
Проверка диска в консоли Linux
Проверка диска на наличие плохих секторов возникает нежданно и лучше знать как это сделать имея под рукой всё необходимое. Вариантов проверки дисков множество. Расскажу о проверке средствами консоли Linux. Просто и ничего лишнего.
Причины для проверки диска
Основная причина проверки это как правило медленная работа системы или зависание при определенных действиях. Вывести диск из строя могут разные факторы. Вот некоторые из них:
Самое лучшее это периодически проверять диск просто так. На ранней стадии обнаружения гораздо больше шансов сохранить важные данные.
Храните важные данные в двух совершенно разных физически местах. Только такой подход гарантирует вам полную сохранность данных.
Определение диска для проверки
Для того чтобы понять какой диск проверять нам достаточно ввести команду в консоли которая выдаст нам список всех имеющихся дисков в системе.
Мы видим в выводе диск который нам надо проверить. Диск имеет 2 раздела с данными.
Проверка диска на битые секторы
Перед проверкой разделы необходимо отмонтировать. Как правило я загружаю операционную систему на базе Linux c Live образа или использую подготовленный PXE сервер на котором присутствуют и другие программы для проверки жестких дисков.
Можно сразу запустить проверку с исправлением, но мне кажется это неправильно. Гораздо логичней вначале проверить диск и собрать информацию обо всех битых секторах и только после этого принять решение о дальнейшей судьбе диска.
При появлении хотя бы нескольких плохих секторов я больше диск не использую. Пометку плохих секторов с попыткой забрать из них информацию использую только для того чтобы сохранить данные на другой диск.
Создание файла для записи плохих секторов
Создадим файл указав для удобства имя проверяемого раздела.
Проверка диска утилитой badblocks
Запустим проверку с информацией о ходе процесса с подробным выводом. Чем больше диск тем дольше проверка!
В нашем случае диск с 8 плохими секторами.
Пометка плохих секторов диска
Запустим утилиту e2fsck, указав ей список битых секторов. Программа пометит плохие сектора и попытается восстановить данные.
Указывать формат файловой системы нет надобности. Утилита сделает всё сама.
Подготовка диска для проверки
Бывают случаи когда таблица разделов повреждена на диске и нет возможности посмотреть какие есть разделы с данными. Возможно вам не надо никаких данных на диске и вы хотите диск отформатировать и затем проверить. Случаи бывают разные и надо подходить исходя из ситуации.
Как работать с утилитой cfdisk я не буду, так как это выходит за рамки данной статьи.
Предположим что вы создали из всего диска лишь один раздел /dev/sda1. Для форматирования его в ext4 достаточно выполнить команду:
Вывод
Проще и понятней механизма проверки диска на битые сектора как в системе Linux я не встречал. Ничего лишнего только суть. Выбор варианта как проверять и когда всегда за вами. После того как я один раз потерял важные данные храню всё важное в 3 разных местах.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Читая их я получаю информацию которая позволяет мне улучшить качество написания статей. Кроме того, оставляя комментарии вы помогаете сайту получить более высокий рейтинг у поисковых систем. Давайте общаться.
База знаний wiki
Продукты
Статьи
Содержание
Проверка состояния жестких дисков в Linux
Слова для поиска: проверка дисков, hdparm, badblocks, smart, smartctl, iostat, mdstat
Задача:
Проверить состояние жестких дисков на выделенном сервере, наличие сбойных блоков на HDD, анализ S.M.A.R.T
Решение:
В этой статье будут рассмотрены способы проверки и диагностики HDD в Linux. Полученная информация поможет проанализировать состояние жестких дисков, и, если это необходимо, заменить носитель до того, как он вышел из строя неожиданно и в самый не подходящий для этого момент.
Задуматься о состоянии HDD следует по некоторым признакам поведения системы в целом: резко выросла общая нагрузка на дисковую подсистему, упала скорость чтения/записи, другие проблемы косвенно указывающие что с HDD что-то не то.
Ниже я приведу основные команды, выполнять их необходимо из-под учётной записи root
Чтобы получить список подключенных HDD в систему, выполнить:
Мы получим листинг всех подключенных накопителей, их размер и имена устройств в системе.
