
Контейнеры стандартной библиотеки C++
Стандартная библиотека предоставляет различные типобезопасные контейнеры для хранения коллекций связанных объектов. Контейнеры являются шаблонами классов. При объявлении переменной контейнера указывается тип элементов, которые будут храниться в контейнере. Контейнеры могут создаваться с использованием списков инициализаторов. Они имеют функции элементов для добавления и удаления элементов и выполнения других операций.
Итерация элементов в контейнере и доступ к отдельным элементам осуществляются с помощью итераторов. Итераторы можно использовать явно, используя функции и операторы их членов и глобальные функции. Вы можете также использовать их неявно, например с помощью цикла range-for. Итераторы для всех контейнеров стандартной библиотеки C++ имеют общий интерфейс, но каждый контейнер определяет собственные специализированные итераторы.
Контейнеры можно разделить на три категории: последовательные контейнеры, ассоциативные контейнеры и контейнеры-адаптеры.
Последовательные контейнеры
Последовательные контейнеры поддерживают указанный пользователем порядок вставляемых элементов.
Контейнер vector ведет себя как массив, но может автоматически увеличиваться по мере необходимости. Он поддерживает прямой доступ и связанное хранение и имеет очень гибкую длину. По этим и многим другим причинам контейнер vector является наиболее предпочтительным последовательным контейнером для большинства областей применения. Если вы сомневаетесь в выборе вида последовательного контейнера, начните с использования вектора. Дополнительные сведения см. в разделе vector класс.
list Контейнер — это двунаправленный связанный список, который обеспечивает двунаправленный доступ, быструю вставку и быстрое удаление в любом месте в контейнере, но не может получить случайный доступ к элементу в контейнере. Дополнительные сведения см. в разделе list класс.
Контейнер forward_list — однонаправленный список. Это версия контейнера list только с доступом в прямом направлении. Дополнительные сведения см. в разделе forward_list класс.
Ассоциативные контейнеры
В ассоциативных контейнерах элементы вставляются в предварительно определенном порядке — например, с сортировкой по возрастанию. Также доступны неупорядоченные ассоциативные контейнеры. Ассоциативные контейнеры можно объединить в два подмножества: сопоставления (set) и наборы (map).
Упорядоченные контейнеры map и set поддерживают двунаправленные итераторы, а их неупорядоченный аналоги — итераторы с перебором в прямом направлении. Дополнительные сведения см. в разделе Итераторы.
Разнородный поиск в ассоциативных контейнерах (C++ 14)
Разнородный поиск включается дополнительно, когда указывается средство сравнения «ромбовидный функтор» std::less<> или std::greater<> при объявлении переменной контейнера, как показано ниже:
Если используется средство сравнения, заданное по умолчанию, контейнер ведет себя точно так же, как в C++ 11 и более ранних версиях.
Следующие функции элементов в Map, multimap, Set и Мультинабор были перегружены для поддержки разнородного уточняющего запроса:
Контейнеры-адаптеры
Контейнер-адаптер — это разновидность последовательного или ассоциативного контейнера, который ограничивает интерфейс для простоты и ясности. Адаптеры контейнеров не поддерживают итераторы.
Контейнер queue соответствует семантике FIFO (первым поступил — первым обслужен). Первый элемент, который отправляется, то есть вставляется, в очередь, должен быть первым элементом, извлекаемым из очереди. Дополнительные сведения см. в разделе queue класс.
Контейнер priority_queue упорядочен таким образом, что первым в очереди всегда оказывается элемент с наибольшим значением. Дополнительные сведения см. в разделе priority_queue класс.
Контейнер stack соответствует семантике LIFO (последним поступил — первым обслужен). Последний элемент, отправленный в стек, становится первым извлекаемым элементом. Дополнительные сведения см. в разделе stack класс.
Так как адаптеры контейнеров не поддерживают итераторы, их нельзя использовать с алгоритмами стандартной библиотеки C++. Дополнительные сведения см. в разделе Алгоритмы.
Требования для элементов контейнеров
Деструктору не разрешено создавать исключение.
Для некоторых операций в контейнерах может также потребоваться открытый конструктор по умолчанию и открытый оператор равенства. Например, неупорядоченным ассоциативным контейнерам требуется поддержка сравнения на равенство и хэширования.
Доступ к элементам контейнера
Доступ к элементам контейнеров осуществляется с помощью итераторов. Дополнительные сведения см. в разделе Итераторы.
Для перебора коллекций стандартной библиотеки C++ можно также использовать циклы for на основе диапазонов.
Сравнение контейнеров
Сравнение контейнеров разного типа (C++ 14)
В C++ 14 и более поздних версиях можно сравнивать несхожие контейнеры и (или) типы элементов, используя одну std::equal из std::mismatch std::is_permutation перегрузок функций, или, принимающих два полных диапазона. Эти перегрузки позволяют сравнивать контейнеры разной длины. Эти перегрузки намного менее подвержены ошибкам пользователя и оптимизированы для возврата значения false в одно и то же время, когда сравниваются контейнеры разной длины. Поэтому рекомендуется использовать эти перегрузки, если у вас нет четкой причины отсутствия или вы используете std::list контейнер, который не имеет преимущества при оптимизации с двойным диапазоном.
Контейнеры это просто. Контейнерные технологии для начинающих

Nov 29, 2018 · 7 min read

Вступление
Будь вы студент или уже состоявшийся разработчик, вы наверняка слышали о «контейнерах». Более того, вероятно вы слышали, что контейнеры — это «лёгкие» виртуальные машины. Но что на самом деле это значит, как именно работают контейнеры и почему они важны?
