
Кэш: что это такое и как с ним справиться начинающим разработчикам
В компьютерных науках есть только две сложные вещи: инвалидация кэша и присвоение имен
Прежде чем мы начнем говорить о инвалидации кэша, давайте посмотрим, что такое кэш на самом деле. Википедия говорит, что кэш — это просто промежуточный буфер с быстрым доступом к нему, содержащий информацию, которая может быть запрошена с наибольшей вероятностью.
В этой статье мы поговорим о трех наиболее часто используемых типах кэша:
Кэш браузера
Каждый раз, когда вы посещаете веб-сайт впервые, браузер локально сохраняет ресурсы веб-страницы (например, html, css, js, изображения и так далее). Это нужно для более быстрой работы и меньшего потребления трафика при следующем посещении.
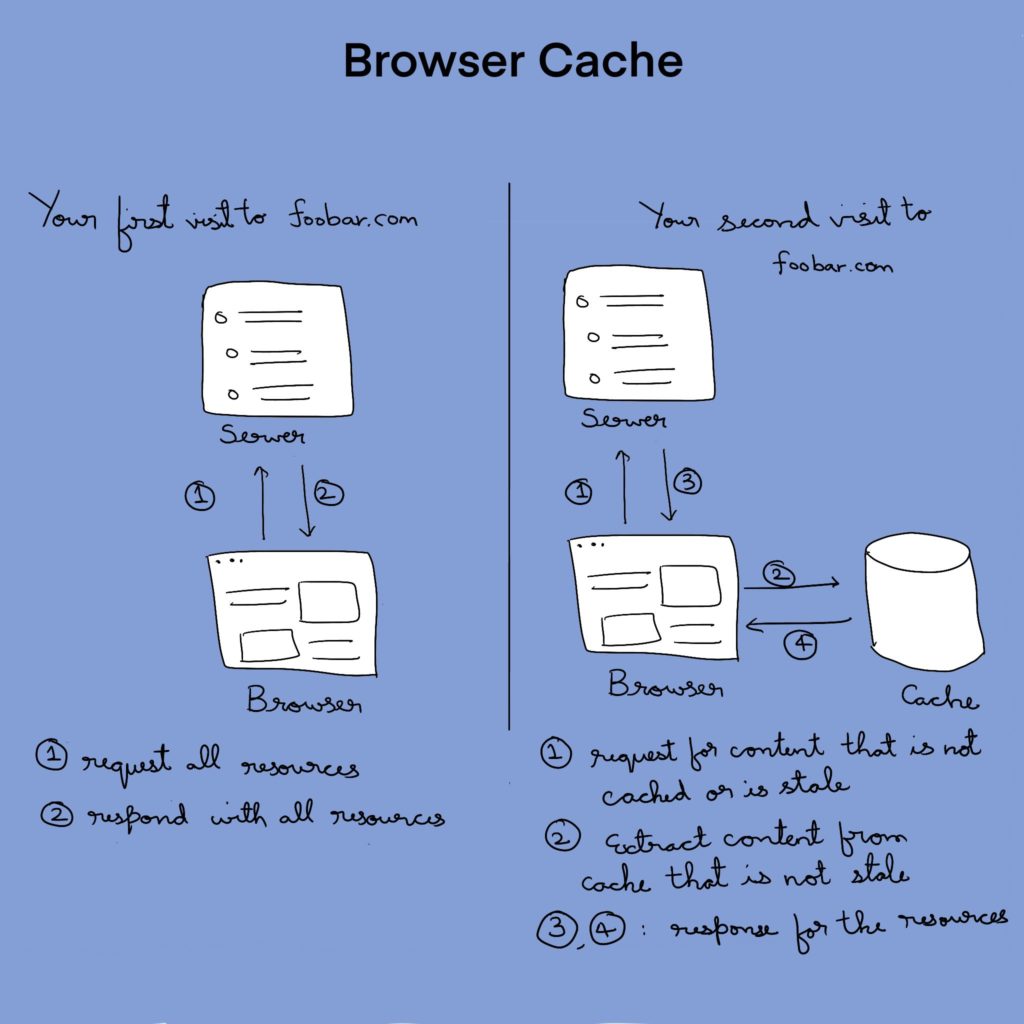
Инвалидация кэша браузера
Инвалидацию кэша также называют очисткой кэша. Под очисткой подразумевается просто удаление кэша. Это делается для того, чтобы пользователю показывались именно свежие ресурсы.
