
SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Хинты в SQL Server
Я с подозрением относился к использованию хинтов в SQL Server, а теперь не могу представить себе работу без них.
Мое мнение по этому поводу менялось на протяжении нескольких последних лет в связи с большим числом проблем с производительностью, над которыми приходилось работать. Я выступал на SQLSaturday 1000 (Oregon 2020) на прошлых выходных, и мой доклад был в основном о вещах, которые я узнал об оптимизации сборки мусора и аналогичных дополнительных процессах. Во время этой работы я столкнулся с рядом проблем с запросами, подобными следующему примеру для базы данных WideWorldImporters:
Вопросы заказов
Логика здесь достаточно проста. Ранее в процессе мы обнаружили заказы, которые хотели удалить в соответствии с политикой хранения, и поместили значения OrderID в табличную переменную, оптимизированную для памяти (motv). Затем мы используем motv для удаления из всех связанных таблиц, и наконец из таблицы Orders.
Этот запрос не имеет предложения WHERE. Ясно, что мы хотим сделать, чтобы это работало. У нас имеется 100 строк в нашей motv, и мы хотим удалить связанные строки в Invoices. Однако я увидел проблемы, вызываемые планами выполнения, которые нарушают порядок:
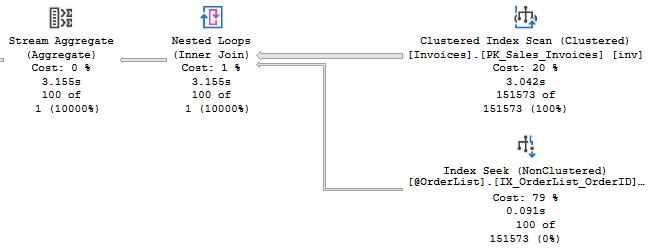
Табличные переменные не имеют статистики, поэтому оптимизатор не знает, сколько строк будет предположительно получено из этой операции (заметим, что табличные переменные иначе компилируются в SQL Server 2019, что может решить проблему). Время от времени я вижу план с порядком соединения, который не совпадает с моими ожиданиями. Здесь все портит отсутствие предложения WHERE, однако тут не существует предложения, которое я могу применить и которое выполнит фильтрацию лучше, чем это уже сделано в моей табличной переменной.
Согласованность
Я работаю с сотнями баз данных, имеющих одну и ту же схему. Они имеют только различные наборы данных и распределения, разные размеры, и их статистика обновляется в разное время. Но если одна из них выбирает плохой план, я должен отбросить всякую другую работу, чтобы исследовать причину высоких значений ЦП на базе данных xyz.
Согласованность весьма важна для меня. И в этом случае ответ прост. Да, я хочу быстро просканировать сначала небольшую оптимизированную для памяти табличную переменную, и использовать её для фильтрации большой более медленной таблицы. Добавление хинта соединения или указанного порядка должно согласовать план и производительность.
Оба варианта навязывают порядок соединения. Хинт INNER LOOP JOIN имеет дополнительное преимущество, гарантируя, что план использует соединение вложенными циклами. Соединение hash match не дало бы эффекта при размере пакета в несколько сотен или тысяч строк. Merge join потребовало бы, вероятно, сортировки одного из входов, а это не то, что нужно.
Индексные хинты
Мне пришлось использовать индексный хинт в следующем примере:
Это был пример процесса сборки мусора. План не выявляет проблемы, но следует с подозрением отнестись к сканированию здесь:
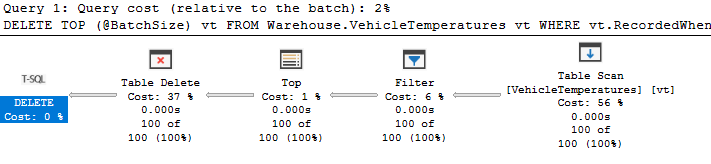
Сканирование таблицы читает только 100 строк, но это потому, что используется оператор ТОР. Первые 100 строк отвечают нашему фильтру, поэтому запрос заканчивается в этом месте. Если никакие строки не отвечают критерию (или их меньше 100), нам придется сканировать всю таблицу.
На столбце RecordedWhen имеется индекс; просто он не был использован. Это другой случай, когда применение хинта кажется очевидным. Возможно, обновление статистики также решило бы проблему, но это дает мне больше уверенности.
Большая ответственность
При использовании хинтов мы принимаем на себя некоторую ответственность, за которую не отвечает SQL Server, и мы можем получить новые проблемы. Ниже приводятся некоторые моменты, которые следует принять во внимание, прежде чем вы попытаетесь применить хинт.
Один из моих коллег недавно решил проблему с производительностью, изменив порядок соединения с помощью хинта, или, по его словам, «выполнив Jared Poche». Это говорит о том, как часто я использовал подсказки, и как часто они срабатывали.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Soft — Consulting
Построение запросов (ORACLE)
Оглавление:
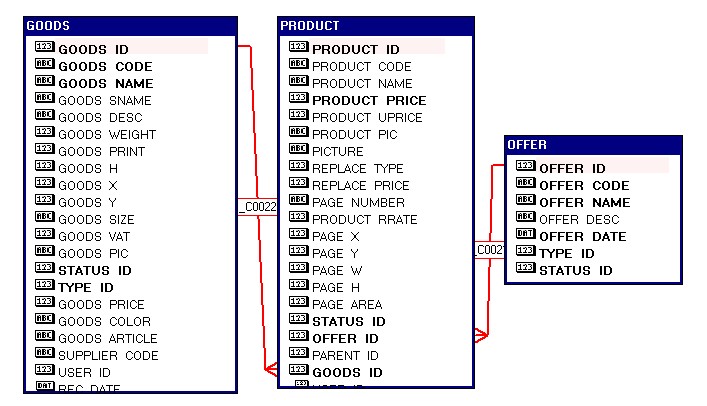
Структуры данных для примеров.
Рекомендации по оптимизации запросов
Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
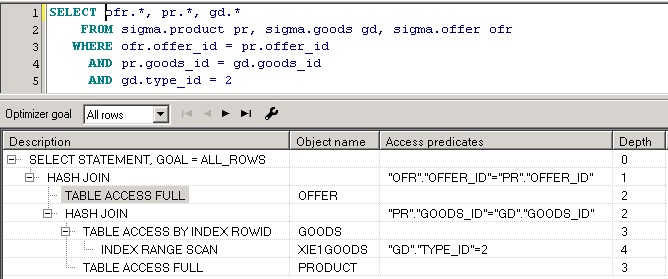
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Хинт — это ключевое слово, иногда с набором параметров, которое может повлиять на оптимизатор при составлении плана запроса. Другими словами, с помощью хинтов вы можете попытаться изменить способ с помощью которого будут получены или обработаны данные (хинты есть не только у операторов SELECT).
Если у вас есть желание более детально ознакомиться с хинтами, то я рекомендовал бы вам просмотреть эту статью.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
Этот хинт официально не поддерживается с версии Oracle 10G. При его успешном применении включается оптимизация по определенным правилам (RBO — Rule Based Optimization). Данный хинт может быть полезен, если у вас сложный запрос с неэффективным планом выполнения и использование других хинтов может занять время, которого мало. Если в запросе не пропущены какие-то JOINS или условия и вы считаете, что он написан верно, то есть достаточно большая вероятность, что RBO построит верный план.
В 11G этот хинт пока работает с некоторыми ограничениями, важны для практической работы следующие:
■ В запросе не должны использоваться другие хинты.
■ Не должен использоваться синтаксис ANSI (left join | full outer join …)
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
MATERIALIZE.
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
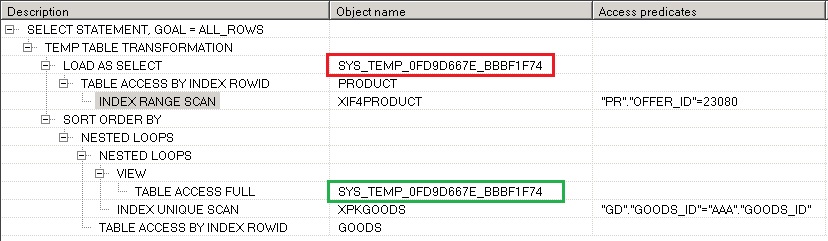
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.
Табличные указания (Transact-SQL)
Табличные подсказки переопределяют поведение оптимизатора запросов по умолчанию на время выполнения инструкции языка обработки данных (DML). Для этого указываются способ блокировки, один или более индексов, операция обработки запроса, например сканирования таблицы или поиска в индексе, или другие параметры. Табличные указания задаются в предложении FROM инструкции DML и относятся только к таблицам и представлениям, на которые ссылается это предложение.
Оптимизатор запросов SQL Server обычно выбирает наилучший план выполнения запроса. Поэтому одсказки рекомендуется использовать только опытным разработчикам и администраторам баз данных в качестве последнего средства.
Применимо к:
 Синтаксические обозначения в Transact-SQL
Синтаксические обозначения в Transact-SQL
Синтаксис
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
WITH (
Табличные указания, за некоторыми исключениями, поддерживаются в предложении FROM только в случае, если они задаются с ключевым словом WITH. Табличные указания также необходимо заключать в скобки.
Пропуск ключевого слова WITH является устаревшей возможностью: В будущей версии Microsoft SQL Server этот компонент будет удален. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
Если подсказка указана с другим параметром, ее необходимо указывать с ключевым словом WITH:
Между табличными подсказками рекомендуется ставить запятые.
Разделение подсказок пробелами, а не с помощью запятых, является устаревшей возможностью. В будущей версии Microsoft SQL Server этот компонент будет удален. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
NOEXPAND
Указывает, что при обработке запроса оптимизатором запросов никакие индексированные представления не расширяются для доступа к базовым таблицам. Оптимизатор запросов обрабатывает представление так же, как и таблицу с кластеризованным индексом. Аргумент NOEXPAND применяется только для индексированных представлений. Дополнительные сведения см. в разделе Использование NOEXPAND.
Если существует кластеризованный индекс, INDEX(0) вызывает проверку кластеризованного индекса, а INDEX(1) — проверку кластеризованного индекса или поиск по нему. Если кластеризованный индекс не существует, INDEX(0) вызывает проверку таблицы, а INDEX(1) интерпретируется как ошибка.
Если в отдельном списке указаний используются несколько индексов, повторяющиеся индексы пропускаются, а остальные используются для получения строк из таблицы. Порядок индексов в указании индекса имеет значение. Несколько указаний индекса также принудительно выполняют операции И с индексами, и оптимизатор запросов применяет столько условий, сколько возможно для каждого из индексов, к которым он получает доступ. Если коллекция индексов с подсказками не включает все указанные в запросе столбцы, то выборка для получения остальных столбцов выполняется после того, как компонентом Компонент SQL Server Database Engine будут получены все индексированные столбцы.
Если указание индекса, ссылающееся на несколько индексов, используется в таблице фактов в соединении типа «звезда», оптимизатор не учитывает индекс и возвращает предупреждение. Кроме того, выполнение операции ИЛИ с индексами также не разрешено для таблицы с заданным указанием индекса.
Максимальное число индексов в табличном указании равно 250 некластеризованным индексам.
KEEPIDENTITY
Применяется только в инструкции INSERT, когда параметр BULK используется с OPENROWSET.
Указывает, что значение или значения идентификаторов в файле импортированных данных будут использоваться для столбца идентификаторов. Если аргумент KEEPIDENTITY не указан, значения идентификаторов для данного столбца проверяются, но не импортируются, а оптимизатор запросов автоматически назначает уникальные значения на основе начального значения и приращения, заданных при создании таблицы.
Если файл данных не содержит значений столбца идентификаторов таблицы или представления, а столбец идентификаторов не является последним в таблице, этот столбец необходимо пропустить. Дополнительные сведения см. в разделе Использование файла форматирования для пропуска поля данных (SQL Server). Если столбец идентификаторов успешно пропущен, то оптимизатор запросов автоматически назначает уникальные значения для столбца идентификаторов в импортируемые строки таблицы.
Дополнительные сведения о проверке идентифицирующего значения для таблицы см. в разделе DBCC CHECKIDENT (Transact-SQL).
KEEPDEFAULTS
Применяется только в инструкции INSERT, когда параметр BULK используется с OPENROWSET.
Указывает на вставку установленного по умолчанию значения столбца таблицы, если таковое имеется, вместо значения NULL, применяемого в случае, когда запись данных не содержит значения для этого столбца.
Пример использования этого указания в инструкции INSERT… Дополнительные сведения об инструкции SELECT * FROM OPENROWSET(BULK. ) см. в разделе Сохранение значений NULL или использование значений по умолчанию при массовом импорте данных (SQL Server).
Начиная с SQL Server 2008 R2 с пакетом обновления 1 (SP1), также могут указываться параметры индекса. В таком случае оптимизатор запросов будет использовать при выполнении операций поиска в индексе по указанному индексу как минимум все указанные столбцы индекса.
index_value
Имя или значение идентификатора индекса. Указывать идентификатор индекса 0 (куча) нельзя. Чтобы получить имя или идентификатор индекса, запросите представление каталога sys.indexes.
index_column_name
Это имя столбца индекса, включаемого в операцию поиска. Указание FORCESEEK с параметрами индекса аналогично использованию FORCESEEK с указанием INDEX. Но более эффективного контроля над путем доступа, который использует оптимизатор запросов, можно добиться указанием и индекса, в котором следует провести поиск, и столбцов индекса, которые предполагается использовать в операции поиска. При необходимости оптимизатор может задействовать дополнительные столбцы. Например, если указан некластеризованный индекс, то оптимизатор может в дополнение к указанным столбцам выбрать использование ключевых столбцов кластеризованного индекса.
Подсказка FORCESEEK может быть указана следующим образом.
| Синтаксис | Пример | Описание |
|---|---|---|
| Без указания INDEX или индекса | FROM dbo.MyTable WITH (FORCESEEK) | Оптимизатор запросов использует только операции поиска в индексе для доступа к таблицам или представлениям через любой подходящий индекс. |
| В сочетании с подсказкой INDEX | FROM dbo.MyTable WITH (FORCESEEK, INDEX (MyIndex)) | Оптимизатор запросов будет использовать при доступе к таблице или представлению через указанный индекс только операции поиска по индексу. |
| Параметризация посредством указания индекса и столбцов индекса | FROM dbo.MyTable WITH (FORCESEEK (MyIndex (col1, col2, col3))) | Оптимизатор запросов будет использовать при выполнении поиска по указанной таблице или представлению индексу как минимум указанные столбцы индекса. |
При использовании указания FORCESEEK (с указанием параметров индексов или без них) руководствуйтесь следующими рекомендациями:
Если FORCESEEK указывается с параметрами индекса, применяются следующие ограничения и рекомендации:
Указание FORCESEEK с параметрами ограничивает число планов, которые могут быть использованы оптимизатором, в отличие от указания FORCESEEK без параметров. Это может привести к тому, что ошибка Plan cannot be generated возникает в нескольких случаях. В будущих выпусках внутренние изменения оптимизатора запросов могут привести к увеличению числа этих планов.
FORCESCAN Применимо к: SQL Server 2008 R2 с пакетом обновления 1 (SP1) и выше. Указывает, что в качестве пути доступа к ссылочным таблицам или представлениям оптимизатор запросов использует только операцию сканирования в индексе. Указание FORCESCAN может оказаться полезным в тех запросах, где оптимизатор недооценивает число затрагиваемых строк и выбирает операцию поиска, а не сканирования. В этом случае объем памяти, выделенный для данной операции, будет недостаточным, что повлияет на производительность запроса.
Указание FORCESCAN может быть указано с указанием INDEX или без него. В сочетании с указанием индекса ( INDEX = index_name, FORCESCAN ) оптимизатор запросов рассматривает пути доступа для сканирования через указанный индекс при доступе к упоминаемой таблице. Указание FORCESCAN может задаваться с указанием индекса INDEX(0) для принудительного сканирования базовой таблицы.
Для секционированных таблиц и индексов указание FORCESCAN применяется после устранения секционирования посредством вычисления предиката запроса. Это означает, что сканирование выполняется только в оставшихся секциях, а не во всей таблице.
Указание FORCESCAN имеет следующие ограничения:
HOLDLOCK
Равнозначен аргументу SERIALIZABLE. Дополнительные сведения об аргументе SERIALIZABLE см. далее в этом разделе. Аргумент HOLDLOCK применяется только к таблице или представлению, для которых он задан, и только на время транзакции, определенной в использующей его инструкции. Аргумент HOLDLOCK нельзя использовать в инструкции SELECT, включающей параметр FOR BROWSE.
IGNORE_CONSTRAINTS
Применяется только в инструкции INSERT, когда параметр BULK используется с OPENROWSET.
Указывает, что при операции массового импорта будут пропускаться какие-либо ограничения на таблицу. По умолчанию INSERT проверяет ограничения уникальности и проверочные ограничения и ограничения первичных и внешних ключей. Если для операции массового импорта задан параметр IGNORE_CONSTRAINTS, инструкция INSERT будет пропускать ограничения в целевой таблице. Обратите внимание, что нельзя отключить ограничения UNIQUE, PRIMARY KEY или NOT NULL.
Отключение ограничений CHECK и FOREIGN KEY может потребоваться, если введенные данные содержат нарушающие ограничения строки. При отключении ограничений CHECK и FOREIGN KEY можно импортировать данные, а затем произвести очистку данных с помощью инструкций Transact-SQL.
Однако при пропуске ограничений CHECK и FOREIGN KEY после операции каждое пропущенное ограничение помечается как is_not_trusted в представлении каталога sys.check_constraints или sys.foreign_keys. Рано или поздно придется проверить всю таблицу на соответствие ограничениям. Если таблица не была пустой перед операцией массового импорта, затраты на повторную проверку ограничений могут превысить затраты от применения ограничений CHECK и FOREIGN KEY к добавочным данным.
IGNORE_TRIGGERS
Применяется только в инструкции INSERT, когда параметр BULK используется с OPENROWSET.
Указывает, что при операции объемного импорта не будут учитываться какие-либо триггеры, определенные для таблицы. По умолчанию для инструкции INSERT применяются триггеры.
Аргумент IGNORE_TRIGGERS следует использовать только в случае, когда приложение не зависит от каких-либо триггеров и важно максимизировать производительность.
NOLOCK
Равнозначен аргументу READUNCOMMITTED. Дополнительные сведения об аргументе READUNCOMMITTED см. далее в этом разделе.
Для инструкций UPDATE и DELETE. В будущей версии Microsoft SQL Server этот компонент будет удален. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
PAGLOCK
Применяет блокировку страниц вместо стандартной блокировки строк или ключей, а также вместо блокировки отдельной таблицы. По умолчанию используется режим блокировки, соответствующий операции. При указании блокировок в транзакциях, выполняемых с уровнем изоляции SNAPSHOT, они применяются только в том случае, когда подсказка PAGLOCK используется в сочетании с другими табличными подсказками, требующими блокировки, например UPDLOCK или HOLDLOCK.
READCOMMITTED
Указывает, что операции чтения соответствуют правилам для уровня изоляции READ COMMITTED путем использования блокировки или управления версиями строк. Если параметр базы данных READ_COMMITTED_SNAPSHOT установлен в значение OFF, компонент Компонент Database Engine устанавливает совмещаемую блокировку по мере чтения данных и снимает блокировку при завершении операции чтения. Если значение параметра базы данных READ_COMMITTED_SNAPSHOT равно ON, компонент Компонент Database Engine не накладывает блокировок и использует управление версиями строк. Дополнительные сведения об уровнях изоляции см. в разделе SET TRANSACTION ISOLATION LEVEL (Transact-SQL).
Для инструкций UPDATE и DELETE. В будущей версии Microsoft SQL Server этот компонент будет удален. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
READCOMMITTEDLOCK
Указывает, что операции чтения соответствуют правилам для уровня изоляции READ COMMITTED путем использования блокировки. Компонент Компонент Database Engine накладывает совмещаемые блокировки по мере чтения данных и снимает их после завершения операции чтения вне зависимости от значения параметра базы данных READ_COMMITTED_SNAPSHOT. Дополнительные сведения об уровнях изоляции см. в разделе SET TRANSACTION ISOLATION LEVEL (Transact-SQL). Это указание не может задаваться в целевой таблице инструкции INSERT, в таком случае возвращается ошибка 4140.
READPAST
Указывает, что компонент Компонент Database Engine не считывает строки и страницы, заблокированные другими транзакциями. Если указан аргумент READPAST, блокировки уровня строк будут пропускаться, а блокировки уровня страниц — не будут. Компонент Компонент Database Engine будет пропускать строки вместо блокировки текущей транзакции до тех пор, пока блокировки не будут сняты. Например, предположим, что в таблице T1 есть один целочисленный столбец со значениями 1, 2, 3, 4, 5. Если транзакция A изменит значение 3 на 8, но еще не будет зафиксирована, то инструкция SELECT * FROM T1 (READPAST) возвратит значения 1, 2, 4, 5. Параметр READPAST главным образом используется для устранения конфликта блокировок при реализации рабочей очереди, использующей таблицу SQL Server. Средство чтения очереди, использующее аргумент READPAST, пропускает прошлые записи очереди, заблокированные другими транзакциями, до следующей доступной записи очереди, не дожидаясь, пока другие транзакции снимут свои блокировки.
Аргумент READPAST можно задать для любой таблицы, к которой обращается инструкция UPDATE или DELETE, и к любой таблице, на которую ссылается предложение FROM. Если аргумент READPAST задан в инструкции UPDATE, он применяется только при считывании данных для идентификации подлежащих обновлению записей вне зависимости от того, где он указан в инструкции. Аргумент READPAST для таблиц из предложения INTO инструкции INSERT задать нельзя. Операции обновления или удаления, использующие аргумент READPAST, могут блокироваться либо при считывании внешних ключей или индексированных представлений, либо при изменении вторичных индексов.
Аргумент READPAST можно указывать только в транзакциях, выполняемых на уровнях изоляции READ COMMITTED или REPEATABLE READ. При указании подсказки READPAST в транзакциях, выполняемых с уровнем изоляции SNAPSHOT, она должна использоваться в сочетании с другими табличными подсказками, требующими блокировки, например UPDLOCK или HOLDLOCK.
Табличное указание READPAST нельзя указать, если для параметра базы данных READ_COMMITTED_SNAPSHOT установлено значение ON и выполняется одно из следующих условий:
Чтобы в этих случаях указать подсказку READPAST, удалите табличную подсказку READCOMMITTED (если существует) и включите в запрос табличную подсказку READCOMMITTEDLOCK.
READUNCOMMITTED
Указывает, что чтение недействительных результатов разрешено. Для предотвращения ситуаций, когда другие транзакции изменяют данные, считанные текущей транзакцией, не накладываются совмещаемые блокировки, а монопольные блокировки других транзакций не мешают текущей транзакции считывать заблокированные данные. Разрешение чтения измененных результатов может привести к повышению параллелизма за счет считывания изменений данных, откат которых произведен другими транзакциями. Это в свою очередь может сопровождаться ошибками транзакции, представлением пользователю незафиксированных данных, повторным появлением некоторых записей или их отсутствием.
Указания READUNCOMMITTED и NOLOCK применяются только к блокировкам данных. Все запросы, включая запросы с указаниями READUNCOMMITTED и NOLOCK, получают блокировку Sch-S (стабильность схемы) в процессе компиляции и выполнения. Поэтому запросы блокируются, если параллельная транзакция удерживает в таблице блокировку Sch-M (изменение схемы). Например, операция языка DDL получает блокировку Sch-M до того, как она изменяет данные схемы. Все параллельные запросы, включая выполняемые с указаниями READUNCOMMITTED или NOLOCK, блокируются при попытке получить блокировку Sch-S. И наоборот, запрос, удерживающий блокировку Sch-S, блокирует параллельную транзакцию, которая пытается получить блокировку Sch-M.
Подсказки READUNCOMMITTED и NOLOCK для таблиц, измененных операциями вставки, обновления или удаления, указать нельзя. Оптимизатор запросов SQL Server не учитывает подсказки READUNCOMMITTED и NOLOCK в предложении FROM, применяемые к целевой таблице инструкции UPDATE или DELETE.
Поддержка использования подсказок READUNCOMMITTED и NOLOCK в предложении FROM, применяемом к целевой таблице инструкции UPDATE или DELETE, будет удалена в следующей версии SQL Server. Следует избегать использования этих указаний в таком контексте в новой разработке и запланировать изменение приложений, использующих их в настоящий момент.
Минимизировать состязание блокировок во время защиты транзакций от «грязных» чтений незафиксированных изменений данных можно следующими способами.
Дополнительные сведения об уровнях изоляции см. в разделе SET TRANSACTION ISOLATION LEVEL (Transact-SQL).
Если выдается сообщение об ошибке 601 при заданном параметре READUNCOMMITTED, ее следует разрешить так же, как и ошибку взаимоблокировки (сообщение об ошибке 1205), и затем повторить инструкцию.
REPEATABLEREAD
Указывает, что сканирование выполняется с той же семантикой блокировки, что и транзакция, запущенная на уровне изоляции REPEATABLE READ. Дополнительные сведения об уровнях изоляции см. в разделе SET TRANSACTION ISOLATION LEVEL (Transact-SQL).
ROWLOCK
Указывает, что вместо блокировки страниц или таблиц применяются блокировки строк. При указании блокировок строк в транзакциях, выполняемых на уровне изоляции SNAPSHOT, они применяются только в случае, когда подсказка ROWLOCK используется в сочетании с другими табличными подсказками, требующими блокировки, например UPDLOCK или HOLDLOCK. ROWLOCK нельзя использовать с таблицей, имеющей кластеризованный индекс columnstore. В следующем примере в приложении возвращается ошибка 651.
SERIALIZABLE
Равнозначен аргументу HOLDLOCK. Накладывает дополнительные ограничения на совмещаемую блокировку: удерживает ее до завершения транзакции вместо снятия блокировки сразу после того, как таблица или страница данных больше не требуется, независимо от того, завершена ли транзакция. Сканирование выполняется с той же семантикой, что и транзакция, запущенная на уровне изоляции SERIALIZABLE. Дополнительные сведения об уровнях изоляции см. в разделе SET TRANSACTION ISOLATION LEVEL (Transact-SQL).
SNAPSHOT
Область применения: SQL Server 2014 (12.x) и более поздних версий.
Доступ к таблице, оптимизированной для памяти, выполняется с изоляцией SNAPSHOT. SNAPSHOT может использоваться только с таблицами, оптимизированными для памяти (не с дисковыми таблицами), как показано в следующем примере. Дополнительные сведения см. в разделе Введение в таблицы, оптимизированные для памяти.
SPATIAL_WINDOW_MAX_CELLS =
Область применения: SQL Server 2012 (11.x) и более поздних версий.
Указывает максимальное количество ячеек, используемых для тесселяции геометрического или географического объекта. — это число от 1 до 8192.
Этот параметр позволяет выполнять тонкую настройку времени выполнения запроса за счет настройки компромисса между временем выполнения первичного и вторичного фильтра. Чем больше число, тем меньше время выполнения вторичного фильтра и больше время выполнения первичного фильтра, и наоборот. Для получения более плотных пространственных данных большее число должно давать большее время выполнения за счет лучшего приближения с первичным фильтром и сокращения времени выполнения вторичного фильтра. Для получения более разреженных данных меньшее число сократит время выполнения первичного фильтра.
Этот параметр работает и в ручной и в автоматической тесселяции сетки.
TABLOCK
Указывает, что полученная блокировка применяется на уровне таблицы. Тип полученной блокировки зависит от того, какая инструкция выполняется. Например, инструкция SELECT может потребовать совмещаемой блокировки. При указании TABLOCK совмещаемая блокировка применяется ко всей таблице, а не на уровне строк или страниц. Если также указано HOLDLOCK, то блокировка таблицы удерживается до конца транзакции.
Во время импорта данных в кучу с помощью инструкции INSERT INTO SELECT FROM можно включить минимальное ведение журнала и оптимизированную блокировку для инструкции, задав для целевой таблицы указание TABLOCK. Кроме того, для базы данных должна быть задана простая модель восстановления или модель восстановления с неполным протоколированием. Кроме того, подсказка TABLOCK позволяет выполнять параллельные вставки в кучи или кластеризованные индексы columnstore. Дополнительные сведения см. в статье INSERT (Transact-SQL).
При использовании с поставщиком больших наборов строк OPENROWSET для импорта данных в таблицу указание TABLOCK позволяет нескольким клиентам параллельно загружать данные в целевую таблицу с оптимизацией записи в журнал и блокировки. Дополнительные сведения см. в разделе Предварительные условия для минимального протоколирования массового импорта данных.
TABLOCKX
Указывает, что к таблице применяется монопольная блокировка.
UPDLOCK
Указывает, что блокировки обновления применяются и удерживаются до завершения транзакции. UPDLOCK получает блокировки обновления для операций чтения только на уровне строк или страниц. Если UPDLOCK используется в сочетании с TABLOCK или по какой-либо другой причине уже получена блокировка на уровне таблицы, то вместо них будет получена монопольная (X) блокировка.
Если указано UPDLOCK, то указания уровня изоляции READCOMMITTED и READCOMMITTEDLOCK не учитываются. Например, если уровень изоляции в данном сеансе установлен в SERIALIZABLE и в запросе указано (UPDLOCK, READCOMMITTED), то указание READCOMMITTED не учитывается и транзакция будет выполняться на уровне изоляции SERIALIZABLE.
XLOCK
Указывает, что монопольные блокировки применяются и удерживаются до завершения транзакции. Если при этом указан аргумент ROWLOCK, PAGLOCK или TABLOCK, монопольная блокировка применяется к соответствующему уровню гранулярности.
Remarks
Табличные указания пропускаются, если доступ к таблице не предусмотрен планом запроса. Это может быть вызвано тем, что оптимизатор вообще отказался от доступа к таблице или вместо этого получает доступ к индексированному представлению. В последнем случае доступ к индексированному представлению можно предотвратить с помощью подсказки в запросе OPTION (EXPAND VIEWS).
Все подсказки блокировки распространяются на все таблицы и представления, к которым имеет доступ данный план запроса, в том числе в таблицы и представления, на которые ссылается данное представление. Кроме того, SQL Server выполняет соответствующие проверки согласованности блокировок.
Указания блокировки ROWLOCK, UPDLOCK и XLOCK, накладывающие блокировку уровня строки, могут накладывать блокировки на ключи индекса вместо фактических строк данных. Например, если для таблицы имеется некластеризованный индекс, а инструкция SELECT обрабатывается покрывающим индексом с использованием подсказки блокировки, блокировка накладывается на ключ покрывающего индекса вместо строки данных в базовой таблице.
Если таблица содержит вычисляемые столбцы, которые вычисляются выражениями или функциями, получающими доступ к столбцам других таблиц, то в таких таблицах табличные подсказки не используются и не распространяются. Например, в запросе указана табличная подсказка NOLOCK для таблицы. В этой таблице есть столбцы, вычисляемые с помощью сочетания выражений и функций, получающих доступ к столбцам другой таблицы. При доступе к таблицам, на которые ссылаются выражения и функции, табличное указание NOLOCK не используется.
SQL Server не разрешает более одного табличного указания из каждой из следующих групп в каждой из таблиц в предложении FROM.
Подсказки отфильтрованного индекса
Оптимизатор запросов не учитывает указание индекса, если в параметрах SET нет требуемых значений для отфильтрованных индексов. Дополнительные сведения см. в разделе CREATE INDEX (Transact-SQL).
Использование NOEXPAND
Аргумент NOEXPAND применяется только для индексированных представлений. Индексированное представление — это представление с созданным на нем уникальным кластеризованным индексом. Если запрос содержит ссылки на столбцы, присутствующие как в индексированном представлении, так и в базовых таблицах, а оптимизатор запросов определяет, что использование индексированного представления является лучшим методом выполнения запроса, то оптимизатор будет использовать индекс представления. Эта функциональная возможность называется сопоставлением индексированного представления. До SQL Server 2016 (13.x); с пакетом обновления 1 (SP1) автоматическое использование индексированного представления оптимизатором запросов поддерживали только определенные выпуски SQL Server. См. сведения о выпусках и поддерживаемых функциях SQL Server 2016, 2017 и 2019 (15.x).
Чтобы оптимизатор запросов учитывал индексированные представления для сопоставления или применял индексированное представление, обращение к которому производится с использованием указания NOEXPAND, нужно задать для следующих параметров SET значение ON.
База данных SQL Azure поддерживает автоматическое использование индексированного представления без указания NOEXPAND.
1 Параметр ARITHABORT неявным образом получает значение ON, когда для ANSI_WARNINGS устанавливается ON. Поэтому менять этот параметр вручную не обязательно.
Кроме того, параметр NUMERIC_ROUNDABORT нужно установить в OFF.
Чтобы оптимизатор запросов использовал индекс для индексированного представления, определите параметр NOEXPAND. Это указание можно использовать только в случае, если представление также названо в запросе. В SQL Server нет указания для принудительного использования определенного индексированного представления в запросе, в котором представление явно не названо в предложении FROM. При этом оптимизатор запросов может использовать индексированные представления, даже если запрос не обращается к ним напрямую. С помощью Компонент SQL Server Database Engine в индексированном представлении автоматически создается статистика только при использовании табличного указания NOEXPAND. Пропуск этой подсказки может привести к предупреждениям об отсутствующей статистике, которые невозможно разрешить, создав статистику вручную. Во время оптимизации запроса Компонент Database Engine будет использовать статистику представления, созданную автоматически или вручную, когда запрос напрямую ссылается на представление и используется указание NOEXPAND.
Использование табличного указания в качестве указания запроса
Табличные указания могут использоваться в качестве указаний запроса с помощью предложения OPTION (TABLE HINT). Табличные указания рекомендуется использовать в качестве подсказок в запросах только в контексте структуры плана. Для нерегламентированных запросов эти указания следует задавать как табличные указания. Дополнительные сведения см. в разделе Указания запросов (Transact-SQL).
Разрешения
Для указаний KEEPIDENTITY, IGNORE_CONSTRAINTS и IGNORE_TRIGGERS требуются разрешения ALTER для таблицы.
Примеры
A. Использование подсказки TABLOCK для указания метода блокировки
В следующем примере показано, как на таблицу Production.Product в базе данных AdventureWorks2012 накладывается совмещаемая блокировка, удерживаемая до завершения инструкции UPDATE.
Б. Использование указания FORCESEEK для указания операции поиска в индексе
В следующем примере показано использование указания FORCESEEK без указания индекса, предписывающее оптимизатору запросов выполнять операцию поиска в индексе для таблицы Sales.SalesOrderDetail в базе данных AdventureWorks2012.
В следующем примере указание FORCESEEK с индексом предписывает оптимизатору запросов выполнить операцию поиска по указанному индексу и столбцу индекса.