Эта статья посвящена контейнерам, их применению и великолепной идеи, которая за этим стоит. Для этой статьи никакой предварительной подготовки не требуется, кроме базового понимания компьютерных технологий.
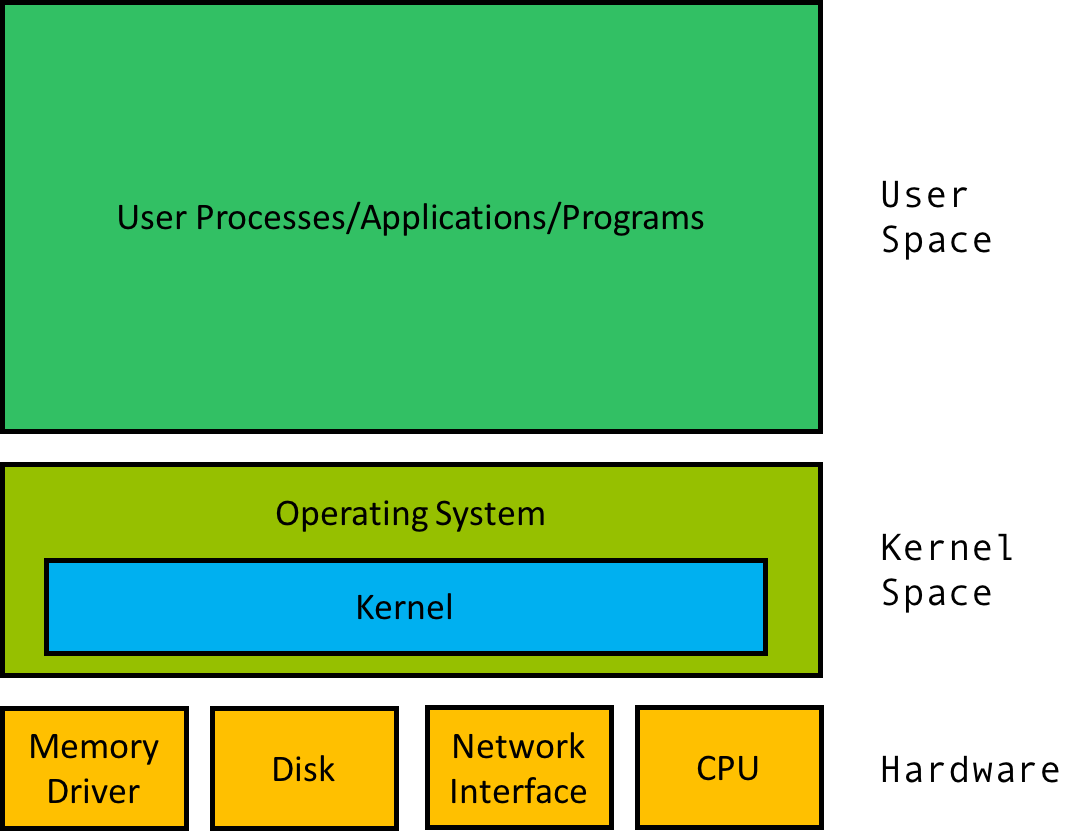
Ядро и ОС
В основе любого компьютера лежит «железо»: процессор, накопитель (hdd, ssd), память, сетевая карта и т.д.
В ОС есть часть прог р аммного кода, которая служит мостом между софтом и железом, он называется — kernel (ядро). Ядро координирует запуск процессов (программ), управляет устройствами (чтение и запись адресов на диск и в память) и многое другое.
Остальная часть ОС служит для загрузки и управления пользовательским пространством, где запускаются и постоянно взаимодействуют с ядром процессы пользователя.
Виртуальная машина
Допустим, что ваш компьютер работает под MacOS, а вы хотите запустить приложение написанное для Ubuntu. Наиболее вероятным решением в этом случае будет загрузка виртуальной машины на MacOS, для запуска Ubuntu и вашей программы.
Виртуальная машина подразумевает виртуализацию ядра и железа, для запуска гостевой ОС. Hypervisor — это ПО для виртуализации железа, в том числе: виртуального накопителя, сетевого интерфейса, ЦП и другого. Виртуальная машина также имеет своё ядро, которое общается с этим виртуальным железом.
H ypervisor может быть реализован как ПО, так и в виде реального железа, установленного непосредственно в Host машину. В любом случае hypervisor ресурсоёмкое решение, требующее виртуализации нескольких, если не всех, “железных” устройств и ядра.
Когда требуется несколько изолированных групп на одной машине, запускать виртуальную машину для каждой группы — слишком расточительный подход, требующий много ресурсов.
