
linux-notes.org

Недавно столкнулся с проблемой, мне нужно было найти определенные слова в файлах и заменить их на нужный мне текст. Немного поискав в интернете, я нашел как это сделать, по этому решил записать заметку «Поиск и замена слов в файлах linux», пригодится как мне так и другим пользователям. Это можно сделать командой find и grep с некоторыми параметрами.
Простой поиск с использованием grep:
Поиск и замена текста в файлах:
Удаление определенного символа из файлов
Нужно символы прописывать в уникоде, если правильно понял.
Как заменить слово в файлах при рекурсивном поиске Linux?
Этой строкой мы ищем во всех файлах с разрешением *.py от текущей директории строку text_1 и заменяя ее наtext_2, так же можно использовать regexp выражения.
Еще примеры
Для начала делаем поиск по фразе которая нам необходима, нам покажет все файлы и в каких строках содержится данная фраза:
или для конкретных файлов:
Выполнить замену можно еще следующим образом:
Допустим, Вам необходимо выполнить замену целой строки ( закомментировать какую либо функцию, добавив // перед самой функцией), то можно это сделать:
Экранируем спец символы и заменяем на любую другую строку, для этого:
Данная команда заменит одну строку на другую во всех файлах.
Упрощенная версия ее:
Можно удалить многострочное содержание текста который находиться, например между //###==### и //###==###
То чтобы удалить все строки кода между данными комментариями, выполните:
Я делал сканирование maldet и нашел много вредоносного кода, по этому, я удалил его так:
Как заменить всю строку на другую? Та вот так можно:
Или тоже самое, но через переменные:
-===Пример===-
Предположим, имеется файл и в нем находится:
Но по заданию, нужно чтобы было — Three.Two.One
Для этого, выполним:
Делаю замену версий в Terraform так:
Делаем замену другим способом:
ПРИМЕЧАНИЕ! Утилиту rpl необходимо установить.
Я попозже постараюсь привести еще примеров и рассказать о утилите в своей новой статье.
Когда не удобно искать файлы в консольном режиме и есть GUI интерфейс, то можно воспользоваться утилитой regexxer.
Debian/Ubuntu/Mint:
CentOS/RedHat/Fedora:
Очень простая и хорошая утилита, я сам ею пользовался и тестировал на своей виртуальной машине на Debian.
На этом моя короткая заметка «Поиск и замена слов в файлах linux» завершена и готова к использованию.
Как использовать sed для поиска и замены строки в файлах
При работе с текстовыми файлами вам часто нужно искать и заменять строки текста в одном или нескольких файлах.
sed является s Tream ред itor. Он может выполнять базовые операции с текстом над файлами и входными потоками, такими как конвейеры. С помощью sed вы можете искать, находить и заменять, вставлять и удалять слова и строки. Он поддерживает базовые и расширенные регулярные выражения, которые позволяют сопоставлять сложные шаблоны.
Найти и заменить строку с помощью sed
Общая форма поиска и замены текста с помощью sed имеет следующий вид:
Рекомендуется заключать аргумент в кавычки, чтобы метасимволы оболочки не расширялись.
Давайте посмотрим, как мы можем использовать команду sed для поиска и замены текста в файлах некоторыми из наиболее часто используемых параметров и флагов.
В демонстрационных целях мы будем использовать следующий файл:
Если флаг g опущен, заменяется только первый экземпляр строки поиска в каждой строке:
С флагом глобальной замены sed заменяет все вхождения шаблона поиска:
Как вы могли заметить, подстрока foo внутри строки foobar также заменена в предыдущем примере. Если это нежелательное поведение, используйте выражение границы слова ( b ) на обоих концах строки поиска. Это гарантирует, что частичные слова не совпадают.
Чтобы сделать совпадение с шаблоном нечувствительным к регистру, используйте флаг I В приведенном ниже примере мы используем флаги g и I
Если вы хотите найти и заменить строку, содержащую символ-разделитель ( / ), вам нужно будет использовать обратную косую черту ( ), чтобы избежать косой черты. Например, чтобы заменить /bin/bash на /usr/bin/zsh вы должны использовать
Вы также можете использовать регулярные выражения. Например, чтобы найти все трехзначные числа и заменить их строковым number вы должны использовать:
Еще одна полезная функция sed заключается в том, что вы можете использовать символ амперсанда & который соответствует сопоставленному шаблону. Персонаж можно использовать несколько раз.
Например, если вы хотите добавить фигурные скобки <> вокруг каждого трехзначного числа, введите:
Чтобы убедиться, что резервная копия создана, выведите список файлов с помощью команды ls :
Рекурсивный поиск и замена
Если вы хотите искать и заменять текст только в файлах с определенным расширением, вы будете использовать:
Другой вариант — использовать команду grep для рекурсивного поиска всех файлов, содержащих шаблон поиска, а затем передать имена файлов в sed :
Выводы
Хотя это может показаться сложным и сложным, поначалу поиск и замена текста в файлах с помощью sed очень просты.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Поиск и замена слов в файлах linux

