Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
Командный синтаксис grep
Синтаксис команды grep следующий:
Пункты в квадратных скобках необязательны.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Результат должен выглядеть примерно так:
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Инвертировать соответствие (исключить)
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
Рекурсивный поиск
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Показать только имя файла
Результат будет выглядеть примерно так:
Поиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Показать номера строк
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
Результат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Подсчет совпадений
Бесшумный режим
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (каретка) для сопоставления выражения в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
Поиск нескольких строк (шаблонов)
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
Строки печати перед матчем
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
Печатать строки после матча
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
Выводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Утилита find представляет универсальный и функциональный способ для поиска в Linux. Данная статья является шпаргалкой с описанием и примерами ее использования.
Общий синтаксис
— путь к корневому каталогу, откуда начинать поиск. Например, find /home/user — искать в соответствующем каталоге. Для текущего каталога нужно использовать точку «.».
— набор правил, по которым выполнять поиск.
* по умолчанию, поиск рекурсивный. Для поиска в конкретном каталоге можно использовать опцию maxdepth.
Описание опций
Опция
Описание
-name
Поиск по имени.
-iname
Регистронезависимый поиск по имени.
-type
Тип объекта поиска. Возможные варианты:
Также доступны логические операторы:
Полный набор актуальных опций можно получить командой man find.
Примеры использования find
Поиск файла по имени
1. Простой поиск по имени:
* в данном примере будет выполнен поиск файла с именем file.txt по всей файловой системе, начинающейся с корня /.
2. Поиск файла по части имени:
* данной командой будет выполнен поиск всех папок или файлов в корневой директории /, заканчивающихся на .tmp
3. Несколько условий.
а) Логическое И. Например, файлы, которые начинаются на sess_ и заканчиваются на cd:
б) Логическое ИЛИ. Например, файлы, которые начинаются на sess_ или заканчиваются на cd:
в) Более компактный вид имеют регулярные выражения, например:
* где в первом поиске применяется выражение, аналогичное примеру а), а во втором — б).
* в данном примере мы воспользовались логическим оператором !.
Поиск по дате
1. Поиск файлов, которые менялись определенное количество дней назад:
* данная команда найдет файлы, которые менялись более 60 дней назад.
* покажет все файлы, которые менялись, начиная с 02.11.2019 00:00.
* найдет все файлы, которые менялись в промежутке между 31.10.2019 и 01.11.2019 (включительно).
* все файлы, к которым обращались с 08.10.2019.
* все файлы, к которым обращались в октябре.
* все файлы, созданные с 07 сентября 2019 года.
* файлы, созданные с 07.09.2019 00:00:00 по 09.09.2019 07:50
По типу
Искать в текущей директории и всех ее подпапках только файлы:
* f — искать только файлы.
Поиск по правам доступа
1. Ищем все справами на чтение и запись:
2. Находим файлы, доступ к которым имеет только владелец:
Поиск файла по содержимому
* в данном примере выполнен рекурсивный поиск всех файлов в директории / и выведен список тех, в которых содержится строка content.
С сортировкой по дате модификации
* команда найдет все файлы в каталоге /data, добавит к имени дату модификации и отсортирует данные по имени. В итоге получаем, что файлы будут идти в порядке их изменения.
Лимит на количество выводимых результатов
Самый распространенный пример — вывести один файл, который последний раз был модифицирован. Берем пример с сортировкой и добавляем следующее:
Поиск с действием (exec)
1. Найти только файлы, которые начинаются на sess_ и удалить их:
* -print использовать не обязательно, но он покажет все, что будет удаляться, поэтому данную опцию удобно использовать, когда команда выполняется вручную.
2. Переименовать найденные файлы:
3. Вывести на экран количество найденных файлов и папок, которые заканчиваются на .tmp:
* в данном примере мы ищем все каталоги (type d) в директории /home/user и ставим для них права 2700.
5. Передать найденные файлы конвееру (pipe):
* в данном примере мы использовали find для поиска строки test в файлах, которые находятся в каталоге /etc, и название которых заканчивается на .conf. Для этого мы передали список найденных файлов команде grep, которая уже и выполнила поиск по содержимому данных файлов.
6. Произвести замену в файлах с помощью команды sed:
* находим все файлы в каталоге /opt/project и меняем их содержимое с test на production.
Чистка по расписанию
Команду find удобно использовать для автоматического удаления устаревших файлов.
Открываем на редактирование задания cron:
* в данном примере мы удаляем все файлы и папки из каталога /tmp, которые старше 14 дней. Задание запускается каждый день в 00:00. * полный путь к исполняемому файлу find смотрим командой which find — в разных UNIX системах он может располагаться в разных местах.
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Рекурсивно найти слово в файлах и папках Linux
Дистрибутив Linux, несмотря на версию и вид, имеет множество графических оболочек, которые позволяют искать файлы. Большинство из их них позволяют искать сами файлы, но, к сожалению, они редко позволяют искать по содержимому. А особенно рекурсивно. В статье покажем два способа того, как можно рекурсивно найти файлы, которые содержат ту или иную фразу. Поиск будет осуществлен по папкам и директориям внутри этих папок.
Найти фразу в файлах рекурсивно через консоль
Все просто. Открываем серверную консоль, подключившись по SSH. А далее, вводим команду:
Например, команда может выглядеть вот так:
Команда найдет и выведет все файлы, которые содержат фразу merionet в директории /home/user/merion и во всех директориях, внутри этой папки. Мы используем следующие ключи:
Так же, вам могут быть полезны следующие ключи:
Поиск слова через Midnight Commander
Так же, в консоли сервера, дайте команду:
Эта команда запустит Midnight Commander. Кстати, если он у вас не установлен, его можно просто установить через yum:
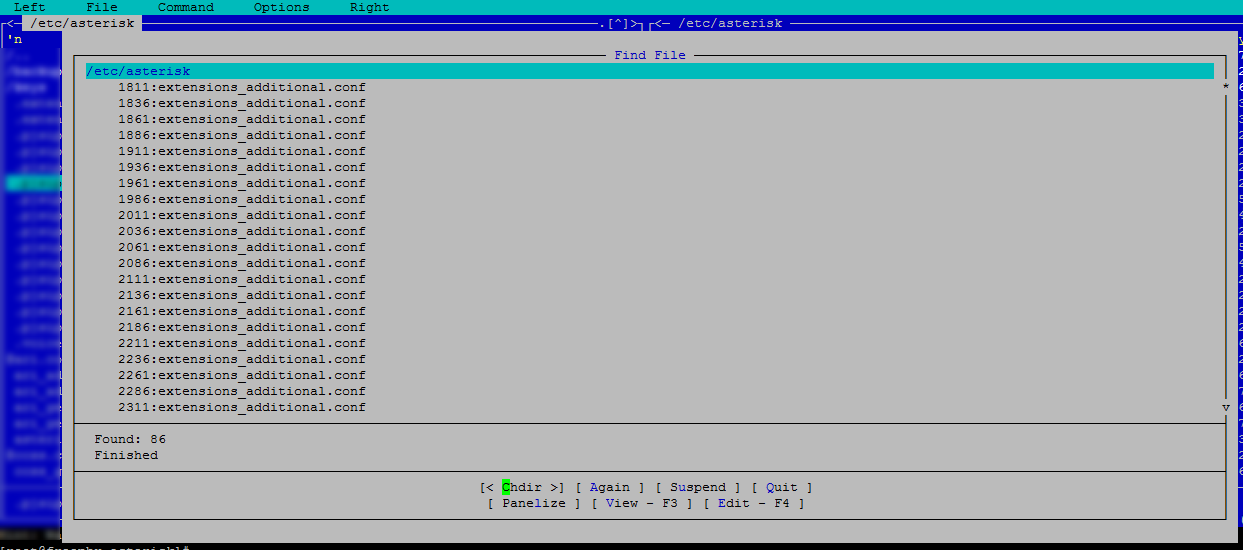
Открыв mc, во вкладке Command выберите Find File и заполните поисковую форму как показано ниже:
Нажимаем OK и получаем результат:
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Как найти все файлы, содержащие определённый текст (на Linux)
Иногда бывают ситуации, когда нужно просканировать всю файловую систему Linux и найти все файлы, содержащие определённую строку текста. То есть нужно выполнить поиск не по имени файла, а по содержимому текстового файла.
Пример таких ситуаций из практики:
Пример — поиск заголовка Strict-Transport-Security в директории конфигурационных файлов веб-сервера:
Одним из лучших вариантов поиска всех файлов, содержащих заданный текст, является команда:
В этой команде используются следующие опции:
-r (также можно использовать -R) для рекурсивного поиска — то есть поиск будет выполнен в папке и подпапках. Опция -R делает так, что программа следует по символическим ссылкам, если натыкается на них, соответственно, с опцией -r этого не происходит. Но поиск является рекурсивным в обоих случаях
-n означает выводить номера строку (чтобы быстрее найти в них нужное место)
-w используется для поиска по полным словам. При использовании опции -w будут выбраны только строки, которые содержат совпадения целых слов. То есть для того, чтобы совпадение засчиталось, совпавшая подстрока быть либо вначале строки, либо перед ней должен идти несловесный составной символ. Аналогично она должна быть либо в конце строки, либо за ней должен следовать несловесный составной символ. Словесными составными символами являются буквы, цифры и подчёркивание. Соответственно, несловесными являются все остальные: пробелы, знаки препинания, дефисы и прочее.
Эти опции являются оптимальными, но, на самом деле, для поиска по всей директории вместе с вложенными поддиректориями, либо по всей файловой системе, достаточно использовать только опцию -r, а остальные можно пропустить.
Рассмотрим ещё несколько опций, которые могут оказаться весьма полезными:
-i для игнорирования регистра букв (по умолчанию ищутся буквы в точно таком же регистре, как и в шаблоне). Но обратите внимание, что эта опция очень сильно замедляет скорость поиска.
-l (маленькая L) подавляет нормальный вывод; вместо него выводится имя каждого файла, в котором найдено совпадение. То есть по умолчанию выводиться совпавшая строка, а с этой опцией будут выводиться только имена файлов, в которых найдена строка. Сканирование будет остановлено после первого совпадения.
—color[=КОГДА], —colour[=КОГДА] — используется для подсветки в терминале совпавшей подстроки, контекстных строк, имён файлов, номеров строк, байтового смещения и разделителей (для полей и групп контестных строк). КОГДА можно указывать или не указывать по жоеланию. В качестве КОГДА может быть never (никогда), always (всегда) или auto (автоматически).
-I — пропускать бинарные файлы. При рекурсивной обработке могут попадаться не текстовые файлы, натыкаясь на которые grep будет показывать предупреждения. Эта опция делает обработку бинарных файлов такой, как если бы они не содержали совпадающих данных.
В качестве шаблона grep используются регулярные выражения — они являются крайне мощным инструментом для поиска строк. Тем не менее, если вы не умеете пользоваться регулярными выражениями, то вы можете получить не те результаты, которых ожидаете, поскольку некоторые символы в регулярных выражениях имеют специальное значение. По этой причине рекомендуется ознакомиться с большой понятной инструкцией «Регулярные выражения и команда grep».
Ещё один вариант — использовать опцию -F. Она будет интерпретировать ШАБЛОНЫ как фиксированные строки, а не как регулярные выражения. С одной стороны, команда grep потеряет часть своей гибкости, но при этом вы получите более предсказуемый результат, если вы не понимаете регулярные выражения.
В зависимости от обстоятельств, можно использовать для повышения эффективности поиска следующие флаги:
—exclude=GLOB — означает пропустить файлы, с именем суффикса, которое совпадёт с шаблоном GLOB. Имя суффикса это как полное имя, так и любой суффикс, начинающийся после / и перед не-/ (то есть между слэшей в пути имени файла). При рекурсивном поиске, пропускаются все подфайлы, чьё базовое имя совпадает с GLOB. Базовое имя — это часть после последнего слэша (/). Шаблон GLOB поддерживает несколько подстановочных символов. Шаблон (GLOB) может использовать в качестве подстановочных символов * (означает последовательность нуля или более символов), ? (означает ровно один символ), и [СИМВОЛЫ] (означает любой один из СИМВОЛОВ), (означает любой из символов), а также \ для экранирования подстановочных символов или символа обратного слэша, чтобы они начали восприниматься буквально.
—include=GLOB — искать только файлы, чьё базовое имя совпадает с GLOB (можно использовать подстановочные символы, как описано чуть выше)
—exclude-dir=GLOB — пропустить директории с суффиксом имени, которые совпадает с шаблоном GLOB. При рекурсивном поиски, пропуск любых поддиректорий, чьё базовое имя совпадает с GLOB. Любые избыточные конечные слэши в GLOB игнорируются.
В этой команде * (звёздочка) означает любое имя файла. Но эта звёздочка экранирована, поскольку для терминала она также имеет особое значение. В этом имене должна идти точка и буква c или h.
Следующий поиск исключит из результатов все файлы, которые заканчиваются на расширение .o:
Для директорий возможно исключить конкретную директорию(ии) через параметр —exclude-dir. Например, следующая команда исключит dirs dir1/, dir2/ и все другие директории соответствующие *.dst/:
Команда grep означает «глобальная печать регулярных выражений», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep считывает из стандартного ввода, которое обычно является выводом другой команды.
grep Синтаксис команды
Синтаксис grep команды следующий:
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ на чтение к файлу.
Поиск строки в файлах
Например, чтобы отобразить все строки, содержащие строку bash из /etc/passwd файла, вы должны выполнить следующую команду:
Вывод должен выглядеть примерно так:
Если строка содержит пробелы, вам необходимо заключить ее в одинарные или двойные кавычки:
Инвертировать (исключить) совпадение
Например, чтобы напечатать строки, которые не содержат строку, которую nologin вы используете:
Использование Grep для фильтрации выходных данных команды
Выходные данные команды могут быть отфильтрованы с grep помощью сквозного трубопровода, и только те строки, которые соответствуют заданному шаблону, будут напечатаны на терминале.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользователь, www-data вы можете использовать следующую ps команду:
Вы также можете объединить несколько каналов в команду. Как вы можете видеть в выводе выше, есть также строка, содержащая grep процесс. Если вы не хотите, чтобы эта строка отображалась, передайте вывод другому grep экземпляру, как показано ниже.
Рекурсивный поиск
Вот пример, показывающий, как искать строку baks.dev во всех файлах в /etc каталоге:
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Показывать только имя файла
Вывод будет выглядеть примерно так:
Поиск без учета регистра
По умолчанию учитывается grep регистр. Это означает, что прописные и строчные символы рассматриваются как разные.
Например, при поиске Zebra без какой-либо опции следующая команда не будет отображать никаких выходных данных, т.е. есть совпадающие строки:
Указание «Зебра» будет соответствовать «Зебра», «ZEbrA» или любой другой комбинации прописных и строчных букв для этой строки.
Поиск полных слов
При поиске строки grep будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Показать номера строк
Например, чтобы отобразить строки из /etc/services файла, содержащего строку с bash префиксом с соответствующим номером строки, вы можете использовать следующую команду:
Вывод ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Количество совпадений
В приведенном ниже примере мы подсчитываем количество учетных записей, которые имеют /usr/bin/zsh оболочку.
Скрытый режим
Вот пример использования grep в тихом режиме в качестве команды тестирования в if инструкции :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте ^ символ (каретка), чтобы соответствовать выражению в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Чтобы избежать специального значения следующего символа, используйте \ символ (обратный слеш).
Расширенные регулярные выражения
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
-o Опция используется для печати только строку соответствия.
Поиск по шаблону нескольких строк
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и их версии с обратной косой чертой должны использоваться.
Печать строк перед сопоставлением
Например, чтобы отобразить пять строк начального контекста перед сопоставлением строк, вы должны использовать следующую команду:
Печать строк после сопоставления
Например, чтобы отобразить пять строк конечного контекста после сопоставления строк, вы должны использовать следующую команду:
Вывод
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.