
Динамическое программирование для начинающих
Авторизуйтесь
Динамическое программирование для начинающих
Динамическое программирование — тема, которой в рунете посвящено довольно мало статей, поэтому мы решили ею заняться. В этой статье будут разобраны классические задачи на последовательности, одномерную и двумерную динамику, будет дано обоснование решениям и описаны разные подходы к их реализации. Весь приведённый в статье код написан на Java.
О чём вообще речь? Что такое динамическое программирование?
Хорошо, как это использовать?
Решение задачи динамическим программированием должно содержать следующее:
И что, мне для решения рекурсивный метод писать надо? Я слышал, они медленные.
Конечно, не надо, есть и другие подходы к реализации динамики. Разберём их на примере следующей задачи:
Идея решения
Здесь нам даны и начальные состояния (a0 = a1 = 1), и зависимости. Единственная сложность, которая может возникнуть — понимание того, что 2n — условие чётности числа, а 2n+1 — нечётности. Иными словами, нам нужно проверять, чётно ли число, и считать его в зависимости от этого по разным формулам.
Рекурсивное решение
Очевидная реализация состоит в написании следующего метода:
Рекурсивное решение с кэшированием значений
Идея мемоизации очень проста — единожды вычисляя значение, мы заносим его в какую-то структуру данных. Перед каждым вычислением мы проверяем, есть ли вычисляемое значение в этой структуре, и если есть, используем его. В качестве структуры данных можно использовать массив, заполненный флаговыми значениями. Если значение элемента по индексу N равно значению флага, значит, мы его ещё не вычисляли. Это создаёт определённые трудности, т.к. значение флага не должно принадлежать множеству значений функции, которое не всегда очевидно. Лично я предпочитаю использовать хэш-таблицу — все действия в ней выполняются за O(1), что очень удобно. Однако, при большом количестве значений два числа могут иметь одинаковый хэш, что, естественно, порождает проблемы. В таком случае стоит использовать, например, красно-чёрное дерево.
Для уже написанной функции f(int) кэширование значений будет выглядеть следующим образом:
Не слишком сложно, согласитесь? Зато это избавляет от огромного числа операций. Платите вы за это лишним расходом памяти.
Последовательное вычисление
Теперь вернёмся к тому, с чего начали — рекурсия работает медленно. Не слишком медленно, чтобы это приносило действительные неприятности в настоящей жизни, но на соревнованиях по спортивному программированию каждая миллисекунда на счету.
Метод последовательного вычисления подходит, только если функция ссылается исключительно на элементы перед ней — это его основной, но не единственный минус. Наша задача этому условию удовлетворяет.
4–5 декабря, Онлайн, Беcплатно
Суть метода в следующем: мы создаём массив на N элементов и последовательно заполняем его значениями. Вы, наверное, уже догадались, что таким образом мы можем вычислять в том числе те значения, которые для ответа не нужны. В значительной части задач на динамику этот факт можно опустить, так как для ответа часто бывают нужны как раз все значения. Например, при поиске наименьшего пути мы не можем не вычислять путь до какой-то точки, нам нужно пересмотреть все варианты. Но в нашей задаче нам нужно вычислять приблизительно log2(N) значений (на практике больше), для 922337203685477580-го элемента (MaxLong/10) нам потребуется 172 вычисления.
Ещё одним минусом такого подхода является сравнительно большой расход памяти.
Создание стека индексов
Сейчас нам предстоит, по сути, написать свою собственную рекурсию. Идея состоит в следующем — сначала мы проходим «вниз» от N до начальных состояний, запоминая аргументы, функцию от которых нам нужно будет вычислять. Затем возвращаемся «вверх», последовательно вычисляя значения от этих аргументов, в том порядке, который мы записали.
Зависимости вычисляются следующим образом:
Полученный размер стека – то, сколько вычислений нам потребуется сделать. Именно так я получил упомянутое выше число 172.
Теперь мы поочередно извлекаем индексы и вычисляем для них значения по формулам – гарантируется, что все необходимые значения уже будут вычислены. Хранить будем как раньше – в хэш-таблице.
Все необходимые значения вычислены, осталось только написать
Конечно, такое решение гораздо более трудоёмкое, однако это того стоит.
Хорошо, математика — это красиво. А что с задачами, в которых не всё дано?
Для большей ясности разберём следующую задачу на одномерную динамику:
На вершине лесенки, содержащей N ступенек, находится мячик, который начинает прыгать по ним вниз, к основанию. Мячик может прыгнуть на следующую ступеньку, на ступеньку через одну или через 2. (То есть, если мячик лежит на 8-ой ступеньке, то он может переместиться на 5-ую, 6-ую или 7-ую.) Определить число всевозможных «маршрутов» мячика с вершины на землю.
Идея решения
На первую ступеньку можно попасть только одним образом — сделав прыжок с длиной равной единице. На вторую ступеньку можно попасть сделав прыжок длиной 2, или с первой ступеньки — всего 2 варианта. На третью ступеньку можно попасть сделав прыжок длиной три, с первой или со втрой ступенек. Т.е. всего 4 варианта (0->3; 0->1->3; 0->2->3; 0->1->2->3). Теперь рассмотрим четвёртую ступеньку. На неё можно попасть с первой ступеньки — по одному маршруту на каждый маршрут до неё, со второй или с третьей — аналогично. Иными словами, количество путей до 4-й ступеньки есть сумма маршрутов до 1-й, 2-й и 3-й ступенек. Математически выражаясь, F(N) = F(N-1)+F(N-2)+F(N-3). Первые три ступеньки будем считать начальными состояниями.
Реализация через рекурсию
Здесь ничего хитрого нет.
Реализация через массив значений
Исходя из того, что, по большому счёту, простое решение на массиве из N элементов очевидно, я продемонстрирую тут решение на массиве всего из трёх.
Так как каждое следующее значение зависит только от трёх предыдущих, ни одно значение под индексом меньше i-3 нам бы не пригодилось. В приведённом выше коде мы записываем новое значение на место самого старого, не нужного больше. Цикличность остатка от деления на 3 помогает нам избежать кучи условных операторов. Просто, компактно, элегантно.
Там вверху ещё было написано про какую-то двумерную динамику.
С двумерной динамикой не связано никаких особенностей, однако я, на всякий случай, рассмотрю здесь одну задачу и на неё.
В прямоугольной таблице NxM в начале игрок находится в левой верхней клетке. За один ход ему разрешается перемещаться в соседнюю клетку либо вправо, либо вниз (влево и вверх перемещаться запрещено). Посчитайте, сколько есть способов у игрока попасть в правую нижнюю клетку.
Идея решения
Логика решения полностью идентична таковой в задаче про мячик и лестницу — только теперь в клетку (x,y) можно попасть из клеток (x-1,y) или (x, y-1). Итого F(x,y) = F(x-1, y)+F(x,y-1). Дополнительно можно понять, что все клетки вида (1,y) и (x,1) имеют только один маршрут — по прямой вниз или по прямой вправо.
Реализация через рекурсию
Ради всего святого, не нужно делать двумерную динамику через рекурсию. Уже было упомянуто, что рекурсия менее выгодна, чем цикл по быстродействию, так двумерная рекурсия ещё и читается ужасно. Это только на таком простом примере она смотрится легко и безобидно.
Реализация через массив значений
Классическое решение динамикой, ничего необычного — проверяем, является ли клетка краем, и задаём её значение на основе соседних клеток.
Отлично, я всё понял. На чём мне проверить свои навыки?
В заключение приведу ряд типичных задач на одномерную и двумерную динамику, разборы прилагаются.
Взрывоопасность
При переработке радиоактивных материалов образуются отходы двух видов — особо опасные (тип A) и неопасные (тип B). Для их хранения используются одинаковые контейнеры. После помещения отходов в контейнеры последние укладываются вертикальной стопкой. Стопка считается взрывоопасной, если в ней подряд идет более одного контейнера типа A. Стопка считается безопасной, если она не является взрывоопасной. Для заданного количества контейнеров N определить количество возможных типов безопасных стопок.
Решение
Ответом является (N+1)-е число Фибоначчи. Догадаться можно было, просто вычислив 2-3 первых значения. Строго доказать можно было, построив дерево возможных построений.
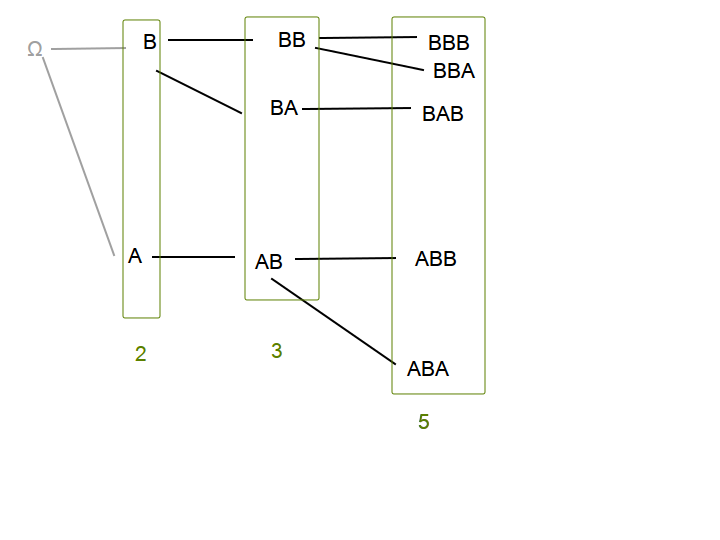
Каждый основной элемент делится на два — основной (заканчивается на B) и побочный (заканчивается на A). Побочные элементы превращаются в основные за одну итерацию (к последовательности, заканчивающейся на A, можно дописать только B). Это характерно для чисел Фибоначчи.
Реализация
Подъём по лестнице
Мальчик подошел к платной лестнице. Чтобы наступить на любую ступеньку, нужно заплатить указанную на ней сумму. Мальчик умеет перешагивать на следующую ступеньку, либо перепрыгивать через ступеньку. Требуется узнать, какая наименьшая сумма понадобится мальчику, чтобы добраться до верхней ступеньки.
Решение
Очевидно, что сумма, которую мальчик отдаст на N-ой ступеньке, есть сумма, которую он отдал до этого плюс стоимость самой ступеньки. «Сумма, которую он отдал до этого» зависит от того, с какой ступеньки мальчик шагает на N-ую — с (N-1)-й или с (N-2)-й. Выбирать нужно наименьшую.
Реализация
Калькулятор
Имеется калькулятор, который выполняет три операции:
Определите, какое наименьшее число операций необходимо для того, чтобы получить из числа 1 заданное число N. Выведите это число, и, на следующей строке, набор исполненных операций вида «111231».
Решение
Наивное решение состоит в том, чтобы делить число на 3, пока это возможно, иначе на 2, если это возможно, иначе вычитать единицу, и так до тех пор, пока оно не обратится в единицу. Это неверное решение, т.к. оно исключает, например, возможность убавить число на единицу, а затем разделить на три, из-за чего на больших числах (например, 32718) возникают ошибки.
Правильное решение заключается в нахождении для каждого числа от 2 до N минимального количества действий на основе предыдущих элементов, иначе говоря: F(N) = min(F(N-1), F(N/2), F(N/3)) + 1. Следует помнить, что все индексы должны быть целыми.
Для воссоздания списка действий необходимо идти в обратном направлении и искать такой индекс i, что F(i)=F(N), где N — номер рассматриваемого элемента. Если i=N-1, записываем в начало строки 1, если i=N/2 — двойку, иначе — тройку.
Реализация
Самый дешёвый путь
В каждой клетке прямоугольной таблицы N*M записано некоторое число. Изначально игрок находится в левой верхней клетке. За один ход ему разрешается перемещаться в соседнюю клетку либо вправо, либо вниз (влево и вверх перемещаться запрещено). При проходе через клетку с игрока берут столько килограммов еды, какое число записано в этой клетке (еду берут также за первую и последнюю клетки его пути).
Требуется найти минимальный вес еды в килограммах, отдав которую игрок может попасть в правый нижний угол.
Решение
В любую клетку таблицы мы можем попасть либо из клетки, находящейся непосредственно над ней, либо из клетки, находящейся непосредственно слева. Таким образом, F(x,y) = min(F(x-1,y), F(x,y-1)). Чтобы не обрабатывать граничные случаи, можно добавить первую строку и столбец, заполненные некоторой константой — каким-то числом, заведомо большим содержимого любой из клеток.
Динамическое программирование примеры
В информатике есть несколько способов описания подхода к решению алгоритма. Жадный, наивный, разделяй и властвуй — всё это способы решения алгоритмов. Один из таких способов называется динамическим программированием (DP). В этой статье мы рассмотрим, что такое динамическое программирование, его характеристики и два основных подхода к решению алгоритмов с помощью DP.
Что такое динамическое программирование?

Концепция динамического программирования была создана, чтобы помочь повысить эффективность методов решения алгоритмов грубой силой или «разделяй и властвуй».