Поиск и замена слов в файлах linux
Недавно столкнулся с проблемой, мне нужно было найти определенные слова в файлах и заменить их на нужный мне текст. Немного поискав в интернете, я нашел как это сделать, по этому решил записать заметку «Поиск и замена слов в файлах linux», пригодится как мне так и другим пользователям. Это можно сделать командой find и grep с некоторыми параметрами.
Простой поиск с использованием grep:
Поиск и замена текста в файлах:
Удаление определенного символа из файлов
Нужно символы прописывать в уникоде, если правильно понял.
Как заменить слово в файлах при рекурсивном поиске Linux?
Этой строкой мы ищем во всех файлах с разрешением *.py от текущей директории строку text_1 и заменяя ее наtext_2, так же можно использовать regexp выражения.
Для начала делаем поиск по фразе которая нам необходима, нам покажет все файлы и в каких строках содержится данная фраза:
или для конкретных файлов:
Выполнить замену можно еще следующим образом:
Допустим, Вам необходимо выполнить замену целой строки ( закомментировать какую либо функцию, добавив // перед самой функцией), то можно это сделать:
Экранируем спец символы и заменяем на любую другую строку, для этого:
Данная команда заменит одну строку на другую во всех файлах.
Упрощенная версия ее:
Можно удалить многострочное содержание текста который находиться, например между //###==### и //###==###
То чтобы удалить все строки кода между данными комментариями, выполните:
Я делал сканирование maldet и нашел много вредоносного кода, по этому, я удалил его так:
Предположим, имеется файл и в нем находится:
Но по заданию, нужно чтобы было — Three.Two.One
Для этого, выполним:
Делаем замену другим способом:
ПРИМЕЧАНИЕ! Утилиту rpl необходимо установить.
Я попозже постараюсь привести еще примеров и рассказать о утилите в своей новой статье.
Когда не удобно искать файлы в консольном режиме и есть GUI интерфейс, то можно воспользоваться утилитой regexxer.
Очень простая и хорошая утилита, я сам ею пользовался и тестировал на своей виртуальной машине на Debian.
На этом моя короткая заметка «Поиск и замена слов в файлах linux» завершена и готова к использованию.
Команда sed Linux
В этой статье мы рассмотрим основы использования команды sed linux, её синтаксис, а также синтаксис регулярных выражений, который используется непосредственно для поиска и замены в файлах.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
А вот её основные опции:
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
Примеры использования sed
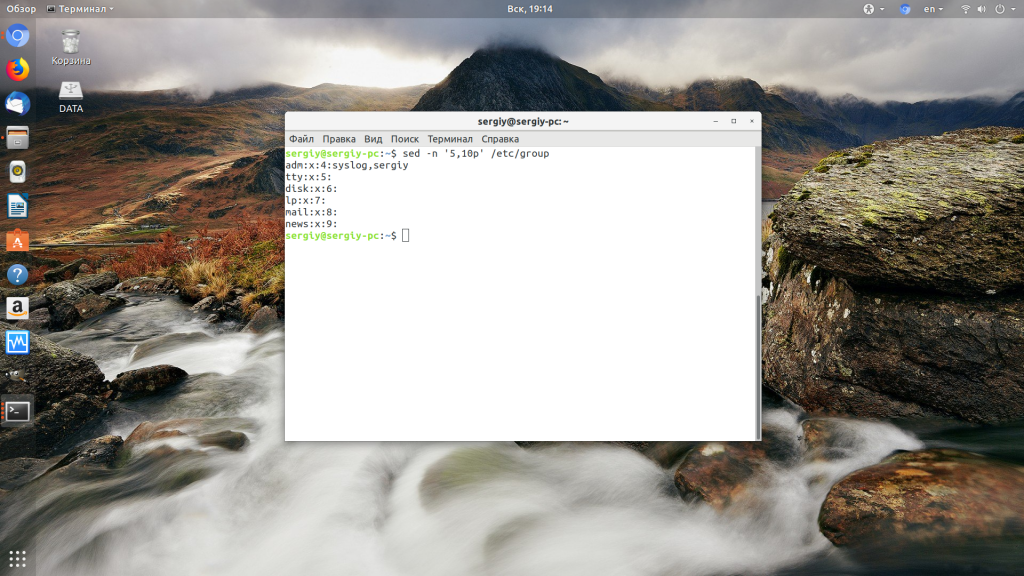
Или можно вывести весь файл, кроме строк с первой по двадцатую:

sed ‘s/root/losst/g’ /etc/group

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:
sed ‘1,10 s/0/1000/g’ /etc/group

Переходим ещё ближе к регулярным выражениям, удалим все пустые строки или строки с комментариями из конфига Apache:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:
sed ‘s/[$p*]/losst_p/g’ /etc/group

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf | sudo tee /etc/apache2/apache2.conf

Выводы
Из этой статьи вы узнали что представляет из себя команда sed Linux. Как видите, это очень гибкий инструмент, который позволяет делать с текстом очень многое. Он сложный в освоении, но с помощью него очень удобно решать многие задачи редактирования конфигурационных файлов или фильтрации вывода.
Bash-скрипты, часть 7: sed и обработка текстов
В прошлый раз мы говорили о функциях в bash-скриптах, в частности, о том, как вызывать их из командной строки. Наша сегодняшняя тема — весьма полезный инструмент для обработки строковых данных — утилита Linux, которая называется sed. Её часто используют для работы с текстами, имеющими вид лог-файлов, конфигурационных и других файлов.

Если вы, в bash-скриптах, каким-то образом обрабатываете данные, вам не помешает знакомство с инструментами sed и gawk. Тут мы сосредоточимся на sed и на работе с текстами, так как это — очень важный шаг в нашем путешествии по бескрайним просторам разработки bash-скриптов.
Сейчас мы разберём основы работы с sed, а так же рассмотрим более трёх десятков примеров использования этого инструмента.
Основы работы с sed
Утилиту sed называют потоковым текстовым редактором. В интерактивных текстовых редакторах, наподобие nano, с текстами работают, используя клавиатуру, редактируя файлы, добавляя, удаляя или изменяя тексты. Sed позволяет редактировать потоки данных, основываясь на заданных разработчиком наборах правил. Вот как выглядит схема вызова этой команды:
Вот что получится при выполнении этой команды.
Простой пример вызова sed
Выше приведён примитивный пример использования sed, нужный для того, чтобы ввести вас в курс дела. На самом деле, sed можно применять в гораздо более сложных сценариях обработки текстов, например — для работы с файлами.
Ниже показан файл, в котором содержится фрагмент текста, и результаты его обработки такой командой:
Текстовый файл и результаты его обработки
Здесь применён тот же подход, который мы использовали выше, но теперь sed обрабатывает текст, хранящийся в файле. При этом, если файл достаточно велик, можно заметить, что sed обрабатывает данные порциями и выводит то, что обработано, на экран, не дожидаясь обработки всего файла.
Выполнение наборов команд при вызове sed
К каждой строке текста из файла применяются обе команды. Их нужно разделить точкой с запятой, при этом между окончанием команды и точкой с запятой не должно быть пробела.
Для ввода нескольких шаблонов обработки текста при вызове sed, можно, после ввода первой одиночной кавычки, нажать Enter, после чего вводить каждое правило с новой строки, не забыв о закрывающей кавычке:
Вот что получится после того, как команда, представленная в таком виде, будет выполнена.
Другой способ работы с sed
Чтение команд из файла
Вот содержимое файла mycommands :
Вызовем sed, передав редактору файл с командами и файл для обработки:
Результат при вызове такой команды аналогичен тому, который получался в предыдущих примерах.
Использование файла с командами при вызове sed
Флаги команды замены
Внимательно посмотрите на следующий пример.
Вот что содержится в файле, и что будет получено после его обработки sed.
Исходный файл и результаты его обработки
Команда замены нормально обрабатывает файл, состоящий из нескольких строк, но заменяются только первые вхождения искомого фрагмента текста в каждой строке. Для того, чтобы заменить все вхождения шаблона, нужно использовать соответствующий флаг.
Схема записи команды замены при использовании флагов выглядит так:
Выполнение этой команды можно модифицировать несколькими способами.
Вызов команды замены с указанием позиции заменяемого фрагмента
Тут мы указали, в качестве флага замены, число 2. Это привело к тому, что было заменено лишь второе вхождение искомого шаблона в каждой строке. Теперь опробуем флаг глобальной замены — g :
Как видно из результатов вывода, такая команда заменила все вхождения шаблона в тексте.
Как результат, при запуске sed в такой конфигурации на экран выводятся лишь строки (в нашем случае — одна строка), в которых найден заданный фрагмент текста.
Использование флага команды замены p
Сохранение результатов обработки текста в файл
Символы-разделители
Однако, выглядит всё это не очень-то хорошо. Всё дело в том, что так как прямые слэши используются в роли символов-разделителей, такие же символы в передаваемых sed строках приходится экранировать. В результате страдает читаемость команды.
К счастью, sed позволяет нам самостоятельно задавать символы-разделители для использования их в команде замены. Разделителем считается первый символ, который будет встречен после s :
В данном случае в качестве разделителя использован восклицательный знак, в результате код легче читать и он выглядит куда опрятнее, чем прежде.
Выбор фрагментов текста для обработки
До сих пор мы вызывали sed для обработки всего переданного редактору потока данных. В некоторых случаях с помощью sed надо обработать лишь какую-то часть текста — некую конкретную строку или группу строк. Для достижения такой цели можно воспользоваться двумя подходами:
Обработка только одной строки, номер который задан при вызове sed
Второй вариант — диапазон строк:
Обработка диапазона строк
Кроме того, можно вызвать команду замены так, чтобы файл был обработан начиная с некоей строки и до конца:
Обработка файла начиная со второй строки и до конца
Для того, чтобы обрабатывать с помощью команды замены только строки, соответствующие заданному фильтру, команду надо вызвать так:
Обработка строк, соответствующих фильтру
Тут мы использовали очень простой фильтр. Для того, чтобы в полной мере раскрыть возможности данного подхода, можно воспользоваться регулярными выражениями. О них мы поговорим в одном из следующих материалов этой серии.
Удаление строк
Вызов команды выглядит так:
Мы хотим, чтобы из текста была удалена третья строка. Обратите внимание на то, что речь не идёт о файле. Файл останется неизменным, удаление отразится лишь на выводе, который сформирует sed.
Удаление третьей строки
Если при вызове команды d не указать номер удаляемой строки, удалены будут все строки потока.
Вот как применить команду d к диапазону строк:
Удаление диапазона строк
А вот как удалить строки, начиная с заданной — и до конца файла:
Удаление строк до конца файла
Строки можно удалять и по шаблону:
Удаление строк по шаблону
При вызове d можно указывать пару шаблонов — будут удалены строки, в которых встретится шаблон, и те строки, которые находятся между ними:
Удаление диапазона строк с использованием шаблонов
Вставка текста в поток
С помощью sed можно вставлять данные в текстовый поток, используя команды i и a :
Теперь взглянем на команду a :
Как видно, эти команды добавляют текст до или после данных из потока. Что если надо добавить строку где-нибудь посередине?
Команда i с указанием номера опорной строки
Проделаем то же самое с командой a :
Команда a с указанием номера опорной строки
Замена строк
Команда c позволяет изменить содержимое целой строки текста в потоке данных. При её вызове нужно указать номер строки, вместо которой в поток надо добавить новые данные:
Замена строки целиком
Если воспользоваться при вызове команды шаблоном в виде обычного текста или регулярного выражения, заменены будут все соответствующие шаблону строки:
Замена строк по шаблону
Замена символов
Команда y работает с отдельными символами, заменяя их в соответствии с переданными ей при вызове данными:
Используя эту команду, нужно учесть, что она применяется ко всему текстовому потоку, ограничить её конкретными вхождениями символов нельзя.
Вывод номеров строк
Вывод номеров строк
Потоковый редактор вывел номера строк перед их содержимым.
Вывод номеров строк, соответствующих шаблону
Чтение данных для вставки из файла
Вставка в поток содержимого файла
Вот что произойдёт, если применить при вызове команды r шаблон:
Использование шаблона при вызове команды r
Содержимое файла будет вставлено после каждой строки, соответствующей шаблону.
Пример
Решить эту задачу можно, воспользовавшись командами r и d потокового редактора sed:
Замена указателя места заполнения на реальные данные
Итоги
Сегодня мы рассмотрели основы работы с потоковым редактором sed. На самом деле, sed — это огромнейшая тема. Его изучение вполне можно сравнить с изучением нового языка программирования, однако, поняв основы, вы сможете освоить sed на любом необходимом вам уровне. В результате ваши возможности по обработке с его помощью текстов будет ограничивать лишь воображение.
На сегодня это всё. В следующий раз поговорим о языке обработки данных awk.
Уважаемые читатели! А вы пользуетесь sed в повседневной работе? Если да — поделитесь пожалуйста опытом.