
Андрей Викторович Столяров: сайт автора
Программирование на языке ассемблера NASM для ОС Unix

Текст этой книги в переработанном виде вошёл в состав «Введения в профессию» в виде третьей части (во втором издании это первый том, в первом издании был второй); небольшие фрагменты материала также вошли в первую (вводную) часть. Переизданий этого материала в виде отдельной книги больше не планируется. Автор настоятельно рекомендует читать Программирование: введение в профессию вместо данной (и сейчас уже устаревшей) книги.
Аннотация
Пособие основано на лекциях, читавшихся автором в рамках курса «Архитектура ЭВМ и язык ассемблера» в Ташкентском филиале МГУ весной 2007 года; часть материала также прошла апробацию в рамках курса «Архитектура ЭВМ и системное программное обеспечение» кафедры Прикладной математики МГТУГА в 2008, 2009 и 2010 гг.
Пособие ориентировано на практические занятия с использованием системы команд i386, «плоской» (бессегментной) модели памяти, ассемблера NASM и операционной системы Linux или FreeBSD; в частности, описываются конвенции системных вызовов обеих систем, также для обеих систем приводятся исходные тексты файлов с макроопределениями, призванными облегчить ассемблерное программирование на ранних этапах изучения дисциплины.
Бумажные публикации

Пособие впервые опубликовано редакционно-издательским отделом МГТУГА в июле 2010 года под заголовком «Архитектура ЭВМ и системное программное обеспечение: язык ассемблера в ОС Unix» в виде двух отдельных частей; ISBN 978-5-86311-769-0 (часть I) и 978-5-86311-770-6 (часть II).
Второе издание пособия, включающее ряд исправлений, новую главу об арифметическом сопроцессоре, параграф, посвящённый машинному представлению целых чисел и некоторые другие дополнения, издано в 2011 году в издательстве МАКС Пресс. ISBN 978-5-317-03627-0.
Электронная версия
PDF-файл, полностью соответствующий печатной версии второго издания, можно взять тут: http://www.stolyarov.info/books/pdf/nasm_unix.pdf
Статус бумажной версии
Издание поступало в свободную продажу. К настоящему времени полностью распродано.
| Прикрепленный файл | Размер |
|---|---|
| Файл stud_io.inc для FreeBSD | 2.08 кб |
| Файл stud_io.inc для Linux | 2.21 кб |
| Архив с текстом примера greet из пар. 5.3 (часть II) | 1.38 кб |
| Программа cmdl.asm из пар. 4.4 (часть II) | 1.1 кб |
| Программа match.asm из пар. 2.6.9 (часть I) | 1.7 кб |
Trailing whitespaces

ах ты ж чёрт
Спасибо
Не знаю почему тут бомбит так у некоторых комментаторов.
Врядли я конечно, когда-нибудь буду писать на ассемблере, но кто знает. Автоу ещё хочется сказать, спасибо, что выложил книгу в открытый доступ. Мне как человеку, который начал интересоваться системным программированием и вообще тем что происходит внутри компьютера было интересно и полезно. Ещё раз спасибо!
Надоели уже эти все современные свителки-перделки, никакой ценности они не несут, не говоря уже о моральных и этических аспектах.
Пожалуйста 
Только зачем это старьё читать? При подготовке второго тома я материал этой книжки изрядно причесал и вообще всячески улучшил.
А писать на ассемблере на практике обычно нет никакого смысла, соответствующие знания и опыт нужны исключительно для понимания сути вещей.
Читаю страницу
Читаю страницу 32:
«Макрос PUTCHAR предназначен для вывода на печать одного символа. Наконец, аргументом этого макроса может выступать исполнительный адрес заключенный в квадратные скобки»
Вот эта программа с посимвольным выводом строки работает правильно:
А вот если раскомментировать две строки (просто исполнительный адрес берется из EDX), вылетает с треском. Где я ошибаюсь?
Очевидно же:
Первая из этих двух команд берёт четыре байта, которые лежат в памяти по адресу string+eax, и кладёт их в edx. Вторая ЭТО использует в качестве адреса, тогда как по смыслу там не адрес вовсе, а первые четыре байта вашей строки. Внимательнее, внимательнее.
