
Что должен знать программист на Java о числах Фибоначчи
Стоит отметить, что иногда 0 опускается, и ряд начинается с 1 1 2 3… Как правило в условиях задачи сразу уточняется, с каких первых двух чисел начинается ряд (0,1 или 1,1), поэтому дальше мы будем рассматривать решения для обоих случаев.
Получение первых n чисел Фибоначчи в Java
К нам приходит некое число n:
Мы создаём массив размера n. Первые два элемента будут равны нулю и единице, а остальные элементы получаем, проходясь по данному циклу и используя предыдущие числа из массива.
И выводим на экран:
для случая 1,1 решение фактически не отличается:
Всё, что нам нужно было изменить — это первый элемент массива arr[0]: с 0 на 1. Соответственно, первые 10 элементов будут:
Первые n чисел Фибоначчи через stream
Статический метод iterate класса Stream возвращает бесконечный упорядоченный поток, созданный применением функции к начальному массиву arr. В нашем случае в качестве функции служит задание правила составления каждого нового массива, основываясь на предыдущем. Как итог мы получим поток из массивов:
Выглядит покруче, не так ли?
 при первых элементах 1,1 этот код также будет почти таким же:
при первых элементах 1,1 этот код также будет почти таким же:
Опять же, различия — в начальном элементе: вместо <0, 1>задаём
Собственно, результаты будут такими же, как и в предыдущем примере.
Сумма чисел Фибоначчи
Получение n-ого число в ряде Фибоначчи
Для выполнения алгоритма с 0,1 необходимо задать, что при попытке получить первый элемент мы получаем 0, а второй — 1. По сути нам, как и в прошлых решениях, нужно задать первые два элемента.
реализация для 1,1 будет немного отличаться:
В этом случае нам достаточно задать только первый элемент как 1, так как второй элемент будет таким же, и реакция метода будет такой же.
При этом мы задаём реакцию метода на 0, ведь если не задать, то когда придёт 2 как аргумент, рекурсивно вызывается этот же метод, но с аргументом 0. Далее будет запускаться этот же метод, но уже с отрицательными числами и так до отрицательной бесконечности. Как итог мы получим StackOverflowError.
5 способов вычисления чисел Фибоначчи: реализация и сравнение
Введение
Программистам числа Фибоначчи должны уже поднадоесть. Примеры их вычисления используются везде. Всё от того, что эти числа предоставляют простейший пример рекурсии. А ещё они являются хорошим примером динамического программирования. Но надо ли вычислять их так в реальном проекте? Не надо. Ни рекурсия, ни динамическое программирование не являются идеальными вариантами. И не замкнутая формула, использующая числа с плавающей запятой. Сейчас я расскажу, как правильно. Но сначала пройдёмся по всем известным вариантам решения.
Код предназначен для Python 3, хотя должен идти и на Python 2.
Для начала – напомню определение:
Замкнутая формула

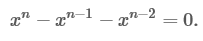
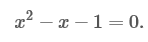
Решаем квадратное уравнение:

Откуда и растёт «золотое сечение» ϕ=(1+√5)/2. Подставив исходные значения и проделав ещё вычисления, мы получаем:

что и используем для вычисления Fn.
Хорошее:
Быстро и просто для малых n
Плохое:
Требуются операции с плавающей запятой. Для больших n потребуется большая точность.
Злое:
Использование комплексных чисел для вычисления Fn красиво с математической точки зрения, но уродливо — с компьютерной.
Рекурсия
Самое очевидное решение, которое вы уже много раз видели – скорее всего, в качестве примера того, что такое рекурсия. Повторю его ещё раз, для полноты. В Python её можно записать в одну строку:
Хорошее:
Очень простая реализация, повторяющая математическое определение
Плохое:
Экспоненциальное время выполнения. Для больших n очень медленно
Злое:
Переполнение стека
Запоминание
У решения с рекурсией есть большая проблема: пересекающиеся вычисления. Когда вызывается fib(n), то подсчитываются fib(n-1) и fib(n-2). Но когда считается fib(n-1), она снова независимо подсчитает fib(n-2) – то есть, fib(n-2) подсчитается дважды. Если продолжить рассуждения, будет видно, что fib(n-3) будет подсчитана трижды, и т.д. Слишком много пересечений.
