
Lifo что это такое в программировании


LIFO (акроним Last In, First Out, «последним пришёл — первым ушёл») — способ организации и манипулирования данными относительно времени и приоритетов. В структурированном линейном списке, организованном по принципу LIFO, элементы могут добавляться и выбираться только с одного конца, называемого «вершиной списка». [1] Структура LIFO может быть проиллюстрирована на примере стопки тарелок: чтобы взять вторую сверху, нужно снять верхнюю, а чтобы снять последнюю, нужно снять все, лежащие выше.
Содержание
Определение
Термин относится к абстрактным принципам обработки списков и временного хранения данных, в частности, когда нужно иметь доступ к ограниченному набору данных в определённом порядке. Принцип LIFO применяется в тех случаях, когда последние данные, добавленные в структуру, должны быть первыми удалены или обработаны. Полезная аналогия с офисным работником: человек может работать только с одной страницей в каждый момент времени, поэтому очередной документ добавляется в папку сверху к стопке предыдущих. По аналогии с этим в компьютере тоже есть ограничения, такие как ширина шины данных и тот факт, что в каждый момент времени система может манипулировать только с одной ячейкой памяти. [2] Абстрактный механизм LIFO, применяемый в вычислениях, реализуется в реальных структурах данных в виде стека, название которого совершенно очевидно имеет отношение к «пачке бумаги», «стопке тарелок» и т. п. (англ. stack переводится как «штабель, кипа, стопка»). В качестве синонима иногда используется термин FILO (first in, last out — «первым пришёл, последним ушёл»), в котором акцентируется, что более ранние дополнения к списку должны ожидать, пока они не поднимутся в структуре на самый верх, после чего к ним будет получен доступ. В теории массового обслуживания иногда используется термин LCFS (last come, first served — «последним пришёл, первым обслужен»). Различие между обобщённым списком, массивом, очередью и стеком определяется правилами, используемыми в механизме доступа к данным. [2] В любом случае в структуре LIFO организован доступ в обратном порядке по сравнению с очередью. «Имеются определённые, часто встречающиеся ситуации в области компьютерных наук, когда нужно ограничить вставки и удаления в списки так, чтобы эти изменения могли происходить только в начале или в конце списка, но не в его середине. В таких случаях полезны две структуры данных: стеки и очереди». [3]
Применение
Стековые структуры в вычислительных системах относятся к числу фундаментальных и потому чрезвычайно важных. Выражаясь высоким слогом, можно сказать, что без способности к перестраиваемой организации данных, в том числе со ссылкой на исполняемый код, компьютеры не были бы таким гибким инструментом, каким они являются сегодня, а были бы просто дорогим калькулятором для специальных целей, подобно ЭНИАКу времён Второй мировой войны, имеющим ограниченные возможности и неширокую сферу применения. [4]
В упорядоченных структурах данных стек используется в качестве динамического элемента памяти, в котором абстрактное понятие — аппаратно зависимый стек вызовов — используется для хранения копии данных или их части, будь то адреса памяти элементов данных (см.: Параметр (программирование)#Передача параметра по ссылке) или копии данных (передача параметра по значению). Самой распространенной задачей обработки списков является сортировка (в лексикографическом порядке, по возрастанию значения, и т. д.), в которой действия машины ограничиваются сравнением всего двух элементов, тогда как список чаще всего содержит миллионы членов. Существуют различные стратегии (компьютерные алгоритмы), оптимальные для разных типов сортируемых данных, но при реализации все они прибегают к применению программ или подпрограмм, которые обычно вызывают сами себя или часть своего кода рекурсивно, и при каждом вызове добавляют в стек вызовов частично упорядоченный список элементов. Именно по этой причине в курсах структур данных стеки и рекурсии обычно вводятся параллельно, потому что они тесно взаимосвязаны. [5]
Именно благодаря гибкости доступа к стеку вызовов с возможностью перегруппировки данных (организованный по абстрактному методу LIFO блок данных как будто специально придуман только для того, чтобы данные можно было легко переупорядочить) подпрограммы и стандартные функции получают требуемые данные, выполняют те свои задачи, для решения которых они оптимизированы, и передают информацию обратно в вызывающий сегмент программы. [6] Стек вызовов в конкретных случаях включает в себя адрес следующей инструкции вызывающей программы, которая обычно выполняет какие-то действия с «откликами», полученными от подпрограмм и стандартных функций. В рекурсивных вызовах эти действия обычно включают сравнение следующего элемента списка с возвратившимся «откликом» (например, выбор из двух значений наибольшей величины), пока список не будет исчерпан.