Для того, чтобы посмотреть какие устройства и куда смонтированы, выполнить:
Узнать сколько на каждом из смонтированном носителе занято пространства, выполнить:
Если мы используем софтовый RAID, его состояние мы можем проверить следующей командой:
Если всё в порядке, то мы увидим что-то подобное:
Из вывода видно состояние raid (active), название устройства raid (md0) и какие устройства в него включены (sdb1[0] sdc1[1]), какой именно raid собран (raid1), в нём два диска и они оба работают в raid ([2/2] [UU])
Смотрим скорость чтения с накопителя
Полезной программой для анализа нагрузки на диски является iostat, входящей в пакет sysstat Ставим:
Теперь смотрим вывод iostat по всем дискам в системе:
С интервалом 10 секунд:
Или по определённому накопителю:
Полученные данные покажут нам нагрузку на устройства хранения, статистику по вводу/выводу, процент утилизации накопителя.
Переходим непосредственно к проверке накопителей. Проверка на наличие сбойных блоков осуществляется при помощи программы badblocks. Для проверки жесткого диска на бэдблоки, выполнить:
Для того, чтобы записать сбойные блоки, выполняем:
Если были обнаружены сбойные блоки на диске, есть тенденция появления новых бэдблоков, необходимо задуматься о скорейшем копировании данных и замене данного носителя. Приведённые выше команды помогут выявить сбойные блоки и пометить их как таковые, но не спасут «сыпящийся» диск.
Также в своём инструментарии полезно использовать данные полученные из S.M.A.R.T. дисков.
Ставим пакет smartmontools
Получаем данные S.M.A.R.T. жесткого диска:
Для сохранности данных настоятельно рекомендуем делать backup (резервное копирование). Это поможет в кратчайшие сроки восстановить необходимые данные и настройки в форс-мажорных обстоятельствах.
Проверка диска на битые секторы в Linux
Битые сектора, это повреждённые ячейки, которые больше не работают по каким либо причинам. Но файловая система всё ещё может пытаться записать в них данные. Прочитать данные из таких секторов очень сложно, поэтому вы можете их потерять. Новые диски SSD уже не подвержены этой проблеме, потому что там существует специальный контроллер, следящий за работоспособностью ячеек и перемещающий данные из нерабочих в рабочие. Однако традиционные жесткие диски используются всё ещё очень часто. В этой статье мы рассмотрим как проверить диск на битые секторы Linux.
Проверка диска на битые секторы Linux
Для поиска битых секторов можно использовать утилиту badblocks. Если вам надо проверить корневой или домашний раздел диска, то лучше загрузится в LiveCD, чтобы файловая система не была смонтирована. Все остальные разделы можно сканировать в вашей установленной системе. Вам может понадобиться посмотреть какие разделы есть на диске. Для этого можно воспользоваться командой fdisk:
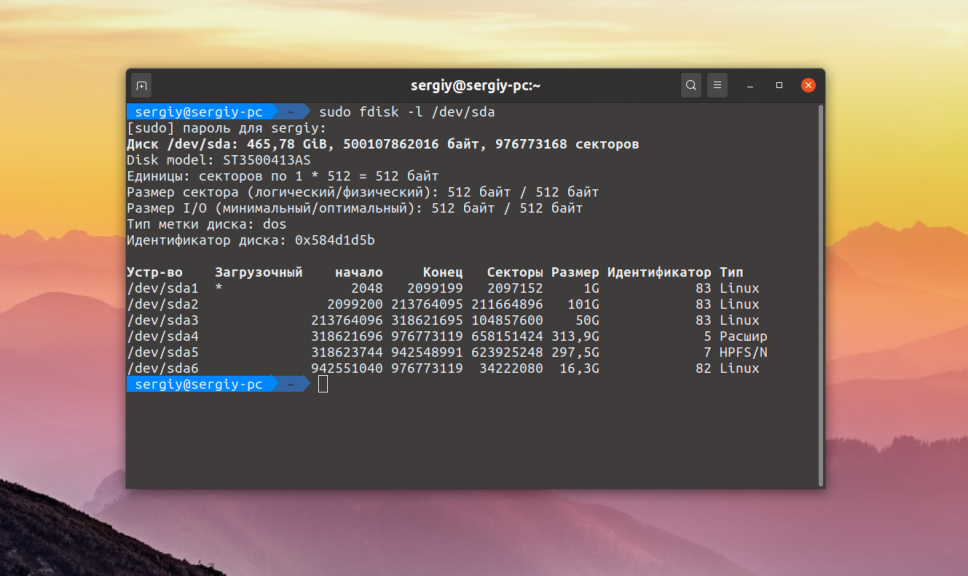
Или если вы предпочитаете использовать графический интерфейс, это можно сделать с помощью утилиты Gparted. Просто выберите нужный диск в выпадающем списке:
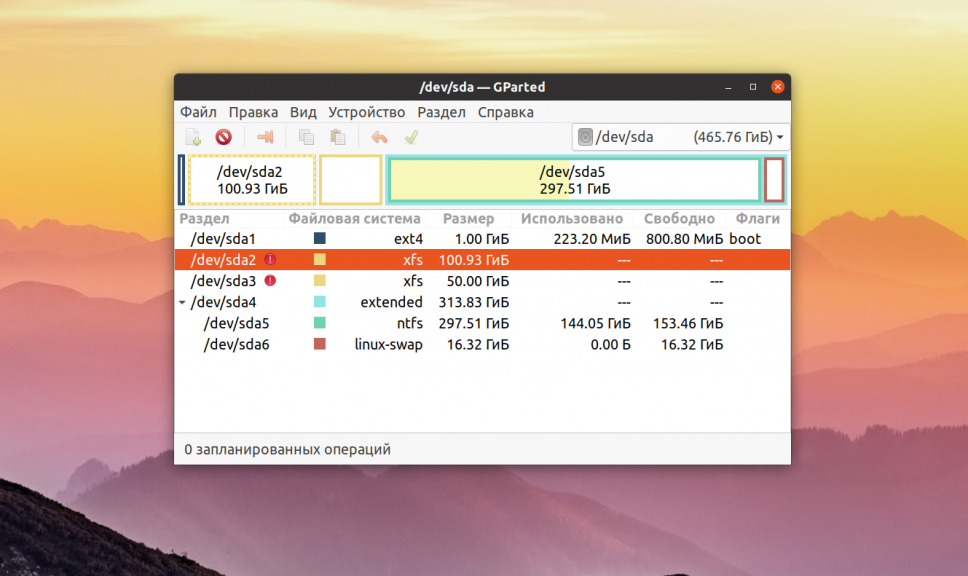
В этом примере я хочу проверить раздел /dev/sda2 с файловой системой XFS. Как я уже говорил, для этого используется команда badblocks. Синтаксис у неё довольно простой:
$ sudo badblocks опции /dev/имя_раздела_диска
Давайте рассмотрим опции программы, которые вам могут понадобится:
Таким образом, для обычной проверки используйте такую команду:
Это безопасно и её можно выполнять на файловой системе с данными, она ничего не повредит. В принципе, её даже можно выполнять на смонтированной файловой системе, хотя этого делать не рекомендуется. Если файловая система размонтирована, можно выполнить тест с записью с помощью опции -n:
Если на разделе используется файловая система семейства Ext, например Ext4, то для поиска битых блоков и автоматической регистрации их в файловой системе можно использовать команду e2fsck. Например:
Выводы
В этой статье мы рассмотрели как выполняется проверка диска на битые секторы Linux, чтобы вовремя предусмотреть возможные сбои и не потерять данные. Но на битых секторах проблемы с диском не заканчиваются. Там есть множество параметров стабильности работы, которые можно отслеживать с помощью таблицы SMART. Читайте об этом в статье Проверка диска в Linux.
Проверка состояния накопителей в Linux
Обновлено Ноя 6, 2019
Проверка и анализ состояния накопителей в Linux с помощью консольных утилит badblocks, smartmontools и графической программы GSmartControl
Проверка накопителей средствами badblocks
Утилита badblocks установлена по-умолчанию.
Для просмотра подключенных накопителей и разделов на них, введите команду:

Для проверки накопителя на битые сектора, выполнить команду:
-v – отображение подробной информации во время работы программы
/dev/sdX – имя устройства, которое необходимо проверить
> badblocks.txt – запись результатов проверки (сохраняется в домашней папке: /home/user)

При наличии битых секторов, можно воспользоваться утилитами: e2fsck (ext2, ext3, ext4), fsck (отличные от ext) для игнорирования системой битых секторов:
Проверка состояния накопителей при помощи S.M.A.R.T.
