Кодирование и декодирование Base64 с помощью C++
Base64 — это набор символов из 64 символов, каждый из которых состоит из 6 бит. Все эти 64 символа являются печатными. Персонаж — это символ. Таким образом, каждый символ набора символов base 64 состоит из 6 бит. Такие шесть битов называются секстетом. Байт или октет состоит из 8 бит. Набор символов ASCII состоит из 127 символов, некоторые из которых не печатаются. Таким образом, некоторые символы набора символов ASCII не являются символами. Символ для набора символов ASCII состоит из 8 бит.
Данные в компьютере хранятся в байтах по 8 бит каждый.
Поток байтов можно преобразовать в поток секстетов (6 бит на символ). И это кодировка base64. Поток секстетов можно преобразовать в поток байтов. И это декодирование base64. Другими словами, поток символов ASCII может быть преобразован в поток символов секстета. Это кодирование, а обратное — декодирование. Поток символов секстета, преобразованный из потока символов октета (байта), по номеру длиннее потока символов октета. Другими словами, поток символов base64 длиннее, чем соответствующий поток символов ASCII. Ну, кодирование в base64 и декодирование из него не так просто, как только что выразилось.
В этой статье объясняется кодирование и декодирование Base64 с помощью компьютерного языка C ++. В первой части статьи объясняется правильное кодирование и декодирование base64. Во второй части показано, как можно использовать некоторые функции C ++ для кодирования и декодирования base64. В этой статье слова «октет» и «байт» используются как синонимы.
Переход на Base 64
Алфавит или набор символов из 2 символов может быть представлен одним битом на символ. Пусть символы алфавита состоят из нуля и единицы. В этом случае ноль — это бит 0, а единица — это бит 1.
Алфавит или набор символов из 4 символов может быть представлен двумя битами на символ. Пусть символы алфавита состоят из: 0, 1, 2, 3. В этой ситуации 0 равно 00, 1 равно 01, 2 равно 10, а 3 равно 11.
Алфавит из 8 символов может быть представлен тремя битами на символ. Пусть символы алфавита состоят из: 0, 1, 2, 3, 4, 5, 6, 7. В этой ситуации 0 — 000, 1 — 001, 2 — 010, 3 — 011, 4 — 100, 5 — 101., 6 — 110 и 7 — 111.
Алфавит из 16 символов может быть представлен четырьмя битами на символ. Пусть символы алфавита состоят из: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F. В этой ситуации 0 — это 0000, 1 — 0001., 2 — 0010, 3 — 0011, 4 — 0100, 5 — 0101, 6 — 0110, 7 — 0111, 8 — 1000, 9 — 1001, A — 1010, B — 1011, C — 1100, D — 1101, E равно 1110, а F — 1111.
Алфавит из 32 различных символов может быть представлен пятью битами на символ.
Это приводит нас к алфавиту из 64 различных символов. Алфавит из 64 различных символов может быть представлен шестью битами на символ. Существует особый набор символов из 64 различных символов, называемый base64. В этом наборе первые 26 символов — это 26 заглавных букв разговорного английского языка в указанном порядке. Эти 26 символов представляют собой первые двоичные числа от 0 до 25, где каждый символ представляет собой секстет из шести битов. Следующие двоичные числа от 26 до 51 — это 26 строчных букв английского разговорного языка в их порядке; опять же, каждый символ, секстет. Следующие двоичные числа от 52 до 61 — это 10 арабских цифр в их порядке; тем не менее, каждый символ — секстет.
Двоичное число 62 соответствует символу +, а двоичное число 63 — символу /. У Base64 есть разные варианты. Таким образом, некоторые варианты имеют разные символы для двоичных чисел 62 и 63.
Таблица base64, показывающая соответствия индекса, двоичного числа и символа:
Алфавит Base64
| Index | Binary | Char | Index | Binary | Char | Index | Binary | Char | Index | Binary | Char |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 000000 | A | 16 | 010000 | Q | 32 | 100000 | g | 48 | 110000 | w | |
| 1 | 000001 | B | 17 | 010001 | R | 33 | 100001 | h | 49 | 110001 | x |
| 2 | 000010 | C | 18 | 010010 | S | 34 | 100010 | i | 50 | 110010 | y |
| 3 | 000011 | D | 19 | 010011 | T | 35 | 100011 | j | 51 | 110011 | z |
| 4 | 000100 | E | 20 | 010100 | U | 36 | 100100 | k | 52 | 110100 | |
| 5 | 000101 | F | 21 | 010101 | V | 37 | 100101 | l | 53 | 110101 | 1 |
| 6 | 000110 | G | 22 | 010110 | W | 38 | 100110 | m | 54 | 110110 | 2 |
| 7 | 000111 | H | 23 | 010111 | X | 39 | 100111 | n | 55 | 110111 | 3 |
| 8 | 001000 | I | 24 | 011000 | Y | 40 | 101000 | o | 56 | 111000 | 4 |
| 9 | 001001 | J | 25 | 011001 | Z | 41 | 101001 | p | 57 | 111001 | 5 |
| 10 | 001010 | K | 26 | 011010 | a | 42 | 101010 | q | 58 | 111010 | 6 |
| 11 | 001011 | L | 27 | 011011 | b | 43 | 101011 | r | 59 | 111011 | 7 |
| 12 | 001100 | M | 28 | 011100 | c | 44 | 101100 | s | 60 | 111100 | 8 |
| 13 | 001101 | N | 29 | 011101 | d | 45 | 101101 | t | 61 | 111101 | 9 |
| 14 | 001110 | O | 30 | 011110 | e | 46 | 101110 | u | 62 | 111110 | + |
| 15 | 001111 | P | 31 | 011111 | f | 47 | 101111 | v | 63 | 111111 | / |
На самом деле символов 65. Последним символом является =, двоичное число которого по-прежнему состоит из 6 битов, то есть 111101. Он не конфликтует с символом base64, равным 9 — см. Ниже.
Кодирование битовых полей Sextet Base64
Это слово состоит из трех байтов ASCII:
присоединился. Это 3 октета, но они состоят из 4 секстетов следующим образом:
Из приведенной выше таблицы алфавита base64 эти 4 секстета являются символами,
Обратите внимание, что кодировка «dog» в base64 — «ZG9n», что непонятно.
Base64 кодирует последовательность из 3 октетов (байтов) в последовательность из 4 секстетов. 3 октета или 4 секстета составляют 24 бита.
Рассмотрим теперь следующее слово:
Для этого слова есть два октета ASCII:
присоединился. Это 2 октета, но они состоят из 2 секстетов и 4 битов. Поток символов base64 состоит из секстетов (6 бит на символ). Итак, к этим 16 битам нужно добавить два нулевых бита, чтобы получить 3 секстета, то есть:
Это еще не все. Последовательность Base64 состоит из 4 секстетов на группу; то есть 24 бита на группу. Знак заполнения = 111101. Два нулевых бита уже добавлены к 16 битам, чтобы получить 18 бит. Таким образом, если 6 битов заполнения символа заполнения добавляются к 18 битам, то при необходимости будет 24 бита. То есть:
Последние шесть битов последнего секстета — это дополнительный секстет =. Эти 24 бита состоят из 4 секстетов, из которых предпоследний секстет имеет первые 4 бита символа base64, за которыми следуют два нулевых бита.
Теперь рассмотрим следующее односимвольное слово:
Для этого слова есть один октет ASCII:
Это 1 октет, но состоит из 1 секстета и 2 бит. Поток символов base64 состоит из секстетов (6 бит на символ). Итак, к этим 8 битам нужно добавить четыре нулевых бита, чтобы получить 2 секстета, то есть:
Это еще не все. Последовательность Base64 состоит из 4 секстетов на группу; то есть 24 бита на группу. Знак заполнения = 111101, что составляет шесть битов. К 8 битам уже добавлено четыре нулевых бита, чтобы получить 12 бит. Это не до четырех секстетов. Итак, нужно добавить еще два дополнительных секстета, чтобы получилось 4 секстета, а именно:
Выходной поток Base64
В программе должен быть составлен массив символов алфавита base64, где индекс 0 имеет символ из 8 бит, A; индекс 1 имеет разряд 8 бит, B; индекс 2 имеет символ из 8 бит, C, до тех пор, пока индекс 63 не станет символом из 8 бит, /.
Таким образом, на выходе для слова из трех символов «собака» будет «ZG9n» из четырех байтов, выраженных в битах как
где Z — 01011010 из 8 бит; G — 01000111 из 8 бит; 9 — это 00111001 из 8 бит, а n — это 01101110 из 8 бит. Это означает, что из трех байтов исходной строки выводятся четыре байта. Эти четыре байта являются значениями массива алфавита base64, где каждое значение является байтом.
На выходе для слова из двух символов «it» будет «aXQ =» из четырех байтов, выраженное в битах как
полученный из массива. Это означает, что из двух байтов по-прежнему выводятся четыре байта.
Для слова из одного символа «I» выводом будет «SQ ==» из четырех байтов, выраженное в битах как
Это означает, что из одного байта по-прежнему выводятся четыре байта.
Секстет 61 (111101) выводится как 9 (00111001). Секстет = (111101) выводится как = (00111101).
Новая длина
Здесь необходимо рассмотреть три ситуации, чтобы оценить новую длину.
Максимальная длина линии
После перехода от исходной строки к массиву алфавита base64 и получения октетов длиной не менее 133,33% ни одна строка вывода не должна быть длиннее 76 октетов. Если длина выходной строки составляет 76 символов, необходимо добавить символ новой строки до того, как будут добавлены еще 76 октетов, или будет добавлено меньше символов. В длинной выходной строке есть все разделы, состоящие из 76 символов каждый, кроме последнего, если его длина не превышает 76 символов. Программисты-разделители строк, скорее всего, используют символ новой строки ’\ n’; но предполагается, что это «\ r \ n».
Декодирование Base64
Для декодирования выполните обратное кодирование. Используйте следующий алгоритм:
Ошибка передачи
На принимающей стороне любой символ, кроме символа разделения строк или символов, который не является значением массива алфавита base64, указывает на ошибку передачи; и с ними нужно обращаться. В этой статье не рассматривается обработка ошибок передачи. Примечание. Наличие байта = среди 76 символов не является ошибкой передачи.
Возможности C ++ Bit
Фундаментальным членам элемента структуры может быть присвоено число битов, отличное от 8. Следующая программа иллюстрирует это:
Decode from Base64 format
Decode files from Base64 format
Meet Base64 Decode and Encode, a simple online tool that does exactly what it says: decodes from Base64 encoding as well as encodes into it quickly and easily. Base64 encode your data without hassles or decode it into a human-readable format.
Base64 encoding schemes are commonly used when there is a need to encode binary data, especially when that data needs to be stored and transferred over media that are designed to deal with text. This encoding helps to ensure that the data remains intact without modification during transport. Base64 is used commonly in a number of applications including email via MIME, as well as storing complex data in XML or JSON.
All communications with our servers come through secure SSL encrypted connections (https). We delete uploaded files from our servers immediately after being processed and the resulting downloadable file is deleted right after the first download attempt or 15 minutes of inactivity (whichever is shorter). We do not keep or inspect the contents of the submitted data or uploaded files in any way. Read our privacy policy below for more details.
Our tool is free to use. From now on, you don’t need to download any software for such simple tasks.
Details of the Base64 encoding
Base64 is a generic term for a number of similar encoding schemes that encode binary data by treating it numerically and translating it into a base-64 representation. The Base64 term originates from a specific MIME-content transfer encoding.
The particular choice of characters to make up the 64 characters required for Base64 varies between implementations. The general rule is to choose a set of 64 characters that is both 1) part of a subset common to most encodings, and 2) also printable. This combination leaves the data unlikely to be modified in transit through systems such as email, which were traditionally not 8-bit clean. For example, MIME’s Base64 implementation uses A-Z, a-z, and 0-9 for the first 62 values, as well as «+» and «/» for the last two. Other variations, usually derived from Base64, share this property but differ in the symbols chosen for the last two values; an example is the URL and filename safe «RFC 4648 / Base64URL» variant, which uses «-» and «_».
Here’s a quote snippet from Thomas Hobbes’s Leviathan:
This is represented as an ASCII byte sequence and encoded in MIME’s Base64 scheme as follows:
In the above quote the encoded value of Man is TWFu. Encoded in ASCII, the letters «M», «a», and «n» are stored as the bytes 77, 97, 110, which are equivalent to «01001101», «01100001», and «01101110» in base-2. These three bytes are joined together in a 24 bit buffer producing the binary sequence «010011010110000101101110». Packs of 6 bits (6 bits have a maximum of 64 different binary values) are converted into 4 numbers (24 = 4 * 6 bits) which are then converted to their corresponding values in Base64.
Расшифровка 64 битного кода
В Base64 данные делятся на 6 бит и преобразуются в буквенно-цифровые символы (A-Z, a-z, 0-9) и символы (+, /). Преобразует каждые 4 символа, а если последний меньше 4 символов, заполните его символом равенства (=).
Кроме того, RFC 1421 (PEM: Privacy-Enhanced Mail) предусматривает перерыв каждые 64 символа, а RFC 2045 (MIME) предусматривает перерыв каждые 76 символов.
Таблица преобразования для символов Base64 выглядит следующим образом.
| 5-битные данные | Base32 символа |
|---|---|
| 000000 | A |
| 000001 | B |
| 000010 | C |
| 000011 | D |
| 000100 | E |
| 000101 | F |
| 000110 | G |
| 000111 | H |
| 001000 | I |
| 001001 | J |
| 001010 | K |
| 001011 | L |
| 001100 | M |
| 001101 | N |
| 001110 | O |
| 001111 | P |
| 010000 | Q |
| 010001 | R |
| 010010 | S |
| 010011 | T |
| 010100 | U |
| 010101 | V |
| 010110 | W |
| 010111 | X |
| 011000 | Y |
| 011001 | Z |
| 011010 | a |
| 011011 | b |
| 011100 | c |
| 011101 | d |
| 011110 | e |
| 011111 | f |
| 100000 | g |
| 100001 | h |
| 100010 | i |
| 100011 | j |
| 100100 | k |
| 100101 | l |
| 100110 | m |
| 100111 | n |
| 101000 | o |
| 101001 | p |
| 101010 | q |
| 101011 | r |
| 101100 | s |
| 101101 | t |
| 101110 | u |
| 101111 | v |
| 110000 | w |
| 110001 | x |
| 110010 | y |
| 110011 | z |
| 110100 | 0 |
| 110101 | 1 |
| 110110 | 2 |
| 110111 | 3 |
| 111000 | 4 |
| 111001 | 5 |
| 111010 | 6 |
| 111011 | 7 |
| 111100 | 8 |
| 111101 | 9 |
| 111110 | + |
| 111111 | — |
Например, если вы конвертируете «Hello» с помощью Base64, это будет следующим образом.
1. Сделайте это двоичным представлением.
2. Разделять каждые 6 бит. Если он меньше 6 бит, дополните его «0» в конце.
3. Преобразуйте в символы с помощью таблицы преобразования. Преобразуйте каждые 4 символа, и если оно меньше 4 символов, дополните конец знаком «=».
4. Соедините все символы, чтобы получить результат преобразования Base64.
Формат заголовка сообщения электронной почты MIME (RFC 2047)
DenCode также поддерживает декодирование формата заголовка сообщения MIME (RFC 2047), как показано ниже. Этот формат используется, когда тема, получатель и т. Д. Электронного письма содержат символы, отличные от ASCII.
SGVsbG8gd29ybGQh или история base64
Краткая предыстория
Вообще, все началось давно. Настолько давно, что вряд ли остались свидетели holy wars тех дней, когда решалось — сколько же бит должно быть в байте.
Это сейчас нам кажется само собой разумеющимся, что 1 байт = 8 бит, что в байте можно закодировать 256 различных значений. Но когда-то было совсем не так. История помнит и семибитные кодировки, и шестибитные, и даже более экзотические системы (например — ЭВМ «Сетунь», которая использовала троичную логику, то есть один троичный бит — трит мог иметь три, а не два значения, для нее было справедливо соотношение 1 трайт = 6 тритам). Но если оставить в стороне всякую экзотику, то мэйнстримом все-таки были кодировки, в которых 6, 7 или 8 бит в байте.
Шестибитная кодировка (например — BCD) позволяла закодировать в одном байте 64 различных значения, что, как казалось, было вполне достаточно для кодирования алфавитно-цифровых символов, а «лишний» седьмой бит расширял кодировку уже до 128 символов.
Однако скоро восьмибитный байт стал общепринятым.