Скажем, например, у нас есть рюкзак, в который может поместиться только определённое количество предметов. Какая комбинация предметов даст нам максимальную ценность? Или предположим, что у нас есть рюкзак определённой грузоподъёмности. Какая комбинация предметов с заданным весом даст нам максимальную ценность?
Наивные решения
Наивное решение — это первое, что приходит в голову программисту. Он может быть не самым эффективным и не использовать преимущества некоторых концепций. Тем не менее, это простое решение, которое решает проблему. Как начинающий программист, в ваших интересах сначала придумать наивные решения, а потом провести рефакторинг для их оптимизации.
Нисходящие решения
Это первый способ использования динамического программирования в вашем решении. Нисходящее решение возьмёт наивное решение, использующее рекурсию, а затем добавит метод, называемый мемоизацией, для его оптимизации. Мемоизация действует как своего рода кеш для хранения наших подзадач по мере продвижения, чтобы алгоритм работал быстрее. Обычно это происходит в форме объекта или словаря.
Решения снизу-вверх
Другой тип решения динамического программирования, который избегает рекурсии и табулирования с самого начала, называется восходящим решением. Это отличный способ, если вы хотите избежать использования большого объёма памяти или предотвратить случайное переполнение стека.
Фибоначчи
Последовательность Фибоначчи — это последовательность чисел, каждое из которых представляет собой сумму двух предыдущих чисел, начиная с 0 и 1:
Fn = 0, 1, 1, 2, 3, 5, 8, 13, 21…и т.д.
0 + 1 = 1
1 + 1 = 2
1 + 2 = 3
2 + 3 = 5
3 + 5 = 8
5 + 8 = 13
8 + 13 = 21
13 + 21 = 34…и т.д.
Подсказка
По заданному числу n найдите n- е число в последовательности Фибоначчи.
Решение 1. Наивно
Наивное решение — это решение, которое программист может придумать, впервые взглянув на проблему. Помните, что наивность необязательно означает плохо. Наивное решение обычно означает, что проблему можно решить с помощью других методов, которые могут создать более оптимальное или эффективное решение. Наивное решение — это хорошо, потому что оно означает, что вы на правильном пути.
Пример наивного решения для Фибоначчи выглядит так:
const fibNaive = (num) => <
if(num <
if(num Читайте также: Что такое IDE и какая лучше
Базовый вариант здесь почти такой же. Разница в том, что мы начинаем с памятки по умолчанию, в которой есть наши первые два числа Фибоначчи. Это вместо того, чтобы просто возвращать переданное число. Мы присваиваем переменный результат нашему уравнению Фибоначчи, которое мы использовали при возврате наивного решения.
В операторе if мы проверяем, существует ли ключ в memo — если нет, мы добавляем его. Возвращаем результат так же, как и в наивном решении.
В конечном счёте, у этого решения есть два отличия. Во-первых, мы добавили memo объект, который запоминает то, что мы уже выяснили. И во-вторых, мы добавили условие, которое проверяет, существует ли эта пара ключ: значение в memo объекте. Если нет, то добавляет.
Это решение изменяет временную сложность с O (2 n) на O (n).
Решение 3. Подход к динамическому программированию № 2 — снизу-вверх с табуляцией
Эта версия решения использует итерацию для решения проблемы и выводит результат в таблицу по мере продвижения. Мы начинаем с объекта JavaScript (или здесь вполне приемлем массив), который будет хранить наши значения. Мы используем эти значения, чтобы довести до нашего числа nth.
for(let i = 3; i <
//find all the substrings.
substrs = [];
maxString = «»;
otherString = «»;
if(str1.length > str2.length) <
maxString = str1;
otherString = str2;
> else <
maxString = str2;
otherString = str1;
>
for(let i = 0; i < // O(m)
if(new RegExp(string).test(otherString)) <
if(maxLength <
let i = str1.length;
let j = str2.length;
//if the strings don’t exist, return 0
if(i === 0 || j === 0) <
return count;
>
if(str1[i — 1] === str2[j — 1]) < // if the chars are the same, up the count and shorten string by 1
count = topDown(str1.slice(0, i — 1), str2.slice(0, j — 1), count + 1);
>
count = Math.max(count, //max between count and the other function
Math.max( // max between looking at shortening one word vs shortening the other word.
topDown(str1.slice(0, i), str2.slice(0, j — 1), 0),
topDown(str1.slice(0, i — 1), str2.slice(0, j), 0)));
Сложность по времени для этого решения составляет O (n + m), чтобы учесть размеры различных строк.
Решение 3. Восходящее решение с табуляцией
Третье решение этой проблемы предполагает использование восходящего подхода. В этом подходе вы должны создать двумерный массив / матрицу, которая будет табулировать максимальную длину подстроки. Первое, что нужно сделать, это создать пустую матрицу, используя длины строк.
for (let i = 0; i <
let table = create2DArray(A, B); // create the table
let max = 0; // initialize and declare max substring length to be 0
//start i and j at 1 so we can compare characters to previous row and column
for (let i = 1; i
Динамическое программирование. Классические задачи
Здравствуй, Хабрахабр. В настоящий момент я работаю над учебным пособием по олимпиадному программированию, один из параграфов которого посвящен динамическому программированию. Ниже приведена выдержка из данного параграфа. Пытаясь объяснить данную тему как можно проще, я постарался сложные моменты сопроводить иллюстрациями. Мне интересно ваше мнение о том, насколько понятным получился данный материал. Также буду рад советам, какие еще задачи стоит включить в данный раздел.
Во многих олимпиадных задачах по программированию решение с помощью рекурсии или полного перебора требует выполнения очень большого числа операций. Попытка решить такие задачи, например, полным перебором, приводит к превышению времени выполнения.
Однако среди переборных и некоторых других задач можно выделить класс задач, обладающих одним хорошим свойством: имея решения некоторых подзадач (например, для меньшего числа n), можно практически без перебора найти решение исходной задачи.
Такие задачи решают методом динамического программирования, а под самим динамическим программированием понимают сведение задачи к подзадачам.
Последовательности
Классической задачей на последовательности является следующая.
Один из способов решения, который может показаться логичным и эффективным, — решение с помощью рекурсии:
Используя такую функцию, мы будем решать задачу «с конца» — будем шаг за шагом уменьшать n, пока не дойдем до известных значений.
Но как можно заметить, такая, казалось бы, простая программа уже при n = 40 работает заметно долго. Это связано с тем, что одни и те же промежуточные данные вычисляются по несколько раз — число операций нарастает с той же скоростью, с какой растут числа Фибоначчи — экспоненциально.
Один из выходов из данной ситуации — сохранение уже найденных промежуточных результатов с целью их повторного использования:
Приведенное решение является корректным и эффективным. Но для данной задачи применимо и более простое решение:
Такое решение можно назвать решением «с начала» — мы первым делом заполняем известные значения, затем находим первое неизвестное значение (F3), потом следующее и т.д., пока не дойдем до нужного.
Именно такое решение и является классическим для динамического программирования: мы сначала решили все подзадачи (нашли все Fi для i 2, соответственно.
Следующая задача одномерного динамического программирования встречается в различных вариациях.
Задача 1. Посчитать число последовательностей нулей и единиц длины n, в которых не встречаются две идущие подряд единицы.
При n 2. То есть данная задача фактически сводится к нахождению чисел Фибоначчи.
Двумерное динамическое программирование
Классической задачей двумерного динамического программирования является задача о маршрутах на прямоугольном поле.
В разных формулировках необходимо посчитать число маршрутов или найти маршрут, который является лучшим в некотором смысле.
Приведем пару формулировок таких задач:
Задача 2. Дано прямоугольное поле размером n*m клеток. Можно совершать шаги длиной в одну клетку вправо или вниз. Посчитать, сколькими способами можно попасть из левой верхней клетки в правую нижнюю.
Задача 3. Дано прямоугольное поле размером n*m клеток. Можно совершать шаги длиной в одну клетку вправо, вниз или по диагонали вправо-вниз. В каждой клетке записано некоторое натуральное число. Необходимо попасть из верхней левой клетки в правую нижнюю. Вес маршрута вычисляется как сумма чисел со всех посещенных клеток. Необходимо найти маршрут с минимальным весом.
Для всех таких задач характерным является то, что каждый отдельный маршрут не может пройти два или более раз по одной и той же клетке.
Рассмотрим более подробно задачу 2. В некоторую клетку с координатами (i,j) можно прийти только сверху или слева, то есть из клеток с координатами (i – 1, j) и (i, j – 1):

Таким образом, для клетки (i, j) число маршрутов A[i][j] будет равно
A[i – 1][j] + A[i][j – 1], то есть задача сводится к двум подзадачам. В данной реализации используется два параметра — i и j — поэтому применительно к данной задаче мы говорим о двумерном динамическом программировании.
Теперь мы можем пройти последовательно по строкам (или по столбцам) массива A, находя число маршрутов для текущей клетки по приведенной выше формуле. Предварительно в A[0][0] необходимо поместить число 1.
В задаче 3 в клетку с координатами (i, j) мы можем попасть из клеток с координатами
(i – 1, j), (i, j – 1) и (i – 1, j – 1). Допустим, что для каждой из этих трех клеток мы уже нашли маршрут минимального веса, а сами веса поместили в W[i – 1][j], W[i][j – 1],
W[i – 1][j – 1]. Чтобы найти минимальный вес для (i, j), необходимо выбрать минимальный из весов W[i – 1][j], W[i][j – 1], W[i – 1][j – 1] и прибавить к нему число, записанное в текущей клетке:
W[i][j] = min(W[i–1][j], W[i][j – 1], W[i – 1][j – 1]) + A[i][j];
Данная задача осложнена тем, что необходимо найти не только минимальный вес, но и сам маршрут. Поэтому в другой массив мы дополнительно для каждой клетки будем записывать, с какой стороны в нее надо попасть.
На следующем рисунке приведен пример исходных данных и одного из шагов алгоритма.
В каждую из уже пройденных клеток ведет ровно одна стрелка. Эта стрелка показывает, с какой стороны необходимо прийти в эту клетку, чтобы получить минимальный вес, записанный в клетке.
После прохождения всего массива необходимо будет проследить сам маршрут из последней клетки, следуя по стрелкам в обратную сторону.
Задачи на подпоследовательности
Рассмотрим задачу о возрастающей подпоследовательности.
Задача 4. Дана последовательность целых чисел. Необходимо найти ее самую длинную строго возрастающую подпоследовательность.
Начнем решать задачу с начала — будем искать ответ, начиная с первых членов данной последовательности. Для каждого номера i будем искать наибольшую возрастающую подпоследовательность, оканчивающуюся элементом в позиции i. Пусть исходная последовательность хранится в массиве A. В массиве L будем записывать длины максимальных подпоследовательностей, оканчивающихся текущим элементом. Пусть мы нашли все L[i] для 1
Что такое динамическое программирование
Представляем нашим читателям научно-популярную статью о динамическом программировании, опубликованную на сайте DOU.UA. Автор — Тимофей Антоненко, ML/Python Team Lead в CreatorIQ.
Введение и немного истории
Всем привет. Меня зовут Тимофей, я Python/ML-разработчик, имею 6 лет опыта в индустрии. Занимаюсь исследованиями в области архитектур нейронных сетей в аспирантуре ХНУРЭ, кандидатская связана с нео-фаззи нейронными сетями.
Тема этой статьи важна для тех, кто сталкивается с обработкой данных в своей работе. На практике динамическое программирование может пригодиться вам всего лишь 1–2 раза в жизни, но сам концепт помогает по-другому посмотреть на работу с алгоритмами.
Когда я сам учился решать задачи с помощью этого подхода, у меня часто возникали трудности с интуицией решения. Скажу даже, что однажды из-за задачи по динамическому программированию я ужасно провалил одно собеседование. Ну не получалось у меня рассмотреть нужные зависимости в структурах данных, как я не пытался. Но меня всегда привлекал этот метод, поскольку в нем есть что-то нестандартное, он часто с большим отрывом обыгрывает другие алгоритмы в вычислительной гонке. В общем, по некоторым причинам подход к решению задач с помощью динамического программирования кажется мне не интуитивным. И многие статьи/уроки, которые освещают эту тему, не раскрывают ее с той стороны, с которой мне бы хотелось.
Вот на основании этих мыслей и возникла идея написать материал.
Итак, что же такое динамическое программирование
Начнем с истории (весьма забавной, кстати). Она о Ричарде Беллмане — человеке, который придумал и закрепил в научном сообществе понятие «динамическое программирование». В 1940 году он использовал этот термин для задач, где решение одной части задачи зависело от другой. Затем в 1953-м Беллман изменил и дополнил определение динамического программирования до его текущего вида.
Он забавно описывает ситуацию с именованием этого понятия. Беллману нужно было придумать название, но чиновник, перед которым он тогда отчитывался, сильно ненавидел (математик подчеркивает, что именно «ненавидел») термины и не хотел разбираться с ними. Каждый раз всем сотрудникам приходилось буквально дрожать от страха из-за того, что их босс не может понять что-то и мешает это с грязью в своих невеселых каламбурах. А особенно математические термины!
В связи с этим Беллман много времени и усилий потратил на придумывание названия. Слово «программирование» было выбрано как аналог слову «планирование», которое не подходило по ряду различных причин (у Советов все время было планирование чего-то).
А слово «динамическое» было выбрано исходя из того, что, помимо передачи сути подхода, с ним трудно было придумать что-то унизительное, бранное. Беллман не хотел, чтобы руководитель как-то коверкал его термин. Даже чиновник не смог бы сделать это так легко (у читателей, конечно же, найдется пара вариантов). Вот таким образом и сформировался термин «динамическое программирование».
Официальное определение есть на Википедии. Упрощенное определение от меня: динамическое программирование — это подход к решению задач, который основывается на том, что исходная задача разбивается на более мелкие подзадачи, которые проще решить. И потом решения этих подзадач можно использовать для решения исходной задачи.
Мой друг, который делал ревью статьи, сказал, что все задачи решаются таким образом! Я был повержен этим утверждением и не нашел, что ему ответить.
Потому важные дополнения:
В тексте иногда будет использоваться аббревиатура ДП — динамическое программирование.
Пройдемся более детально по этому определению.
1. ДП — это подход к решению задач. То есть это не просто формула или алгоритм, а скорее методология, которая говорит вам, как думать, чтобы решить задачу.
2. Это подход к решению задач, где нужно разбить задачу на более мелкие подзадачи, которые легко решить. К этому утверждению может быть много вопросов.
Что означает «более мелкие подзадачи»? (Можно также сказать «более простые подзадачи»). Ответ: это задачи, которые нужно решить для входных данных меньшего размера. Под меньшим размером можно подразумевать или меньшее число, или массив меньшего размера, или меньшее количество настраиваемых параметров и так далее. Возьмем, например, числа Фибоначчи. Обозначим как Ф(N) — N-е число Фибоначчи. То есть Ф(5) — это пятое число Фибоначчи. Чтобы посчитать пятое число Фибоначчи, нужны третье Ф(3) и четвертое Ф(4) числа Фибоначчи. Вот как раз задачи нахождения третьего и четвертого чисел Фибоначчи и являются более мелкими подзадачами.
Эти более мелкие задачи легко/просто решить. Если вы знакомы с O-нотацией, то я вам скажу просто, что более простая задача O(простая) является легче сложной О(сложная), если О(простая)  Рис. 1. Граф вычисления пятого числа Фибоначчи
Рис. 1. Граф вычисления пятого числа Фибоначчи
На практике люди часто путают ДП с рекурсией или с методом «разделяй и властвуй». Но здесь весьма просто все прояснить и найти отличия.
В рекурсии вы в некотором месте алгоритма начинаете использовать этот же алгоритм (или его часть) для решения подзадачи. При этом вам все равно, решалась ли эта подзадача раньше. И таким образом строится дерево рекурсии, в котором вы вызываете условную функцию A внутри функции А.
В методе «разделяй и властвуй» имеет значение, на каких данных вы вызываете свою функцию, но тут нет таких хороших инструментов ДП, как мемоизация и табуляция (речь о них пойдет дальше).
Как применять динамическое программирование для решения задач
У программистов могут быть совершенно разные задачи. В одном случае вам нужно просто использовать язык разметки, чтобы что-то нарисовать, в другом — прописать инструкции через ассемблер для эффективной работы процессора.
Но у всех людей работает эта ассоциация — программисты разрабатывают алгоритмы.
И вот представим, что и к вам прилетела свеженькая задача, у которой есть цель и ограничения. Как и в любой задаче, в ней также присутствуют структуры данных и зависимости от других частей системы.
И в один момент вы понимаете, что именно для этой задачи важно быстродействие. Вы можете это понять не сразу. Например, сначала вы решили задачу, потом заметили, что ваше решение медленно работает. Или же вам невдомек, как решить задачу, чтобы результаты вычисления были получены быстрее чем через 100 лет.
Да, наверняка у вас есть/был способ, который решал бизнес-цели задачи. Но когда вы понимаете, что время решения сильно увеличивается (полиномиально, например) при росте количества/значения входных данных, то пора задуматься о ДП.
Прежде чем описать алгоритм, введем два понятия — мемоизация и табуляция.
Мемоизация и табуляция
Мемоизация — оптимизационная техника, которая позволяет запоминать результаты вычислений и потом переиспользовать их тогда, когда нужно сделать такие же вычисления.
Любимый пример: при подсчете седьмого числа Фибоначчи вы можете запомнить четвертое число Фибоначчи и не вычислять его каждый раз, а только один раз.
Также эту технику описывают как «сверху вниз». Причина — на рисунке. Это граф в виде дерева рекурсии для вычисления пятого числа Фибоначчи:
То есть вы сначала решаете большую проблему «сверху» — Ф(5), а потом спускаетесь. Так вот, когда вы, например, первый раз достигли вершины графа Ф(2) и посчитали ее значение, то запоминаете его и второй раз уже не пересчитываете, а достаете из памяти. То же самое и для остальных вершин. В большинстве случаев доставать из памяти намного быстрее, чем пересчитывать.
Табуляция — оптимизационная техника, которая начинает решать подзадачи с самой простой и потом при дальнейшем продвижении решает все более сложные подзадачи, пока не будет решена основная задача. При этом для решения более сложных подзадач используются решения более простых подзадач.
В отличие от мемоизации, этот подход называют «снизу вверх» из-за того, что вы сначала беретесь за самые простые задачи.
На числах Фибоначчи это работает в том случае, когда вы решаете задачу с помощью цикла. То есть Ф(i) = Ф(i-1) + Ф(i-2), где i — это индекс внутри цикла. И если вы уже получили Ф(i-1) и Ф(i-2) на предыдущих итерациях, то текущее вычисление не составит труда.
Понятия мемоизации и табуляции позволяют расширить свой взгляд на программистские хаки для решения задач.
Итак, пошаговый алгоритм для задач динамического программирования
1. Представим, что решение вашей задачи — это результат работы функции Z.
Итого Z(x) = y, где x — входные параметры, y — решение задачи для входных параметров x.
2. Посмотрите, как ведет себя решение задачи для небольших и последовательных значений x. То есть в тех случаях, когда объем вычислений небольшой.
Под «посмотрите» я имею в виду в буквальном значении — напишите все результаты (и то, как они получились) и пробегитесь своими глазами по всем решениям.
Например, если знаете, что х может принимать значения натуральных чисел, то посмотрите на результаты работы функции при:
Если же x — это какой-то массив, то посмотрите, как ведет себя функция Z при разных небольших массивах:
Здесь элементы массива должны удовлетворять требованиям вашей задачи (например, натуральные или положительные и рациональные зависит уже от вашей конкретной задачи).
3. На основании результатов из предыдущего пункта попытайтесь понять общую закономерность.
И, что очень важно, проверьте, есть ли зависимость в результатах вычисления. То есть может y_5 зависеть от y_4 или от y_2. Или, может, данные, которые были получены при вычислении y_3, можно использовать при вычислении y_5. Например, в числах Фибоначчи Ф(5) зависит от Ф(3) и Ф(4).
Бывают случаи, когда нет прямой зависимости между результатами разных вычислений. Или она есть, но ее сложно увидеть, так как для вас эта задача является непривычной.
Мы такие случаи рассмотрим в примерах с задачами.
4. Понять, как использовать увиденную закономерность для решения общей задачи.
Если брать пример с числами Фибоначчи, то это означает, что в процессе решения некоторые значения будет проще сохранить в памяти, а не пересчитывать каждый раз. А это как раз будет мемоизация.
В примерах, где решение задачи для N + 1 можно получить из решения для N, весьма вероятно, что придется хранить в памяти состояние переменных (индексов, указателей) в момент получения решения N.
Простой пример — это заполнения массива числами Фибоначчи через цикл.
(arr[i] = arr[[i-1] + arr[i-2]. На момент вычисления arr[i] у нас в памяти уже были правильные решения для arr[i-1] и arr[i-2].)
Для одномерной задачи это может выглядеть примерно так:
В этом примере нужно посчитать значение произвольной функции S от числа n, то есть S(n). Но во время поиска S(n-1) у вас были еще дополнительные переменные, которые работали с другими элементами прошлых решений. Пусть это будут указатели pointer № 1 и pointer № 2. Также у вас применяется стандартная индексация массива (индекс i может принимать значения из <0, 1, 2, …, n-1>). Тогда выходит, что, следуя алгоритму, для поиска S(n) нужны S(n-1), pointer № 1 и pointer № 2.
Это можно назвать примером табуляции, поскольку для нахождения S(n) вы используете информацию S(n-1), при этом считаете результат снизу вверху: сначала S(1), потом S(2) и так далее, пока не дойдете до нужного S(n).
В двумерном мире все продолжается по аналогии. Например, у вас зависимость от двух координат/переменных. То есть наша функция S теперь зависит от двух переменных — S(i, j). И вы можете легко посчитать решения (или часть решения) по каждой из них при условии, что вторая координата будет константой. В примере ниже мы зафиксировали это значение на числе ноль.
Но вот для получения решения S(3, 3) (или же в более общем виде S(i, j)) вам потребуется:
И вы понимаете, что это не для вас, так как очень много ресурсов/времени нужно потребить.
Подход с помощью ДП как раз и предлагает получить искомое S(3, 3) путем более эффективного использования уже имеющихся решений. Мы будем применять полученные результаты из этих подзадач для нахождения нужного нам главного решения.
В примере ниже мы посчитали результат для S(3, 3), вычисляя при этом не все возможные S(i, j), а только часть из них. Стрелочками показано, как мы двигались по пространству результатов для подзадач.
То есть мы получили значение для S(1, 1) на основании S(0, 1) и S(1, 0). Затем получили S(2, 1) на основании S(1, 1) и S(2, 0). Да, это абстрактный пример, но он весьма хорошо описывает подход, который используется в реальных задачах. Суть в том, что мы:
По аналогии вы находите решение и для задач большой размерности. Да, это легко сказать, но универсального ключика под все задачи, к сожалению, нет. Разве что ваш ум.
5. Вот мы и подобрались к тому, чтобы привести наше решение в пригодный для бизнес-целей вид. Время оформлять его. Если нужно, пишем код, получаем решение, радуемся. Ну а если код не нужен, оформляем блок-схему или просто радуемся, что решение есть у нас в голове. (Замечу, однако, что часто решение «в голове» не покрывает все детали задачи.)
По этому пункту особых замечаний и советов я дать не могу. Одна вещь только. Так как для ДП зачастую нужна дополнительная память, то в основном это следующие структуры данных:
Решает ли ДП задачи из реального мира
Да, конечно! ДП решает задачи из реального мира. Хотя это не очень-то легко заметить.
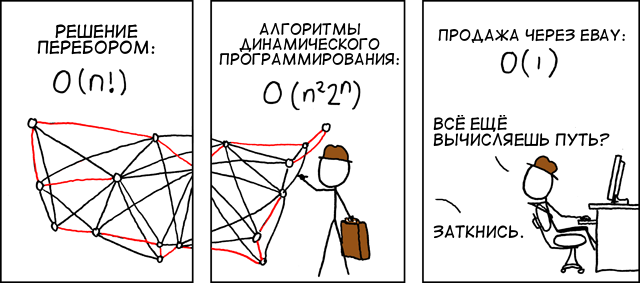
Одна из самых наглядных задач — построение маршрута, который проходит через несколько точек. Приложения для онлайн-карт и сервисы такси часто сталкиваются с подобным вопросом (вероятно, что одни сервисы используют API других сервисов). Например, захотелось вам развести компанию друзей после веселой вечеринки на такси. Ну а как понять, кого отправить домой первым и через какие улицы ехать? Вот здесь и работает с теорией графов наше динамическое программирование. Из классических задач ДП это пересекается с задачей коммивояжера.
Соответственно, похожим является пример в компьютерных сетях, когда пакет данных нужно доставить сразу нескольким адресатам. Алгоритму нужно понять, по какому маршруту и в каком порядке доставить данные во все пункты назначения.
Утилита diff — тоже яркий пример использования ДП. Так как задача состоит в том, чтобы найти похожие подстроки в двух строках, то здесь явно прорисовывается одна из классических задач ДП — нахождение наибольшей общей подпоследовательности.
Вот здесь рассказывается, как смежную с diff задачу приходится решать в реальном приложении. На фронтенде!
Еще интересный пример. Ребята сжимают изображения с помощью ДП. Все вы знаете, что при сжатии иллюстрации используют подходы, где похожие места/одинаковые пиксели записывают через меньшее количество информации. А вот в приведенном примере описан подход того, как можно сжать изображение с модификацией контента изображения и при этом сохранить высокий уровень информативности. То есть если смысловая нагрузка фото была «собака с кошкой на лужайке», то и после обрезания она будет такой. А это уже непростая задача!
Прикладным программистам при использовании этого подхода стоит в первую очередь разделить бизнес-логику и алгоритмическую часть. Чтобы не приходилось потом объяснять продуктовым людям, почему вы упустили баг, в котором берете элемент под индексом 100 (arr[100]) из массива размером в 100. Но это, конечно же, касается не только ДП.
Да, в мире реальных задач аутсорса/аутстаффа решать задачи с помощью ДП приходится нечасто. И вам ни в коем случае не нужно стараться лишний раз придумать себе, где применить ДП. Просто уже достаточно, что вы знаете о таком подходе, понимаете, как он работает, и знаете, где его можно использовать в реальной жизни.
Примеры применение динамического программирования для решения алгоритмических задач
Чтобы лучше разобраться с динамическим программированием, я приведу пример решения трех различных задач. Сложность их возрастает (первая — самая легкая, последняя — самая сложная).
Примечание. Если вы не программист, то можете пропустить этот раздел, так как он, скорее всего, вам покажется скучным. А из-за того, что вы не будете применять знания из примеров на практике, то они быстро выветрятся из головы. Не волнуйтесь, в этом нет ничего плохого.
Задача 1. Восхождение по лестнице
Вы поднимаетесь по лестнице. Чтобы добраться до вершины, нужно преодолеть n ступенек. За один шаг вы можете подниматься на одну или на две ступеньки. Вопрос: сколько существует различных способов подняться?
Для примера покажу один из возможных способов:
Решение с помощью ДП
Воспользуемся нашим алгоритмом. Итак, пусть у нас есть функция DP_steps(n) — возвращает количество различных способов подняться в зависимости от n ступенек.
(DP_steps это сокращение от Dynamic Programming steps.)
Далее смотрим, как ведет себя решение задачи от различного количества ступенек.
1. DP_steps(1) = 1. Так как существует только один способ подняться на одну ступень — за один шаг преодолеть одну ступень.
2. DP_steps(2) = 2. То есть существует два способа подняться на две ступени. Первый способ — сделать два шага по одной ступени. Второй способ — сделать один шаг в две ступени.
Дальше я упрощу запись и буду указывать количество ступеней за шаг.
3. DP_steps(3) = 3.
Первый способ: 1, 1, 1.
Второй способ: 1, 2.
Третий способ: 2, 1.
4. DP_steps(4) = 5
Первый способ: 1, 1, 1, 1.
Второй способ: 1, 2, 1.
Третий способ: 2, 1, 1
Четвертый способ: 1, 1, 2
Пятый способ: 2, 2.
Теперь попытайтесь понять общую закономерность в результатах. Если у вас есть время и желание подумать, то лучше попытайтесь сначала сами это сделать. Дальше будут описаны детали решения.
Итак, что же можно было заметить? А то, что результаты DP_steps(n) зависят от DP_steps(n-1) и DP_steps(n-2).
И представим, что мы уже знаем DP_steps(2) и DP_steps(3). Каким же будет DP_steps(4)?
Для получения ответа необходимо заметить, что в четвертую ступень можно попасть только из второй и из третьей. А как мы уже добирались до второй и до третьей ступеней, уже неважно. Главное, что мы там уже оказались. А это означает, что нашим ответом будет сумма способов попасть во вторую ступень плюс сумма способов попасть в третью ступень. DP_steps(4) = DP_steps(2) + DP_steps(3), то есть DP_steps(4) = 2 + 3 = 5.
Дальше уже нужно просто запрограммировать решение, и для этого есть несколько способов. Я думаю, что самый очевидный — это создать массив и пробежаться по нему циклом:
dp_steps[i] = dp_steps[i-1] + dp_steps[i-2]
Пусть индекс массива у нас отвечает за количество ступеней (тогда размер массива равен n + 1).
И заранее объявить что:
— dp_steps[0] = 1
— dp_steps[1] = 1
— dp_steps[2] = 2
И после заполнения цикла результат будет просто dp_steps[n].
Если присмотреться, то задача похожа на задачу Фибоначчи. Можете подумать, как решить модификацию этой задачи для случая, когда вы можете за один шаг проскакивать не 1–2 ступени, а 1, 2 или 3 ступени.
Задача 2. Поиск размера самой длинной строго возрастающей подпоследовательности
Пояснение к условию задачи. Подпоследовательность — это последовательность, которая может быть получена из исходной последовательности путем удаления некоторых или никаких (!) элементов из исходной последовательности.
Например, [2, 4, 1] является подпоследовательностью [1, 2, 5, 7, 4, 2, 1]. Чтобы последовательность была строго возрастающей, нужно, чтобы каждый ее элемент был строго больше предыдущего.
На примере массива: пусть у нас есть массив array, то он будет строго возрастающим, если array[i] > array[j] для всех i > j.
Решение без помощи ДП
Первое, что может прийти в голову — это перебрать все возможные последовательности. То есть итерировать массив по всем его числам и каждый раз, когда встречаем число, которое нарушает возрастающую последовательность, вызывать еще раз метод поиска самой длинной подпоследовательности, но уже начиная с этого числа.
Например, если у нас есть массив [3, 4, 1, 7]. И мы итерируемся по нему:
Тогда мы запускаем новый поиск строго возрастающей последовательности, но уже начиная с 1. То есть вызываем наш метод для массива [1, 7]. И так далее.
В конце мы просто возвращаем размер самой большой строго возрастающей подпоследовательности. Понятно, что если массив будет строго убывающим (например, [7, 6, 5, 4, 3, 2, 1]), то наша функция будет вызываться рекурсивно много раз.
Решение с ДП
Попробуем применить подход ДП. Итак, пусть есть наша функция — length_of_LIS. Где LIS это Longest Increasing Subsequence.
В этой задаче мы не можем просто проверять, как работает функция, когда мы даем ей на вход только одно небольшое натуральное число. Поэтому для того, чтобы посмотреть, как ведут себя результаты функции, придумаем себе какой-то небольшой массив, по которому будет легко найти правильный ответ и человеку.
Например, [1, 3, 2]. Начнем с одного элемента — [1].
length_of_LIS([1]) = 1. Здесь все понятно.
length_of_LIS([1, 3]) = 2. Здесь тоже все понятно, два подряд строго возрастающих числа.
length_of_LIS([1, 3, 2]) = 2. В этом примере у вас может произойти секундная задержка, где вы, увидев число 2, вернетесь и проверите глазами, что только один меньше двух. Затем вы быстренько сравните по длине две последовательности [1, 3] и [1, 2]. Увидите, что они одинаковые, подумаете, нормально ли это, и поймете, что нормально. И затем вернете ответ: 2.
То есть мы видим, что для последнего примера пришлось вернуться назад и найти число поменьше. А если бы массив был такой: [0, 1, 3, 2], мы бы, когда возвращались и нашли 1, должны были бы понимать, что до единички еще есть и 0, который добавляет длины в эту последовательность.
Первое, что подумал: я бы не хотел возвращаться назад к массиву во время того, как я его итерирую. Ведь это на самом деле никак не влияет на размер самой большой строго возрастающей подпоследовательности.
Ведь я точно знаю, что для каждого среза массива (то есть куска массива от нулевого до какого-то элемента) у нас есть решение. Когда мы здесь прибавляем следующий элемент, то решение может поменяться. Но если мы знаем, как образовалось предыдущее решение, то нам уже необязательно проходить еще раз по массиву.
И вот здесь мое решение и решение известного сервиса Leetcode расходятся (мне кажется, что их решение более канонично с точки зрения ДП).
Следующий этап — понять, как можно переиспользовать то, что в данную итерацию массива у нас уже существует решения задачи. И на следующем шаге итерации мы можем это переиспользовать.
Добавим структуру данных — HashMap. Назовем ее просто: saved_lengths. Будем рассматривать saved_lengths как словарь
Ключами этого словаря будут числа, которые встречаются в нашем массиве. А значениями будут (вот здесь внимательно читайте) размеры самых длинных строго возрастающих подпоследовательностей до момента встречи этого числа. Ух, сложно! Но я сейчас все объясню.
Например, на вход нам передали массив [10,9,2,5,3,7,101,18].
Мы начинаем итерироваться по нему:
Затем мы просто перебираем все значения (а не ключи) в saved_length — максимальный вариант это 4, что и является решением нашей задачи!
Задача 3. О поиске N-го уродливого числа
Пояснение к условию задачи. Под «уродливым числом» (англ. Ugly Number) мы понимаем целое положительное число, простыми делителями которого являются только 2, 3 и 5.
Примеры некоторых уродливых чисел:
Примеры не уродливых чисел:
Вот список первых 11 уродливых чисел:
1, 2, 3, 4, 5, 6, 8, 9, 10, 12, 15.
Задача состоит в том, чтобы найти уродливое число под определенным номером. То есть если нужно первое число, то ответ 1, если десятое — 12.
Обозначим нашу функцию как U_N(n). Она возвращает n-ное уродливое число.
Иногда вместо «уродливое число» я буду использовать аббревиатуру УЧ.
Решение № 1 — в лоб
Алгоритм решения: перебираем все числа подряд начиная с единицы. При этом считаем количество встреченных уродливых чисел. Когда дошли до нужного нам по счету числа — возвращаем его.
Блок-схема для наглядности:
В приведенном выше алгоритме есть функция is_number_ugly. Это не сложная функция, которая проверяет простые делители числа. Если простые делители только 2, 3 и 5, то функция возвращает нам истину (true), иначе же возвращается значение ложь (false).
Самый главный недостаток этого алгоритма в том, что нам для каждого числа нужно делать проверку, уродливое ли оно или нет. А эта задача выполняется не за константное время, поэтому хотелось бы как-то избежать подобных вычислений.
Решение № 2 — подход с помощью динамического программирования
Сначала воспользуемся нашим подходом для понимания того, является ли эта задача той задачей, которую можно решить с помощью ДП.
U_N(1) = 1
U_N(2) = 2
U_N(3) = 3
U_N(4) = и здесь уже первая «мини-нетривиальность». При получении этого числа мы проверяем число 4 на то, является ли оно уродливым. И для выяснения этого делим 4 на 2 (2 раза). И понимаем, что U_N(4) = 4.
U_N(5) = 5
U_N(6) = 6
U_N(7) = а здесь вообще чудеса происходят. Мы делим 7 на 2 — не делится. Делим 7 на 3 — тоже не делится. И даже на 5 не делится! Выходит, что 7 — это первое натуральное число, которое не является уродливым. А что еще интереснее, U_N(7) = 8.
Ну как, вы заметили общую закономерность, которая скажет нам, что эта задача решается с помощью ДП? Скажу честно, я не заметил ее сразу. Но умные ребята заметили. И вот как прийти к этой закономерности:
1. Согласитесь с тем, что каждое уродливое число является результатом произведения чисел 2, 3, 5. Это, собственно, следует из определения уродливых чисел.
2. А это означает, что каждое уродливое число (больше 1) является некоторым другим уродливым числом, умноженным на 2, 3 или 5. Чтобы убедиться в истинности этого утверждения, представьте, что у вас есть сколь угодно большое число M. Если оно уродливое, то значит, делится на 2, 3 или 5. Представим, что на 2. Вот поделим мы его на 2. M/2 = G. Мы знаем, что M — уродливое. А это означает, что если его разделить на 2, то все, что останется, тоже состоит из простых множителей 2, 3, 5.
А значит и G — уродливое. Пример: 100 — уродливое. Его простые множители: 1 * 5 * 5 * 2 * 2 = 100. Разделим мы 100 на 2. 100 / 2 = 50. Это означает, что мы просто убрали один из множителей. Было 1 * 5 * 5 * 2 * 2 = 100, а стало 1 * 5 * 5 * 2 = 50. Мы видим, что 50 тоже состоит из простых множителей, входящих в множество <2, 3, 5>. А значит и 50 — простое число.
3. Предыдущий пункт приводит к мысли, что мы не должны просто перебирать все подряд числа и проверять, являются ли они уродливыми. Мы можем просто сгенерировать нужное количество уродливых чисел. Будет генерировать (N+1)-ое уродливое число исходя из уже имеющихся N уродливых чисел.
Но как это сделать эффективным образом? Дальше я приведу детали решения (по порядку):
Ниже приведена визуализация, которая поможет разобраться с этой идеей:
Вот еще ресурс, где приведена эта визуализация только уже в виде анимации.
Выводы
Динамическое программирование — это подход к решению алгоритмических задач, который может сильно уменьшить время работы программ. При этом он потенциально использует неконстантное количество памяти (то есть чем больше задача, тем больше памяти потребуется для ее решения). Но зачастую затраты по памяти ничтожно малы по сравнению с тем ускорением, которое мы получаем.
ДП редко применяется в ежедневных задачах инженеров ПО и не является тривиальным/нативным подходом. Но понимание того, что такой метод существует и что с его помощью можно значительно улучшить эффективность работы программы — это хорошо как для решения конкретных проблем, так и для мировоззрения специалиста.
Спасибо за ваше внимание! Надеюсь, эта статья вам или помогла, или хотя бы скрасила вечер.