Да уж!
Это я не подумавши сделал! )))
Ну, то есть, сначала-то сразу указатель отдавался на разыменование PUTCHAR, а потом добавил транзит через EDX, типа, «какая разница»! Вот она и «разница», бедный указатель разыменовали дважды. А вроде, все просто!
Погорячился, был неправ. Спасибо.
Если вы бы не
Если вы бы не писали сокращенно команды, многое стало бы очевидным и хватало бы времени подумать. Пишите «offset, byte ptr и т.п.» и не используйте «mov» для определения адреса («lea»). Не давайте компилятору повода додумывать за вас что вы написали.
В nasm’е нет ни
В nasm’е нет ни слова offset, ни этого страшного byte ptr. К большому счастью. Вы бы хотя бы разобрались сначала, о каком ассемблере идёт речь и как он устроен, а потом уже лезли со своими нелепыми советами, особенно насчёт применения lea вместо mov.
Ошибка компоновщика
Не сработало
Nasm под MacOS
«возможно ли это вообще под макосью»
Говорят: «Можно и зайца научить курить, нет ничего невозможного». Если мой заяц не притворяется, MacOS Sierra 10.12.1, nasm 2.12.02, то так:
Прикольно
То есть там конвенция BSD, причём даже 32-битные приложения поддерживаются. Само по себе это прикольно, спасибо за результаты эксперимента, заодно мы теперь знаем, что точка входа там называется start без подчёркивания в начале. Может быть, вы ещё расскажете, как туда Nasm поставить?
Но вот насчёт стека не вполне понятно, когда он, по-вашему, должен быть кратен 16? На момент int 80h? Так он и в вашем примере не кратен. А подпрограмм никаких в stud_io.inc нет.
поставить Nasm на MacOS
>Может быть, вы ещё расскажете, как туда Nasm поставить?
Это не очень детективная история.
stud_io.inc
За
Версии для Windows нет и не будет.
отдельный респект, свободой веет от неё.
На здоровье
В книжных этой книги нет, единственный вариант сейчас — заказать её на этом сайте, но этот вариант тоже скоро кончится. Книга издавалась тиражом 100 экз., какие там книжные.
А версии под винду не будет в том числе и по причине сугубо технической: тамошний набор системных вызовов может осилить только мазохист, я таковым не являюсь.
Добрый вечер.
Добрый вечер. Подскажите, где можно взять файл «stud_io.inc» и в какую папку nasma положить? Пытался на этой странице взять, но куда и с каким разрешением положить не знаю.
Во-первых, термин «папка» в применении к директориям недопустим, оставьте такую терминологию секретаршам. Папки обычно делают из картона и ставят в шкаф. В компьютере никаких «папок» нет и быть не может.
Во-вторых, на вопрос «где взять» вы ответили сами. Файл следует взять на этой странице, выше есть ссылка.
В-третьих, чтобы всё сработало, этот файл должен находиться в той же директории, что и ваш файл, который вы транслируете nasm’ом. Вообще-то это довольно очевидно, если внимательно прочитать в книге, как работает макродиректива %include.
Но вот насчёт «с каким разрешением» — на такой вопрос я ответить не могу, я, пардон, даже представить себе не могу, что вы имеете в виду. Если имеется в виду действительно «разрешение», то такая характеристика присуща растровым графическим файлам, видео и (с некоторой натяжкой) аудио, но никак не текстовым файлам. Если имеются в виду «разрешения» (а не «разрешение»), то есть права доступа (один из очень кривых вариантов перевода термина «permissions»), то пользователь, под которым вы работаете, должен иметь права на чтение этого файла, только вряд ли это то, что вы имели в виду. Наконец, можно предположить, что имелось в виду «расширение» (то есть часть имени файла, указывающая на его формат и отделяемая от имени точкой) — в этом случае да будет вам известно, что это пресловутое «расширение» (extension) бывает только под Windows. В *nix-системах используется понятие «суффикс», которое не является однозначно связанным с типом файла и вообще необязательно. В применении к stud_io.inc таким суффиксом, очевидно, является «.inc».
На всякий случай отмечу, что, ежели вам пришло в голову пробовать это всё под виндой, то stud_io.inc вам ничем не поможет — он зависит не только от конкретного набора поддерживаемых операционкой системных вызовов, но и от конкретной конвенции вызовов, именно поэтому для Linux и FreeBSD используются совершенно разные версии. Версии для Windows нет и не будет.
Ещё про 64 бита
Нарылась любопытная ссылочка:
Что-то сдаётся мне, что 64-битные архитектуры идут далеко-далеко лесом, и так ещё лет на десять.
Вот еще
Хочу сказать
Хочу сказать огромное спасибо за Вашу книгу. К своему стыду должен признать, что несмотря на то, что я уже получил высшее образование по профильной специальности, некоторые вопросы, касающиеся низкоуровневого программирования, оставались для меня не до конца ясными. Ваша книга помогла решить эту проблему. Очень жаль, что у меня не было подобного курса в университете.
Инструкция loop
Здравствуйте.
На странице 64 в вашей книге:
>Однако команда loop lp, делая те же действия, работает быстее.
В IA-32 Intel® Architecture Optimization Reference Manual написано следующее:
Assembly/Compiler Coding Rule 41. (ML impact, M generality) Avoid using complex instructions (for example, enter, leave, or loop) that generally have more than four μops and require multiple cycles to decode. Use sequences of simple instructions instead
http://www.openwatcom.org/ftp/devel/docs/intel%20optimisations%20manual%.
Спасибо!
Про enter/leave я знал, но что это к loop тоже относится, никак не мог предположить. Учту в следующем издании, если таковое когда-нибудь будет.
Скорость инструкций для разных процессоров
Я тут нашел таблицу со скоростями инструкций http://agner.org/optimize/instruction_tables.pdf
Для первого пентиума loop быстрее, если я все правильно понял. Скорее всего, аналогичная ситуация будет и для старых i386 процессоров
Спасибо!
Тоже весьма любопытная ссылочка, thanks!
Mac OS X
А можно ли, и как запустить его на Mac OS X?
Можно-то можно
Что можно — это я не сомневаюсь. Сам NASM представляет собой программу, написанную на ANSI C, так что с его компиляцией и запуском проблем не будет. Более того, вроде бы (если не ошибаюсь) там должны быть те же соглашения о системных вызовах, что и под FreeBSD, потому что в глубине души эта самая Mac OS X и есть FreeBSD :), так что можно будет даже запустить программы, написанные для NASM.
Спасибо
Спасибо большое за книгу и Ваш труд.
Выделение памяти
Добрый день, Андрей Викторович.
Могли бы Вы прояснить ситуацию, возникшую в процессе чтения Вашего пособия. Заключается она в следующем: если выделять инициализированную память директивой db (dw, dd), то в параметрах указываются значения через запятую, кот. будут храниться в бинарнике. Если же указать одно значение, например, x db 150, то получается, что выделяется одна ячейка памяти и в эту ячейку памяти заносится байт, принимающий значение 150 (10010110) и x указывает на эту ячейку (точнее ассемблер ассоциирует эту метку с адресом ячейки на этапе ассемблирования). А если бы использовалась директива выделения неинициализированной памяти x resb 150, то здесь выделилась бы память размером в 150 однобайтовых ячеек. Верно? Наставьте, пожалуйста, непонимающего на путь света =). Заранее спасибо.
Абсолютно верно
Вы совершенно правы, а в книге на стр. 50 опечатка. Спасибо за её выявление.
Это Вам
Это Вам огромное спасибо за книгу. Стиль изложения великолепен. Желаю Вам, чтобы Ваши творческие труды продолжались также успешно. А в гостевой книги комментарий #43 оставил я. Прошу прощения за дублирование, т.к. боялся, что он не прошел премодерацию. Еще раз спасибо за ответ.
Огроммное
«Уж сколько раз твердили миру»
Да пожалуйста, мне не жалко  А где это вы в моих книгах нашли объяснение указателей? Вроде бы учебника по чистому Си я ещё не написал, да и по Паскалю тоже.
А где это вы в моих книгах нашли объяснение указателей? Вроде бы учебника по чистому Си я ещё не написал, да и по Паскалю тоже.
Без розовых очков.
. И где, простите, Sun Microsystems и её SPARC.