Проблема восьмого бита
Утверждение восьмибитных кодировок как стандарта де-факто принесло много проблем. К этому моменту уже существовала определенная инфраструктура, использующая именно семибитные кодировки, и holy wars разгорелись с новой силой.
До нас они дошли в виде проблем с «обрезанием восьмого бита» в системе электронной почты. Утверждение восьмибитного байта дало 256 различных значений для одного байта, что, в свою очередь позволило уместить в одной кодовой таблице и общепринятые символы (цифры, знаки препинания, латиницу) и символы, скажем кириллицы. Казалось бы — сплошное удобство, текст можно набирать хоть русскими буквами, хоть английскими, а если нужно — и для немецких умлаутов место найдется!
Но, как всегда, дьявол крылся в деталях. Уже накопленный и работающий хард-н-софт зачастую был приспособлен для кодировок семибитных, что приводило к разнообразным проблемам.
Например, почтовый сервер при передаче письма мог совершенно спокойно обнулить старшие биты в каждом байте сообщения, что не могло не привести к проблемам, зачастую информация просто катастрофически терялась.
Для временного решения этой проблемы было предложено несколько вариантов. Одним из них стала кодировка «КОИ-8». Решение, нужно признать, весьма элегантное — в этой кодировке русские буквы располагались по порядку латинских и отличались от них ровно на тот самый старший бит. Таким образом при обрезании этого бита русская «А» превращалась в латинскую «A», «Б» — в «B» и так далее, сообщение просто транслитерировалось и его все-таки можно было прочитать. Правда, и тут не обошлось без скелета в шкафу — сортировка в русском алфавитном порядке в «КОИ» становилась кошмаром…
А что было делать другим языкам, народам и кодировкам? А бинарные данные? Все равно кодировки с транслитерацией не решали фундаментальную проблему — потерю восьмого бита, потерю части информации. Так родилась кодировка (а точнее — алгоритм) Base64.
Алгоритм Base64
Идея base64 проста — обратимое кодирование, с возможностью восстановления, которое переводит все символы восьмибитной кодовой таблицы в символы, гарантированно сохраняющиеся при передаче данных в любых сетях и между любыми устройствами.
В основе алгоритма лежит сведение трех восьмерок битов (24) к четырем шестеркам (тоже 24) и представление этих шестерок в виде символов ASCII. Таким образом получается обратимое шифрование, единственным недостатком которого будет увеличивающийся при кодировании размер — в соотношении 4:3.
Пример:
Возьмем текст русский текст «АБВГД». В двоичной форме в кодировке Windows-1251 мы получим 5 байтов:
11000000
11000001
11000010
11000011
11000100
(00000000) — лишний нулевой байт нужен, чтобы общее число бит делилось на 6
Разделим эти биты на группы по 6:
110000
001100
000111
000010
110000
111100
010000
000000
Берем массив символов «ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/» и получившиеся числа переводим в эти символы, используя их, как индексы массива, получаем «wMHCw8Q». Остается только добавить в конце один символ «=», как указание на один лишний нулевой байт, который мы добавляли на первом шаге и получить окончательный результат:
«АБВГД»: base64 = «wMHCw8Q=»
Обратное преобразование не менее легко, попробуйте, например, расшифровать то, что вынесено в заголовок этой статьи.
Применение
Алгоритм base64 и по сей день применяется там, где нет возможности гарантировать бережного обращения с вашей информацией — например при кодировании вложений электронной почты. В PGP алгоритм base64 используется для кодирования бинарных данных.
Можно представить себе и другие применения base64 — например при сохранении в базу данных, если заранее неизвестно окружение (ох уж эти magic_qoutes в PHP!) и нет необходимости в индексации и поиске по тексту, можно воспользоваться base64.
base64 вполне может использоваться для получения хэшей, например по алгоритму md5, как средство против табличного подбора хэша, если данные, например пароль пользователя в системе, предварительно будут преобразованы в base64.
Мануал по методу кодирования base 16/32/64.
История появления кодировки.
Кодировка base берет свое начало еще с тех времен, когда не было определено сколько бит должно содержаться в одном байте. Сейчас всем известно, что в одном байте содержится 8 бит и с помощью него можно закодировать 256 различных значений, но так было не всегда.
Раньше были популярны кодировки, содержащие 6, 7 или 8 бит в байте. Таким образом, 6 бит позвояло закодировать в одном байте 64 различных значения, а 7-ми битная кодировка 128 значений. Казалось бы, что этого достаточно для того, чтобы закодировать буквенно-цифровой алфавит. Но вскоре была принята кодировка, содержащая 8 бит в одном байте.
Такая кодировка привнесла много проблем. В первую очередь, эти проблемы были связаны с оборудованием, которое уже работало на других кодировках, где байт содержал 6 или 7 бит. Но помимо этого была проблема обрезания 8-го бита в системах электронной почты, т.к. весь сфот был заточен под 7-ми или 6-ти битную кодировку. Как пример, 7-ми битная кодировка могла спокойно обнулить каждый 8-ой бит, что приводило к потери данных.
Тут на помощь пришел base 64. Идея base64 проста — обратимое кодирование, с возможностью восстановления, которое переводит все символы восьмибитной кодовой таблицы в символы, гарантированно сохраняющиеся при передаче данных в любых сетях и между любыми устройствами. В основе алгоритма лежит сведение трех восьмерок битов (24) к четырем шестеркам (тоже 24) и представление этих шестерок в виде символов ASCII. Таким образом получается обратимое шифрование, единственным недостатком которого будет увеличивающийся при кодировании размер — в соотношении 4:3.
Ниже приведена схема смещения битов в base 64
Пример:
Возьмем русский текст «АБВГД». В двоичной форме в кодировке Windows-1251 мы получим 5 байтов: 11000000 11000001 11000010
11000011 11000100 (00000000) — лишний нулевой байт нужен, чтобы общее число бит делилось на 6
Разделим эти биты на группы по 6: 110000 001100 000111 000010
110000 111100 010000 000000
Берем массив символов «ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/» и получившиеся числа переводим в эти символы, используя их, как индексы массива, получаем «wMHCw8Q». Остается только добавить в конце один символ «=», как указание на один лишний нулевой байт, который мы добавляли на первом шаге и получить окончательный результат: «АБВГД»: base64 = «wMHCw8Q=» Возможно и обратное преобразование.
Base 16
Base 32
Base 32 использует 32 символа: A-Z (или a-z), 2-7. Может содержать в конце кодированной последовательности несколько спецсимволов (по аналогии с base64). В данном алгоритме преобразования нам необходимо будет разделять двоичные значения на группы по 5 бит.
Основные отличия кодировок
Base64
Позволяет кодировать информацию, представленную набором байтов, используя всего 64 символа: A-Z, a-z, 0-9, /, +. В конце кодированной последовательности может содержаться несколько спецсимволов (обычно “=”).
Преимущества: Позволяет представить последовательность любых байтов в печатных символах. В сравнении с другими Base-кодировками дает результат, который составляет только 133.(3)% от длины исходных данных.
Недостатки: Регистрозависимая кодировка.
Base32
Использует только 32 символа: A-Z (или a-z), 2-7. Может содержать в конце кодированной последовательности несколько спецсимволов (по аналогии с base64).
Преимущества: Последовательность любых байтов переводит в печатные символы. Регистронезависимая кодировка. Не используются цифры, слишком похожие на буквы (например, 0 похож на О, 1 на l).
Недостатки: Кодированные данные составляют 160% от исходных.
Как закодировать/декодировать base?
В основном в заданиях по ctf вам будет попадаться base 64. Его легко определить, т.к. на конце будет знак «=». Например, мы кодировали строку «АБВГД» в base 64 и у нас получился результат «wMHCw8Q=». Как мы видим, здесь присутсвует знак «=», который говорит нам о том, что строка зашифрована в base 64.
Итак, как же ее декодировать? Все очень просто. Base 16, 32, 64 легко декодировать онлайн-сервисами. Т.е. вбиваете в гугле подобный запрос:»base 64 online decoder» и вам будет выдан большой перечнь ссылок на онлайн декодеры. Берем первый попавшийся, разве что для уточнения стоит воспользоваться сразу несколькимим онлайн декодерами.
Процесс кодирования почти ничем не отличается, разве, что вам нужно вбить в запросе не «decode», а «encrypt». Бывает, что нужно обращать внимание на то, какой кодировкой вы пользуетесь. В русскоязычной версии ОС «Windows» обычно используется кодировка windows-1251.