Установка:
Для проверки накопителя на битые сектора при помощи S.M.A.R.T., выполнить команду:
/dev/sdX – имя устройства, которое необходимо проверить
Проверка состояния накопителей при помощи GSmartControl
Чтобы установить самую свежую стабильную версию GSmartControl в Ubuntu, можно воспользоваться PPA репозиторием. Для этого выполните последовательно в терминале команды:
Выбираем диск и кликаем левой клавишей мыши 2 раза или выбираем диск, потом идём в меню, там жмём на Device, далее жмём View details, далее жмём на вкладку Attributes:
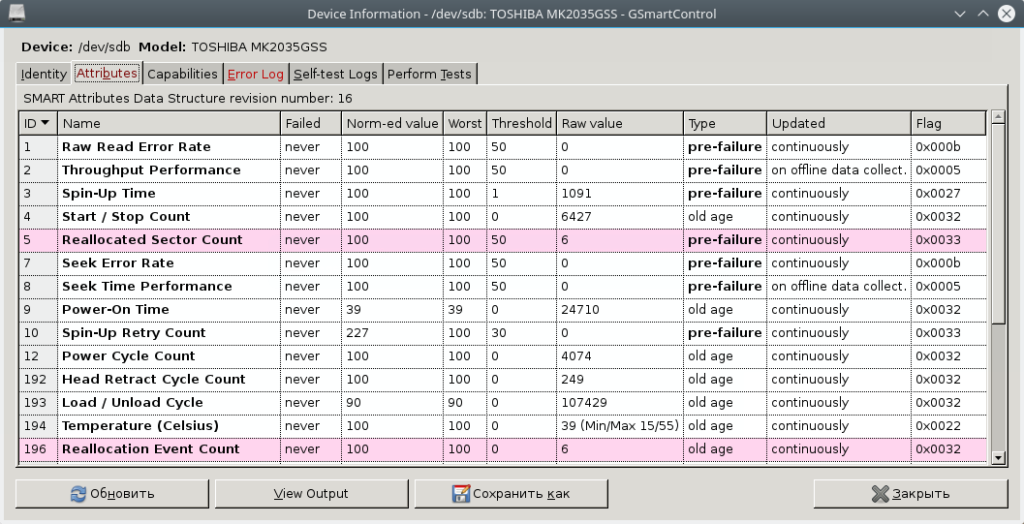
Анализ параметров, выводимых программой
Каждый атрибут имеет величину Value. Value Изменяется в диапазоне от 0 до 255 задается производителем). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Raw Value – это значение атрибута во внутреннем формате производителя значение малоинформативно для всех кроме сервисманов. Threshold – минимальное возможное значение атрибута, при котором гарантируется безотказная работа накопителя. SMART. Смотрим состояние жесткого диска. Если VALUE стало меньше THRESH – Атрибут считается failed и отображается в столбце WHEN_FAILED. При значении атрибута меньше Threshold очень вероятен сбой в работе или полный отказ. WORST- минимальное нормализованное значение. Это минимальное значение, которое достигалось с момента включения SMART на диске. Атрибуты бывают критически важными (Pre-fail) и некритически важными (Old_age). Выход критически важного параметра за пределы Threshold фактический означает выход диска из строя, выход за пределы допустимых значений не критически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность.
Критичные атрибуты
Raw Read Error Rate – частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time – время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся не максимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например просадка по вольтажу блока питания.
Spin Up Retry Count – число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно не максимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate – частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count – число операций переназначения секторов. SMART в современных дисках способен произвести анализ сектора на стабильность работы “на лету” и в случае признания его сбойным, произвести его переназначение.
Некритичные атрибуты:
Start/Stop Count – полное число запусков/остановов шпинделя. Гарантировано мотор диска способен перенести лишь определенное число включений/выключений. Это значение выбирается в качестве Treshold. Первые модели дисков со скоростью вращения 7200 оборотов/мин имели ненадежный двигатель, могли перенести лишь небольшое их число и быстро выходили из строя.
Power On Hours – число часов проведенных во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF). Обычно величина MTBF огромна, и маловероятно, что этот параметр достигнет критического порога. Но даже в этом случае выход из строя диска совершенно не обязателен.
Drive Power Cycle Count – количество полных циклов включения-выключения диска. По этому и предыдущему атрибуту можно оценить, например, сколько использовался диск до покупки.
Temperatue – Здесь хранятся показания встроенного термодатчика. Температура имеет огромное влияние на срок службы диска (даже если она находится в допустимых пределах). Вернее имеет влияние не на срок службы диска а на частоту возникновения некоторых типов ошибок, которые влияют на срок службы.
Current Pending Sector Count – Число секторов, являющихся кандидатами на замену. Они не были ещё определены как плохие, но считывание их отличается от чтения стабильного сектора, так называемые подозрительные или нестабильные сектора.
Uncorrectable Sector Count – число ошибок при обращении к сектору, которые не были скорректированы. Возможными причинами возникновения могут быть сбои механики или порча поверхности.
UDMA CRC Error Rate – число ошибок, возникающих при передаче данных по внешнему интерфейсу. Могут быть вызваны некачественными кабелями, нештатными режимами работы.
Write Error Rate – показывает частоту ошибок происходящих при записи на диск. Может служить показателем качества поверхности и механики накопителя.
Проверка жесткого диска в Линукс
Начнем с определения плохого/битого сектора или блока — это раздел на диске или флэш-памяти, которые больше не могут быть прочитаны или записаны, в результате фиксированного физического повреждения на поверхности диска или сбойных транзисторов флэш-памяти.
По мере того как битые сектора продолжают накапливаться, они могут нежелательно или разрушительно влиять на ваше место накопителя на диске или флэш-памяти или даже привести к возможному сбою оборудования.
Также важно отметить, что наличие битых блоков должно предупредить вас о том, чтобы начать думать о приобретении нового диска или просто отметить битые блоки как непригодные для использования.
Поэтому в этой статье мы рассмотрим необходимые шаги, которые позволят вам определить наличие или отсутствие поврежденных секторов на вашем Linux-диске или флэш-памяти с помощью определенных утилит сканирования диска. Проверка жесткого диска в Линукс является очень быстрой.
Также, вы можете прочитать статью о том, какой менеджер закачек для Linux является лучшим.
Проверка жесткого диска в Линукс
Проверка Bad Sectors в Linux-дисках с использованием инструмента badblocks
Программа badblocks позволяет пользователям сканировать устройство на наличие поврежденных секторов или блоков. Устройство может быть жестким диском или внешним диском, представленным файлом, например / dev / sdc.
Во-первых, используйте команду fdisk с привилегиями суперпользователя, чтобы отображать информацию обо всех ваших дисках или флэш-памяти и их разделах:
Затем сканируйте свой Linux-диск, чтобы проверить наличие поврежденных секторов / блоков, набрав:
Если вы обнаружите какие-либо поврежденные сектора на вашем диске, отключите диск и сообщите операционной системе, чтобы она не записывалась в указанные сектора следующим образом.
Вам нужно будет использовать e2fsck (для файловых систем ext2 / ext3 / ext4) или fsck с файлом badsectors.txt и файлом устройства, как в приведенной ниже команде.
———— Specifically for ext2/ext3/ext4 file-systems ————
———— For other file-systems ————
Сканирование битых секторов на диске Linux с помощью Smartmontools
Этот метод более надежный и эффективный для современных дисков (жесткие диски ATA / SATA и SCSI / SAS и твердотельные накопители), которые поставляются с системой SMART (Self-Monitoring, Analysis and Reporting Technology), которая помогает обнаруживать, сообщать и, возможно, Запишите их состояние работоспособности, чтобы вы могли найти возможные сбои аппаратного обеспечения.
Вы можете установить smartmontools, выполнив следующую команду:
———— On Debian/Ubuntu based systems ————
$ sudo apt-get install smartmontools
———— On RHEL/CentOS based systems ————
$ sudo yum install smartmontools
По завершении установки используйте smartctl, который управляет системой S.M.A.R.T, интегрированной в диск. Вы можете просмотреть страницу своего руководства или страницу справки следующим образом:
Результат, указанный выше, указывает на то, что ваш жесткий диск здоров, и в скором времени могут не произойти сбои оборудования.
Возможно, у вас есть какие-то вопросы по теме «Проверка жесткого диска в Линукс» — сообщите нам об этом в форме комментариев на сайте.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.