Поэтому надо просто запоминать результаты, чтобы не подсчитывать их снова. Время и память у этого решения расходуются линейным образом. В решении я использую словарь, но можно было бы использовать и простой массив.
(В Python это можно также сделать при помощи декоратора, functools.lru_cache.)
Хорошее:
Просто превратить рекурсию в решение с запоминанием. Превращает экспоненциальное время выполнение в линейное, для чего тратит больше памяти.
Плохое:
Тратит много памяти
Злое:
Возможно переполнение стека, как и у рекурсии
Динамическое программирование
После решения с запоминанием становится понятно, что нам нужны не все предыдущие результаты, а только два последних. Кроме этого, вместо того, чтобы начинать с fib(n) и идти назад, можно начать с fib(0) и идти вперёд. У следующего кода линейное время выполнение, а использование памяти – фиксированное. На практике скорость решения будет ещё выше, поскольку тут отсутствуют рекурсивные вызовы функций и связанная с этим работа. И код выглядит проще.
Это решение часто приводится в качестве примера динамического программирования.
Хорошее:
Быстро работает для малых n, простой код
Плохое:
Всё ещё линейное время выполнения
Злое:
Да особо ничего.
Матричная алгебра
И, наконец, наименее освещаемое, но наиболее правильное решение, грамотно использующее как время, так и память. Его также можно расширить на любую гомогенную линейную последовательность. Идея в использовании матриц. Достаточно просто видеть, что

А обобщение этого говорит о том, что
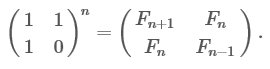
Два значения для x, полученных нами ранее, из которых одно представляло собою золотое сечение, являются собственными значениями матрицы. Поэтому, ещё одним способом вывода замкнутой формулы является использование матричного уравнения и линейной алгебры.
Так чем же полезна такая формулировка? Тем, что возведение в степень можно произвести за логарифмическое время. Это делается через возведения в квадрат. Суть в том, что
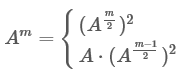
где первое выражение используется для чётных A, второе для нечётных. Осталось только организовать перемножения матриц, и всё готово. Получается следующий код. Я организовал рекурсивную реализацию pow, поскольку её проще понять. Итеративную версию смотрите тут.
Хорошее:
Фиксированный объём памяти, логарифмическое время
Плохое:
Код посложнее
Злое:
Приходится работать с матрицами, хотя они не так уж и плохи
Сравнение быстродействия
Сравнивать стоит только вариант динамического программирования и матрицы. Если сравнивать их по количеству знаков в числе n, то получится, что матричное решение линейно, а решение с динамическим программированием – экспоненциально. Практический пример – вычисление fib(10 ** 6), числа, у которого будет больше двухсот тысяч знаков.
n = 10 ** 6
Вычисляем fib_matrix: у fib(n) всего 208988 цифр, расчёт занял 0.24993 секунд.
Вычисляем fib_dynamic: у fib(n) всего 208988 цифр, расчёт занял 11.83377 секунд.
Теоретические замечания
Не напрямую касаясь приведённого выше кода, данное замечание всё-таки имеет определённый интерес. Рассмотрим следующий граф:
Подсчитаем количество путей длины n от A до B. Например, для n = 1 у нас есть один путь, 1. Для n = 2 у нас опять есть один путь, 01. Для n = 3 у нас есть два пути, 001 и 101. Довольно просто можно показать, что количество путей длины n от А до В равно в точности Fn. Записав матрицу смежности для графа, мы получим такую же матрицу, которая была описана выше. Это известный результат из теории графов, что при заданной матрице смежности А, вхождения в А n — это количество путей длины n в графе (одна из задач, упоминавшихся в фильме «Умница Уилл Хантинг»).
Почему на рёбрах стоят такие обозначения? Оказывается, что при рассмотрении бесконечной последовательности символов на бесконечной в обе стороны последовательности путей на графе, вы получите нечто под названием «подсдвиги конечного типа», представляющее собой тип системы символической динамики. Конкретно этот подсдвиг конечного типа известен, как «сдвиг золотого сечения», и задаётся набором «запрещённых слов» <11>. Иными словами, мы получим бесконечные в обе стороны двоичные последовательности и никакие пары из них не будут смежными. Топологическая энтропия этой динамической системы равна золотому сечению ϕ. Интересно, как это число периодически появляется в разных областях математики.
Почему числа Фибоначчи значимы в информатике?
числа Фибоначчи стали популярным введение в рекурсию для студентов компьютерных наук и есть сильный аргумент, что они сохраняются в природе. По этим причинам, многие из нас знакомы с ними.
Они также существуют в компьютерной науке и в других местах; в удивительно эффективных структурах данных и алгоритмах, основанных на последовательности.
есть два основных примера, которые приходят на ум:
есть ли какое-то специальное свойство этих чисел, которое дает им преимущество над другими числовыми последовательностями? Это пространственное качество? Какие еще возможные приложения они могут иметь?
кажется странно для меня, так как есть много натуральных последовательностей чисел, которые происходят в других рекурсивных задачах, но я никогда не видел каталанский кучи.
8 ответов
числа Фибоначчи имеют всевозможные действительно хорошие математические свойства, которые делают их отличными в информатике. Вот несколько:
Я уверен, что есть больше причин, чем просто это, но я уверен, что некоторые из этих причин являются основными факторами. Надеюсь, это поможет!
Наибольший Общий Делитель другое магия; см. этой слишком много магии. Но Числа Фибоначчи легко вычислить; также он имеет определенное название. Например, натуральные числа 1,2,3,4,5 имеют слишком много логики; все простые числа находятся внутри них; сумма 1..N вычислим, каждый из них может производить с другими. но никто о них не заботится:)
одна важная вещь, о которой я забыл, это Золотой Пропорции, который имеет очень важную влияние в реальной жизни (например, вам нравятся широкие мониторы 
Если у вас есть алгоритм, который можно успешно объяснить простым и кратким маннором с понятными примерами в CS и nature, какой лучший инструмент обучения может кто-то придумать?
последовательности Фибоначчи действительно встречаются повсюду в природе и жизни. Они полезны при моделировании роста популяций животных, роста растительных клеток, формы снежинок, формы растений, криптографии и, конечно, информатики. Я слышал, что это называют ДНК-паттерном природы.
Torrent как протоколы, которые используют систему узлов и супернодов, используют Фибоначчи, чтобы решить, когда нужен новый суперузел и сколько подузлов он будет управлять. Они делают управление узлами на основе спирали Фибоначчи (золотое сечение). См. фото ниже, как узлы разбиваются / объединяются (разбиваются с одного большого квадрата на меньшие и наоборот). Смотрите фото: http://smartpei.typepad.com/.a/6a00d83451db7969e20115704556bd970b-pi
некоторые явления в природе
Я не думаю, что есть окончательный ответ, но одна из возможностей заключается в том, что операция деления множества S на два раздела S1 и S2, один из которых затем делится на подразделы S11 и S12, один из которых имеет тот же размер, что и S2,-это вероятный подход ко многим алгоритмам и который иногда можно численно описать как последовательность Фибоначчи.
позвольте мне добавить еще одну структуру данных к вашей: деревья Фибоначчи. Они интересны тем, что вычисление следующей позиции в дереве может быть выполнено простым добавлением предыдущих узлов:
Это хорошо связано с обсуждением templatetypedef на AVL-деревьях (дерево AVL может в худшем случае иметь структуру Фибоначчи). Я также видел буферы, расширенные в шагах Фибоначчи, а не в степенях двух в некоторых случаях.
их вычисление как мощность [[0,1], [1,1]] матрицы можно рассматривать как самую примитивную проблему оперативных исследований (вроде как дилемма заключенного-самая примитивная проблема теории игр).
Значение «Чисел Фибоначчи» в истории параллельного программирования
С недавнего времени мне не дают покоя эти самые числа Фибоначчи! С какими бы материалами по параллельному программированию я не знакомился, я всюду встречаю эти числа. Возникает ощущение, что все параллельное программирование связано исключительно с проблемой вычислений чисел Фибоначчи.
Вычисление чисел Фибоначчи приводится во множестве печатных и электронных статей. Даже Wikipedia-статья о Parallel computing содержит пример их вычисления.
Какой пример любят приводить разработчики Cilk? Конечно, вычисление чисел Фибоначчи. Числа Фибоначчи в проекте Cilk «Parallelism for the Masses». Числа Фибоначчи в описании Cilkview. Про Фибонначи идет речь в «Cilk Reference Manual». Проще говоря, везде.
Числа Фибоначчи используются для демонстрации средства автоматического динамического распараллеливания «Т-система», разработанного в рамках суперкомпьютерной программы «СКИФ» Союзного государства России и Беларуси: » Т-Система с открытой архитектурой».
Этот список можно продолжать и продолжать. Фибомания какая-то. Собственно такое частое упоминание Фибоначчи понятно. Простой и наглядный пример, демонстрирующий принципы распараллеливания, но приводимый излишне часто. Есть, конечно, и другие примеры, демонстрирующие распараллеливание алгоритмов. Но все они чаще всего являются решением какой-то математической задачи. Это плохо, и я остановлюсь на этом моменте подробнее.
Роль чисел Фибоначчи и других аналогичных математических примеров является, как ни странно, тормозом в истории популяризации параллельного программирования. Все эти статьи с примерами параллельной сортировки и математических вычислений наводят на мысль, что параллельное программирование это что-то отдаленное, удел математиков, решающих свои специфические задачи.
Примеры с числами Фибоначчи, вместо того, чтобы продемонстрировать как легко и эффективно можно распараллелить программу, оставляют у программиста-прикладника ощущение, что к его программам это никакого отношения не имеет. Он мыслит не в математических алгоритмах, а в форме работы с GUI, в терминах «файлы» и «здесь мне нужно очистить массив». Возможно, у него есть потребность в ускорении программного комплекса. Но это никак не связывается с параллельностью, так как он не видит в своем проекте тех алгоритмов для распараллеливания, про которые пишут в статьях и книгах.
Многоядерные системы представляют разработчику множество путей повышения эффективности их программ. Но литература часто смотрит на это с крайней позиции распараллеливания и изменения счетных алгоритмов. Хотя есть множество других уровней распараллеливания. И следует не забывать рассказывать о них разработчику и приводить соответствующие примеры. Один пример из своей практики я могу привести прямо сейчас.
Одним из этапов развития нашего инструмента PVS-Studio было использование возможностей многоядерной системы. Статический анализ кода больших проектов может занимать часы, и скорость обработки является важной характеристикой таких инструментов.
Хорошо, что распараллеливание алгоритмов статического анализа явилось сложной задачей и в ходе размышлений мы поднялись на более высокий уровень абстракции. Нам незачем быстро обрабатывать один файл с исходным кодом. Он обрабатывается и так достаточно быстро. Проблема в обработке множества файлов. Так будем обрабатывать эти файлы параллельно! Просто запустим параллельно несколько анализаторов (создадим несколько процессов) и соберем выдаваемую ими информацию. Не надо OpenMP, не надо думать над синхронизациями, не нужно искать узкие места и проверять эффективность распараллеливания.
Описанное решение было реализовано и отлично работает. Такое решение кажется очевидным? Безусловно. Не буду врать, что нам понадобилось много времени, чтобы прийти к нему. Но в других задачах все может быть не так очевидно. Легко можно увлечься выискиванием неэффективных участков в программе, их распараллеливанием, затем выявлением в них ошибок. Очень легко забыть взглянуть на задачу с более высоких уровней. Рассмотрение примеров типа Фибоначчи как раз способствуют такой забывчивости. Программирование параллельных систем намного более многогранный вопрос. Но осветить эту многогранность часто незаслуженно забывают, сосредотачиваясь на определенной технологии или методике распараллеливания.
Я клоню к тому, что, прежде чем начинать перестройки алгоритмов, следует поискать методы «простой параллельности». В некоторых случай это просто, как в приведенном выше примере. Этот же подход с отдельной обработкой файлов можно применить в пакете перекодирования картинок. В других системах таких объектов для параллельной обработки может не быть, но их можно попробовать выделить в отдельные сущности. Главное не забывать взглянуть сверху.
Урок №107. Рекурсия и Числа Фибоначчи
Обновл. 28 Авг 2021 |
На этом уроке мы рассмотрим, что такое рекурсия в языке C++ и зачем её использовать, а также последовательность Фибоначчи и факториал целого числа.
Рекурсия
Рекурсивная функция (или просто «рекурсия») в языке C++ — это функция, которая вызывает сама себя. Например:
На уроке о стеке и куче в С++ мы узнали, что при каждом вызове функции, определенные данные помещаются в стек вызовов. Поскольку функция countOut() никогда ничего не возвращает (она просто снова вызывает countOut()), то данные этой функции никогда не вытягиваются из стека! Следовательно, в какой-то момент, память стека закончится и произойдет переполнение стека.
Условие завершения рекурсии
Рекурсивные вызовы функций работают точно так же, как и обычные вызовы функций. Однако, программа, приведенная выше, иллюстрирует наиболее важное отличие простых функций от рекурсивных: вы должны указать условие завершения рекурсии, в противном случае — функция будет выполняться «бесконечно» (фактически до тех пор, пока не закончится память в стеке вызовов).
Условие завершения рекурсии — это условие, которое, при его выполнении, остановит вызов рекурсивной функции самой себя. В этом условии обычно используется оператор if.
Вот пример функции, приведенной выше, но уже с условием завершения рекурсии (и еще с одним дополнительным выводом текста):
Когда мы запустим эту программу, то countOut() начнет выводить:
push 4
push 3
push 2
push 1
Если сейчас посмотреть на стек вызовов, то увидим следующее:
countOut(1)
countOut(2)
countOut(3)
countOut(4)
main()
Таким образом, результат выполнения программы, приведенной выше:
push 4
push 3
push 2
push 1
pop 1
pop 2
pop 3
pop 4
Стоит отметить, что push выводится в порядке убывания, а pop — в порядке возрастания. Дело в том, что push выводится до вызова рекурсивной функции, а pop выполняется (выводится) после вызова рекурсивной функции, когда все экземпляры countOut() вытягиваются из стека (это происходит в порядке, обратном тому, в котором эти экземпляры были введены в стек).
Теперь, когда мы обсудили основной механизм вызова рекурсивных функций, давайте взглянем на несколько другой тип рекурсии, который более распространен:
Рассмотреть рекурсию с первого взгляда на код не так уж и легко. Лучшим вариантом будет посмотреть, что произойдет при вызове рекурсивной функции с определенным значением. Например, посмотрим, что произойдет при вызове вышеприведенной функции с value = 4 :
sumCount(4). 4 > 1, поэтому возвращается sumCount(3) + 4
sumCount(3). 3 > 1, поэтому возвращается sumCount(2) + 3
sumCount(2). 2 > 1, поэтому возвращается sumCount(1) + 2
sumCount(1). 1 = 1, поэтому возвращается 1. Это условие завершения рекурсии
Теперь посмотрим на стек вызовов:
sumCount(1) возвращает 1
sumCount(2) возвращает sumCount(1) + 2, т.е. 1 + 2 = 3
sumCount(3) возвращает sumCount(2) + 3, т.е. 3 + 3 = 6
sumCount(4) возвращает sumCount(3) + 4, т.е. 6 + 4 = 10
На этом этапе уже легче увидеть, что мы просто добавляем числа между 1 и значением, которое предоставил caller. На практике рекомендуется указывать комментарии возле рекурсивных функций, дабы облегчить жизнь не только себе, но, возможно, и другим людям, которые будут смотреть ваш код.
Рекурсивные алгоритмы
Числа Фибоначчи
Одним из наиболее известных математических рекурсивных алгоритмов является последовательность Фибоначчи. Последовательность Фибоначчи можно увидеть даже в природе: ветвление деревьев, спираль ракушек, плоды ананаса, разворачивающийся папоротник и т.д.
Спираль Фибоначчи выглядит следующим образом:

Каждое из чисел Фибоначчи — это длина горизонтальной стороны квадрата, в которой находится данное число. Математически числа Фибоначчи определяются следующим образом:
F(n) = 0, если n = 0
1, если n = 1
f(n-1) + f(n-2), если n > 1
Следовательно, довольно просто написать рекурсивную функцию для вычисления n-го числа Фибоначчи: