
Что такое логирование?

Известно, что программисты проводят много времени, отлаживая свои программы, пытаясь разобраться, почему они не работают — или работают неправильно. Когда говорят про отладку, обычно подразумевают либо отладочную печать, либо использование специальных программ – дебагеров. С их помощью отслеживается выполнение кода по шагам, во время которого видно, как меняется содержимое переменных. Эти способы хорошо работают в небольших программах, но в реальных приложениях быстро становятся неэффективными.
Сложность реальных приложений
Возьмем для примера типичный сайт. Что он в себя включает?
И это только самый простой случай. Реальность же значительно сложнее: множество разноплановых серверов, системы кеширования (ускорения доступа), асинхронный код, очереди, внешние сервисы, облачные сервисы. Все это выглядит как многослойный пирог, внутри которого где-то работает нами написанный код. И этот код составляет лишь небольшую часть всего происходящего. Как в такой ситуации понять, на каком этапе был сбой, или все пошло не по плану? Для этого, как минимум, нужно определить, в каком слое произошла ошибка. Но даже это не самое сложное. Об ошибках в работающем приложении узнают не сразу, а уже потом, — когда ошибка случилась и, иногда, больше не воспроизводится.
Логирование
И для всего этого многообразия систем существует единое решение — логирование. В простейшем случае логирование сводится к файлу на диске, куда разные программы записывают (логируют) свои действия во время работы. Такой файл называют логом или журналом. Как правило, внутри лога одна строчка соответствует одному действию.
Выше небольшой кусок лога веб-сервера Хекслета. Из него видно ip-адрес, с которого выполнялся запрос на страницу и какие ресурсы загружались, метод HTTP, ответ бекенда (кода) и размер тела ответа в HTTP. Очень важно наличие даты. Благодаря ей всегда можно найти лог за конкретный период, например на то время, когда возникла ошибка. Для этого логи грепают:
Когда программисты только начинают свой путь, они, часто не зная причину ошибки, опускают руки и говорят «я не знаю, что случилось, и что делать». Опытный же разработчик всегда первым делом говорит «а что в логах?». Анализировать логи — один из базовых навыков в разработке. В любой непонятной ситуации нужно смотреть логи. Логи пишут все программы без исключения, но делают это по-разному и в разные места. Чтобы точно узнать, куда и как, нужно идти в документацию конкретной программы и читать соответствующий раздел документации. Вот несколько примеров:
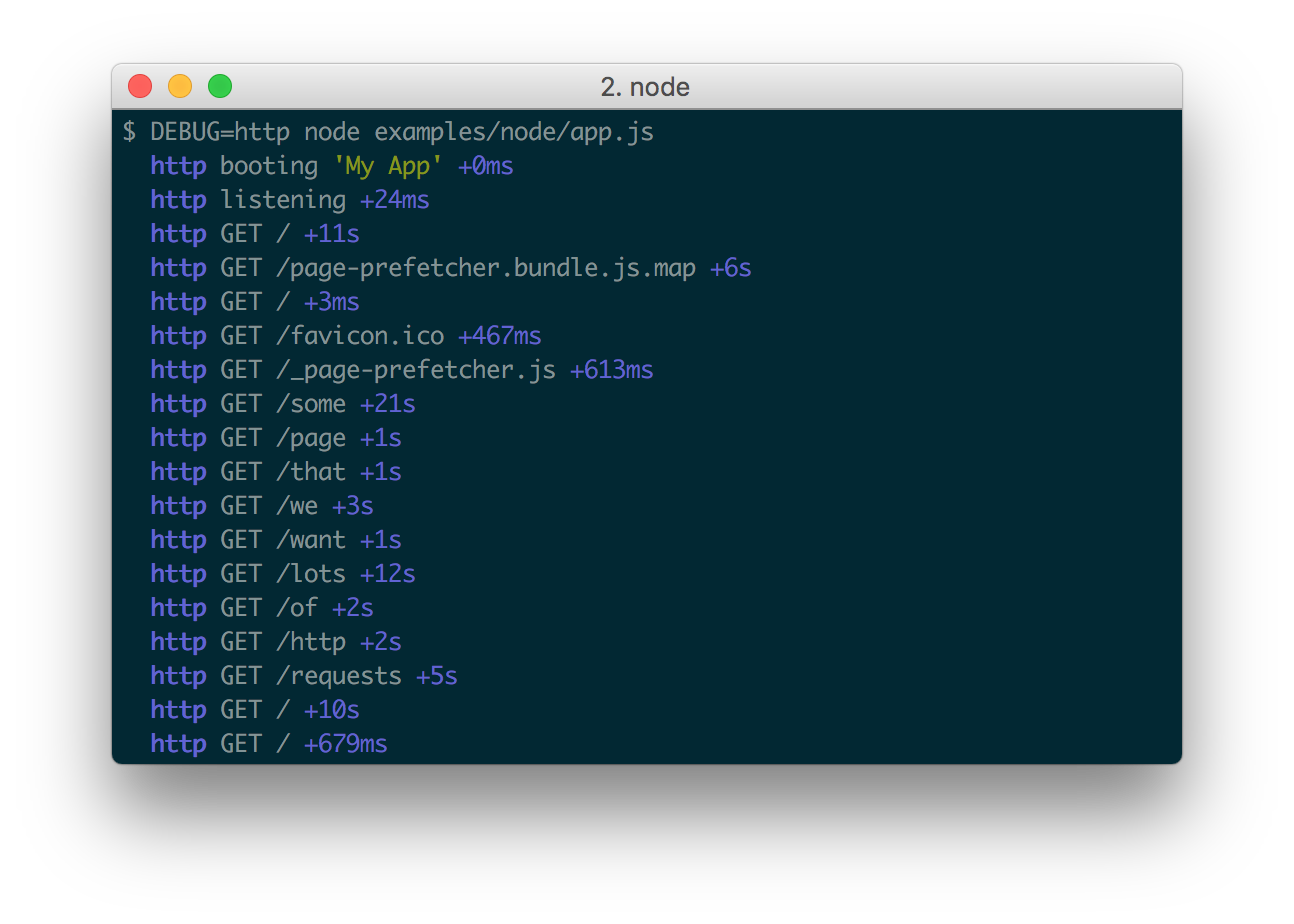
Многие программы логируют прямо в консоль, например Webpack показывает процесс и результаты сборки:
Во фронтенде файлов нет, поэтому логируют либо прямо в консоль, либо к себе в бекенды (что сложно), либо в специализированные сервисы, такие как LogRocket.
Уровни логирования
Чем больше информации выводится в логах, тем лучше и проще отладка, но когда данных слишком много, то в них тяжело искать нужное. В особо сложных случаях логи могут генерироваться с огромной скоростью и в гигантских размерах. Работать в такой ситуации нелегко. Чтобы как-то сгладить ситуацию, системы логирования вводят разные уровни. Обычно это:
Поддержка уровней осуществляется двумя способами. Во-первых, внутри самой программы расставляют вызовы библиотеки логирования в соответствии с уровнями. Если произошла ошибка, то логируем как error, если это отладочная информация, которая не нужна в обычной ситуации, то уровень debug.
Во-вторых, во время запуска программы указывается уровень логирования, необходимый в конкретной ситуации. По умолчанию используется уровень info, который используется для описания каких-то ключевых и важных вещей. При таком уровне будут выводиться и warning, и error. Если поставить уровень error, то будут выводиться только ошибки. А если debug, то мы получим лог, максимально наполненный данными. Обычно debug приводит к многократному росту выводимой информации.
Уровни логирования, обычно, выставляются через переменную окружения во время запуска программы. Например, так:
Существует и другой подход, основанный не на уровнях, а на пространствах имен. Этот подход получил широкое распространение в JS-среде, и является там основным. Фактически, он построен вокруг одной единственной библиотеки debug для логирования, которой пронизаны практически все JavaScript-библиотеки как на фронтенде, так и на бекенде.
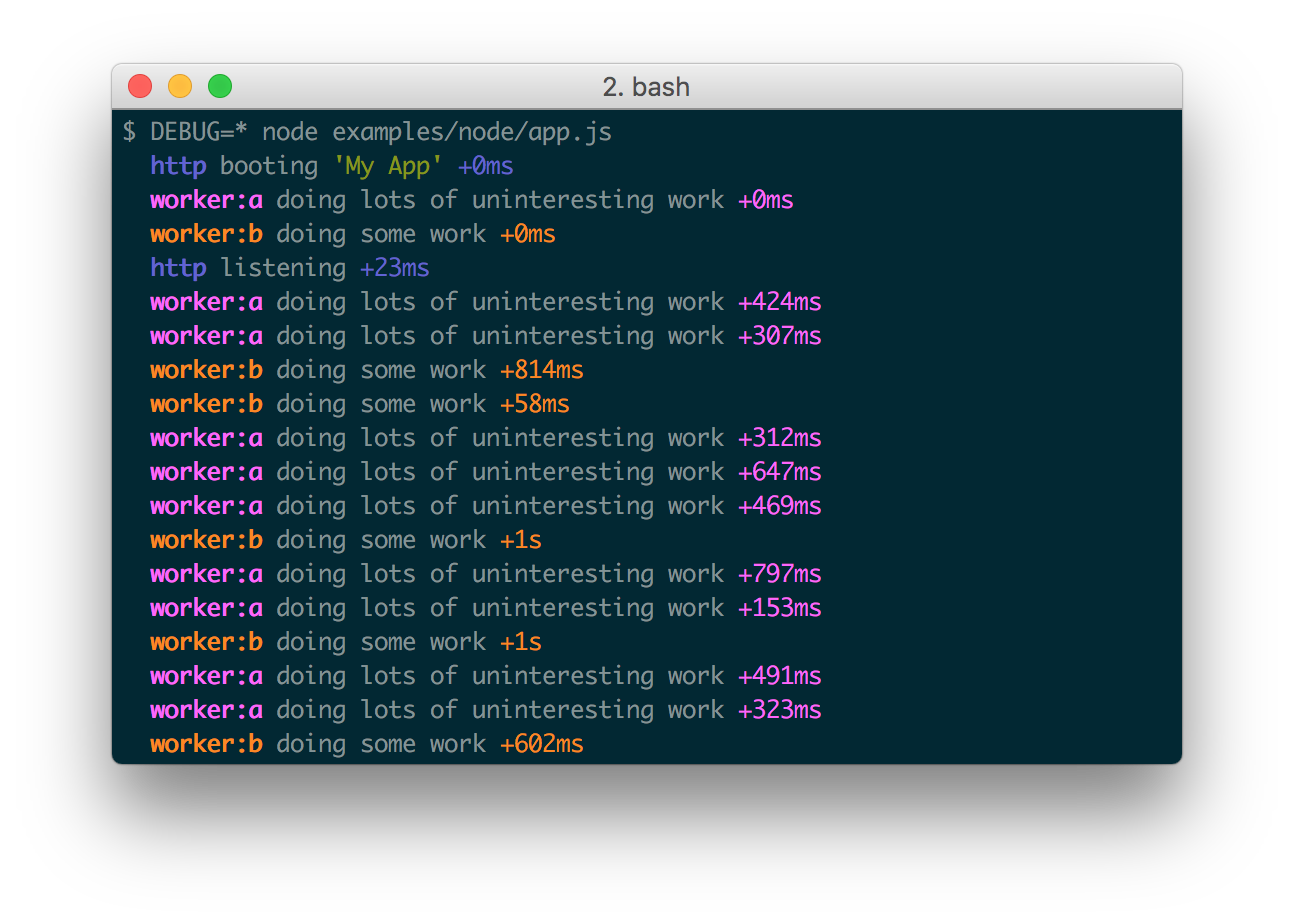
Принцип работы здесь такой. Под нужную ситуацию создается специализированная функция логирования с указанием пространства имен, которая затем используется для всех событий одного процесса. В итоге библиотека позволяет легко отфильтровать только нужные записи, соответствующие нужному пространству.
Запуск с нужным пространством:
Ротация логов
Со временем количество логов становится большим, и с ними нужно что-то делать. Для этого используется ротация логов. Иногда за это отвечает сама программа, но чаще — внешнее приложение, задачей которого является чистка. Эта программа по необходимости разбивает логи на более мелкие файлы, сжимает, перемещает и, если нужно, удаляет. Подобная система встроена в любую операционную систему для работы с логами самой системы и внешних программ, которые могут встраиваться в нее.
С веб-сайтами все еще сложнее. Даже на небольших проектах используется несколько серверов, на каждом из которых свои логи. А в крупных проектах тысячи серверов. Для управления такими системы созданы специализированные программы, которые следят за логами на всех машинах, скачивают их, складывают в заточенные под логи базы данных и предоставляют удобный способ поиска по ним.
Здесь тоже есть несколько путей. Можно воспользоваться готовыми решениями, такими как DataDog Logging, либо устанавливать и настраивать все самостоятельно через, например, ELK Stack
Как правильно писать логи (?)
Тема может и банальная, но когда программа начинает работать как то не так, и вообще вести себя очень странно, часто приходится читать логи. И много логов, особенно если нет возможности отлаживать программу и не получается воспроизвести ошибку. Наверно каждый выработал для себя какие то правила, что, как и когда логировать. Ниже я хочу рассмотреть несколько правил записи сообщений в лог, а также будет небольшое сравнение библиотек логирования для языков php, ruby и go. Сборщики логов и системы доставки не будут рассматриваться сознательно (их обсуждали уже много раз).
Есть такая linux утилита, а также по совместительству сетевой протокол под названием syslog. И есть целый набор RFC посвящённый syslog, один из них описывает уровни логирования https://en.wikipedia.org/wiki/Syslog#Severity_level (https://tools.ietf.org/html/rfc5424). Согласно rfc 5424 для syslog определено 8 уровней логирования, для которых также дается краткое описание. Данные уровни логирования были переняты многими популярными логерами для разных языков программирования. Например, http://www.php-fig.org/psr/psr-3/ определяет те же самые 8 уровней логирования, а стандартный Ruby logger использует немного сокращённый набор из 5 уровней. Несмотря на формальное указание в каких случаях должен быть использован тот или иной уровень логов, зачастую используется комбинация вроде debug/info/fatal — первый для логирования во время разработки и тестирования, второй и третий в расчёте на продакшен. Потом в какой то момент на продакшене начинает происходить что то не понятное и вдруг оказывается, что info логов не хватает — бежим включать debug. И если они не сильно нагружают систему, то зачастую так и остаются включенными в продакшен окружении. По факту остаётся два сценария, когда нужно иметь логи:
В языке Go в котором всё упрощено до предела, стандартный логер тоже прилично покромсали и оставили следующие варианты:
Я часто при написании программы с нуля повсеместно использую debug уровень для логирования с расчётом, что на продакшене будет выставлен уровень логирования info и тем самым сократится зашумлённость сообщениями. Но в таком подходе часто возникают ситуация, что логов вдруг становится не хватать. Трудно угадать, какая информация понадобиться, что бы отловить редкий баг. Возможно рационально всегда использовать по умолчанию уровень info, а в обработчиках ошибок уровень error и выше. Но если у вас сотни и больше сообщений лога в секунду, то тогда наверно есть смысл тонкой настройки между info/debug. В таких ситуациях уже имеет смысл использовать специализированные решения что бы не просаживать производительность.
Есть ещё тонкий момент, когда вы пишите что то вроде logger.debug(entity.values) — то при выставленном уровне логирования выше debug содержимое entity.values не попадёт в лог, но оно каждый раз будет вычисляться отъедая ресурсы. В Ruby логеру можно передать вместо строки сообщения блок кода: Logger.debug < entity.values >. В таком случае вычисления будут происходить только при выставленном соответствующем уровне лога. В языке Go для реализации ленивого вычисления в логер можно передать объект поддерживающий интерфейс Stringer.
После того, как разобрались с использованием уровней логов, нужно ещё уметь связывать разрозненные сообщения, особенно это актуально для многопоточных приложений или связанных между собой отдельных сервисов, когда в логах все сообщения оказываются вперемешку.
Типичный формат строки сообщения в логе можно условно разделить на следующие составные части:
Но с единым контекстом в рамках запроса возникает проблема с различными ORM, http клиентами или другими сервисами\библиотеками, которые живут своей жизнью. И ещё хорошо, если они предоставляют возможность переопределить свой стандартный логер хотя бы глобально, а вот выставить контекст для логера в рамках запроса зачастую не реально. Данная проблема в основном актуальна для многопоточной обработки, когда один процесс обслуживает множество запросов. Но например в фрэймворке Rails имеется очень тесная интеграция между всеми компонентами и запросы ActiveRecord могут писаться в лог вместе с глобальным контекстом для текущего сетевого запроса. А в языке Go некоторые библиотеки логирования позволяют динамически создавать новый объект логера с нужным контекстом, выглядит это примерно так:
После этого такой экземпляр логера можно передать как зависимость в другие объекты. Но отсутствие стандартизированного интерфейса логирования (например как psr-3 в php) провоцирует создателей библиотек хардкодить малосовместимые реализации логеров. Поэтому если вы пишите свою библиотеку на Go и в ней есть компонент логирования, не забудьте предусмотреть интерфейс для замены логера на пользовательский.
Что такое лог (log) программы.

Решая различные компьютерные задачи, можно не раз столкнуться с таким понятием как лог (с англ. log). Лог какой-то программы. Давайте попробуем разобраться что это такое и для чего это нужно.
Log (с англ. журнал). У большинства программ, которые установлены на вашем компьютере, есть этот самый журнал.
Т.е. это такой же обычный файл, который мы с вами можем создать на компьютере. Таким же образом программа работая на компьютере, может создать этот файл и вносить туда программным образом какие-то текстовые пометки.
Зачем же программе вести какие-то записи, какой-то журнал?
Дело в том, что если мы с вами будем следить за человеком, который работает на компьютере, мы можем сказать, что этот человек делал в конкретный момент времени, какие программы он запускал, какие ошибки он совершал при работе на компьютере и.т.д.
Но, если мы говорим о компьютерной программе, здесь все не так ясно. Все действия, которые производит программа, они скрыты от взгляда обычного пользователя. Они обычно происходят с такой большой скоростью событий, что человеческий глаз просто не успеет за все этим уследить.
Для того, чтобы отслеживать состояние какой-то программы. Что делала программа в какой-то конкретный момент времени, какие при этом возникали ошибки, кто с этой программой взаимодействовал и др. вопросы. Все события, которые происходили с этой программой, эта программа может записывать в специальный журнал, так называемый лог-файл.
В каждой записи содержится информация о том, что происходило с программой и когда это происходило.
Давайте подведем итог, что такое лог и зачем он нужен. Это текстовый файл, в который программа записывает какие-то события, которые с ней происходят. Благодаря этим событиям мы можем получить какую-то дополнительную информацию, что происходило с этой программой в какой-то определенный момент времени, получить отладочную информацию, чтобы легче устранить какую-то ошибку.
Надеюсь, что стало понятнее что такое лог-файл и зачем он нужен и вы теперь будете использовать этот журнал в своей работе.
Логирование как способ отлаживать код
Почему так важно запретить самому себе отладку руками?
Когда вы отлаживаете программу, то вы, сами того не осознавая, думаете что за один отладочный сеанс исправите все проблемы, возникшие в рамках этой задачи. Но наша недальновидность не хочет верить в то, что на самом деле там не одна проблема, а несколько. И за один отладочный сеанс не получится решить все эти проблемы.
Поэтому вам надо будет несколько раз запускать этот код в отладочном режиме, проводя часы отладки над одним и тем же куском кода. И это только вы один столько времени потратили над этой частью программы. Каждый член команды, кому «посчастливится» работать с этим кодом, будет вынужден прожить ту же самую историю, которую прожили вы.
Я уже не говорю о том, что люди в командах меняются, команды меняются и так далее. Человеко-часы уходят на одно и то же. Перестаньте делать это. Я серьёзно. Возьмите ответственность за других людей на себя. Помогите им не переживать тот же самый участок вашей жизни.
Проблематика: Сложно отлаживать составной код
Возможный алгоритм решения проблемы:
Таким образом, вы избавляете других людей от отладки этого кода, т.к. если возникнет проблема, то человек посмотрит ваши логи и поймёт в чём причина. Логировать стоит только важные участки алгоритма.
Давайте посмотрим пример. Вы знаете, что по отдельности все реализации интерфейсов работают (т.к. написаны тесты, доказывающие это). Но при взаимодействии всего вместе возникает некорректное поведение. Что вам нужно? Нужно логировать ответы от «корректных» интерфейсов:
В этом примере видно, как мы трассируем отдельные части алгоритма для того, чтобы можно было зафиксировать тот или иной этап его выполнения. Посмотрев на логи, станет ясно в чём причина. В реальной жизни весь этот алгоритм стоило бы разбить на отдельные методы, но суть от этого не меняется.
Всё это в разы ускоряет написание кода. Вам не нужно бежать по циклу с F10 для того, чтобы понять на какой итерации цикла возникла проблема. Просто залогируйте состояние нужных вам объектов при определённых условиях на определённой итерации цикла.
В конечном итоге вы оставляете важные логи и удаляете побочные логи, например, где вы узнавали состояние объекта на определённой итерации цикла. Такие логи не помогут вашим коллегам, т.к. вы, скорее всего, уже поняли проблему некорректного алгоритма и исправили её. Если нет, то ведите разработку в вашей ветке до тех пор, пока не найдёте в чём причина и не исправите проблему. А вот логи, которые записывают важные результаты от выполнения других алгоритмов, понадобятся всем. Поэтому их стоит оставить.
Что если нам не нужен этот мусор? В таком случае выполняйте трассировку только в рамках отладки, а затем подчищайте за собой.
Логирование как инструмент повышения стабильности веб-приложения
Авторизуйтесь
Логирование как инструмент повышения стабильности веб-приложения

техлид в Dunice
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
4–5 декабря, Онлайн, Беcплатно
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
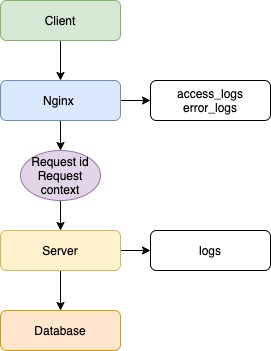
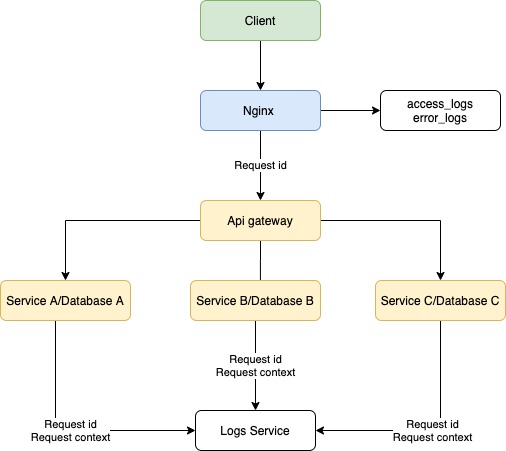
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.

В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: «GET /api/v1/users/levels HTTP/2.0», upstream: «http://127.0.0.1:5000/api/v1/users/levels», host: «app.dunice-testing.com»
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
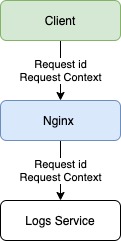
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.
При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.
В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.
Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.