
Программное обеспечение и базы данных что это
По Вашему запросу ничего не найдено.
Рекомендуем сделать следующее:
Темы на странице по базам данных
База данных — определение
База данных — это упорядоченный набор структурированной информации или данных, которые обычно хранятся в электронном виде в компьютерной системе. База данных обычно управляется системой управления базами данных (СУБД). Данные вместе с СУБД, а также приложения, которые с ними связаны, называются системой баз данных, или, для краткости, просто базой данных.
Данные в наиболее распространенных типах современных баз данных обычно хранятся в виде строк и столбцов формирующих таблицу. Этими данными можно легко управлять, изменять, обновлять, контролировать и упорядочивать. В большинстве баз данных для записи и запросов данных используется язык структурированных запросов (SQL).
Что такое язык структурированных запросов (SQL)?
SQL — это язык программирования, используемый в большинстве реляционных баз данных для запросов, обработки и определения данных, а также контроля доступа. SQL был разработан в IBM в 1970-х годах. Со временем у стандарта SQL ANSI появились многочисленные расширения, разработанные такими компаниями как IBM, Oracle и Microsoft. Хотя в настоящее время SQL все еще широко используется, начали появляться новые языки программирования запросов.
Эволюция базы данных
Базы данных значительно изменились с момента их появления в начале 1960-х годов. Исходными системами, которые использовались для хранения и обработки данных, были навигационные базы данных – например, иерархические базы данных (которые опирались на древовидную модель и допускали только отношение «один-ко-многим») и базы данных с сетевой структурой (более гибкая модель, допускающая множественные отношения). Несмотря на простоту, эти ранние системы были негибкими. В 1980-х годах стали популярными реляционные базы данных, в 1990-х годах за ними последовали объектно-ориентированные базы данных. Совсем недавно вследствие роста Интернета и возникновения необходимости анализа неструктурированных данных появились базы данных NoSQL. В настоящее время облачные базы данных и автономные базы данных открывают новые возможности в отношении способов сбора, хранения, использования данных и управления ими.
В чем заключается различие между базой данных и электронной таблицей?
Базы данных и электронные таблицы (в частности, Microsoft Excel) предоставляют удобные способы хранения информации. Основные различия между ними заключаются в следующем.
Электронные таблицы изначально разрабатывались для одного пользователя, и их свойства отражают это. Они отлично подходят для одного пользователя или небольшого числа пользователей, которым не нужно производить сложные операции с данными. С другой стороны, базы данных предназначены для хранения гораздо больших наборов упорядоченной информации—иногда огромных объемов. Базы данных дают возможность множеству пользователей в одно и то же время быстро и безопасно получать доступ к данным и запрашивать их, используя развитую логику и язык запросов.
Типы баз данных
Существует множество различных типов баз данных. Выбор наилучшей базы данных для конкретной компании зависит от того, как она намеревается использовать данные.
Это лишь некоторые из десятков типов баз данных, используемых в настоящее время. Другие, менее распространенные базы данных, предназначены для очень специфических научных, финансовых и иных задач. Помимо появления новых типов, базы данных развиваются в абсолютно новых направлениях — изменяются подходы к разработке технологий, происходят значительные сдвиги, такие как внедрение облачных технологий и автоматизации. В частности, в последнее время появились следующие базы данных.
Что такое программное обеспечение базы данных?
Программное обеспечение базы данных используется для создания, редактирования и обслуживания файлов и записей базы данных, что упрощает создание файлов и записей, ввод данных, редактирование, обновление и отчетность. Программное обеспечение также помогает хранить данных, осуществлять резервное копирование и формировать отчетность, предоставлять управление множественным доступом и поддерживать безопасность. Сегодня надежная безопасность базы данных особенно важна, поскольку случаи кражи данных значительно участились. Программное обеспечение для баз данных иногда называют системой управления базами данных (СУБД).
Программное обеспечение баз данных упрощает управление данными, помогая пользователям хранить данные в структурированной форме, а затем получать к ним доступ. Обычно программа имеет графический интерфейс, помогающий создавать данные и управлять ими, и в некоторых случаях пользователи могут создавать собственные базы данных с помощью такого ПО.
Что такое система управления базами данных (DBMS)?
Для базы данных обычно требуется комплексное программное обеспечение, которое называется системой управления базами данных (СУБД). СУБД служит интерфейсом между базой данных и пользователями или программами, предоставляя пользователям возможность получать и обновлять информацию, а также управлять ее упорядочением и оптимизацией. СУБД обеспечивает контроль и управление данными, позволяя выполнять различные административные операции, такие как мониторинг производительности, настройка, а также резервное копирование и восстановление.