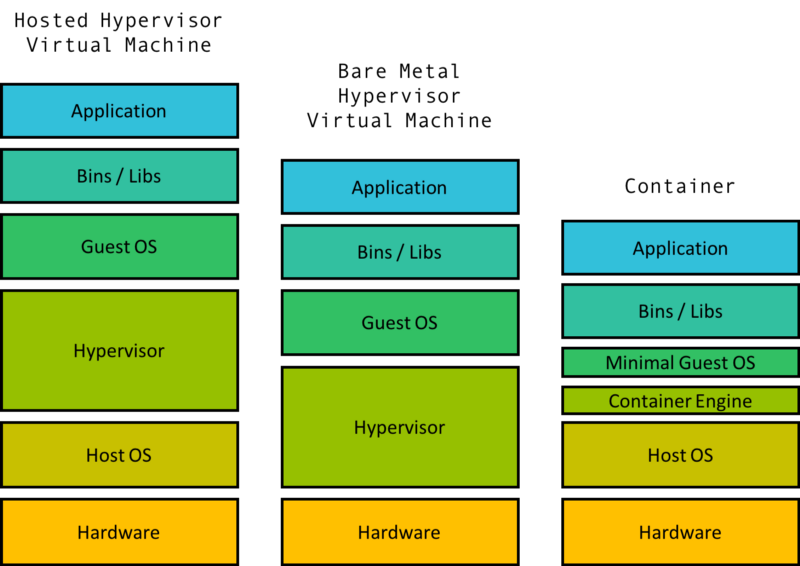
Для виртуальной машины необходима аппаратная виртуализация, для изоляции на уровне железа, тогда как контейнерам требуется изоляция в пределах операционной системы. С увеличением числа изолированных пространств, разница в расходах ресурсов становится очевидной. Обычный ноутбук может работать с десятками контейнеров, но едва справляется даже с одной виртуальной машиной.
cgroups
Cgroups — это аббревиатура от Linux “control groups”. Это функция ядра Linux, которая изолирует и контролирует использование ресурсов для пользовательских процессов. Её создали инженеры из Google в 2006 году.
Эти процессы могут быть помещены в пространства имён, то есть группы процессов, у которых общие ограниченные ресурсы. В компьютере может быть несколько пространств имён, у каждого из которых есть свойства ресурса, закреплённые ядром.
Для каждого пространства имён можно распределять ресурсы, так, чтобы ограничить использование CPU, RAM и т.д., для каждого набора процессов. Например, для фонового приложения агрегации логов, вероятно, потребуется ограничить ресурсы, чтобы не перегружать сам сервер, для которого ведётся лог.
Cgroups была в конечном итоге переработана в Linux, для добавления функции namespace isolation (изоляция пространства имён). Идея изоляции пространства имён не нова. В Linux уже было много видов namespace isolation. Например, изоляция процессов, которая разделяет каждый процесс и предотвращает совместное использование памяти.
Cgroup обеспечивает более высокий уровень изоляции. Благодаря cgroup, процессы из одного пространства имён независимы от процессов из других пространств. Ниже описаны важные функции изоляции пространств имён. Это и есть основа изоляции в контейнерах.
Проще говоря, каждое пространство имён для внутренних процессов, выглядит так как будто это отдельная машина.
Linux контейнеры
Linux cgroups стала основой для технологии linux containers (LXC). На самом деле LXC была первой реализацией того, что сегодня называют контейнеры. Для создания виртуальной среды, с разделением процессов и сетевого пространства, взяли за основу преимущества cgroups и изоляцию пространств имён.
Сама идея контейнеров вышла из LXC. Можно сказать, что благодаря LXC стало возможным создавать независимые и изолированные пространства пользователей. Более того, ранние версии Docker ставились поверх LXC.
Docker
Docker — это наиболее распространённая технология контейнеров, именно Docker имеют в виду, когда говорят о контейнерах вообще. Тем не менее, существуют и другие open source технологии контейнеров, например rkt от CoreOS. Крупные компании создают собственные движки, например lmctfy от Google. Docker стал стандартом в этой области. Он до сих пор строится на основе cgroups и пространстве имён, которые обеспечивает ядро Linux, а теперь и Windows.

В Docker контейнер состоит из слоёв образов, при этом бинарные файлы упакованы в один пакет. В базовом образе содержится операционная система, она может отличаться от ОС хоста.
ОС контейнера существует в виде образа. Она не является полноценной ОС, как система хоста. В образе есть только файловая система и бинарные файлы, а в полноценной ОС, помимо этого, есть ещё и ядро.
Поверх базового образа лежит ещё несколько образов, каждый из них является частью контейнера. Например, следующим после базового, может быть образ, который содержит apt-get зависимости. Следующим может быть образ с бинарными файлами приложения и т.д.
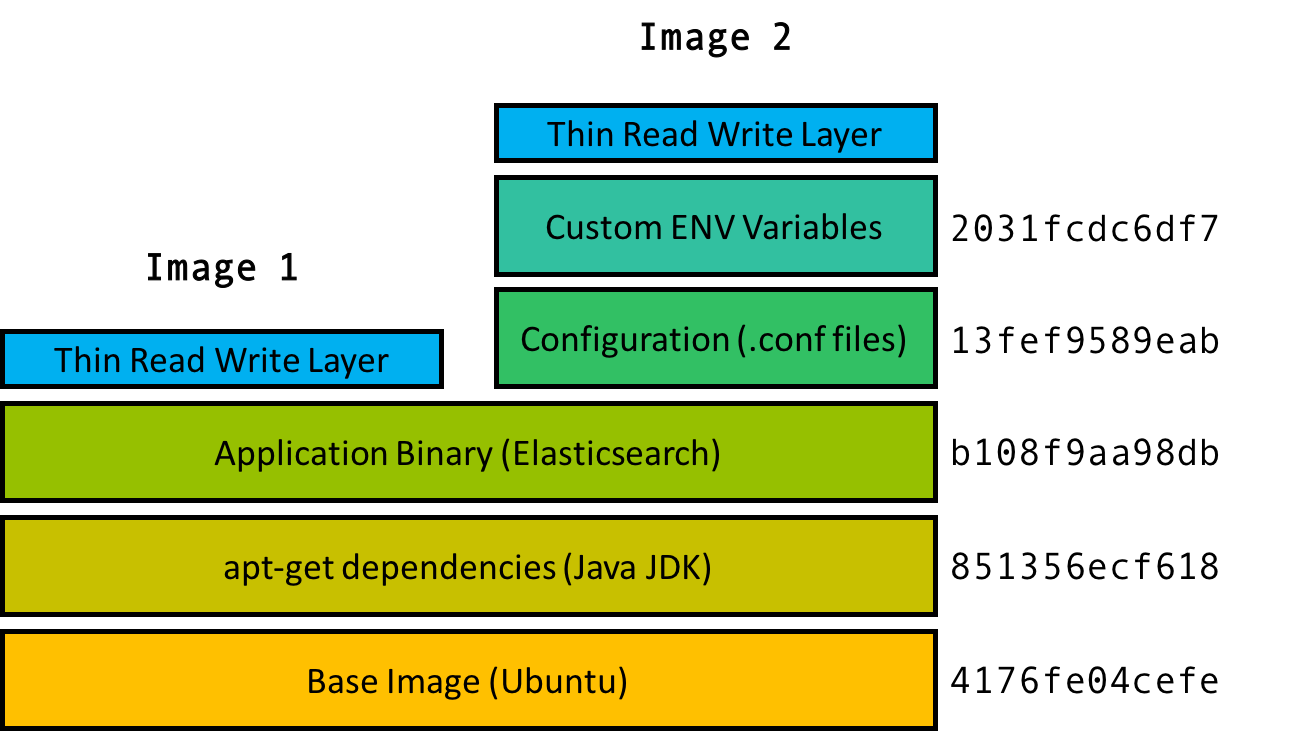
Каждый образ идентифицируется хэшем, и является одним из множества возможных слоёв образов, из которых состоит контейнер. Но идентификатором самого контейнера является только верхний образ, который содержит ссылки на родительские образы. На картинке выше видно, что два образа верхнего уровня ( Image 1 и Image 2), разделяют три общих нижних слоя. В Image 2 есть два дополнительных слоя конфигурации, но родительские образы те же, что и у Image 1.
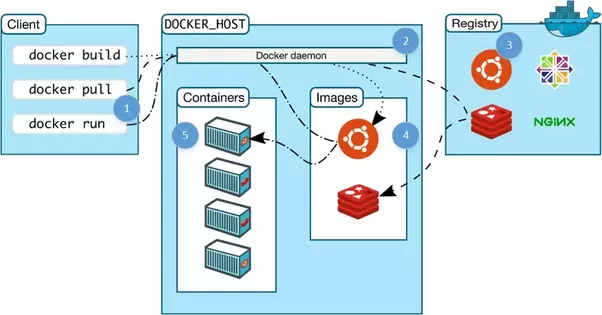
При загрузке контейнера происходит следующее: образ и его родительские образы подгружаются из репозитория, создаётся cgroup и пространство имён, далее образ используется для создания виртуального окружения. Файлы из контейнера, в том числе и бинарные, в образе представлены как будто это единственные файлы на всей машине. После этого, запускается основной процесс контейнера. Теперь можно считать контейнер работающим.
В Docker есть ещё очень классные фичи, например копирование во время записи, тома (общие файловые системы между контейнерами), docker daemon (управление контейнерами), репозитории с контролем версий (например Github для контейнеров), и много чего ещё.
Почему именно контейнеры
Помимо изоляции процессов, у контейнеров есть много преимуществ.
Контейнер — это самоизолированная единица, которая запустится на любой поддерживаемой платформе, и каждый раз это будет всё тот же контейнер. Независимо от операционной системы хоста, вы сможете запустить ту систему, которая находится в контейнере. Поэтому можете быть уверены, что контейнер, который вы создаёте на своём ноутбуке, будет работать так же на корпоративном сервере.
Кроме того, контейнер используют как способ унификации рабочего процесса. Существует даже парадигма — один контейнер — одна задача. Контейнер для запуска одного веб-сервера, одного сегмента базы данных и т. д. Чтобы масштабировать приложение, достаточно масштабировать количество контейнеров.
Эта парадигма подразумевает, что у каждого контейнера своя фиксированная конфигурация ресурсов (CPU, RAM, количество потоков и т.д.), поэтому достаточно масштабировать количество контейнеров, а не индивидуальные ресурсы. Это обеспечивает более простую абстракцию для масштабирования приложений.
Кроме того, контейнеры — это отличный инструмент для реализации архитектуры микросервисов. В таком случае, каждый микросервис это комплекс взаимодействующих контейнеров. Например, микросервис Redis, можно реализовать с одним мастер контейнером и несколькими slave контейнерами.
В такой (микро)сервис-ориентированной архитектуре, есть очень важные особенности, которые позволяют команде инженеров с лёгкостью создать и развернуть приложение.
Администрирование
Со времён Linux контейнеров, для того чтобы развернуть большие приложения, используют большое количество виртуальных машин, где каждый процесс выполняется в собственном контейнере. Такой подход требует эффективно развёртывать десятки, а то и тысячи контейнеров на сотнях виртуальных машин, управлять их сетями, файловыми системами и ресурсами. Docker позволяет делать это чуточку проще. Он предоставляет абстракции для определения сетевых ресурсов, томов для файловой системы, конфигурации ресурсов и т.д.
Для этого инструмента требуется:
Эти задачи относятся к администрированию распределённой системы, построенной на основе контейнеров (временно или постоянно изменяющихся). Для решения этих задач, уже созданы действительно классные системы.
