
Python, введение в БД
Здравствуйте, здесь и сейчас я хочу рассказать, что такое базы данных, зачем они нужны, и т.д.; для работы с ними мы будем использовать python и его библиотеку sqlite3.
Так нам говорит Яндекс, но если сказать простыми словами, не углубляясь во все эти понятия, то:
То есть как в библиотеку мы можем прийти и взять книгу «Война и мир», зная что она будет лежать в разделе романов, на букву «В», так и из БД мы можем взять запись по определённому аргументу, в данном случае жанру.
И тут возникает вопрос.
И что бы ответить на этот вопрос, мы должны кое-что узнать.
Как хранятся данные в базах данных
Сначала нужно понять, что БД делятся на:
Сетевые и иерархические БД:
Такие БД представляют собой графы и хранят информацию в них же.
Данные БД здесь мы рассматривать не будем. Поэтому перейдём к реляционной БД.
Реляционные базы данных

Я думаю что, на вопрос мы ответили, и можно идти дальше.
Зачем нужны базы данных?
За всю жизнь, человечество накопила невероятно много информации, а БД, как мы знаем собирают, и сортирует эту информацию по таблицам (в нашем случае). И БД помогают абсолютно спокойно ориентироваться во всей этой куче информации, добавлять её туда, изменять и т.д.;
Из теории в практику
Сейчас мы пойдём в практику, но перед этим хотелось бы уточнить кое-что. Сверху я написал такую строку:
Мой косяк исправили, идём в практику!
Установка sqlite3
Да, это смешно, но мало ли кому-нибудь понадобится
Я не буду описывать алгоритм установки, ведь это давно сделали за меня, если вам нужно установить данный модуль, то просьба идти вот сюда.
Создание первой БД
cur = con.cursor — позволит нам производить операции с БД, остальное не важно.
cur.execute(. ) — создаёт таблицу с именем тест и всего 1 колонкой id, в которой все данные — числа
commit() — грубо говоря, сохранение БД
А давайте создадим программу, которая запрашивает имя и фамилию, и записывает их в БД, а потом по выбору цифр либо выводит, либо записывает снова.
Стандартные моменты пропустим.
cur.execute(«INS. ») — Добавление данных
cur.execute(«SeL. ») — Получение данных. И так как там отдаётся массив, то мы его перебираем, а после ещё и из кортежа данные берём.
«SELECT», «INSERT», «DROP» и т.д. — это всё SQL.
cur.fetchall() — это что бы в переменную записалось всё, что пришло из БД.
Вывод
Базы данных — важная и очень нужная вещь. Здесь мы затронули настолько её малую часть, что аж смешно. Поэтому чтобы действительно узнать как это работает, советую почитать об этом всём в интернете, благо информации много. Удачи!
База данных. Реляционная база данных
Что такое базы данных (БД) и зачем они нужны
База данных (БД) — это программа, которая позволяет хранить и обрабатывать информацию в структурированном виде.
БД это отдельная независимая программа, которая не входит в состав языка программирования. В базе данных можно сохранять любую информацию, чтобы позже получать к ней доступ.
Пример использования
Базы данных нужны для хранения информации. Чтобы получить полное понимание необходимости использования БД в современном веб-программировании, необходимо ответить на три вопроса:
Предположим, вы решили сделать сайт, где каждый пользователь может вести личный дневник наблюдения за погодой в своем городе.
Такой сайт должен иметь как минимум одну форму ввода со следующими полями: город, дата, температура, облачность, погодное явление, и так далее.
Каждый день наблюдатель записывает показания погоды в эту форму, чтобы когда-нибудь в будущем вернуться на сайт и посмотреть, какая была погода месяц или даже год назад.
Из этого примера следует, что программист каким-то образом должен сохранять данные из формы для дальнейшего использования.
Кроме обычного просмотра дневника погоды за месяц в виде таблицы, можно сделать и более сложный проект.
Например, чтобы электронный дневник чем-то качественно отличался от своего бумажного аналога, будет неплохо добавить туда возможности для простого анализа: показать какой день был самым холодным в ноябре или какой продолжительности была самая длинная серия пасмурных дней.
Получается, что данные надо не просто как-то хранить, но и иметь возможность их обрабатывать и анализировать.