Практика
Задание 1:
Взгляните на эту строку:
ZmxhZ2lzVzBXdGhpc2lzQkFTRTY0Cg==
На конце мы видим «=», причем двойное, что сразу наводит на мысль, что это base 64. Воспользуемся онлайн-декодером.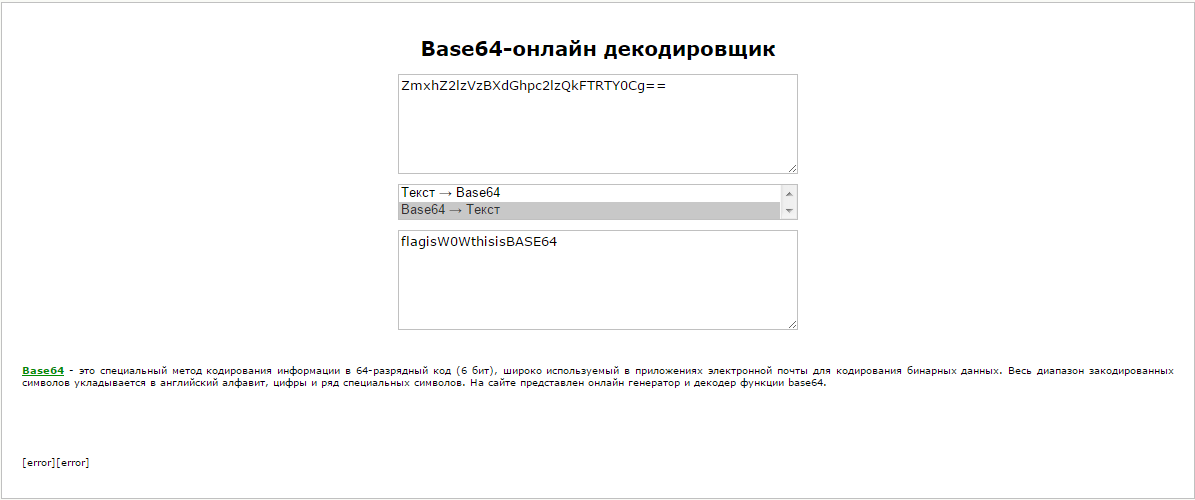
Задание 2:
Посмотрим на эту строку:
MZWGCZ33MJQXGZJTGJ6Q
На конце мы не видим знака «=». На base 16 тоже не похоже, тогда попробуем base 32.
Снова воспользуемся онлайн-декодером.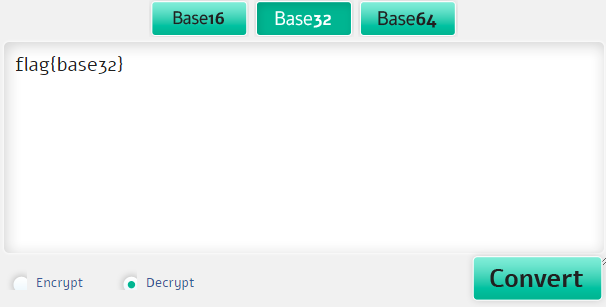
И вот наш флаг: flag
Задание 3:
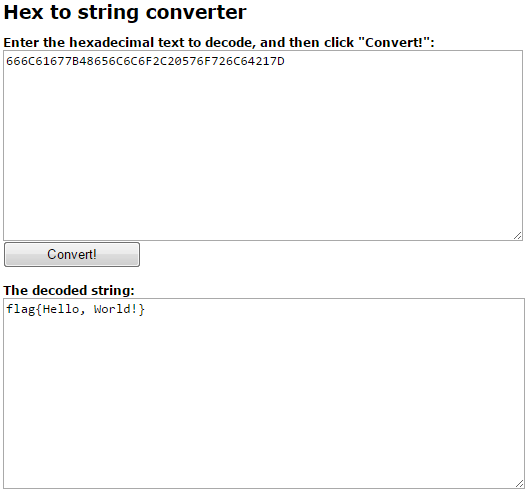
Была получена такая строка: 666C61677B48656C6C6F2C20576F726C64217D
Здесь нет ни знака «=», алфавит ограниченный. Похоже на base 16 или просто hex.
Как и прежде, пользуемся онлайн-декодером.
Отлично, у нас есть флаг, но это же задание можно было решить и через hex декодер.