SPARC, простите, вот здесь, в первой строчке TOP 500, в суперкомпьютере производительностью порядка десяти петафлоп. Но о задачах, для которых и такой производительности будет мало, Вы, наверное, даже и не слыхали.
Пять минут смеха продлевают жизнь на сутки
Ситуация, ей-богу, начинает меня забавлять. Я уж думал, вы сдулись, но ни фига — таки припёрлись опять, причём только для того, чтобы вывалить толпу «аргументов», содержательная ценность которых приблизительно равна сакраментальному утверждению «сам дурак». У вас по существу-то есть что возразить? Ну а пока вы об этом думаете, проведём работу над ошибками.
Насчёт спарков: ну опять вы со своими ракетами. Не волнуют меня суперкомпьютеры, и в особенности меня не волнует top500, представляющий собой бессмысленное мерянье пиписьками, исполняемое, что несколько обидно, за чужой счёт (иногда, замечу, и мой счёт, я ведь тоже налоги плачу). Попадание в верхние позиции top500 означает ровно одно: у кого-то нашлось больше лишних (при этом чужих) денег, чем у других. Вы вот мне скажите, где мне сейчас купить десктоп на спарке, чтобы его на стол поставить, взгромоздить на него тот самый Debian (NB: разумеется, я знаю, на скольких платформах он работает; я, знаете ли, с Linux работаю с 1994 года, а с 1997 — только с ним; больше того, можно было бы заметить, что я и в проекте Openwall участвую, и не только в нём) — так вот, взгромоздить и использовать в качестве рабочего инструмента заместо этого идиотского интела. Что до задач — NASA человека на Луну запустила, обладая совокупной вычислительной мощностью в разы меньшей, нежели мощность современного мобильника. Если программы писать через. ээ. короче, если их как попало писать, то вам любого суперкомпьютера окажется мало. А этот ваш первый в top500 жрёт почти 13 мегаватт, то есть он за месяц одного электричества съедает на сумму, приблизительно соответствующую стоимости строительства многоквартирного дома. Меня это обстоятельство интересует гораздо больше, чем те прожорливые модели, которые на нём обсчитываются.
Миллионы людей вокруг, как это ни печально, действительно идиоты, идиоты вообще преобладают. Среди программистов идиотов меньше, чем «в целом по больнице», но и тут их более чем хватает, и сто три системных вызова, выданные программой, которая по сути своей должна была бы состоять из трёх машинных команд — тому подтверждение (кстати, опять же — по существу есть что сказать на эту тему? Или вы всерьёз полагаете, что 103 вызова в исполнении /bin/true — это нормально?) Но идиоты идиотами, а с чего это вы решили, что я «один»? Между делом, круг моих знакомств среди людей, имеющих прямое отношение к ядрам и дистрибутивам, тоже можно было бы достаточно легко установить — ссылки есть прямо здесь на сайте, да и на гугле никого пока не забанили. Не, ну ладно, вы вот другое скажите: вы пробовали когда-нибудь читать исходники glibc? Я пробовал. Эти люди мне бы зачёт не сдали со своим кодинг стайлом (как они сами ЭТО читают — для меня вопрос открытый). А ещё мне как-то раз пришлось в GNU tar добавлять лишнюю опцию, так я туде тоже занырнул. И сходу нашел супер-конструкцию: парочка не-статических функций в модуле (не только не статических, но и вынесенных в хидер), которые реально вызываются только из статических (!) функций того же модуля. Причём всё это было обнаружено при попытке пофиксить два предупреждения компилятора. Мой отчёт по этому поводу можно вот тут, например, посмотреть: http://permalink.gmane.org/gmane.comp.gnu.tar.bugs/3124 Что такое GNU tar, насколько плотно оно используется — объяснять надо? И что можно сказать о таких вывертах в официальном релизе? (NB: я вообще ничего специально не искал, это был мой первый и последний опыт правки мейнстримовых программ — и сходу вот такое).
