, состоящей из пути предыдущего URL и строки, подобной «junk.cgi?birthyear=1905&press=OK».
Например, если форма располагалась по адресу «www.hotmail.com/when/birth.html», то при нажатии на кнопку OK вы попадете на URL «www.hotmail.com/when/junk.cgi?birthyear=1905&press=OK».
Большинство поисковых систем работают таким образом.
Чтобы curl сформировал GET-запрос, просто введите то, что ожидалось от формы:
4.2 POST
Метод GET приводит к тому, что вся введенная информация отображается в адресной строке вашего браузера. Может быть это хорошо, когда вам нужно добавить страницу в закладки, но это очевидный недостаток, когда вы вводите в поля формы секретную информацию, либо когда объем информации, вводимый в поля, слишком велик (что приводит к нечитаемому URL).
Протокол HTTP предоставляет метод POST. С помощью него клиент отправляет данные отдельно от URL и поэтому вы не увидете их в адресной строке.
Форма, генерирующая POST-запрос, похожа на предыдущую:
Curl может сформировать POST-запрос с теми же данными следующим образом:
Этот POST-запрос использует ‘Content-Type application/x-www-form-urlencoded’, это самый широко используемый способ.
4.3 Загрузка файлов с помощью POST (File Upload POST)
В далеком 1995 был определен дополнительный способ передавать данные по HTTP. Он задокументирован в RFC 1867, поэтому этот способ иногда называют RFC1867-posting.
Этот метод в основном разработан для лучшей поддержки загрузки файлов. Форма, которая позволяет пользователю загрузить файл, выглядит на HTML примерно следующим образом:
Заметьте, что тип содержимого Content-Type установлен в multipart/form-data.
Чтобы отослать данные в такую форму с помощью curl, введите команду:
4.4 Скрытые поля
Простой пример формы с одним видимым полем, одним скрытым и кнопкой ОК:
Чтобы отправить POST-запрос с помощью curl, вам не нужно думать о том, скрытое поле или нет. Для curl они все одинаковы:
4.5 Узнать, как выглядит POST-запрос
Когда вы хотите заполнить форму и отослать данные на сервер с помощью curl, вы наверняка хотите, чтобы POST-запрос выглядел точно также, как и выполненный с помощью браузера.
Простой способ увидеть свой POST-запрос, это сохранить HTML-страницу с формой на диск, изменить метод на GET, и нажать кнопку ‘Отправить’ (вы можете также изменить URL, которому будет передаваться данные).
Вы увидите, что данные присоединились к URL, отделенные символами ‘?’, как и предполагается при использовании GET-форм.
5. PUT
Пожалуй, лучший способ загружать данные на HTTP-сервер, это использовать PUT. Опять же, это требует программы (скрипта) на серверной части, которая знает, что делать и как принимать поток HTTP PUT.
Отослать файл на сервер при помощи curl:
6. Аутентификация
Указание curl использовать имя пользователя и пароль:
Заметьте, что когда curl работает, строка запуска (а вместе с этим и ключи, и пароли) могут быть видны другим пользователям вашей системы в списке задач. Есть способы предотвратить это. Об этом ниже.
7. Referer
HTTP-запрос может включать поле ‘referer’, которое указывает, с какого URL пользователь пришел на данный ресурс. Некоторые программы/скрипты проверяют поле ‘referer’ и не выполняют запрос, если пользователь пришел с неизвестной страницы. Хотя это и глупый способ проверки, тем не менее многие скрипты используют его. С помощью curl вы можете вписать что угодно в поле ‘referer’ и таким образом заставлять выполнять то, что вам нужно.
Это делается следующим образом:
8. User Agent
Все HTTP-запросы поддерживают поле ‘User-Agent’, в котором указывается клиентское приложение пользователя. Многие web-приложения используют эту информацию, чтобы тем или иным способом отобразить страницу. Web-программисты создают несколько версий страницы для пользователей разных браузеров в целях улучшения внешнего вида, использования различных скриптов javascript, vbscript и т.д.
Иногда вы можете обнаружить, что curl возвращает страницу не такой, какой вы ее видели в своем браузере. В этом случае как раз уместно использовать поле ‘User Agent’, чтобы в очередной раз обмануть сервер.
Замаскировать curl под Internet Explorer на машине с Windows 2000:
Почему бы не стать Netscape 4.73 на Linux-машине (PIII):
9. Перенаправления (redirects)
По умолчанию curl не идет по адресу, указанному в ‘Location:’, а просто показывает страницу как обычно. Но можно его направить следующим образом:
10. Cookies
Когда клиент соединяется с сервером по адресу, указанному в принятом cookie, клиент посылает этот cookie к серверу (если время жизни не истекло).
Многие приложения и сервера используют этот метод, чтобы объединить нескольких запросов в одну логическую сессию. Чтобы curl также мог выполнять такую функцию, мы должны уметь сохранять и отправлять cookies, как и делают браузеры.
Простейший способ отправить cookie к серверу при получении страницы с помощью curl, это добавить соответствующий ключ в командной строке:
Cookies отправляются как обычные HTTP-заголовки. Это позволяет curl сохранять cookies, сохраняя заголовки. Сохранение cookies с помощью curl выполняется командой:
У curl имеется полнофункциональный обработчик cookies, который полезен, когда вы хотите соединиться в очередной раз к серверу и использовать cookies, сохраненные в прошлый раз (либо подработанные вручную). Для использования cookies, сохраненных в файле, вызовите curl так:
11. HTTPS
Есть несколько способов обезопасить ваши HTTP-передачи. Наиболее известным протоколом, решающим эту задачу, является HTTPS, или HTTP over SSL. SSL зашифровывает все посылаемые и принимаемые по сети данные, что увеличивает вероятность того, что ваша информация останется в тайне.
Curl поддерживает запросы к HTTPS-серверам благодаря свободно распространяемой библиотеке OpenSSL. Запросы происходят обычным способом:
11.1 Сертификаты
В мире HTTPS для аутентификации в дополнение к имени пользовавателя и паролю вы используете сертификаты. Curl поддерживает сертификаты на стороне клиента. Все сертификаты заперты ключевой фразой, которую вам нужно ввести прежде чем curl может начать с ними работу. Ключевая фраза может быть указана либо в командной строке, либо введена в интерактивном режиме. Сертификаты в curl используются следующим образом:
12. Произвольные заголовки запроса
Возможно, вам понадобится изменять или добавлять элементы отдельных запросов curl.
К примеру, вы можете изменить запрос POST на PROPFIND и отправить данные как «Content-Type: text/xml» (вместо обычного Content-Type):
Вы можете удалить какой-нибудь заголовок, указав его без содержимого. Например, вы можете удалить заголовок ‘Host:’, тем самым сделав запрос «пустым»:
Также вы можете добавлять заголовки. Возможно, вашему серверу потребуется заголовок ‘Destination:’:
13. Отладка
Часто бывает так, что сайт реагирует на запросы curl не так, как на запросы браузера. В этом случае нужно максимально уподобить curl браузеру:
Укажите в поле ‘user-agent’ один из последних популярных браузеров
Заполните поле ‘referer’ как это делает браузер
14. Ссылки
RFC 2616 обязательно для чтения всем, кто хочет понять протокол HTTP.
RFC 2396 объясняет синтаксис URL.
RFC 2109 определяет работу cookies.
RFC 1867 определяет формат File Upload Post.
7 сетевых Linux-команд, о которых стоит знать системным администраторам
Существуют Linux-команды, которые всегда должны быть под рукой у системного администратора. Эта статья посвящена 7 утилитам, предназначенным для работы с сетью.
Этот материал — первый в серии статей, построенных на рекомендациях, собранных от множества знатоков Linux. А именно, я спросил у наших основных разработчиков об их любимых Linux-командах, после чего меня буквально завалили ценными сведениями. А именно, речь идёт о 46 командах, некоторые из которых отличает тот факт, что о них рассказало несколько человек.

В данной серии статей будут представлены все эти команды, разбитые по категориям. Первые 7 команд, которым и посвящена эта статья, направлены на работу с сетью.
Команда ip
Команда ip — это один из стандартных инструментов, который необходим любому системному администратору для решения его повседневных задач — от настройки новых компьютеров и назначения им IP-адресов, до борьбы с сетевыми проблемами существующих систем. Команда ip может выводить сведения о сетевых адресах, позволяет управлять маршрутизацией трафика и, кроме того, способна давать данные о различных сетевых устройствах, интерфейсах и туннелях.
Синтаксис этой команды выглядит так:
Самое важное тут — это (подкоманда). Здесь можно использовать, помимо некоторых других, следующие ключевые слова:
Вывод IP-адресов, назначенных интерфейсу на сервере:
Назначение IP-адреса интерфейсу, например — enps03 :
Удаление IP-адреса из интерфейса:
Изменение статуса интерфейса, в данном случае — включение eth0 :
Изменение статуса интерфейса, в данном случае — выключение eth0 :
Изменение статуса интерфейса, в данном случае — изменение MTU eth0 :
Изменение статуса интерфейса, в данном случае — перевод eth0 в режим приёма всех сетевых пакетов:
Добавление маршрута, используемого по умолчанию (для всех адресов), через локальный шлюз 192.168.1.254, который доступен на устройстве eth0 :
Добавление маршрута к 192.168.1.0/24 через шлюз на 192.168.1.254:
Добавление маршрута к 192.168.1.0/24, который доступен на устройстве eth0 :
Удаление маршрута для 192.168.1.0/24, для доступа к которому используется шлюз 192.168.1.254:
Вывод маршрута к IP 10.10.1.4:
Команда ifconfig
Команда mtr
Синтаксис команды выглядит так:
Если вызвать эту команду, указав лишь имя или адрес хоста — она выведет сведения о каждом шаге маршрутизации. В частности — имена хостов, сведения о времени их ответа и о потерянных пакетах:
А следующий вариант команды позволяет выводить и имена, и IP-адреса хостов:
Так можно задать количество ping-пакетов, которые нужно отправить системе, маршрут к которой подвергается анализу:
А так можно получить отчёт, содержащий результаты работы mtr :
Вот — ещё один вариант получения такого отчёта:
Для того чтобы принудительно использовать TCP вместо ICMP — надо поступить так:
А вот так можно использовать UDP вместо ICMP:
Вот — вариант команды, где задаётся максимальное количество шагов маршрутизации:
Так можно настроить размер пакета:
Для вывода результатов работы mtr в формате CSV используется такая команда:
Вот — команда для вывода результатов работы mtr в формате XML:
Команда tcpdump
Утилита tcpdump предназначена для захвата и анализа пакетов.
Установить её можно так:
Прежде чем приступить к захвату пакетов, нужно узнать о том, какой интерфейс может использовать эта команда. В данном случае нужно будет применить команду sudo или иметь root-доступ к системе.
Если нужно захватить трафик с интерфейса eth0 — этот процесс можно запустить такой командой:
▍ Захват трафика, идущего к некоему хосту и от него
Можно отфильтровать трафик и захватить лишь тот, который приходит от определённого хоста. Например, чтобы захватить пакеты, идущие от системы с адресом 8.8.8.8 и уходящие к этой же системе, можно воспользоваться такой командой:
Для захвата трафика, идущего с хоста 8.8.8.8, используется такая команда:
Для захвата трафика, уходящего на хост 8.8.8.8, применяется такая команда:
▍ Захват трафика, идущего в некую сеть и из неё
Трафик можно захватывать и ориентируясь на конкретную сеть. Делается это так:
Ещё можно поступить так:
Можно, кроме того, фильтровать трафик на основе его источника или места, в которое он идёт.
Вот — пример захвата трафика, отфильтрованного по его источнику (то есть — по той сети, откуда он приходит):
Вот — захват трафика с фильтрацией по сети, в которую он направляется:
▍ Захват трафика, поступающего на некий порт и выходящего из некоего порта
Вот пример захвата трафика только для DNS-порта по умолчанию (53):
Захват трафика для заданного порта:
Захват только HTTPS-трафика:
Захват трафика для всех портов кроме 80 и 25:
Команда netstat
Если в вашей системе netstat отсутствует, установить эту программу можно так:
Ей, в основном, пользуются, вызывая без параметров:
В более сложных случаях её вызывают с параметрами, что может выглядеть так:
Можно вызывать netstat и с несколькими параметрами, перечислив их друг за другом:
Для вывода сведений обо всех портах и соединениях, вне зависимости от их состояния и от используемого протокола, применяется такая конструкция:
Для вывода сведений обо всех TCP-портах применяется такой вариант команды:
Если нужны данные по UDP-портам — утилиту вызывают так:
Список портов любых протоколов, ожидающих соединений, можно вывести так:
Список TCP-портов, ожидающих соединений, выводится так:
Так выводят список UDP-портов, ожидающих соединений:
А так — список UNIX-портов, ожидающих соединений:
Вот — команда для вывода статистических сведений по всем портам вне зависимости от протокола:
Так выводятся статистические сведения по TCP-портам:
Для просмотра списка TCP-соединений с указанием PID/имён программ используется такая команда:
Для того чтобы найти процесс, который использует порт с заданным номером, можно поступить так:
Команда nslookup
Команда nslookup используется для интерактивного «общения» с серверами доменных имён, находящимися в интернете. Она применяется для выполнения DNS-запросов и получения сведений о доменных именах или IP-адресах, а так же — для получения любых других специальных DNS-записей.
Рассмотрим распространённые примеры использования этой команды.
Получение A-записи домена:
Просмотр NS-записей домена:
Выяснение сведений о MX-записях, в которых указаны имена серверов, ответственных за работу с электронной почтой:
Обнаружение всех доступных DNS-записей домена:
Проверка использования конкретного DNS-сервера (в данном случае запрос производится к серверу имён ns1.nsexample.com ):
Проверка A-записи для выяснения IP-адресов домена — это распространённая практика, но иногда нужно проверить то, имеет ли IP-адрес отношение к некоему домену. Для этого нужно выполнить обратный просмотр DNS:
Команда ping
Команда ping — это инструмент, с помощью которого проверяют, на уровне IP, возможность связи одной TCP/IP-системы с другой. Делается это с использованием эхо-запросов протокола ICMP (Internet Control Message Protocol Echo Request). Программа фиксирует получение ответов на такие запросы и выводит сведения о них вместе с данными о времени их приёма-передачи. Ping — это основная команда, используемая в TCP/IP-сетях и применяемая для решения сетевых проблем, связанных с целостностью сети, с возможностью установления связи, с разрешением имён.
Эта команда, при простом способе её использования, принимает лишь один параметр: имя хоста, подключение к которому надо проверить, или его IP-адрес. Вот как это может выглядеть:
Обычно, если запустить команду ping в её простом виде, не передавая ей дополнительные параметры, Linux будет пинговать интересующий пользователя хост без ограничений по времени. Если нужно изначально ограничить количество ICMP-запросов, например — до 10, команду ping надо запустить так:
Или можно указать адрес интерфейса. В данном случае речь идёт об IP-адресе 10.233.201.45:
Применяя эту команду, можно указать и то, какую версию протокола IP использовать — v4 или v6:
В процессе работы с утилитой ping вы столкнётесь с различными результатами. В частности, это могут быть сообщения о нештатных ситуациях. Рассмотрим три таких ситуации.
▍ Destination Host Unreachable
Вероятной причиной получения такого ответа является отсутствие маршрута от локальной хост-системы к целевому хосту. Или, возможно, это удалённый маршрутизатор сообщает о том, что у него нет маршрута к целевому хосту.
▍ Request timed out
Если результат работы ping выглядит именно так — это значит, что локальная система не получила, в заданное время, эхо-ответов от целевой системы. По умолчанию используется время ожидания ответа в 1 секунду, но этот параметр можно настроить. Подобное может произойти по разным причинам. Чаще всего это — перегруженность сети, сбой ARP-запроса, отбрасывание пакетов фильтром или файрволом и прочее подобное.
▍ Unknown host/Ping Request Could Not Find Host
Такой результат может указывать на то, что неправильно введено имя хоста, или хоста с таким именем в сети просто не существует.
О хорошем качестве связи между исследуемыми системами говорит уровень потери пакетов в 0%, а так же — низкое значение времени получения ответа. При этом в каждом конкретном случае время получения ответа варьируется, так как оно зависит от разных параметров сети. В частности — от того, какая среда передачи данных используется в конкретной сети (витая пара, оптоволокно, радиоволны).
Итоги
Надеемся, вам пригодятся команды и примеры их использования, о которых мы сегодня рассказали. А если они вам и правда пригодились — возможно, вам будет интересно почитать продолжение этого материала.
Базовые команды Linux для тестировщиков и не только
Всем привет! Меня зовут Саша, и я больше шести лет занимаюсь тестированием бэкенда (сервисы Linux и API). Мысль о статье у меня появилась после очередной просьбы знакомого тестировщика подсказать ему, что можно почитать по командам Linux перед собеседованием. Обычно от кандидата на позицию QA инженера требуют знание основных команд (если, конечно, подразумевается работа с Linux), но как понять, про какие команды стоит почитать во время подготовки к собеседованию, если опыта работы с Linux мало или вовсе нет?
Поэтому, хоть про это уже и много раз написано, я всё же решился написать ещё одну статью «Linux для новичков» и перечислить здесь базовые команды, которые нужно знать перед любым собеседованием в отдел (или компанию), где используют Linux. Я подумал, какие команды и утилиты и с какими параметрами я использую чаще всего, собрал фидбек от коллег, и скомпоновал это всё в одну статью. Статья условно делится на 3 части: сначала краткая информация об основах ввода-вывода в терминале Linux, затем обзор самых базовых команд, а в третьей части описывается решение типовых задач в Linux.
У каждой команды есть много опций, здесь все они перечислены не будут. Всегда можно ввести `man ` или ` —help`, чтобы узнать о команде подробнее.
Если какая-то команда выполняется слишком долго, её можно завершить, нажав в консоли Ctrl+C (процессу посылается сигнал SIGINT).
Немного о выводе команд
Когда запускается процесс в Linux, создаётся 3 стандартных потока данных для этого процесса: stdin, stdout и stderr. Они имеют номер 0, 1 и 2 соответственно. Но нас сейчас интересуют stdout и, в меньшей степени, stderr. Из названий несложно догадаться, что stdout используется для вывода данных, а stderr — для вывода сообщений об ошибках. По умолчанию при запуске команды в Linux stdout и stderr выводят всю информацию на консоль, однако, если вывод команды большой, может быть удобно перенаправить его в файл. Это можно сделать, например, так:
Если мы выведем содержимое файла man_signal, то мы увидим, что оно идентично тому, что было бы при простом запуске команды `man signal`.
Операция перенаправления `>` по умолчанию использует stdout. Можно указать о перенаправлении stdout явно: `1>`. Аналогично можно указать о перенаправлении stderr: `2>`. Можно эти операции скомбинировать и таким образом разделить обычный вывод команды и вывод сообщений об ошибках:
Перенаправить и stdout, и stderr в один файл можно следующим образом:
Операция перенаправления `2>&1` означает перенаправление stderr туда же, куда направлен stdout.
Еще один удобный инструмент для работы с вводом-выводом (а точнее, это удобное средство межпроцессного взаимодействия) — pipe (или конвейер). Конвейеры часто используются для связи нескольких команд: stdout команды перенаправляется в stdin следующей, и так по цепочке:
Базовые команды Linux
Вывести текущую (рабочую) директорию.
Вывести текущую дату и время системы.
Данная команда показывает, кто залогинен в системе. Помимо этого также на экран выводится uptime и LA (load average).
Вывести содержимое директории. Если не передать путь, то выведется содержимое текущей директории.
Лично я часто использую опции -l (long listing format — вывод в колонку с дополнительной информацией о файлах), -t (сортировка по времени изменения файла/директории) и -r (обратная сортировка — в сочетании с -t наиболее «свежие» файлы будут внизу):
Есть 2 специальных имени директории: «.» и «..«. Первое означает текущую директорию, второе — родительскую директорию. Их бывает удобно использовать в различных командах, в частности, ls:
Также есть полезная опция для вывода скрытых файлов (начинаются на «.«) — -a:
И еще можно использовать опцию -h — вывод в human readable формате (обратите внимание на размеры файлов):
Изменить текущую директорию.
Если не передавать имя директории в качестве аргумента, будет использоваться переменная окружения $HOME, то есть домашняя директория. Также может быть удобно использовать `
` — специальный символ, означающий $HOME:
mkdir
Иногда нужно создать определенную структуру директорий: например, директорию в директории, которой не существует. Чтобы не вводить несколько раз подряд mkdir, можно использовать опцию -p — она позволяет создать все недостающие директории в иерархии. Также с этой опцией mkdir не вернет ошибку, если директория существует.
Копировать файл или директорию.
У этой команды также есть опции -r и -f, их можно использовать, чтобы гарантированно скопировать иерархию директорий и папок в другое место.
Переместить или переименовать файл или директорию.
Вывести содержимое файла (или файлов).
Также стоит обратить внимание на команды head (вывести n первых строк или байт файла) и tail (о ней — далее).
Вывести n последних строк или байт файла.
Очень полезной является опция -f — она позволяет выводить новые данные в файле в реальном времени.
Иногда текстовый файл слишком большой, и неудобно выводить его командой cat. Тогда можно открыть его с помощью команды less: файл будет выводиться по частям, доступна навигация по этим частям, поиск и прочий простой функционал.
Также может оказаться удобным вариант использования less с конвейером (pipe):
Вывести список процессов.
Я сам обычно использую BSD опции «aux» — вывести все процессы в системе (так как процессов может быть много, я вывел только первые 5 из них, использовав конвейер (pipe) и команду head):
Многие также используют BSD опции «axjf«, что позволяет вывести дерево процессов (здесь я убрал часть вывода для демонстрации):
У этой команды много различных опций, так что при активном использовании рекомендую ознакомиться с документацией. Для большинства же случаев хватит просто знать «ps aux«.
Послать сигнал процессу. По умолчанию посылается сигнал SIGTERM, который завершает процесс.
Так как процесс может иметь обработчики сигналов, kill не всегда приводит к ожидаемому результату — моментальному завершению процесса. Чтобы «убить» процесс наверняка, нужно послать процессу сигнал SIGKILL. Однако это может привести к потере данных (например, если процесс перед завершением должен сохранить какую-то информацию на диск), так что нужно пользоваться такой командой осторожно. Номер сигнала SIGKILL — 9, поэтому короткий вариант команды выглядит так:
Помимо упомянутых SIGTERM и SIGKILL существует еще множество различных сигналов, их список можно легко найти в интернете. И не забывайте, что сигналы SIGKILL и SIGSTOP не могут быть перехвачены или проигнорированы.
Послать хосту ICMP пакет ECHO_REQUEST.
По умолчанию ping работает, пока его не завершить вручную. Поэтому может быть полезна опция -c — количество пакетов, после отправки которых ping завершится самостоятельно. Ещё одна опция, которую я иногда использую — -i, интервал между посылками пакетов.
OpenSSH SSH клиент, позволяет подключаться к удаленному хосту.
Есть много нюансов в использовании SSH, также этот клиент обладает большим количеством возможностей, поэтому при желании (или необходимости) можно почитать про это более подробно.
Копировать файлы между хостами (для этого используется ssh).
rsync
Также для синхронизации директорий между хостами можно использовать rsync (-a — archive mode, позволяет скопировать полностью всё содержимое директории «как есть», -v — вывод на консоль дополнительной информации):
Вывести на экран строку текста.
Здесь заслуживают внимания опции -n — не дополнять строку переносом строки в конце, и -e — включить интерпретацию экранирования с помощью «\».
Также с помощью этой команды можно выводить значения переменных. Например, в Linux exit code последней завершенной команды хранится в специальной переменной $?, и таким образом можно узнать, какая именно ошибка произошла в последнем запущенном приложении:
telnet
Клиент для протокола TELNET. Используется для коммуникации с другим хостом.
Если нужно использовать протокол TLS (напомню, что SSL давно устарел), то telnet для этих целей не подойдёт. Зато подойдёт клиент openssl:
Решение типовых задач в Linux
Изменить владельца файла
Изменить владельца файла или директории можно с помощью команды chown:
В параметр этой команде нужно отдать нового владельца и группу (опционально), разделенных двоеточием. Также при изменении владельца директории может быть полезна опция -R — тогда владельцы изменятся и у всего содержимого директории.
Изменить права доступа файла
Эта задача решается с помощью команды chmod. В качестве примера приведу установку прав «владельцу разрешено чтение, запись и исполнение, группе разрешено чтение и запись, всем остальным — ничего»:
Первая 7 (это 0b111 в битовом представлении) в параметре означает «все права для владельца», вторая 6 (это 0b110 в битовом представлении) — «чтение и запись», ну и 0 — это ничего для остальных. Битовая маска состоит из трёх битов: самый младший («правый») бит отвечает за исполнение, следующий за ним («средний») — за запись, и самый старший («левый») — за чтение.
Также можно выставлять права с помощью специальных символов (мнемонический синтаксис). Например, в следующем примере сначала убираются права на исполнение для текущего пользователя, а затем возвращаются обратно:
У этой команды есть много вариантов использования, поэтому советую прочитать про неё подробнее (особенно про мнемонический синтаксис, например, здесь).
Вывести содержимое бинарного файла
Это можно сделать с помощью утилиты hexdump. Ниже приведены примеры её использования.
С помощью этой утилиты можно вывести данные и в других форматах, однако наиболее часто могут пригодиться именно такие варианты её использования.
Искать файлы
Найти файл по части имени в дереве каталогов можно с помощью команды find:
Также доступны другие опции и фильтры поиска. Например, так можно найти файлы в папке test, созданные более 5 дней назад:
Искать текст в файлах
Справиться с этой задачей поможет команда grep. У неё есть множество вариантов использования, здесь в качестве примера указан самый простой.
Один из популярных способов использования команды grep — использование её в конвейере (pipe):
Опция -v позволяет сделать эффект grep‘а обратным — будут выводиться только строки, не содержащие паттерн, переданный в grep.
Смотреть установленные пакеты
Универсальной команды нет, потому что всё зависит от дистрибутива Linux и используемого пакетного менеджера. Скорее всего вам поможет одна из следующих команд:
Посмотреть, сколько места занимает дерево директорий
Один из вариантов использования команды du:
Можно менять значение параметра -d, чтобы получать более подробную информацию о дереве директорий. Также можно использовать команду в комбинации с sort:
Опция -h у команды sort позволяет сортировать размеры, записанные в human readable формате (например, 1K, 2G), опция -r позволяет отсортировать данные в обратном порядке.
«Найти и заменить» в файле, в файлах в директории
Данная операция выполняется с помощью утилиты sed (без флага g в конце заменится только первое вхождение «old-text» в строке):
Можно использовать её для нескольких файлов сразу:
Вывести колонку из вывода
Справиться с этой задачей поможет awk. В данном примере выводится вторая колонка вывода команды `ps ux`:
При этом надо иметь ввиду, что awk обладает гораздо более богатым функционалом, так что при необходимости работы с текстом в командной строке стоит почитать об этой команде подробнее.
Узнать IP адрес по имени хоста
С этим поможет одна из следующих команд:
Сетевая информация
Можно использовать ifconfig:
При этом, если, например, вас интересует только IPv4, то можно добавить опцию -4:
Посмотреть открытые порты
Для этого используют утилиту netstat. Например, чтобы посмотреть все слушающие TCP и UDP порты с отображением PID’а процесса, слушающего порт, и с числовым представлением порта, нужно использовать ее со следующими опциями:
Информация о системе
Получить данную информацию можно с помощью команды uname.
Чтобы понять, в каком формате производится вывод, можно обратиться к help‘у данной команды:
Информация о памяти
Чтобы понять, сколько оперативной памяти занято или свободно, можно воспользоваться командой free.
Информация о файловых системах (свободное место на дисках)
Команда df позволяет посмотреть, сколько места свободно и занято на примонтированных файловых системах.
Опция -T указывает, что нужно выводить тип файловой системы.
Информация о задачах и различной статистике по системе
Для этого используется команда top. Она способна вывести разную информацию: например, топ процессов по использованию оперативной памяти или топ процессов по использованию процессорного времени. Также она выводит информацию о памяти, CPU, uptime и LA (load average).
Эта утилита обладает богатым функционалом, так что если вам надо часто ей пользоваться, лучше ознакомиться с её документацией.
Дамп сетевого трафика
Для перехвата сетевого трафика в Linux используется утилита tcpdump. Чтобы сдампить трафик на порте 12345, можно воспользоваться следующей командой:
Опция -A говорит о том, что мы ходим видеть вывод в ASCII (поэтому это хорошо для текстовых протоколов), -i any указывает, что нас не интересует сетевой интерфейс, port — трафик какого порта дампить. Вместо port можно использовать host, либо комбинацию host и port (host A and port X). И еще полезной может оказаться опция -n — не конвертировать адреса в хостнеймы в выводе.
Что если трафик бинарный? Тогда нам поможет опция -X — выводить данные в hex и ASCII:
При этом надо учитывать, что в обоих вариантах использования будут выводиться IP пакеты, поэтому в начале каждого из них будут бинарные заголовки IP и TCP. Вот пример вывода для запроса «123» посланного в сервер, слушающий порт 12345: