
Декомпозиция задач: что это и зачем нужно
И как сделать так, чтобы всё шло по плану.
Приходит маркетолог интернет-магазина к разработчику с задачей:
Для маркетолога это одна строчка текста. Он думает, что такую простую задачку можно сделать за 15 минут. А разработчик пожимает плечами: «Подумаю, потом назову срок». Что за дичь? А вот так.
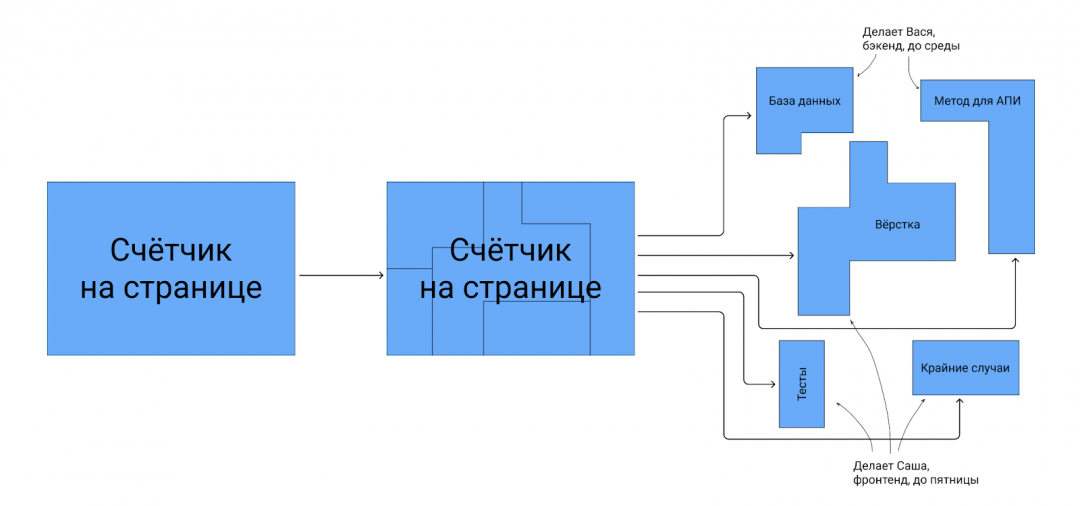
Прежде чем эту задачу делать, её было бы неплохо декомпозировать — то есть понять, из чего она состоит, на что влияет и в каком порядке её стоит делать. В случае со счётчиком покупок это получится такой набор подзадач:
В зависимости от архитектуры системы могут быть и другие действия. Поэтому назвать срок сразу разработчик не может: сначала надо понять, что вообще нужно делать и сколько времени займёт каждый пункт.
Чем крупнее задача, тем сложнее обойтись без декомпозиции. «Покрасить кнопку в красный» можно не раскладывать. А «Добавить новый раздел в админку» точно стоит сначала разобрать по частям: тут работа и для фронтенда, и для бэкенда. Декомпозиция нужна не всегда, но очень часто.
 Была одна большая задача, стало несколько маленьких.
Была одна большая задача, стало несколько маленьких.
Зачем декомпозировать
Понять, что и в каком порядке делать. «Добавить счётчик на страницу» кажется задачей для фронтенд-разработчика. Но на самом деле он сможет сделать свою часть, только когда будет готова база данных и АПИ — механизм, по которому эти данные подтягиваются на сайт.
Если фронтенд попробует сам предположить, как будет выглядеть запрос, то после интеграции могут всплыть непредвиденные баги: бэкенд мог реализовать АПИ не так, как думал фронтенд-разработчик. Декомпозиция поможет понять, с какой стороны подступиться и в какой последовательности двигаться.
Оценить сроки. Когда задача разложена на части, можно оценить по времени каждую и понять, сколько потребуется на всё вместе. Понятно, что не получится запустить счётчик за день, если только на базу данных и АПИ нужно два.
Упростить тестирование. Тестировать проще, когда понятно, что нужно проверить. В случае со счётчиком: базу данных, метод и вёрстку.
Расставить приоритеты. Декомпозиция может показать, что задача большая и требует времени. Например, если маркетолог хочет указать не только количество покупок, но и количество городов, в которые товар доставляли. Разработчик может показать, что делать всё вместе — две недели, но счётчик покупок можно выкатить быстрее. А маркетолог уже решит, как лучше поступить.
Как декомпозировать
Декомпозировать можно по-разному, это зависит от масштаба и сути задачи.
Например, запуск мобильного приложения можно декомпозировать сначала на уровне платформ: iOS и Android. Потом — на уровне пользовательских сценариев: регистрация, просмотр контента, покупка, переписка с контактами. Сценарии можно разложить на интерфейс и серверную часть. А их — на отдельные конкретные задачи.
Чаще всего задачи раскладывают вертикально и горизонтально. Вертикально — значит по типам работ. Горизонтально — значит вглубь одного типа работы. Вот как это работает со счётчиком покупок в интернет-магазине:
Вертикальная декомпозиция:
Бэкенд: считать количество покупок и отдавать данные на фронт.
Фронтенд: запрашивать данные при загрузке страницы и выводить.
Горизонтальная декомпозиция:
Кто должен декомпозировать
Декомпозировать задачу может сам разработчик, тимлид, менеджер проекта или другой компетентный сотрудник: универсальных правил здесь нет. Руководитель службы разработки Яндекс.Практикума Александр Трегер рассказывает, как это работает у них:
Когда появляется новая большая задача, один из опытных разработчиков берёт её на себя. С этого момента он за неё отвечает: собирает встречи, даёт заказчикам обратную связь, определяет, как решить задачу, декомпозирует её. Для разработчиков это возможность расширить свою зону ответственности, попробовать себя в роли архитектора и менеджера проекта.
Иногда нужно выделить время и разобраться в задаче, подумать про пограничные случаи, изучить технологию, придумать решение. Бывает, что на этом этапе задача может разделиться на несколько этапов: что делаем сейчас, а что потом. Так было, например, с проверкой домашних работ от студентов: сначала они приходили в виде архива на проверку, потом появился полноценный интерфейс для ревью кода. Система будет развиваться и дальше, но декомпозиция помогает понять, что и в какой последовательности можно сделать, чтобы быстрее получить результат.
👉 Почитайте полное интервью с Александром Трегером. Там больше подробностей о разработке Практикума.
Методология программирования
Сейчас мы немного поговорим об общей методологии составления программ. Конечно, не стоило бы заводить об этом разговор, если бы мы ограничивались написанием только небольших программ, т.е. программ, содержащих до нескольких сотен строк. Такие программочки легко охватить взором как единую и неделимую единицу. Однако по мере увеличения размера программы такая монолитность становиться не удобной. Поэтому программа должна быть разбита на ряд независимых программ, называемых модули. А сам процесс разбиения назовем декомпозицией. Необходимость декомпозиции становится все более и более очевидной, когда возрастает размер программы, а в процесс составления программ вовлекается много людей.
По этой причине программа может быть разбита на части, причем каждая их них может создаваться отдельными участниками относительно независимо от остальных. Кроме того, следует учитывать и такой немаловажный факт, как вопросы модификации и сопровождения программ, по возможности не сопровождая этот процесс полной переделкой. В таких случаях предпочтительнее вносить изменения в существующую структуру и, следовательно, важно, чтобы структура допускала возможность такой модификации. В частности, необходимо, чтобы части были независимы друг от друга, что позволяло бы вносить изменения в один модуль, не изменяя другие. Нужно учитывать и тот факт, что вопросами сопровождения программного продукта, как правило, занимается вовсе не его разработчик, поэтому еще одна цель, которую преследует структурируемость программ, – это простота понимания программы.
Декомпозиция и абстракция
На этапе декомпозиции задачи на подзадачи следует придерживаться трех правил:
Декомпозиция – весьма полезный инструмент для решения задач в различных областях. Однако при неумелом использовании она не может принести желаемого эффекта. К числу наиболее распространенных проблем относится ситуация, когда объединение решений подзадач не приводит к решению исходной. Как правило, такое случается для больших и плохо понимаемых задач.
Пример. Группа авторов создает пьесу, причем каждый из них пишет текст для одного персонажа. Очевидно, что хотя каждый из авторов и справится со своей задачей, о смысле готового произведения говорить не приходится.
Поэтому стадии декомпозиции должен предшествовать этап абстракции.
После чего декомпозиция такой задачи окажется более простой по сравнению с исходной.
Пример. Группа авторов предварительно оговаривает сюжет пьесы, смысл отдельных диалогов и т.п.
Задача абстрагирования и последующей декомпозиции типична для процесса создания программ. Декомпозиция используется для разбиения программ на компоненты, которые затем могут быть объединены, позволив решить основную задачу, абстрагирование же предлагает продуманный выбор таких компонент. Последовательно выполняя то один, то другой процесс можно свести исходную задачу к подзадачам, решение которых известно.
Использование в программировании языков высокого уровня хотя и позволяет не манипулировать напрямую кодами машинных инструкций, что существенно упрощает процесс написания программ, однако зачастую конструкции, написанные на таком языке, не удовлетворяют необходимому уровню абстракции.
Сравним, например, два фрагмента кода
На уровне абстракции, определенном языком высокого уровня, приведенные фрагменты отличаются друг от друга: первый фрагмент, отыскивает первый максимальный элемент в массиве (если их несколько), второй – последний. Однако оба они написаны для выполнения одной и той же функции – отыскать максимальное значение в целочисленном массиве a и индекс такого элемента. Если необходимо выполнение этого требования, то очевидно, что приведенные фрагменты не находятся на требуемом уровне абстракции.
Было бы гораздо удобнее обладать некоторым мощным набором примитивов для манипуляции со структурами данных. Так, если бы существовали примитивы GetMaxValue и GetMaxIndex, тогда рассматриваемая задача легко реализуется
aMax = GetMaxValue (a);
iMax = GetMaxIndex (a);
Но предусмотреть необходимость использования всех абстракций такого рода было бы достаточно сложно для разработчика языка программирования, иначе говоря, нельзя реализовать все абстракции для всех случаев жизни. Было бы гораздо более эффективным предусмотреть в языке программирования такие механизмы, которые позволяли бы программисту создавать свои собственные абстракции по мере необходимости. Наиболее распространенным механизмом такого рода является использование процедур (или функций в языке С). Разделяя в программе тело процедуры и обращение к ней, язык позволяет реализовать два важных метода абстракции: абстракцию через параметризацию и абстракцию через спецификацию.
Абстракция через параметризацию
Абстракцией через параметризацию почти все Вы пользовались много раз, даже не замечая этого. Возьмем наш пример с поиском максимального значения в массиве. Использовав эту процедуру однажды, вероятно, где-то в другом месте программы необходимо будет найти максимальный элемент в другом массиве, причем его имя может быть вовсе не а, а скажем z.
Следовательно, мы используем абстракцию через параметризацию, обобщая этим процедуру и делая ее более универсальной.
Абстракция через параметризацию – весьма полезное средство. Она не только позволяет проще описывать большое число вычислений, но и, как правило, легко реализуема. Однако она не позволяет полностью реализовать тот уровень обобщения, который можно достичь при работе с процедурами.
Абстракция через спецификацию
Спецификации важны для достижения требуемой модульности программы. Абстракция используется для декомпозиции программы на модули. Однако взятая в отдельности абстракция является малопонятной. Без какого-либо описания мы не можем ни сказать, что она собой представляет, ни отличить ее от одной из своих реализаций. В качестве такого описания и выступает спецификация.
При анализе спецификации для уяснения смысла обращения к процедуре нужно придерживаться двух правил:
1. После выполнения процедуры можно считать, что выполнено конечное условие. Выполнение конечного условия при соблюдении начальных условий – это собственно то, ради чего и построена процедура. Если это процедура поиска максимального значения в массиве, то конечное условие – факт, что максимальный элемент найден. Если это процедура вычисления квадратного корня, то конечное условие – нахождение квадратного корня.
2. Можно ограничиться только той информацией, которую подразумевает конечное условие.
Эти правила демонстрируют два преимущества абстракции через спецификацию. Первое состоит в том, что программисты, использующие данную процедуру, не обязаны знакомиться с ее телом. Следовательно, им не нужно уяснять, например, подробности алгоритма отыскания квадратного корня, устанавливая действительно ли возвращенный результат искомое число.
Второе правило показывает, что на самом деле имеем дело с абстракцией: абстрагируясь от тела процедуры, можно не обращать внимания на несущественную информацию. Именно такое «игнорирование» информации и отличает абстракцию от декомпозиции. Конечно, анализируя тело процедуры можно извлечь некоторое количество информации, не следующей из конечного условия (как, например, то, что найденный элемент первый или последний в рассмотренном выше примере). В спецификации подобная информация о возвращаемом результате отбрасывается.
Абстракции через параметризацию и через спецификацию являются мощным средством для создания программ. Они позволяют определить два вида абстракций: процедурную абстракцию и абстракцию данных. В общем случае каждая процедурная абстракция и абстракция данных используют оба способа.
Например, абстракцию SQRT (извлечение квадратного корня) можно сравнить с операцией: она абстрагирует отдельное событие или задачу. Мы будем ссылаться к абстракциям такого рода как к процедурным абстракциям. Отметим, что абстракция SQRT включает в себя как абстракцию через параметризацию, так и абстракцию через спецификацию. Процедурная абстракция – мощное средство. Она позволяет расширить заданную некоторым языком программирования виртуальную машину новой операцией. Такое расширение полезно, когда мы работаем с задачами, которые можно представить в виде набора независимых функциональных единиц. Однако часто удобно к такой новой виртуальной машине добавить несколько объектов данных с новыми типами.
Поведение объектов данных наиболее естественно представлять в терминах набора операций, применимых к данным объектам. Такой набор включает в себя операции по созданию объектов, получению информации о них и их модификации.
Например, при работе с целыми числами используются обычные арифметические операции, но при работе со стеком нужны другие операции, такие как POP (изъять из стека), PUSH (положить в стек).
Таким образом, абстракция данных (или тип данных) состоит из набора объектов и набора операций, характеризующих поведение этих объектов.
Процедурная абстракция
Процедура выполняет преобразование входных аргументов в выходные. Более точно, это есть отображение набора значений входных аргументов в выходной набор результатов с возможной модификацией входных значений. Причем оба эти набора могут быть пусты.
Посмотрим, как же проявляются рассмотренные нами абстракции через параметризацию и спецификацию в процедурах, и выявим те преимущества, предоставляемые процедурной абстракцией.
Абстракция представляет собой некоторый способ отображения. При этом мы абстрагируемся от «несущественных» подробностей, описывая лишь те, которые имеют непосредственное отношение к решаемой задаче. Реализации абстракций должны быть согласованы по всем таким «существенным» подробностям, а в остальном могут отличаться. Разумеется, различие между существенным и несущественным зависит от конкретной решаемой задачи.
В абстракции через параметризацию мы абстрагируемся от конкретных используемых данных. Эта абстракция определяется в терминах формальных параметров. Фактические данные связываются с этими параметрами в момент использования этой абстракции. Значения конкретных используемых данных являются несущественными, важно только их количество и тип. Преимущество таких обобщений заключается в том, что они уменьшают объем программ и, следовательно, объем модификаций.
В абстракции через спецификацию внимание фокусируется на «поведении» – «то, что делается», несущественным же является то, «как» это делается. В этом состоит главное преимущество абстракции через спецификацию, что позволяет переходить к другой реализации без внесения изменений в программу, использующую данную процедуру.
Например, существует достаточно много разнообразных алгоритмов сортировки и предположим, что в вашей программе описана некоторая процедура = функция SORT, реализующая один из таких алгоритмов. Допустим, что по каким-то причинам Вас перестал удовлетворять запрограммированный вариант, в этом случае достаточно просто переписать тело этой самой SORT, не внося изменений в остальную часть программы (однако при условии, что сохранится тип обрабатываемых данных). В данном случае для общего выполнения программы считается несущественным механизм сортировки.
Абстракция через спецификацию наделяет структуру программы двумя отличительными особенностями.
Для понимания и сопровождения программы, составленной из абстракций важно знать, что реализуют собой сами используемые абстракции, а не конкретные операторы их тел. Именно в этом и состоит игнорирование несущественной информации, коей является текст тел используемых процедур.
Вторая особенность – модифицируемость. Абстракция через спецификацию позволяет упростить модификацию программы. Если реализация абстракции меняется, но ее спецификация остается прежней, то эти изменения не повлияют на оставшуюся часть программы. Разумное определение необходимых абстракций на начальном этапе разработки с учетом возможных модификаций может значительно сократить объем работ.
Как Вы видите, все представленное здесь, в общем-то, не является чем-то качественно новым, возможно лишь, что для многих из Вас это заставит по-иному смотреть на, казалось бы, привычные и понятные вещи. Язык С, с которым Вы достаточно хорошо знакомы, как впрочем, и все процедурные языки такого уровня, позволяет реализовывать процедурную абстракцию посредством написания функций. Однако до сих пор возможность добавлять в базовый уровень новых типов данных не подкреплялась введением новых операций с этими типами. Такая возможность предоставляется на уровне абстракции данных.
Абстракция данных
То, какие новые типы данных необходимы, зависит от области применения программы. При реализации интерпретатора полезны стеки, а при определении пакета численных функций – матрицы, в банковской системе естественной абстракцией являются счета. В каждом конкретном случае абстракция данных состоит из набора объектов (стеков, полиномов, матриц и т.д.) и набора операций над ними. Например, матричные операции включают в себя сложение, умножение.
Новые типы данных должны включать в себя абстракции как через параметризацию, так и через спецификацию. Абстракция через параметризацию может быть осуществлена также как и для процедур, – использованием параметров там, где это имеет смысл. Абстракция через спецификацию достигается за счет того, что мы представляем операции как часть типа. Чтобы понять зачем, почему необходимы операции, посмотрим, что получится, если рассматривать тип просто как набор объектов. В этом случае, все, что необходимо сделать для реализации типа – это выбрать представление памяти для объектов. Тогда все программы могут быть реализованы в терминах этого представления. Однако, если представление изменяется, все программы, которые используют этот тип, должны быть изменены.
С другой стороны, предположим, что операции включены в определение типа следующим образом:
При этом потребуем, чтобы пользователи употребляли эти операции непосредственно, не обращаясь к представлению. Затем для реализации типа мы реализуем операции в терминах выбранного представления. При изменении представления нужно заново реализовывать только операции. Однако переделывать программы уже нет необходимости, так как они не зависят от представления, а зависят только от операций. Следовательно, мы получаем абстракцию через спецификацию.
Если обеспечено большое количество операций, отсутствие прямого доступа к представлению не будет создавать для пользователя трудностей, все что они хотят сделать с объектами, может быть сделано при помощи операций. Обычно имеются операции для создания и модификации объектов, а так же для получения информации об их значениях. Пользователи могут увеличивать набор операций определением процедур, но такие процедуры не должны использовать представление.
Абстракции данных полезны при модификации программ, когда предпочтительнее изменить структуру данных в реализации типа, не меняя при этом самой программы.
Для реализации типа данных мы выбираем представление для объектов и реализуем операции в терминах этого представления. Выбранное представление должно предоставлять возможности для довольно простой и эффективной реализации всех операций. Кроме того, если некоторые операции должны выполняться быстро, представление должно предоставлять и эту возможность. Заметим, что, вообще говоря, следует различать новый абстрактный тип и тип его представления. Предполагается, что с типом представления мы имеем дело только при реализации. Все, что мы можем делать с объектами абстрактного типа, – это применять к ним соответствующие данному типу операции.
Если абстракция данных определена, то она не отличается от встроенных типов и ее объекты и операции должны использоваться точно также как объекты и операции встроенных типов. Определенные пользователем типы могут также использоваться для представления других определяемых пользователем типов.
Теперь, когда мы немного уяснили, что же такое операции над абстрактными типами данных, дадим им некоторую классификацию.
Классы операций
Операции абстракции данных распадаются на четыре класса.
Обычно примитивные конструкторы создают не все, а только некоторые объекты. Другие объекты создаются конструкторами и модификаторами. Иногда наблюдатели комбинируются с конструкторами и модификаторами (pop).
Теперь скажем несколько слов о полноте новых типов данных.
Полнота
Тип данных является полным, если он обеспечивает достаточно операций для того, чтобы все требующиеся пользователю работы с объектами могли быть проделаны с приемлемой эффективностью.
Строгое определение полноты дать невозможно, хотя существуют пределы относительно того, насколько мало операций может иметь тип, оставаясь при этом приемлемым. В общем случае абстракция данных должна иметь операции, по крайней мере, трех из четырех рассмотренных классов. Это примитивные конструкторы, наблюдатели и либо конструкторы, либо модификаторы.
Полнота типа зависит от контекста использования, т.е. тип должен иметь достаточно богатый набор операций для предполагаемого использования. Если тип предполагается использовать в ограниченном контексте, то нужно обеспечить достаточно операций только для этого контекста. Если тип предназначен для общего пользования, то желательно иметь более богатый набор операций. Однако чрезмерное количество операций в типе затрудняет понимание абстракций, и делает сложной ее реализацию. Введение дополнительных операций должно быть соотнесено с затратами на реализацию этих операций. Если тип является полным, его набор операций может быть расширен процедурами, функционирующими вне реализации типа.
Декомпозиция. Как разобрать огромный проект на понятные сегменты для предварительной оценки

Вот притащили вам с охоты мамонта: выше вас ростом, упитанный и на вид пока несъедобный. Что делать?! Декомпозировать, конечно: лапы отдельно, шкуру отдельно. Но с чего начать? И когда хоть примерно будет готов ужин?
Если вам достался жирненький проект, вопросы примерно такие же — какой круг задач предстоит, и как их предварительно оценить. Декомпозиция — крутой способ разложить всё по полочкам и прикинуть объём работ, заложить резервы на трудные блоки и докопаться до неприятных задач со звездочкой. Как это сделать, мы уже рассказывали в одном из обучающих видео. А для любителей вдумчивого чтения мы преобразовали его в крутую статью.
Уровни декомпозиции
Казалось бы, проще простого: режем проект на большие части, эти части — ещё на части, а те части — снова на части. Но действительно ли всё так просто?!
1 уровень. Крупные блоки или компоненты
Это может быть блок с е-коммерсом, личный кабинет, мобильное приложение, супер-навороченная админка. В общем, любые блоки работ, которые могут быть как-то между собой связаны, но которые можно делать изолированно друг от друга.
2 уровень. Страницы сайта или экраны мобильного приложения
В случае с блоком «мобильное приложение», как на схеме выше, разбиваем его на экраны. Но как узнать, что вы учли все-все-все возможные экраны? Для проверки полноты берите в расчёт сценарии использования — это даст понимание, какие задачи юзеры будут решать в приложении (или на сайте) и каким примерно образом они это будут делать.
Для e-commerce основной сценарий — продавать, а путь пользователя в нём выглядит так: каталог → список товаров → карточка товара и так далее.
Есть соблазн написать в смете только сценарий использования и его оценку (скажем, сценарий покупки товара или сценарий заказа такси) — ну, ведь понятно же, что там внутри. Нет, непонятно, и есть большой риск потерять множество шагов, поскольку такие сценарии большие, и их крайне сложно адекватно оценить целиком.
Когда сценарий раскладывается на экраны, шансов ошибиться становится меньше. Но помните, что каждый сценарий стоит проверять на связанность — достаточно ли вам вот этих экранов, чтобы этот сценарий сбылся?
У нас есть маркетплейс — магазин, куда другие производители могут загружать свои товары. Сценарии, лежащие на поверхности: загрузка своих товаров (загрузка и описание, разделы каталога и вот это вот всё), покупка товара (шаги покупателя на пути к цели), обработка заказа (как будут распределяться деньги, как будет получать свою долю маркетплейс и так далее). Если всё это не расписать подробно, можно запросто упустить кучу нюансов.
Будет ещё легче, если вы выделите ключевые роли на проекте (пользователь, администратор интернет-магазина и т. д.), у каждой из которых есть свой сценарий, а у каждого сценария — свой набор экранов. И тогда проверить полноту экранов ещё проще — достаточно посмотреть, связан и выполняется ли сценарий конкретной роли по ним.
3 уровень. Содержание экранов
В общем случае у вас на экранах могут быть какие-то вкладки либо какие-то блоки — грубо, вложенные экраны. Например, страница корзины/оформления заказа — здесь всегда есть блок товаров со своим сценарием (добавить-убавить-очистить), а еще блоки доставки, оплаты, авторизации, бонусной системы и так далее. Бывают ситуации, когда эти блоки также разбивают на экраны по шагам. Зависит от решения, принятого по итогам аналитики — бывает, что удобнее их всё-таки «слить» воедино.
Задача менеджера, когда он добрался до такого экрана, — посмотреть, из чего тот состоит. Бывает, экран легко разбить на блоки, бывает — сложно. Яркий пример сложной разбивки — калькуляторы: по ним чаще всего неочевидно, что происходит и как процесс расчёта делить на шаги.
Когда вы добираетесь до третьего уровня, нужно быть супер-внимательными, потому что на странице могут появляться самые разные вещи. И важно понимать, откуда они там вообще берутся — от этого будут сильно зависеть ваши оценки.
Откуда эта хрень на странице?!
Итак, вы добрались до какого-то блока или страницы. Самое время задать себе вопрос «Откуда это на странице?!». Но проджекты, аналитики и аккаунт-менеджеры (и даже заказчики) вот тут часто-часто ленятся — «подумаем об этом потом».
Например, аналитик сказал: «это мы как-нибудь на коде решим», а потом на планинге сидят 4 умных человека, смотрят друг на друга и спрашивают: «кто это придумал, что это за маразм?!». Такая ситуация — явный признак, что где-то недоработали раньше. Бывает, конечно, что принятие какого-то решения действительно откладывается, но это должно быть осознанно и где-то зафиксировано.
Чем меньше вы понимаете в момент «Откуда это на странице!?», тем больше у вас должен быть зазор в смете. И когда к вам приходит клиент и говорит «а почему тут такой большой зазор?!», у вас должен быть готовый ответ — потому что вы не понимаете, как работает то, то и это (лучше — фиксированный перечень конкретных вопросов), и что эти вопросы вы будете выяснять вместе с ним позже.
Итак, какими могут быть варианты, откуда берутся данные на странице?
Вариант 1. Хардкод
Самый простой в реализации вариант ответа на наш вопрос — хардкод. Это значит, что программисты сели, прямо в коде зафигачили какую-то штуку, и теперь поменять ее могут только они. Самые частые блоки, с которыми так делают — логотипы компаний, иногда ссылки на соцсети, время от времени такое делают с меню (всё реже), телефонами (плохо!), декоративными элементами на верстке. Всё это — более-менее разумные моменты. Неразумно, это когда в код зашиваются, например, ВСЕ страницы или SEO-тексты блоками.
Вариант 2. Включаемая область
У включаемых областей есть специфика: во-первых, их можно случайно удалить. Во-вторых, если в них указываются даты мероприятий или цены на товары, это чревато путаницей, поскольку у этих областей нет связанности: если поменять дату или цену в одном месте, в другом она останется той же. Клиенты зачастую сразу говорят, что такого им не нужно — а значит, придётся продумывать, как менять цены, даты и прочие изменяемые поля автоматически и повсеместно.
Вариант 3. Из админки (из базы данных)
Итак, мы знаем, что какие-то данные выбираются из базы данных. Тогда нам нужно понимать, из какой сущности и из какого поля. Примеры сущностей в интернет-магазине: «товар», «раздел», «пользователь», «заказ» — то есть то, что состоит из каких-то полей. Поля — например, «цена».
Но достаточно ли нам будет понимать, из какой сущности и из какого поля выводятся данные? Не совсем. Когда выбираете какую-то информацию из базы, она может выводиться не в том виде, как она там хранится, а в несколько модифицированном.
Например, это формула
Когда информация хранится в базе, но ее нужно как-то определенным образом модифицировать, появляется понятие «формула». Одна из самых опасных вещей, которую менеджеры часто пропускают.
Когда вам аналитик говорит «ну там это как-то считается» — навострите ушки, впереди точно будет затык. Математики не понимают программистов и считают что, их формулу достаточно переписать и следом «просто» запрограммировать — делов-то. Но когда клиента начинаешь спрашивать о формуле, часто слышишь что-то вроде «ой, она у нас там в excel», или «механика пока непонятна», или вообще «ну скопируйте вон с того сайта».
Видите формулу — копайте глубже. У неё внутри есть коэффициенты — а откуда берутся эти коэффициенты? Добро пожаловать в новый виток расследования «Откуда эта хрень на странице!?».
Вот из-за этого о формулах никто не любит думать:)
В зависимости от используемой технологии бывает, что часть данных хранится в файлах. Может показаться, что это какая-то сущность или поле сущности, но это всё-таки ФАЙЛ.
Очень часто файлы в самой базе данных не хранятся, чтобы не «раздувать» её. Из-за этого работа с ними организована иначе. В случае банального каталога товаров файлом может быть фотография у пользователя (userpic), описания, спецификации в pdf и всё такое прочее. Такие файлы находятся не совсем в базе, но при оценке важно понимать, что они есть.
С файлами ещё бывает история, что их нужно хранить на отдельных серверах, или в облаках S3, закачивая по специальному протоколу, но это уже нюансы масштабирования. На старте проекта, окупаемость которого непонятна, городить тут огород я не вижу смысла. Исключение — тяжелый видео-контент. Его лучше сразу писать в видеохостинги.
— Владимир Завертайлов, CEO & Founder
Как данные попадают в базу данных?
Обычно администратор или контент-менеджер садится и забивает данные ручками. Тогда здесь должен возникать вопрос, а хватит ли ему стандартных компонентов админки для этого. Для этого ПМ должен быть очень хорошо знаком с возможностями стандартной административной панели. А ещё с ними должен быть знаком аналитик и тестировщик (про кодера, понятно, молчим). В Сибирикс все QA-специалисты проходят базовый курс контент-менеджера, чтобы понимать, на что способна админка. Ну, а про то, что QA-спецы у нас обычно вырастают в проджект-менеджеров, мы уже как-то писали.
У вас на дизайне есть слайдер, где расставлены точки, по клику на которые открывается всплывашка, в которой есть фотография, описание и ссылка на куда-нибудь. Вопрос: как расставлять эти точки? Как вариант — координаты X и Y, но вряд ли контентщик будет счастлив от такого функционала. А значит, придётся что-то придумывать. И значит, в смету нужно это заложить.
Второй момент, который проджекты часто упускают, — права доступа и хватит ли их. А значит, это тоже нужно иметь ввиду и сразу перечислить потенциальные роли.
Вариант 4. Интеграция со сторонним ресурсом
Один из источников данных в базе — пользовательский контент. И здесь важно понимать, как он попадает в базу. На этом этапе часто теряется один из крупных сценариев: например, как пользователь вносит отзывы. У отзывов часто бывает рейтинг — штука с виду простая, но внутри она может быть довольно сложно организована. У чего больше рейтинг? Там, где поставили одну оценку в 10 баллов, или где 1000 оценок, но разных? Среднеарифметическое тут работает плохо. Но хитрые алгоритмы есть — привет, ещё один резерв в смете.
Если данные берутся всё-таки с внешнего источника, то без интеграции никак. Вариантов интеграции может быть несколько:
Другая проблема — админы сайтов, с которым парсятся данные, не слишком счастливы, что эти данные кто-то «ворует», и будут всячески защищаться. А это приводит к «падению» парсинга и попаданию в черные списки. Вы попытаетесь с этим бороться добавлением каких-нибудь платных proxy — короче, целый квест. Есть особые сервисы для организации парсинга — например, Mozenda, Automation Anywhere, Beautiful Soup, WebHarvy или Content Grabber (полный список из 30 сервисов ищите тут).
Здесь имеется ввиду, что есть какой-то интеграционный протокол, либо файловый протокол, либо XML, либо шина данных (сервер очередей вроде RabbitMQ, ZerroMQ или Apache Kafka) — подробнее о разнице штатной интеграции и по API наш техдир рассказывает тут. С чем именно интегрировать и по какому протоколу, на этапе предварительной оценки не столь важно — важнее, есть ли для этого документация. А у неё обычно бывает два состояния:
Хуже всего бывает, когда говорят «ну вы, программисты, между собой договоритесь и разберитесь сами как-нибудь». Если протокол не формализован и взаимной ответственности нет, критический путь проекта будет пролегать через интеграцию, и на ней он завалится. Или по крайней мере, здесь потратится куча времени на согласование с программистом заказчика его протокола и отладку.
Соответственно, если на проекте планируется интеграция с внешним сервисом, на неё нужно закладывать большие резервы. Лайфхак, если нужно интегрироваться, а протокола пока нет — делать MOCK-объекты. Это специальные заглушки для интеграционного протокола, которые можно быстро сделать. А как только будет реальный протокол — просто заменить их (но обязательно с перепроверкой).
Как все это «подружить»
Начинаем с крупных компонентов: первый, второй третий — можно расписать подробно. Следом важно примерно понять, какие есть пользователи (роли) и какие у них сценарии. Сами сценарии в смету лучше не прописывать. Дальше — идём по страницам. После — работаем с отдельными блоками, используя уже известную схему «Откуда эта хрень на странице?!».
Как только вы слышите слово «калькулятор» или «считается», напрягайтесь  Когда есть интеграция со сторонним сервисом — тоже. В остальном — ничего страшного, и всё довольно прозрачно
Когда есть интеграция со сторонним сервисом — тоже. В остальном — ничего страшного, и всё довольно прозрачно
Когда это может не сработать
Если на проекте есть какая-то дремучая математика, и вы живете в мире, полном злых неожиданностей, то декомпозиция по экранам будет давать сбой. В общем случае она довольно хорошо показывает, что и как происходит на типовых проектах.
Успехов в декомпозиции и почаще заглядывайте к нам на YouTube-канал за новыми полезными видео для проджектов (и не только)!