В качестве примеров популярного программного обеспечения для управления базами данных, или СУБД, можно назвать MySQL, Microsoft Access, Microsoft SQL Server, FileMaker Pro, СУБД Oracle Database и dBASE.
Что такое база данных MySQL?
MySQL — это реляционная система управления базами данных с открытым исходным кодом на основе языка SQL. Она была разработана и оптимизирована для веб-приложений и может работать на многих платформах. Она обладает всеми возможностями, которые требуются веб-разработчикам. База данных MySQL предназначена для обработки миллионов запросов и тысяч транзакций, поэтому ее часто выбирают компании электронной коммерции, которым требуется управлять большим количеством денежных переводов. Гибкость по мере необходимости — основная характеристика MySQL.
Многие ведущие веб-сайты и веб-приложения используют СУБД MySQL, в том числе Airbnb, Uber, LinkedIn, Facebook, Twitter и YouTube.
Использование баз данных для повышения производительности бизнеса и улучшения процесса принятия решений
Обширный сбор данных из Интернета вещей меняет действительность и производственный сектор по всему миру: современные компании имеют доступ к большему количеству данных, чем когда-либо прежде. Прогрессивные компании теперь могут использовать базы данных, чтобы от обычного хранения данных и базовых транзакций перейти к анализу огромных объемов данных из множества систем. Благодаря базам данных и другим средствам вычислений и бизнес-аналитики современные компании могут использовать собираемые ими данные для более эффективной работы, эффективного принятия решений, гибкости и масштабируемости.
Автономная база данных способна значительно расширить эти возможности. Автономные базы данных автоматизируют дорогостоящие и длительные ручные процедуры, благодаря чему бизнес-пользователи могут сосредоточиться на работе со своими данными. За счет возможностей создания и использования баз данных пользователи приобретают контроль и автономию, поддерживая при этом важные стандарты безопасности.
Задачи для баз данных
Современные крупные корпоративные базы данных нередко поддерживают очень сложные запросы, и предполагается, что они должны предоставлять почти мгновенные ответы на них. В результате администраторы баз данных вынуждены применять самые разные методы для повышения производительности. Вот некоторые из наиболее распространенных вызовов, с которыми они сталкиваются.
Решение всех этих задач может занимать много времени и отвлекать администраторов баз данных от решения стратегических задач.
Как автономные технологии улучшают управление базами данных
Автономные базы данных — это модель будущего, представляющая исключительный интерес для компаний, которые хотят использовать лучшую из имеющихся технологий баз данных, при этом не сталкиваясь с проблемами при запуске и эксплуатации этой технологии.
Автономные базы данных используют облачные технологии и машинное обучение для автоматизации множества стандартных задач управления базами данных, таких как настройка, защита, резервное копирование, обновление и другие повседневные задачи администрирования. Благодаря автоматизации этой рутины администраторы баз данных могут сосредоточиться на более стратегической работе. Возможности автономного управления, самозащиты и самовосстановления автономных баз данных могут радикально изменить способы управления и защиты данных, улучшая производительность, снижая расходы и повышая безопасность.
Будущее баз данных и автономных баз данных
О выходе первой автономной базы данных было объявлено в конце 2017 года, и многие независимые отраслевые аналитики быстро оценили возможности этой технологии и ее потенциальное воздействие на обработку данных.
В феврале 2018 г. эксперты IDC дали высокую оценку технологии автономных баз данных за “упрощение развертывания, использования и администрирования корпоративного программного обеспечения, применение искусственного интеллекта и машинного обучения для обеспечения возможностей, практически не требующих вмешательства человека в управление программным обеспечением”.
В отчете KuppingerCole’ от января 2018 г. (PDF) говорится: “«Этот подход обладает огромным потенциалом, так как не только сокращает трудовые издержки и финансовые затраты заказчиков, но и серьезно повышает устойчивость баз данных к человеческим ошибкам и злонамеренным действиям, как внутренним, так и внешним». В каждой базе данных также предусмотрены функции безопасности, включенные по умолчанию, а необходимые параметры автоматически настраиваются в соответствии с лучшими практиками защиты.”
Компьютеры и программное обеспечение. Базы данных




![]()
![]()
Техническую основу обеспечения информационных технологий составляют средства компьютерной техники, средства коммуникационной техники и средства организационной техники.
Средства компьютерной техники составляют базис всего комплекса технических средств информационных технологий и предназначены прежде всего для обработки и преобразования различных видов информации, используемой в управленческой деятельности.
Средства организационной техники предназначены для механизации и автоматизации управленческой деятельности во всех ее проявлениях.
Вычислительная техника прошла те же исторические этапы эволюции, которые прошли и все прочие технические устройства: от ручных приспособлений к механическим устройствам и далее к гибким автоматическим системам. Современный компьютер — это прибор. Его принцип действия — электронный, а назначение — автоматизация операций с данными. Гибкость автоматизации основана на том, что операции с данными выполняются по заранее заготовленным и легко сменяемым программам. Универсальность компьютеров основана на том, что любые типы данных представляются в нем с помощью универсального двоичного кодирования.
В отечественной и зарубежной литературе существует достаточно много систем классификации компьютеров, рассмотрим следующие из них: классификация по назначению; по спецификации PC99; по уровню специализации; по размеру. Все виды классификаций достаточно условны, поскольку интенсивное развитие технологий приводит к размыванию границ между различными классами компьютеров.
Классификация по назначению. По этому принципу выделяют:
· Мэйнфреймы (большие ЭВМ);
· Настольные персональные компьютеры;
· Серверы начального и высокого уровня;
Мини ЭВМ. От больших компьютеров компьютеры этой группы отличаются меньшими размерами, меньшей производительностью и стоимостью. Такие компьютеры используются крупными предприятиями, научными учреждениями, банками.
Персональные компьютеры (ПК). Многие современные модели персональных компьютеров превосходят большие ЭВМ 70-х годов, мини ЭВМ 80-х годов. ПК применяются для решения задач автоматизации управления предприятиями, автоматизации учебного процесса, индивидуальной работы пользователя. Особенно широкую популярность ПК получили в связи с бурным развитием сети Интернет. Персонального компьютера вполне достаточно для использования всемирной сети в качестве источника научной, справочной, учебной и др. информации. На характеристиках и возможностях персонального компьютера мы остановимся позднее.
Рабочие станции предназначены для инженеров и пользователей настольных издательских систем, там, где нужно работать со сложной графикой. Такие системы оснащаются процессором Pentium III, IVс 2 Мб кэш-памяти второго уровня.
Серверы начального и высокого уровня. На сервер начального уровня устанавливают один или два процессора. Сервер начального уровня может поддерживать небольшую локальную сеть (до 40 пользователей). Серверы высокого уровня имеют обычно от двух до восьми процессоров, не менее двух источников питания. Серверы содержат большие объемы оперативной (до 4-х Гб) и дисковой памяти (6Тб и более).

Суперкомпьютеры. Применяются для решения задач в области метеорологии, аэродинамики, сейсмологии, различных военных исследованиях, в атомной и ядерной физике, физике плазмы, математическом моделировании сложных систем. Производительность суперкомпьютеров измеряется в триллионах операций с «плавающей точкой» в секунду, так называемых терафлопах. Например, для предсказания погоды используется 1024-процессорный компьютер Cray T3E900 фирмы SGI, показавший производительность 69 Гфлоп (миллиардов операций с плавающей точкой в секунду) на программе по прогнозированию погодных катаклизмов (HILARM). Этот же компьютер, но оснащенный 1328 процессорами, показал производительность 1,195 Тфлоп, что позволило предсказывать стихийные бедствия за 6 часов до их начала. Компьютер Cray T3E900 используется для построения трехмерных моделей гелиосферы, моделирования процессов, протекающих в земной коре и др.
Классификация по спецификации PC99. Начиная с 1999 г. в области персональных компьютеров начал действовать международный сертификационный стандарт –спецификация PC99. В соответствии с этой классификацией выделяют следующие категории персональных компьютеров:
· Consumer PC (массовый ПК);
· Office PC (офисный ПК);
· Mobile PC (мобильный, переносной);
· Workstation PC (рабочая станция);
· Entertainment PC (развлекательный ПК).
Классификация по размерам.Персональные компьютеры можно классифицировать по типоразмерам: Настольные; портативные (notebook); карманные (palmtop).
Программное обеспечение (ПО) компьютера называют мягким оборудованием или SOFTWARE.
В зависимости от функций, выполняемых программным обеспечением, его можно разделить на 2 группы: системное программное обеспечение и прикладное программное обеспечение.
Системное ПО организует процесс обработки информации на компьютере и обеспечивает нормальную рабочую среду для прикладных программ. Системное ПО настолько тесно связано с аппаратными средствами, что его иногда считают частью компьютера.
В состав системного ПО входят:
• трансляторы языков программирования;
• программы технического обслуживания.
Прикладное ПО предназначено для решения конкретных задач пользователя и организации вычислительного процесса информационной системы в целом.
Прикладное ПО позволяет разрабатывать и выполнять задачи (приложения) пользователя по бухгалтерскому учету, управлению персоналом и т.п.
Прикладное программное обеспечение работает под управлением системного ПО, в частности операционных систем. В состав прикладного ПО входят:
• пакеты прикладных программ (ППП) общего назначения;
• пакеты прикладных программ функционального назначения.
К этому классу ППП относятся:
• редакторы текстовые (текстовые процессоры) и графические;
• системы управления базами данных (СУБД);
• оболочки экспертных систем и систем искусственного интеллекта.
К ППП функционального назначения относятся программные продукты, ориентированные на автоматизацию функций пользователя в конкретной сфере экономической деятельности. К данному классу относятся пакеты программ по бухгалтерскому учету, технико-экономическому планированию, разработке инвестиционных проектов, управлению персоналом, системы автоматизированного управления предприятием в целом.
Базами данных (БД) называют электронные хранилища информации, доступ к которым осуществляется с помощью одного или нескольких компьютеров. Обычно БД создается для хранения и доступа к данным, содержащим сведения о некоторой предметной области, то есть некоторой области человеческой деятельности или области реального мира.
Системы управления базами данных (СУБД) — это программные средства, предназначенные для создания, наполнения, обновления и удаления баз данных. Различают три основных вида СУБД: промышленные универсального назначения,промышленные специального назначения и разрабатываемые для конкретногозаказчика. Специализированные СУБД создаются для управления базами данныхконкретного назначения — бухгалтерские, складские, банковские и т. д. УниверсальныеСУБД не имеют четко очерченных рамок применения, они рассчитаны «на все случаи жизни» и, как следствие, достаточно сложны и требуют от пользователя специальных знаний. Как специализированные, так и универсальные промышленные СУБД относительно дешевы, достаточно надежны (отлажены) и готовы к немедленной работе, в то время как заказные СУБД требуют существенных затрат, а их подготовка к работе и отладка занимают значительный период (от нескольких месяцев до нескольких лет). Однако в отличие от промышленных заказные СУБД в максимальной степени учитывают специфику работы заказчика (того или иного предприятия), их интерфейс обычно интуитивно понятен пользователям и не требует от них специальных знаний.
По своей архитектуре СУБД делятся на одно-, двух- и трехзвенные (рис.2). В однозвенной архитектуре используется единственное звено (клиент), обеспечивающее необходимую логику управления данными и их визуализацию. В двухзвенной архитектуре значительную часть логики управления данными берет на себя сервер БД, в то время как клиент в основном занят отображением данных в удобном для пользователя виде. В трехзвенных СУБД используется промежуточное звено — сервер приложений, являющееся посредником между клиентом и сервером БД. Сервер приложений призван полностью избавить клиента от каких бы то ни было забот по управлению данными и обеспечению связи с сервером БД.
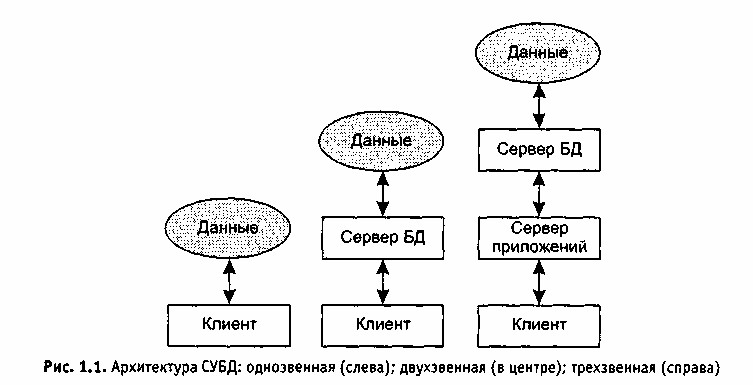
В зависимости от расположения отдельных частей СУБД различают локальные и сетевые СУБД.
Все части локальной СУБД размещаются на компьютере пользователя базы данных. Чтобы с одной и той же БД одновременно могло работать несколько пользователей, каждый пользовательский компьютер должен иметь свою копию локальной БД. Существенной проблемой СУБД такого типа является синхронизация копий данных, именно поэтому для решения задач, требующих совместной работы нескольких пользователей, локальные СУБД фактически не используются.
К сетевым относятся файл-серверные, клиент-серверные и распределенныеСУБД. Непременным атрибутом этих систем является сеть, обеспечивающая аппаратную связь компьютеров и делающая возможной корпоративную работу множества пользователей с одними и теми же данными.
В файл-серверных СУБД все данные обычно размещаются в одном или нескольких каталогах достаточно мощной машины, специально выделенной для этих целей и постоянно подключенной к сети. Такой компьютер называется файл-сервером — отсюда название СУБД. Безусловным достоинством СУБД этого типа является относительная простота ее создания и обслуживания — фактически все сводится лишь к развертыванию локальной сети и установке на подключенных к ней компьютерах сетевых операционных систем. По счастью, Delphi «умеет» использовать сетевые средства самой популярной в мире ОС — Windows — для создания соответствующихклиентских мест, то есть специального программного обеспечения компьютеров пользователей. Нетрудно заметить, что между локальными и файл-серверными вариантами СУБД нет особых различий, так как в них все части собственно СУБД (кроме данных) находятся на компьютере клиента. По архитектуре они обычно являются однозвенными, но в некоторых случаях могут использовать сервер приложений. Недостатком файл-серверных систем является значительная нагрузка на сеть. Если, например, клиенту нужно отыскать сведения об одной из фирм-партнеров, по сети вначале передается весь файл, содержащий сведения о многих сотнях партнеров, и лишь затем в созданной таким образом локальной копии данных отыскивается нужная запись. Ясно, что при интенсивной работе с данными уже нескольких десятков клиентов пропускная способность сети может оказаться недостаточной, и пользователя будут раздражать значительные задержки в реакции СУБД на его требования. Файл-серверные СУБД могут успешно использоваться в относительно небольших фирмах с количеством клиентских мест до нескольких десятков.
Распределенные СУБД могут содержать несколько десятков и сотен серверов БД. Количество клиентских мест в них может достигать десятков и сотен тысяч. Обычно такие СУБД работают на предприятиях государственного масштаба, отдельные подразделения которых разнесены на значительной территории. К таковым, например, относятся подразделения Министерства обороны и Министерства внутренних дел. В распределенных СУБД некоторые серверы могут дублировать друг друга с целью достижения предельно малой вероятности отказов и сбоев, которые могут исказить жизненно важную информацию. Они используют собственные региональные средства связи. Интерес к распределенным СУБД возрос в связи со стремительным развитием Интернета. Опираясь на возможности Интернета, распределенные системы строят не только предприятия государственного масштаба, но и относительно небольшие коммерческие предприятия, обеспечивая своим сотрудникам работу с корпоративными данными на дому и в командировках.
CASE-технологии. CASE-технологии применяются при создании сложных информационных систем, обычно требующих коллективной реализации проекта, в котором участвуют различные специалисты: системные аналитики, проектировщики и программисты.
Что такое База Данных (БД)
База данных — это место для хранения данных. Используется в том числе в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов. Вы делаете заказ, а система сохраняет ваши данные в базе.

В этот статье я на простых примерах расскажу, что такое база данных и как она выглядит. А потом поясню некоторые термины из конкретной (реляционной) базы. Те, с которыми вы почти наверняка столкнетесь на работе.
Статья рассчитана на начинающих тестировщиков или аналитиков, то есть тех, кто будет работать с базой, но не на супер-глубоком уровне. Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Содержание
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.
Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!
Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.
Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги.
Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
То же самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
Пример базы Oracle
Цель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
заходишь в папку в винде → видишь файлики только из этой папки
заходишь в пространство → видишь только те таблицы, которые в нем есть
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
select — выбери мне такие-то колонки.
from — из такой-то таблицы базы.
where — такую-то информацию.
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
В дословном переводе:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
Открыть файл с нужными данными (clients)
Поставить фильтр на колонку «ФИО» — «Назина Ольга».
То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. То же самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order
order (таблица order)
fio (таблица client)
phone (таблица contacts)
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
В таблице «client» лежат данные по клиентам: ФИО, пол, дата рождения и т.д.
last_name
first_name
birthdate
В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order
addr
date
time
Роллы «Филадельфия» и «Канада»
Пицца 35 см, роллы комбо 1
Пицца с сосиками по краям
Комбо набор 3, обед №4
Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам. В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
Чтобы избежать дублей, таблицы принято разделять:
Новые объекты отдельно
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку. А если у нас два клиента Ивана? Или три Маши? Десять Саш. Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.
А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Здесь ключ — «id_order»
Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!