
Осваиваем реактивное программирование на Java


Асинхронный ввод/вывод уже какое-то время используется в обиходе. При этом разные языки реализуют его по-разному, но все предоставляют способ уменьшить количество потоков, давая вроде бы полную конкурентность. JavaScript занимался этим с самого начала. При использовании всего одного потока будет мало хорошего, отправь вы в продакшн блокирующий вызов.
Несмотря на то, что реактивный Java все больше привле к ает интерес разработчиков, большинство знакомых мне программистов по-прежнему живут в многопоточной парадигме. Почему? Принцип потоков относительно легко усвоить. Реактивное же программирование требует переосмысления многих привычных нам принципов программирования. Попытка объяснить, почему асинхронный ввод/вывод является лучшей альтернативой, подобна попытке объяснить сферичность Земли тому, кто всегда верил в ее плоскую природу.
Я предпочитаю обучаться через игру и эксперименты, создавая “игрушечные” системы, которые затем при необходимости можно использовать в качестве основы для больших систем. Здесь я представлю одну такую базовую систему, которая продемонстрирует основы реактивного Java, используя Project Reactor. А поскольку она мала (меньше тысячи строк в девяти файлах), то и понять ее будет несложно.
Это система псевдо-микросервисов. То есть несмотря на то, что все заключено в один исполняемый файл, каждый “сервис” находится в отдельном классе, который не содержит состояния, а сами классы могут взаимодействовать друг с другом только с помощью очереди сообщений и базы данных. Их все запускает один основной класс, при этом они программируются на завершение по истечению установленного периода времени.
Моя система смоделирована на основе схемы приема подержанных транспортных средств (ТС) и начинается с заказа на покупку, который в нашем случае будет случайно генерироваться и добавляться в очередь сообщений. Другой сервис получает заказ на покупку из этой очереди, добавляет его в базу данных и отправляет информацию о типе ТС в одну из трех очередей сообщений, в зависимости от того легковой это автомобиль, грузовик или мотоцикл. В завершении есть еще три сервиса, которые считывают эти три очереди, проверяют наличие заказа в базе данных и определяют автомобилю парковочное место для транспортировки.
Функция main выступает больше в качестве функции тестирования, поскольку в настоящей системе микросервисов каждый из них должен иметь собственную функцию main или быть частью такого фреймворка, как Spring. Однако нам нужно лишь увидеть, что все согласованно работает в одной JVM. Настоящий тест этой системы заключается в наблюдении работоспособности всех сервисов по-отдельности, но я предположу, что это сработает и так либо потребует минимальных корректировок. Вот суть функции main :
Мы стартуем всех потребителей, после чего запускаем генератор заказа на покупку, который создает заказы и поочередно помещает их в очередь в течение 10 секунд. Поскольку ни у одного из классов нет состояния, все их методы могут быть статическими.
Далее метод delayElements добавляет задержку между каждым элементом. Я делаю это для симуляции появления случайных заказов с разумной скоростью. Можете без проблем его удалить, но тогда вместо выполнения системы в течение десяти секунд и завершения, она будет заполняться очередями сообщений о заказах на покупку, для обработки которых потребуется уже более двух минут. Метод take позволит Flux выполнять обработку на протяжении десяти секунд и затем останавливаться. Я так делаю, потому что этот генератор служит исключительно для тестирования. В реальной же системе заказы на покупку наверняка будут поступать из API, который будет добавлять их в очередь сообщений.
У вас голова еще не взорвалась? На это можно посмотреть так. Внутри многозадачной операционной системы нечто наблюдает за ожидающими процессами и решает, какой из них очередным получит внимание ЦПУ. Планировщик работает аналогичным образом, только ему не нужно беспокоиться о прерываниях. Все задачи, с которыми работает планировщик, представляют очень мелкие фрагменты кода. “Блокирующие” задачи вроде delayElements разбиваются на две части. Первая часть получает элемент из потока, устанавливает таймер и возвращает управление планировщику. Далее планировщик может выполнять какую-нибудь другую задачу. Как только таймер метода delayElements истекает, вызывается вторая часть и сохраненный элемент получает возможность перемещения в следующий метод цепочки.
Я рассматриваю этот процесс как две непрерывные конвейерные ленты. Первая перемещает элементы по направлению ко второй, но вторая движется намного медленнее. В итоге элементы задерживаются на первой ленте, в то время как вторая их постепенно с нее снимает. По мере накопления задерживающихся элементов возникает так называемое “обратное давление”, и система понимает, что нужно просто остановить первую ленту, пока вторая ее немного не догонит.
Осталось проговорить последний метод цепочки, остальные же аналогичны предыдущим. Если бы речь шла о реальном сервисе, то метод timeout даже не должен был бы находиться в потоке. У нас он присутствует только, чтобы отменять поток, когда в рамках заданного временного промежутка не происходит получение элемента. Это позволяет нашей небольшой игрушечной системе все закрывать и в конечном итоге завершаться.
В реальном сервисе такого бы у вас наверняка не было. Единственное исключение возможно, если сервис ожидает определенное количество элементов в секунду, и в течение нескольких минут не получает ни одного. Тогда вы можете заподозрить, что было потеряно соединение с очередью, и захотите, чтобы служба оркестровки, например Kubernetes, перезапустила ваш сервис.
Еще один вариант применения таймаута — это тестирование кода. Если ваш тест ожидает элемент из очереди сообщений, то вы можете установить таймаут так, чтобы тест не ждал бесконечно.
Я создал три класса сервисов, по одному для каждого типа; Car (легковое авто), Truck (грузовик) или Motorcycle (мотоцикл). В примере текущего кода я мог сделать один класс с рядом параметров и запустить метод получения три раза, по одному для каждого типа. Но я оставил их отдельными, так как предвидел, что для каждого типа потребуется своя логика, кардинальность типов окажется очень низка, а базовый код короче сотни строк. Если бы у сервисов было много общей логики, я бы не пожалел лишнего времени на их объединение. Но мой прагматизм иногда превосходит перфекционизм, и мне это нравится.
Чтобы все проверить, пришлось запустить CoucheBase и RabbitMQ. В обоих случаях я просто создал экземпляр Docker:
Сборка прошла успешно! Если вы соберете и запустите систему, то советую внимательно проследить за логами, все из которых выводят текущий поток. Вскоре вы заметите паттерн маленьких конвейерных лент (некоторые будут выполняться параллельно), о котором я говорил.
Надеюсь, что помог вам понять предлагаемое Project Reactor асинхронное решение ввода/вывода. Разобраться с использованием цепочек методов может быть непросто, но я верю, что, как только вы это осилите, все будет читаться намного проще. Эта техника берет нормальный декларативный стиль программирования и делает его больше похожим на императивный. Весь код моего игрушечного проекта можете найти здесь:
Реактивное программирование со Spring Boot 2. Часть 1

Не так давно вышла новая версия самого популярного фреймворка на Java: Spring Framework 5. Новая версия принесла много нового. Одно из самых больших нововведений — модель реактивного программирования. Совсем скоро выйдет Spring Boot 2, который существенно упростит создание микросервисов c данным подходом.
Если вы, как и я, хотите разобраться подробнее, что это такое и как это используется, то добро пожаловать под кат. Статья делится на две части — теоретическую и практическую. Сейчас мы постараемся разобраться, что значит быть реактивным. После чего попробуем использовать полученные знания для написания собственного микросервиса(часть 2).
Что такое реактивность?
Для начала рассмотрим понятие реактивности. И тут нужно сделать сразу четкое разраничение в определениях.
Реактивная система
Реактивная система — архитектурный паттерн, который удовлетворяет некоторому набору правил(reactive manifesto). Данный монифест был разработан в 2013 году для устранения неопределенности. Дело в том, что на тот момент в Европе и США термин «reactive» являлся слишком избыточным. Каждый понимал по-своему, какую систему можно назвать реактивной. Это рождало огромную путаницу, и в итоге был создан манифест, который устанавливает четкие критерии реактивной системы.
Посмотрим на картинку из манифеста и разберем более подробно, что означает каждый пункт:

Реактивное программирование
Если верить википедии, то реактивное программирование — парадигма программирования, ориентированная на потоки данных. Очень скоро мы разберем, как это работает на практике. Но вначале посмотрим, на чем основана данная парадигма.
Основная концепция реактивного программирования базируется на неблокирующем вводе/ввыоде. Обычно при обращении к некоторому ресурсу(базе данных, файле на диске, удаленному серверу и т.д.) мы получаем результат сразу же(часто в той же строчке). При неблокирующем обращении к ресурсу наш поток не останавливается на обращении и продолжает выполнение. Результат мы получаем позже и при необходимости.
Практика
Отлично! Теперь приступим к реализации реактивного программирования в Java. Единственное, следует заметить, что мы будем использовать Spring WebFlux. Это новый фреймворк для реактивного программирования. Возникает вопрос, почему команда Spring не использовала для этих целей Spring Web MVC? Дело в том, что далеко не все модули в этом фреймворке можно использовать для работы в реактивном режиме. Остается много кода и сторонних библитек, например, Tomcat, которые основаны на декларативном программировании и потоках.
В процессе работы над фреймворком была разработана небольшая спецификация для асинхронной работы. В дальнейшем эту спецификацию решили включить в Java 9. Однако я буду использовать Java 8 и Spring Boot 2 для простоты.
Основные концепции
В новом подходе у нас есть два основных класса для работы в реактивном режиме:
Далее создадим класс с тестами и подготовленными пользователями:
Как видно из примера, использовать реактивный подход довольно просто.
Кроме того, у класса Mono есть множество методов на любой случай жизни. Например, есть всем известный метод map для преобразования одного типа в другой:
Данный класс схож с Mono, но предоставляет возможность асинхронной работы со множеством объектов:
Как и в случае с Mono у Flux есть набор полезных методов:
Здесь следует подчеркнуть одну особенность. В отличае от стандартных(не демонов) потоков при завершении работы основного потока выполнения сбор наших данных останавливается, и программа завершается. Это можно легко продемострировать. Следующий код ничего не выведет на консоль:
Этого можно избежать с помощью класса CountDownLatch:
Все это очень просто и эффективно по ресурсам. Представьте, чего можно достить при комбинировании вызовов методов стрима.
В данной статье мы рассмотрели понятие рективностивной системы и реактивного программирования. Кроме того, мы поняли, как связаны эти понятия. В следующей части мы пойдем дальше и попробуем построить свой сервис на основе полученных знаний.
Реактивное программирование на реальных примерах: подробное введение
Авторизуйтесь
Реактивное программирование на реальных примерах: подробное введение

Обучение реактивному подходу в программировании — достаточно непростая вещь, и недостаток обучающих материалов только усугубляет этот процесс. Большинство существующих обучающих пособий не дают глубокого обзора и не рассказывают о том, как спроектировать архитектуру проекта в целом.
Этот материал направлен на то, чтобы помочь новичкам начать думать по-настоящему «реактивно».
Так что же такое реактивное программирование?
Есть множество не до конца верных определений и объяснений в интернете. Википедия дает слишком скупое описание. Ответы на Stack Overflow часто непонятны новичкам. Реактивный Манифест выглядит так, будто его писали для руководителей проектов или бизнесменов. Rx терминология от Microsoft, гласящая о том, что «Rx = Observables + LINQ + Schedulers», звучит настолько тяжело и по-майкрософтовски, что большинство из нас слабо понимает, о чем идёт речь. Такие термины, как «реактивность» и «распространение изменений» не выражают ничего, что бы отличалось от обычного MV* подхода, реализованного уже на бесчисленном множестве языков. Любой фреймворк реагирует на изменения моделей. В любом фреймворке изменения распространяются. Если бы это было не так, пользователь не видел бы никаких изменений.
Дадим подробное объяснение термину «реактивное программирование».
Реактивное программирование — программирование с асинхронными потоками данных
Впрочем, ничего нового. Event bus’ы или обычные события клика — это тоже асинхронные потоки данных, которые вы можете прослушивать, чтобы реагировать какими-либо действиями. Реактивность — это та же самая идея, возведенная в абсолют. Вы можете создавать потоки данных не только из событий наведения или кликания мышью. Потоком может быть что угодно: переменные, пользовательский ввод, свойства, кэш, структуры данных и т.п. Например, представьте, что ваша лента новостей в Твиттере — поток событий. Вы можете слушать этот поток и реагировать на события соответственно.
Кроме этого, вы получаете удивительный набор функций для комбинирования, создания и фильтрации этих потоков. Вот где проявляется вся магия этого подхода. Один или несколько потоков могут использоваться как входные данные для другого потока. Вы можете объединять два потока. Также вы можете фильтровать поток, выбирая только те события, которые вам интересны.
Так как потоки — основопологающая вещь в реактивном подходе, давайте рассмотрим их подробнее на примере пользовательского клика мышью:
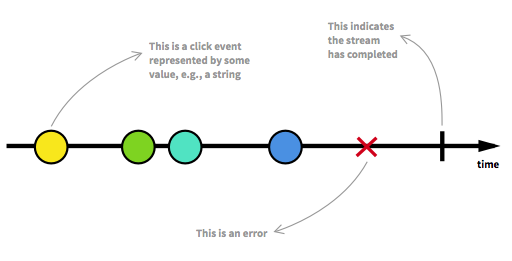
Поток — это последовательность событий, упорядоченная по времени. Он может выбрасывать три типа данных: значение (определенного типа), ошибку или сигнал завершения. Сигнал завершения распространяется, когда текущее окно или окно, содержащее кнопку, закрывается.
Мы перехватываем эти события асинхронно, указывая одну функцию, которая будет вызываться, когда выброшено значение, другую для ошибок и третью для обработки сигнала завершения. В некоторых случаях можно опустить последние две и сфокусироваться на объявлении функции для перехвата значений. Прослушивание потока называется подпиской (subscribing). Функции, которые мы объявляем, называются наблюдателями (observer). Поток — это объект наших наблюдений (observable, наблюдаемый объект). Это в точности паттерн проектирования, называемый «Наблюдатель«. Подробнее о шаблонах проектирования для новичков, читайте в нашей статье.
В данном руководстве мы будем использовать альтернативный способ представления вышеупомянутой диаграммы с помощью ASCII символов:
Теперь давайте сгенерируем новые потоки сообщений клика, трансформированные из оригинального потока.
Чтобы вы поняли всю мощь реактивного подхода, давайте предположим, что вы хотите реализовать поток событий «двойной клик». Чтобы сделать эту задачу еще интереснее новый поток должен принимать множественные нажатия за двойные. Представьте себе, как бы вы реализовывали эту задачу в императивном стиле. Потребовалось бы несколько переменных, хранящих состояние, и использование интервалов.
В реактивном же подходе все достаточно просто. Всю описанную выше логику можно реализовать четырьмя строками кода. Но давайте пока не останавливаться на коде. Лучший способ научиться понимать и проектировать потоки, вне зависимости от того, новичок вы или эксперт — это изображать диаграммы:
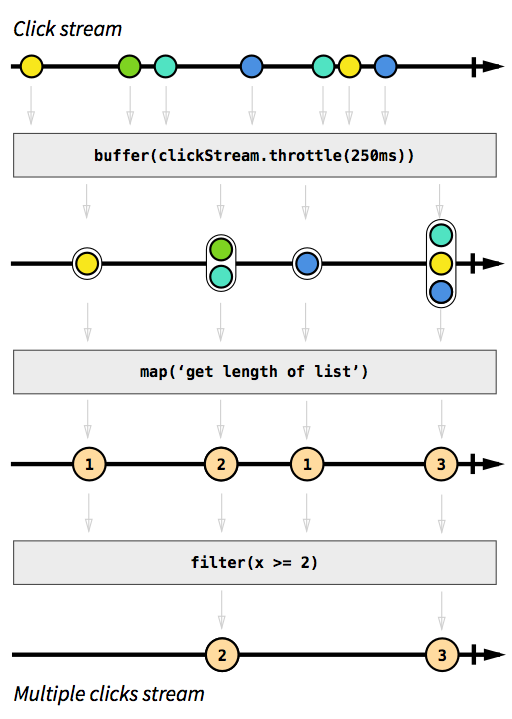
Этот пример показывает всю простоту, с которой реализовывается достаточно сложная на первый взгляд задача, если мы используем реактивный подход.
Для чего нужно реактивное программирование
Реактивный подход повышает уровень абстракции вашего кода и вы можете сконцентрироваться на взаимосвязи событий, которые определяют бизнес-логику, вместо того, чтобы постоянно поддерживать код с большим количеством деталей реализации. Код в реактивном программировании, вероятно, будет короче.
Преимущество более заметно в современных веб- и мобильных приложениях, которые работают с большим количеством разнообразных UI-событий. 10 лет назад всё взаимодействие с веб-страницей сводилось к отправке больших форм на сервер и выполнении простого рендеринга в клиентской части. Сейчас приложения более сложны: изменение одного поля может повлечь за собой автоматическое сохранение данных на сервере, информация о новом «лайке» должна отправиться другим подключенным пользователям и т.д.
Реактивное программирование очень хорошо подходит для обработки большого количества разнообразных событий.
Начинаем думать в реактивном стиле
В последующих примерах используется JavaScript и RxJS, но Rx-библиотеки доступны для многих других языков и платформ (.NET, Java, Scala, Clojure, JavaScript, Ruby, Python, C++, Objective-C/Cocoa, Groovy, и т.д.). На нашем сайте есть руководства по использованию библиотек RxSwift и ReactiveX в Python.
Реализуем виджет «На кого подписаться»
В Twitter есть такой виджет, который предлагает вам другие аккаунты, на которые вы можете подписаться:

Мы намерены реализовать его основную функциональность:
Вместо Twitter-аккаунтов, которые закрыты для неавторизованных пользователей, мы будем использовать Github API и брать аккаунты оттуда. Ссылку на Github API для получения списка пользователей вы можете найти в официальной документации. Также можете смотреть на готовый код данного примера.
Запрос и ответ
Как подойти к решению этой проблемы в Rx-стиле? Надо начать с того, что (почти) все, что угодно может быть потоком. Первое, что мы реализуем, будет «Загрузка из API и вывод трех аккаунтов». Ничего необычного, нужно просто (1) сделать запрос, (2) получить ответ, (3) отобразить ответ. Представим запрос в качестве потока.
При инициализации мы должны сделать только один запрос, так что если мы смоделируем его, как поток данных, он будет выбрасывать только одно значение. В дальнейшем мы будем делать множество запросов, но на данный момент нам нужен только один.
Когда происходит запрос, он сообщает нам две вещи: когда запрос должен быть выполнен — время генерации события, и куда мы делаем запрос — значение генерируемого событие, строка, содержащая URL.
Создать поток, содержащий одно значение, очень просто с библиотеками семейства Rx*:
То, что мы написали — это просто поток, содержащий строку, который не делает ничего, так что мы должны как-то заставить его действовать так, как нам нужно. Это делается с помощью подписки на поток:
Заметьте, что мы используем Ajax-коллбэк (callback) из библиотеки jQuery, чтобы управлять асинхронностью операции запроса. Если вы слабо понимаете, что такое callback’и, почитайте нашу статью об эволюции асинхронного программирования в JS. «Но подождите, Rx же работает с асинхронными потоками данных. Не может ли ответ на запрос быть потоком, содержащим данные, которые придут когда-нибудь позже?» — можете спросить вы. Что ж, на концептуальном уровне все верно, давайте попробуем это реализовать:
Rx.Observable.create() создает пользовательский поток данных, информируя каждого подписчика о событиях ( onNext() ) или ошибках ( onError() ). Мы обернули Ajax-промис в соответствующий коллбэк. Значит ли это, что Promise — то же самое, что Observable? Да, значит. Подробнее о Promis’ах читайте в нашей вводной статье.
Observable — это Promise++. В Rx вы можете конвертировать Promise в Observable очень простым образом:
Единственное отличие между Promise и Observable в том, что Observable не совместим с Promises/A+. Promise — это, по сути, Observable с одним генерируемым значением. Потоки в Rx расширяют промисы, позволяя возвращать множество значений.
Одна из таких функций, с которой вы уже познакомились — map(f) — берет каждое значение из потока A, применяет на нем f() и производит значение для потока B. Если мы применим эту функцию на потоке запроса и ответа, мы можем преобразовать список URL’ов в промисы ответа.
Затем мы должны создать поток потоков, называемый так же метапоток (metastream). Не пугайтесь, все достаточно просто. Метапоток — это такой поток, в котором каждое генерируемое им значение является потоком. Можно представить их себе как указатели: каждое генерируемое значение — указатель на новый поток. В нашем примере URL каждого запроса преобразуется в указатель на поток, содержащий промис ответа.


Как и ожидалось, если у нас впоследствии будут какие-то события, генерируемые потоком запросов, поток ответов будет реагировать на них соответствующим образом:
И теперь, когда у нас есть поток ответов, мы можем отрендерить получаемые данные:
Кнопка обновления
Нужно отметить, что список пользователей, который мы получаем по API, состоит из 100 элементов. API позволяет нам задавать смещение списка, но не его размер, так что пока мы используем только 3 объекта, игнорируя остальные. Вы научитесь кэшировать ответ чуть позже.
Каждый раз, когда пользователь нажимает кнопку обновления, поток запросов должен сгенерировать URL, чтобы мы могли получить новые данные. Для этой задачи нам потребуется сделать две вещи: реализовать поток событий нажатия на кнопку, а также изменить поток запросов так, чтобы он реагировал на события потока нажатий. К счастью, RxJS позволяет нам преобразовать обычные JavaScript-события в Observable.
Давайте поменяем поток запросов так, чтобы при нажатии кнопки обновления генерировался URL со случайным параметром смещения списка.
Похоже, мы что-то сломали. Теперь запрос срабатывает только после того, как мы нажали кнопку. Но по условию задачи мы должны делать запрос и при инициализации. Давайте попробуем починить наш код.
Для начала создадим разные потоки для вышеупомянутых условий:
Ну, теперь все очень просто:
Также есть альтернативный и более чистый способ реализовать задачу без вспомогательных переменных:
А можно и еще короче!
Моделируем 3 рекомендации с помощью потоков
Теперь, вместе с кнопкой обновления, у нас появилась проблема: при нажатии этой кнопки текущие 3 рекомендации не исчезают. Новые предложения появляются, как только с сервера пришел ответ, но для того, чтобы наш UI выглядел отзывчивым, мы должны очищать текущие предложения сразу же.
Теперь у нас есть два подписчика, влияющих на DOM-элементы (другой подписывается на responseStream ) и это соответствует принципу «Разделяй и властвуй«. Вы еще помните мантру реактивного подхода? Напоминаем:

Все является потоком
Давайте сделаем так, чтобы рекомендации были потоками, в которых каждое генерируемое значение — это JSON-объект, содержащий данные рекомендации. Мы сделаем по потоку на каждую из трех рекомендаций. Вот так выглядит поток для рекомендации №1:
Скопипастим этот код для потока №2 ( suggestion2Stream ) и №3 ( suggestion3Stream ). Подумайте над тем, как можно избежать дублирования кода в данном примере. Это будет отличным упражнением. А еще и очень хорошим способом избежать эффекта последней строки.
Теперь мы можем обнулять рекомендацию при нажатии кнопки обновления:
Вот диаграмма того, что мы только что реализовали:
В качестве бонуса мы также можем выводить «пустые» рекомендации при инициализации с помощью startWith(null) :
Удаление рекомендации и кэширование ответа сервера
Последняя функция, которую мы реализуем — удаление рекомендации. Напротив каждой рекомендации есть кнопка удаления, которая закрывает текущую рекомендацию и показывает вместо неё новую. Первая мысль, которая может у вас возникнуть — нужно делать новый запрос по нажатию этой кнопки:
Это не сработает. Перезагрузятся все рекомендации. Существует несколько способов решения этой проблемы, и один из наиболее оптимальных — повторное использование предыдущего ответа сервера. Ответ API состоит из списка длиной в 100 элементов, из которых мы используем только 3. Нет надобности запрашивать новые данные, когда мы можем использовать 97 «свежих».
Когда происходит нажатие кнопки «close1», нам нужно использовать наиболее свежий ответ сервера, чтобы получить случайного пользователя из списка. Примерно так:
Есть несколько способов решения этой проблемы и мы воспользуемся простейшим: симулированием клика кнопки «close1» при инициализации:
Все, курс молодого бойца по реактивному программированию окончен! Вы можете взглянуть на рабочий код.