Эта статья, еще одна попытка переосмысления метапрограммирования, которые я периодически предпринимаю. Идея каждый раз уточняется, но в этот раз удалось подобрать достаточно простых и понятных примеров, которые одновременно очень компактны и иллюстративны, имеют реальное полезное применение и не тянут за собой библиотек и зависимостей. В момент публикации я буду докладывать эту тему на ОдессаJS, поэтому, статью можно использовать, как место для вопросов и комментариев к докладу. Формат статьи дает возможность более полно изложить материал, чем в докладе, слушатели которого, не освобождаются от прочтения.
UPD: Обновленная видеоверсия статьи на Youtube (лекция записана в Киевском политехническом институте 18 апреля 2019 года в рамках курса «100 видео-лекций по программированию»):
Что такое моделирование?
Понятие метапрограммирования тесно связано с моделированием, потому, что сам метод подразумевает повышение уровня абстракции моделей за счет вынесения метаданных из модели. В результате чего мы получаем метамодель и метаданные. Во время раннего или позднего связывания (при компиляции, трансляции или работе программы) мы из метамодели и метаданных опять получаем модель автоматическим программным способом. Созданная модель может меняться многократно, без изменения программного кода метамодели, а часто, даже без остановки программы.
Удивительно, но человек способен успешно решать задачи, сложность которых превышает возможности его памяти и мышления, при помощи построения моделей и абстракций. Точность этих моделей определяет их пользу для принятия решений и выработки управляющих воздействий. Модель всегда не точна и отображает только малую часть реальности, одну или несколько ее сторон или аспектов. Однако, в ограниченных условиях использования, модель может быть неотличимой от реального объекта предметной области. Есть физические, математические, имитационные и другие виды моделей, но нас будут интересовать, в первую очередь, информационные модели данных и модели программной логики. Парадигмы программирования, это и есть модели программной логики, например, императивное, декларативное, функциональное, событийное. Нашей же задачей, как программистов, можем обозначить не написание кода, а, в первую очередь, построение моделей и абстракций. Таким образом, метапрограммирование позволяет нам поднять уровень абстракции в моделях, что делает их универсальнее, а нашу работу значительно интереснее.
Что такое метапрограммирование?
Метапрограммирование — это не что-то новое, вы всегда его использовали, если имеете опыт практического программирования на любом языке и в любой прикладной сфере применения. Все парадигмы программирования, по крайней мере, для ЭВМ фоннеймановской архитектуры, так или иначе наследуют основные принципы моделирования от этой архитектуры. Самый важный принцип архитектуры фон Неймана, это смешивание данных и команд, определяющих логику обработки данных, в одной универсальной памяти. То есть, отсутствие принципиальной разницы между программой и данными. Это дает множество последствий, во-первых, машине нужно различать где команда, а где число и какая его разрядность и тип, где адрес, а где массив, где строка, а где длина этой строки, в какой кодировке она представлена и т.д., вплоть до сложных конструкций, как объекты и области видимости. Все это определяется метаданными, без метаданных вообще ничего не происходит в языках программирования для фоннеймановской архитектуры. Во-вторых, программа получает доступ к памяти, в которой хранится она сама, другие программы, их исходный код, и может обрабатывать код как данные, что позволяет делать трансляцию и интерпретацию, автоматизированное тестирование и оптимизацию, интроспекцию и отладку, динамическое связывание и многое другое.
Определения: Метаданные — это данные, о данных. Например тип переменной, это метаданные переменной, а названия и типы параметров функции, это метаданные этой функции. Интроспекция — механизм, позволяющий программе во время работы получать метаданные о структурах памяти, включая метаданные о переменных и функциях, типах и объектах, классах и прототипах. Динамическое связывание (или позднее связывание) — это обращение к функции через идентификатор, который превращается в адрес вызова только на этапе исполнения. Метамодель — модель высокого уровня абстрактности, из которой вынесены метаданные, и которая динамически порождает конкретную модель при получении метаданных. Метапрограммирование — это парадигма программирования, построенная на программном изменении структуры и поведения программ.
Итак, нельзя начать применять метапрограммирование с сегодняшнего дня, но можно осознать, проанализировать и применять инструмент осознанно. Это парадоксально, но многие стремятся разделить данные и логику, используя фоннеймановскую архитектуру. Между тем, их следует не разделять, а правильным способом объединить. Есть и другие архитектуры, например, аналоговые решатели, цифровые сигнальные процессоры (DSP), программируемые логические интегральные схемы (ПЛИС), и другие. В этих архитектурах, вычисления производятся не императивно, то есть, не последовательностью операций обработки, заданной алгоритмом, а параллельно работающими цифровыми или аналоговыми элементами, в реальном времени реализующими множество математических и логических операций и имеющими уже готовый ответ в любой момент. Это аналоги реактивного и функционального программирования. В ПЛИС коммутация схем происходит при перепрограммировании, а в DSP императивная логика управляет мелкой перекоммутацией схем в реальном времени. Метапрограммирование возможно и для систем с неимперативной или гибридной логикой, например, я не вижу причины, чтобы одна ПЛИС не могла перепрограммировать другую.
Теперь рассмотрим обобщенную модель, показанную на схеме программного модуля. Каждый модуль обязательно имеет внешний интерфейс и программную логику. А такие компоненты, как конфигурация, состояние и постоянная память, могут как отсутствовать, так и играть основную роль. Модуль получает запросы от других модулей, через интерфейс и отвечают на них, обмениваясь данными в определенных протоколах. Модуль посылает запросы к интерфейсам других модулей из любого места своей программной логики, поэтому входящие связи объединены интерфейсом, а исходящие рассеяны по телу модуля. Модули входят в состав более крупных модулей и сами строятся из нескольких или многих подмодулей. Обобщенная модель подходит для модулей любого масштаба, начиная от функций и объектов, до процессов, серверов, кластеров и крупных информационных систем. При взаимодействии модулей, запросы и ответы — это данные, но они обязательно содержат метаданные, которые влияют на то, как модуль будет обрабатывать данные или как он указывает другому модулю обрабатывать данные.Обычно, набор метаданных ограничивается тем, что протокол обязательно требует для считывания структуры передаваемых данных. В двоичных форматах метаданных меньше, чем в синтаксических форматах, применяемых для сериализации данных (как, например, JSON и MIME). Информация о структуре двоичных форматов, по большей части находится у принимающего модуля в виде struct (структур для C, C++, C# и др. языках) или «зашита» в логику интерпретирующего модуля другим способом. Разделить, где заканчивается обработка данных с использованием метаданных и начинается метапрограммирование, достаточно сложно. Условно, можно определить такой критерий: когда метаданные не просто описывают структуры, а повышают абстракцию программного кода в модуле, интерпретирующем данные и метаданные, вот тут начинается метапрограммирование. Другими словами, когда происходит переход от модели, к метамодели. Основным признаком такого перехода, является расширение универсальности модуля, а не расширение универсальности протокола или формата данных. На схеме справа показано, как из данных выделяются метаданные и заходят в модуль, меняя его поведение при обработке данных. Таким образом, абстрактная метамодель, содержащаяся в модуле на этапе исполнения превращается в конкретную модель.
Прежде чем приступить к рассмотрению техник и приемов метапрограммирования, я бы хотел привести одну цитату, которую всегда привожу, если речь заходит о метапрограммировании. Она наталкивает на мысль, что метапрограммирование, это отражение такого фундаментального закона, на котором основаны вообще все кибернетические системы. То есть системы «живые», в которых происходит управление, коррекция поведения и параметров деятельности при помощи регулирования с обратной связью. Это позволяет системам воспроизводить свое состояние и структуру в разных условиях и с разными модификациями, сохраняя существенное и варьируя поведение, в том числе и порождая производные системы для этого.
«Вот что я имею в виду под производящим произведением или, как я называл его в прошлый раз, «opera operans». В философии существует различение между «natura naturata» и «natura naturans» – порожденная природа и порождающая природа. По аналогии можно было бы образовать – «cultura culturata» и «cultura culturans». Скажем, роман «В поисках утраченного времени» строится не как произведение, а как «cultura culturans» или «opera operans». Это и есть то, что у греков называлось Логосом.» // Мераб Мамардашвили «Лекции по античной философии»
Как работает метапрограммирование?
Для чего нам нужно метапрограммирование?
Пример 1
Рассмотрим самый простой пример выделения метаданных из модели и построения метамодели (см. пример на github). Сначала определим задачу примера: есть массив строк, нужно отфильтровать их по определенным правилам: длина подходящих строк должна быть от 10 до 200 символов включительно, но исключая строки длиной от 50 до 65 символов; строка должна начинаться на «Mich» и не начинаться на «Abu»; строка должна содержать «V» и не содержать «Lev»; строка должна заканчиваться на «ov» и не должна заканчиваться на «iov». Определим данные для примера:
Реализуем логику без метапрограммирования:
Выделяем метаданные из модели решения задачи и формируем их в отдельную структуру:
Преимущество решения задачи при помощи метапрограммирования очевидно, мы получили универсальный фильтр строк, с конфигурируемой логикой. Если фильтрацию нужно провести не один раз, а несколько, на одной и той же конфигурации метаданных, то метамодель можно обернуть в замыкание и получить кеширование индивидуированной функции для ускорения работы.
Пример 2
Второй пример мы будем сразу писать при помощи метапрограммирования (см. пример на github), потому, что если я представлю себе его размеры в размеры в говнокоде, то мне становится страшно. Описание задачи: нужно делать HTTP GET/POST запросы с определенных URLов или загружать данные из файлов и передавать полученные или считанные данные через HTTP PUT/POST на другие URLы и/или сохранять их в файлы. Таких операций будет несколько и их нужно производить с различными интервалами времени. Задачу можно описать в виде метаданных следующим образом:
Решаем задачу при помощи метапрограммирования:
Видим, что мы написали «красивые столбики» и можно произвести еще одну свертку, вынеся метаданные уже внутри метамодели. Как будет выглядеть метамодель, конфигурируемая метаданными:
Замечу, что в примере используются замыкания для индивидуации тасков.
Пример 3
Во втором примере используется функция duration, возвращающая значение в миллисекундах, которую мы не рассмотрели. Эта функция интерпретирует значение интервала, заданное как строка в формате: «Dd Hh Mm Ss», например «1d 10h 7m 13s», каждый компонент которого опциональный, например «1d 25s», если функция получает число, то она его и отдает, это нужно для удобства задания метаданных, если мы задаем интервал напрямую в миллисекундах.
Теперь реализуем интерпретацию, конфигурируемую метаданными:
Пример 4
Теперь посмотрим на метапрограммирование с интроспекцией, примененное для интеграции модулей. Сначала определим удаленные методы на клиенте при помощи такой структуры и покажем, как использовать данные вызовы при написании прикладной логики:
Теперь проведем инициализацию из метаданных, получаемых из другого модуля и покажем, что прикладная логика не изменилась:
В слудующем примере мы создадим локальный источник данных с таким же интерфейсом, как и у удаленного и покажем, что прикладная логика так же не изменилась:
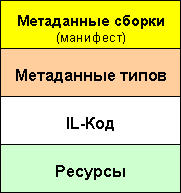
Метаданные — это данные в двоичном формате с описанием программы, хранящиеся либо в переносимом исполняемом (PE) файле среды CLR, либо в памяти. Когда код компилируется в PE-файл, метаданные помещаются в одну часть файла, а код преобразуется в MSIL и помещается в другую часть файла. В метаданных описываются все типы и члены, определенные или используемые в модуле или сборке. При исполнении кода среда выполнения загружает метаданные в память и обращается к ним для получения сведений о классах, членах, наследовании и других элементах кода.
В метаданных в независимом от языка виде описываются все типы и члены, определенные в коде. В метаданных хранятся следующие сведения.
Удостоверение (имя, версия, язык и региональные параметры, открытый ключ).
Другие сборки, от которых зависит данная сборка.
Необходимые разрешения безопасности.
Имя, видимость, базовый класс и реализованные интерфейсы.
Члены (методы, поля, свойства, события, вложенные типы).
Преимущества метаданных
Файлы с самоописанием.
Модули среды CLR и сборки обладают свойством самоописания. Метаданные модуля содержат все необходимое для взаимодействия с другим модулем. Метаданные автоматически предоставляют функциональные возможности IDL для модели СОМ, в связи с чем один и тот же файл может использоваться и для определения, и для реализации. Модули и сборки среды выполнения даже не требуют регистрации в операционной системе. Благодаря этому описания, используемые средой выполнения, всегда отражают фактический код в скомпилированном файле, что повышает надежность приложения.
Взаимодействие языков и упрощение разработки на основе компонентов
Метаданные содержат полные сведения о скомпилированном коде, необходимые для наследования класса из PE-файла, написанного на другом языке. Можно создать экземпляр класса, написанного на любом другом управляемом языке (это может быть любой язык, обращающийся к среде CLR), не беспокоясь о явной упаковке или настройке кода взаимодействия.
Метаданные и структура PE-файла
Таблицы и кучи метаданных
Каждая таблица метаданных содержит сведения об элементах программы. К примеру, в одной таблице метаданных описываются классы в коде, в другой — поля и так далее. Если в коде используется десять классов, таблица классов будет содержать десять строк, по одной для каждого класса. Таблицы метаданных ссылаются на другие таблицы и кучи. Например, таблица метаданных для классов ссылается на таблицу методов.
В метаданных сведения также хранятся в четырех структурах кучи — в куче строк, больших двоичных объектов, пользовательских строк и идентификаторов GUID. Все строки, используемые для названия типов и членов, хранятся в куче строк. Например, в таблице методов не хранится имя конкретного метода, но содержится ссылка на имя этого метода, находящееся в куче строк.
Лексемы метаданных
Каждая строка любой таблицы метаданных уникально идентифицируется в разделе MSIL PE-файла с помощью лексемы метаданных. Лексемы метаданных по своей сути похожи на указатели, сохраненные в MSIL, которые ссылаются на определенную таблицу метаданных.
Лексема метаданных является четырехбайтным числом. Старший байт указывает на таблицу метаданных, к которой относится данная лексема (метод, тип и т. д.). Остальные три байта определяют строку в таблице метаданных, которая соответствует описываемому программному элементу. Если определить метод в языке C# и скомпилировать его в PE-файл, то в разделе MSIL PE-файла может появиться следующая лексема метаданных:
Старший байт ( 0x06 ) указывает, что это лексема MethodDef. Три младших байта ( 000004 ) отсылают среду CLR к четвертой строке таблицы MethodDef для получения сведений с описанием определения метода.
Метаданные внутри PE-файла
После компиляции программы для среды CLR она преобразуется в PE-файл, состоящий из трех разделов. В следующей таблице описано содержание каждого раздела.
Раздел PE-файла
Содержание раздела PE-файла
Заголовок PE
Индекс основных разделов PE-файла и адрес точки входа.
Среда выполнения использует эти сведения для определения файла как PE-файла и определения начала выполнения при загрузке программы в память.
Инструкции MSIL
Инструкции промежуточного языка MSIL, реализующие пользовательский код. Многие инструкции MSIL сопровождаются лексемами метаданных.
Метаданные
Таблицы и кучи метаданных Среда выполнения использует этот раздел для записи сведений о каждом типе и члене в коде. Этот раздел также содержит пользовательские атрибуты и сведения о безопасности.
Использование метаданных во время выполнения
При запуске кода среда выполнения загружает модуль в память и обращается к метаданным за сведениями об этом классе. После загрузки среда выполнения проводит подробный анализ потока кода MSIL для метода, чтобы преобразовать его в инструкции машинного кода (выполнение которых осуществляется максимально быстро). В среде выполнения для преобразования инструкций MSIL в исходный машинный код используется JIT-компилятор. Преобразование выполняется по одному методу за раз по мере необходимости.
JIT-компилятор считывает код MSIL для всего метода, проводит тщательный анализ и создает эффективный набор машинных инструкций для этого метода. В строке IL_000d появляется маркер метаданных для метода Add ( /* 06000003 */ ), и среда выполнения использует этот маркер для обращения к третьей строке таблицы MethodDef.
Строка
Относительный виртуальный адрес (RVA)
Неявные флаги
Флаги
name
(Указывает на кучу строк.)
Сигнатура (указывает на кучу больших двоичных объектов)
1
0x00002050
IL
Управляемый
Public
.ctor
.ctor (конструктор)
2
0x00002058
IL
Управляемый
Public
ReuseSlot
Главная ветвь
Строка
3
0x0000208c
IL
Управляемый
Public
ReuseSlot
Add
int, int, int
В каждом столбце таблицы содержатся важные сведения о коде. Значения в столбце RVA позволяют среде выполнения вычислить начальный адрес в памяти кода MSIL, определяющего этот метод. Столбцы Неявные флаги и Флаги содержат битовые маски, описывающие метод (например, является ли метод общим или закрытым). Столбец Имя содержит указатель имени метода из кучи строк. Столбец Сигнатура содержит указатель определения сигнатуры метода в куче больших двоичных объектов.
Среда выполнения вычисляет нужный относительный адрес из столбца RVA в третьей строке и возвращает этот адрес JIT-компилятору, который затем переходит к новому адресу. JIT-компилятор продолжает обрабатывать код MSIL по новому адресу до тех пор, пока не найдет другую лексему метаданных, и затем процесс повторяется заново.
Благодаря метаданным среда выполнения имеет доступ к любым сведениям, необходимым для загрузки кода пользователя и его преобразования в инструкции машинного кода. Таким образом, метаданные позволяют использовать файлы с самоописанием и — совместно с системой общих типов — межъязыковое наследование.
Метаданные типов. Назначение и особенности использования. Необходимость в метаданных. Способы получения информации о типе
Связанные темы
Поиск на других ресурсах:
1. Что такое метаданные типов? Пример, демонстрирующий необходимость использования метаданных типов
Метаданные типов широко используются при взаимодействии между программами. Можно перечислить следующие направления использования метаданных типов:
Рисунок 1. Взаимодействие между клиентом и сервером с помощью метаданных совместной сборки
2. Типы, которые описываются метаданными
3. Способы получения информации о типе
Информацию о типах можно получить следующими способами:
Чтобы получить метаданные программным путем можно использовать один из трех способов:
В простейшем случае, метод System.Object.GetType() применяется к экземпляру класса по следующему образцу
Результат выполнения программы
где SomeType – некоторый тип.
В наиболее простом случае для определения информации о типе MyClass применение typeof() может быть, например, таким
Пример. На примере класса Complex (смотрите предыдущий пример) получается перечень конструкторов этого класса. Ниже приведен сокращенный код решении задачи.
Результат выполнения программы
Метод GetType() имеет несколько перегруженных реализаций, одна из которых имеет следующую общую форму
Автор: Андрей Мартынов The RSDN Group Источник: RSDN Magazine #2
Опубликовано: 14.03.2003 Исправлено: 10.12.2016 Версия текста: 1.1.1
Что такое метаданные и зачем они нужны?
Для того, чтобы различные части программ могли взаимодействовать друг с другом, им необходимо обмениваться информацией о предоставляемых ими возможностях, и о том, каким образом эти возможности использовать. Например, если программа использует статическую библиотеку, к библиотеке обычно прилагается заголовочный файл, описывающий экспортируемые данные, процедуры и структуру типов. Другой пример – DLL. Чтобы использовать её в своей программе, вы, скорее всего, будете использовать соответствующие заголовочный файл и библиотеку импорта. Ещё один пример – COM-компонент. Описание его интерфейса обычно хранится в idl-файле или в виде специальных данных, в виде библиотеки типов. Все эти дополнительные файлы и данные, описывающие программные компоненты, называют метаданными.
Приставка мета подчеркивает что это – данные, описывающие другие данные. «Данные о данных».
Доступ к метаданным сборки является необходимым и достаточным условием доступа к содержащимся в ней типам.
Доступ к метаданным могут получить любые программные компоненты и любые инструменты программирования. Так, компилятор во время компиляции сборки использует информацию о зависимостях между сборками и проверяет соответствие используемых типов, извлекая нужную для этого информацию из метаданных. Инструменты программирования (в том числе среда программирования – IDE), извлекают информацию о типах и в удобном виде представляют структуру классов, а также предоставляют справочную информацию по ним (ObjectBrowser, IntelliSense). Набор утилит, обеспечивающих взаимодействие с COM-компонентами (Regasm, Tlbexp, Tlbimp), целиком опираются в своей работе на метаданные.
ПРИМЕЧАНИЕ
ПРИМЕЧАНИЕ
Метаданные содержат подробнейшую информацию о каждом типе: его имя, типы и имена его полей, описание свойств и методов со всеми их параметрами и возвращаемыми значениями. Здесь же хранится информация о доступности (видимости) всех членов класса и об их атрибутах. Метаданные хранят не только информацию о интерфейсе экспортируемых классов. Такие детали реализации, как структура защищённых полей, описания защищённых методов и других компонентов, также могут быть извлечены из метаданных.
.Net позволяет создавать новые сборки во время исполнения программы, наполнять эти сборки новыми классами, реализовывать код методов этих классов.
1. RTTI ( r un t ime t ype i dentification) в языке С++.
Механизм, встроенный в язык С++. Метаданные основаны на указателях на таблицы виртуальных методов и потому работают только с полиморфными типами. RTTI позволяет выяснять родственные отношения между типами и производить безопасные нисходящие приведения типов. Как правило, имеется возможность опционального использования RTTI. Сам факт применения данного средства в языке C++ вызывает бурные споры.
2. CRuntimeClass в библиотеке MFC.
Независимый от RTTI механизм. Метаданные хранятся как статические данные классов и обеспечивают возможность динамического создания экземпляров класса и сериализации.
3. Механизм Reflection в языке Java.
Глубоко встроенный в язык механизм. Механизм используется в реализации самих языковых конструкций. Имеются возможности исследования структуры типов во время исполнения, динамического создания объектов и вызова методов.
4. IDL – язык описания интерфейсов (Interface Definition Language)
5. Библиотеки типов (Type Libraries) в технологии программирования COM.
6. WSDL – язык описания Web-служб (Web Services Description Language). WSDL представляет собой стандарт XML-документов, предназначенный для описания возможностей Web-службы, включая формат принимаемых и передаваемых сообщений, имена и типы методов и функций, реализуемых службой, а также используемые протоколы обмена данными.
Получение информации о типе
Более того, с его помощью можно динамически создавать экземпляры описываемого им типа (класса), а также исполнять методы и работать со свойствами полученного объекта.
Поэтому работа с типом начинается с получения соответствующего экземпляра класса Type.
Получение экземпляра класса Type
Получить экземпляр класса Type можно несколькими способами. Выбор способа зависит от условий задачи, и от того, какой информацией о типе вы располагаете при разработке программы (на момент компиляции).
1. Простейший случай – когда тип определён в вашей программе, или если при компиляции указана ссылка на сборку, содержащую данный тип. В этом случае экземпляр класса Type можно получить посредством операции typeof (все примеры в этой статье написаны на C#) :
3. Имеется возможность перебрать все типы, определённые в сборке, и найти нужный класс по каким-либо критериям или выполнить необходимые действия со всеми классами в сборке. Вот так, например, можно напечатать имена всех типов, содержащихся в текущей сборке-приложении:
4. Возможна ситуация, когда во время написания программы тип объектов, с которыми предстоит работать, неизвестен. Способ получения имени класса во время исполнения программы может быть самый разным. Например, вы запрашиваете его у пользователя, или считываете при старте программы из файла конфигурации. В этом случае указанием только имени типа не обойтись. Необходимо указать, в какой именно сборке содержится данный тип. Эту сборку потом необходимо загрузить динамически.
Динамическая загрузка сборок
Приложение может загружать сборки из:
Первые два способа идентифицируют сборку по имени.
Имя сборки содержит, помимо собственно имени, также ещё и версию сборки, информацию о локализации (Culture) и открытый ключ сборки (PublicKeyToken). Вот пример имени сборки:
Полное имя (т.е. содержащее все компоненты имени) однозначно идентифицирует сборку и по нему можно будет её загрузить.
Имя сборки может быть как полным, так и частичным. Частичное имя позволяет задействовать специальный механизм версионности сборок. Метод LoadWithPartialName класса Assembly загружает сборку по частичной информации о ней.
В данном случае передано только имя сборки. В соответствии с политикой версий будет выбрана и загружена наиболее подходящая сборка. Этот способ более гибок, т.к. позволяет управлять загрузкой сборок, задавая или опуская различные параметры. Например, если вы укажете номер версии, то сборки другой версии (пусть даже более поздней!) использоваться не будут. А если явно задать культуру, то в будущем не нужно будет беспокоиться, что приложение случайно подключит новую версию сборки, не поддерживающую указанную культуру.
Динамическая загрузка сборок из каталога приложения не требует указания полного имени сборки, достаточно краткого имени.
Функции Assembly.Load и Assembly.LoadWithPartialName при выборе подходящей сборки первым делом просматривают каталог приложения, отдавая предпочтение private-сборкам.
ПРИМЕЧАНИЕ
Размещение сборок в каталоге приложения считается предпочтительным. Такой способ помогает предотвратить взаимное влияние приложений – «кошмар DLL».
Динамическая загрузка сборки по полному пути к файлу позволяет загрузить любую сборку в системе (не только private- или из GAC’а).
Однако этот способ недостаточно гибок и вряд ли стоит его широко применять.
Динамическая загрузка типов
Теперь, когда сборка загружена, можно извлечь из неё информацию о типе. Для этого необходимо использовать так называемое «квалифицированное имя типа» ( Assembly Qualified Type Name ). Квалифицированное имя типа состоит из двух частей: полного имени типа и полного или частичного имени сборки. Для получения описания метаданных некоторого типа его квалифицированное имя передаётся в статический метод GetType класса Type. В случае успеха этот метод возвращает экземпляр класса Type.
В данном случае загрузка типа проведена в три этапа. Сначала загружена сборка, затем получено её полное имя, и только потом получен объект Type. Эти этапы можно объединить. Если вы знаете полное имя сборки, можно использовать его для составления квалифицированного имени типа, которое можно напрямую передать методу Type.GetType().
Исследование типа
Имея в руках объект Type, можно начинать исследовать структуру типа, который он описывает (перебирать поля, методы, события, свойства, вложенные типы. ).
Характеристики типа как целого
Класс Type содержит больше трёх десятков методов, позволяющих получать информацию об описываемом типе. Так можно узнать какое-либо свойство типа или наличие (и значение) определённого атрибута, выяснить принадлежность типа к некоторому семейству. Вот некоторые их этих методов:
Вот, например, как можно с помощью этих свойств получить описание семейства типа:
Члены класса
Ниже перечислены основные семейства методов класса Type, используемые для получения информации о членах класса.
Давайте рассмотрим пример получения информации обо всех конструкторах класса.
В этом примере вы можете видеть, каким способом извлекается информация о параметрах методов. Каждая структура данных, отвечающая за методы-члены (EventInfo, MethodInfo, ConstructorInfo), имеет метод GetParameters(), возвращающий массив элементов типа ParameterInfo. Каждый элемент этого массива описывает отдельный параметр метода: его тип, имя, значение по умолчанию, направление передачи данных (in/out) и др.
Надеюсь, я убедил вас, что в получении информации о типах нет ничего сложного. Информации этой много, и она очень подробна, но извлекать её довольно просто (особенно когда точно знаешь, что именно тебе нужно).
Утилита для исследования типов в сборке
Написать утилиту, во многом повторяющую функциональность ildasm.exe по исследованию типов, не составляет большого труда. Среди исходных текстов примеров, прилагающихся к этой статье, вы найдёте такую программу.
Исследование объекта
Итак, предположим, мы изучили класс досконально. Теперь мы знаем о нём всё. Как же воспользоваться этим знанием, если имеется готовый экземпляр класса? Как прочитать его поля, как получить значения его свойств, как вызывать его методы? Давайте для начала научимся читать поля и свойства объекта.
ПРИМЕЧАНИЕ
— Дело в том, что класс, экземпляр которого мы хотим создать и исследовать, не известен в момент написания программы. Более того, он не только не известен, он даже ещё и не написан! Его напишут после того, как программа будет скомпилирована!
А этот выводит список свойств объекта:
Трассировка полей объекта
В процессе отладки иногда возникает необходимость запротоколировать состояние некоторых важных для работы программы классов. Написание кода протоколирования полей – не самая интересная работа, да и времени она может отнять много. К тому же может оказаться, что самое интересное поле класса всё-таки осталось не выведенным, а ситуация была трудновоспроизводимой. В таком случае можно порекомендовать вывести просто все (!) поля класса, тем более, что механизм reflection позволяет делать это одной строчкой кода.
ПРИМЕЧАНИЕ
— Не спорю. Действительно, ToString позволяет точно отрегулировать, как и какие данные класса выводить. Но мне кажется, что если это делается только для отладочных целей, поддержка методов ToString в сотнях (а может и в тысячах) классов – дело очень хлопотное. Гораздо проще однажды написать функцию, подобную приведённой ниже, и использовать её при необходимости.
Вы легко сможете модифицировать код этой процедуры, если потребуется изменить формат вывода или выводить дополнительно свойства класса или другие его компоненты.
ПРИМЕЧАНИЕ
Хочу обратить ваше внимание на имеющиеся здесь подводные камни. Посмотрим на поле типа string. Тип string имеет статическое поле Empty того же типа string. Поэтому, выводя поле Empty, вы снова обнаружите у него статическое поле Empty, выводя которое вы снова обнаружите статическое поле Empty. короче, получается бесконечная рекурсия. Выход простой – не выводить второй раз статические поля, а ссылаться на первый вывод этих полей.
Второй камушек связан с взаимными ссылками объектов друг на друга. В последнем примере класс Class1 имеет ссылку на класс Data1, а тот, в свою очередь, имеет ссылку на Class1. Если не предпринять специальных мер, то опять получится бесконечная рекурсия. Меры примерно такие же, как в предыдущем случае – запоминаем все выведенные объекты и не выводим их второй раз.
ПРИМЕЧАНИЕ
Динамическое создание объекта и вызов методов
Итак, мы умеем получать исчерпывающую информацию о типе, который ещё неизвестен в момент компиляции. На основе этой информации, имея экземпляр этого типа, мы умеем получать значения его полей и свойств. Для полного владения ситуацией нам остаётся только научиться создавать экземпляры этих типов, а потом ещё и вызывать их методы.
Создание объекта по его типу
При создании объекта вызывается его конструктор. Если вас устраивает вариант создания объекта с вызовом конструктора без аргументов (конструктора по умолчанию), то задача решается очень просто. Например, вот так:
ПРИМЕЧАНИЕ
Здесь приведён вариант создания объекта с использованием конcтруктора с параметрами. Составлен массив из параметров и передан в Activator.CreateInstance. Среди возможного множества конструкторов будет использован тот, который имеет в точности то же количество параметров и те же типы (и в том же порядке!), что и в переданном массиве параметров.
ПРИМЕЧАНИЕ
Наряду с классом Activator способностью создавать объекты по их типу обладают классы Assembly, AppDomain и некоторые другие. У них тоже есть методы CreateInstance, работа с которыми ведётся подобным образом.
Динамический вызов методов
На самом деле мы только что уже занимались динамическим вызовом методов. С конструкторами, по крайней мере, разобрались. Вызов остальных методов производится без помощи дополнительных классов типа Activator. Этим занимается сам класс Type.
Если вызываемый метод перегружен, будет вызван тот вариант метода, который имеет те же типы параметров, причем в том же порядке, что и типы элементов переданного массива параметров.
Использование интерфейсов
Для вызова методов динамически созданного объекта можно применять гораздо более удобный и эффективный способ. Правда, этот способ работает, только если вы знаете, что объект реализует известный вам на момент компиляции интерфейс.
Очевидно, что эффективность вызова метода динамически созданного объекта через интерфейс гораздо выше, чем через InvokeMember, ведь это обычный вызов виртуального метода. Поэтому, если есть такая возможность, лучше использовать интерфейсы.
Для получения ссылки на интерфейс ICloneable здесь применяется операция as языка C#. Эта операция возвращает ссылку на интерфейс, если он реализован объектом. Если объект не поддерживает данный интерфейс, будет возвращена пустая ссылка ( null ). Ниже будут подробнее рассмотрены другие способы динамического приведения типов.
Позднее связывание
Ну вот, теперь можно сказать, что мы умеем работать с типами, определяемыми в момент исполнения, почти столь же свободно, как и с типами, известными нам на момент компиляции. (Если я и преувеличил, то совсем чуть-чуть. 8-). Теперь мы вправе заслуженно насладиться плодами вновь освоенных технологий. Предлагаю вам в качестве небольшой передышки рассмотреть позднее связывание.
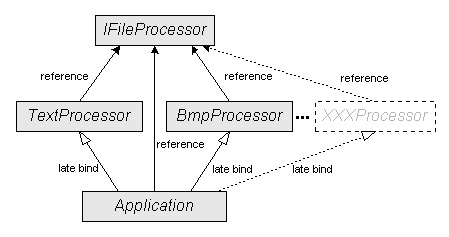
Традиционная постановка задачи позднего связывания: предположим, у нас есть программа, позволяющая выполнять обработку каких-либо файлов. Для обработки используются классы, реализующие интерфейс FileProcessor. Список типов обрабатываемых программой файлов и соответствующих им классов-обработчиков постоянно пополняется. Сборки, содержащие новые классы-обработчики, помещаются в отдельную папку, а программа-обработчик файлов должна уметь использовать всё новые и новые классы-обработчики без перекомпиляции.
Интерфейс класса-обработчика будет иметь единственную функцию, определяющую, может ли данный класс обработать данный файл. Поместим интерфейс в отдельную сборку. На неё будут ссылаться конкретные классы-обработчики.
Теперь определим пару классов обработчиков. Один из них будет работать с текстовыми файлами, второй – с картинками в формате ВMP. При этом каждый будет реализовывать интерфейс-обработчик, и будет помещён в отдельную сборку, ссылающуюся на сборку с интерфейсом (см. рис.3).
В самом приложении, осуществляющем позднее связывание с классами-обработчиками, для вас уже почти ничего нового нет. Здесь просто загружаются все сборки из каталога приложения. Затем запрашиваются все типы из каждой сборки, и среди типов ищутся те, что унаследованы от абстрактного класса-обработчика. После того, как нужный тип найден, создаётся его экземпляр и вызывается метод IsSupport.
Теперь, если появится необходимость обрабатывать файлы, например, формата VRML, не потребуется дорабатывать и перекомпилировать приложение. Достаточно будет разработать соответствующий класс-обработчик VRMLProcessor и поместить его в ту же папку, что и остальные классы-обработчики.
Динамическое приведение типов
У Java-программистов первое время может возникнуть в голове путаница. Похожая по смыслу операция instanceof в Javа имеет такие же аргументы, но только в другом порядке. Она применяется к объекту и принимает в качестве аргумента имя типа. В Java операция instanceof совпадает по смыслу с операцией is в С#.
Если речь зашла о приведениях типов и о выяснении того, кто чей предок, то нельзя не коснуться операций is и as. Честно говоря, я начал немного путаться в этих функциях и операциях, и сделал себе такую табличку. Может, она и вам пригодится?
Возвращаемое значение
Применяется к:
Оператор или функция
Тип аргумента
Комментарий
bool
Object
is
тип
Оператор is позволяет определить, является ли объект (Object) наследником некоторого класса или интерфейса. Оператор также применим к массивам, и позволяет узнать, является ли объект массивом, совместимым с заданным типом.
Object
Object
as
тип
Оператор as пытается привести ссылку на объект или интерфейс (Object) к некоторому типу (возможно, интерфейсу). Если это невозможно (в смысле is ), возвращается null.
bool
Type
IsInstanceOfType
Object
Позволяет определить, является ли некоторый экземпляр объекта (Object) экземпляром указанного типа (Type).
bool
Type
IsSubclassOf
Type
Позволяет определить, что тип является наследником типа, переданного в качестве аргумента, и не является абстрактным. Если типы одинаковые, возвращается false.
bool
Type
IsAssignableFrom
Type
Позволяет определить, что в переменную данного типа можно установить значение, тип которого указан в качестве параметра метода IsAssignableFrom. Также говорит о возможности приведения типов.
Атрибуты
Говоря о метаданных и рефлексии, нельзя не коснуться такой темы, как атрибуты. Ведь когда говорится о таком важном свойстве метаданных, как их расширяемость, то подразумеваются именно атрибуты. Атрибуты позволяют дополнить информацию о любом элементе программы. Атрибуты могут использоваться любыми программами, в том числе компиляторами, визуальными средствами разработки и конечными приложениями.
ПРИМЕЧАНИЕ
Работа с атрибутами подробно освещена в статье Андрея Алифанова [5]. В ней вы найдёте подробные примеры работы, а также исходные тексты демонстрационного приложения. Наличие этой статьи на RSDN.ru сильно облегчает мою задачу и позволяет не останавливаться подробно на технической стороне дела. Я позволю себе подчеркнуть только некоторые принципиальные моменты и привести небольшой пример использования атрибутов (эту статью можно найти на нашем компакт-диске).
Декларативное программирование
Но главное значение атрибутов в том, что они позволяют изменять поведение программных элементов. Механизм такого изменения прост. Алгоритм, имеющий дело с экземпляром некоторого объекта, может считать значения атрибутов его типа и, в зависимости от считанных значений атрибутов, принять решение о применении того или иного способа обработки.
Давайте рассмотрим этот механизм на примере работы нашей процедуры протоколирования. Сейчас она выводит абсолютно все поля объекта без разбора. С помощью атрибутов можно создать механизм управления выводом в лог тех или иных полей класса (фильтрации). Для этого достаточно ввести новый атрибут, обозначающий, что протоколирование данного поля не требуется. Ниже приведено описание атрибута NotTrace:
Чтобы упростить использование этого атрибута, напишем простую вспомогательную функцию:
Теперь можно модифицировать функцию протоколирования, чтобы она выводила только те поля, у которых не задан атрибут NotTrace:
Заметьте, что теперь управление выводом полей производится не изменением кода функции протоколирования, а изменением описаний полей – заданием их атрибутов. Другими словами, судьба объекта задаётся при его декларации. Отсюда название данного метода программирования – декларативное программирование.
ПРИМЕЧАНИЕ
Советую заглянуть в статью Игоря Ткачёва «Память больше не ресурс», опубликованную в RSDN Magazine #1, где приводится изящный пример использования атрибутов. В этой статье атрибуты используются для управления автоматическим вызовом Dispose.
Код, исполняющийся в design-time
На примере атрибутов мы впервые (я, по крайней мере, впервые) столкнулись с тем, что часть кода, который пишет программист, выполняется в runtime (это как обычно), а часть кода выполняется в момент разработки (design time)! Не просто используются описания типов (декларации), а именно код! Ведь чтобы получить информацию об атрибутах, надо создать экземпляры объектов-атрибутов, а значит, в этот момент отрабатывают конструкторы атрибутов.
Вот как пишет об использовании атрибутов компилятором Э. Гуннерсон [2]:
Впрочем, создавать объект в действительности и не требуется, поскольку мы всё равно ограничимся сохранением информации. Поэтому компилятор только убеждается в том, что он может создать объект, вызвать конструктор и присвоить значения всех именованных параметров. Параметры атрибута заносятся в небольшой блок двоичных данных, который сохраняется вместе с метаданными объекта.
Новые механизмы абстракции?
Теперь, когда мы завершили краткое рассмотрение методов исследования типов (методов рефлексии), у нас есть повод задуматься над вопросом: «Какое новое качество могут принести методы рефлексии в наши программы. Дают ли они в наши руки принципиально новые возможности? Думаю этот вопрос имеет положительный ответ.
Напомню, что в С++ (а может и во всей идеологии ООП) существуют два принципиально разных подхода к разработке абстрактных алгоритмов и абстрактных структур данных. Первый подход основан на наследовании и виртуальных методах, в основе второго лежат шаблоны.
Формулируя алгоритм с помощью абстрактных типов данных (шаблонов), вы предполагаете наличие определённых свойств у типов, которые будут «подставлены» в шаблон (параметров шаблона). Конкретная реализация алгоритма становится ясной тогда, когда становятся известны типы-параметры шаблона, т.е. во время компиляции программы, использующей шаблон. («конкретизация при компиляции»)
Формулируя алгоритм с помощью абстрактных (виртуальных) методов класса, вы откладываете окончательную реализацию алгоритма на время исполнения программы. Именно тогда, во время исполнения, решается то, какие реальные методы будут участвовать в работе алгоритма. Это зависит от того с какими конкретными объектами придётся работать алгоритму. Можно сказать, что виртуальные методы конкретизируются в runtime. («конкретизация времени исполнения»).
Но заметьте, виртуальными (абстрактными) до сих пор могли быть только методы. А если вам нужно применить тот же самый механизм конкретизации времени исполнения, но по отношению к полям объекта? А если вам необходимы абстрактные структуры данных, конкретизируемые не при компиляции, а во время исполнения? Всё это позволяет сделать reflection. Короче, reflection – это виртуализация всех элементов программы.
Теперь нам позволительно формулировать алгоритмы подобные таким:
«Найди в этой структуре поле обозначающее цену товара и верни её». Перебираем все поля класса, в поисках поля типа Currency. Заметьте вам не надо знать имя поля. Если вы знаете что поле такого типа есть и оно одно – этого достаточно!
«Свяжи поля этой структуры с аргументами той хранимой процедуры на основе типов и имён полей и параметров». В последнем номере русского MSDN отличная статья про подобного рода методы.
«Выведи на консоль поля c атрибутом «видимый» (этим мы только что занимались).
У меня складывается впечатление, что наконец то мы с вами стали настоящими хозяевами своих программ! Наконец то нам стало доступно то, что раньше мог делать только «его величество компилятор». Уверен, что эти новые возможности породят совершенно новые классы алгоритмов, новые подходы к программированию, что в свою очередь принесёт новое качество в наши программы. Поживём – увидим.
Динамическое создание типов
Да. Заголовок этой главки написан правильно. Опечатки нет. Именно создание типа в момент исполнения программы. То есть в каком-то смысле программы начинают программировать себя сами.
Динамический «Hello World!»
Значит, начинаем процесс обучения программ программированию? Тогда не будем отступать от традиций и начнём обучение с классической программы «Hello World!».
Класс-программист (класса Programmer) пишет код методом WriteCode(). Код – это метод класса HelloWorldClass, который содержится в модуле HelloWorldModule, который принадлежит сборке HelloWorldAssembly.
Класс-программист создаёт эти объекты с помощью набора соответствующих объектов-Buider’oв, прописанных в пространстве имён System.Reflection.Emit, попутно задавая атрибуты создаваемых объектов. В данном случае и тип, и метод создаются как открытые (об этом говорят флаги TypeAttributes.Public и MethodAttributes.Public).
Самое интересное, конечно – это непосредственное генерирование кода. Он в данном случае состоит всего из двух команд языка IL: вывод строки на консоль и возврат из процедуры.
Забавно? Только и всего?
Если динамически сгенерированный класс широко используется в программе, то было бы удобно использовать его точно так же, как классы в сборках, создаваемых и используемых обычным образом.
Среди прилагающихся к статье примеров есть соответствующий этому случаю.
Динамическое разворачивание циклов
Давайте рассмотрим более интересный пример, который, я надеюсь, продемонстрирует практическое значение динамического программирования.
Что бы пояснить этот пример, необходимо сделать небольшое отступление. Давайте рассмотрим решение задачи непосредственного суммирования последовательности целых чисел, не превышающих заданное.
Нас интересует именно непосредственное суммирование, т.е. мы не хотим пользоваться общеизвестной формулой нахождения суммы арифметической прогрессии. Представьте себе, что наша задача как раз и состоит в проверке правильности этой формулы!
Для решения этой задачи используется простейший цикл с верхней границей valMax. Величина valMax является параметром этого алгоритма и может меняться от одного запуска алгоритма к другому.
То, что valMax является величиной переменной, играет важную роль для оптимизации этого цикла. Дело в том, что если бы в задаче требовалось провести вычисления только для одного значения valMax, можно было бы обойтись без цикла. Например, для valMax = 20 код выглядел бы вот так.
Какой смысл в таком преобразовании кода? – спросите вы. Думаю, что убедительнее всего будет вам самим произвести замер скорости выполнения двух вариантов суммирования. Вы убедитесь, что вариант с циклом проигрывает по скорости второму варианту в несколько раз! Надо сказать, что разработчики компиляторов прекрасно осведомлены в этом вопросе и давно используют приём разворачивания циклов при трансляции кода циклов.
Но тут есть одна подробность. Развернуть цикл можно только в том случае, если в момент компиляции точно известно количество необходимых повторений его тела. В противном случае приходится генерировать код цикла, проигрывая при этом в быстродействии. Ничего не поделаешь.
Постойте, но ведь технология Reflection.Emit позволяет генерировать код во время исполнения программы. Это значит, что мы можем отложить генерирование кода цикла до того момента, когда количество необходимых повторений станет известным. В этот момент мы можем «на лету» сгенерировать код развёрнутого цикла и получить огромный выигрыш в скорости!
Вот такой получается результат:
Выигрыш от разворачивания цикла – в 4-7 раз.
ПРИМЕЧАНИЕ
Справедливости ради надо отметить, что выигрыш достигается в тех случаях, когда разворачиваемый цикл используется в программе большое число раз (тысячи раз). В противном случае накладные расходы на генерирование кода могут сделать динамическое разворачивание цикла бессмысленным занятием.
Динамическое программирование на C#.
Рассмотрим ещё одну задачу. Имеется два массива целых чисел – массив А и массив Б. Наша задача подсчитать количество элементов массива Б, совпадающих с каким либо элементом массива А.
Ясно, что быстродействие данного алгоритма зависит главным образом от внутреннего цикла. Потому можно предположить, что быстродействие существенно возросло, ели бы нам удалось заменить внутренний цикл примерно вот такой гипотетический код
Разработчики компиляторов достигли больших успехов в оптимизации оператора switch. Он выполняется много быстрее соответствующего цикла. Этим мы и хотим воспользоваться. Мешает одно – в операторе case могут фигурировать только константные выражения, а значения элементов массива нам при компиляции не известны.
Вот результат, говорящий сам за себя.
СОВЕТ
Пытливый читатель конечно заметит, что динамически созданный код соревновался с не совсем оптимально написанным поиском по массиву. Было бы гораздо оптимальнее предварительно отсортировать массив, с тем чтобы потом применить двоичный поиск. А вот в этом соревновании вряд ли будет выявлен явный лидер, т.к. сам реализация switch’а сама использует двоичный поиск. Ну что ж. Тогда можно считать, что предложенный способ это всего лишь автоматизация сортировки и двоичного поиска, переложенная на плечи компилятора.
В заключение хочу рассказать вам о ещё одном классе задач, где применение динамического программирования может дать существенный выигрыш в эффективности.
Это задачи с гибким (многовариантным) нижним уровнем. (Название я придумал сам, так что наверняка есть более правильное.) Что я имею в виду под словами «гибкий нижний уровень»?
Примерно следующее. Представьте себе, что вы разрабатываете библиотеку для обработки некоторых данных. При этом все ваши алгоритмы оперируют данными с помощью некоторых унифицированных методов доступа. Эти методы доступа скрывают от ваших алгоритмов всё разнообразие типов данных и способов доступа к ним, скрывают их разнообразные параметры и настройки. Методы доступа универсальны (гибки), а, значит, вряд ли обладают достаточной эффективностью (универсальность и эффективность редко сочетаются). Вы могли бы реализовать частные методы доступа, но разнообразие типов и параметров данных так велико, что задача становится невыполнимой. Из-за этого вам приходится мириться с недостаточной эффективностью кода.
Другими словами, вы откладываете реализацию нижнего уровня до момента обработки конкретных данных, прописывая настройки прямо в коде (перенося данные в код, учитывая настройки непосредственно при генерации кода, выражая данные в виде кода) и получаете за это максимальную эффективность.
Примером может служить реализация класса RegExp в демонстрационной версии CLR – Rotor. Класс RegExp позволяет производить поиск и замену в тексте на основе регулярных выражений. В данном случае регулярное выражение играет роль того самого гибкого метода доступа (фильтра). Динамическое генерирование метода проверки соответствия регулярному выражению, позволяет в несколько раз повысить скорость поиска и замены текста. Подробности реализации класса RegExp вы можете изучить по исходникам Rotor’а [7].
Заключение
Мне же на этом пора заканчивать. Надеюсь, мне удалось вызвать у вас интерес к обсуждаемой теме и помочь сделать первые шаги в столь увлекательной и перспективной области, как программирование с использованием метаданных. Удачи!

 Эта статья, еще одна попытка переосмысления метапрограммирования, которые я периодически предпринимаю. Идея каждый раз уточняется, но в этот раз удалось подобрать достаточно простых и понятных примеров, которые одновременно очень компактны и иллюстративны, имеют реальное полезное применение и не тянут за собой библиотек и зависимостей. В момент публикации я буду докладывать эту тему на ОдессаJS, поэтому, статью можно использовать, как место для вопросов и комментариев к докладу. Формат статьи дает возможность более полно изложить материал, чем в докладе, слушатели которого, не освобождаются от прочтения.
Эта статья, еще одна попытка переосмысления метапрограммирования, которые я периодически предпринимаю. Идея каждый раз уточняется, но в этот раз удалось подобрать достаточно простых и понятных примеров, которые одновременно очень компактны и иллюстративны, имеют реальное полезное применение и не тянут за собой библиотек и зависимостей. В момент публикации я буду докладывать эту тему на ОдессаJS, поэтому, статью можно использовать, как место для вопросов и комментариев к докладу. Формат статьи дает возможность более полно изложить материал, чем в докладе, слушатели которого, не освобождаются от прочтения. Обычно, набор метаданных ограничивается тем, что протокол обязательно требует для считывания структуры передаваемых данных. В двоичных форматах метаданных меньше, чем в синтаксических форматах, применяемых для сериализации данных (как, например, JSON и MIME). Информация о структуре двоичных форматов, по большей части находится у принимающего модуля в виде struct (структур для C, C++, C# и др. языках) или «зашита» в логику интерпретирующего модуля другим способом. Разделить, где заканчивается обработка данных с использованием метаданных и начинается метапрограммирование, достаточно сложно. Условно, можно определить такой критерий: когда метаданные не просто описывают структуры, а повышают абстракцию программного кода в модуле, интерпретирующем данные и метаданные, вот тут начинается метапрограммирование. Другими словами, когда происходит переход от модели, к метамодели. Основным признаком такого перехода, является расширение универсальности модуля, а не расширение универсальности протокола или формата данных. На схеме справа показано, как из данных выделяются метаданные и заходят в модуль, меняя его поведение при обработке данных. Таким образом, абстрактная метамодель, содержащаяся в модуле на этапе исполнения превращается в конкретную модель.
Обычно, набор метаданных ограничивается тем, что протокол обязательно требует для считывания структуры передаваемых данных. В двоичных форматах метаданных меньше, чем в синтаксических форматах, применяемых для сериализации данных (как, например, JSON и MIME). Информация о структуре двоичных форматов, по большей части находится у принимающего модуля в виде struct (структур для C, C++, C# и др. языках) или «зашита» в логику интерпретирующего модуля другим способом. Разделить, где заканчивается обработка данных с использованием метаданных и начинается метапрограммирование, достаточно сложно. Условно, можно определить такой критерий: когда метаданные не просто описывают структуры, а повышают абстракцию программного кода в модуле, интерпретирующем данные и метаданные, вот тут начинается метапрограммирование. Другими словами, когда происходит переход от модели, к метамодели. Основным признаком такого перехода, является расширение универсальности модуля, а не расширение универсальности протокола или формата данных. На схеме справа показано, как из данных выделяются метаданные и заходят в модуль, меняя его поведение при обработке данных. Таким образом, абстрактная метамодель, содержащаяся в модуле на этапе исполнения превращается в конкретную модель.