
2.10 – Заголовочные файлы
Заголовки и их назначение
По мере того, как программы становятся больше (и используют больше файлов), становится всё более утомительным давать предварительные объявления каждой функции, которую вы хотите использовать, и которая определена в другом файле. Было бы неплохо, если бы вы могли поместить все свои предварительные объявления в одно место, а затем импортировать их, когда они вам понадобятся?
Ключевой момент
Заголовочные файлы позволяют нам размещать объявления в одном месте, а затем импортировать их туда, где они нам нужны. Это может сэкономить много времени при наборе текста в проектах из нескольких файлов.
Использование заголовочных файлов стандартной библиотеки
Рассмотрим следующую программу:
Ключевой момент
Когда дело доходит до функций и переменных, стоит помнить, что заголовочные файлы обычно содержат только объявления функций и переменных, а не их определения (в противном случае может произойти нарушение правила одного определения). std::cout объявлен в заголовке iostream, но определен как часть стандартной библиотеки C++, которая автоматически подключается к вашей программе на этапе линкера.
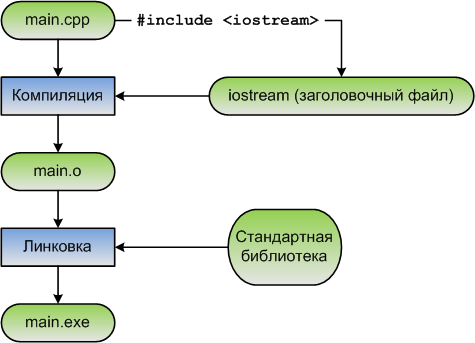 Рисунок 1 – Диаграмма процесса сборки
Рисунок 1 – Диаграмма процесса сборки
Лучшая практика
Заголовочные файлы обычно не должны содержать определений функций и переменных, чтобы не нарушать правило одного определения. Исключение сделано для символьных констант (которые мы рассмотрим в уроке «4.14 – const, constexpr и символьные константы»).
Написание собственных заголовочных файлов
(Если вы воссоздаете этот пример с нуля, не забудьте добавить add.cpp в свой проект, чтобы он компилировался).
Давайте напишем заголовочный файл, чтобы избавиться от этого бремени. Написать заголовочный файл на удивление легко, поскольку файлы заголовков состоят только из двух частей:
Добавление заголовочного файла в проект работает аналогично добавлению исходного файла (рассматривается в уроке «2.7 – Программы с несколькими файлами исходного кода»). Если вы используете IDE, выполните такие же действия и при появлении запроса выберите Файл заголовка (или C/C++ header) вместо Файла С++ (или C/C++ source). Если вы используете командную строку, просто создайте новый файл в своем любимом редакторе.
Лучшая практика
Лучшая практика
Если заголовочный файл идет в паре с файлом исходного кода (например, add.h с add.cpp ), они оба должны иметь одинаковое базовое имя ( add ).
Вот наш завершенный заголовочный файл:
Следовательно, наша программа будет правильно компилироваться и компоноваться.
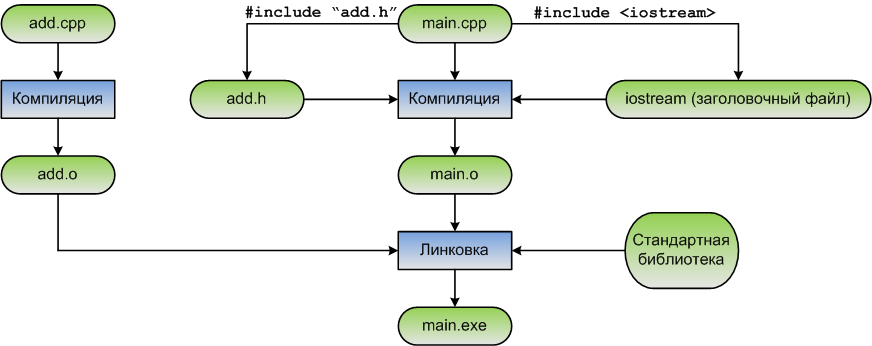 Рисунок 2 – Диаграмма процесса сборки
Рисунок 2 – Диаграмма процесса сборки
Включение заголовочного файла в соответствующий исходный файл
Позже вы увидите, что большинство исходных файлов включают свой соответствующий заголовочный файл, даже если он им не нужен. Зачем?
Включение заголовочного файла в исходный файл увеличивает прямую совместимость. Очень вероятно, что в будущем вы добавите больше функций или измените существующие таким образом, что им нужно будет знать о существовании друг друга.
Когда мы углубимся в изучение стандартной библиотеки, вы будете включать множество заголовочных файлов библиотек. Если вам потребовалось включение в заголовочном файле, оно, вероятно, понадобилось вам для объявления функции. Это означает, что вам также потребуется такое же включение в исходный файл. Это приведет к тому, что в исходном файле у вас будет копия включений заголовочного файла. Включив заголовочный файл в исходный файл, исходный файл получит доступ ко всему, к чему имел доступ заголовочный файл.
При разработке библиотеки включение заголовочного файла в исходный файл может даже помочь в раннем обнаружении ошибок.
Лучшая практика
При написании исходного файла включите в него соответствующий заголовочный файл (если он существует), даже если он вам пока не нужен.
Поиск и устранение проблем
Угловые скобки и двойные кавычки
Когда мы используем угловые скобки, мы сообщаем препроцессору, что это заголовочный файл, который мы не писали сами. Компилятор будет искать заголовок только в каталогах, указанных в каталогах включаемых файлов (include directories). Каталоги включаемых файлов настраиваются как часть вашего проекта / настроек IDE / настроек компилятора и обычно по умолчанию используются для каталогов, содержащих заголовочные файлы, которые поставляются с вашим компилятором и/или ОС. Компилятор не будет искать заголовочный файл в каталоге исходного кода вашего проекта.
Когда мы используем двойные кавычки, мы сообщаем препроцессору, что это заголовочный файл, который написали мы. Компилятор сначала будет искать этот заголовочный файл в текущем каталоге. Если он не сможет найти там подходящий заголовочный файл, он будет искать его в каталогах включаемых файлов.
Правило
Используйте двойные кавычки, чтобы включать заголовочные файлы, которые написали вы или которые, как ожидается, будут найдены в текущем каталоге. Угловые скобки используйте, чтобы включать заголовочные файлы, которые поставляются с вашим компилятором, ОС или сторонними библиотеками, которые вы установили в другом месте своей системы.
Лучшая практика
Включение заголовочных файлов из других каталогов
Другой распространенный вопрос связан с тем, как включать заголовочные файлы из других каталогов.
Хотя это будет компилироваться (при условии, что файлы существуют в этих относительных каталогах), обратная сторона этого подхода состоит в том, что он требует от вас отражения структуры каталогов в вашем коде. Если вы когда-нибудь обновите структуру каталогов, ваш код больше не будет работать.
Лучший способ – сообщить вашему компилятору или IDE, что у вас есть куча заголовочных файлов в каком-то другом месте, чтобы он смотрел туда, когда не может найти их в текущем каталоге. Обычно это можно сделать, установив путь включения (include path) или каталог поиска (search directory) в настройках проекта в IDE.
Для пользователей Visual Studio
Кликните правой кнопкой мыши на своем проекте в обозревателе решений и выберите Свойства (Properties), затем вкладку Каталоги VC++.(VC++ Directories). Здесь вы увидите строку с названием «Включаемые каталоги» (Include Directories). Добавьте каталоги, в которых компилятор должен искать дополнительные заголовочные файлы.
Для пользователей Code::Blocks
В Code:: Blocks перейдите в меню Project (Проект) и выберите Build Options (Параметры сборки), затем вкладку Search directories (Каталоги поиска). Добавьте каталоги, в которых компилятор должен искать дополнительные заголовочные файлы.
Для пользователей GCC/G++
Хороший момент в этом подходе заключается в том, что если вы когда-нибудь измените структуру каталогов, вам нужно будет изменить только одну настройку компилятора или IDE, а не каждый файл кода.
Заголовочные файлы могут включать другие заголовочные файлы
Обычно для заголовочных файлов требуется объявление или определение, которое находится в другом заголовочном файле. Из-за этого заголовочные файлы часто включают с помощью #include другие заголовочные файлы.
Когда ваш исходный файл включает с помощью #include первый заголовочный файл, вы также получите любые другие заголовочные файлы, которые были включены в первый заголовочный файл (и любые заголовочные файлы, которые были включены в предыдущие, и т.д.). Эти дополнительные заголовочные файлы иногда называют «транзитивными включениями», поскольку они включаются неявно.
Содержимое этих транзитивных включений доступно для использования в вашем файле исходного кода. Однако не следует полагаться на содержимое заголовков, которые включены транзитивно. Реализация заголовочных файлов может со временем меняться или отличаться в разных системах. Если это произойдет, ваш код может компилироваться только на определенных системах или может компилироваться сейчас, но перестать в будущем. Этого легко избежать, явно включив все заголовочные файлы, необходимые для содержимого вашего файла исходного кода.
Лучшая практика
Каждый файл должен явно включать с #include все заголовочные файлы, необходимые для компиляции. Не полагайтесь на заголовочные файлы, включенные транзитивно из других заголовков.
К сожалению, нет простого способа определить, полагается ли ваш файл кода случайно на содержимое заголовочного файла, который был включен другим заголовочным файлом.
Порядок #include заголовочных файлов
Если ваши заголовочные файлы написаны правильно и включают с #include всё, что им нужно, порядок включения не имеет значения. Однако включение заголовочных файлов в определенном порядке может помочь выявить ошибки, когда заголовочные файлы могут не включать в себя всё, что им нужно.
Лучшая практика
Упорядочьте свои включения с #include следующим образом: сначала ваши собственные пользовательские заголовки, затем заголовки сторонних библиотек, затем заголовки стандартных библиотек; заголовки в каждом разделе должны быть отсортированы в алфавитном порядке.
Таким образом, если в одном из ваших пользовательских заголовков отсутствует #include для заголовка сторонней библиотеки или стандартной библиотеки, это с большей вероятностью вызовет ошибку компиляции, чтобы вы могли ее исправить.
Рекомендации по использованию заголовочных файлов
Вот еще несколько рекомендаций по созданию и использованию заголовочных файлов.
Структура программы на языке Паскаль
Программа состоит из заголовка и блока.
Заголовок программы
В заголовке указывается имя программы и список параметров. Общий вид:
здесь n – имя программы; input – файл ввода; output – файл вывода; x, y – внешние файлы, используемые в программе.
Заголовка может и не быть или он может быть без параметров.
Блок программы состоит из шести разделов, следующих в строго определенном порядке:
Раздел действий должен присутствовать всегда, остальные разделы могут отсутствовать.
Каждый из первых четырех разделов начинается с соответствующего ключевого слова (label, const, type, var), которое записывается один раз в начале раздела и отделяется от последующей информации только пробелом, либо концом строки, либо комментарием.
Раздел меток (label)
Любой выполняемый оператор может быть снабжен меткой – целой положительной константой, содержащей не более 4-х цифр. Все метки, встречающиеся в программе, должны быть описаны в разделе label.
здесь l1, l2, l3 – метки.
Пример. label 5, 10, 100;
Метка отделяется от оператора двоеточием.
Пример. Пусть выражение a := b имеет метку 20. Тогда этот оператор выглядит так:
Раздел констант (const)
Если в программе используются константы, имеющие достаточно громоздкую запись (например, число пи с 8-ю знаками), либо сменные константы (для задания варианта программы), то такие константы обычно обозначаются какими-либо именами и описываются в разделе const, а в программе используются только имена констант. Это делает программу более наглядной и удобной при отладке и внесении изменений.
здесь a1 – имя константы, c1 – значение константы.
Пример. const pi = 3.14; c = 2.7531;
Раздел типов (type)
Если в программе вводится тип, отличный от стандартного, то этот тип описывается в разделе type:
где t1 и t2 – идентификаторы вводимых типов.
Затем тип используется при объявлении переменных.
Пример использования нестандартных типов:
Раздел описания типов имеет большое значение в программе на языке Pascal. Если в программе не использовать типы, то можно столкнуться с несовместимостью типов переменных, даже если они описаны одинаково.
Раздел переменных (var)
Пусть в программе встречаются переменные v11, v12,…; все они должны быть описаны следующим образом:
Пример. var k, i, j: integer; a, b: real;
Каждая переменная должна быть описана до ее использования в программе и отнесена к одному и только одному типу. Названия разделов (const, type, var…) указываются только один раз.
Таким образом, в разделе var вводится имя каждой переменной и указывается, к какому типу эта переменная принадлежит. Тип переменной можно задать двумя способами: указать имя типа (например, real, color и т.д.), либо описать сам тип, например: array[1..16] of char
Раздел процедур и функций
Здесь присутствуют заголовки и тела пользовательских процедур и функций.
Раздел действий (операторов)
Эта часть программы начинается с ключевого слова begin и заканчивается словом end, после которого должна стоять точка. Раздел действий есть выполняемая часть программы, состоящая из операторов.
Программирование: Разработка и отладка программ
Более подробная информация приведена в разделе Заголовок ELF в Главе 32.
| Имя | Значение | Описание |
|---|---|---|
| PF_X | 0x1 | Выполнение |
| PF_W | 0x2 | Запись |
| PF_R | 0x4 | Чтение |
| PF_MASKOS | 0x0ff00000 | Не задано |
| PF_MASKPROC | 0xf0000000 | Не задано |
Все биты в маске PF_MASKOS зарезервированы для конкретной операционной системы.
Все биты в маске PF_MASKPROC зарезервированы для конкретного процессора. Их применение описано в документации по процессору.
Если некоторый бит равен 0, то соответствующий тип доступа запрещен. Действительные права доступа зависят также от блока управления памятью и могут различаться в разных системах. Хотя допустимы все комбинации флагов, система может предоставлять более широкие права доступа, чем запрошено. Однако права на запись предоставляются только в том случае, если они явно указаны. В следующей таблице показана точная интерпретация флагов в допустимая интерпретация. В системах, совместимых с ABI, может применяться любая схема.
Права доступа к сегменту
| Флаги | Значение | Точная | Допустимая |
|---|---|---|---|
| none | 0 | Доступ запрещен | Доступ запрещен |
| PF_X | 1 | Только выполнение | Чтение, выполнение |
| PF_W | 2 | Только запись | Чтение, запись, выполнение |
| PF_W+PF_X | 3 | Запись, выполнение | Чтение, запись, выполнение |
| PF_R | 4 | Только чтение | Чтение, выполнение |
| PF_R+PF_X | 5 | Чтение, выполнение | Чтение, выполнение |
| PF_R+PF_W | 6 | Чтение, запись | Чтение, запись, выполнение |
| PF_R+PF_W+PF_X | 7 | Чтение, запись, выполнение | Чтение, запись, выполнение |
Например, обычно для текстовых сегментов указываются права на чтение и выполнение. Сегменты данных обычно имеют права доступа на чтение, запись и выполнение.
Сегмент объектного файла может содержать несколько разделов, хотя в заголовке программы это и не отражено. Количество разделов также не имеет значения при загрузке программы. Однако некоторый набор данных должен обязательно присутствовать при выполнении, динамической компоновке и других операциях над программой. На следующих рисунках показано содержимое сегмента. Порядок и наличие разделов сегмента может различаться в разных операционных системах и на разных платформах. Более подробная информация приведена в документации по процессору.
Текстовые сегменты обычно содержат инструкции и данные, предназначенные только для чтения. Обычно они содержат разделы, описанные в Главе 32. В загружаемых сегментах могут присутствовать и другие разделы; приведенные ниже примеры не призваны дать полное и всеобъемлющее описание содержимого сегмента.
Текстовый сегмент
| .text |
| .rodata |
| .hash |
| .dynsym |
| .dynstr |
| .plt |
| .rel.got |
Сегменты данных обычно содержат данные и инструкции, предназначенные для записи. Обычно они содержат следующие разделы.
Сегмент данных
| .data |
| .dynamic |
| .got |
| .bss |
type Это слово интерпретирует дескриптор. Каждая компания применяет свой набор типов; один и тот же тип может интерпретироваться по-разному. Таким образом, для правильного распознавания дескриптора программа должна учесть имя и тип примечания. В текущей версии значения типа должны быть неотрицательными. Назначение дескрипторов не определяется в ABI.
В следующем примере сегмент примечания содержит две записи.
Пример сегмента примечания
Примечание: Сегменты без имени (namesz=0) и с нулевой длиной имени (name[0]=’\0′) зарезервированы системой, но типы для них не определены. Все остальные имена должны содержать по крайней мере один символ.
Примечание: Информацию примечания указывать не обязательно. Наличие сегмента примечания не влияет на совместимость с ABI и не должно влиять на выполнение программы. В противном случае, программа считается несовместимой с ABI, и ее поведение не определено.