
Написание программ на PHP с использованием fork()
Параллельные программы на PHP
Реализация
Реализация этого системного вызова в PHP очень проста:
Что такое системный вызов fork()
Системный вызов fork() в *nix-системах представляет из себя такой системный вызов, который делает полную копию текущего процесса. Системный вызов fork() возвращает своё значение два раза: родитель получает PID потомка, а потомок получает 0. Как ни странно, во многих случаях только этого достаточно для того, чтобы писать приложения, использующие несколько CPU.
Подводные камни при использовании fork()
На самом деле fork() делает свою работу не задумываясь о том, что находится у пользовательского процесса в памяти — он копирует всё, например функции, которые зарегистрированы через atexit (register_shutdown_function). Пример:
К сожалению, PHP в конце выполнения скрипта осуществляет вызов деструкторов (в том числе и внутренних деструкторов ресурсов соединений с базой данных). Пример для расширения mysqli:
Вывод программы будет не обязательно таким, как написано. Иногда потомок «успевает» до исполнения процедуры закрытия соединения в родителе и всё работает, как надо.
Боремся с отложенным исполнением функций / деструкторов
На самом деле, проблему с отложенным исполнением можно решить, если вы точно знаете, что хотите. Например, в Си есть функция _exit(), которая выходит, не запуская никаких установленных обработчиков. К сожалению, в PHP такой функции нет, но её поведение можно частично эмулировать с использованием сигналов:
Этого «хака» нам будет достаточно, чтобы соединение с базой оставалось активным для двух PHP-процессов одновременно, хотя лучше, конечно, так на практике не делать :):
Пишем grep
Давайте теперь, для примера, напишем простенькую версию grep, которая будет искать по маске в текущей директории.
Пишем параллельную версию grep
Осталось заменить foreach() на использование нашей функции parallelForeach и добавить обработку ошибок:
Проверим работу нашего грепа на исходном коде PHP 5.3.10:
Работает! Я описал один из часто используемых паттернов при параллельном программировании на PHP — параллельная обработка очереди из задач. Надеюсь, моя статья кому-нибудь поможет перестать бояться писать многопоточные приложения на PHP, если задача допускает такую декомпозицию, как в примере с грепом. Спасибо.
Что такое форк в программировании
Это когда делаешь свою версию какого-то софта
У разработчиков есть понятие «форк» — оно часто встречается в командной разработке и в проектах с открытым кодом. Посмотрите, что это, и когда вам предложат сделать форк, вы будете во всеоружии.
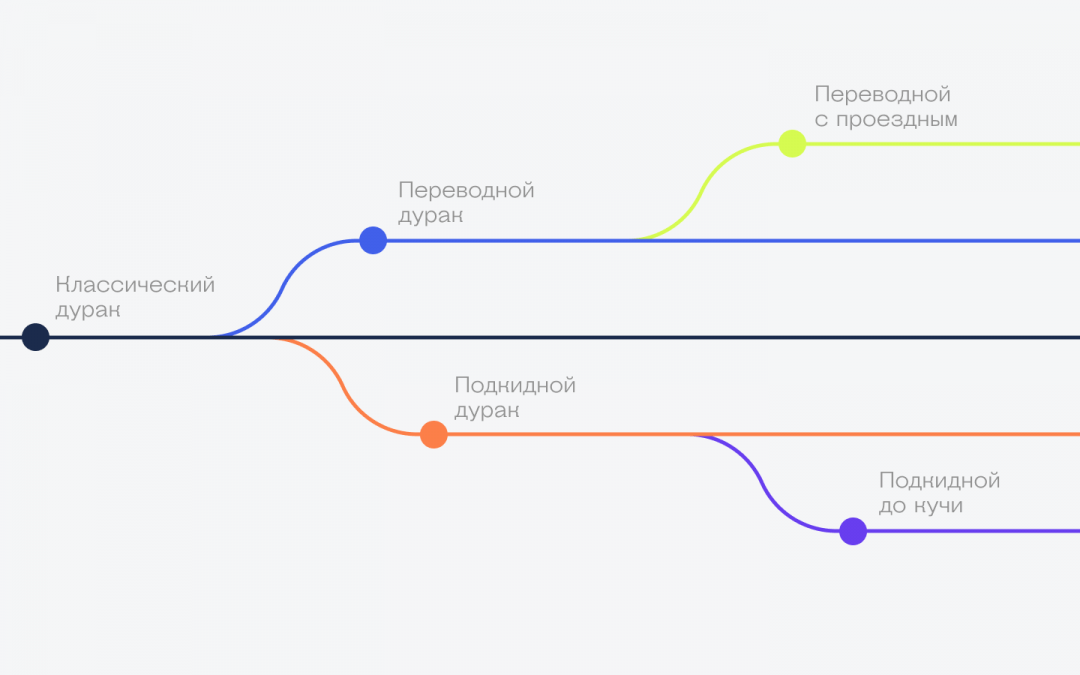
Пример: игра в дурака
Игра в дурака — одна из самых простых карточных игр. У всех на старте по 6 карт, есть колода, есть козырные карты, все ходят по очереди и подкидывают друг другу карты, чтобы самому остаться без карт.
Но в разных компаниях принято играть в дурака по-разному:
И ещё десяток разных вариантов в зависимости от компании или от того, как принято в этом месте.
Все основные правила дурака сохраняются, просто каждая версия добавляет в него что-то своё (например, возможность перевести ход). Но в основе это всё тот же дурак. Если вы знаете основные правила, то легко сможете разобраться в каждом новом варианте игры.
Все эти разные версии игры — это форки исходного дурака. Запомните пока эту аналогию, а чтобы было проще разбираться дальше, вот вам ещё одна мысль:
👉 Форк — это новая программа на базе какой-то версии исходной программы. Она может дальше развиваться самостоятельно, без оглядки на исходную программу.
Откуда такое название
Форк в переводе с английского — это вилка, развилка или ответвление (fork). Этот термин стали использовать, потому что ручка вилки — это как будто основная программа, а зубцы — ответвления от неё. Чтобы было понятнее, вот картинка с форками игры в дурака.
Каждое ответвление — это своя отдельная версия игры, которая живёт и развивается по своим правилам. А вместе все эти ответвления напоминают вилку — отсюда и название.
Если есть время, посмотрите ветку форков Линукса в википедии. Предупреждаем: она большая и это надолго.
Форки в программировании
В программировании всё работает точно так же: у некоторых программ появляются самостоятельные ответвления, которые начинают жить своей жизнью. Но для этого нужно два условия:
👉 Чтобы форк был успешным, в него тоже нужно вкладывать много времени и сил, как в основной продукт. Если им не заниматься, форк умрёт. Та же судьба ждёт форк, если им никто не будет пользоваться — в конце концов чаще всего разработчикам надоедает поддерживать софт просто так и они его забрасывают.
Примеры форков
В современном мире многие успешные сервисы, продукты и программы — это форки. Смотрите сами:
А вот ещё интересный случай, как бывает с форками. Сначала была библиотека node.js, потом от неё пошёл форк io.js, а в 2015 году этот форк стал официальным node.js.
Зачем нужны форки
Причин может быть много:
👉 Главная причина появления форков — желание сделать лучше. Но обычно получается не лучше, а просто по-другому.
Форк и версии
Иногда форк путают с версиями, хотя у них есть важное отличие:
Как сделать свой форк
Git fork. Зачем нужны форки и как с ними работать
Как и в случае с ребейзом, с форками в гите я разобрался не сразу. Вроде ничего особенного там нет, это просто копия репозитория, но натыкаешься на какие-то подводные камни и не сразу понимаешь, как их обойти. Да и вообще, зачем нужны эти форки, тоже осознаешь не сразу. Когда врубаешься, все становится просто, ну это как всегда.
Я не сторонник подхода «чо тут не понимать, тупой штоле» и попробую рассказать человеческими словами, что вообще такое форки, зачем они нужны и как с ними работать. А вы оцените, как получилось. Синьор git девелоперам статья покажется банальщиной, но тем, кто еще не успел обрести такой титул, будет полезно.
Ты работаешь в компании Company в какой-то команде и со своими ребятами пишешь код, например, блога вашего сайта. Рядом сидят ребята из другой команды, которые занимаются админкой. У каждой команды отдельный репозиторий, вы работаете и друг другу не мешаете.
Доступа к их репозиторию нет, поэтому идете договариваться. Обсуждаете вместе детали. Так, нужно завести поле в базе, какое-нибудь булево isAllowedComments, соответственно, подготовить миграцию, вывести это поле отдельной колонкой в таблице пользователей, там поставить чекбокс и уметь сохранять это в базу. А еще в апи, которое вы дергаете, нужно добавить в респонсе это самое поле. Вроде немного, ребята говорят, окей, через пару дней сделаем. И на самом деле делают, все хорошо.
Небольшие просьбы вроде этой появляются все чаще. То вам нужно накатить миграцию и разбанить всех пользователей, которые зарегались больше года назад. То в апи в респонсе вам понадобилось количество комментов пользователя. И каждый раз вы идете с такой мелочью к соседям и просите это сделать.
Рано или поздно ребятам из админки это надоедает, потому что у них хватает и своей работы. Они предлагают вам дать права на репозиторий и пробовать такие небольшие задачи делать самим. Говорят, мол, с такой фигней типа добавления поля в респонс вы и сами справитесь. Если что, зовите, поможем. Прав на пуш в мастер, конечно, никто не даст, но свои ветки создавайте и присылайте мердж-реквесты. Мы смотрим, если все хорошо, то мерджим в мастер и выкладываем в прод. Все довольны. И нам работы меньше, и вам не ждать, пока у нас руки дойдут до вашей задачи.
Вы с командой соглашаетесь. Ты клонируешь их репозиторий и пилишь фичи. Примерно так
Дальше идешь в битбакеты-гитхабы, в репозиторий админки, делаешь мердж-реквест и ждешь, когда его примут. Обычная схема. Мердж-реквест примерно везде делается одинаково: ищешь кнопку «Создать мердж-реквест» или пулл-реквест, выбираешь свою ветку, затем выбираешь, куда сливать (обычно уже по умолчанию будет мастер) и жмешь «Отправить».
Проходит пара месяцев. Ты случайно замечаешь в репозитории админки ветку petya/update-email. Спрашиваешь ребят из админки, а что за Петя вам коммитит? Те говорят, а, это чувак из отдела емейлов, мы им тоже доступ дали, как и вам. Они тоже приходили к нам по 3 раза в месяц, мы задолбались и теперь с ними работаем по вашей схеме. Ничего, все довольны.
Проходит год. Команд, которые работают по такой схеме, уже десяток. В репозитории появляются ветки
Эти ветки множатся, мерджатся между собой и вообще живут своей жизнью. Называются они как попало, коммиты подписывают кто во что горазд, старые ветки не удаляются после мерджей. Надвигается хаос.
Конечно, ребятам из админки не очень нравится такой мусор в их репозитории. Сначала они пытаются с этим бороться и проводить разъяснительные работы. Пытаются рассказать о правилах приличия в их репозитории. Пишут доку и официальное письмо всем программистам, где все подробно рассказывают. Как именовать ветки, как подписывать коммиты, не забывать удалять старые ветки, не заводить лишние ветки без надобности и прочее.
Это дело хорошее, но бесполезное. В компании полсотни разрабов, у каждого своя команда и свои правила работы с репозиторием. Люди приходят и уходят, эти правила уже никто не помнит, да и всем пофигу, главное фичу сделать, чего там заморачиваться с ветками и коммитами. Пусть у команды админки об этом голова болит. Главное, у нас все хорошо, в своем командном проекте, потому что мы никого к себе не пускаем, ахаха. Поэтому и ветки красиво называются, и коммиты адекватно подписаны. Нас тут 5 человек работают, уж между собой-то договоримся.
А между тем в репозитории админки образуется все больший трэш. То злодеи опять пушат ветки с названиями не по ГОСТу, и тимлида бесят. То сам тимлид с похмелья выдал новому чуваку доступы на пуш в мастер, а тот на радостях запушил миграцию, которая пол-сайта уронила. То по ошибке смерджили petya/hotfix вместо vasya/hotfix. В общем весело всем, кроме ребят из админки.
И вот однажды что-то изменилось. Тебе понадобилось запилить новую фичу и ты привычно набиваешь
Сначала идешь в гитхаб-битбакет и ищешь там в нужном репозитории кнопку Fork. Обычно она недалеко от кнопки clone. Жмешь на fork и для тебя создается проект. Если исходный был company/adminka.git, то твой будет примерно vasya/adminka.git. Ну или примерно так. Дальше клонируешь его как обычно
Естественно, свой форк клонируешь, а не оригинальный. Затем там создаешь привычно ветку и пушишь ее.
Заходишь в гитхаб-битбакет исходного репозитория, жмешь «Создать мердж-реквест», выбираешь свою ветку, она будет называться примерно vasya/adminka/blog/new-field, и ждешь, пока мердж-реквест примут.
Пока все ровно так, как ты привык, ничего нового. Мердж-реквест принимают и все хорошо.
Через месяц тебе нужно сделать еще одну задачу. Ты привычно подтягиваешь мастер и настораживаешься
За месяц нет новых коммитов в мастере? Да не верю. Идешь в репозиторий админки, смотришь, там до фига коммитов, чуть не каждый день в мастер пушат. В чем дело?
Присматриваешься, откуда ты пулишься и видишь, что это vasya/adminka. Это твой репозиторий, твой форк. Конечно, ты его месяц не трогал и он ничего не знает о новых коммитах в исходном проекте. Их нужно подтянуть и только тогда создавать новую ветку. Можно сделать это так
То есть вместо origin указываешь адрес нужного репозитория. И вот теперь-то подтянется мастер именно исходного проекта, а не твоего. А еще лучше сделать так, чтобы не набивать каждый раз длинный адрес
Вот теперь твой мастер актуален, можешь создавать ветку и пушить в репозиторий. Пушить уже в origin, то есть свой, потому что в upstream, исходный, тебе пушить никто не даст. То есть еще раз, пулишь мастер так
а пушишь свою ветку так
По сути это все, что нужно знать о работе с форками. После этого идешь создавать мердж-реквест, твоя ветка уже видна в исходном репозитории. Если ты работал над веткой, а за это время в мастер накидали еще коммитов, то перед отправкой мердж-реквеста стоит отребейзиться от мастера
Тут можешь делать, как хочешь, твой форк, твои правила. Можешь пушить с форсом, как у меня в примере. Если не хочешь с форсом, то можешь создать отдельную ветку и положить коммит в нее. Как угодно. Главное, чтобы твои коммиты лежали поверх свежих коммитов из мастера. Тогда никто не будет возникать при рассмотрении мердж-реквеста, а ты будешь уверен, что у тебя самые свежие обновления.
И на этом все. Главное, что нужно сделать, это добавить upstream и четко понимать, в чем его отличие от origin.
С форками можно работать и в компании на полсотни разработчиков, но особенно это популярно в опенсорсе. Возьмите какой-нибудь проект, например, vuejs, у него больше 20 тысяч форков и 3 сотни контрибьюторов. Представьте, что бы творилось в репозитории, пусти всех этих энтузиастов пушить свои правки. А так они спокойно работают со своими форками и присылают пулл-реквесты, не засоряя проект.
Всем удачи. Любите гит, он совсем не страшный 
Русские Блоги
Fork () многопроцессорного программирования
Каталог статей
1. Обзор процесса
Студенты, которые хотят узнать больше о процессе, могут переехать
Команда ps aux используется для просмотра всех идентификаторов процессов.
Команда Linux для остановки процесса: kill [идентификатор процесса] или killall [имя процесса]
Linux останавливает выполняющуюся функцию процесса: int kill(pid_t pid, int sig);
Функция для получения идентификатора процесса:
2. Обзор пространства памяти процесса.
В этой части Сяохэй написал еще один блог, и незнакомые студенты могут двигаться:
https://blog.csdn.net/weixin_46027505/article/details/105076010
Также есть блоги о зомби-процессах:
3. Система вызывает fork ().
В Linux есть два основных системных вызова, которые можно использовать для создания дочерних процессов: fork () и vfork (). Fork в переводе с английского означает «вилка». Почему это имя? Поскольку процесс запущен, если используется fork, порождается другой процесс, и процесс «разветвляется», поэтому имя очень яркое.
Ниже мы приводим образец кода для дальнейшего понимания fork ()

Мы наблюдаем за результатами операции. И родительский процесс, и дочерний процесс выполняют свои собственные операции над значением исходной глобальной переменной, указывая на то, что a = 10 имеет собственное независимое пространство между родительским и дочерним процессами и не мешает друг другу.
И мы обнаружили, что после fork был напечатан дважды, потому что дочерний процесс завершился и запустился один раз, а родительский процесс завершился и запустился. 
4. Системный вызов vfork ()
Перед реализацией копирования при записи (это будет подробно описано позже) разработчики Unix всегда беспокоились о бесполезной трате адресного пространства, вызванной выполнением exec сразу после fork.
Таким образом, старейшины придумали vfork ()
За исключением того, что дочерний процесс должен немедленно выполнить системный вызов exec или вызвать _exit () для выхода, результат успешного вызова vfork () такой же, как и fork ().
5. Разница между форком и vfork
| fork() | vfork() |
|---|---|
| Дочерний процесс копирует сегмент данных и сегмент кода родительского процесса. | Дочерний процесс разделяет сегмент данных с родительским процессом.Когда значение переменной в сегменте общих данных нужно изменить, родительский процесс копируется. |
| Порядок выполнения родительского и дочернего процессов неопределен. | Убедитесь, что дочерний процесс запускается первым, а данные передаются родительскому процессу перед вызовом exec или exit, а запуск родительского процесса может быть запланирован после его вызова exec или exit. |
| Родительский и дочерний процессы независимы друг от друга | Если дочерний процесс полагается на дальнейшие действия родительского процесса перед вызовом этих двух функций, это вызовет взаимоблокировку. |
Почему там vfork, потому что предыдущий форк глуп, когда он создает дочерний процесс, он создаст новый адрес
space, и скопируйте ресурсы родительского процесса, и часто выполняйте вызов exec в дочернем процессе, чтобы предыдущая копия работала
— пустая трата усилий.
В этом случае умные люди придумали vfork, и порожденный им дочерний процесс был временно связан с
Родительский процесс разделяет адресное пространство (фактически, концепцию потока), потому что в это время дочерний процесс находится в адресном пространстве родительского процесса.
запущен, поэтому дочерний процесс не может выполнять операции записи, и когда сын «занимает» дом Лао-цзы, со мной, должно быть, поступили несправедливо.
не работает, пусть отдыхает снаружи (блокирует), как только сын выполняет exec или выходит, он купил свой
Сейчас дом, и на этот раз он расположен относительно разделения.
// Вышеупомянутый абзац виден в Интернете, думаю, это хорошо, Если вы забыли конкретный источник, вы не сможете прикрепить ссылку. Если первоначальный автор видит это, я надеюсь, что вы понимаете и можете оставить сообщение. Я прикреплю ссылку.
6, копирование при записи
Linux использует метод копирования при записи, чтобы уменьшить накладные расходы, вызванные полным копированием процесса пространства родительского процесса при fork.
После fork () exec часто вызывается для выполнения другой программы, и exec оставит текстовый сегмент, сегмент данных и стек родительского процесса и загрузит другую программу, поэтому многие реализации fork () теперь не выполняют родительский Полная копия сегмента данных процесса, кучи и стека.
Его предпосылка проста: если есть несколько процессов, которые хотят читать свою собственную копию ресурсов отдела, то в копировании нет необходимости. Каждому процессу нужно только сохранить указатель на этот ресурс. Пока ни один процесс не хочет изменять свою собственную «копию», существует иллюзия, что каждый процесс, кажется, монополизирует этот ресурс. Это позволяет избежать бремени копирования. Если процесс хочет изменить свою собственную «копию» ресурса, он скопирует этот ресурс и предоставит скопированную копию процессу. Однако копирование прозрачно для процесса. Этот процесс может изменить скопированный ресурс, в то время как другие процессы по-прежнему совместно используют неизмененный ресурс.
Отсюда и название: копировать при записи.
6.1 Преимущества копирования при записи
Основное преимущество копирования при записи заключается в том, что, если процессу не требуется изменять ресурс, его не нужно копировать.
Преимущество ленивых алгоритмов заключается в том, что они максимально откладывают дорогостоящие операции до тех пор, пока они не будут выполнены, когда это необходимо.
6.2 Копирование при записи расширенных знаний
1. В случае использования виртуальной памяти копирование при записи выполняется постранично. Следовательно, пока процесс не изменяет все свое адресное пространство, ему не нужно копировать все адресное пространство. После завершения вызова fork () и родительский, и дочерний процессы считают, что у них есть собственное адресное пространство, но на самом деле они совместно используют исходные страницы родительского процесса, и эти страницы могут использоваться другими родительскими или дочерними процессами.
2. Реализация копирования при записи в ядре очень проста. Структуры данных, относящиеся к страницам ядра, могут быть помечены как доступные только для чтения и копирования при записи. Если процесс пытается изменить страницу, он генерирует прерывание из-за ошибки страницы. То, как ядро обрабатывает прерывание из-за ошибки страницы, заключается в создании прозрачной копии страницы. В это время атрибут COW страницы будет очищен, что означает, что к ней больше не предоставляется общий доступ.
3. В современной архитектуре компьютерной системы поддержка копирования при записи на аппаратном уровне обеспечивается блоком управления памятью (MMU), поэтому реализация очень проста. При вызове fork () копирование при записи является большим преимуществом. Поскольку за большим количеством вилок будет следовать exec, то копирование содержимого всего адресного пространства родительского процесса в адресное пространство дочернего процесса является пустой тратой времени: если дочерний процесс немедленно выполняет образ нового двоичного исполняемого файла, его предыдущий Адресное пространство будет заменено. Копирование при записи может оптимизировать эту ситуацию.
7. Что дочерний процесс наследует от родительского?
8. Другие связанные функции API.
Все перечисленные выше семь различных функций называются функциями exec, и вызов любой из этих функций после fork () заставит вновь созданный процесс выполнить другую программу.
wait () и waitpid ()
Функции wait и waitpid используются для работы с мертвыми процессами.
Сюй Сяохэй до этого написал блог по теме:
https://blog.csdn.net/weixin_46027505/article/details/105097361
system () (используйте с осторожностью) и popen ()
Если мы хотим выполнить другую команду Linux в программе, мы можем вызвать fork (), а затем exec для выполнения соответствующей команды, но это относительно проблематично. В системе Linux предусмотрена функция библиотеки system (), которая может быстро создать процесс для выполнения соответствующих команд.
Студенты этих двух функций могут также искать связанные блоги, чтобы узнать
fork() vs. vfork()
Послушайте!
Ведь, если звезды зажигают — значит — это кому-нибудь нужно?

Я занимаюсь программированием для встроенных систем, и данную статью решил написать для того, чтобы лучше разобраться с проблемой использования системных вызовов fork() и vfork(). Второй из них часто советуют не использовать, но ясно, что появился он не просто так.
Давайте разберёмся, когда и почему лучше использовать тот или иной вызов.
В качестве бонуса будет приведено описание реализаций vfork()/fork() в нашем проекте. Прежде всего, мой интерес связан с применением этих вызовов во встроенных системах, и главной особенностью приведённых реализаций является отсутствие виртуальной памяти. Возможно, хабровчане, хорошо разбирающиеся в системном программировании и во встроенных системах, дадут советы и поделятся опытом.
Кому интересно, прошу под кат.
Начнём с определения, то есть со стандарта POSIX, в котором эти функции определены:
fork() создаёт точную копию процесса за исключением нескольких переменных. При успешном выполнении функция возвращает значение ноль дочернему процессу и номер дочернего процесса — родителю (дальше процессы начинают «жить своей жизнью»).
В отличие от fork(), vfork() не создает копию родительского процесса, а создает разделяемое с родительским процессом адресное пространство до тех пор, пока не будет вызвана функция _exit или одна из функций exec.
Родительский процесс на это время останавливает свое выполнение. Отсюда следуют и все ограничения на использование – дочерний процесс не может изменять никакие глобальные переменные или даже общие переменные, разделяемые с родительским процессом.
Другими словами, если это утверждение верно, после вызова vfork() оба процесса, будут видеть одни и те же данные.
Давайте проведем эксперимент. Если это действительно так, то изменения, вносимые в данные порожденного процесса, должны быть видны в родительском процессе, и наоборот.
Если собрать и запустить эту программу, получим вывод:
fork(): common variable hasn’t been changed.
При замене fork() на vfork(), вывод изменится:
vfork(): common variable has been changed.
Многие пользуются этим свойством, передавая данные между процессами, хотя по POSIX поведение таких программ не определено. Вероятно, это и создает проблемы, из-за которых советуют не использовать vfork().
Действительно, одно дело, когда разработчик осознанно меняет значение некоторой переменной, и совсем другое, когда он забывает о том, что дочернему процессу нельзя, например, совершать возврат из функции, в которой был вызван vfork() (ведь это разрушит структуру стека родительского процесса!). И даже действуя сознательно, как и обычно, вы используете недокументированные возможности на свой страх и риск.
The fork() operation creates a separate address space for the child. The child process has an exact copy of all the memory segments of the parent process.
Конечно, на большинстве современных систем с виртуальной памятью никакого копирования не происходит, все страницы памяти родительского процесса просто помечаются флагом copy-on-write. Тем не менее, при этом нужно пробегаться по всей иерархии таблиц, а это требует времени.
Получается что, вызов vfork() должен выполняться быстрее fork(), что упоминается и в LinuxMan page.
Проведем еще один эксперимент и убедимся, что это действительно так. Немного изменим предыдущий пример: добавим цикл для создания 1000 процессов, уберём общую переменную и вывод на экран.
Запустим через команду time.
| Вывод при использовании fork() | Вывод при использовании vfork() |
Результат, мягко говоря, впечатляет. От запуска к запуску данные будут незначительно отличаться, но всё равно vfork() будет от 4 до 5 раз быстрее.
Выводы следующие:
fork() — более «тяжелый» вызов, и если можно вызвать vfork(), лучше использовать его.
vfork() — менее безопасный вызов, и с ним легче выстрелить себе в ногу, и, соответственно, применять его нужно осмысленно.
fork()/vfork() нужно применять там, где нужно создать отдельные ресурсы для процесса (индексные дескрипторы, пользователь, рабочая папка), в остальных случаях стоит работать с pthread*, которые работают ещё быстрее.
fork() лучше применять в случае, когда действительно нужно создать отдельное адресное пространство. Впрочем, это очень трудно реализовать на небольших процессорных платформах без аппаратной поддержки виртуальной памяти.
Прежде чем перейти ко второй части статьи, отмечу, что в POSIX есть функция posix_spawn(). Эта функция, по сути, содержит в себе vfork() и exec(), и, следовательно, позволяет избежать проблем, связанных с vfork(), при отсутствии повторного создания адресного пространства как в fork().
Теперь перейдём к нашей реализации fork()/vfork() без поддержки MMU.
Реализация vfork
Реализуя vfork() в нашей системе, мы предполагали, что вызов vfork() должен происходит так: родитель переходит в режим ожидания, а первым из vfork() возвращается дочерний процесс, пробуждая родителя при вызове функции _exit() или exec*(). Это значит, что потомок может выполняться на родительском стеке, но с собственными ресурсами остальных типов: индексными дескрипторами, таблицей сигналов и так далее.
Возврат из vfork() будет осуществлён дважды: для родительского и дочернего процессов. Значит, где-то должны быть сохранены регистры того фрейма стека, из которого был вызван vfork(). Сделать это на стеке нельзя, так как дочерний процесс может затереть эти значения во время исполнения. Тем не менее, сигнатура vfork() не подразумевает наличие какого-то буфера, поэтому сначала регистры сохраняются на стеке, а только потом — где-то в родительской задаче. Сохранение регистров на стеке можно было произвести с помощью системного вызова, но мы решили обойтись без него и сделали это самостоятельно. Естественно, функция vfork() написана на ассемблере.
Немного пояснений к коду.
Сначала происходит проверка на многопоточность (проблемы, связанные с ней при использовании vfork(), обсуждались выше). Затем создаётся новая задача, и, если это удалось, в ней сохраняются регистры для возврата из vfork().
После этого вызывается функция vfork_child_start(), которая, как следует из названия, «запускает» дочерний процесс. Кавычки здесь поставлены не случайно, так как на самом деле задача может запускаться позднее, всё зависит от конкретной реализации, которых в нашем проекте две. Прежде чем перейти к их описанию, рассмотрим функции _exit() и exec*().
При их вызове родительский поток должен разблокироваться. Будем говорить, что именно в этот момент происходит полноценный запуск дочернего процесса как отдельной сущности в системе.
Другие функции семейства exec* у нас выражены через вызов execv().
Первая реализация
Идея первой реализации заключается в том, чтобы помимо того же стека использовать тот же поток управления. По сути, в этом случае нужно только «подменить» задачу для текущего потока на дочернюю до тех пор, пока дочерняя задача не стартует окончательно при вызове vfork_child_done().
Происходит следующее: текущий поток исполнения (то есть родительский) привязывается к порождённому процессу функцией thread_set_task() — для этого достаточно изменить соответствующий указатель в структуре текущего потока. Это значит, что при обращении к ресурсам, связанных с задачей, поток будет обращаться к задаче дочерней, а не к родительской, как раньше. Например, при попытке потока узнать, к какой задаче поток относится (функция task_self()), он получит именно дочернюю задачу.
После этого дочерняя задача помечается как созданная в результате vfork-а, этот флаг понадобится для того, чтобы функция vfork_child_done() выполнялась нужным образом (подробнее — чуть позже).
Затем восстанавливаются регистры, сохранённые при вызове vfork(). Напомним, что согласно POSIX вызов vfork() должен возвращать значение ноль дочернему процессу, что и происходит с помощью вызова ptregs_retcode_jmp(ptregs, 0).
Как уже говорилось, при вызове дочерним процессом функции _exit() или execv() функция vfork_chlid_done() должна разблокировать родительский поток. Помимо этого нужно подготовить дочернюю задачу к исполнению нужного обработчика.
При вызове vfork_child_done() необходимо учесть случай использования exec()/_exit() без vfork() — тогда нужно просто выйти из текущей функции, ведь нет нужды заниматься разблокировкой родителя, и можно сразу перейти к запуску потомка. Если же процесс был создан с помощью vfork(), совершается следующее: сперва снимается флаг is_vforking с дочерней задачи с помощью task_vfork_end(), затем, наконец, стартует главный поток дочерней задачи. В качестве точки входа указывается функция run, которая должна быть одним из обработчиков, описанных ранее (task_exec_callback, task_exit_callback) — они необходимы при реализации vfork(). После этого меняется принадлежность потока к задаче: вместо дочерней вновь указывается родительская. Наконец, производится возврат в родительскую задачу из вызова vfork() с идентификатором дочернего процесса в качестве возвращаемого значения. Выше уже говорилось, что это делается с помощью вызова ptregs_retcode_jmp().
Вторая реализация vfork
Идея второй реализации заключается в использовании родительского стека новым потоком, который был создан вместе с новой задачей. Это получится автоматически, если в дочернем потоке восстановить регистры, ранее сохранённые в родительском потоке. При этом можно использовать настоящую синхронизацию между потоками, как описано в уже упомянутой статье. Это, безусловно, более красивое, но и более сложное в реализации решение, ведь когда родительский поток будет в ожидании, на этом же стеке будет выполняться его потомок. Значит, на время ожидания нужно переключиться на некоторый промежуточный стек, где можно спокойно ждать вызов потомком _exit() или exec*().
Пояснения к коду:
Сначала выделяется место под стек, после этого сохраняется pid (process ID) дочернего, так как он потребуется родителю для возврата из vfork().
Вызов setjmp() позволит вернуться в то место стека, где был вызван vfork(). Как уже говорилось, ожидание должно выполняться на некотором промежуточном стеке, и переключение совершается с помощью макроса CONTEXT_JMP_NEW_STACK(), который меняет текущий стек и передаёт управление функции vfork_waiting(). В ней-то и будет происходить активация потомка и блокирование предка до вызова vfork_child_done().
Как видно из кода, прежде всего сохраняется таблица сигналов дочернего процесса. На самом деле, будет переопределён сигнал SIGCHLD, который посылается при изменении статуса дочернего процесса. В данном случае он используется для разблокировки родителя.
Сохранение и восстановление таблицы сигналов совершается с помощью POSIX-вызова sigaction().
После замены обработчика сигнала задача помечается как находящаяся в режиме ожидания, в котором она будет пребывать вплоть до настоящего запуска дочерней задачи при вызове _exit()/exec*(). В качестве точки входа в задачу используется функция vfork_child_task(), которая восстанавливает сохранённые ранее регистры и возвращается из vfork().
При вызове _exit() и exec*() будет отправлен SIGCHLD, и обработчик этого сигнала снимет отметку об ожидании запуска потомка. После этого восстановится старый обработчик сигнала SIGCHLD, а управление вернётся в функцию vfork_child_start() с помощью longjmp(). Нужно помнить, что фрейм стека этой функции будет повреждён после выполнения дочернего процесса, поэтому локальные переменные будут содержать не то, что нужно. После освобождения выделенного ранее стека производится возврат из функции vfork() номера дочерней задачи.
Проверка работоспособности vfork
Для проверки корректного поведения vfork() нами был написан набор тестов, покрывающих несколько ситуаций.
Два из них проверяют корректный возврат из vfork() при вызове _exit() и execv() дочерним процессом.
Однако, хотелось бы проверить корректность работы на какой-то реальной, причем сторонней, программе, и для этого был выбран достаточно известный пакет dropbear. При конфигурации он проверяет наличие fork(), и, если не находит его, может использовать vfork(). Сразу оговорюсь, что это было сделано ради поддержки ucLinux, а не в целях улучшения производительности.
ОС была сконфигурирована соответствующим образом (чтобы dropbear использовал vfork()), и с помощью ssh было успешно установлено соединение при обеих реализациях.