Сети доставки контента (CDN)
Сеть доставки контента (CDN) способна на больше, чем просто кэширование. Она хранит данные в географически распределенных местах, из-за чего время приема и передачи в конкретный географически локализованный браузер и обратно сокращается. Благодаря этому ваш браузер получает данные из ближайшего к вам узла сети CDN.
CDN следует тем же правилам, что и ваш браузер, и фактически просто становится еще одним посредником. Если срок действия кэша еще не истек, первый запрос от браузера в определенном временном окне достигает сервера, а затем последующие запросы уже будут обслуживаться из самой CDN.
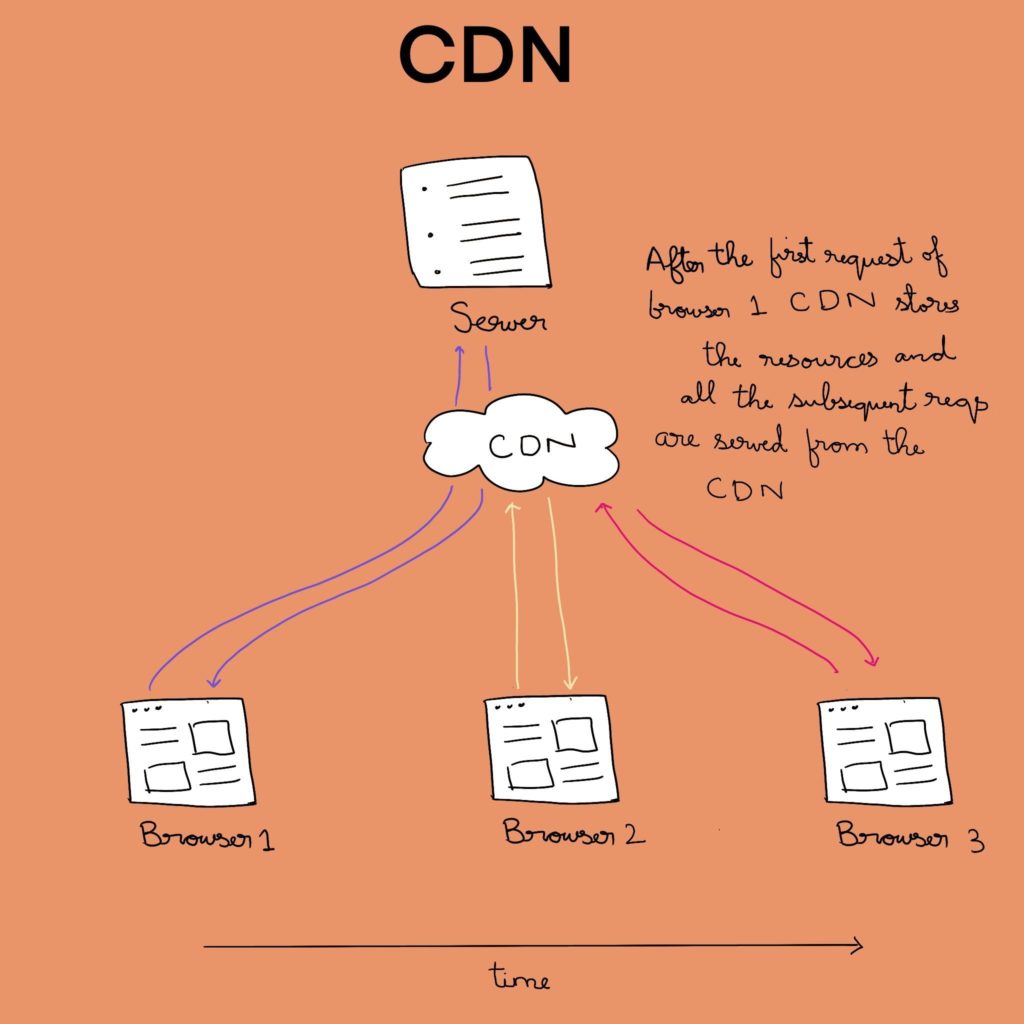
Данный тип кэширования не только помогает сократить время отклика, но и снижает нагрузку на ваш сервер.
Инвалидация кэша в сетях доставки контента (CDN)
У разных провайдеров есть разные способы инвалидации кэша. Например, вы можете описать желаемое поведение кэша в заголовках ваших ответов с сервера. Большинство провайдеров также предоставляют свои собственные API-интерфейсы и возможность очистки кэша со своей панели управления.