Книжка Реймонда — она ничего, да (хотя утверждение о том, что pipe — механизм устаревший, поскольку есть сокеты, мне глаз резануло в своё время весьма и весьма). Пару раз я её уже читал, перечитывать в третий раз, пожалуй, всё-таки не стану, некогда. Кстати, вы могли бы и заметить, что в моей книжке 2006 года издания имеются ссылки и на Реймонда, и на Стивенса, и на Танненбаума (хотя его я не люблю, он вечно пишет не о том), и на Торвальдса. Но за язык никто не тянул: берём с полки Реймонда и читаем главу 20. Лучше с карандашиком. Хотя что-то мне сдаётся, что вы сами Реймонда если и открывали, то ни хрена там не увидели.
Но самое занятное, конечно, что вы меня антиглобалистом назвали — вот тут я, извините, долго ржал. Я вообще-то либертарианец, а либертарианство и антиглобализм несовместимы принципиально. Опять же, мою принадлежность к либертарианцам можно было бы установить прямо тут, вот на этом же сайте, из текста вот этого вот сборника. Тьфу.
Да, так вот — мы с вами что-то в неравном положении. Вам про меня известно практически всё — можно легко простым поиском узнать моё имя, возраст, квалификацию, место работы, список публикаций, информацию об участии в разных проектах и всё прочее (если вы этого ещё не сделали, то это исключительно ваши проблемы), но вот мне про вас неизвестно вообще ничего, кроме имени. При этом вы тут пальцы гнёте, что я якобы о том не слышал, того не видел, этого не читал, того не делал, сего не пробовал (хотя я и видел, слышал, и делал, и читал, и пробовал) — а вы сами-то чем можете похвастаться? Основания для пальцовки есть? Или кроме пальцев ни хрена за душой? Пока что от ваших постов впечатление именно такое.
Спасибо за
Ассемблер в Linux для программистов C
Содержание
Введение
Premature optimization is the root of all evil.
Donald Knuth
А стоит ли?
Архитектура
x86 или IA-32?
Вы, вероятно, уже слышали такое понятие, как «архитектура x86 «. Вообще оно довольно размыто, и вот почему. Само название x86 или 80×86 происходит от принципа, по которому Intel давала названия своим процессорам:
Регистры
![]()
В ОС Linux используется плоская модель памяти (flat memory model), в которой все сегменты описаны как использующие всё адресное пространство процессора и, как правило, явно не используются, а все адреса представлены в виде 32-битных смещений. В большинстве случаев программисту можно даже и не задумываться об их существовании, однако операционная система предоставляет специальные средства (системный вызов modify_ldt() ), позволяющие описывать нестандартные сегменты и работать с ними. Однако такая потребность возникает редко, поэтому тут подробно не рассматривается.
Есть команды, которые устанавливают флаги согласно результатам своей работы: в основном это команды, которые что-то вычисляют или сравнивают. Есть команды, которые читают флаги и на основании флагов принимают решения. Есть команды, логика выполнения которых зависит от состояния флагов. В общем, через флаги между командами неявно передаётся дополнительная информация, которая не записывается непосредственно в результат вычислений.
Стек растёт в сторону младших адресов. Это значит, что последний записанный в стек элемент будет расположен по адресу младше остальных элементов стека.
При помещении нового элемента в стек происходит следующее (принцип работы команды push ):
При выталкивании элемента из стека эти действия совершаются в обратном порядке(принцип работы команды pop ):
Память
Порядок байтов. Little-endian и big-endian
| начиная со старшего байта: | 0x01 0x02 0x03 0x04 | — big-endian |
| начиная с младшего байта: | 0x04 0x03 0x02 0x01 | — little-endian |
У порядка little-endian есть одно важное достоинство. Посмотрите на запись числа 0x00000033 :
См. также
Hello, world!
Вспомним, как вы писали Hello, world! на Си. Скорее всего, приблизительно так:
А вот и сама программа:
Если компиляция проходит успешно, GCC ничего не выводит на экран. Теперь запускаем нашу программу и убеждаемся, что она корректно завершилась с кодом возврата 0.
Теперь посоветуем прочитать главу про отладчик GDB. Он вам понадобится для исследования работы ваших программ. Возможно, сейчас вы не всё поймёте, но эта глава специально расположена в конце, так как задумана больше как справочная, нежели обучающая. Для того, чтобы научиться работать с отладчиком, с ним нужно просто работать.
Синтаксис ассемблера
Команды
Почти у каждой команды можно определить операнд-источник (из него команда читает данные) и операнд-назначение (в него команда записывает результат). Общий синтаксис команды ассемблера такой:
Для того, чтобы привести пример команды, я, немного забегая наперед, расскажу об одной операции. Команда mov источник, назначение производит копирование источника в назначение. Возьмем строку из hello.s :
Важной особенностью всех команд является то, что они не могут работать с двумя операндами, находящимися в памяти. Хотя бы один из них следует сначала загрузить в регистр, а затем выполнять необходимую операцию.
Как формируется указатель на ячейку памяти? Синтаксис:
Данные
Также существуют директивы для размещения в памяти строковых литералов:
Приведём небольшую таблицу, в которой сопоставляются типы данных в Си на IA-32 и в ассемблере. Нужно заметить, что размер этих типов в языке Си на других архитектурах (или даже компиляторах) может отличаться.
| Тип данных в Си | Размер (sizeof), байт | Выравнивание, байт | Название |
|---|---|---|---|
| char signed char | 1 | 1 | signed byte (байт со знаком) |
| unsigned char | 1 | 1 | unsigned byte (байт без знака) |
| short signed short | 2 | 2 | signed halfword (полуслово со знаком) |
| unsigned short | 2 | 2 | unsigned halfword (полуслово без знака) |
| int signed int long signed long enum | 4 | 4 | signed word (слово со знаком) |
| unsigned int unsigned long | 4 | 4 | unsigned word (слово без знака) |
Второй и третий аргумент являются необязательными.
Метки и прочие символы
Возьмём hello.s и скомпилируем его так:
Например, определим символ foo = 42:
Ещё пример из hello.s :
Неинициализированные данные
Хорошо, но известные нам директивы размещения данных требуют указания инициализирующего значения. Поэтому для неинициализированных данных используются специальные директивы:
Методы адресации
Пространство памяти предназначено для хранения кодов команд и данных, для доступа к которым имеется богатый выбор методов адресации (около 24). Операнды могут находиться во внутренних регистрах процессора (наиболее удобный и быстрый вариант). Они могут располагаться в системной памяти (самый распространенный вариант). Наконец, они могут находиться в устройствах ввода/вывода (наиболее редкий случай). Определение места положения операндов производится кодом команды. Причем существуют разные методы, с помощью которых код команды может определить, откуда брать входной операнд и куда помещать выходной операнд. Эти методы называются методами адресации. Эффективность выбранных методов адресации во многом определяет эффективность работы всего процессора в целом.
Прямая или абсолютная адресация
Физический адрес операнда содержится в адресной части команды. Формальное обозначение:
Непосредственная адресация
В команде содержится не адрес операнда, а непосредственно сам операнд.
Непосредственная адресация позволяет повысить скорость выполнения операции, так как в этом случае вся команда, включая операнд, считывается из памяти одновременно и на время выполнения команды хранится в процессоре в специальном регистре команд (РК). Однако при использовании непосредственной адресации появляется зависимость кодов команд от данных, что требует изменения программы при каждом изменении непосредственного операнда.
Косвенная (базовая) адресация
Адресная часть команды указывает адрес ячейки памяти или регистр, в котором содержится адрес операнда:
Предоставляемые косвенной адресацией возможности могут быть расширены, если в системе команд ЭВМ предусмотреть определенные арифметические и логические операции над ячейкой памяти или регистром, через которые выполняется адресация, например увеличение или уменьшение их значения.
Автоинкрементная и автодекрементная адресация
Иногда, адресация, при которой после каждого обращения по заданному адресу с использованием механизма косвенной адресация, значение адресной ячейки автоматически увеличивается на длину считываемого операнда, называется автоинкрементной. Адресация с автоматическим уменьшением значения адресной ячейки называется автодекрементной.
Регистровая адресация
Предполагается, что операнд находится во внутреннем регистре процессора.
Относительная адресация
Этот способ используется тогда, когда память логически разбивается на блоки, называемые сегментами. В этом случае адрес ячейки памяти содержит две составляющих: адрес начала сегмента (базовый адрес) и смещение адреса операнда в сегменте. Адрес операнда определяется как сумма базового адреса и смещения относительно этой базы:
Для задания базового адреса и смещения могут применяться ранее рассмотренные способы адресации. Как правило, базовый адрес находится в одном из регистров регистровой памяти, а смещение может быть задано в самой команде или регистре.
Рассмотрим два примера:
Команды ассемблера
Команда mov
Команда mov производит копирование источника в назначение. Рассмотрим примеры:
Команда lea
Команда lea помещает адрес источника в назначение. Например:
Команды для работы со стеком
Предусмотрено две специальные команды для работы со стеком: push (поместить в стек) и pop (извлечь из стека). Синтаксис:
GCC вернёт следующее:
Интересный вопрос: какое значение помещает в стек вот эта команда
Арифметика
Арифметических команд в нашем распоряжении довольно много. Синтаксис:
Давайте подумаем, каким будет результат выполнения следующего кода на Си:
Большинство сразу скажет, что результат (250 + 14 = 264) больше, чем может поместиться в одном байте. И что же напечатает программа? 8. Давайте рассмотрим, что происходит при сложении в двоичной системе.
Этот код выдаёт правильную сумму в регистре %ax с учётом переполнения, если оно произошло. Попробуйте поменять числа в строках 2 и 3.
Команда lea для арифметики
Вспомним, как формируется адрес операнда:
Чем это нам удобно? Так мы можем получить команду с двумя операндами-источниками и одним результатом:
Вспомните, что при сложении командой add результат записывается на место одного из слагаемых. Теперь, наверно, стало ясно главное преимущество lea в тех случаях, где её можно применить: она не перезаписывает операнды-источники. Как вы это сможете использовать, зависит только от вашей фантазии: прибавить константу к регистру и записать в другой регистр, сложить два регистра и записать в третий: Также lea можно применять для умножения регистра на 3, 5 и 9, как показано выше.
Команда loop
На Си это выглядело бы так:
Команды сравнения и условные переходы. Безусловный переход
Команды jcc не существует, вместо cc нужно подставить мнемоническое обозначение условия.
| Мнемоника | Английское слово | Смысл | Тип операндов |
|---|---|---|---|
| e | equal | равенство | любые |
| n | not | инверсия условия | любые |
| g | greater | больше | со знаком |
| l | less | меньше | со знаком |
| a | above | больше | без знака |
| b | below | меньше | без знака |
Таким образом, je проверяет равенство операндов команды сравнения, jl проверяет условие операнд_1 и так далее. У каждой команды есть противоположная: просто добавляем букву n :
Теперь пример использования этих команд:
Сравните с кодом на Си:
Кроме команд условного перехода, область применения которых ясна сразу, также существует команда безусловного перехода. Эта команда чем-то похожа на оператор goto языка Си. Синтаксис:
Эта команда передаёт управление на адрес, не проверяя никаких условий. Заметьте, что адрес может быть задан в виде непосредственного значения (метки), регистра или обращения к памяти.
Произвольные циклы
Программа: поиск наибольшего элемента в массиве
Этот код соответствует приблизительно следующему на Си:
Возможно, такой способ обхода массива не очень привычен для вас. В Си принято использовать переменную с номером текущего элемента, а не указатель на него. Никто не запрещает пойти этим же путём и на ассемблере:
Рассматривая код этой программы, вы, наверно, уже поняли, как создавать произвольные циклы с постусловием на ассемблере, наподобие do<> while(); в Си. Ещё раз повторю эту конструкцию, выкинув весь код, не относящийся к циклу:
эквивалентен такой конструкции:
Таким образом, нам достаточно и уже рассмотренных двух видов циклов.
Логическая арифметика
Кроме выполнения обычных арифметических вычислений, можно проводить и логические, то есть битовые.
Команда not инвертирует каждый бит операнда на противоположный, так же как и оператор языка Си
Команду test можно применять для сравнения значения регистра с нулём:
К логическим командам также можно отнести команды сдвигов:
Принцип работы команды shl :
Принцип работы команды shr :
Многие программисты Си знают об умножении и делении на степени двойки (2, 4, 8:) при помощи сдвигов. Этот трюк отлично работает и в ассемблере, используйте его для оптимизации.
Кроме сдвигов обычных, существуют циклические сдвиги:
Объясню на примере циклического сдвига влево на три бита: три старших ( ) бита из регистра влево и в него справа. При этом в флаг cf записывается самый последний бит.
Принцип работы команды rol :
Принцип работы команды ror :
Принцип работы команды rcl :
Принцип работы команды rcr :
Эти сложные циклические сдвиги вам редко понадобятся в реальной работе, но уже сейчас нужно знать, что такие инструкции существуют, чтобы не изобретать велосипед потом. Ведь в языке Си циклический сдвиг производится приблизительно так:
Подпрограммы
Используется для вызова подпрограммы, код которой находится по адресу метка. Принцип работы:
Существует несколько способов передачи аргументов в подпрограмму.
Рассмотрим передачу аргументов через стек подробнее. Предположим, нам нужно написать подпрограмму, принимающую три аргумента типа long (4 байта). Код:
Как видите, если идти от вершины стека в сторону аргументов, то мы будем встречать аргументы в обратном порядке по отношению к тому, как их туда поместили. Нужно сделать одно из двух: или помещать аргументы в обратном порядке (чтобы доставать их в прямом порядке), или учитывать обратный порядок аргументов в подпрограмме. В Си принято при вызове помещать аргументы в обратном порядке. Так как операционная система Linux и большинство библиотек для неё написаны именно на Си, я советую использовать способ передачи аргументов и в ваших ассемблерных программах.
Вы не можете делать никаких предположений о содержимом локальных переменных. Никто их для вас не инициализировал нулем. Можете для себя считать, что там находятся случайные значения.
Остаётся одна маленькая проблема: в стеке всё ещё находятся аргументы для подпрограммы. Это можно решить одним из следующих способов:
Обратите внимание на обратный порядок аргументов и очистку стека от аргументов.
Программа: печать таблицы умножения
Рассмотрим программу посложнее. Итак, программа для печати таблицы умножения. Размер таблицы умножения вводит пользователь. Нам понадобится вызвать функцию scanf(3) для ввода, printf(3) для вывода и организовать два вложенных цикла для вычислений.
Программа: вычисление факториала
Теперь напишем рекурсивную функцию для вычисления факториала. Она основана на следующей формуле: 0! = 1 
Любой программист знает, что если существует очевидное итеративное (реализуемое при помощи циклов) решение задачи, то именно ему следует отдавать предпочтение перед рекурсивным. Итеративный алгоритм нахождения факториала даже проще, чем рекурсивный; он следует из определения факториала: 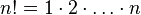
Что я сделал? Сначала я переписал рекурсию в виде цикла. Потом я увидел, что мне больше не нужен кадр стека, так как я не вызываю других функций и ничего не помещаю в стек. Поэтому я убрал пролог и эпилог, при этом регистр %ebp я не использую вообще. Если бы я его использовал, сначала я должен был бы сохранить его значение, а перед возвратом восстановить.
Нам нужно умножить 64-битное число на 32-битное. Мы будем это делать как при умножении :
Системные вызовы
В качестве примера можете посмотреть код программы Hello world.
Структуры
| 0x23 | 0x72 | 0x45 | 0x17 |
Приблизительно так в ассемблере организована работа со структурами: к базовому адресу структуры прибавляется смещение, по которому находится нужный элемент. Теперь вопрос: как определить смещение? В Си компилятор руководствуется следующими правилами:
Примеры (внизу указано смещение элементов в байтах; заполнители обозначены XX ):
Обратите внимание на два последних примера: элементы структур одни и те же, только расположены в разном порядке. Но размер структур получился разный!
Программа: вывод размера файла
Напишем программу, которая выводит размер файла. Для этого потребуется вызвать функцию stat(2) и прочитать данные из структуры, которую она заполнит. man 2 stat :
Значит, sizeof(dev_t) = 8.
Наверное, могут возникнуть некоторые сложности с пониманием, как расположены argc и argv в стеке. Допустим, вы запустили программу как
Тогда стек будет выглядеть приблизительно так:
Программа: печать файла наоборот
Напишем программу, которая читает со стандартного ввода всё до конца файла, а потом выводит введённые строки в обратном порядке. Для этого мы во время чтения будем помещать строки в связный список, а потом пройдем этот список в обратном порядке и напечатаем строки.