
Для чего нужны стеки?

Jul 3, 2019 · 4 min read
Когда я узнал, что такое стек, мне стало интересно его практическое применение. Оказалось, что чаще всего эта структура используется для имплементации операции “Отмена” ( то есть, ⌘+ Z или Ctrl+ Z).
Чтобы понять, как это работает, разберемся с определением стека.
Что такое стек?
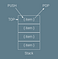
Стек — список элементов, который может быть изменён лишь с одной стороны, называющейся вершиной стека.

Представьте приспособление для раздачи тарелок, в котором тарелки стоят в стопке. Новые тарелки можно добавлять только поверх уже имеющихся, а брать можно лишь сверху. Таким образом, чем позже тарелку положат в стопку, тем раньше её оттуда возьмут. В рамках структур данных это называется LIFO-принципом (последним пришёл — первым ушёл).
Если использовать терминологию, то стек поддерживает операции добавления ( push) и удаления ( pop) элементов на его вершине.
Зачем использовать стек для отмены?
Потому что обычно мы хотим отменить последнее действие.
Стек позволяет добавлять элементы к его вершине и удалять тот элемент, который был последним.
Что произойдёт, если ни одно действие не будет отменено? Стек ведь станет огромным!
Верно. Если не удалять элементы из стека отмены, то есть не использовать операцию отмены, то он станет очень большим. Именно поэтому такие приложения, как Adobe Photoshop, с увеличением времени работы над файлом используют всё больше и больше оперативной памяти. Стек отмены хранит все действия, произведённые над файлом, в памяти до тех пор, пока вы не сохраните и не закроете файл.
Имплементация стека
Стек можно реализовать, используя либо связные списки, либо массивы. Я приведу пример реализации стека на обеих структурах на Python и расскажу о плюсах и минусах каждой.
Стек на связном списке:
Стек на массиве:
Что лучше?
В коде я указал сложность каждой из операций, используя “О” большое. Как видите, имплементации мало чем отличаются.
Однако есть некоторые нюансы, которые стоит учесть.

Массив
Это непрерывный блок памяти. Из-за этого при маленьком размере стека массив будет занимать лишнее место. Ещё один недостаток в том, что каждый раз при увеличении размера массива придётся копировать все уже существующие элементы в новую ячейку памяти.
Связный список
Он состоит из отдельных блоков в памяти и может увеличиваться бесконечно. Поэтому, с одной стороны, имплементация стека с использованием этой структуры немного лучше с точки зрения сложности алгоритма. С другой стороны, каждый элемент должен хранить адреса предыдущего и следующего элемента, что требует больше памяти.
Заключение
Так как динамический массив увеличивается в два раза при заполнении очереди, необходимость выделить дополнительную память будет возникать всё реже и реже. Кроме того, так как указатели не занимают много места, дополнительные данные в связных списках не критичны.
Как видим, между этими двумя реализациями стека практически нет различий — используйте ту, что нравится вам.
Что такое стек
И почему так страшен стек-оверфлоу.
Постепенно осваиваем способы организации и хранения данных. Уже было про деревья, попробуем про стеки. Это для тех, кто хочет в будущем серьёзно работать в ИТ: одна из фундаментальных концепций, которая влияет на качество вашего кода, но не касается какого-то конкретного языка программирования.
👉 Стек — это одна из структур данных. Структура данных — это то, как хранятся данные: например, связанные списки, деревья, очереди, множества, хеш-таблицы, карты и даже кучи (heap).
Как устроен стек
Стек хранит последовательность данных. Связаны данные так: каждый элемент указывает на тот, который нужно использовать следующим. Это линейная связь — данные идут друг за другом и нужно брать их по очереди. Из середины стека брать нельзя.
👉 Главный принцип работы стека — данные, которые попали в стек недавно, используются первыми. Чем раньше попал — тем позже используется. После использования элемент стека исчезает, и верхним становится следующий элемент.
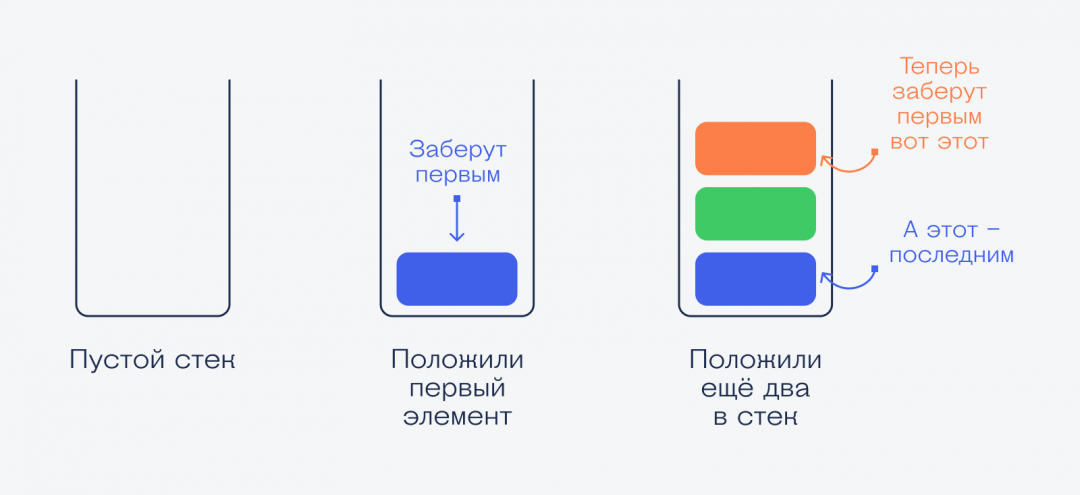
Классический способ объяснения принципов стека звучит так: представьте, что вы моете посуду и складываете одинаковые чистые тарелки стопкой друг на друга. Каждая новая тарелка — это элемент стека, а вы просто добавляете их по одной в стек.
Когда кому-то понадобится тарелка, он не будет брать её снизу или из середины — он возьмёт первую сверху, потом следующую и так далее.
🤔 Есть структура данных, похожая на стек, — называется очередь, или queue. Если в стеке кто последний пришёл, того первым заберут, то в очереди наоборот: кто раньше пришёл, тот раньше ушёл. Можно представить очередь в магазине: кто раньше её занял, тот первый дошёл до кассы. Очередь — это тоже линейный набор данных, но обрабатывается по-другому.
Стек вызовов
В программировании есть два вида стека — стек вызовов и стек данных.
Когда в программе есть подпрограммы — процедуры и функции, — то компьютеру нужно помнить, где он прервался в основном коде, чтобы выполнить подпрограмму. После выполнения он должен вернуться обратно и продолжить выполнять основной код. При этом если подпрограмма возвращает какие-то данные, то их тоже нужно запомнить и передать в основной код.
Чтобы это реализовать, компьютер использует стек вызовов — специальную область памяти, где хранит данные о точках перехода между фрагментами кода.
Допустим, у нас есть программа, внутри которой есть три функции, причём одна из них внутри вызывает другую. Нарисуем, чтобы было понятнее:
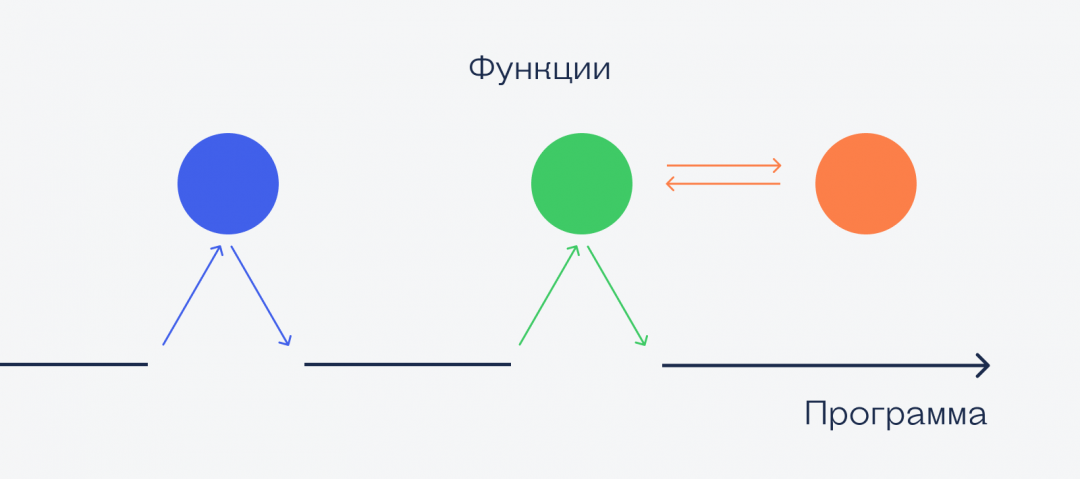
Программа запускается, потом идёт вызов синей функции. Она выполняется, и программа продолжает с того места, где остановилась. Потом выполняется зелёная функция, которая вызывает красную. Пока красная не закончит работу, все остальные ждут. Как только красная закончилась — продолжается зелёная, а после её окончания программа продолжает свою работу с того же места.
А вот как стек помогает это реализовать на практике:
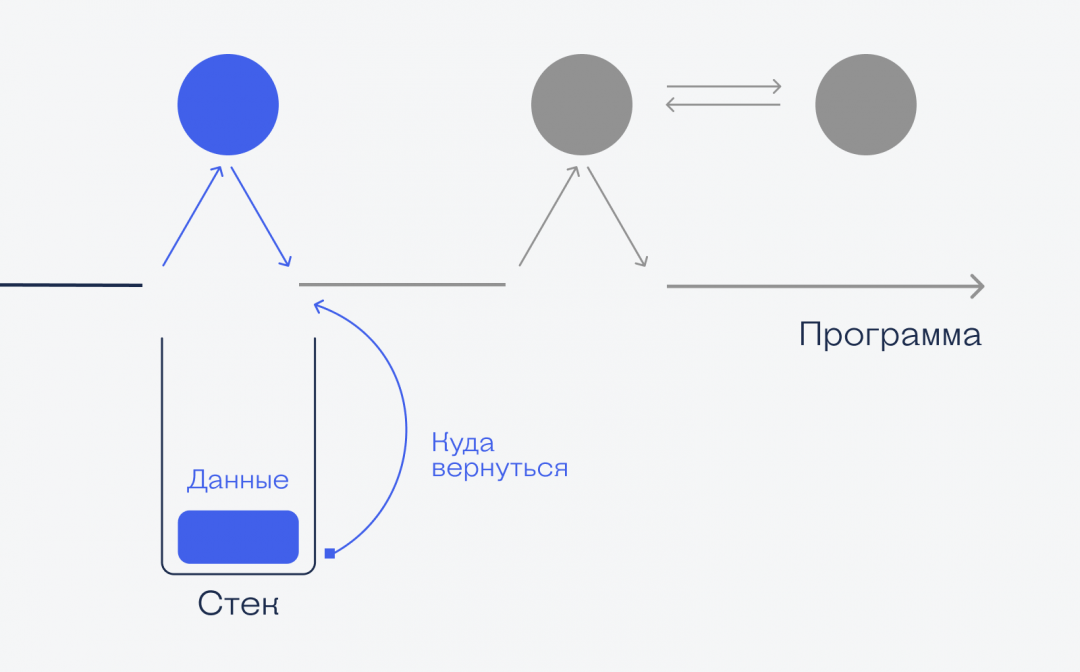
Программа дошла до синей функции, сохранила точку, куда ей вернуться после того, как закончится функция, и если функция вернёт какие-то данные, то программа тоже их получит. Когда синяя функция закончится и программа получит верхний элемент стека, он автоматически исчезнет. Стек снова пустой.
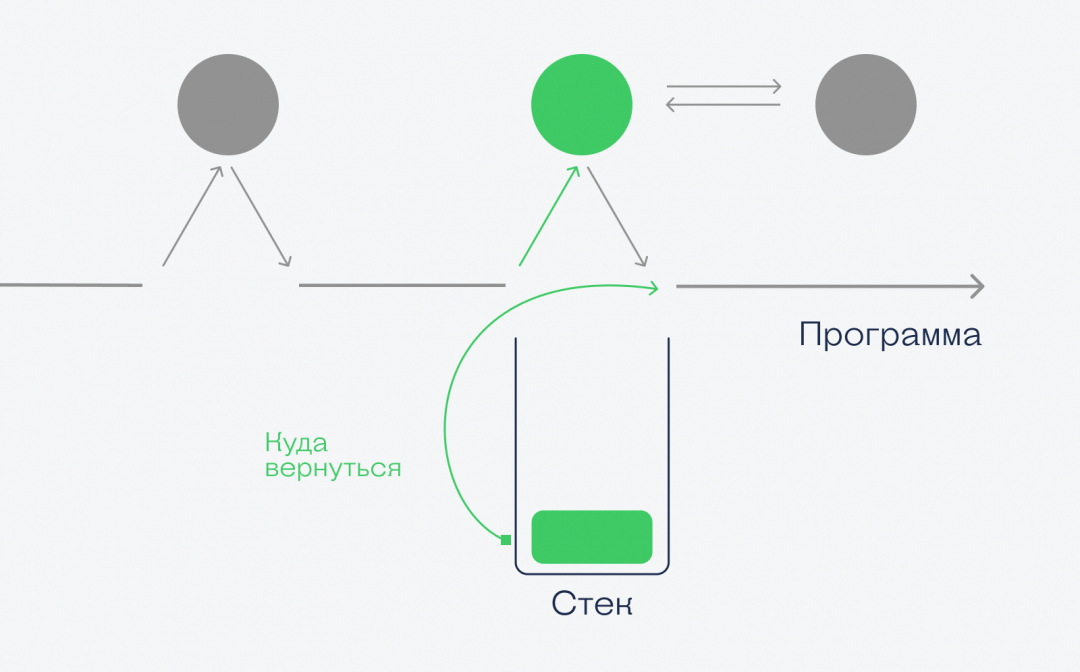
С зелёной функцией всё то же самое — в стек заносится точка возврата, и программа начинает выполнять зелёную функцию. Но внутри неё мы вызываем красную, и вот что происходит:
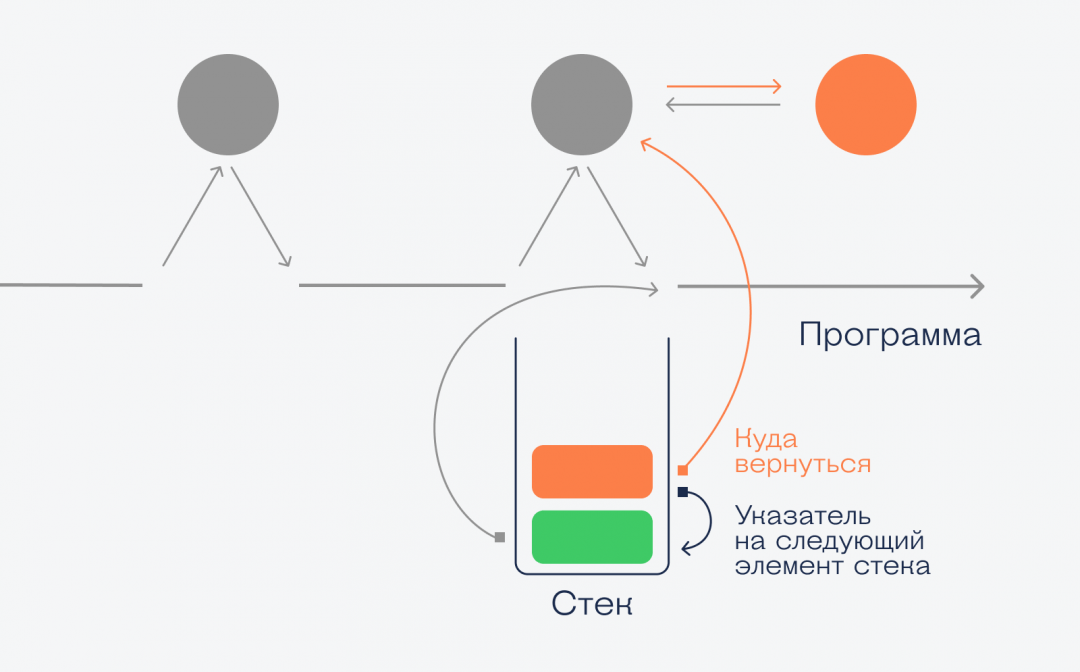
При вызове красной функции в стек помещается новый элемент с информацией о данных, точке возврата и указанием на следующий элемент. Это значит, что когда красная функция закончит работу, то компьютер возьмёт из стека адрес возврата и вернёт управление снова зелёной функции, а красный элемент исчезнет. Когда и зелёная закончит работу, то компьютер из стека возьмёт новый адрес возврата и продолжит работу со старого места.
Переполнение стека
Почти всегда стек вызовов хранится в оперативной памяти и имеет определённый размер. Если у вас будет много вложенных вызовов или рекурсия с очень большой глубиной вложенности, то может случиться такая ситуация:
Переполнение — это плохо: данные могут залезать в чужую область памяти и записывать себя вместо прежних данных. Это может привести к сбою в работе других программ или самого компьютера. Ещё таким образом можно внедрить в оперативную память вредоносный код: если программа плохо работает со стеком, можно специально вызвать переполнение и записать в память что-нибудь вредоносное.
Стек данных
Стек данных очень похож на стек вызовов: по сути, это одна большая переменная, похожая на список или массив. Его чаще всего используют для работы с другими сложными типами данных: например, быстрого обхода деревьев, поиска всех возможных маршрутов по графу, — и для анализа разветвлённых однотипных данных.
Стек данных работает по такому же принципу, как и стек вызовов — элемент, который добавили последним, должен использоваться первым.
Что дальше
А дальше поговорим про тип данных под названием «куча». Да, такой есть, и с ним тоже можно эффективно работать. Стей тюнед.
Путешествие по Стеку. Часть 1

В предыдущих материалах мы рассмотрели размещение программы в памяти – одну из центральных концепций, касающихся выполнения программ на компьютерах. Теперь обратимся к стеку вызовов – рабочей лошадке большинства языков программирования и виртуальных машин. Нас ожидает знакомство с удивительными вещами вроде функций-замыканий, переполнений буфера и рекурсии. Однако всему свое время – в начале нужно составить базовое представление о том, как работает стек.
Стек имеет такое важное значение, потому что благодаря ему любая функция «знает» куда возвращать управление после завершения; функция же, в свою очередь — это базовый строительный блок программы. Вообще, программы внутренне устроены довольно просто. Программа состоит из функций, функции могут вызывать другие функции, в процессе своей работы любая функция помещает данные в стек и снимает их оттуда. Если нужно, чтобы данные продолжили существовать после завершения функции, то место под них выделяется не в стеке, а в куче. Вышесказанное в равной степени относится как к программам, написанным на относительно низкоуровневом C, так и к интерпретируемым языкам вроде JavaScript и C#. Знание данных вещей обязательно пригодится — и если придется отлаживать программу, и если доведется заниматься тонкой подстройкой производительности, да и просто для того, чтобы понимать, что же там, все-таки творится внутри программы.
Итак, начнем. Как только мы вызываем функцию, в стеке для нее создается стековый кадр. Стековый кадр содержит локальные переменные, а также аргументы, которые были переданы вызывающей функцией. Помимо этого кадр содержит служебную информацию, которая используется вызванной функцией, чтобы в нужный момент возвратить управление вызвавшей функции. Точное содержание стека и схема его размещения в памяти могут быть разными в зависимости от процессорной архитектуры и используемой конвенции вызова. В данной статье мы рассматриваем стек на архитектуре x86 с конвенцией вызова, принятой в языке C (cdecl). На рисунке вверху изображен стековый кадр, разместившийся у верхушки стека.
Сразу бросаются в глаза три процессорных регистра. Указатель стека, esp, предназначается для того, чтобы указывать на верхушку стека. Вплотную к верхуше всегда находится объект, который был добавлен в стек, но еще оттуда не снят. Точно также в реальной жизни обстоят дела со стопкой тарелок или пачкой 100-долларовых банкнот.
Хранимый в регистре esp адрес изменяется по мере того, как объекты добавляются и снимаются со стека, однако он всегда указывает на последний добавленный и еще не снятый со стека объект. Многие процессорные инструкции изменяют значение регистра esp как побочный результат своего выполнения. Реализовать работу со стеком без регистра esp было бы проблематично.
В случае с процессорами Intel, ровно как и со многими другими архитетурами, стек растет в направлении меньших адресов памяти. Поэтому верхушка, в данном случае, соответствует наименьшему адресу в стеке, по которому хранятся валидные используемые данные: в нашем случае это переменная local_buffer. Думаю, должно быть понятно, что означает стрелка от esp к local_buffer. Здесь все, как говорится, по делу – стрелка указывает точно на первый байт, занимаемый local_buffer, и это соответствует тому адресу, который хранится в регистре esp.
Далее на очереди еще один регистр, используемый для отслеживания позиций в стеке – регистр ebp – базовый указатель или указатель базы стекового кадра. Данный регистр предназначен для того, чтобы указывать на позицию в стековом кадре. Благодаря регистру ebp текущая функция всегда имеет своего рода точку отсчёта для доступа к аргументам и локальным переменным. Хранимый в регистре адрес изменяется, когда функция начинает или прекращает выполнение. Мы можем довольно просто адресовать любой объект в стековом кадре как смещение относительно ebp, что и показано на рисунке.
В отличии от esp, манипуляции с регистром ebp осуществляется в основном самой программой, а не процессором. Иногда можно добиться выигрыша в производительности просто отказавшись от страндартного использования регистра ebp – за это отвечают некоторые флаги компилятора. Ядро Linux – пример того, где используется такой прием.
Наконец, регистр eax традиционно используется для хранения данных, возвращаемых вызвавшей функции — это высказывание справедливо для большинства поддерживаемых в языке C типов.
Теперь давайте разберем данные, содержащиеся в стековом кадре. Рисунок показывает точное побайтовое содержимое кадра, c направлением роста адресов слево-направо – это то, что мы обычно видим в отладчике. А вот и сам рисунок:
Локальная переменная local_buffer – это массив байт, представляющий собой нуль-терминированную ASCII-строку; такие строки — неизменный атрибут всех программ на C. Размер строки — 7 байт, и, скорее всего, она была получена в результате клавиатурного ввода или чтения из файла. В нашем массиве может храниться 8 байт и, следовательно, один байт остается неиспользуемым. Значение этого байта неизвестно. Дело в том, что, данные то и дело добавлются и снимаются со стека, и в этом «бесконечном танце операции добавления и снятия» никогда нельзя знать заранее, что содержит память, пока не осуществишь в нее запись. Компилятор языка C не обременяет себя тем, чтобы иницилизировать стековый кадр нулями. Поэтому содержащиеся там данные заранее неизвестны и являются в некоторой степени случайными. Уж сколько крови попило такое поведение компилятора у программистов!
Идем далее. local1 – 4-байтовое целое число, и на рисунке видно содержимое каждого байта. Кажется, что это большое число – только взгляните на все эти нули после восьмерки, однако здесь наша интуиция сослужила нам дурную службу.
Процессоры Intel используют прямой порядок байтов (дословно «остроконечный»), и это значит, что числа хранятся в памяти начиная с младшего байта. Иными словами, самый младший значащий байт хранится в ячейке памяти с наименьшим адресом. На рисунках и схемах байты многобайтовых чисел традиционно изображаются в порядке слева-направо. В случае с прямым порядком байт, самый младший значащий байт будет изображен в крайней левой позиции, что отличается от привычного нам способа представления и записи чисел.
Неплохо знать о том, что вся эта «остроконечная / тупоконечная» терминология восходит к произведению Джонатана Свифта «Путешествия Гулливера». Подобно тому, как жители Лилипутии чистили яйцо с острого конца, процессоры Intel тоже обрабатывают числа начиная с младшего байта.
Таким образом, переменная local1 в действительности хранит число 8 (да-да, прям как количество щупалец у осьминога). Что касается param1, то там во втором от начала октете изображена двойка, поэтому в результате получаем число 2 * 256 = 512 (мы умножаем на 256, потому что каждый октет – это диапазон от 0 до 255). param2 хранит число 1 * 256 * 256 = 65536.
Служебная информация стекового кадра включает в себя два компонента: адрес стекового кадра вызвавшей функции (на рисунке — saved ebp) и адрес инструкции, куда необходимо передать управление по завершении данной функции (на рисунке – return address). Эта информация делает возможным возвращение управления, и следовательно, дальнейшее выполнение программы как будто никакого вызова и не было.
Теперь давайте рассмотрим процесс «рождения» стекового кадра. Стек растет не в том направлении, которое обычно ожидают увидеть, и сначала это может сбивать с толку. Например, чтобы увеличить стек на 8 байт, программист вычитает 8 из значения, хранимого в регистре esp. Вычитание – странный способ что-либо увеличить. Забавно, не правда ли!
Возьмем для примера простенькую программу на C:
Предположим, программу запустили без параметров в командной строке. При выполнении «сишной» программы в Linux, первым делом управление получает код, содержащийся в стандартной библиотеке C. Этот код вызовет функцию main() нашей программы, и, в данном случае, переменная argc будет равна 0 (на самом деле, переменная будет равна «1», что соответствует параметру — названию, под которым запущена программа, но давайте для простоты это момент сейчас опустим). При вызове функции main() происходит следующее:
Шаг 2 и 3, а также 4 (описан ниже) соответствуют последовательности инструкций, которая называется «прологом» и встречается практически в любой функции: текущее значение регистра ebp помещается в стек, затем значение регистра esp копируется в регистр ebp, что фактически приводит к созданию нового стекового кадра. Пролог функции main() такой же, как и других функций, с той лишь разницей, что при начале выполнения программы регистр ebp содержит нули.
Если взглянуть на то, что располагается в стеке под argc, то будут видны еще некоторые данные – указатель на строку-название, под которым программа была запущена, указатели на строки-параметры, переданные через командную строку (традиционный C-массив argv), а также указатели на переменные среды и непосредствено сами эти переменные. Однако, на данном этапе нам это не особо важно, так что продолжаем двигаться по направлению к вызову функции add():
Функция main() сначала вычетает 12 из текущего значения в регистре esp для выделения нужного ей места и затем присваивает значения переменным a и b. Значения, хранимые в памяти, изображены на рисунке в шестнадцатеричной форме и с прямым порядком байтов – как и в любом отладчике. После присвоения значений, функция main() вызывает функцию add(), и та начинает выполняться:
Чем дальше, тем интересней! Перед нами еще один пролог, однако теперь уже четко видно как последовательность стековых кадров в стеке оказывается организованной в связный список, и регистр ebp хранит ссылку на первый элемент этого списка. Вот с опорой на это и реализованы трассировка стека в отладчиках и Exception-объекты высокоуровневых языков. Обратим внимание на типичную для начала выполнения функции ситуацию, когда регистры ebp и esp указывают в одно и то же место. И еще раз вспомним, что для наращивания стека осуществляется вычитание из значения, хранящегося в регистре esp.
Важно заметить следующее — при копировании данных из регистра ebp в память происходит непонятное на первый взгляд изменение порядка хранения байтов. Дело в том, что для регистров такого понятия как «порядок байтов» не существует. Иными словами, рассматривая регистр, мы не можем говорить о том, что в нем есть «старшие или младшие адреса». Поэтому отладчики показывают значения, хранимые в регистрах, в наиболее удобном для человеческого восприятия виде: от более значимых к менее значимым цифрам. Таким образом, имея стандартную нотацию «слева-направо» и «little-endian» машину, создается обманчивое впечатление, что в результате операции копирования из регистра в память байты поменяли порядок на обратный. Я хотел, чтобы картина, показанная на рисунках была максимально приближена к реальности – отсюда и такие рисунки.
Теперь, когда самая сложная часть у нас позади, осуществляем сложение:
Здесь у нас появляется неизвестный регистр, чтобы помочь со сложением, но в целом ничего особенного или удивительного. Функция add() выполняет вою работу и, начиная с этого момента все действия в стеке будут осуществляться в обратном порядке. Но об этом расскажем как-нибудь в другой раз.
Все, кто дочитал до этих строк, заслуживает подарок за стойкость, поэтому я с огромной гиковской гордостью презентую Вам вот эту единую схемку, на которой изображены все вышеописанные шаги.
Не так уж все и сложно, стоит только разложить все по полочкам. Кстати, маленькие квадратики очень сильно помогают понимаю. Без «маленьких квадратиков» в информатике вообще никуда. Надеюсь, мои рисунки позволили составить ясную картину происходящего, на которой интуитивно просто показан и рост стека, и изменения содержимого памяти. При ближайшем рассмотрении, наше программное обеспечение не так уж и сильно отличается от простой машины Тьюринга.
На этом завершается первая часть нашего путешествия по стеку. В будущих статьях нас ждут новые погружения в «байтовые» дебри, после чего посмотрим, что же на этом фундаменте способны выстроить высокоуровневые языки программирования. Увидимся на следующей неделе.
Урок №105. Стек и Куча
На этом уроке мы рассмотрим стек и кучу в языке C++.
Сегменты
Память, которую используют программы, состоит из нескольких частей — сегментов:
Сегмент кода (или «текстовый сегмент»), где находится скомпилированная программа. Обычно доступен только для чтения.
Сегмент bss (или «неинициализированный сегмент данных»), где хранятся глобальные и статические переменные, инициализированные нулем.
Сегмент данных (или «сегмент инициализированных данных»), где хранятся инициализированные глобальные и статические переменные.
Куча, откуда выделяются динамические переменные.
Стек вызовов, где хранятся параметры функции, локальные переменные и другая информация, связанная с функциями.
Сегмент кучи (или просто «куча») отслеживает память, используемую для динамического выделения. Мы уже немного поговорили о куче на уроке о динамическом выделении памяти в языке С++.
В языке C++ при использовании оператора new динамическая память выделяется из сегмента кучи самой программы:
Адрес выделяемой памяти передается обратно оператором new и затем он может быть сохранен в указателе. О механизме хранения и выделения свободной памяти нам сейчас беспокоиться незачем. Однако стоит знать, что последовательные запросы памяти не всегда приводят к выделению последовательных адресов памяти!
При удалении динамически выделенной переменной, память возвращается обратно в кучу и затем может быть переназначена (исходя из последующих запросов). Помните, что удаление указателя не удаляет переменную, а просто приводит к возврату памяти по этому адресу обратно в операционную систему.
Куча имеет свои преимущества и недостатки:
Выделение памяти в куче сравнительно медленное.
Выделенная память остается выделенной до тех пор, пока не будет освобождена (остерегайтесь утечек памяти) или пока программа не завершит свое выполнение.
Доступ к динамически выделенной памяти осуществляется только через указатель. Разыменование указателя происходит медленнее, чем доступ к переменной напрямую.
Поскольку куча представляет собой большой резервуар памяти, то именно она используется для выделения больших массивов, структур или классов.
Стек вызовов
Стек вызовов (или просто «стек») отслеживает все активные функции (те, которые были вызваны, но еще не завершены) от начала программы и до текущей точки выполнения, и обрабатывает выделение всех параметров функции и локальных переменных.
Стек вызовов реализуется как структура данных «Стек». Поэтому, прежде чем мы поговорим о том, как работает стек вызовов, нам нужно понять, что такое стек как структура данных.
Стек как структура данных
Структура данных в программировании — это механизм организации данных для их эффективного использования. Вы уже видели несколько типов структур данных, например, массивы или структуры. Существует множество других структур данных, которые используются в программировании. Некоторые из них реализованы в Стандартной библиотеке C++, и стек как раз является одним из таковых.
Например, рассмотрим стопку (аналогия стеку) тарелок на столе. Поскольку каждая тарелка тяжелая, а они еще и сложены друг на друге, то вы можете сделать лишь что-то одно из следующего:
Посмотреть на поверхность первой тарелки (которая находится на самом верху).
Взять верхнюю тарелку из стопки (обнажая таким образом следующую тарелку, которая находится под верхней, если она вообще существует).
Положить новую тарелку поверх стопки (спрятав под ней самую верхнюю тарелку, если она вообще была).
В компьютерном программировании стек представляет собой контейнер (как структуру данных), который содержит несколько переменных (подобно массиву). Однако, в то время как массив позволяет получить доступ и изменять элементы в любом порядке (так называемый «произвольный доступ»), стек более ограничен.
В стеке вы можете:
Посмотреть на верхний элемент стека (используя функцию top() или peek() ).
Вытянуть верхний элемент стека (используя функцию pop() ).
Добавить новый элемент поверх стека (используя функцию push() ).
Стек — это структура данных типа LIFO (англ. «Last In, First Out» = «Последним пришел, первым ушел»). Последний элемент, который находится на вершине стека, первым и уйдет из него. Если положить новую тарелку поверх других тарелок, то именно эту тарелку вы первой и возьмете. По мере того, как элементы помещаются в стек — стек растет, по мере того, как элементы удаляются из стека — стек уменьшается.
Например, рассмотрим короткую последовательность, показывающую, как работает добавление и удаление в стеке:
Stack: empty
Push 1
Stack: 1
Push 2
Stack: 1 2
Push 3
Stack: 1 2 3
Push 4
Stack: 1 2 3 4
Pop
Stack: 1 2 3
Pop
Stack: 1 2
Pop
Stack: 1
Стопка тарелок довольно-таки хорошая аналогия работы стека, но есть лучшая аналогия. Например, рассмотрим несколько почтовых ящиков, которые расположены друг на друге. Каждый почтовый ящик может содержать только один элемент, и все почтовые ящики изначально пустые. Кроме того, каждый почтовый ящик прибивается гвоздем к почтовому ящику снизу, поэтому количество почтовых ящиков не может быть изменено. Если мы не можем изменить количество почтовых ящиков, то как мы получим поведение, подобное стеку?
Во-первых, мы используем наклейку для обозначения того, где находится самый нижний пустой почтовый ящик. Вначале это будет первый почтовый ящик, который находится на полу. Когда мы добавим элемент в наш стек почтовых ящиков, то мы поместим этот элемент в почтовый ящик, на котором будет наклейка (т.е. в самый первый пустой почтовый ящик на полу), а затем переместим наклейку на один почтовый ящик выше. Когда мы вытаскиваем элемент из стека, то мы перемещаем наклейку на один почтовый ящик ниже и удаляем элемент из почтового ящика. Всё, что находится ниже наклейки — находится в стеке. Всё, что находится в ящике с наклейкой и выше — находится вне стека.
Сегмент стека вызовов
Сегмент стека вызовов содержит память, используемую для стека вызовов. При запуске программы, функция main() помещается в стек вызовов операционной системой. Затем программа начинает свое выполнение.
Когда программа встречает вызов функции, то эта функция помещается в стек вызовов. При завершении выполнения функции, она удаляется из стека вызовов. Таким образом, просматривая функции, добавленные в стек, мы можем видеть все функции, которые были вызваны до текущей точки выполнения.
Наша аналогия с почтовыми ящиками — это действительно то, как работает стек вызовов. Стек вызовов имеет фиксированное количество адресов памяти (фиксированный размер). Почтовые ящики являются адресами памяти, а «элементы», которые мы добавляем или вытягиваем из стека, называются фреймами (или «кадрами») стека. Кадр стека отслеживает все данные, связанные с одним вызовом функции. «Наклейка» — это регистр (небольшая часть памяти в ЦП), который является указателем стека. Указатель стека отслеживает вершину стека вызовов.
Единственное отличие фактического стека вызовов от нашего гипотетического стека почтовых ящиков заключается в том, что, когда мы вытягиваем элемент из стека вызовов, нам не нужно очищать память (т.е. вынимать всё содержимое из почтового ящика). Мы можем просто оставить эту память для следующего элемента, который и перезапишет её. Поскольку указатель стека будет ниже этого адреса памяти, то, как мы уже знаем, эта ячейка памяти не будет находиться в стеке.
Стек вызовов на практике
Давайте рассмотрим детально, как работает стек вызовов. Ниже приведена последовательность шагов, выполняемых при вызове функции:
Программа сталкивается с вызовом функции.
Создается фрейм стека, который помещается в стек. Он состоит из:
адреса инструкции, который находится за вызовом функции (так называемый «обратный адрес»). Так процессор запоминает, куда ему возвращаться после выполнения функции;
памяти для локальных переменных;
сохраненных копий всех регистров, модифицированных функцией, которые необходимо будет восстановить после того, как функция завершит свое выполнение.
Процессор переходит к точке начала выполнения функции.
Инструкции внутри функции начинают выполняться.
После завершения функции, выполняются следующие шаги:
Регистры восстанавливаются из стека вызовов.
Фрейм стека вытягивается из стека. Освобождается память, которая была выделена для всех локальных переменных и аргументов.
Обрабатывается возвращаемое значение.
ЦП возобновляет выполнение кода (исходя из обратного адреса).
Возвращаемые значения могут обрабатываться разными способами, в зависимости от архитектуры компьютера. Некоторые архитектуры считают возвращаемое значение частью фрейма стека, другие используют регистры процессора.
Знать все детали работы стека вызовов не так уж и важно. Однако понимание того, что функции при вызове добавляются в стек, а при завершении выполнения — удаляются из стека, дает основы, необходимые для понимания рекурсии, а также некоторых других концепций, которые полезны при отладке программ.