Следовательно, в реальном мире реализаций абстрактного принципа LIFO количество стеков вызовов меняется чрезвычайно часто, размер каждого зависит от числа требуемых элементов данных, которыми необходимо манипулировать. Поэтому уместно сравнить LIFO с кипой буклетов и брошюр, а не со стопкой тонких листов бумаги.
LIFO (информатика)
LIFO — акроним Last In, First Out («последним пришёл — первым ушёл», англ. ), абстрактное понятие в способах организации и манипулирования данными относительно времени и приоритетов. В структурированном линейном списке, организованном по принципу LIFO, элементы могут добавляться и выбираться только с одного конца, называемого «вершиной списка». [1] Структура LIFO может быть проиллюстрирована на примере стопки тарелок: чтобы взять вторую сверху, нужно снять верхнюю, а чтобы снять последнюю, нужно снять все лежащие выше.
Содержание
Определение
Термин относится к абстрактным принципам обработки списков и временного хранения данных, в частности, когда нужно иметь доступ к ограниченному набору данных в определённом порядке. Принцип LIFO применяется в тех случаях, когда последние данные, добавленные в структуру, должны быть первыми удалены или обработаны. Полезная аналогия с офисным работником: человек может работать только с одной страницей в каждый момент времени, поэтому очередной документ добавляется в папку сверху к стопке предыдущих. По аналогии с этим в компьютере тоже есть ограничения, такие как ширина шины данных и тот факт, что в каждый момент времени система может манипулировать только с одной ячейкой памяти. [2] Абстрактный механизм LIFO, применяемый в вычислениях, реализуется в реальных структурах данных в виде стека, название кототого совершенно очевидно имеет отношение к «пачке бумаги», «стопке тарелок» и т. п. (англ. stack переводится как «штабель, кипа, стопка»). В качестве синонима иногда используется термин FILO («first in, last out», «первым пришёл, последним ушёл»), в котором акцентируется, что более ранние дополнения к списку должны ожидать, пока они не поднимутся в структуре на самый верх, после чего к ним будет получен доступ. В теории массового обслуживания иногда используется термин LCFS («last come, first served», «последним пришёл, первым обслужен»). Различие между обобщённым списком, массивом, очередью и стеком определяется правилами, используемыми в механизме доступа к данным. [2] В любом случае в структуре LIFO организован доступ в обратном порядке по сравнению с очередью. «Имеются определённые, часто встречающиеся ситуации в области компьютерных наук, когда нужно ограничить вставки и удаления в списки так, чтобы эти изменения могли происходить только в начале или в конце списка, но не в его середине. В таких случаях полезны две структуры данных: стеки и очереди». [3]
Применение
Стековые структуры в вычислительных системах относятся к числу фундаментальных и потому чрезвычайно важных. Выражаясь высоким слогом, можно сказать, что без способности к перестриваемой организации данных, в том числе со ссылкой на исполняемый код, компьютеры не были бы таким гибким инструментом, каким они являются сегодня, а были бы просто дорогим калькулятором для специальных целей, подобно ЭНИАКу времён Второй мировой войны, имеющим ограниченные возможности и неширокую сферу применения. [4]
