
CGI: пишем простой сайт на Python. Часть 2: Обработка форм, cookies
В первой части мы написали Hello world. Сегодня мы рассмотрим несколько более сложные вещи: обработку данных форм и cookies.
Получение данных из форм
Итак, во-первых разберёмся с формами. В модуле CGI есть полезный класс: FieldStorage, который содержит в себе переданную в форме информацию. По сути дела этот класс представляет из себя словарь, обладающий теми же свойствами, что и обычный словарь в python.
У класса FieldStorage есть 2 метода получения значений данных формы:
Разберём на примере: создадим в нашей папке файл index.html со следующим содержимым (это будет наша форма, данные из которой мы будем обрабатывать):
Попробуем это в действии (кто сидит на linux, не забудьте поставить права на выполнение).
Но есть нюанс.
А если попробовать так?
Это серьёзная уязвимость, поэтому от неё нужно избавляться. Для этого нужно (в самом простом случае) экранировать все опасные символы. Это можно сделать с помощью функции escape из модуля html.
Результат можете проверить сами.
Cookies
Cookies (печеньки) — небольшой фрагмент данных, отправленный веб-сервером и сохраняемый на компьютере пользователя. Браузер всякий раз при попытке открыть страницу соответствующего сайта пересылает этот фрагмент данных веб-серверу в составе HTTP-запроса.
Отправка печенек осуществляется заголовком Set-cookie:
Например, если сохранить этот скрипт в /cgi-bin/cookie.py и зайти на localhost:8000/cgi-bin/cookie.py, то вам поставится печенька с именем name и значением value. Срок её хранения до мая 2033 года, отправляется повторно на сервер только к скриптам, которые расположены в /cgi-bin/, и передается только http-запросами (её нельзя получить из браузера пользователя с помощью javascript).
Все эти параметры не являются обязательными. Можно написать так:
Тогда храниться она будет до того момента, когда закроется браузер, будет отправляться на сервер для любых документов (и для /index.html тоже, в отличие от предыдущего случая). Также её можно будет получить средствами javascript (поскольку не был установлен флаг httponly).
Обработка Cookies
Теперь научимся получать cookies. Они передаются на сервер и доступны в переменной os.environ (словарь, cookies хранятся по ключу HTTP_COOKIE). Они передаются в виде пар ключ=значение, что не очень удобно при обработке. Для упрощения работы можно использовать модуль http.cookies.
Напишем простой скрипт (/cgi-bin/cookie.py), проверяющий, установлена ли кука, и если нет, устанавливает:
Так страница выглядит после первого запроса:
И после обновления страницы:
Не следует хранить в cookies важные данные, и не полагайтесь на выставленный вами срок хранения. Cookies можно удалить или изменить вручную в браузере.
WebCode — библиотека для Python, для написания Фронтэнда
Недавно я наткнулся на интересную библиотеку на GitHub — WebCode. Библиотека позволяет писать на Python CSS и HTML код. Ранее я не встречал аналогов, поэтому решил изучить WebCode поподробнее.
Чтобы скачать WebCode нужно перейти по ссылке, а далее нажать на ‘Clone or download’ => ‘Download ZIP’. (После извлечения файла, перенесите его в папку, где будете писать код)
Итак, перейдём к делу.
Первые строки, которые надо написать это:
В начале импортируем библиотеку, как wb. А дальше пишем базовую функцию startuse().
Первый аргумент в этой функции — название HTML файла, который библиотека будет генерировать, второй — имя вашего сайта во вкладке, третий — название CSS файла(если не собираетесь его создавать, напишите css=0) и наконец четвёртый аргумент отвечает за язык, на котором Вы будете писать текст. finuse() завершает работу и принимает 1 аргумент, который может быть либо True, либо False. Если Вы укажите True, то когда вы запустите файл, он автоматически откроется в браузере. Если же False, то он этого делать не будет.
Как можно было догадаться, между startuse() и finuse(), будет наш дальнейший код.
Давайте его напишем:
Функция writep() добавляет HTML p тег на наш сайт, иными словами — пишет текст на нашу страницу. С первым аргументом text в этой функции — всё понятно, второй аргумент — это класс(в дальнейшем с помощью этого свойства, мы сможем изменить цвет или размер нашего текста), третий аргумент отвечает за то, будет ли наш текст принадлежать другому элементу. True — не будет, False — будет. Пример:
Как видите, чтобы «положить» один элемент в другой, нам нужно создать переменную, которая будет содержать в нашем случае p тег, указать change=False, а далее указать переменную в text.
Примечание: функция writediv() аналогична writep(), только вместо p создаётся div элемент.
Можете запустить и посмотреть, что у нас получилось:
Украшаем нашу страницу
Давайте сделаем наш сайт, более ярким. Для этого нам нужно написать несколько функций:
Функции stylestart() и stylefin() — это по сути тоже самое, что и startuse() finuse(), только теперь мы запускаем CSS, а не HTML код.
Помните, мы назначали writep() класс «simple-text»? Так вот, теперь мы его объявляем с помощью функции startclass(), задавая псевдо-классу(:hover, :active, :focus и т.д) значение 0, то есть его не объявляем. usestyle() принимает стандартные CSS свойства. К последнему usestyle() нужно приписать True. Так мы показываем, что после этой функции в нашем классе ничего не будет.
Теперь поменяем фон на нашей странице:
Прошу заметить, что для тегов используется startobject(), а не startclass().
Используем преимущества Python для создания сайта
В написании кода на HTML и CSS зачастую возникает проблема: несколько раз писать одно и тоже. Но WebCode её решает:
Как видите, использование данной библиотеки сильно облегчает жизнь программистам.
Вот весь код, который мы сегодня написали:
CGI: пишем простой сайт на Python. Часть 1: Hello world
Сегодня я расскажу про то, как написать Hello world, как CGI-скрипт.
Настройка локального сервера
В Python уже есть встроенный CGI сервер, поэтому его настройка элементарна.
Для запуска из консоли (для любителей linux-систем). Запускать нужно из той папки, где мы хотим работать:
Для сидящих на Windows чуть проще будет запуск Python файла (заметьте, что он должен находиться в той же папке, в которой мы планируем работать!):
Теперь откройте браузер и в адресной строке наберите localhost:8000
Если у вас примерно такая же картина, значит, у вас все заработало!
Hello world
Теперь в той папке, где мы запустили сервер, создаём папку cgi-bin (у меня она уже создана).
В этой папке создаём скрипт hello.py со следующим содержимым:
Первая строка говорит о том, что это Python скрипт (CGI-скрипты можно не только на Python писать).
Вторая строка печатает заголовок. Он обозначает, что это будет html файл (бывает ещё css, javascript, pdf и куча других, и браузер различает их по заголовкам).
Третья строка (просто символ новой строки) отделяет заголовки от тела ответа.
Четвёртая печатает Hello world.
Теперь переходим на localhost:8000/cgi-bin/hello.py
Если у вас не работает, проверьте, установлены ли права на выполнение.
Также в консоли запущенного сервера появляются сообщения об ошибках. Например, убрал скобочку и обновил страницу:
В следующей части мы рассмотрим обработку данных форм и cookies.
Скрапинг сайта с помощью Python: гайд для новичков
Авторизуйтесь
Скрапинг сайта с помощью Python: гайд для новичков
В этой статье мы разберемся, как создать HTML скрапер на Python, который получает неофициальный доступ к коду сайта и позволяет извлечь необходимые данные.
Отличие от вызовов API
Альтернативный метод получения данных сайта — вызовы API. Взаимодействие с API — это официально предоставляемый владельцем сайта способ получения данных прямо из БД или обычных файлов. Обычно для этого требуется разрешение владельца сайта и специальный токен. Однако апи доступен не всегда, поэтому скрапинг так привлекателен, однако его законность вызывает вопросы.
Юридические соображения
Скрапинг может нарушать копирайт или правила использования сайта, особенно когда он используется для получения прибыли, конкурентного преимущества или причинения ущерба (например из-за слишком частых запросов). Однако скрапинг публично доступен и используется для личного использования, академических целей или безвредного некоммерческого использования.
Если данные являются платными, требуют регистрации, имеют явную защиту от скрапинга, содержат конфиденциальные данные или личные данные пользователей, то нужно избегать любого из видов скрапинга.
Установка Beautiful Soup в Python
Beautiful Soup — это Python библиотека для скрапинга данных сайтов через HTML код.
Установите последнюю версию библиотеки.
Чтобы делать запросы, установите requests (библиотеку для отправки HTTP запросов):
Импортируйте библиотеки в файле Python или Jupiter notebook:
И несколько стандартных библиотек, которые потребуются для скрапинга на Python:
Введение
Представьте, что мы хотим произвести скрапинг платформы, содержащей общедоступные объявления о недвижимости. Мы хотим получить цену недвижимости, ее адрес, расстояние, название станции и ближайший до нее тип транспорта для того, чтобы узнать, как цены на недвижимость распределяются в зависимости от доступности общественного транспорта в конкретном городе.
Предположим, что запрос приведет к странице результатов, которая выглядит следующим образом: 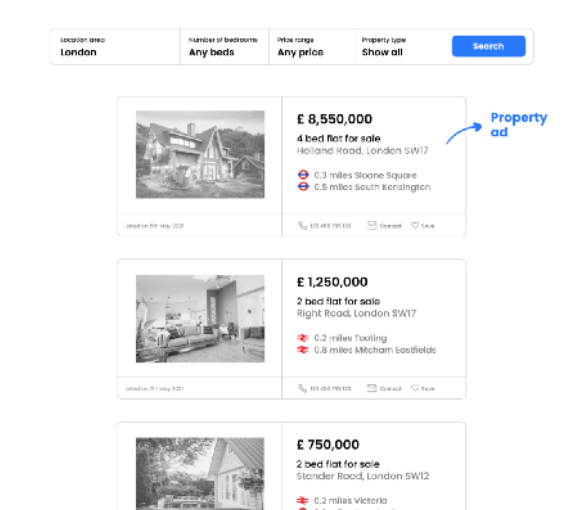
Как только мы узнаем, в каких элементах сайта хранятся необходимые данные, нам нужно придумать логику скрапинга, которая позволит нам получить всю нужную информацию из каждого объявления.
Нам предстоит ответить на следующие вопросы:
Логика получения одной точки данных
Все примеры кода для скрапинга на Python можно найти в Jupiter Notebook файле на GitHub автора.
Запрос кода сайта
Во-первых, мы используем поисковый запрос, который мы сделали в браузере в скрипте Python:
Переменная soup содержит полный HTML-код страницы с результатами поиска.
Поиск тегов-свойств
HTML классы и атрибут id
HTML-классы и id в основном используются для ссылки на класс в таблице стилей CSS, чтобы данные могли отображаться согласованным образом.
В приведенном выше примере, класс, используемый для получения информации о ценах из одного объявления, также применяется для получения цен из других объявлений (что соответствует основной цели класса).
Обратите внимание, что HTML-класс также может ссылаться на ценники за пределами раздела объявлений (например, специальные предложения, которые не связаны с поисковым запросом, но все равно отображаются на странице результатов). Однако для целей этой статьи мы фокусируемся только на ценах в объявлениях о недвижимости.
Вот почему мы сначала ориентируемся на объявление и ищем HTML-класс только в исходном коде для конкретного объявления:
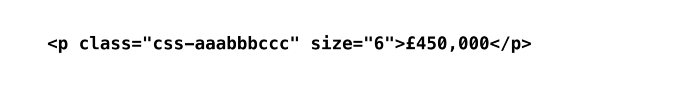
Важное примечание: нам всегда нужно указывать элемент, в данном случае это p.
Логика получения всех точек данных с одной страницы
Чтобы получить ценники для всех объявлений, мы применяем метод find.all() вместо find():
Переменная ads теперь содержит HTML-код для каждого объявления на первой странице результатов в виде списка списков. Этот формат хранения очень полезен, так как он позволяет получить доступ к исходному коду для конкретных объявлений по индексу.
Python и разработка простого веб-приложения, использующего технологии машинного обучения
Тот, кто занимается машинным обучением (Machine Learning, ML), обычно, реализуя различные проекты, выполняет следующие действия: сбор данных, их очистка, разведочный анализ данных, разработка модели, публикация модели в локальной сети или в интернете. Вот хорошее видео, в котором можно узнать подробности об этом.

Жизненный цикл проекта в сфере машинного обучения
Этап публикации модели завершает жизненный цикл ML-проектов. Он так же важен для дата-сайентистов и специалистов по машинному обучению, как и другие этапы. Обычные подходы к публикации моделей предусматривают использование универсальных фреймворков, таких, как Django или Flask. Главные проблемы тут заключаются в том, что для применения подобных инструментов требуются особые знания и навыки, и в том, что работа с ними может потребовать немалых затрат времени.
Автор статьи, перевод которой мы сегодня публикуем, хочет рассказать о том, как, используя Python-библиотеки streamlit, pandas и scikit-learn, создать простое веб-приложение, в котором применяются технологии машинного обучения. Он говорит, что размер этого приложения не превышает 50 строк. Статья основана на этом видео, которое можно смотреть параллельно с чтением. Инструменты, которые будут здесь рассмотрены, кроме прочего, позволяют ускорить и упростить развёртывание ML-проектов.
Обзор модели, определяющей вид цветка ириса
Сегодня мы создадим простое веб-приложение, использующее технологии машинного обучения. Оно будет классифицировать цветки ириса из выборки Фишера, относя их к одному из четырёх видов: ирис щетинистый (iris setosa), ирис версиколор (iris versicolor), ирис виргинский (iris virginica). Возможно, вы уже видели множество ML-примеров, построенных на основе этого знаменитого набора данных. Но, надеюсь, то, что я тут буду рассматривать ещё один такой пример, вам не помешает. Ведь этот набор — он как «lorem ipsum» — классический бессмысленный текст-заполнитель, который вставляют в макеты страниц.
Нам, чтобы построить модель и опубликовать её где-нибудь, понадобятся библиотеки streamlit, pandas и scikit-learn. Взглянем на общую схему проекта. Он будет состоять из двух больших частей: фронтенд и бэкенд.
Во фронтенд-части приложения, а именно, на веб-странице, будет боковая панель, находящаяся слева, в которой можно будет вводить входные параметры модели, которые связаны с характеристиками цветков ириса: длина лепестка (petal length), ширина лепестка (petal width), длина чашелистика (sepal length), ширина чашелистика (sepal width). Эти данные будут передаваться бэкенду, где предварительно обученная модель будет классифицировать цветки, используя заданные характеристики. Фактически, речь идёт о функции, которая, получая характеристики цветка, возвращает его вид. Результаты классификации отправляются фронтенду.
В бэкенд-части приложения то, что ввёл пользователей, сохраняется в датафрейме, который будет использоваться в виде тестовых данных для модели. Потом будет построена модель для обработки данных. В ней будет применяться алгоритм «случайный лес» из библиотеки scikit-learn. И наконец, модель будет применена для классификации данных, введённых пользователем, то есть — для определения вида цветка. Кроме того, вместе со сведениями о виде цветка, будут возвращаться и данные о прогностической вероятности. Это позволит нам определить степень достоверности результатов классификации.
Установка библиотек
Разработка веб-приложения
Теперь напишем код приложения. Проект у нас довольно скромный. Он состоит из менее чем 50 строк кода. А если точнее — то их тут всего 48. Если же этот код «уплотнить», избавившись от комментариев и пустых строк, то размер текста программы сократится до 36 строк.
Разбор кода
Теперь разберём этот код.
▍Импорт библиотек
▍Формирование боковой панели
▍Создание модели
Получение сведений о виде цветка с помощью обученной модели.
Получение сведений о прогностической вероятности.
▍Формирование основной панели
Данный код описывает второй подзаголовок основной панели. В этом разделе будут выведены данные о видах цветков.
Вывод третьего подзаголовка для раздела, в котором будет находиться результат классификации.
Выводим заголовок четвёртого (и последнего) раздела основной панели. Здесь будут представлены данные о прогностической вероятности.
Вывод данных о прогностической вероятности.
Запуск веб-приложения
Если всё идёт как надо, через некоторое время вы должны увидеть следующее:
То, что вы увидите, будет похоже на следующий рисунок.

Скриншот веб-приложения для классификации цветков ириса. Если щёлкнуть по стрелке, находящейся в левом верхнем углу окна, расположенного в верхней части рисунка, будет открыта боковая панель
Итоги
Можете себя поздравить: только что вы создали веб-приложение, в котором используются технологии машинного обучения. Вы вполне можете упомянуть подобное приложение в своём портфолио ML-проектов, а если хотите, можете опубликовать его на своём веб-сайте (правда, вы, вполне возможно, решите построить собственную модель, используя другие данные).
Пользуетесь ли вы библиотекой streamlit?