Снова про STL: контейнеры
В предыдущей заметке речь шла о массивах как прототипе и прародителе контейнеров. Теперь дошла очередь до собственно контейнерных классов и поддерживающих их библиотек.
Под термином библиотека стандартных шаблонов (STL, Standard Template Library) понимают набор интерфейсов и компонентов, первоначально разработанных Александром Степановым, Менг Ли и другими сотрудниками AT&T Bell Laboratories и Hewlett-Packard Research Laboratories в начале 90-х годов (хотя и позже ещё весьма многие приложили руку к тому, что стало на сегодня стандартным компонентом C++). Далее библиотека STL перешла в собственность компании SGI, а также была включена как компонент в набор библиотек Boost. И наконец библиотека STL вошла в стандарты C++ 1998 и 2003 годов (ISO/IEC 14882:1998 и ISO/IEC 14882:2003) и с тех пор считается одной из составных частей стандартной библиотек C++.
Стандарт не называет эту часть библиотеки STL, но эту хронологию хорошо бы учитывать, разбираясь с какой версией компилятора, языка и литературы вы имеете дело — в процессе сокращения HP STL до размеров, подходящих для стандартизации, часть алгоритмов и функторов выпали из состава библиотеки, а кое-что, со временем, и добавляется (например, расширение набора переопределенных прототипов некоторых методов контейнеров). По тексту будет использоваться традиционное название STL только чтобы было ясно какую часть стандартной библиотеки C++ мы имеем в виду.
Первоначальной целью STL (это хорошо видно из хронологии комментариев в заголовочных файлах) было создание боле гибкой модели регулярных контейнеров по сравнению с массивами и обобщение на них некоторых широко используемых алгоритмов (таких как поиск, сортировка и некоторых других). Но затея оказалась плодотворнее первоначальных намерений, и была существенно расширена. STL вводит ряд понятий и структур данных, которые почти во всех случаях позволяют сильно упростить программный код. Вводятся следующие категории понятий:
Центральным понятием STL, вокруг которого крутится всё остальное, это контейнер (ещё используют термин коллекция). Контейнер — это набор некоторого количества обязательно однотипных элементов, упакованных в контейнер определённым образом. Простейшим прототипом контейнера в классическом языке C++ является массив. Тот способ, которым элементы упаковываются в контейнер и определяет тип контейнера и особенности работы с элементами в таком контейнере. STL вводит целый ряд разнообразных типов контейнеров, основные из них:
элементов типа float. Далее мы видим такие методы класса vector как max_size() — максимально возможная длина векторов вообще (константа реализации), size() — текущий размер (число элементов) вектора, capacity() — текущая ёмкость вектора, максимальное число элементов, которое может быть помещено в вектор в текущем его размещении. Выполнение этого фрагмента даст что-то примерно следующее (детали могут различаться в зависимости от реализации):
Здесь видно достаточно интересное поведение вектора (в этом и его смысл): как только при добавлении очередного элемента вектора его ёмкости становится недостаточно для ещё одного элемента, делается новое размещение вектора, резервируя для него удвоенную ёмкость (с запасом, чтобы следующее же добавление нового элемента не потребовало тут же нового переразмещения).
Примечание: Показанное выше удвоение ёмкости вектора при переразмещении — это характерное поведение для реализации библиотек компилятора GCC. Но точный алгоритм резервирования ёмкости под будущие элементы стандарт оставляет на волю реализатора, поэтому на него нельзя рассчитывать, и описан он здесь только для качественного понимания картины (реализации Visual Studio ведут себя по-другому, резервируя только небольшой избыток… это вы изучите сами).
Отметим на дальнейшее, пока без комментариев, то важное обстоятельство, что операции помещения элементов в контейнер выполняет копирование элемента, что влечёт за собой а).требование наличия копирующего конструктора для типа элементов и б).для структурных элементов это может привести к заметным затратам производительности.
Таким образом мы получили эквивалент массива C++, размер которого (size()) динамически меняется в произвольных пределах от нескольких единиц до миллионов элементов. Обратим внимание (это очень важно), что увеличение размера вектора достигается ни в коем случае не индексацией за пределы его текущего размера, а «заталкиванием» (метод push_back()) нового элемента в конец вектора (симметрично, метод pop_back() выталкивает последний элемент из массива и уменьшает его size()). Другой способ изменить размер вектора — это сразу вызвать методы resize() под нужный размер. Именно потому, что размер вектора, в отличие от массива, может динамически меняться, для вектора предусмотрено 2 разных способа индексации: как операция [ i ] и как метод-функция at( i ). Они различаются: метод at() проверяет текущий размер вектора size(), и при индексации за его границу возбуждает исключение. Напротив, операция индексации не проверяет границу, что небезопасно, но зато это быстрее. Метод at() позволяет нам контролировать выход за границы вектора и либо квалифицировать это как логическую ошибку, либо корректировать текущий размер контейнера под потребность, как в вот таком фрагменте (здесь попыток доступа вдвое больше, чем реально выполненных операций):
Стандарт C++11 привносит дополнительные выразительные средства, такие, например, как списки инициализации и выводимость типов, которые намного упрощают работу с контейнерами (и даже делают ненужными старые привычные приёмы записи). Вот как может описываться матрица, когда одновременно описываются её а). конфигурация (квадратная, хотя может быть прямоугольная и даже треугольная), b). размерность (3х3) и c). инициализирующие значения:
А заодно, здесь же показана работа с векторами (транспонирование квадратной матрицы и вывод в выходной поток) как с псевдо-массивами (пользуясь только индексированием), чем вектора, по существу, и являются (в частности, показано как тип элемента вектор определяется на основании выводимого типа по стандарту C++11):
Примечание: В рамках того, что мы уже знаем о векторах, возникает иногда вопрос: а как строго должен определяться тип возвращаемого size() результата (чтобы избежать зависимости от платформы) и, соответственно, любых переменных циклов, оперирующих с размером вектора? Временами от блюстителей чистоты синтаксиса следует ответ, что это должен быть size_t, и этот ответ — неверный (тем более, что для многих платформ size_t и определяется как unsigned int). Если вы захотите записать абсолютно строгого определение типа size() вектора, то строку в примере выше следует записать вот так:
Или, полагаясь на выводимость типов C++11, вот так:
Отметив здесь этот тонкий нюанс (приняв к сведению), мы не станем его применять далее, во избежания лишней громоздкости примеров, а будем использовать для размерностей просто unsigned.
Недостающее введение в контейнеризацию
Эта статья помогла мне немного углубится в устройство и принцип работы контейнеров. Поэтому решил ее перевести. «Экосистема контейнеров иногда может сбивать с толку, этот пост может помочь вам понять некоторые запутанные концепции Docker и контейнеров. Мы также увидим, как развивалась экосистема контейнеров». Статья 2019 года.

Все началось с того, что Chroot Jail и системный вызов Chroot были введены во время разработки версии 7 Unix в 1979 году. Chroot jail предназначен для «Change Root» и считается одной из первых технологий контейнеризации. Он позволяет изолировать процесс и его дочерние элементы от остальной части операционной системы. Единственная проблема с этой изоляцией заключается в том, что корневой процесс может легко выйти из chroot. В нем никогда не задумывались механизмы безопасности. FreeBSD Jail была представлена в ОС FreeBSD в 2000 году и была предназначена для обеспечения большей безопасности простой изоляции файлов Chroot. В отличие от Chroot, реализация FreeBSD также изолирует процессы и их действия от Файловой системы.
Chroot Jail. Источник: https://linuxhill.wordpress.com/2014/08/09/014-setting-up-a-chroot-jail-in-crunchbang-11debian-wheezy
Когда в ядро Linux были добавлены возможности виртуализации на уровне операционной системы, в 2001 году был представлен Linux VServer, который использовал chroot-подобный механизм в сочетании с «security contexts (контекстами безопасности)», так и виртуализацию на уровне операционной системы. Он более продвинутый, чем простой chroot, и позволяет запускать несколько дистрибутивов Linux на одном VPS.
Подобно контейнерам Solaris, первая версия OpenVZ была представлена в 2005 году. OpenVZ, как и Linux-VServer, использует виртуализацию на уровне ОС и был принят многими хостинговыми компаниями для изоляции и продажи VPS. Виртуализация на уровне ОС имеет некоторые ограничения, поскольку контейнеры и хост используют одну и ту же архитектуру и версию ядра, недостаток возникает в ситуациях, когда гостям требуются версии ядра, отличные от версии на хосте. Linux-VServer и OpenVZ требуют патча ядра, чтобы добавить некоторые механизмы управления, используемые для создания изолированного контейнера. Патчи OpenVZ не были интегрированы в ядро.
В 2013 году была представлена первая версия Docker. Он выполняет виртуализацию на уровне операционной системы, как и контейнеры OpenVZ и Solaris.
В 2014 году Google представил LMCTFY, версию стека контейнеров Google с открытым исходным кодом, которая предоставляет контейнеры для приложений Linux. Инженеры Google сотрудничают с Docker над libcontainer и переносят основные концепции и абстракции в libcontainer. Проект активно не развивается, и в будущем ядро этого проекта, вероятно, будет заменено libcontainer.
LMCTFY запускает приложения в изолированных средах на том же ядре и без патчей, поскольку он использует CGroups, namespases и другие функции ядра Linux.
 Фото Павла Червиньского для Unsplash
Фото Павла Червиньского для Unsplash
В декабре 2014 года CoreOS выпустила и начала поддерживать rkt (первоначально выпущенную как Rocket) в качестве альтернативы Docker.

Jails, VPS, Zones, контейнеры и виртуальные машины
Изоляция и управление ресурсами являются общими целями использования Jail, Zone, VPS, виртуальных машин и контейнеров, но каждая технология использует разные способы достижения этого, имеет свои ограничения и свои преимущества.
До сих пор мы вкратце видели, как работает Jail, и представили, как Linux-VServer позволяет запускать изолированные пользовательские пространства, в которых программы запускаются непосредственно в ядре операционной системы хоста, но имеют доступ к ограниченному подмножеству его ресурсов.
Linux-VServer позволяет запускать VPS, и для его использования необходимо пропатчить ядро хоста.
Контейнеры Solaris называются Zones.
Виртуальные машины могут быть «System Virtual Machines (системными виртуальными машинами)» или «Process Virtual Machines (процессными виртуальными машинами)». В повседневном использовании под словом «виртуальные машины» мы обычно имеем в виду «системные виртуальные машины», которые представляют собой эмуляцию оборудования хоста для эмуляции всей операционной системы. Однако «Process Virtual Machines», иногда называемый «Application Virtual Machine (Виртуальной машиной приложения)», используется для имитации среды программирования для выполнения отдельного процесса: примером является виртуальная машина Java.
Виртуализация на уровне ОС также называется контейнеризацией. Такие технологии, как Linux-VServer и OpenVZ, могут запускать несколько операционных систем, используя одну и ту же архитектуру и версию ядра.
