
Инструкция по использованию команды htop для интерактивного просмотра процессов в Linux
Лучше htop или top?
Команда htop похожа на команду top по выполняемой функции: они обе показывают информацию о процессах в реальном времени, выводят данные о потреблении системных ресурсов и позволяют искать, останавливать и управлять процессами.
У обеих команд есть свои преимущества. Например, в программе htop реализован очень удобный поиск по процессам, а также их фильтрация. В команде top это не так удобно — нужно знать кнопку для вывода функции поиска.
Зато в top можно разделять область окна и выводить информацию о процессах в соответствии с разными настройками. В целом top намного более гибкая в настройке отображения процессов.
В общем, чтобы решить, какая из команд лучше именно для вас, попробуйте их обе. В данной статье будет подробно рассказано о htop, чтобы познакомиться с top обратитесь к статье «Как пользоваться командой top для наблюдения за процессами в Linux».
Как установить htop
Установите пакет с именем htop используя менеджер пакетов для вашего дистрибутива.
В Debian, Linux Mint, Ubuntu, Kali Linux и их производных выполните:
В Arch Linux, Manjaro, BlackArch и их производных выполните:
Как просмотреть все процессы в Linux
Команду htop можно запускать как с правами обычного пользователя:
Так и с привилегиями суперпользователя, для этого используйте sudo:

Права суперпользвоателя нужны только для некоторых действий: для изменения приоритета (nice) процессов, для закрытия процессов других пользователей.
Как и в случае с программой top, окно разделено на два основных раздела:
Область с информацией о системе
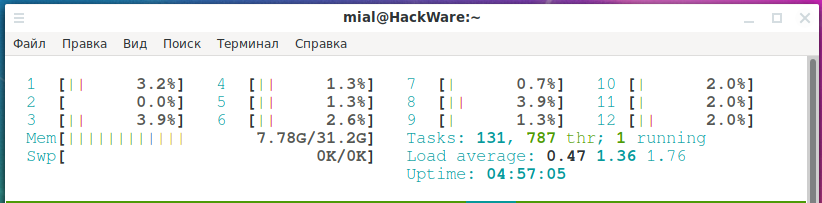
В самом верху показана нагрузка на каждое ядро центрального процессора (цифры от 1 до 12).
Mem — это общее количество оперативной памяти и используемая память.
Task — обобщённая статистика по процессам
Swp — уровень занятости файла подкачки (если он есть)
Load average — средняя загрузка центрального процессора
Uptime — время работы операционной системы с момента последней загрузки
Теперь перейдём к области с информацией о запущенных процессах.
Значение столбцов htop
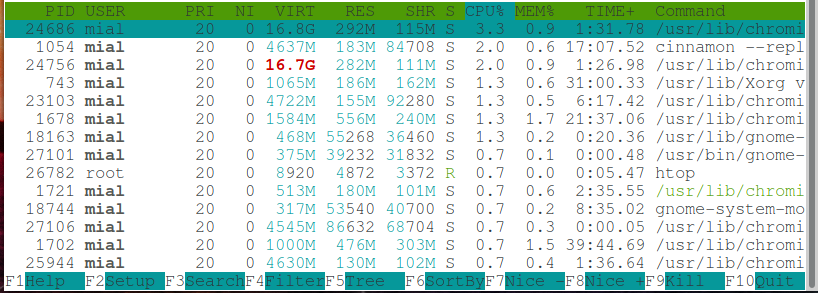
Программа htop выводит следующие столбцы:
USER
Имя пользователя владельца процесса или ID если имя не может быть определено.
Приоритет — внутренний приоритет ядра для процесса, обычно это просто значение nice плюс двадцать. Отличается для процессов имеющих приоритет выполнения real-time.
VIRT
Размер виртуальной памяти процесса (M_SIZE).
Размер резидентного набора (text + data + stack) процесса (т.е. размер используемой физической памяти процесса, M_RESIDENT).
Размер общих страниц процесса (M_SHARE).
STATE, состояние процесса, может быть:
S для спящих (в простое)
R для запущенных
D для сна диска (бесперебойный)
Z для зомби (ожидает родитель считает его статус выхода)
T для отслеживания или приостановки (т. е. от SIGTSTP)
W для подкачки
Процент процессорного времени, которое процесс использует в данный момент.
Процент памяти, используемой процессом в данный момент (в зависимости от размера резидентной памяти процесса, см. M_RESIDENT выше).
TIME+
Время, измеренное в часах, указывает на то, сколько процесс провёл в пользовательском и системном времени.
Command
Полная командная строка процесса (то есть имя программы и аргументы).
Как ускорить или замедлить частоту обновления htop
Для установки времени обновления htop используйте опцию -d после которой укажите время обновления в десятой части секунд. Например, чтобы программа обновляла окно каждую 1/10 секунды:
Чтобы программа выводила новые данные раз в 5 секунд:
Как вывести процессы в виде дерева
Для вывода процессов в виде дерева используйте опцию -t:
Либо во время работы программы нажмите клавишу F5:

Как перемещаться по списку процессов в htop
Вы можете использовать курсорные клавиши (←, →, ↑, ↓ ) для прокрутки списка процессов.
Также работают клавиши PgUp, PgDn для прокрутки окна.
Кнопка Home перенесёт к началу списка.
Кнопка End прокрутит список до конца.
Как в htop отсортировать по потреблению памяти. Как выбрать поле для сортировки
Нажмите клавишу F6 для выбора поля, которое вы хотите использовать для сортировки.
Для переключения к обратному порядку сортировки используйте кнопку I (Shift+i). При повторном нажатии список вновь будет отсортирован в обратном порядке.

Как свернуть ветки дерева процессов в htop
В режиме дерева процессов выберите ветку дерева, которую вы хотите свернуть и нажмите F6.
Поиск и фильтрация процессов в htop
Поиск отличается от фильтрации тем, что найденные процессы показываются наравне с остальными, и между найденными процессами можно переключаться кнопкой F3.
При фильтрации на экран будут выводиться только процессы, соответствующие введённой строке.
Для перехода к поиску по процессам нажмите F3 или /. Для переключения между найденными процессами нажимайте F3.
Для фильтрации процессов нажмите F4 или \ начните вводить имя процесса.

Для очистки фильтра вновь нажмите F4 и затем Esc.
Как изменить приоритет процесса в htop
Для увеличения приоритета процесса (вычитание из величины nice) нажмите кнопку F7 или ]. Помните, что эту операцию может делать только суперпользователь (вы должны быть root’ом или запустить htop с sudo).
Для уменьшения приоритета процесса (прибавления к величине nice) нажмите кнопку F8 или [.
Как выбрать один или несколько процессов в htop
Для выбора процессов используйте Пробел. После этого введённые команды, такие как kill или изменение приоритета, могут применяться к группе выделенных процессов вместо подсвеченного в данный момент.
Для снятия выделения со всех процессов нажмите U (Shift+u).
Как закрыть процесс в htop
Для закрытия процесса выберите один или несколько процессов и нажмите F9 или k. Выбранному процессу будет отправлен сигнал завершения. Если не отмечен ни один процесс, то будет закрыть тот, на котором находиться в данный момент курсор.
Как показать файлы, которые использует процесс
Если вы хотите увидеть файлы, открытые процессом, то выделите интересующий вас процесс и нажмите кнопку l (маленькая латинская L).
Чтобы эта функция работала, в системе должны быть установлена утилита lsof.
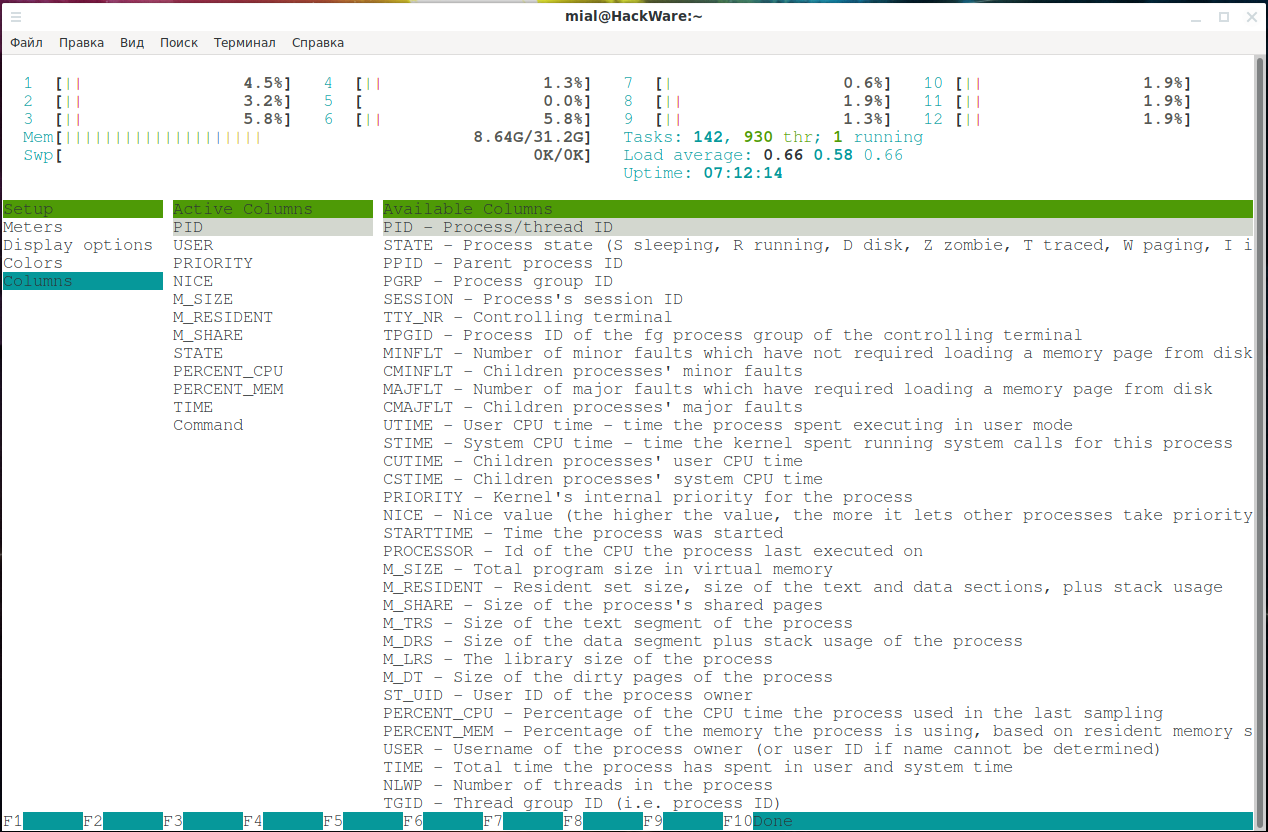
Как изменить внешний вид htop
Для изменения внешнего вида — панели с информацией о системе, выводимых столбцах и прочем, нажмите кнопку F2 или S (Shift+s).

Там вы увидите следующие вкладки:
Как указать поле для сортировки при запуске htop
С помощью опции -s можно указать столбец, по которому будут отсортированы процессы.
Например, для сортировки процессов по столбцу PERCENT_MEM (процент используемой памяти):
Чтобы увидеть все доступные столбцы для сортировки выполните команду:
Как показать только процессы определённого пользователя
Используйте опцию -u в команде вида:
Например, для вывода процессов только пользователя mial:
Как показать только процесс с определённым номером
Для слежения только за некоторыми процессами используйте опцию -p PID,PID…. Через запятую вы можете перечислить один или более идентификаторов процессов. Только эти процессы будут показаны в окне htop.
Трассировка системных вызовов
Вы можете проследить, какие системные вызовы сделал процесс. Для этого выберите интересующий вас процесс и нажмите кнопку s.
Для работы этой функции у вас должна быть установлена утилита strace.
Как закрыть htop
Для выхода из программы нажмите F10 или q или Ctrl+c.
Если возможностей htop вам недостаточно, то обратитесь к статье «Как пользоваться командой top для наблюдения за процессами в Linux».
В защиту swap’а [в Linux]: распространенные заблуждения
Прим. перев.: Эта увлекательная статья, в подробностях раскрывающая предназначение swap в Linux и отвечающая на распространённое заблуждение на этот счёт, написана Chris Down — SRE из Facebook, который, в частности, занимается разработкой новых метрик в ядре, помогающих анализировать нагрузку на оперативную память. И начинает он своё повествование с лаконичного TL;DR…

Предисловие
Работая над улучшением и использованием cgroup v2, я успел поговорить со многими инженерами об их отношении к управлению памяти, особенно о поведении приложения под нагрузкой и об эвристическом алгоритме операционной системы, используемым «под капотом» для управления памятью.
Повторяющейся темой этих обсуждений стал swap. Тема swap активно оспаривается и плохо понимается даже теми, кто проработал с Linux долгие годы. Многие воспринимают его как нечто бесполезное или очень вредное — мол, это пережиток прошлого, когда памяти было мало и диски являлись необходимым злом, предоставляющим столь нужное пространство для подкачки. И до сих пор, все последние годы, я достаточно часто наблюдаю споры вокруг этого утверждения: немало дискуссий провёл и я сам с коллегами, друзьями, собратьями по индустрии, помогая им понять, почему swap — это по-прежнему полезная концепция на современных компьютерах, имеющих гораздо больше физической памяти, чем в былые времена.
Широкое недопонимание существует и насчёт предназначения swap’а: многие люди видят в нём лишь «медленную дополнительную память» для использования в критических ситуациях, но не понимают его вклад в адекватное функционирование операционной системы в целом при нормальной нагрузке.
Многие из нас слышали такие распространённые фразы о памяти: «Linux использует слишком много памяти», «swap должен быть вдвое больше размера физической памяти» и т.п. Эти заблуждения легко развеять и их обсуждения стали более точными в последние годы, однако миф о «бесполезном» swap гораздо больше завязан на эвристику и таинство, которые не поддаются объяснению с простой аналогией, — для его обсуждения требуется более глубокое понимание управления памятью.
Введение
Сложно говорить, почему наличие swap’а и перемещение в него страниц памяти — хорошо при нормальной работе, не разделяя понимание некоторых базовых нижележащих механизмов в управлении памятью в Linux, поэтому давайте убедимся, что говорим на одном языке.
Типы памяти
В Linux существует множество различных типов памяти, и у каждого из этих типов есть свои свойства. Понимание их особенностей — ключ к пониманию, почему swap важен.
Например, есть страницы («блоки» памяти, обычно по 4k), ответственные за хранение кода для каждого процесса, запущенного на компьютере. Есть также страницы, ответственные за кэширование данных и метаданных, относящихся к файлам, к которым обращаются эти программы для ускорения своих обращений в будущем. Они являются частью страничного кэша [page cache], и далее я буду на них ссылаться как на файловую [file] память.
Есть и другие типы памяти: разделяемая память, slab-память, память стека ядра, буферы и иные, — но анонимная память и файловая память известны лучше других и просты для понимания, поэтому именно они будут использоваться в примерах, которые, впрочем, равносильно применимы и к другим типам.
Память с высвобождением и без
В размышлениях о конкретном типе памяти одним из главных вопросов становится возможность её высвобождения. «Высвобождение» [reclaim] означает, что система может, без потери данных, удалить страницы этого типа из физической памяти.
Для некоторых типов страниц это сделать весьма просто. Например, в случае чистой [clean], т.е. немодифицированной, памяти страничного кэша мы просто кэшируем для лучшей производительности то, что уже есть на диске, поэтому можем сбросить страницу без необходимости в каких-либо специальных операциях.
Для некоторых типов страниц это возможно, но непросто. Например, в случае грязной [dirty], т.е. модифицированной, памяти страничного кэша мы не можем просто сбросить страницу, потому что на диске ещё нет произведённых модификаций. Поэтому необходимо или отказаться от высвобождения [reclamation], или перенести наши изменения обратно на диск перед тем, как сбрасывать эту память.
Для некоторых типов страниц это невозможно. Например, упомянутые раньше анонимные страницы могут существовать только в памяти и никаком ином резервном хранилище, поэтому их необходимо хранить здесь (т.е. в самой памяти).
О природе swap’а
Если поискать объяснения, зачем нужен swap в Linux, неизбежно находятся многочисленные обсуждения его предназначения просто как расширения физической RAM для критических случаев. Вот, например, случайный пост, который я вытащил из первых результатов в Google по запросу «what is swap»:
«По своей сути swap — это экстренная память; запасное пространство для случаев, когда система на какое-то время нуждается в большем количестве физической памяти, чем доступно в RAM. Она считается «плохой» в том смысле, что медленная и неэффективная, и если системе постоянно требуется использовать swap, очевидно, ей не хватает памяти. [..] Если у вас достаточно RAM для удовлетворения всех потребностей и вы не ожидаете её превышения, вы можете прекрасно работать и без swap-пространства».
Поясню, что я вовсе не обвиняю автора этого комментария за содержимое его поста — это «общеизвестный факт», признаваемый многими системными администраторами Linux и являющийся, пожалуй, одним из наиболее вероятных ответов на вопрос о swap’е. К сожалению, это вдобавок и неправильное представление о предназначении и использовании swap’а, особенно на современных системах.
Как я уже писал выше, высвобождение анонимных страниц «невозможно», поскольку анонимные страницы по своей природе не имеют резервного хранилища, к которому можно обратиться при удалении данных из памяти, — таким образом, их высвобождение приведёт к полной утере данных из соответствующих страниц. Однако… что будет, если мы смогли бы создать такое хранилище для этих страниц?
Вот именно для этого и существует swap. Swap — область хранения для этих, кажущихся «невысвобождаемыми» [unreclaimable], страниц, позволяющая отправлять их на устройство хранения по запросу. Это означает, что их можно начинать считать такими же доступными для высвобождения, как и их более простые в этом смысле друзья (вроде чистых файловых страниц), что позволяет эффективнее использовать свободную физическую память.
Swap — это преимущественно механизм для равного высвобождения, а не для срочной «дополнительной памяти». Не swap замедляет работу вашего приложения — замедление происходит из-за начала совокупной конкуренции за память.
Итак, в каких же ситуациях это «равное высвобождение» будет оправданно выбирать высвобождение анонимных страниц? Вот абстрактные примеры некоторых не самых редких сценариев:
Что происходит с использованием swap и без него
Давайте посмотрим на типовые ситуации и к чему они приводят при наличии и отсутствии swap. О метриках «конкуренции за память» я рассказываю в докладе про cgroup v2.
Без конкуренции или с малой конкуренцией за память
С умеренной или высокой конкуренцией за память
При временных всплесках в потреблении памяти
Окей, я хочу системный swap, но как его настроить для конкретных приложений?
Вы же не думали, что в этой статье не будет упоминаний использования cgroup v2?
И в этом вопросе нельзя просто положиться на OOM killer. Потому что OOM killer вызывается только в самых критичных ситуациях, когда система уже оказалась в значительно нездоровом состоянии и, возможно, находилась в нём некоторое время. Необходимо самостоятельно и оппортунистически разрешить ситуацию ещё до того, как задумываться об OOM killer’е.
Тем не менее, выявить давление на память достаточно трудно с помощью традиционных счётчиков памяти в Linux. Нам доступно нечто, что каким-то образом относится к проблеме, однако скорее по касательной: потребление памяти, количество операций сканирования страниц и т.п. — и по одним этим метрикам очень трудно отличить эффективную конфигурацию памяти от той, что приводит к конкуренции за память. У нас есть группа в Facebook, возглавляемая Johannes’ом и работающая над новыми метриками, упрощающими демонстрацию давления на память, — это должно помочь нам в будущем. Больше информации об этом можно получить из моего доклада про cgroup v2, где я начинаю подробнее рассказывать об одной из метрик.
Тюнинг
Сколько же swap’а мне тогда нужно?
В общем случае минимальное количество swap-пространства, требуемого для оптимального управления памятью, зависит от количества анонимных страниц, которые привязаны к пространству памяти и к которым редко обращается приложение, а также от стоимости высвобождения этих анонимных страниц. Последнее — это в большей степени вопрос о том, какие страницы больше не должны удаляться, чтобы уступить место тем анонимным страницам, к которым редко обращаются.
Если у вас достаточно дискового пространства и свежее (4.0+) ядро, большее количество swap’а почти всегда лучше, чем меньшее. В более старых ядрах kswapd — один из процессов ядра, что отвечает за управление swap’ом, — исторически слишком усердствовал в перемещении памяти в swap, делая это тем активнее, чем больше swap’а было доступно. В последнее время поведение swapping’а при наличии большого swap-пространства значительно улучшили. Так что, если вы работаете с ядром 4.0+, большой swap не приведёт к чрезмерному swapping’у. В общем, на современных ядрах нормально иметь swap размером в несколько гигабайт, если такое пространство у вас есть.
Если же дисковое пространство ограничено, ответ в действительности зависит от компромисса, на который вы готовы пойти, и особенностей окружения. В идеале у вас должно быть достаточно swap’а, чтобы система оптимально функционировала при нормальной и пиковой (по памяти) нагрузке. Рекомендую настроить несколько тестовых систем с 2-3 Гб swap’а или более и понаблюдать, что происходит на протяжении недели или около того в разных условиях нагрузки (на память). Если на протяжении этой недели не случалось ситуаций резкой нехватки памяти, что означает недостаточную пользу такого теста, всё закончится занятостью swap’а небольшим количеством мегабайт. В таком случае, пожалуй, разумно будет иметь swap хотя бы такого размера с добавлением небольшого буфера для меняющихся нагрузок. Также atop в режиме логирования в столбце SWAPSZ может показать, страницы каких приложений попадают в swap. Если вы ещё не используете эту утилиту на своих серверах для логирования истории состояний сервера — возможно, в эксперимент стоит добавить её настройку на тестовых машинах (в режиме логирования). Заодно вы узнаете, когда приложение начало перемещать страницы в swap, что можно привязать к событиям из логов или другим важным показателям.
Ещё стоит задуматься о типе носителя для swap’а. Чтение из swap имеет тенденцию быть очень случайным, поскольку нельзя уверенно предсказать, у каких страниц будет отказ и когда. Для SSD это не имеет особого значения, а вот для вращающихся дисков случайный ввод/вывод может оказаться очень дорогим, поскольку требует физических движений. С другой стороны, отказы у файловых страниц обычно менее случайны, поскольку файлы, относящиеся к работе одного запущенного приложения, обычно менее фрагментированы. Это может означать, что для вращающегося диска вы можете захотеть сместиться в сторону высвобождения файловых страниц вместо swapping’а анонимных страниц, но, опять же, необходимо протестировать и оценить, как будет соблюдаться баланс для вашей рабочей нагрузки.
Для пользователей ноутбуков/десктопов, желающих использовать swap для перехода в спящий режим [hibernate], этот факт также необходимо учитывать, поскольку swap-файл тогда должен как минимум соответствовать размеру физической оперативной памяти.
Какой должна быть настройка swappiness?
Это означает, что vm.swappiness — это по существу просто соотношение дорогой анонимной памяти, которую можно высвобождать и приводить к отказам, в сравнении с файловой памятью для вашего железа и рабочей нагрузки. Чем ниже значение, тем активнее вы сообщаете ядру, что редкие обращения к анонимным страницам дороги для перемещения в swap и обратно на вашем оборудовании. Чем выше это значение, тем вы больше говорите ядру, что стоимость swapping’а анонимных и файловых страниц одинакова на вашем оборудовании. Подсистема управления памятью будет по-прежнему пытаться решить, помещать в swap файловые или анонимные страницы, руководствуясь тем, насколько «горяча» память, однако swappiness склоняет подсчёт стоимости в пользу большего swapping’а или большего пропуска кэшей файловой системы, когда доступны оба способа. На SSD-дисках эти подходы практически равны по стоимости, поэтому установка vm.swappiness = 100 (т.е. полное равенство) может работать хорошо. На вращающихся дисках swapping может быть значительно дороже, т.к. в целом он требует случайного чтения, поэтому вы скорее всего захотите сместиться в сторону меньшего значения.
Реальность же в том, что большинство людей не имеют представления о том, чего требует их железо, поэтому настроить это значение, основываясь лишь на инстинкте, затруднительно — это вопрос, требующий личного тестирования с разными значениями. Можно также заняться анализом состава памяти вашей системы, основных приложений и их поведения в условиях небольшого высвобождения памяти.
linux-notes.org
Утилиты top/htop и free отображают общее количество свободной, занятой физической памяти, а так же SWAP на сервере. Как определить, какой процесс использует пространство подкачки в Unix/Linux?
Вы можете использовать любой из следующих методов (но имейте в виду, что из-за общих страниц, нет никакого надежного способа получить данную информацию):
Какие процессы заняли SWAP в Unix/Linux
Можно добиться желаемого результата несколькими способами.
Находим идентификатор процесса (PID):
Альтернатива, использовать «pgrep» команду для поиска PID-а:
И так, одна из команд выведет подобный результат:
Чтобы увидеть сколько использует swap служба memcached можно следующим образом:
И так, я показал сколько используется swap-а по указанному процессу ( memcached), но это не совсем удобно т.к имеется и ряд других процессов которые могут или использует swap, по этому — я сейчас покажу как можно красиво использовать данные утилиты для проверки.
Введите следующую команду в терменале, чтобы увидеть использование свопа по каждому процессу:
Небольшая оптимизация — используем сортировку и вывод частями:
Нашел небольшой bash скрипт:
И прописываем в него:
Запускайте его от суперпользователя для того, чтобы иметь возможность собрать точные цифры. Скрипт будет работать и от любого другого пользователя в системе, но если у него не поулчится получить доступ к процессу которые не принадлежат вашему пользователю, то он не сможет показать данные по процессам. Например, чтобы найти процесс с большим использованием свопа, просто запустите скрипт вот так:
Данные скрипт покажет все процессы которые используют или не используют SWAP, но можно убрать ненужно ( отображать только те процессы, которые имеют обращение к свапу):
Выход будет в килобайтах.
Вот уже готовый, упрощенный скрипт:
Хочу показать отличную вариацию данного скрипта ( на мой взгляд — одно из самых лучших):
Вот еще один вариант использования:
Они все работают и их можно использовать для своих нужд. А можно использовать утилиту smem. О ней можно прочитать тут:
А на этом, у меня все! Статья «Какие процессы заняли SWAP в Unix/Linux» завершена.