Кэширование в базах данных
В предыдущем разделе мы обсудили сети доставки контента (CDN) и тот факт, что они являются посредниками между клиентом и сервером. Аналогичным образом система кэширования базы данных является посредником между сервером и базой данных. Существует множество таких систем кэширования, например redis, memcache и т. д. Их работа объяснена ниже:
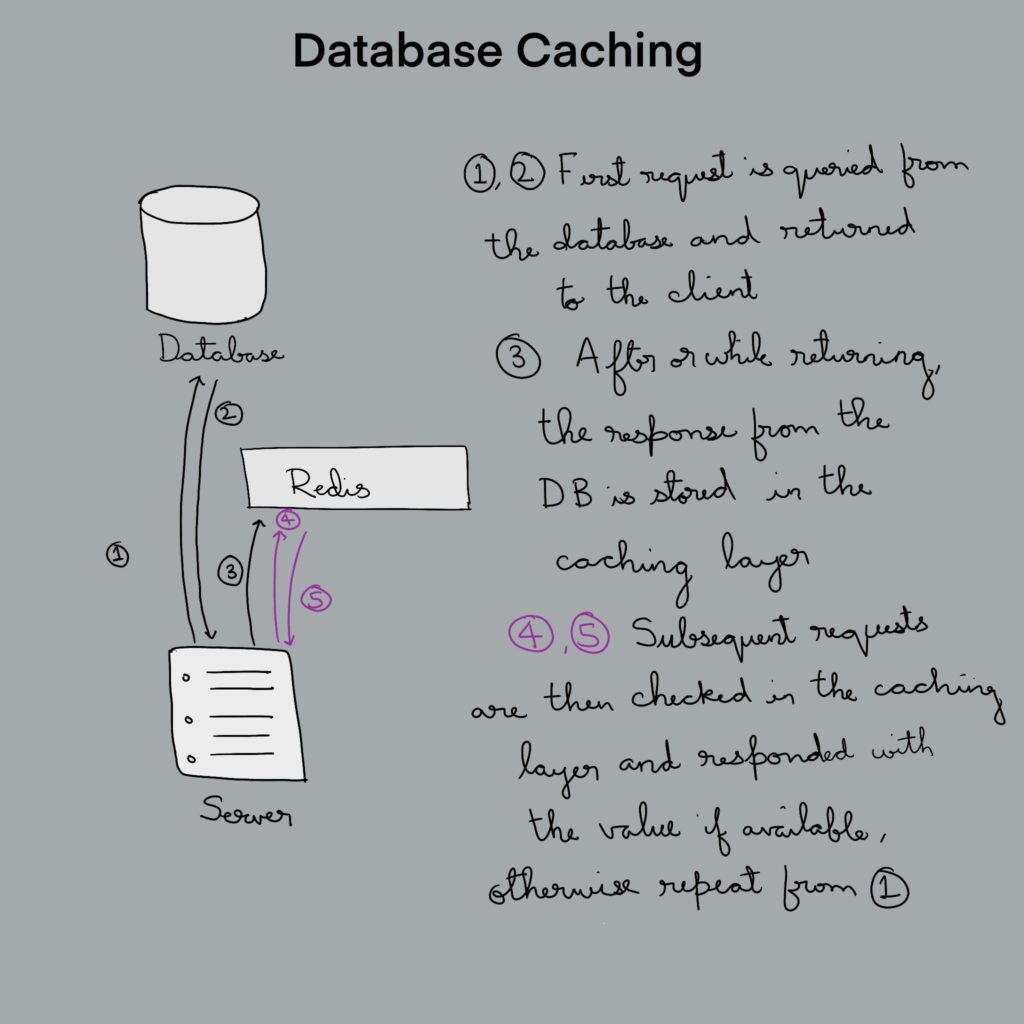
Инвалидация кэша в базах данных
Каждая из подобных систем предоставляет свои собственные методы уничтожения кэша. Обратитесь к их документации, чтобы узнать больше.
Теперь перейдем к вопросу, почему начинающим разработчикам приходится с этим бороться. Как правило, в современных стеках технологий применяются все три вида кэширования. И иногда разработчики застревают при отладке.
Представьте, что вы внесли некоторые изменения в свой веб-сайт, но они не отображаются. Если предположить, что с кодом все в порядке, виновником этого может быть любой из трех вышеописанных видов кэширования. Но это относительно небольшой недостаток (даже не недостаток, если вы о нем знаете) по сравнению с огромным положительным эффектом, который дает кэширование. Этот эффект выражен в масштабируемости, меньшем времени отклика и в целом лучшем пользовательском интерфейсе.
Теория кэша
Введение
Кэширование – это неотъемлемая часть всех сложных систем. Кэширование позволяет существенно увеличить скорость работы приложения, путем сохранения трудновычислимых данных для их последующего использования. Впрочем, не буду вдаваться в определения, большинство разработчиков отлично знает что это такое.
В данной статье я попытаюсь «разложить по полочкам» проблему кэширования, ориентированную прежде всего на сайты и системы управления контентом. Сразу предупреждаю, это мои личные соображения, которые не претендуют на истину в последней инстанции. Вся терминология так же моя, вы можете использовать её, если считаете нужным на своё усмотрение. Конструктивная критика приветствуется.
Основные проблемы кэширования
При кэшировании данных, как правило, не возникает проблем в их сохранении и повторном использовании. Основная проблема заключается в том, что бы определить, когда кэш утрачивает свою актуальность. То есть определить, можно ли использовать данные из кэша, или необходимо вычислить эти данные заново, поскольку что-то могло измениться. Это я назову проблемой актуальности кэша (терминология моя).
Второй проблемой кэширования является проблема быстродействия. А не выполняются ли наш алгоритм без кэширования быстрее, чем с кэшированием? Несмотря на абсурдность с первого взгляда, она более чем имеет место. Дело в том, что алгоритмы кэширования тоже потребляют ресурсы, и запросто может случиться так, что количество потребляемых кэшем ресурсов превышает количество ресурсов для вычисления самих данных. Это часто случается в 2-х случаях. Первый случай — это когда сайт из 10-ти страниц сажают на мощный фреймворк. Тут все просто – исходных данных настолько мало, что скорость вычисления очень высока, а кэширование только тормозит работу. Второй случай обратный — когда сайт настолько большой, что размер кэша вырастает до объемов приводящих к существенному замедлению их поиска в кэше.
Добиться решения обоих проблем невозможно. Возможно лишь выбрать метод обеспечивающие максимальное быстродействие. А еще лучше – что бы это метод выбирался автоматически.
Проблема быстродействия не так актуальна, и решается либо отключением использования кэширования в конфигурации, либо периодического физического удаления закешированных данных и переход на более быстродействующее оборудование.
А вот что касается проблемы актуальности, тут все намного сложнее…
Теория кэша
Автор различает 4 основных типа кэширования информации:
1. Независимый или статичный – имеет место, когда не требуется проверка изменился ли объект. Алгоритм прост – если есть данные в кеше, то отдать данные, иначе их вычислить. Эффективно в рамках работы одного процесса, когда требуется частое использование результатов сложных промежуточных вычислений. После завершения процесса статичный кэш умирает и для повторного процесса все данные вычисляются вновь. Вобщем-то в любом языке программирования все временные переменные – ни что иное, как статичный кеш. Если же требуется кэширование результатов функции, то можно использовать такой алгоритм с использованием static-переменных на примере PHP:
2. Явно-зависимый – имеет место, когда решение об обновлении кэша принимается по некоторому легко вычисляемому признаку. Сюда относится прежде всего кэширование данных взятых из определенного файла, а так же кэширование по времени. В этих случаях легко определить изменился ли файл или не истекло ли время существования кэша (и кэш явно зависит от этих факторов). Алгоритмы здесь тоже достаточно простые – сводятся к проверкам условий, но в отличие от статического кэша он может независимо использоваться разными процессами.
3. Неявно-зависимый – имеет место, когда изменение объекта кэширования зависит от множества факторов. Например, в состав объекта входит множество других объектов, которые тоже могут изменяться. То есть объект неявно (не на прямую) зависит от других, которые тоже могут зависеть от других и т.д. Совокупность этих факторов является неявными зависимостями объекта, и что бы принять решение о том, изменился ли объект нужно «опросить» их все, что не всегда возможно или целесообразно. Например, функция, которая показывает информацию, взятую из базы данных. Мы можем закешировать результат функции, но мы должны знать, когда данные изменятся, что бы их обновить. А это эквивалентно обращению к таблице, что по ресурсоемкости равносильно выполнению функции. А если таблиц много? Смысл кэша теряется.
Это раскрывается через так называемую «таблицу зависимостей». В этой таблице присутствует 2 столбца: объекты и время их изменения. При изменении объектов необходимо обновлять их времена в таблице. Скорость доступа к самой таблице очень высока, (как правило, она находится в статичном или явно-зависимом кеше), и получить времена изменения всех необходимых нам объектов можно очень быстро. И если хоть одно время изменения нужных объектов превышает время кэширования, то кэш необходимо сбросить. Таким образом, неявные зависимости превращаются в явные – объект зависит от некоторого набора времен в таблице зависимостей.
Приведу пример. Есть некий модуль CMS, который занимается отображением комментариев. У нас есть 2 таблицы в БД – пользователей и комментариев, которые связаны соотношением один-ко-многим. При изменении данных некоторого пользователя, мы устанавливаем текущее время в строке «users» в таблице зависимостей. Если изменились комментарии, мы аналогично поступаем со строкой «comments». Модуль знает, что он зависит от «users» и «comments» и если время хотя бы одного из них превышает время изменения кэша, то кэш сбрасывается, иначе — используется. Обращу внимание на то, что «users» и «comments» — это не обязательно время изменения таблицы, это скорее времена изменения некоторой сущности, которая может состоять из множества таблиц и других параметров.
4. Условно-зависимый – имеет место, когда неявно-зависимый кэш может быть приведен к явно-зависимому или статичному при выполнении некоторого условия. Например, можно утверждать, что время последнего изменения таблицы зависимостей – это время последнего изменения данных на сайте. Если для пользователя на странице нет уникальных данных (читай – он не залогинен), то вся страница будет зависеть только от таблицы зависимостей. А значит, всю страницу целиком можно положить в кэш, на данном условии. Сюда же относится кэш, который в нужный момент просто физически удаляется.
Заключение
Как видно, кеширование данных – это очень сложный процесс, требующий большое количество ресурсов на его разработку. Не стоит забывать, что в наше время стоимость железа может оказать дешевле, чем стоимость разработки сложных алгоритмов. Поэтому, если возникли проблемы с быстродействием сайта, то может стоит купить просто помощнее сервер – в ряде случаев это окажется дешевле.
Описанное мной – лишь основа. Тут можно много чего добавить, просто не хочется статью делать излишне большой. Если статья покажется интересной, я попробую написать продолжение.
Учебное пособие по кэшированию, часть 1
Довольно подробное и интересное изложение материала, касающегося кэша и его использования. Часть 2.
Автор, Mark Nottingham, — признанный эксперт в области HTTP-протокола и веб-кэширования. Является председателем IETF HTTPbis Working Group. Принимал участие в редактировании HTTP/1.1, part. 6: Caching. В настоящий момент участвует в разработке HTTP/2.0.
От переводчика: об опечатках и неточностях просьба сообщать в личку. Спасибо.
Веб-кэш располагается между одним или несколькими веб-серверами и клиентом, или множеством клиентов, и следит за входящими запросами, сохраняя при этом копии ответов — HTML-страниц, изображений и файлов (совокупно известных, как представления (representations); прим. переводчика — позвольте я буду употреблять слово “контент” — оно, на мой взгляд, не так режет слух), для собственных нужд. Затем, если поступает другой запрос с аналогичным url-адресом, кэш может использовать сохраненный прежде ответ, вместо повторного запроса к серверу.
Существует две основные причины, по которым используется веб-кэш:
1. Уменьшение времени ожидания — так как данные по запросу берутся из кэша (который располагается “ближе” к клиенту), требуется меньше времени для получения и отображения контента на стороне клиента. Это делает Веб более отзывчивым (прим. переводчика — “отзывчивым” в контексте быстроты реакции на запрос, а не эмоционально).
2. Снижение сетевого трафика — повторное использование контента снижает объем данных, передаваемых клиенту. Это, в свою очередь, экономит деньги, если клиент платит за трафик, и сохраняет низкими и более гибкими требования к пропускной способности канала.
Виды веб-кэшей
Кэш браузера (Browser cache)
Если вы изучите окно настроек любого современного веб-браузера (например, Internet Explorer, Safari или Mozilla), вы, вероятно, заметите параметр настройки «Кэш». Эта опция позволяет выделить область жесткого диска на вашем компьютере для хранения просмотренного ранее контента. Кэш браузера работает согласно довольно простым правилам. Он просто проверяет являются ли данные “свежими”, обычно один раз за сессию (то есть, один раз в текущем сеансе браузера).
Этот кэш особенно полезен, когда пользователь нажимает кнопку “Назад” или кликает на ссылку, чтобы увидеть страницу, которую только что просматривал. Также, если вы используете одни и те же изображения навигации на вашем сайте, они будут выбираться из браузерного кэша почти мгновенно.
Прокси-кэш (Proxy cache)
Прокси-кэш работает по аналогичному принципу, но в гораздо большем масштабе. Прокси обслуживают сотни или тысячи пользователей; большие корпорации и интернет-провайдеры часто настраивают их на своих файрволах или используют как отдельные устройства (intermediaries).
Поскольку прокси не являются частью клиента или исходного сервера, но при этом обращены в сеть, запросы должны быть к ним как-то переадресованы. Одним из способов является использование настроек браузера для того, чтобы вручную указать ему к какому прокси обращаться; другой способ — использование перехвата (interception proxy). В этом случае прокси обрабатывают веб-запросы, перенаправленные к ним сетью, так, что клиенту нет нужды настраивать их или даже знать об их существовании.
Прокси-кэши являются своего рода общей кэш-памятью (shared cache): вместо обслуживания одного человека, они работают с большим числом пользователей и поэтому очень хороши в сокращении времени ожидания и сетевого трафика. В основном, из-за того, что популярный контент запрашивается много раз.
Кэш-шлюз (Gateway Cache)
Также известные как “реверсивные прокси-кэши” (reverse proxy cache) или “суррогаты” (surrogate cache) шлюзы тоже являются посредниками, но вместо того, чтобы использоваться системными администраторами для сохранения пропускной способности канала, они (шлюзы) обычно используются веб-мастерами для того, чтобы сделать их сайты более масштабируемыми, надежными и эффективными.
Запросы могут быть перенаправлены на шлюзы рядом методов, но обычно используется балансировщик нагрузки в той или иной форме.
Сети доставки контента (content delivery networks, CDN) распространяют шлюзы по всему интернету (или некоторой его части) и отдают кэшированный контент заинтересованным веб-сайтам. Speedera и Akamai являются примерами CDN.
Это учебное пособие преимущественно сфокусировано на браузерных кэшах и прокси, но некоторая информация подходит также и тем, кому интересны шлюзы.
Почему я должен им пользоваться
Кэширование является одной из наиболее неправильно понятых технологий в интернете. Веб-мастера, в частности, боятся потерять контроль над их сайтом, потому что прокси могут “скрыть” их пользователей, сделав сложным наблюдение посещаемости.
К несчастью для них (веб-мастеров), даже если бы веб-кэша не существовало, есть слишком много переменных в интернете, чтобы гарантировать, что владельцы сайтов будут в состоянии получить точную картину того, как пользователи обращаются с сайтом. Если это является для вас большой проблемой, данное руководство научит вас как получить необходимую статистику, не делая ваш сайт “кэшененавистником”.
Другой проблемой является то, что кэш может хранить содержимое, которое устарело или просрочено.
С другой стороны, если вы ответственно подходите к проектированию вашего веб-сайта, кэш может помочь с более быстрой загрузкой и сохранением нагрузки на сервер и интернет-соединение в рамках допустимого. Разница может быть впечатляющей: загрузка сайта, не работающего с кэшем, может потребовать нескольких секунд; в то время как преимущества использования кэширования могут сделать её кажущейся мгновенной. Пользователи по достоинству оценят малое время загрузки сайта и, возможно, будут посещать его чаще.
Подумайте об этом в таком ключе: многие крупные интернет-компании тратят миллионы долларов на настройку ферм серверов по всему миру для репликации контента для того, чтобы ускорить, как только можно, доступ к данным для своих пользователей. Кэш делает то же самое для вас и он гораздо ближе к конечному пользователю.
CDN, с этой точки зрения, являются интересной разработкой, потому что, в отличие от многих прокси-кэшей, их шлюзы приведены в соответствие с интересами кэшируемого веб-сайта. Тем не менее, даже тогда, когда вы используете CDN, вы все равно должны учитывать, что там будет прокси и последующее кэширование в браузере.
Резюмируя, прокси и кэш браузера будут использоваться, нравится вам это или нет. Помните, если вы не настроите ваш сайт для корректного кэширования, он будет использовать настройки кэша по-умолчанию.
Как работает веб-кэш
Все виды кэшей обладают определенным набором правил, которые они используют, чтобы определить, когда брать контент из кэша, если он доступен. Некоторые из эти правил установлены протоколами (HTTP 1.0/HTTP 1.1), некоторые — администраторами кэша (пользователями браузера или администраторами прокси).
Вообще говоря, это самые общие правила (не волнуйтесь, если вы не понимаете детали, они будут объяснены ниже):
Свежесть (freshness) и валидация (validation) являются наиболее важными способами, с помощью которых кэш работает с контентом. Свежий контент будет доступен мгновенно из кэша; валидное же содержимое избежит повторной отправки всех пакетов, если оно не было изменено.
Кэши для «чайников»
Кэш глазами «чайника»:

Кэш – это комплексная система. Соответственно, под разными углами результат может лежать как в действительной, так и в мнимой области. Очень важно понимать разницу между тем, что мы ждем и тем, что есть на самом деле.
Давайте прокрутим полный оборот ситуаций.
Tl;dr: добавляя в архитектуру кэш важно явно осознавать, что кэш может быть средством дестабилизации системы под нагрузкой. Смотрите конец статьи.
Представим, что у нас есть доступ к базе данных, возвращающей курсы валют. Мы спрашиваем rates.example.com/?currency1=XXX¤cy2=XXX и в ответ получаем plain text значение курса. Каждые 1000 запросов к базе данных для нас, допустим, стоят 1 евроцент.
Итак, теперь мы хотим показывать на нашем сайте курс доллара к евро. Для этого нам нужно получить курс, поэтому на нашем сайте мы создаём API-обёртку для удобного использования:
И в шаблонах в нужном месте вставляем что-нибудь вроде:
Наивная имплементация делает самое простое, что можно придумать: на каждый запрос от пользователя спрашивает удалённую систему и использует ответ напрямую. Это означает, что теперь каждые 1000 просмотров пользователями нашей страницы стоят для нас на копейку больше. Казалось бы – гроши. Но вот проект растёт, у нас уже 1000 постоянных пользователей, которые каждый день заходят на сайт и просматривают по 20 страниц, а это уже 6 евро в месяц, что превращает сайт из бесплатного во вполне уже сопоставимый с платой за самые дешевые выделенные виртуальные серверы.
Вот тут на сцену выходит его величество Кэш
Зачем нам спрашивать курс для каждого пользователя на каждое обновление страницы, если для людей эта информация, в общем-то, не нужна так часто? Давайте просто ограничим частоту обновления до, например, раз в 5 секунд. Пользователи, переходя со страницы на страницу, всё равно будут видеть новое число, а мы платить будем в 1000 раз меньше.
Сказано – сделано! Добавляем несколько строчек:
Это самый главный аспект кэша: хранение последнего результата.
И вуаля! Сайт снова становится для нас почти бесплатным… До конца месяца, когда мы обнаруживаем от внешней системы счет на 4 евро. Конечно, не 6, но мы ожидали намного большей экономии!
К счастью, внешняя система позволяет посмотреть начисления, где мы видим всплески по 100 и более запросов каждые ровные 5 секунд в течение пиковой посещаемости.
Так мы познакомились со вторым важным аспектом кэша: дедупликацией запросов. Дело в том, что как только значение устарело, между проверкой наличия результата в кэше и сохранением нового значения, все пришедшие запросы фактически выполняют запрос к внешней системе одновременно.
В случае с memcache это можно реализовать, например, так:
И вот, наконец, потребление сравнялось с ожидаемым — 1 запрос в 5 секунд, расходы сократились до 2 евро в месяц.
Почему 2? Было 6 без кэширования для тысячи человек, мы же всё закэшировали, а сократилось всего в 3 раза? Да, стоило просчитать пораньше… 1 раз в 5 секунд = 12 в минуту = 72 в час = 576 за рабочий день = 17 тысяч в месяц, а ещё не все ходят по расписанию, есть странные личности заглядывающие поздней ночью… Вот и получается, в пике вместо сотни обращений одно, а в тихое время — по-прежнему запрос почти на каждое обращение проходит. Но всё равно, даже в худшем случае счёт должен быть 31×86400÷5 = 5.36 евро.
Так мы познакомились с еще одной гранью: кэш помогает, но не устраняет нагрузку.
Впрочем, в нашем случае люди приходят в проект и уходят и в какой-то момент начинают жаловаться на тормоза: страницы замирают на несколько секунд. А еще бывает под утро сайт не отвечает вообще… Просмотр консоли сайта показывает, что иногда днём запускаются дополнительные инстансы. В это же время скорость выполнения запросов падает до 5-15 секунд на запрос — из-за чего это и происходит.
Упражнение для читателя: посмотреть внимательно предыдущий код и найти причину.
Кстати, это грабли отнюдь не только кэша, это общий аспект распределённых блокировок: важно освобождать блокировки и иметь таймауты, во избежание дедлоков. Если бы мы добавляли «?» вообще без времени жизни, всё б замирало при первой же ошибке связи с внешней системой. К сожалению, memcache не предоставляет хороших способов для создания распределённых блокировок, использование полноценной БД с блокировками на уровне строк лучше, но это было просто лирическое отступление, необходимое просто потому, что на эти грабли наступили.
Итак, мы исправили проблему, вот только ничего не изменилось: всё равно изредка начинались тормоза. Что примечательно, они совпадали по времени с информационным бюллетенем от внешней системы о технических работах…
Ну-ка ну-ка… Давайте сделаем краткую передышку и пересчитаем, что мы насобирали уже сейчас, что должен уметь кэш:
Отсюда: кэш обязан уметь какое-то время хранить отрицательный результат. Наше наивное исходное предположение по сути подразумевает хранение отрицательного результата 0 секунд (но передачу этого самого отрицания всем, кто уже ждёт его). К сожалению, в случае с Memcache реализация нулевого времени ожидания весьма проблематична (оставлю как домашнее задание въедливому читателю; cовет: используйте механизм CAS; и да, в AppEngine можно использовать и Memcache и Memcached).
Мы же просто добавим сохранение отрицательного значения с 1 секундой жизни:
Казалось бы, ну теперь-то уже всё, и можно успокоиться? Как бы не так. Пока мы росли, наш любимый внешний сервис тоже рос, и в какой-то момент начал иногда тормозить и отвечать аж по секунде… И что примечательно – вместе с ним начал тормозить и наш сайт! Причем снова для всех! Но почему? Мы же всё кэшируем, в случае ошибок запоминаем ошибку и тем самым отпускаем всех ожидающих сразу, разве нет?
Что ж, мы можем вместо ожидания, добавить ветку else<> у условия вокруг memcache->add … Правда, стоит, наверное, вернуть последнее известное значение, да? Ведь мы кэшируем ровно затем, что мы согласны получить устаревшие сведения, если нет свежих; итак, еще одно требование к кэшу: пусть подтормаживает не более одного запроса.
Итак, мы снова победили: даже если тормозит внешний сервис, подтормаживает не более одной страницы… То есть как бы среднее время ответа сократилось, но пользователи всё равно немного недовольны.
Примечание: обычный PHP по умолчанию пишет сессии в файлы, блокируя параллельные запросы. Чтобы избежать этого поведения, можно передать в session_start параметр read_and_close либо принудительно закрывать через session_close сессию после совершения всех необходимых изменений, иначе тормозить будет не одна страница, а один пользователь: так как скрипт, обновляющий значение, будет блокировать открытие сессии другим запросом от того же пользователя. При исполнении на AppEngine по умолчанию включено хранение сессий в memcache, то есть без блокировок, поэтому будет проблема не так заметна.
Так вот, пользователи всё равно недовольны (ох уж эти пользователи!). Те, кто проводят времени больше всех на сайте, всё равно замечают эти короткие зависания. И их нисколько не радует осознание факта того, что так случается редко, и им просто не везёт. Придётся для данного случая сделать требование еще более жестким: никакие запросы не должны ждать ответа.
Что же мы можем сделать в такой постановке вопроса? Мы можем:
Итак, наш поставщик данных растёт, но не все его клиенты читают хабр, а потому они не используют правильного кэширования (если используют его вообще) и в какой-то момент начинают выдавать огромное количество запросов, из-за чего сервису становится плохо, и эпизодически он начинает отвечать не просто медленно, а очень медленно. До десятков секунд и более. Пользователи, конечно, быстро обнаружили, что можно нажать F5 или иначе перезагрузить страницу, и она появляется моментально – вот только страница снова начала упираться в бесплатные пределы, так как постоянно начали висеть процессы, просто ожидающие внешний ответ, но потребляющие наши ресурсы.
В числе прочих побочных эффектов участились случаи показа устаревшего курса. [Мда… в общем, представьте, что мы сейчас говорим не про наш случай, а про что-нибудь более сложное, где устаревание видно невооруженным глазом  на самом деле, даже в простом случае обязательно найдётся пользователь, который заметит такие совершенно неочевидные косяки].
на самом деле, даже в простом случае обязательно найдётся пользователь, который заметит такие совершенно неочевидные косяки].
Смотрите, что получается:
Итак, давайте подведём промежуточный итог. В бытовом понимании кэш:
Рассмотрим простейший случай:
3600. Что означает, что если отравление наступило на 5000 запросах в минуту, до тех пор, пока нагрузка не упадёт с 5000 до 3000 система нестабильна. То есть любой (даже пиковый!) всплеск трафика потенциально может вызвать длительную нестабильность системы.
Особенно прекрасно это смотрится, когда после новостной рассылки с какими-либо новыми функциями практически одновременно приходит волна пользователей. Эдакий маркетологический хабраэффект на регулярной основе.
Всё это не означает, что кэш нельзя или вредно использовать! О том, как правильно применять кэш для улучшения стабильности системы и как восстанавливаться от вышеупомянутой петли гистерезиса, мы поговорим в следующей статье, не переключайтесь.