Именно для этих целей и существуют базы данных.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
Так мы решим сразу две задачи:
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Зачем нужны базы данных
И какие они бывают.
Если вы будете делать веб-приложение — например интернет-магазин, блог или игры, — почти наверняка вы столкнётесь с базой данных. Вот что это такое с точки зрения программирования, какие тут основные понятия и что с ними делать.
Данные
Вокруг нас всегда много разных данных, например:
Если это компьютерная игра, то данными будут типы и местоположения врагов, их уровень здоровья, уровень здоровья героя, тип героя, его положение, характеристики карты.
Если это приложение для работы с клиентом, то там будут храниться имя клиента, его заказы, номер телефона, уровень в программе лояльности.
Если это служба слежения за гражданами — фотография, имя, посещённые станции метро и улицы, место работы.
База данных и СУБД
Есть понятие базы данных — это набор данных, организованных каким-то способом. Например, если у вас в квартире есть гардеробная или кладовка, то всё это помещение со всем её содержимым может считаться базой (но не данных, а вещей или банок с огурцами, что не меняет сути).
Есть понятие системы управления базой данных (СУБД) — это когда семья села за стол и самого младшего отправляют в кладовку за огурцами, он приносит её и не разбивает по дороге. То есть СУБД — это какое-то средство для манипуляции данными в базе, например программа.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
🤔 Представьте, что у вас есть экселька со списком клиентов. Это не база данных, это просто таблица. Чтобы прочитать или записать что-то в эту эксельку, вам нужно её открыть, сделать дело, сохранить.
❌ Допустим, экселька с клиентами лежит на сетевом диске. Вы открыли её и ковыряетесь в данных, вносите изменения. Пока вы это делаете, ваш коллега тоже её открыл и тоже вносит изменения. Потом вы сохранились и закрыли эксельку. Экселька перезаписалась вашими данными. Но у вашего коллеги эти данные не отобразились, он-то открыл её раньше. Теперь, когда он сохранит свою эксельку, его данные перезапишутся поверх ваших, а ваши данные пропадут. Это полный ахтунг: вся ваша работа потеряна.
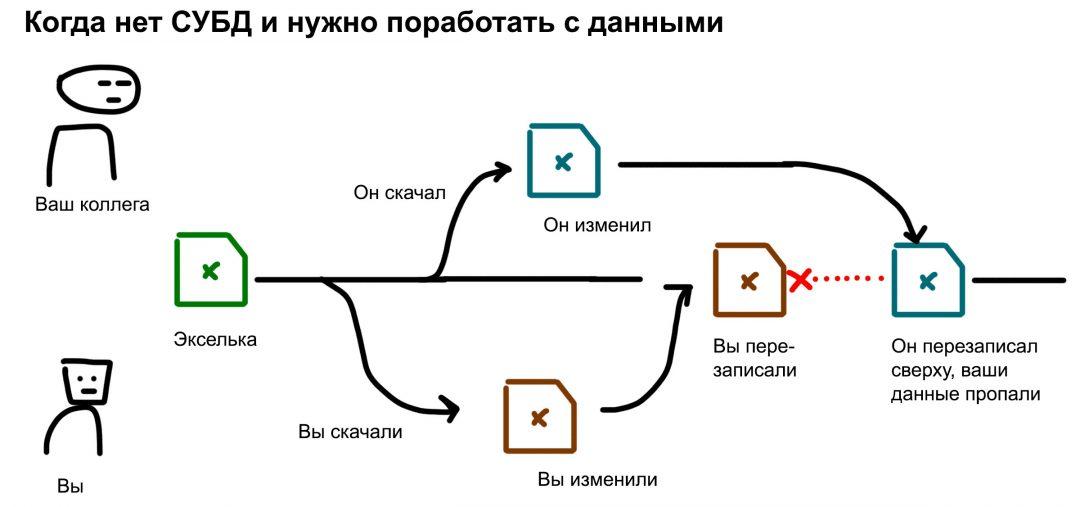
❌ Или у вас в компании правило: экселька всегда на одной флешке, работаем только с неё. Сейчас флешка в вашем компьютере, вы с ней работаете. А вашему коллеге нужно с ней тоже поработать. Он говорит: «Дай». Вы ему «Отстань». Ну и слово за слово…
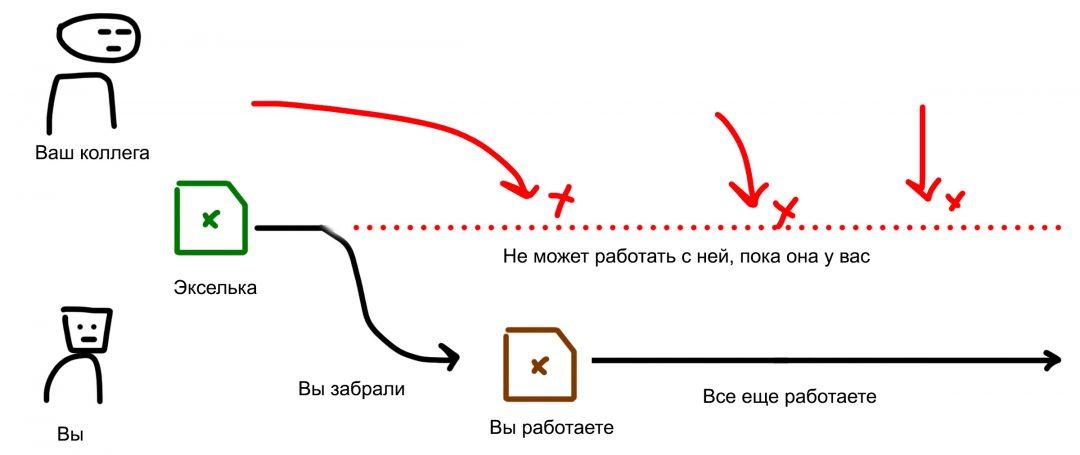
✅ Но можно организовать своего рода СУБД. Один ответственный сотрудник назначается главным по эксельке. Она открыта на его компьютере, а вы ему говорите: «Петруха, добавь в клиента такого-то вот такие данные». «Петруха, а шо, когда дедлайн по поставке для этих ребят из Воронежа?», «Петруха, питерские отказались, поставь там отказ».
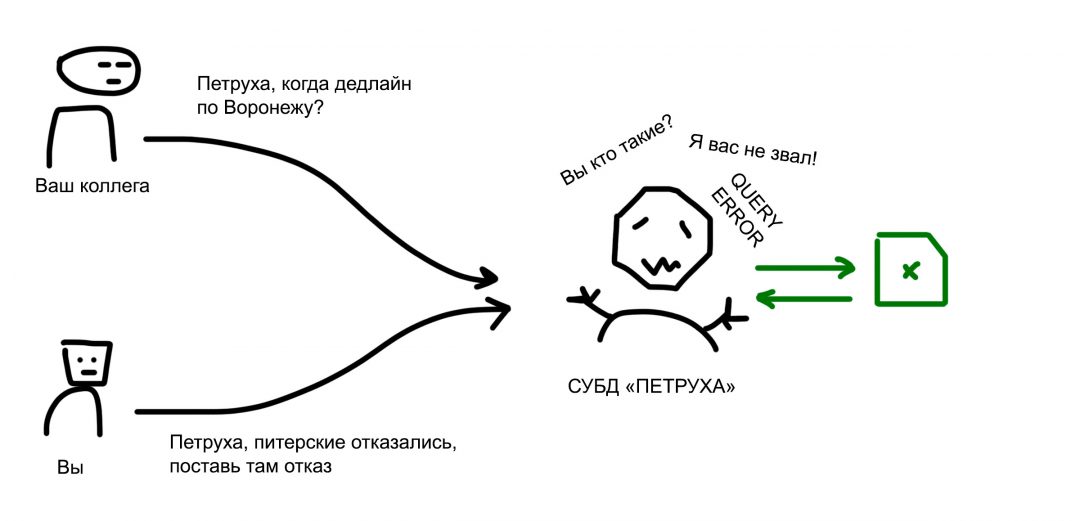
Петруха — ваша система управления базой данных. А экселька — это его база данных.
Понятно, что Петруха медленный и не всегда многозадачный, но хотя бы он избавляет от проблемы рассинхрона версий и потери данных.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
База данных — это отдельный файл?
Чаще всего да, все данные СУБД хранит внутри одного большого файла. Но если данных много или сама база так устроена, то она может разбиваться на несколько файлов поменьше.
Но для пользователей нет разницы, как физически хранится база, это забота СУБД. Главное — уметь общаться с базой через СУБД.
Где их используют
Базы данных сейчас используются почти везде:
Если у вас в работе появляется много одинаковых или похожих данных, то самый надёжный способ не потерять ничего из них — поместить их в базу данных.
Как это работает
Возьмём простой пример реляционной базы данных (можно упрощённо сказать, что это база данных в виде таблицы).
Каждая запись в реляционной базе данных раскладывается в одну или несколько ячеек. Например, запись в телефонной книге может выглядеть так:
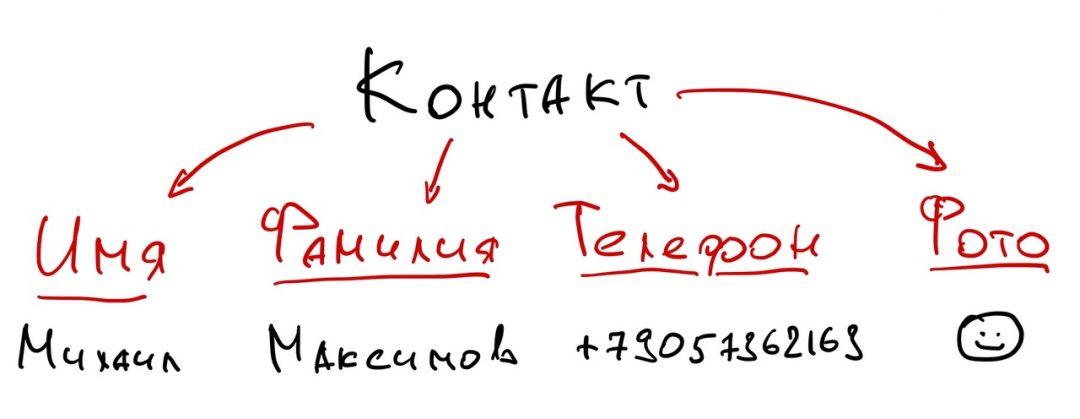
В нашем примере у базы есть поля — Имя, Фамилия, Телефон и Фото, в которых могут храниться данные. Одна строчка — одна запись с данными.
Если пользователю нужно будет найти телефон Михаила Максимова по фамилии, происходит следующее:
Запрос от пользователя: Выдай мне из базы «Контакты» все записи, где поле «Фамилия» равно «Максимов»
Ответ от базы данных: ЛОЛ КЕК Ты кто такой
Запрос пользователя: Я хозяин этой базы Админ Админыч, пароль •••••. Выдай мне из базы «Контакты» все записи, где поле «Фамилия» равно «Максимов»
Ответ от базы данных: Найдена одна запись: [Михаил, Максимов, +79057362163, вот фото]
Разные базы — разные правила
Внутри каждой базы данных и её управляющей системы свои строгие правила:
Рабочая ситуация: допустим, вы работаете в банке и открыли карточку клиента, чтобы поменять ему кредитный лимит. В этот же момент другой сотрудник из соседнего офиса тоже хочет поменять лимит этому же клиенту, но уже на другую сумму. Как база отреагирует на такое? Должна ли она разрешать второму сотруднику открывать карточку или её нужно заблокировать, пока первый не закончит? А если она разрешит открыть карточку, то что будет, если двое сотрудников напишут там разный лимит — какой из них сохранять в итоге? СУБД задаёт эти правила и следит за их выполнением.
Что дальше
В следующей статье поговорим про MySQL — бурерождённую мать всех баз. Если разобраться, как она работает, то можно творить чудеса.
Урок 1. Введение в базы данных
Что такое база данных
Структура базы данных
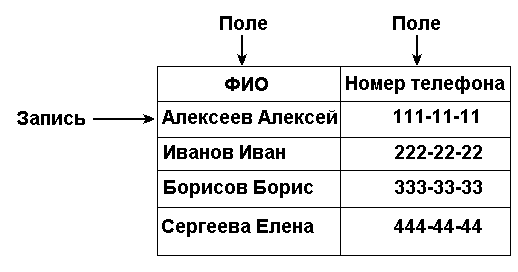
Рис.1.1. Таблица, запись и поле.
В отличие от плоских, реляционные базы данных состоят из нескольких таблиц, связь между которыми устанавливается с помощью совпадающих значений одноименных полей.
Здесь следует отметить, что использование реляционной модели баз данных не является единственно возможным способом представления информации. В настоящее время существует несколько различных моделей представления данных, которые, однако, пока не получили такого широкого распространения среди разработчиков и пользователей, как реляционная модель. То есть при разработке систем управления базами данных реляционная модель практически является стандартом.
В качестве примера реляционной базы данных можно привести поставляемую вместе с Visual Basic базу данных BIBLIO.MDB, содержащую библиографическую информацию о книгах по программированию, их авторах и издательствах, эти книги опубликовавших.
Так как Visual Basic использует ту же систему управления базами данных (MS Jet Engine), что и MS Access, то несмотря на наличие в Visual Basic средств работы со многими форматами БД, все таки в приложениях предпочтительно использовать файлы баз данных в формате MS Access. Эти файлы имеют расширение MDB и здесь в основном будут описаны приемы работы с файлами именно такого формата.
Перейдем теперь к исследованию базы данных с библиографией. Для этого откройте файл BIBLIO.MDB при помощи MS Access или VisData.
Содержимое файла базы данных BIBLIO.MDB показано на рис.1.2. В базу данных входят таблицы (Tables), запросы (Queries), формы (Forms), отчеты (Reports), макросы (Macros) и модули (Modules). Макросы, формы и модули нам не интересны, так как это вотчина разработчиков, применяющих Visual Basic for Applications или, сокращенно, VBA.
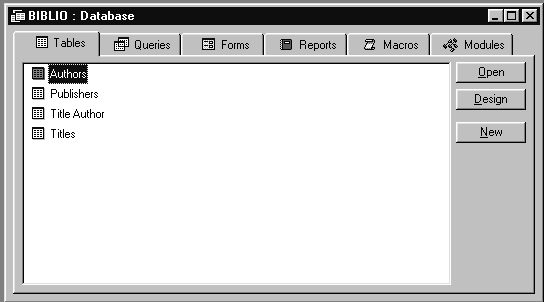
Рис.1.2. Содержимое файла BIBLIO.MDB
Из рисунка видно, что база данных состоит из таблиц: PUBLISHERS, AUTHORS и TITLES. Каждая из таблиц содержит информацию об объектах одного типа. Из названий таблиц становиться понятно, что данные в каждой таблице принадлежат одной и той же группе объектов. Каждая строка в этих таблицах однозначно определяет один объект из соответствующей группы. Вообще, база данных может состоять из одной или нескольких таблиц. Запись, в свою очередь, состоит из нескольких полей, каждое из которых содержит элемент данных об объекте.
Типы данных, которые можно поместить в таблицу, зависят от формата файла базы данных. В таблице 1.1 приведены некоторые типы данных, которые поддерживаются системой управления базами данных Visual Basic для файлов MS Access.
Таблица 1.1
Таблица PUBLISHERS (Издатели) содержит информацию об издательствах (имя компании, ее адрес, телефон, факс и др.). На рис. 1.3 и 1.4 показаны структура таблицы PUBLISHERS и ее содержимое в табличном виде.
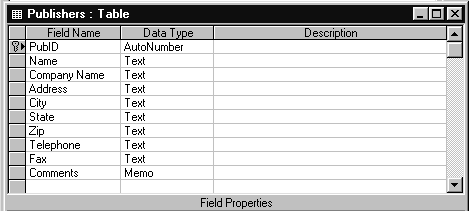
Рис.1.3. Структура таблицы PUBLISHERS 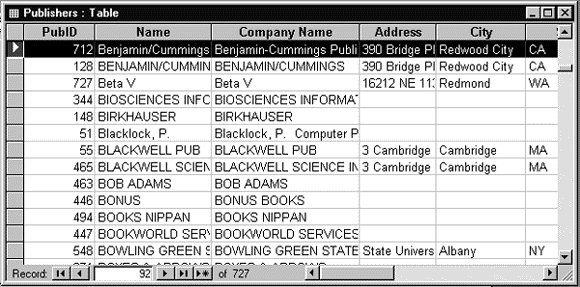
Рис.1.4. Содержимое таблицы PUBLISHERS
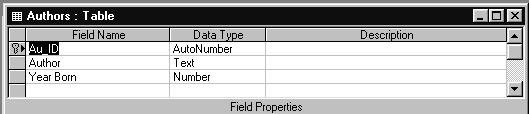
Рис.1.5. Структура таблицы AUTHORS 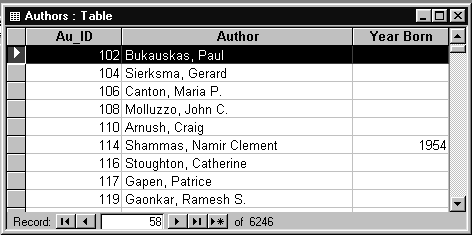
Рис.1.6. Содержимое таблицы AUTHORS
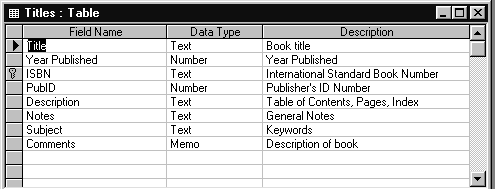
Рис.1.7. Структура таблицы TITLES 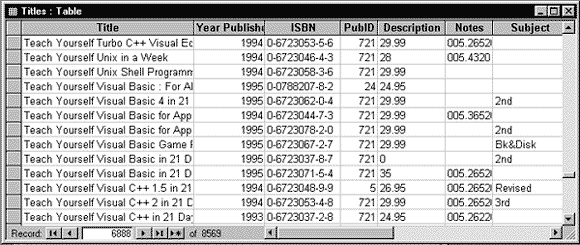
Рис.1.8. Содержимое таблицы TITLES
Из рис.1.2 видно, что в базе данных BIBLIO.MDB присутствует еще и таблица TITLE AUTHOR. На первый взгляд непонятно зачем она нужна. Ведь в базе данных есть таблица TITLES с заголовками книг и таблица AUTHORS с данными об авторах. Однако все же эта таблица нужна и для чего она так необходима станет понятно, когда в дальнейшем будем рассматривать отношения между таблицами.
Отношения между таблицами
Отношения между таблицами устанавливают связь между данными находящимися в разных таблицах базы данных.
Отношения между таблицами определяются отношением между группами объектов соответствующего типа. Например, один автор может написать несколько книг и издать их в разных издательствах. Или издательство может опубликовать несколько книг разных авторов. Таким образом, между авторами и названиями книг существует отношение один-ко-многим, а между издательствами и авторами существует отношение много-ко-многим.
Отношения между таблицами базы данных BIBLIO.MDB показаны на рис.1.9.
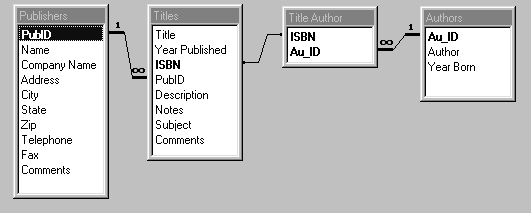
Рис.1.9. Отношения между таблицами базы данных BIBLIO.MDB.
Отношение один-к-одному
Если между двумя таблицами существует отношение один-к-одному, то это означает, что каждая запись в одной таблице соответствует только одной записи в другой таблице.
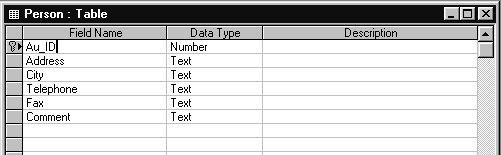
Рис.1.10. Структура таблицы PERSON
Между таблицами AUTHORS и PERSON существует отношение один-к-одному, так как одна запись, идентифицирующая автора, однозначно соответствует только одной записи в таблице PERSON, содержащей персональные данные об авторе.
Связь между таблицами определяется с помощью совпадающих полей: Au_ID в таблице AUTHORS и в таблице PERSON.
Отношение один-ко-многим
Хорошим примером отношения между таблицами один-ко-многим является отношение между авторами и названиями книг (таблицы AUTHORS и TITLES), так как каждый автор может иметь отношение к созданию нескольких книг. Связь между таблицами AUTHORS и TITLES осуществляется с помощью совпадающих полей Au_ID в обеих таблицах.
Аналогичное отношение существует между издательствами и названиями изданных книг, организацией и работающими в ней сотрудниками, автомобилем и деталями, из которых он состоит и т.п. Понятно, что подобный тип отношения между таблицами наиболее часто встречается при проектировании структуры баз данных.
Отношение много-к-одному
Отношение много-к-одному полностью аналогично рассмотренному выше отношению один-ко-многим.
Отношение много-ко-многим
Для удобства работы с таблицами, имеющими отношение много-ко-многим, обычно в базу данных добавляют еще одну таблицу, которая находится в отношении один-ко-многим и много-к-одному к соответствующим таблицам. В случае базы данных BIBLIO.MDB такой таблицей является TITLE AUTHOR.
Нормализация баз данных
Рассмотрим процесс нормализации базы данных на примере базы данных BIBLIO.MDB. Вообще говоря, все данные о книгах, авторах и издательствах можно разместить в одной таблице, названной, например, BIBLIOS. Структура этой таблицы показана на рис. 1.11. В принципе, можно работать и с такой таблицей. С другой стороны понятно, что такая структура данных является неэффективной. В таблице BIBLIOS будет достаточно много повторяющихся данных, например сведения об издательстве или авторе будут повторяться для каждой опубликованной книги. Такая организация данных приведет к следующим проблемам, с которыми столкнется конечный пользователь вашей программы:
Наличие повторяющихся данных приведет к неоправданному увеличению размера файла базы данных. Кроме нерационального использования дискового пространства, это также вызовет заметное замедление работы приложения.
Ввод пользователем большого количества повторяющейся информации неизбежно приведет к возникновению ошибок.
Изменение, например, номера телефона издательства потребует значительных усилий по корректировке каждой записи, содержащей данные об издателе.
Если, при проектировании приложения для работы с базами данных, вы организуете свои данные таким нерациональным образом, то в дальнейшем вам, скорее всего, больше не поручат решение аналогичных задач.
Чтобы избежать всех этих проблем, надо стремиться максимально уменьшить количество повторяющейся информации. Процесс уменьшения избыточности информации в базе данных посредством разделения ее на несколько связанных друг с другом таблиц и называется нормализацией данных.
Вообще говоря, существует строгая теория нормализации данных, в рамках которой разработаны алгоритмы уменьшения избыточности информации, определены несколько уровней нормализации и установлены критерии, определяющие соответствие данных определенному уровню нормализации. Знакомство с теорией нормализации данных выходит за рамки этих уроков и тем читателям, которым интересно побольше узнать об этом, можно посоветовать обратиться к специальной литературе.
Для того, чтобы построить достаточно эффективную структуру данных, достаточно придерживаться нескольких простых правил:
1. Определите таблицы таким образом, чтобы записи в каждой таблице описывали объекты одного и того же типа. В нашем случае библиографические данные можно разместить в трех таблицах:
2. Если в вашей таблице появляются поля, содержащие аналогичные данные, разделите таблицу.
3. Не запоминайте в таблице данных, которые могут быть вычислены при помощи данных из других таблиц.
4. Используйте вспомогательные таблицы. Например, если в вашей таблице есть поле Страна, то может быть стоит ввести вспомогательную таблицу Country, которая будет содержать соответствующие записи (Россия, Украина, США и т.п.). Этот прием также поможет уменьшить количество ошибок при вводе данных, допускаемых пользователями.
Ключи и индексы
Как было отмечено выше при описании отношений между таблицами, в реляционных базах данных таблицы связываются друг с другом посредством совпадающих значений ключевых полей. Ключевым полем может быть практически любое поле в таблице. Ключ может быть первичным (primary) или внешним (foreign).
Первичный ключ однозначно определяет запись в таблице. В примере с базой данных BIBLIO.MDB таблицы PUBLISHERS, AUTHORS и TITLES имеют первичные ключи PubID, Au_ID и ISBN соответственно. Таблица TITLES также имеет два внешних ключа PubID и Au_ID для связи с таблицами PUBLISHERS и AUTHORS. Таким образом, первичный ключ однозначно определяет запись в таблице, в то время как внешний ключ используется для связи с первичным ключом другой таблицы.
Ключевой поле может иметь определенный смысл, как например ключ ISBN в таблице TITLES. Однако, очень часто ключевое поле не несет никакой смысловой нагрузки и является просто идентификатором объекта в таблице. Во многих случаях удобно использовать в качестве ключа поле счетчика (Counter field). При этом вся ответственность по поддержанию уникальности ключевого поля снимается с пользователя и перекладывается на процессор баз данных. Поле счетчика представляет собой четырехбайтовое целое число (Long) и автоматически увеличивается на единицу при добавлении пользователем новой записи в таблицу.
Данные запоминаются в таблице в том порядке, в котором они вводятся пользователем. Это, так называемый, физический порядок следования записей. Однако, часто требуется представить данные в другом, отличном от физического, порядке. Например может потребоваться просмотреть данные об авторах книг, упорядоченные по алфавиту. Кроме того, часто необходимо найти в большом объеме информации запись, удовлетворяющую определенному критерию. Простой перебор записей при поиске в большой таблице может потребовать достаточно много времени и поэтому будет неэффективным.
Одними из основных требований, предъявляемым к системам управления базами данных, являются возможность представления данных в определенном, отличном от физического, порядке и возможность быстрого поиска определенной записи. Эффективным средством решения этих задач является использование индексов.
Индекс представляет собой таблицу, которая содержит ключевые значения для каждой записи в таблице данных и записанные в порядке, требуемом для пользователя. Ключевые значения определяются на основе одного или нескольких полей таблицы. Кроме того, индекс содержит уникальные ссылки на соответствующие записи в таблице. На рис.1.12 показан фрагмент таблицы CUSTOMERS, содержащей информацию о покупателях, и индекс IDX_NAME, построенный на основе поля Name таблицы CUSTOMERS. Индекс IDX_NAME содержит значения ключевого поля Name, упорядоченные в алфавитном порядке, и ссылки на соответствующие записи в таблице CUSTOMERS.
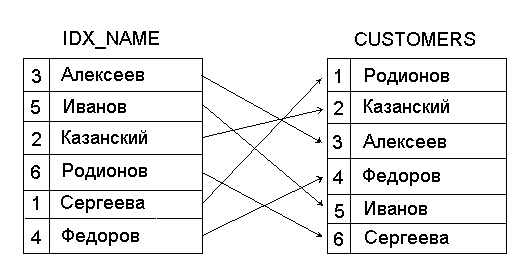
Рис.1.12. Связь между таблицей и индексом.
Каждая таблица может иметь несколько различных индексов, каждый из которых определяет свой собственный порядок следования записей. Например, таблица AUTHORS может иметь индексы для представления данных об авторах, упорядоченные по дате рождения или по алфавиту. Таким образом, каждый индекс используется для представления одних и тех же данных, но упорядоченных различным образом.
Вообще говоря, таблицы в базе данных могут и не иметь индексов. В этом случае для большой таблицы время поиска определенной записи может быть весьма значительным и использование индекса становиться необходимым. С другой стороны, не следует увлекаться созданием слишком большого количества индексов, так как это может заметно увеличить время необходимое для обновления базы данных и значительно увеличить размер файла базы данных.
При разработке приложений, работающих с базами данных, наиболее широко используются простые индексы. Простые индексы используют значения одного поля таблицы. Примером простого индекса в базе данных BIBLIO.MDB может служить код ISBN, идентификатор автора Au_ID или идентификатор издательства PubID.
Хотя в большинстве случаев для представления данных в определенном порядке достаточно использовать простой индекс, часто возникают ситуации, где не обойтись без использования составных индексов. Составной индекс строится на основе значений двух или более полей таблицы. Хорошей иллюстрацией использования составных индексов может служить база данных родственников при генеалогических исследованиях какой-либо фамилии. Понятно, что использование в качестве простого индекса фамилии человека в данном случае недопустимо. Даже использование составного индекса, основанного на полях имени, фамилии и отчества может быть неэффективным, так как и в этом случае все равно возможно существование достаточно большого числа однофамильцев. Выходом из положения может быть использование составного индекса, основанного, например, на следующих полях таблицы: имя, фамилия, отчество, город и номер телефона.