В упорядоченных структурах данных стек используется в качестве динамического элемента памяти, в котором абстрактное понятие — аппаратно зависимый стек вызовов — используется для хранения копии данных или их части, будь то адреса памяти элементов данных (см. передача параметра по ссылке) или копии данных (передача параметра по значению). Самой распространенной задачей обработки списков является сортировка (в лексикографическом порядке, по возрастанию значения, и т. д.), в которой действия машина ограничиваются сравнением всего двух элементов, тогда как список чаще всего содержит миллионы членов. Существуют различные стратегии (компьютерные алгоритмы), оптимальные для разных типов сортируемых данных, но при реализации все они прибегают к применению программ или подпрограмм, которые обычно вызывают сами себя или часть своего кода рекурсивно, и при каждом вызове добавляют в стек вызовов частично упорядоченный список эементов. Именно по этой причине в курсах структур данных стеки и рекурсии обычно вводятся параллельно, потому что они тесно взаимосвязаны. [5]
Именно благодаря гибкости доступа к стеку вызовов с возможностью перегруппировки данных (организованный по абстрактному методу LIFO блок данных как будто специально придуман только для того, чтобы данные можно было легко переупорядочить) подпрограммы и стандартные функции получают требуемые данные, выполняют те свои задачи, для решения которых они оптимизированы, и передают информацию обратно в вызывающий сегмент программы. [4] Стек вызовов в конкретных случаях включает в себя адрес следующей инструкции вызывающей программы, которая обычно выполняет какие-то действия с «откликами», полученными от подпрограмм и стандартных функций. В рекурсивных вызовах эти действия обычно включают сравнение следующего элемента списка с возвратившимся «откликом» (например, выбор из двух значений наибольшей величины), пока список не будет исчерпан.
Следовательно, в реальном мире реализаций абстрактного принципа LIFO количество стеков вызовов меняется чрезвычайно часто, размер каждого зависит от числа требуемых элементов данных, которыми необходимо манипулировать. Поэтому уместно сравнить LIFO с кипой буклетов и брошюр, а не со стопкой тонких листов бумаги.
Очереди сообщений в бэкенд-архитектуре: как построить надежную систему
Очереди сообщений — устоявшаяся технология, которую разработчики применяют уже много лет. Разберемся, как она работает.
Почему понадобились очереди сообщений
Серверные сообщения обычно устроены просто и однотипно: сервер получает запрос, обрабатывает его и сразу же возвращает клиенту. Схема хорошо работает до тех пор, пока обработка запроса занимает немного времени, например доли секунды.
Но бывает, что вернуть ответ клиентскому приложению сразу невозможно. Например, когда сервер обрабатывает видео — это может занять минуты и даже часы. На время обработки большого объема данных вычислительные ресурсы сервера загружены и его способность обрабатывать входящие запросы падает.
Что такое обмен серверными сообщениями и как он устроен
Допустим, серверное приложение получило тяжелый запрос. Оно передает его другим приложениям дальше по цепочке, а само продолжает общение с клиентом.
Для передачи сообщения другим приложениям используют специальный инструмент — очереди сообщений. Эта технология решает любые инфраструктурные вопросы:
Когда в вашем бэкенд-приложении задействованы очереди, обработка видео выглядит так:
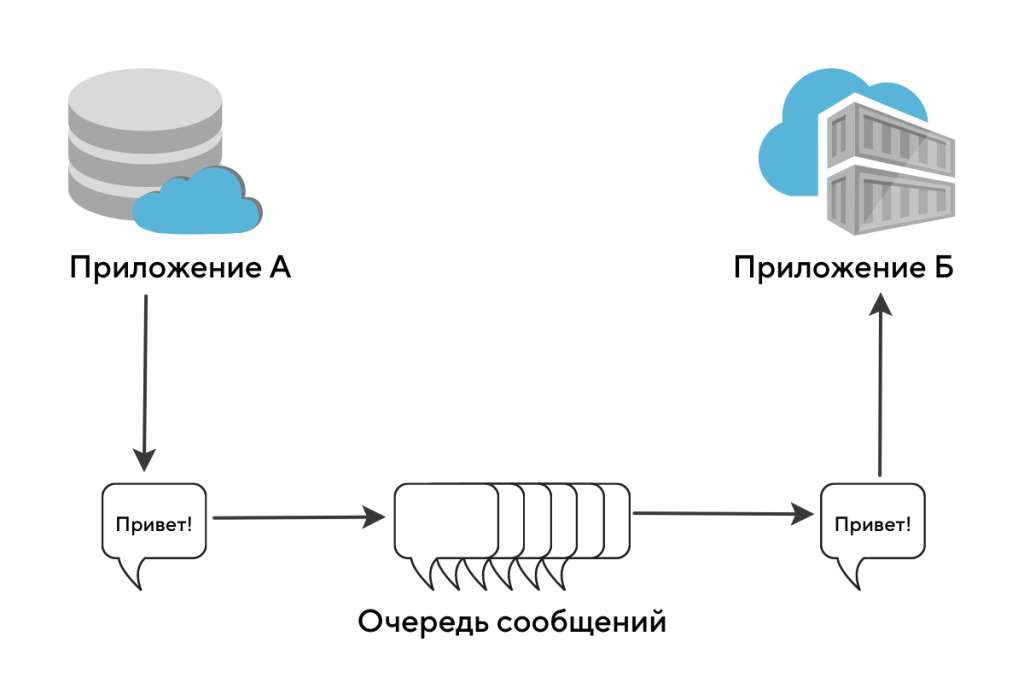
Схема асинхронного обмена сообщениями между приложениями. Источник
FIFO и LIFO (ФИФО и ЛИФО) — что это такое
Сервисы обмена сообщениями между серверами делятся на два типа:
Сервисы для организации очередей сообщений
Популярные сервисы для организации очередей сообщений — RabbitMQ, Apache Kafka и Redis. Давайте посмотрим, чем они различаются.
RabbitMQ
Сервер организации очередей сообщений, написанный на языке программирования Erlang. Это распределенный и горизонтально масштабируемый брокер сообщений. Он позволяет разным программам взаимодействовать с помощью протокола AMQP, а через дополнительные модули — и с помощью некоторых других протоколов: MQTT, HTTP и так далее.
RabbitMQ — это инструмент, который силен в маршрутизации сообщений. Система поддерживает несколько видов распределения сообщений в сети, их комбинация позволяет создавать очень хитрые правила доставки сообщений.
Apache Kafka
Apache Kafka — продукт, который реализует систему распределенного журнала событий. Kafka славится своей скоростью работы и масштабируемостью. Из-за способности передавать терабайты данных эту систему очередей сообщений любят разработчики, работающие с Big Data. Например, ее используют в Airbnb, Adidas, Cisco и PayPal.
Redis
Redis создавалась как система хранения данных в оперативной памяти. Изначальное предназначение — ускорение доступа к востребованной информации и построение систем кеширования.
Но разработчики добавили в код возможность построения простых очередей и стеков. В итоге Redis применяют в качестве сервера очередей сообщений в проектах, где нужно быстро и дешево проверить инженерные гипотезы по работе с очередями.
Структура данных — Стек (LIFO, Stack)
После описания базовой структуры данных очередь, как правило, необходимо сразу рассказывать про стек. Эти две базовые конструкции, наиболее массово распространены в информатике, логистике и просто в быту. Они всегда идут рядом и достаточно похожи друг на друга. Единственная разница только в методе доступа к элементам данных и способу добавления новых значений в «пачку».
Стек (Stack) — это абстрактная структура данных для организации хранения списка элементов. Сам термин впервые был введён Аланом Тьюрингом ещё в далеком 1946 году. В основе стека стоит аббревиатура LIFO (Last In – First Out; первым попал — первым и вылетел), что означает, что каждый новый поступающий элемент попадает не в хвост списка (как это было с очередью), а в голову — в начало.
Каноническим и самым распространённым примером стека — является пример с тарелками. Допустим, вы холостяк 🙂 и у вас полная раковина грязных тарелок. Пришло время наконец-то помыть посуду. Скорее всего, ваш алгоритм будет таким: взять первую грязную тарелку, помыть и отложить в сторону. Следующие вымытые тарелки ставим поверх помытых, таким образом у нас появляется массив посуды, в котором снизу будет самая первая тарелка, а сверху — самая последняя. Это способ внесения новых элементов — добавляем новое сверху стопки (в голову нашего стека, если говорить абстрактно). Следующая операция после добавления — считывание элементов, когда мы во время обеда берём чистую тарелку сверху нашей вымытой стопки. Таким образом, когда будем перемыта вся посуда и настанет время обеда — мы первой возьмём ту тарелку, которая была вымыта последней. Это и есть основной принцип LIFO — кто последний был добавлен, первым и будет использован.
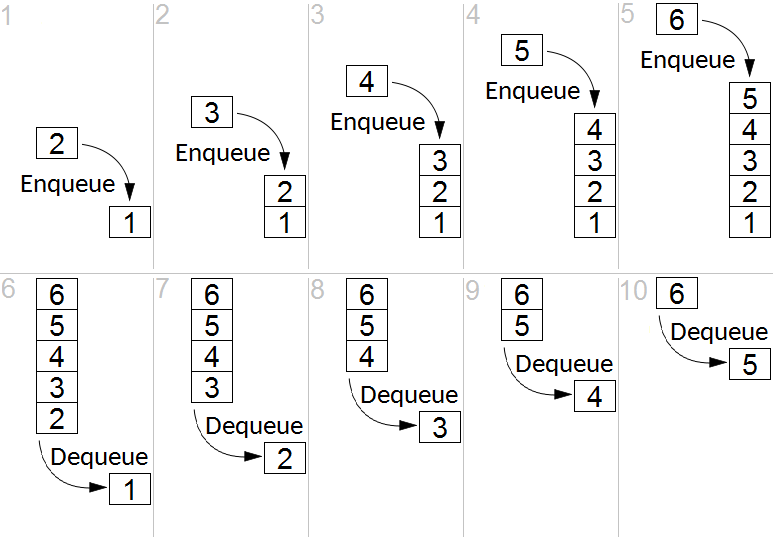
Конечно, из стека тарелок можно сделать и очередь. Для этого нужно каждую новую вымытую тарелку складывать не поверх стопки, а под самый низ. Что очень не удобно, иррационально и алогично — при росте количества тарелок организовать очередь будет труднее и по времени, и по количеству лишних действий. Кроме того, каждый раз поднимая все тарелки их можно разбить.
Примеры У стека широкая область применения: прокладки пути в графах и деревьях, существуют целые стековые языки программирования (в первую очередь использующие ассемблер, как финальный результат компиляции, как это реализовано в Java/C#), организация работы «стековых» машин (к примеру, для расчётов по алгоритму обратной польской нотации)
В повседневной жизни существуют и другие примеры стека: выглаженные футболки, магазин с патронами, стек вызовов ваших функций\методов, рекурсивные функции и т.д.
В программировании, стек играет очень важную роль, если не самую главную. В иерархии методов (call history) всегда будет именно (и только) стек. Приведём следующий псевдокод для примера:
Рекурсивные методы вызываются подобным образом. Отсюда и классическая проблема stack overflow (знакомый сайт, да?), когда стек забивается до отказа выполняемыми методами и мы упираемся в физическое ограничение по памяти или возможностям вашего компьютера или ОС. С этим нужно быть осторожными.
Привычными методами внутри стека являются Push – добавление наверх и Pop – считывание и удаление с верхушки. Иногда добавляются также методы Peek для считывания верхнего элемента без удаления, а также IsFull и IsEmpty — для понимания заполненности стека. Алгоритм организации стека не сложнее очереди:
Шаг №1 — объявление переменных:
Шаг №2 — функция\метод добавления элемента в стек ( push ):
Шаг №3 — функция\метод считывания элемента из головы стека ( pop ):
Принципы FIFO, FEFO, LIFO, FPFO, BBD и чем их различие

В зависимости от требований и конкурентной среды, применяются виды обработки товара, которые будут оптимальны, удобны и эффективны. Как мы настроим бизнес-процессы, в том числе в логистике, будет зависеть наша оперативность и точность. Принцип FiFo, что это такое? Чем отличается от FeFo, LiFo и других видов обработки товара или информации?
Сегодня просто и доступно разберем все эти вопросы. Исходя из этого Вам будет гораздо проще подобрать оптимальный вариант. Итак, начнем.
Принцип FeFo — что это такое в логистике
Аббревиатура FEFO — first expire, first out. Дословно с Английского, — что первым заканчивается, то первым и выходит. Классический принцип FeFo применяют для товара, который имеет ограниченный срок годности. То есть, товар, имеющий наименьший срок годности отгружается, продается в первую очередь. Под принцип FeFO попадают продукты питания или иные товары с небольшим сроком годности.
Мы наблюдаем в супермаркетах, что на полки, ближе всего к покупателю, выставляют товар, сроки годности по которым, имеют меньший срок, чем товары, которые располагаются в глубине полок. Как понимаем, если срок годности не вышел, здесь нет криминала. Менеджеры и мерчендайзеры продовольственных магазинов грамотно используют принцип FeFo.
Этот же принцип FeFo может являться основным на продовольственных складах или складах медицинского назначения, где этот метод также может быть уместен по ряду товаров.
На складе, визуально за такими товарами не уследить. Здесь нужна хорошая автоматизированная система учета.
Еще при приемке на склад, кладовщик заводит в WMS ( складскую программу) не только общие характеристики товара, но и обязательно, данные со сроками годности. При задаче на отгрузку, WMS склада, по заданному алгоритму, подтягивает те товары, которые по срокам годности имеют приоритет.
Исходя из этого, топология склада должна строиться таким образом, что бы доступ к товарам был свободным. Часто используется стеллажное хранение. Или, если это позволяет условия хранения товара, возможен вариант с наклонными ячейками, набивными стеллажами, где закладка товара идет с одной и более высокой стороны, а его выемка, с другой стороны.
 наклонный стеллаж хранения и подбора товара
наклонный стеллаж хранения и подбора товара
Принцип FiFo — что это такое в логистике
FiFo — first-in-first-out. Дословно с Английского, что первым зашло, то первым вышло. Здесь уже определяется не по срокам годности, а по срокам прибытия. Что первым пришло, то и первым должно уйти, отрузиться. Принцип FiFo, тот же принцип живой очереди. Какой клиент пришел первым, тот первым должен быть обслужен.
Принцип FiFo является основным методом обработки товара, как сборного груза, у транспортно-логистических компаний. Таким компаниям важно, что бы их клиенты получали товары в разных концах страны в заявленные ими сроки.
Например, идет сборка разных грузов клиентов с одной точки для доставки по разным направлениям. Процессы склада должны быть пространственно и на уровне складской программы настроены так, что бы товары клиентов не терялись в плане приоритетов отгрузки. Все, что для перемещения в точку «А» пришло сегодня, должно быть отгружено в одно время.
Но никак груз пришедший через 10 минут или завтра, не должен попасть в документ отгрузки раньше предыдущего груза.
При быстрой оборачиваемости товара или условий доставки требующей быстрой обработки, используют метод напольного хранения. Пришедший груз, тут же перемещают в противоположный участок склада, с ворот приемки, к воротам отгрузки, в зону накопления.
 зона накопления на складе
зона накопления на складе
Если товар не требует быстрой отгрузки, то уместно хранить на стеллажах с системой адресного хранения, где также к товару будут привязаны сроки поступления на склад.
Принцип LiFo — что это такое в логистике
LiFo — last-in-first-out. С Английского, что пришло последним, — отгружено первым. Принцип LiFo прямо противоположен принципу FiFo.
Принцип LiFo иногда называют бюрократическим методом, поскольку те документы, что легли сверху, первыми и рассматриваются. На самом деле, в логистике принцип LiFo широко используются, когда груз почти не ограничен сроками годности, и не связан приоритетами отгрузок по FiFo. Например, это могут быть какие-то заготовки, блоки из камня.
 укладка заготовок по методу Lifo
укладка заготовок по методу Lifo
Также склад может иметь только одни ворота на вход и отгрузку, или ограничен в пространстве. В этом случае, что вошло на склад последним, отгружается первым.
Принцип Lifo в бухгалтерии
В бухгалтерии также используется принцип Lifo. Например:
Согласно методу LiFo, статьи запаса закупленными последними, будут проданы первыми. Соответственно, статьи, остающиеся в запасе в конце периода, были раньше всего приобретены или произведены.
Списание в производство материалов по последней цене их приобретения, позволяет устранить инфляционное занижение расчетной себестоимости готовой продукции. Тем самым, избежать преждевременной уплаты части налога на прибыль.
Метод FpFo
FpFo — First Product First Out. Что означает, — первым произведено, первым и выходит. FpFo используют на производственных предприятиях. Произведенный товар имеет партии, и должен быть отгружен с учетом самой ранней партии производства.
Можно задать вопрос, в чем тогда разница между FiFo и FpFo. Вроде принцип один и тот же. По сути да, но сделано разделение между продуктом, который родился в стенах производства (FpFo) и тем продуктом, который, в готовом виде зашел в стены производства, склада, магазина (FiFo).
Метод BBD
BBD — Best Before Day. Первым исходит рекомендуемый срок, первым и выходит, подлежит отгрузке.
Такая продукция ротируется в соответствие с минимально остаточным рекомендуемыми сроками. Для понимания, хорошим примером будет винная продукция, где используется рекомендуемая дата употребления продукта. Как мы понимаем, такая продукция вовсе не несет рисков для здоровья, а имеет свою специфику приготовления и использования.
Аналогичным примером может послужить, приготовление сыров. Некоторые его сорта, также имеют специфику с рекомендуемой датой его полной готовности и употребления.
Принцип FiFo, FeFo, LiFo. Резюме.
В самом начале, мы говорили о том, что при построении модели бизнеса, бизнес-процессов компании, нам нужно иметь ясное понимание, каким методом будет обрабатываться товар, груз, информация. Нам необходимо взглянуть достаточно широко, ведь нам нужно еще отталкиваться от требований рынка, конкуренции, наших клиентов.
И например, принцип FiFo на складе может стать не единственным видом обработки. На этом же складе может потребоваться два или три вида обработки, что существенно усложнит его работу. Сможет ли выполнять один склад? Я работал на складе, где использовалось сразу 3 принципа обработки товара. Здесь должно все работать, как единый, слаженный механизм.
После выбранной модели или моделей, необходима топология склада с учетом максимальной нагрузки на каждый участок и пропускной нагрузки на ворота склада. Из своего опыта расчетов по топологии склада, скажу, что это очень важная работа, поскольку для бизнеса сразу определяет оптимальную и максимальную нагрузку на склад.
Крайне важно заранее понимать самое узкое место склада.
Могу рекомендовать книгу Гэвин Ричардса — «Управление современным складом». Обычно, я стараюсь дать ссылку на бесплатный материал, но здесь ничего не нашел. Поэтому, только ссылка на покупку этой книги в интернете. https://book24.ru/product/upravlenie-sovremennym-skladom-1650401/
Надеюсь, статья, принцип FiFo, FeFo, LiFo, была полезной. Мы разобрали основную классику; принцип FiFo — что это такое в логистике, принцип FeFo — что это такое в логистике и принцип LiFo — что это такое в логистике. Пишите в комментариях, задавайте вопросы. Будьте здоровы и счастливы!