Совместное использование одной и той же архитектуры и ядра имеет некоторые ограничения и недостатки в ситуациях, когда гостям требуются версии ядра, отличные от версии хоста.
Источник: https://fntlnz.wtf/post/why-containers
Системные контейнеры (например, LXC) предлагают среду, максимально приближенную к той, которую вы получаете от виртуальной машины, но без накладных расходов, связанных с запуском отдельного ядра и имитацией всего оборудования.
VM vs Container. Источник: Docker Blog
Контейнеры ОС vs контейнеры приложений
Виртуализация на уровне ОС помогает нам в создании контейнеров. Такие технологии, как LXC и Docker, используют этот тип изоляции.
Здесь у нас есть два типа контейнеров:
Контейнеры ОС, в которые упакована операционная система со всем стеком приложений (пример LEMP).
Контейнеры приложений, которые обычно запускают один процесс для каждого контейнера.
В случае с контейнерами приложений у нас будет 3 контейнера для создания стека LEMP:
сервер PHP (или PHP FPM).
Докер: контейнер или платформа?
Коротко: и то и другое
Подробный ответ:
Когда Docker начал использовать LXC в качестве среды выполнения контейнера, идея заключалась в том, чтобы создать API для управления средой выполнения контейнера, изолировать отдельные процессы, выполняющие приложения, и контролировать жизненный цикл контейнера и ресурсы, которые он использует. В начале 2013 года проект Docker должен был создать «стандартный контейнер», как мы можем видеть в этом манифесте.
Манифест стандартного контейнера был удален.
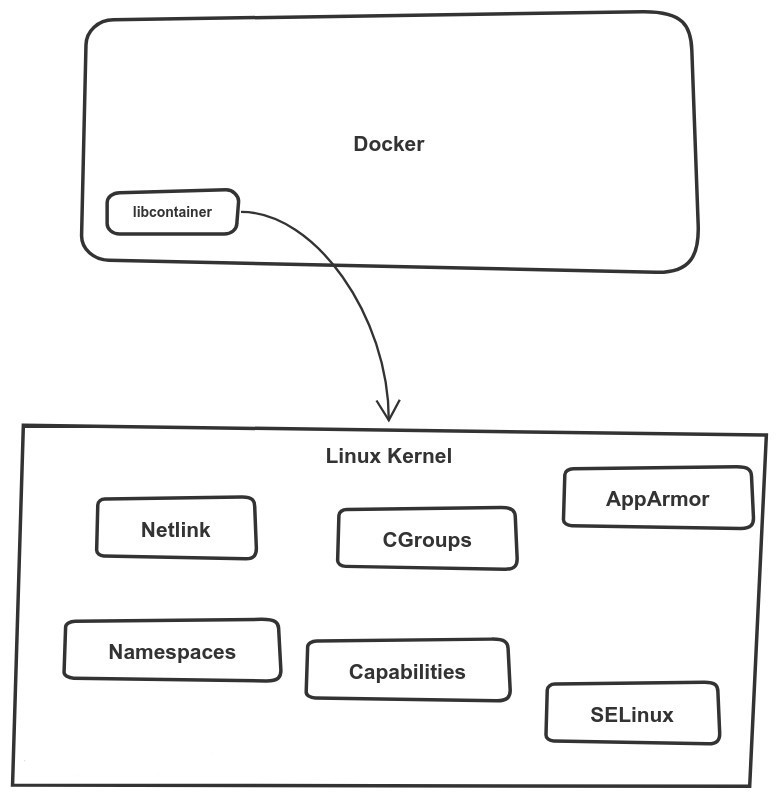
Давайте создадим контейнер с использованием СGroups и Namespaces
В этом примере я использую Ubuntu, но это должно работать для большинства дистрибутивов. Начните с установки CGroup Tools and утилиты stress, поскольку мы собираемся выполнить некоторые стресс-тесты.
Эта команда создаст новый контекст исполнения:
Команда «unshare» разъединяет части контекста исполнения процесса
Следующим шагом будет определение лимита памяти и его активация:
Теперь давайте запустим stress для изолированного namespace, которое мы создали с ограничениями памяти.
Мы можем заметить, что выполнение не удалось, значит ограничение памяти работает. Если мы сделаем то же самое на хост-машине, тест завершится без ошибки, если у вас действительно достаточно свободной памяти:
Выполнение этих шагов поможет понять, как средства Linux, такие как CGroups и другие функции управления ресурсами, могут создавать изолированные среды в системах Linux и управлять ими.
Интерфейс libcontainer взаимодействует с этими средствами для управления контейнерами Docker и их запуска.
runC: Использование libcontainer без Docker
В 2015 году Docker анонсировал runC: легкую портативную среду выполнения контейнеров.
Этот проект был передан в дар Open Container Initiative (OCI).
Репозиторий libcontainer сейчас заархивирован. На самом деле, libcontainer не забросили, а перенесли в репозиторий runC.
Перейдем к практической части и создадим контейнер с помощью runC. Начните с установки среды выполнения runC (прим. переводчика: если стоит docker то этого можно (нужно) не делать):
Давайте создадим каталог (/mycontainer), в который мы собираемся экспортировать содержимое образа Busybox.
Используя команду runC, мы можем запустить контейнер busybox, который использует извлеченный образ и файл спецификации (config.json).
Команда runc spec изначально создает этот файл JSON:
Альтернативой для создания кастомной спецификации конфигурации является использование «oci-runtime-tool», подкоманда «oci-runtime-tool generate» имеет множество опций, которые можно использовать для выполнения разных настроек.
Для получения дополнительной информации см. Runtime-tools.
Используя сгенерированный файл спецификации JSON, вы можете настроить время работы контейнера. Мы можем, например, изменить аргумент для выполнения приложения.
Давайте посмотрим, чем отличается исходный файл config.json от нового:
Давайте теперь снова запустим контейнер и заметим, как он ожидает 10 секунд, прежде чем завершится.
Стандарты сред исполнения контейнеров
Containerd полностью поддерживает запуск пакетов OCI и управление их жизненным циклом. Containerd (как и другие среды выполнения, такие как cri-o) использует runC для запуска контейнеров, но реализует также другие высокоуровневые функции, такие как управление образами и высокоуровневые API.
Интеграция containerd со средами выполнения Docker и OCI
Сontainerd, Shim и RunC, как все работает вместе
runC построен на libcontainer, который является той же библиотекой, которая ранее использовалась для Docker Engine.
До версии 1.11 Docker Engine использовался для управления томами, сетями, контейнерами, образами и т. д.
Теперь архитектура Docker разбита на четыре компонента:
Бинарные файлы соответственно называются docker, docker-containerd, docker-containerd-shim и docker-runc.
Давайте перечислим этапы запуска контейнера с использованием новой архитектуры docker:
Docker engine создает контейнер (из образа) и передает его в containerd.
Containerd вызывает containerd-shim
Containerd-shim использует runC для запуска контейнера
Containerd-shim позволяет среде выполнения (в данном случае runC) завершиться после запуска контейнера
Используя эту новую архитектуру, мы можем запускать «контейнеры без служб» (“daemon-less containers”), и у нас есть два преимущества:
runC может завершиться после запуска контейнера, и нам не нужны запущенными все процессы исполнения.
containerd-shim сохраняет открытыми файловые дескрипторы, такие как stdin, stdout и stderr, даже когда Docker и /или containerd завершаются.
«Если runC и Containerd являются средами исполнения, какого черта мы используем оба для запуска одного контейнера?»
Это, наверное, один из самых частых вопросов. Поняв, почему Docker разбил свою архитектуру на runC и Containerd, вы понимаете, что оба являются средами исполнения.
Если вы следили за историей с самого начала, вы, вероятно, заметили использование сред исполнения высокого и низкого уровня. В этом практическая разница между ними.
Обе они могут называться средами исполнения, но каждая среда исполнения имеет разные цели и функции. Чтобы сохранить стандартизацию экосистемы контейнеров, среда исполнения низкоуровневых контейнеров позволяет запускать только контейнеры.
Среда исполнения низкого уровня (например, runC) должна быть легкой, быстрой и не конфликтовать с другими более высокими уровнями управления контейнерами. Когда вы создаете контейнер Docker, он фактически управляет двумя средами исполнения containerd и runC.
Вы можете найти множество сред исполнения контейнеров, некоторые из них стандартизированы OCI, а другие нет, некоторые являются средами исполнения низкого уровня, а другие представляют собой нечто большее и реализуют уровень инструментов для управления жизненным циклом контейнеров и многое другое:
передача и хранение образов,
завершение и наблюдение за контейнерами,
Мы можем добавить новую среду исполнения с помощью Docker, выполнив:
Интерфейс среды исполнения контейнера (Container Runtime Interface)
Первоначально Kubernetes использовал среду исполнения Docker для запуска контейнеров, и она по-прежнему остается средой исполнения по умолчанию.
Однако CoreOS хотела использовать Kubernetes со средой исполнения RKT и предлагала патчи для Kubernetes, чтобы использовать эту среду исполнения в качестве альтернативы Docker.
Вместо изменения кодовой базы kubernetes в случае добавлении новой среды исполнения контейнера создатели Kubernetes решили создать CRI (Container Runtime Interface), который представляет собой набор API-интерфейсов и библиотек, позволяющих запускать различные среды исполнения контейнеров в Kubernetes. Любое взаимодействие между ядром Kubernetes и поддерживаемой средой выполнения осуществляется через CRI API.
Вот некоторые из плагинов CRI:
CRI-O:
Containerd CRI :
С cri-containerd пользователи могут запускать кластеры Kubernetes, используя containerd в качестве базовой среды исполнения без установленного Docker.
gVisor CRI:
Google Cloud App Engine использует gVisor CRI для изоляции клиентов.
Среда исполнения gVisor интегрируется с Docker и Kubernetes, что упрощает запуск изолированных контейнеров.
CRI-O Kata Containers

Проект Moby
От проекта создания Docker как единой монолитной платформы отказались и родился проект Moby, в котором Docker состоит из множества компонентов, таких как RunC.
Источник: Solomon Hykes Twitter
Источник: Solomon Hykes Twitter
Open Containers Initiative
Как мы видели, Docker пожертвовал RunC Open Container Initiative (OCI), но что это?
Open Container Initiative (OCI) направлена на установление общих стандартов для контейнеров, чтобы избежать потенциальной фрагментации и разделения внутри экосистемы контейнеров.
Он содержит две спецификации:
runtime-spec: спецификация исполнения
image-spec: спецификация образов
Контейнер, использующий другую среду исполнения, можно использовать с Docker API. Контейнер, созданный с помощью Docker, должен работать с любым другим движком.
На этом статья заканчивается.
Буду рад замечаниям и возможно неточностям в статье оригинального автора. Это позволит избежать заблуждений в понимании внутреннего устройства контейнеров. Если нет возможности комментирования на Хабре, можете обсудить тут в комментариях.