
Машинное зрение на Python. Обучаем нейросеть распознавать цифры

Nov 4, 2019 · 7 min read

Раньше капча с числами была отличным способом отсеять ботов, а сейчас такая разновидность уже почти не встречается. Думаю, ты и сам догадываешься, в чем дело: нейросети научились распознавать такие капчи лучше нас. В этой статье мы посмотрим, как работает нейронная сеть и как использовать Keras и Tensorflow, чтобы реализовать распознавание цифр.
Для каждого примера я приведу код на Python 3.7. Т ы можешь запустить его и посмотреть, как все это работает. Для запуска примеров потребуется библиотека Tensorflow. Установить ее можно командой pip install tensorflow-gpu, если видеокарта поддерживает CUDA, в противном случае используй команду pip install tensorflow. Вычисления с CUDA в несколько раз быстрее, так что, если твоя видеокарта их поддерживает, это сэкономит немало времени. И не забудь установить наборы данных для обучения сети командой pip install tensorflow-datasets.
Как работает нейронная сеть
Как работает один нейрон? Сигналы со входов (1) суммируются (2), причем каждый вход имеет свой «коэффициент передачи» — w. Затем к получившемуся результату применяется «функция активации» (3).
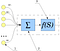
Типы этой функции различны, она может быть:
Рассмотрим простейшую нейросеть и научим ее выполнять функцию XOR. Разумеется, вычисление XOR с помощью нейронной сети не имеет практического смысла. Но именно оно поможет нам понять базовые принципы обучения и использования нейросети и позволит по шагам проследить ее работу. С сетями большей размерности это было бы слишком сложно и громоздко.
Простейшая нейронная сеть
Сначала нужно подключить необходимые библиотеки, в нашем случае это tensorflow. Я также отключаю вывод отладочных сообщений и работу с GPU, они нам не пригодятся. Для работы с массивами нам понадобится библиотека numpy.
Теперь мы готовы создать нейросеть. Благодаря Tensorflow на это понадобится всего лишь четыре строчки кода.
Мы создали модель нейронной сети — класс Sequential — и добавили в нее два слоя: входной и выходной. Такая сеть называется «многослойный перцептрон» (multilayer perceptron), в общем виде она выглядит так.

В нашем случае сеть имеет два входа (внешний слой), два нейрона во внутреннем слое и один выход.
Можно посмотреть, что у нас получилось:

Обучение нейросети состоит в нахождении значений параметров этой сети.
Наша сеть имеет девять параметров. Чтобы обучить ее, нам понадобится исходный набор данных, в нашем случае это результаты работы функции XOR.
Функция fit запускает алгоритм обучения, которое у нас будет выполняться тысячу раз, на каждой итерации параметры сети будут корректироваться. Наша сеть небольшая, так что обучение пройдет быстро. После обучения сетью уже можно пользоваться:
Результат соответствует тому, чему сеть обучалась.
Мы можем вывести все значения найденных коэффициентов на экран.
W2: [[3.9633768] [3.9168582]]
Внутренняя реализация функции model.predict_proba выглядит примерно так:
Рассмотрим ситуацию, когда на вход сети подали значения [0,1]:
Функция активации ReLu (rectified linear unit) — это просто замена отрицательных элементов нулем.
Теперь найденные значения попадают на второй слой.
Наконец, в качестве выхода используется функция Sigmoid, которая приводит значения к диапазону 0. 1:
Мы совершили обычные операции умножения и сложения матриц и получили ответ: XOR(0,1) = 1.
С этим примером на Python советую поэкспериментировать самостоятельно. Например, ты можешь менять число нейронов во внутреннем слое. Два нейрона, как в нашем случае, — это самый минимум, чтобы сеть работала.
Но алгоритм обучения, который используется в Keras, не идеален: нейросети не всегда удается обучиться за 1000 итераций, и результаты не всегда верны. Так, Keras инициализирует начальные значения случайными величинами, и при каждом запуске результат может отличаться. Моя сеть с двумя нейронами успешно обучалась лишь в 20% случаев. Неправильная работа сети выглядит примерно так:
Но это не страшно. Если видишь, что нейронная сеть во время обучения не выдает правильных результатов, алгоритм обучения можно запустить еще раз. Правильно обученную сеть потом можно использовать без ограничений.
Можно сделать сеть поумнее: использовать четыре нейрона вместо двух, для этого достаточно заменить строчку кода model.add(Dense(2, input_dim=2, activation=’relu’)) на model.add(Dense(4, input_dim=2, activation=’relu’)). Такая сеть обучается уже в 60% случаев, а сеть из шести нейронов обучается с первого раза с вероятностью 90%.
Все параметры нейронной сети полностью определяются коэффициентами. Обучив сеть, можно записать параметры сети на диск, а потом использовать уже готовую обученную сеть. Этим мы будем активно пользоваться.
Распознавание цифр — сеть MLP
Рассмотрим практическую задачу, вполне классическую для нейронных сетей, — распознавание цифр. Для этого мы возьмем уже известную нам сеть multilayer perceptron, ту же самую, что мы использовали для функции XOR. В качестве входных данных будут выступать изображения 28 × 28 пикселей. Такой размер выбран потому, что существует уже готовая база рукописных цифр MNIST, которая хранится именно в таком формате.
Для удобства разобьем код на несколько функций. Первая часть — это создание модели.
На вход сети будет подаваться image_w*image_h значений — в нашем случае это 28 × 28 = 784. Количество нейронов внутреннего слоя такое же и равно 784.
С распознаванием цифр есть одна особенность. Как мы видели в предыдущем примере, выход нейросети может лежать в диапазоне 0…1, а нам нужно распознавать цифры от 0 до 9. Как быть? Чтобы распознавать цифры, мы создаем сеть с десятью выходами, и единица будет на выходе, соответствующем нужной цифре.

Структура отдельного нейрона настолько проста, что для его использования даже не обязателен компьютер. Недавно ученые смогли реализовать нейронную сеть, аналогичную нашей, в виде куска стекла — такая сеть не требует питания и вообще не содержит внутри ни одного электронного компонента.

Когда нейронная сеть создана, ее надо обучить. Для начала необходимо загрузить датасет MNIST и преобразовать данные в нужный формат.
У нас есть два блока данных: train и test — один служит для обучения, второй для верификации результатов. Это общепринятая практика, обучать и тестировать нейронную сеть желательно на разных наборах данных.
Готовый код обучения сети:
Создаем модель, обучаем ее и записываем результат в файл.

На моем компьютере c Core i7 и видеокартой GeForce 1060 процесс занимает 18 секунд и 50 секунд с расчетами без GPU — почти втрое дольше. Так что, если ты захочешь экспериментировать с нейронными сетями, хорошая видеокарта весьма желательна.
Теперь напишем функцию распознавания картинки из файла — то, для чего эта сеть и создавалась. Для распознавания мы должны привести картинку к такому же формату — черно-белое изображение 28 на 28 пикселей.
Теперь использовать нейронную сеть довольно просто. Я создал в Paint пять изображений с разными цифрами и запустил код.
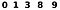
Результат, увы, неидеален: 0, 1, 3, 6 и 6. Нейросеть успешно распознала 0, 1 и 3, но спутала 8 и 9 с цифрой 6. Разумеется, можно изменить число нейронов, число итераций обучения. К тому же эти цифры не были рукописными, так что стопроцентный результат нам никто не обещал.
Вот такая нейронная сеть с дополнительным слоем и большим числом нейронов корректно распознает цифру восемь, но все равно путает 8 и 9.
При желании можно обучать нейронную сеть и на своем наборе данных, но для этого данных нужно довольно много (MNIST содержит 60 тысяч образцов цифр). Желающие могут поэкспериментировать самостоятельно, а мы пойдем дальше и рассмотрим сверточные сети (CNN, Convolutional Neural Network), более эффективные для распознавания изображений.
Распознавание цифр — сверточная сеть (CNN)
В предыдущем примере мы использовали изображение 28 × 28 как простой одномерный массив из 784 цифр. Такой подход, в принципе, работает, но начинает давать сбои, если изображение, например, сдвинуто. Достаточно в предыдущем примере сдвинуть цифру в угол картинки, и программа уже не распознает ее.
Сверточные сети в этом плане гораздо эффективнее — они используют принцип свертки, по которому так называемое ядро (kernel) перемещается вдоль изображения и выделяет ключевые эффекты на картинке, если они есть. Затем полученный результат сообщается «обычной» нейронной сети, которая и выдает готовый результат.
Слой Conv2D отвечает за свертку входного изображения с ядром 3 × 3, а слой MaxPooling2D выполняет downsampling — уменьшение размера изображения. На выходе сети мы видим уже знакомый нам слой Dense, который мы использовали ранее.
Как и в предыдущем случае, сеть вначале надо обучить, и принцип здесь тот же самый, за тем исключением, что мы работаем с двумерными изображениями.
Все готово. Мы создаем модель, обучаем ее и записываем модель в файл:
Обучение нейронной сети с той же базой MNIST из 60 тысяч изображений занимает 46 секунд с использованием Nvidia CUDA и около пяти минут без нее.
Теперь мы можем использовать нейросеть для распознавания изображений:
Результат гораздо точнее, что и следовало ожидать: [0, 1, 3, 8, 9].
Все готово! Теперь у тебя есть программа, умеющая распознавать цифры. Благодаря Python работать код будет где угодно — на операционных системах Windows и Linux. При желании можешь запустить его даже на Raspberry Pi.
Ты наверняка хочешь знать, можно ли распознавать буквы аналогичным способом? Да, придется только увеличить число выходов сети и найти подходящий набор картинок для обучения.
Надеюсь, у тебя достаточно информации для экспериментов. К тому же с реальным примером перед глазами разбираться значительно проще!
Python + OpenCV + Keras: делаем распознавалку текста за полчаса
После экспериментов с многим известной базой из 60000 рукописных цифр MNIST возник логичный вопрос, есть ли что-то похожее, но с поддержкой не только цифр, но и букв. Как оказалось, есть, и называется такая база, как можно догадаться, Extended MNIST (EMNIST).
Если кому интересно, как с помощью этой базы можно сделать несложную распознавалку текста, добро пожаловать под кат.

Примечание: данный пример экспериментальный и учебный, мне было просто интересно посмотреть, что из этого получится. Делать второй FineReader я не планировал и не планирую, так что многие вещи тут, разумеется, не реализованы. Поэтому претензии в стиле «зачем», «уже есть лучше» и пр, не принимаются. Наверно готовые OCR-библиотеки для Python уже есть, но было интересно сделать самому. Кстати, для тех кто хочет посмотреть, как делался настоящий FineReader, есть две статьи в их блоге на Хабре за 2014 год: 1 и 2 (но разумеется, без исходников и подробностей, как и в любом корпоративном блоге). Ну а мы приступим, здесь все открыто и все open source.
Для примера мы возьмем простой текст. Вот такой:
HELLO WORLD
И посмотрим что с ним можно сделать.
Разбиение текста на буквы
Первым шагом разобьем текст на отдельные буквы. Для этого пригодится OpenCV, точнее его функция findContours.
Откроем изображение (cv2.imread), переведем его в ч/б (cv2.cvtColor + cv2.threshold), слегка увеличим (cv2.erode) и найдем контуры.
Мы получаем иерархическое дерево контуров (параметр cv2.RETR_TREE). Первым идет общий контур картинки, затем контуры букв, затем внутренние контуры. Нам нужны только контуры букв, поэтому я проверяю что «родительским» является общий контур. Это упрощенный подход, и для реальных сканов это может не сработать, хотя для распознавания скриншотов это некритично.
Следующим шагом сохраним каждую букву, предварительно отмасштабировав её до квадрата 28х28 (именно в таком формате хранится база MNIST). OpenCV построен на базе numpy, так что мы можем использовать функции работы с массивами для кропа и масштабирования.
В конце мы сортируем буквы по Х-координате, также как можно видеть, мы сохраняем результаты в виде tuple (x, w, letter), чтобы из промежутков между буквами потом выделить пробелы.
Убеждаемся что все работает:
Буквы готовы для распознавания, распознавать их мы будем с помощью сверточной сети — этот тип сетей неплохо подходит для таких задач.
Нейронная сеть (CNN) для распознавания
Исходный датасет EMNIST имеет 62 разных символа (A..Z, 0..9 и пр):
Нейронная сеть соответственно, имеет 62 выхода, на входе она будет получать изображения 28х28, после распознавания «1» будет на соответствующем выходе сети.
Создаем модель сети.
Как можно видеть, это классическая сверточная сеть, выделяющая определенные признаки изображения (количество фильтров 32 и 64), к «выходу» которой подсоединена «линейная» сеть MLP, формирующая окончательный результат.
Обучение нейронной сети
Переходим к самому продолжительному этапу — обучению сети. Для этого мы возьмем базу EMNIST, скачать которую можно по ссылке (размер архива 536Мб).
Для чтения базы воспользуемся библиотекой idx2numpy. Подготовим данные для обучения и валидации.
Мы подготовили два набора, для обучения и валидации. Сами символы представляют собой обычные массивы, которые несложно вывести на экран:
Также мы используем лишь 1/10 датасета для обучения (параметр k), в противном случае процесс займет не менее 10 часов.
Запускаем обучение сети, в конце процесса сохраняем обученную модель на диск.
Сам процесс обучения занимает около получаса:
Это нужно сделать только один раз, дальше мы будем пользоваться уже сохраненным файлом модели. Когда обучение закончено, все готово, можно распознавать текст.
Распознавание
Для распознавания мы загружаем модель и вызываем функцию predict_classes.
Как оказалось, изображения в датасете изначально были повернуты, так что нам приходится повернуть картинку перед распознаванием.
Окончательная функция, которая на входе получает файл с изображением, а на выходе дает строку, занимает всего 10 строк кода:
Здесь мы используем сохраненную ранее ширину символа, чтобы добавлять пробелы, если промежуток между буквами более 1/4 символа.
Результат:
Забавная особенность — нейронная сеть «перепутала» букву «О» и цифру «0», что впрочем, неудивительно т.к. исходный набор EMNIST содержит рукописные буквы и цифры, которые не совсем похожи на печатные. В идеале, для распознавания экранных текстов нужно подготовить отдельный набор на базе экранных шрифтов, и уже на нем обучать нейросеть.
Заключение
Как можно видеть, не боги горшки обжигают, и то что казалось когда-то «магией», с помощью современных библиотек делается вполне несложно.
Поскольку Python является кроссплатформенным, работать код будет везде, на Windows, Linux и OSX. Вроде Keras портирован и на iOS/Android, так что теоретически, обученную модель можно использовать и на мобильных устройствах.
Для желающих поэкспериментировать самостоятельно, исходный код под спойлером.
Распознавание рукописных цифр на Python + GUI
Разработчики используют машинное обучение и глубокое обучение, чтобы делать компьютеры более умными. Человек учится, выполняя определенную задачу, практикуясь и повторяя ее раз за разом, запоминая, как именно это делается. После этого нейроны в мозге срабатывают автоматически и могут быстро выполнить выученную задачу.
Глубокое обучение работает по похожему принципу. В нем используются разные типы архитектуры нейронной сети в зависимости от типов проблем. Например, распознавание объектов, классификация изображений и звуков, определение объектов, сегментация изображений и так далее.
Что такое распознавание рукописных цифр?
Распознавание рукописных цифр — это способность компьютера узнавать написанные от руки цифры. Для машины это не самая простая задача, ведь каждая написанная цифра может отличаться от эталонного написания. В случае с распознаванием решением является то, что машина способна узнавать цифру на изображении.
О Python-проекте
В этом материале реализуем приложение для распознавания написанных от руки цифр с помощью набора данных MNIST. Используем специальный тип глубокой нейронной сети, которая называется сверточной нейронной сетью. А в конце создадим графический интерфейс, в котором можно будет рисовать цифру и тут же ее узнавать.
Требования
Для этого проекта нужны базовые знания программирования на Python, библиотеки Keras для глубокого обучения и библиотеки Tkinter для создания графического интерфейса.
Набор данных MNIST
Это, наверное, один из самых популярных наборов данных среди энтузиастов, работающих в сфера машинного обучения и глубокого обучения. Он содержит 60 000 тренировочных изображений написанных от руки цифр от 0 до 9, а также 10 000 картинок для тестирования. В наборе есть 10 разных классов. Изображения с цифрами представлены в виде матриц 28 х 28, где каждая ячейка содержит определенный оттенок серого.
Создание проекта на Python для распознавания рукописных цифр
1. Импорт библиотек и загрузка набор данных
Сначала нужно импортировать все модули, которые потребуются для тренировки модели. Библиотека Keras уже включает некоторые из них. В их числе и MNIST. Таким образом можно запросто импортировать набор и начать работать с ним. Метод mnist.load_data() возвращает тренировочные данные, их метки и тестовые данные с метками.
2. Предварительная обработка данных
3. Создание модели
4. Тренировка модели
Функция model.fit() в Keras начнет тренировку модели. Она принимает тренировочные, валидационные данные, эпохи ( epoch ) и размер батча ( batch ).
5. Оценка модели
В наборе данных есть 10 000 изображений, которые используются для оценки качества работы модели. Тестовые данные не используются во время тренировки, поэтому являются новыми для модели. Набор MNIST хорошо сбалансирован, поэтому можно рассчитывать на точность около 99%.
6. Создание графического интерфейса для предсказания цифр
Для графического интерфейса создадим новый файл, в котором будет интерактивное окно для рисования цифр на полотне и кнопка, отвечающая за процесс распознавания. Библиотека Tkinter является частью стандартной библиотеки Python. Функция predict_digit() принимает входящее изображение и затем использует натренированную сеть для предсказания.
Дальше весь код из файла gui_digit_recognizer.py :
Получится: 
Выводы
Проект для распознавания рукописных цифр на Python готов. Была создана и натренирована сверточная нейронная сеть, которая идеально подходит для классификации изображений. Наконец, был реализован графический интерфейс, который используется для рисования и представления результата предсказания цифры.
Нейронная сеть на практике с Python и Keras
Что такое машинное обучение и почему это важно?
Машинное обучение — это область искусственного интеллекта, использующая статистические методы, чтобы предоставить компьютерным системам способность «учиться». То есть постепенно улучшать производительность в конкретной задаче, с помощью данных без явного программирования. Хороший пример — то, насколько эффективно (или не очень) Gmail распознает спам или насколько совершеннее стали системы распознавания голоса с приходом Siri, Alex и Google Home.
С помощью машинного обучения решаются следующие задачи:
Машинное обучение — огромная область, и сегодня речь пойдет лишь об одной из ее составляющих.
Обучение с учителем
Обучение с учителем — один из видов машинного обучения. Его идея заключается в том, что систему сначала учат понимать прошлые данные, предлагая много примеров конкретной проблемы и желаемый вывод. Затем, когда система «натренирована», ей можно давать новые входные данные для предсказания выводов.
Например, как создать спам-детектор? Один из способов — интуиция. Можно вручную определять правила: например «содержит слово деньги» или «включает фразу Western Union». И пусть иногда такие системы работают, в большинстве случаев все-таки сложно создать или определить шаблоны, опираясь исключительно на интуицию.
С помощью обучения с учителем можно тренировать системы изучать лежащие в основе правила и шаблоны за счет предоставления примеров с большим количеством спама. Когда такой детектор натренирован, ему можно дать новое письмо, чтобы он попытался предсказать, является ли оно спамом.
Обучение с учителем можно использовать для предсказания вывода. Есть два типа проблем, которые решаются с его помощью: регрессия и классификация.
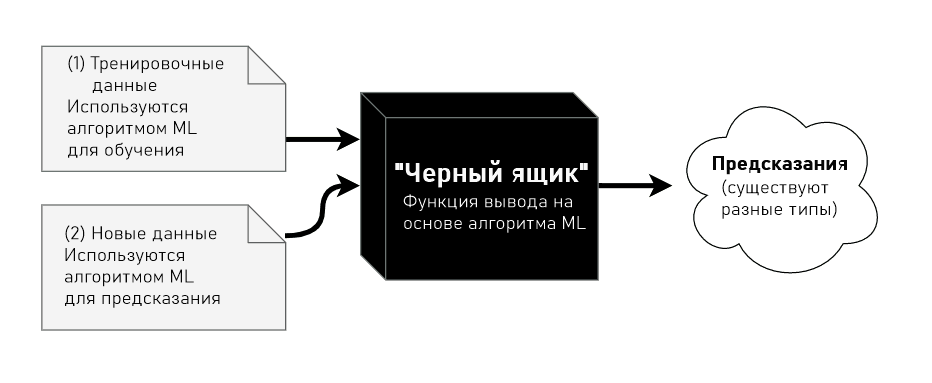
Невозможно говорить о машинном обучении с учителем, не затронув модели обучения с учителем. Это как говорить о программировании, не касаясь языков программирования или структур данных. Модели обучения — это те самые структуры, что поддаются тренировке. Их вес (или структура) меняется по мере того, как они формируют понимание того, что нужно предсказывать. Есть несколько видов моделей обучения, например:
В этом материале в качестве модели будет использоваться нейронная сеть.
Понимание работы нейронных сетей
Нейронные сети получили такое название, потому что их внутренняя структура должна имитировать человеческий мозг. Последний состоит из нейронов и синапсов, которые их соединяют. В момент стимуляции нейроны «активируют» другие с помощью электричества.
Каждый нейрон «активируется» в первую очередь за счет вычисления взвешенной суммы вводных данных и последующего результата с помощью результирующей функции. Когда нейрон активируется, он в свою очередь активирует остальные, которые выполняют похожие вычисления, вызывая цепную реакцию между всеми нейронами всех слоев.
Стоит отметить, что пусть нейронные сети и вдохновлены биологическими, сравнивать их все-таки нельзя.
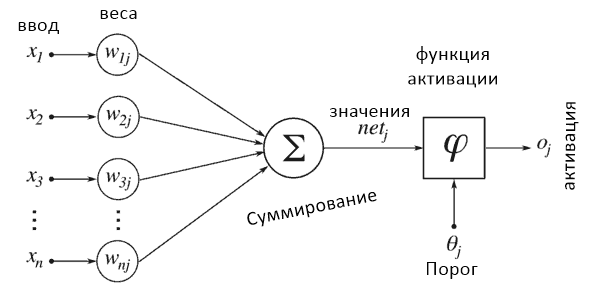
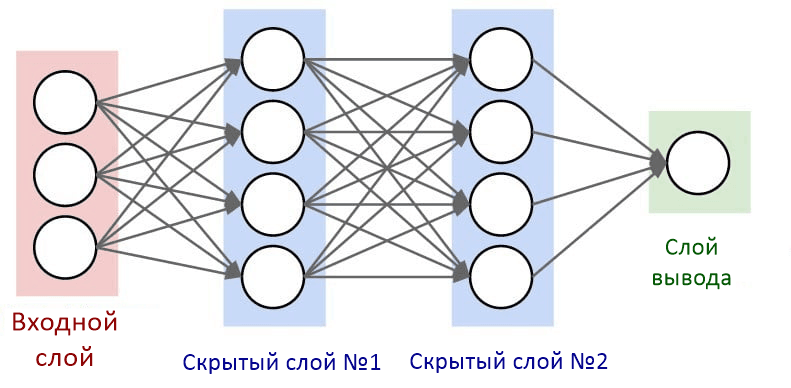
Слои нейронной сети
Нейроны внутри нейронной сети организованы в слои. Слои — это способ создать структуру, где каждый содержит 1 или большее количество нейронов. В нейронной сети обычно 3 или больше слоев. Также всегда определяются 2 специальных слоя, которые выполняют роль ввода и вывода.
Слои между ними описываются как «скрытые слои». Именно там происходят все вычисления. Все слои в нейронной сети кодируются как признаковые описания.
Выбор количества скрытых слоев и нейронов
Нет золотого правила, которым стоит руководствоваться при выборе количества слоев и их размера (или числа нейронов). Как правило, стоит попробовать как минимум 1 такой слой и дальше настраивать размер, проверяя, что работает лучше всего.
Использование библиотеки Keras для тренировки простой нейронной сети, которая распознает рукописные цифры
Программистам на Python нет необходимости заново изобретать колесо. Такие библиотеки, как Tensorflow, Torch, Theano и Keras уже определили основные структуры данных для нейронной сети, оставив необходимость лишь декларативно описать структуру нейронной сети.
Keras предоставляет еще и определенную свободу: возможность выбрать количество слоев, число нейронов, тип слоя и функцию активации. На практике элементов довольно много, но в этот раз обойдемся более простыми примерами.
Как уже упоминалось, есть два специальных уровня, которые должны быть определены на основе конкретной проблемы: размер слоя ввода и размер слоя вывода. Все остальные «скрытые слои» используются для изучения сложных нелинейных абстракций задачи.
В этом материале будем использовать Python и библиотеку Keras для предсказания рукописных цифр из базы данных MNIST.
Запуск Jupyter Notebook локально
Список необходимых библиотек:
Запуск из интерпретатора Python
Для запуска чистой установки Python (любой версии старше 3.6) установите требуемые модули с помощью pip.
Рекомендую (но не обязательно) запускать код в виртуальной среде.
Если эти модули установлены, то теперь можно запускать весь код в проекте.
База данных MNIST
MNIST — это огромная база данных рукописных цифр, которая используется как бенчмарк и точка знакомства с машинным обучением и системами обработки изображений. Она идеально подходит, чтобы сосредоточиться именно на процессе обучения нейронной сети. MNIST — очень чистая база данных, а это роскошь в мире машинного обучения.
Натренировать систему, классифицировать каждое соответствующим ярлыком (изображенной цифрой). С помощью набора данных из 60 000 изображений рукописных цифр (представленных в виде изображений 28х28 пикселей, каждый из которых является градацией серого от 0 до 255).
Набор данных
Набор данных состоит из тренировочных и тестовых данных, но для упрощения здесь будет использоваться только тренировочный. Вот так его загрузить:

Чтение меток
Файл ярлыка тренировочного набора (train-labels-idx1-ubyte):
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | label |
Значения меток от 0 до 9.
Первые 8 байт (или первые 2 32-битных целых числа) можно пропустить, потому что они содержат метаданные файлы, необходимые для низкоуровневых языков программирования. Для парсинга файла нужно проделать следующие операции:
Примечание: если этот файл из непроверенного источника, понадобится куда больше проверок. Но предположим, что этот конкретный является надежным и подходит для целей материала.
Чтение изображений
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 0017 | unsigned byte | ?? | pixel |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | pixel |
Чтение изображений немного отличается от чтения меток. Первые 16 байт содержат уже известные метаданные. Их можно пропустить и переходить сразу к чтению изображений. Каждое из них представлено в виде массива 28*28 из байтов без знака. Все что требуется — читать по одному изображению за раз и сохранять их в массив.
Кодирование меток изображения с помощью One-hot encoding
Будем использовать one-hot encoding для превращения целевых меток в вектор.
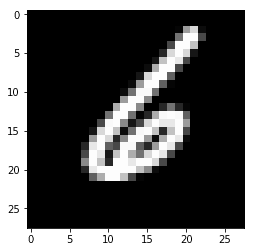
В примере выше явно видно, что изображение с индексом 999 представляет цифру 6. Ассоциированный с ним вектор содержит 10 цифр (поскольку имеется 10 меток), а цифра с индексом 6 равно 1. Это значит, что метка правильная.
Разделение датасета на тренировочный и тестовый
Для проверки того, что нейронная сеть была натренирована правильно, берем определенный процент тренировочного набора (60 000 изображений) и используем его в тестовых целях.
Здесь видно, что весь набор из 60 000 изображений бал разбит на два: один с 45 000, а другой с 15 000 изображений.
Тренировка нейронной сети с помощью Keras
Для обучения нейронной сети, выполним этот код.
Проверяем точность на тренировочных данных.
Посмотрим результаты
Вот вы и натренировали нейронную сеть для предсказания рукописных цифры с точностью выше 90%. Проверим ее с помощью изображения из тестового набора.
Возьмем случайное изображение — картинку с индексом 1010. Берем предсказанную метку (в данном случае — 4, потому что на пятой позиции стоит цифра 1)
array([0., 0., 0., 0., 1., 0., 0., 0., 0., 0.])
Построим изображения соответствующей картинки
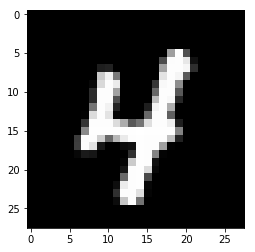
Понимание вывода активационного слоя softmax
Пропустим цифру через нейронную сеть и посмотрим, какой вывод она предскажет.
Вывод слоя softmax — это распределение вероятностей для каждого вывода. В этом случае их может быть 10 (цифры от 0 до 9). Но ожидается, что каждое изображение будет соответствовать лишь одному.
Поскольку это распределение вероятностей, их сумма приблизительно равна 1 (единице).
Чтение вывода слоя softmax для конкретной цифры
Как можно видеть дальше, 5-ой индекс действительно близок к 1 (0,99), а это значит, что он с большой долей вероятности является
4… а это так и есть!
Просмотр матрицы ошибок

Выводы
В течение этого руководства вы должны были разобраться с основными концепциями, которые составляют основу машинного обучения, а также научиться:
Библиотеки Sci-Kit Learn и Keras значительно понизили порог входа в машинное обучение — так же, как Python снизил порог знакомства с программированием. Однако потребуются годы (или десятилетия), чтобы достичь экспертного уровня!
Программисты, обладающие навыками машинного обучения, очень востребованы. С помощью упомянутых библиотек и вводных материалов о практических аспектах машинного обучения у всех должна быть возможность познакомиться с этой областью знаний. Даже если теоретических знаний о модели, библиотеке или фреймворке нет.
Затем навыки нужно использовать на практике, разрабатывая более умные продукты, что сделает потребителей более вовлеченными.
Попробуйте сами
Вот что вы можете попробовать сделать сами, чтобы углубиться в мир машинного обучения с Python: