
Суперсила индексов для оптимизации SQL-запросов

Введение
Вы любите SQL и хотите улучшить свои навыки выполнения SQL-запросов? Вы знаете, что индексация — отличный инструмент для оптимизации запросов, но при этом не уверены, что она из себя представляет, с какой целью и как используется?
Добро пожаловать! Вы оказались именно там, где нужно. Сейчас объясним суть индексации на простом и понятном языке.
Начнем с простого запроса:
Для его выполнения база данных (БД) должна просканировать все 12 миллионов строк, чтобы проверить каждую запись на соответствие. Предположим, что время этой операции составляет 4 секунды.
Можно ли быстрее? Конечно. А Как? С помощью индексации.
Индексация
Понятие индексации
Свое название индексация получила по образу и подобию книжного индекса. Если, читая книгу по статистике, вы ищите информацию о “линейной регрессии”, то, вряд ли, станете поочередно перелистывать сотни страниц, чтобы добраться до главы с интересующим вас материалом.
Вы просто откроете страницу индексов, найдете “линейную регрессию” и сразу перейдете на нужную страницу.
Индексация позволяет задействовать данный метод и в работе БД, которая с помощью созданного индекса быстро находит данные по запросу. А как именно это происходит, разберемся далее.
Создание индексов
Давайте создадим индекс для таблицы product и включим в него ‘category’:
Теперь же задействуем индекс и протестируем выполнение самого первого нашего запроса:
Как видно, в этот раз он будет выполняться намного быстрее и, вероятно, займет 400 миллисекунд.
Выполнение этого запроса займет меньше времени, чем обычно — около 600 миллисекунд. С помощью индекса БД быстро найдет все товары ‘electronics’ и из небольшого списка записей выберет ‘headphones’.
Какова же внутренняя суть процесса?
БД анализирует все возможные пути выполнения запроса, выбирая самый оптимальный из них.
Теперь пора познакомиться с некоторыми терминами БД. Каждый возможный путь называется планом выполнения запроса. По сути, это последовательность операций для получения результата SQL-запроса в реляционной системе управления базами данных (СУРБД).
А компонент СУРБД, определяющий наиболее эффективный способ выполнения запроса с учетом анализа всех возможных планов, называется оптимизатором запросов.
Индексация по нескольким столбцам
Теперь рассмотрим индексацию по нескольким столбцам.
Индекс можно создать более чем для одного столбца.
Данный тип индекса еще больше ускорит выполнение запроса, предположительно до 60 миллисекунд.
Более того, БД может включать более одного индекса.
В каких случаях следует применять индексацию?
Индексы ускоряют работу БД, а по мере ее разрастания их эффективность становится очевиднее.
При этом важно помнить о том, что:
В связи с этим, лучше использовать индексы для БД в хранилищах данных, получающих плановые обновления, т. е. в часы наименьшей нагрузки, а не для производственных, которые обновляются постоянно. Это объясняется тем, что при постоянных обновлениях БД индексы обновляться не будут, а следовательно станут бесполезны.
Типы индексов
Здесь мы кратко рассмотрим 2 типа индексов БД для лучшего понимания темы:
1. Кластеризованные индексы
2. Декластеризованные индексы
Кластеризованные индексы
Кластеризованные называется особый индекс, который использует первичный ключ для структуризации данных в таблице. Он не требует явного объявления и создается по умолчанию при определении ключа. Отсортированный же в порядке возрастания первичный ключ по умолчанию применяется в качестве кластеризованного индекса.
Продемонстрируем вышесказанное на простом примере:
Интересно, как же именно это происходит?
Индексы используют оптимальный метод поиска, известный как двоичный поиск.
Двоичный поиск — это эффективный алгоритм поиска записи в сортированном списке. Принцип его работы основан на повторяющемся делении данных пополам и определении того, находится ли искомая запись до или после записи в середине структуры данных. Если значение искомой записи меньше срединного, то поиск продолжается в первой половине, иначе — во второй. Эта процедура повторяется вплоть до нахождения значения. Благодаря данному методу уменьшается число требуемых поисков и, следовательно, ускоряется выполнение запросов.
Следующая таблица отражает соотношение записей данных и максимальное число поисков:
Аналогичным образом для нашего датасета с 12 миллионами строк понадобится не 12 миллионов, а всего лишь 24 поиска — и всё благодаря двоичному поиску. Думаю, теперь вы осознаете супер силу индексов.
Некластеризованный индекс
Теперь узнаем, как применить преимущества индексации к столбцами, отличающимися от первичного ключа. Для этого существуют некластеризованные индексы.
Их примеры уже встречались в начальных разделах статьи во время написания оптимизированных запросов — это индексы, которые требуют явного определения.
Некластеризованный индекс хранится в одном месте, а физические данные таблицы — в другом. Опять нам на ум приходит сравнение со страницей индексов, которая размещается отдельно от содержимого книги. Благодаря этой особенности для каждой таблицы можно создавать более одного некластеризованного индекса, как было показано ранее.
Как именно это происходит?
Предположим, вы уже создали некластеризованный индекс для столбца и теперь пишите запрос для поиска в нем записи. Этот индекс содержит следующее:
Это наглядно отображено в таблице слева на рис.6:
Давайте рассмотрим этот запрос более подробно:
БД совершает 3 шага:
Как видим, работа с некластеризованным индексом предполагает дополнительный шаг, включающий поиск адреса строки и переход к ней в основной таблице. Следовательно запрос с таким индексом выполняется медленнее в отличие от кластеризованного аналога.
Заключение
Итак, мы выяснили, что такое индексы и какую роль они играют в оптимизации выполнения SQL-запросов, особенно при работе с огромными датасетами.
В завершении приведу вам высказывание Тайгера Вудса, лучшего гольфиста всех времен:
“Независимо от того, насколько хорошо вы играете, вы всегда можете стать лучше, и это вдохновляет”.
Индекс (информационные технологии)
Содержание
Идентификатор элемента массива
Для объектов данных хранящихся в массиве, отдельные объекты выбираются индексом, который обычно является неотрицательным скалярным целым числом.
Есть три способа, как элементы массива могут быть проиндексированы [1] :
0 («индекс с началом с нуля») первый элемент массива имеет индекс 0; 1 («индекс с началом с единицы») первый элемент массива имеет индекс 1; n («индекс началом с n») базисный индекс массива может быть свободно выбран. Обычно языки программирования, позволяющие «индекс началом с n», разрешают также в качестве индекса массива выбирать отрицательные значения, а также и другие скалярные типы данных, как перечисления или символы.
Массив может иметь несколько измерений, таким образом обычная практика обращаться к массиву, используя несколько индексов. Например к двумерному массиву с тремя строками и четырьмя столбцами можно было бы обратиться к элементу в 2-ом ряду и 4-ой столбце с помощью выражения: [1,3] (в языке в котором приоритет у строки) и [3,1] (в языке в котором приоритет у столбца) в случае индексом с началом с нуля. Таким образом два индекса используются для двумерных массивов, три для трехмерного массива, и n для n-мерного массива.
За деталями поддержки различных особенностей в языках программирования см. Сравнение языков программирования (массивы).
Поисковой индекс: поддержка быстрого поиска
Индекс для поиска или Поисковой индекс — вспомогательная для поиска в некотором хранилище структура данных, обеспечивающая сублинейное время поиска в этом хранилище.
Объяснение на примере
Предположим, что контейнер данных содержит N объектов данных. Прямой подход — использовать индекс объекта как его идентификатор, то есть, компания могла бы просить, чтобы его клиенты всегда упомянули свой номер счета и что число непосредственно идентифицирует запись клиента, хотя практически у номера счета должны быть дополнительные цифры, для защиты от опечаток. Это первой форма использования: целое число, которое идентифицирует элемент множества.
Однако, использование таких чисел не может быть удобным, так же, как «wikipedia.org» предпочтительнее чем тридцатидвухбитное число 3494942722 представленное в форме IP как 208.80.152.2. Наивный алгоритм был бы такой: подготовить список имен и при поиске некоторого конкретного имени, каждое имя из списка по очереди проверять, с начала до конца. В случае успешного поиска проверяется в среднем половина из них, в худшем случае проверяются все элементы, в итоге выдавая результат «не найдено»; Время работы алгоритма O(N), оно же линейное время. Так как хранилища данных нередко содержат миллионы объектов и так как поиск — достаточно частая операция, желательно изменить его работу к лучшему.
Для этого и применяют поисковой индекс: любую структуру данных, которая улучшает работу поиска.
Аспекты применения
Индекс — любая структура данных, которая улучшает работу поиска. Есть много различных структур данных, используемых с этой целью, и фактически существенная часть предмета информатики посвящена проектированию и анализу структур данных поискового индекса. Есть сложность в выборе компромиссов при выборе дизайна поискового индекса, рассматривая такие параметры как быстродействие при поиске, размер индекса, и скорость обновления индекса. Многие дизайны индекса показывают логарифмическое (O (log(N)) время работа поиска, а в некоторых приложениях даже возможно достигнуть равномерного-O (1) быстродействия.
Все базы данных содержат технологии индексации для обеспечения быстрого поиска в данных. См. Индекс (базы данных).
Еще одно специфичное, но часто встречающееся приложение — в области информационного поиска, где полнотекстовое индексирование позволяет быстро идентифицировать документы, основываясь на их текстовом содержании.
Компьютерная грамотность с Надеждой
Заполняем пробелы — расширяем горизонты!
Что такое переменная с индексами, массив, комментарий, цикл и счетчик в программировании на конкретном примере
Имея представление о том, что такое переменная в программировании, давайте попробуем решить небольшую задачку. А именно, задачу про суммирование веса всех товаров в супермаркете. Заодно немного углубимся в секреты составления программ и выясним для себя, что такое переменная с индексами, массив в программировании, а также комментарий, цикл и счетчик.

Итак, вернемся к задаче. Зачем мерить сумму веса товаров? Наверное, в супермаркете это не очень нужно, но вот, скажем, на складе, откуда осуществляются поставки товаров в супермаркеты, это надо делать. Зачем? Ну, хотя бы для того, чтобы потом посчитать, каким количеством рейсов можно эти товары вывезти автомобильным транспортом. Ведь в каждый автомобиль влезает строго определенный вес, не более.
Задачу чуть усложним. Будем считать, что товаров у нас, например, миллион единиц. И у каждого товара есть вес нетто (это чистый вес без упаковки), есть дополнительный вес упаковки и суммарный вес брутто. Нас будет интересовать вес каждого товара: нетто, вес упаковки, брутто, — а также общий вес всех товаров на складе.
1. Решение задачи суммирования весов с использованием переменных в программировании
Можно определять вес брутто как сумму весов нетто и веса упаковки
(брутто=нетто+вес_упаковки). Обозначим:
Тогда выражение C = A + B даст нам, очевидно, вес брутто. Здорово, задача почти решена.
Но не все так просто. Ведь товаров у нас миллион. Мы посчитали только вес брутто одного товара. Что делать с остальными? Очевидно, их тоже надо суммировать.
Тогда выражение F = D + E даст нам вес брутто второго товара. Хорошо, теперь мы можем просуммировать веса брутто двух товаров, например, в таком выражении, как G = C + F, где C – вес брутто первого товара, F – вес брутто второго товара.
Мы получили с Вами небольшую программу, которая суммирует вес 2-х товаров из миллиона. Она выглядит следующим образом:
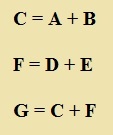
Рис. 1. Программа суммирует вес 2-х товаров
В итоге в значении переменной G мы получим вес 2-х товаров из миллиона. Но даже в такой самой небольшой программе мы можем со временем запутаться. Посмотрим на нее, скажем, через полгода. Разве мы вспомним, что означает A, B, C, D, E, F? Маловероятно.
2. Комментарии в программировании, что это такое и как их пишут
В запоминании смысла того, что мы запрограммировали, нам могут помочь комментарии, которые программисты имеют возможность писать в своих программах.
Комментарии – это ничего не значащий для компьютера текст, который понятен только программистам. Этот текст можно писать прямо в тексте программы, но чтобы его отделить от текста программы, нужны некоторые правила.
В разных языках программирования правила для написания комментариев могут несколько отличаться, но суть от этого не меняется. Например, давайте комментарии писать сразу после слова (или выражения, команды) Comment (в переводе на русский язык означает Комментарии). Такое слово, такая команда будет для нас означать, что это комментарий, а для компьютера это будет означать, что далее после этой команды на данной строке программы ничего нет, чтоб представляло бы интерес для ее исполнения. Тогда наша программа может выглядеть следующим образом:

Рис. 2. Комментарий в программировании пишут в конце строки для пояснения содержимого строки
Неплохо, правда? С комментариями текст в программе понятен. Но, как говорилось в старой присказке, «так-то так, да вон-то как?!» – это про того, кто строил телегу прямо в избе, и не думал о том, как он ее будет выносить из избы на улицу через маленькие низкие двери и совсем маленькие окошки.
В чем проблема? В миллионе товаров. Их – целый миллион, а мы только добрались до второго товара. И сколько же времени мы будем идти к миллиону? Наверное, при таком подходе, всю жизнь…
3. Сложные имена и идентификаторы переменных в программировании
Попробуем подойти к решению задачи иначе. Переменная величина в программировании обозначается своим именем, или иными словами, у переменной есть идентификатор имени, или просто идентификатор. Вообще-то, идентификаторы в программировании – это не только идентификаторы имен переменных. Это могут быть, например, идентификаторы меток и других объектов программ, но сейчас мы не будем об этом говорить, ограничимся идентификаторами переменных.
Назовем иначе вес нетто первого товара, скажем, обозначим его идентификатором VESNET01, подразумевая, что VES – это «вес», NET – это «нетто», а 01 – это первый товар. Аналогично можем обозначить VESUP01 – вес упаковки первого товара и VESBRT01 – вес брутто 1-го товара. Получаем тогда следующую программу:

Рис. 3. Программа суммирует вес брутто 99 товаров
Ура, мы теперь смогли просуммировать вес аж 99 товаров! Продвинулись мы так далеко, так как стали применять сложные идентификаторы переменных, чем просто привычные переменные A, B, C, D и т.п., которые скорее похожи на алгебраические, чем на программистские.
4. Переменные с индексами или массивы в программировании
Но мы все равно не просуммировали миллион весов товаров. Нас хватило только на 100. Потому что нам не хватило длины имени переменной. Мы ограничены 8-ю символами. Конечно, VES можно сократить до V, BRT – до B, NET – до N, и тем самым высвободить еще поля. Тогда, конечно, можно будет сложить миллион весов товаров, ибо высвободится 5 знаков, которых хватит как раз на 99999 вариантов, а с пятизначным нулем 00000 хватит на миллион вариантов наименования имени переменной.
А ведь для современных компьютеров миллион данных – это пустяк. Они оперируют триллионами и более данных. Что же делать? Надо двигаться дальше в освоении переменных величин. Для таких больших массивов данных простые переменные величины не годятся. Нужны так называемые переменные с индексами.
В алгебре, например, есть такие записи, как a1, a2, a3, b1, b2, b3 и т.д. Так почему бы этому не быть в программировании? Конечно, такое там есть. Такие переменные в программировании называются переменными с индексами.
Переменная с индексом – это переменная, имеющая одно и то же имя, но которая может иметь не единственное значение, а множество разных значений. Под одним именем переменной с индексом скрывается целый массив данных. Каждое отдельное значение этого массива отличается от остальных значений массива своим уникальным индексом.
Индексы в языках программирования обычно указывают в круглых скобках сразу после имени переменной, например, A(1), A(2), A(3), B(1), B(2), B(3) и т.д.
Индексов может быть не один, а несколько, которые указывают через запятую, например A(1,1), A(1,2), A(1,3), A(2,1), A(2,2), A(2,3) и т.д.
Что такое массив в программировании?
Переменные с индексами, независимо от количества индексов, довольно часто еще называют массивами, это даже как-то проще и короче звучит.
Чем отличается массив от переменной? В массиве под одним идентификатором переменной хранится не одно число, а целый массив данных.
Массив, в котором переменная имеет один индекс, называют линейным или одномерным массивом. Пример одномерного массива: A(1), A(2), A(3).
Массив, где переменная может иметь два индекса, называют двумерным. Пример двумерного массива: A(1,1), A(1,2), A(1,3), A(2,1) A(2,2), A(2,3).
Также могут быть 3-х мерные, 4-х мерные и более мерные массивы (или иными словами массивы большей размерности), если они нужны для решения тех или иных задач в программировании. Нам же для нашей задачи суммирования веса товаров вполне достаточно линейного (одномерного) массива.
Вернемся к почти полюбившемуся и уже привычному выражению C = A + B. Напишем теперь программу суммирования, не много не мало, миллиона весов товаров, больше не задумываясь над «сочинением» имен или идентификаторов разных переменных:

Рис. 4. Программа суммирует миллион единиц товаров
5. Понятие размерности для переменных с индексами или для массивов в программировании
Все, кажется просто, и мы вроде как решили задачку. Но не все так просто. Для компьютера надо заранее указать, какой будет размерность каждого применяемого массива или каждой применяемой в программе переменной с индексами.
Размерность – это максимальное значение индекса для переменной с индексом, иначе транслятор с языка программирования не сможет распознать нашу запись любой неописанной переменной с индексами, и выдаст ошибку. Почему так: подумаешь индексы, зачем их надо заранее описывать?
Дело в том, что под каждый элемент массива, под каждый индекс переменной с индексом транслятор с языка программирования должен зарезервировать в оперативной памяти компьютера одну свободную ячейку памяти. И затем каждое значение переменной с индексом разместить строго в свою ячейку памяти.
Именно для этого перед выполнением программы нужно еще поставить оператор (команду), задающий эту максимальную размерность. Это будет указанием для транслятора с языка программирования на отведение соответствующего количества оперативной памяти под указанный массив данных.
Например, применим для обозначения размерности массива команду Dimension (в данном контексте в переводе с английского языка это означает «Размерность»):

Рис. 5. Команда для обозначения размерности массива
Или проще, в одну строку:
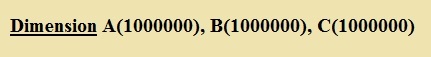
Рис. 6. Указываем в программе размерность 3-х массивов
И только потом напишем нашу программу:
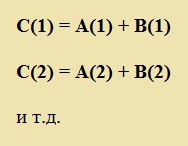
Рис. 7. Программа суммирует веса товаров: в каждой строке вес одного товара
Но и этого недостаточно. Ведь не сможем мы и в данном случае написать программу из миллиона строк. А ведь придется, если в каждой строке мы суммируем данные только по одному товару. Но нам «жизни не хватит» написать такую длинную программу, поэтому такая программа возможна только теоретически, но никак не практически. Что же делать?
6. Цикл или Многократное циклическое выполнение команд в программировании
Для решения подобных задач в языках программирования есть более сложные, и при этом более эффективные выражения, чем просто присвоить переменной в левой части значение выражения из правой части (рис. 7). Подобных команд множество, но мы пока не ставим задачу все их изучить. Возьмем пока одну команду – команду выполнения программы в цикле. Что такое цикл в программировании для нашей задачи?
У нас есть массив данных веса нетто товара – массив A размерностью миллион. Также есть массив B такой же размерности. И нам надо миллион раз сложить A(I) и B(I), где значение новой переменной I меняется от единицы до миллиона. Это записать просто с помощью команд циклического выполнения программы или проще с помощью цикла, как говорят программисты:

Рис. 8. Цикл в программировании суммирует товары от 1 до 1000000
В переводе на русский:

Рис. 9. Цикл в программировании на русском языке
Или иными словами, для всех значений переменной I от единицы с шагом по одному до миллиона просуммируйте A(I) и B(I), результат запишите в C(I). Миллион суммирований! С помощью лишь одной строки программы! А вот это уже и есть настоящее программирование. Что нам теперь миллион? Можем и миллиард сумм сделать в одной программной строке! А если надо, то и больше.
7. Счетчик в программировании или Многократное суммирование данных в одной переменной
Так-то так, да вон-то как? А как же общая сумма? Да, согласен, нужно к этой простой и эффективной одной единственной строке программы приписать еще пару строк, например, таких, как показано ниже, и тоже с использованием цикла:

Рис. 10. Счетчик в программировании работает по принципу счетчика в такси
Вот такое решение задачки, которую мы обозначили в начале этой статьи об именах и идентификаторах переменных в программировании, у нас получилось. Всего четыре строчки программы, и «миллион у нас в кармане»:

Рис. 11. Программа суммирует вес брутто для миллиона товаров
Кстати, обратите, пожалуйста, внимание на выражение в последней строке программы после команды Do. Речь идет о выражении G = G + C(I).
В этом выражении переменная G используется как в левой части выражения (ей присваивается результат вычисления), так и в правой части выражения, поскольку ее предыдущее значение участвует в очередном суммировании. Такая конструкция в языках программирования называется «счетчик». Как счетчик в такси: щелк-щелк-щелк и все время цифра прибавляется. В результате «набегает» общая сумма за поездочку на такси, или, в данном контексте набегает сумма всех весов товаров.
Такое почти невозможно в алгебре, чтобы одна и та же переменная стояла слева и справа в выражении. Вернее, это там возможно, например, в уравнениях. А вот в программировании такая конструкция счетчика очень распространена и довольно часто встречается в текстах программ. Все-таки программирование – это не алгебра.
В итоге наша программа занимает всего 4 строки, а делает очень большое дело: суммирует миллион весов нетто, упаковки, и брутто, а также получает конечный результат – сумму весов миллиона товаров, и эта сумма становится значением переменной G.
Правда, непростая работа у программистов?!
Нашли ошибку? Выделите фрагмент текста и нажмите Ctrl+Enter.