
Что такое логирование?

Известно, что программисты проводят много времени, отлаживая свои программы, пытаясь разобраться, почему они не работают — или работают неправильно. Когда говорят про отладку, обычно подразумевают либо отладочную печать, либо использование специальных программ – дебагеров. С их помощью отслеживается выполнение кода по шагам, во время которого видно, как меняется содержимое переменных. Эти способы хорошо работают в небольших программах, но в реальных приложениях быстро становятся неэффективными.
Сложность реальных приложений
Возьмем для примера типичный сайт. Что он в себя включает?
И это только самый простой случай. Реальность же значительно сложнее: множество разноплановых серверов, системы кеширования (ускорения доступа), асинхронный код, очереди, внешние сервисы, облачные сервисы. Все это выглядит как многослойный пирог, внутри которого где-то работает нами написанный код. И этот код составляет лишь небольшую часть всего происходящего. Как в такой ситуации понять, на каком этапе был сбой, или все пошло не по плану? Для этого, как минимум, нужно определить, в каком слое произошла ошибка. Но даже это не самое сложное. Об ошибках в работающем приложении узнают не сразу, а уже потом, — когда ошибка случилась и, иногда, больше не воспроизводится.
Логирование
И для всего этого многообразия систем существует единое решение — логирование. В простейшем случае логирование сводится к файлу на диске, куда разные программы записывают (логируют) свои действия во время работы. Такой файл называют логом или журналом. Как правило, внутри лога одна строчка соответствует одному действию.
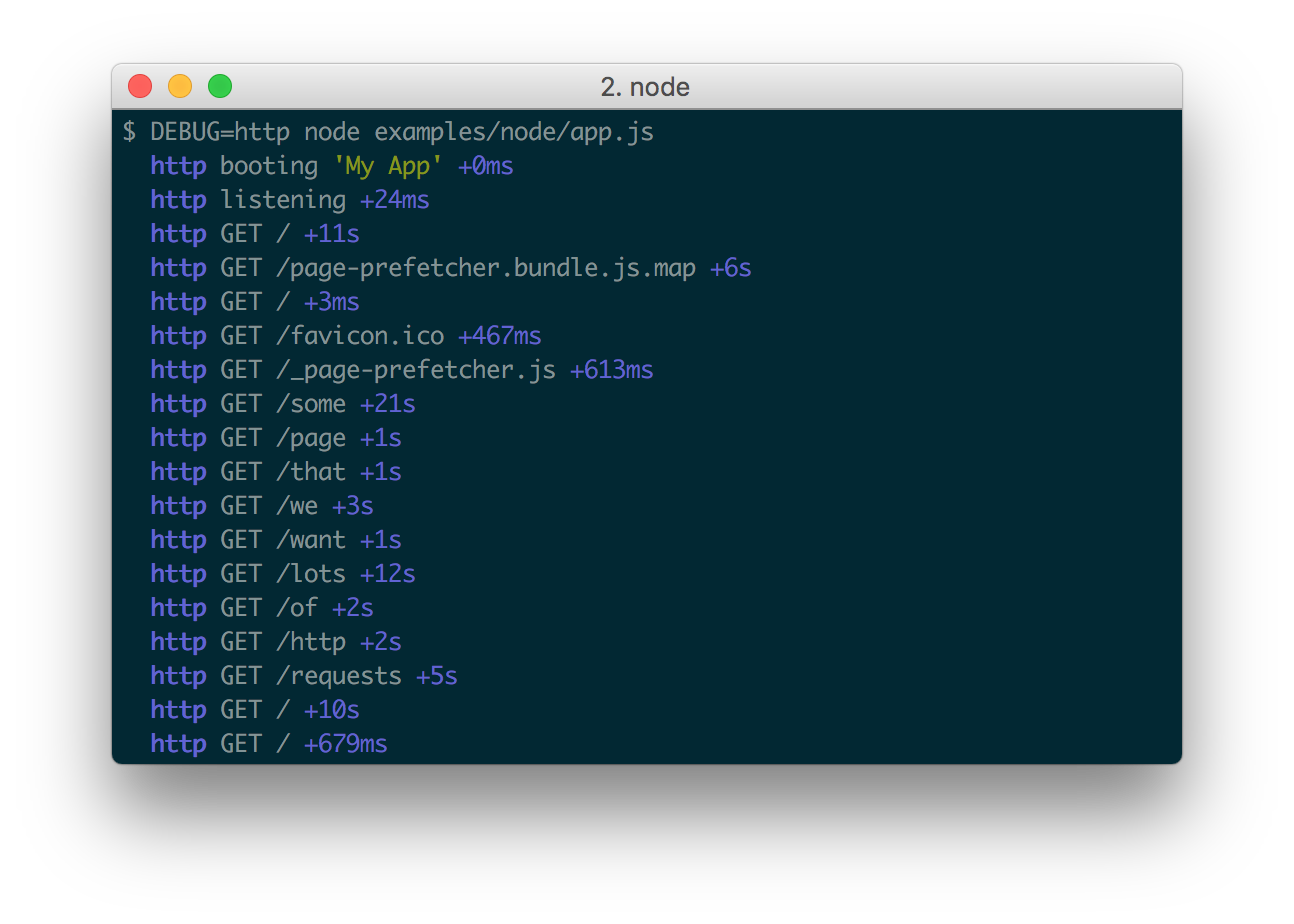
Выше небольшой кусок лога веб-сервера Хекслета. Из него видно ip-адрес, с которого выполнялся запрос на страницу и какие ресурсы загружались, метод HTTP, ответ бекенда (кода) и размер тела ответа в HTTP. Очень важно наличие даты. Благодаря ей всегда можно найти лог за конкретный период, например на то время, когда возникла ошибка. Для этого логи грепают:
Когда программисты только начинают свой путь, они, часто не зная причину ошибки, опускают руки и говорят «я не знаю, что случилось, и что делать». Опытный же разработчик всегда первым делом говорит «а что в логах?». Анализировать логи — один из базовых навыков в разработке. В любой непонятной ситуации нужно смотреть логи. Логи пишут все программы без исключения, но делают это по-разному и в разные места. Чтобы точно узнать, куда и как, нужно идти в документацию конкретной программы и читать соответствующий раздел документации. Вот несколько примеров:
Многие программы логируют прямо в консоль, например Webpack показывает процесс и результаты сборки:
Во фронтенде файлов нет, поэтому логируют либо прямо в консоль, либо к себе в бекенды (что сложно), либо в специализированные сервисы, такие как LogRocket.
Уровни логирования
Чем больше информации выводится в логах, тем лучше и проще отладка, но когда данных слишком много, то в них тяжело искать нужное. В особо сложных случаях логи могут генерироваться с огромной скоростью и в гигантских размерах. Работать в такой ситуации нелегко. Чтобы как-то сгладить ситуацию, системы логирования вводят разные уровни. Обычно это:
Поддержка уровней осуществляется двумя способами. Во-первых, внутри самой программы расставляют вызовы библиотеки логирования в соответствии с уровнями. Если произошла ошибка, то логируем как error, если это отладочная информация, которая не нужна в обычной ситуации, то уровень debug.
Во-вторых, во время запуска программы указывается уровень логирования, необходимый в конкретной ситуации. По умолчанию используется уровень info, который используется для описания каких-то ключевых и важных вещей. При таком уровне будут выводиться и warning, и error. Если поставить уровень error, то будут выводиться только ошибки. А если debug, то мы получим лог, максимально наполненный данными. Обычно debug приводит к многократному росту выводимой информации.
Уровни логирования, обычно, выставляются через переменную окружения во время запуска программы. Например, так:
Существует и другой подход, основанный не на уровнях, а на пространствах имен. Этот подход получил широкое распространение в JS-среде, и является там основным. Фактически, он построен вокруг одной единственной библиотеки debug для логирования, которой пронизаны практически все JavaScript-библиотеки как на фронтенде, так и на бекенде.
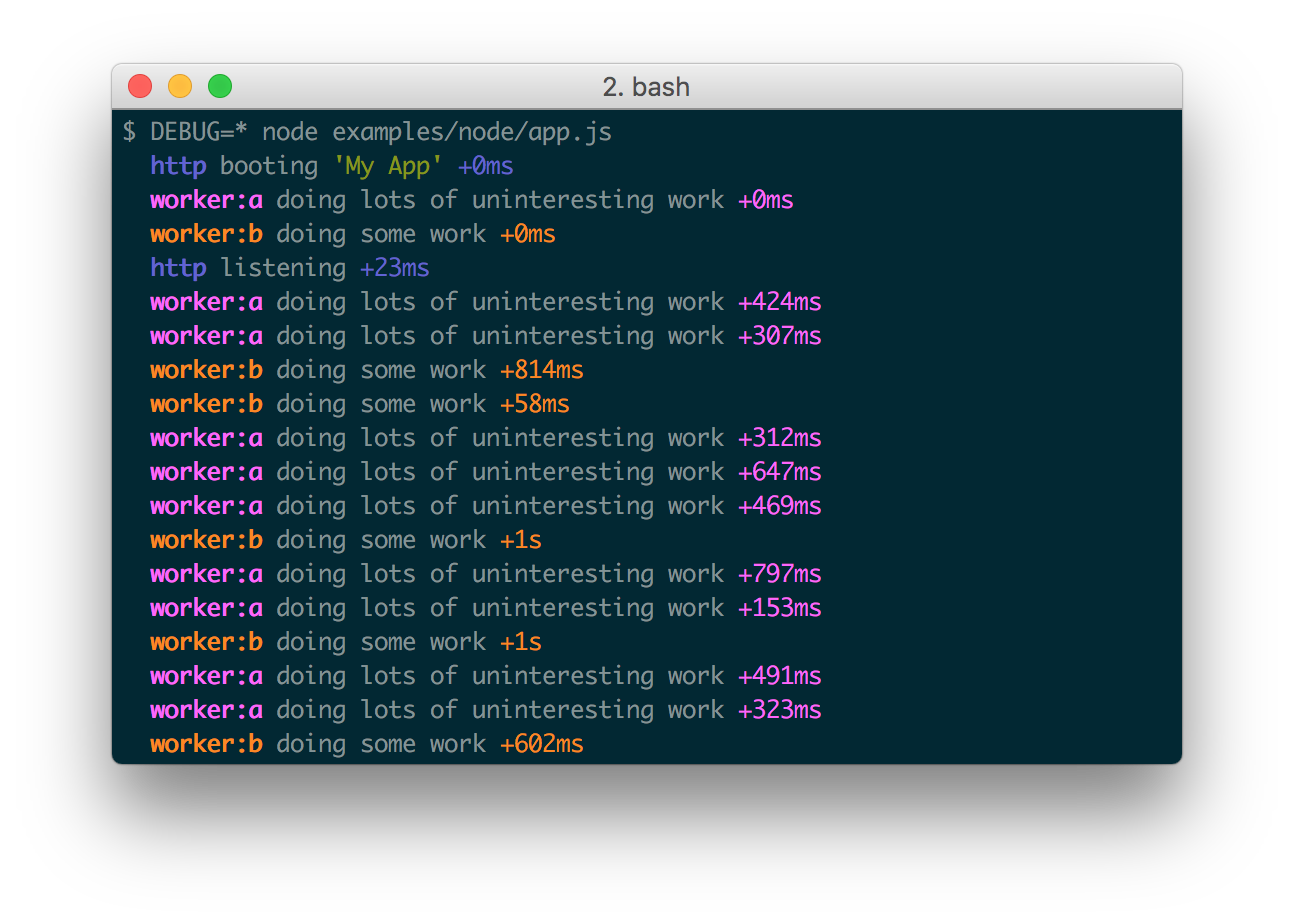
Принцип работы здесь такой. Под нужную ситуацию создается специализированная функция логирования с указанием пространства имен, которая затем используется для всех событий одного процесса. В итоге библиотека позволяет легко отфильтровать только нужные записи, соответствующие нужному пространству.
Запуск с нужным пространством:
Ротация логов
Со временем количество логов становится большим, и с ними нужно что-то делать. Для этого используется ротация логов. Иногда за это отвечает сама программа, но чаще — внешнее приложение, задачей которого является чистка. Эта программа по необходимости разбивает логи на более мелкие файлы, сжимает, перемещает и, если нужно, удаляет. Подобная система встроена в любую операционную систему для работы с логами самой системы и внешних программ, которые могут встраиваться в нее.
С веб-сайтами все еще сложнее. Даже на небольших проектах используется несколько серверов, на каждом из которых свои логи. А в крупных проектах тысячи серверов. Для управления такими системы созданы специализированные программы, которые следят за логами на всех машинах, скачивают их, складывают в заточенные под логи базы данных и предоставляют удобный способ поиска по ним.
Здесь тоже есть несколько путей. Можно воспользоваться готовыми решениями, такими как DataDog Logging, либо устанавливать и настраивать все самостоятельно через, например, ELK Stack
Логирование как способ отлаживать код
Почему так важно запретить самому себе отладку руками?
Когда вы отлаживаете программу, то вы, сами того не осознавая, думаете что за один отладочный сеанс исправите все проблемы, возникшие в рамках этой задачи. Но наша недальновидность не хочет верить в то, что на самом деле там не одна проблема, а несколько. И за один отладочный сеанс не получится решить все эти проблемы.
Поэтому вам надо будет несколько раз запускать этот код в отладочном режиме, проводя часы отладки над одним и тем же куском кода. И это только вы один столько времени потратили над этой частью программы. Каждый член команды, кому «посчастливится» работать с этим кодом, будет вынужден прожить ту же самую историю, которую прожили вы.
Я уже не говорю о том, что люди в командах меняются, команды меняются и так далее. Человеко-часы уходят на одно и то же. Перестаньте делать это. Я серьёзно. Возьмите ответственность за других людей на себя. Помогите им не переживать тот же самый участок вашей жизни.
Проблематика: Сложно отлаживать составной код
Возможный алгоритм решения проблемы:
Таким образом, вы избавляете других людей от отладки этого кода, т.к. если возникнет проблема, то человек посмотрит ваши логи и поймёт в чём причина. Логировать стоит только важные участки алгоритма.
Давайте посмотрим пример. Вы знаете, что по отдельности все реализации интерфейсов работают (т.к. написаны тесты, доказывающие это). Но при взаимодействии всего вместе возникает некорректное поведение. Что вам нужно? Нужно логировать ответы от «корректных» интерфейсов:
В этом примере видно, как мы трассируем отдельные части алгоритма для того, чтобы можно было зафиксировать тот или иной этап его выполнения. Посмотрев на логи, станет ясно в чём причина. В реальной жизни весь этот алгоритм стоило бы разбить на отдельные методы, но суть от этого не меняется.
Всё это в разы ускоряет написание кода. Вам не нужно бежать по циклу с F10 для того, чтобы понять на какой итерации цикла возникла проблема. Просто залогируйте состояние нужных вам объектов при определённых условиях на определённой итерации цикла.
В конечном итоге вы оставляете важные логи и удаляете побочные логи, например, где вы узнавали состояние объекта на определённой итерации цикла. Такие логи не помогут вашим коллегам, т.к. вы, скорее всего, уже поняли проблему некорректного алгоритма и исправили её. Если нет, то ведите разработку в вашей ветке до тех пор, пока не найдёте в чём причина и не исправите проблему. А вот логи, которые записывают важные результаты от выполнения других алгоритмов, понадобятся всем. Поэтому их стоит оставить.
Что если нам не нужен этот мусор? В таком случае выполняйте трассировку только в рамках отладки, а затем подчищайте за собой.
Как правильно писать логи (?)
Тема может и банальная, но когда программа начинает работать как то не так, и вообще вести себя очень странно, часто приходится читать логи. И много логов, особенно если нет возможности отлаживать программу и не получается воспроизвести ошибку. Наверно каждый выработал для себя какие то правила, что, как и когда логировать. Ниже я хочу рассмотреть несколько правил записи сообщений в лог, а также будет небольшое сравнение библиотек логирования для языков php, ruby и go. Сборщики логов и системы доставки не будут рассматриваться сознательно (их обсуждали уже много раз).
Есть такая linux утилита, а также по совместительству сетевой протокол под названием syslog. И есть целый набор RFC посвящённый syslog, один из них описывает уровни логирования https://en.wikipedia.org/wiki/Syslog#Severity_level (https://tools.ietf.org/html/rfc5424). Согласно rfc 5424 для syslog определено 8 уровней логирования, для которых также дается краткое описание. Данные уровни логирования были переняты многими популярными логерами для разных языков программирования. Например, http://www.php-fig.org/psr/psr-3/ определяет те же самые 8 уровней логирования, а стандартный Ruby logger использует немного сокращённый набор из 5 уровней. Несмотря на формальное указание в каких случаях должен быть использован тот или иной уровень логов, зачастую используется комбинация вроде debug/info/fatal — первый для логирования во время разработки и тестирования, второй и третий в расчёте на продакшен. Потом в какой то момент на продакшене начинает происходить что то не понятное и вдруг оказывается, что info логов не хватает — бежим включать debug. И если они не сильно нагружают систему, то зачастую так и остаются включенными в продакшен окружении. По факту остаётся два сценария, когда нужно иметь логи:
В языке Go в котором всё упрощено до предела, стандартный логер тоже прилично покромсали и оставили следующие варианты:
Я часто при написании программы с нуля повсеместно использую debug уровень для логирования с расчётом, что на продакшене будет выставлен уровень логирования info и тем самым сократится зашумлённость сообщениями. Но в таком подходе часто возникают ситуация, что логов вдруг становится не хватать. Трудно угадать, какая информация понадобиться, что бы отловить редкий баг. Возможно рационально всегда использовать по умолчанию уровень info, а в обработчиках ошибок уровень error и выше. Но если у вас сотни и больше сообщений лога в секунду, то тогда наверно есть смысл тонкой настройки между info/debug. В таких ситуациях уже имеет смысл использовать специализированные решения что бы не просаживать производительность.
Есть ещё тонкий момент, когда вы пишите что то вроде logger.debug(entity.values) — то при выставленном уровне логирования выше debug содержимое entity.values не попадёт в лог, но оно каждый раз будет вычисляться отъедая ресурсы. В Ruby логеру можно передать вместо строки сообщения блок кода: Logger.debug < entity.values >. В таком случае вычисления будут происходить только при выставленном соответствующем уровне лога. В языке Go для реализации ленивого вычисления в логер можно передать объект поддерживающий интерфейс Stringer.
После того, как разобрались с использованием уровней логов, нужно ещё уметь связывать разрозненные сообщения, особенно это актуально для многопоточных приложений или связанных между собой отдельных сервисов, когда в логах все сообщения оказываются вперемешку.
Типичный формат строки сообщения в логе можно условно разделить на следующие составные части:
Но с единым контекстом в рамках запроса возникает проблема с различными ORM, http клиентами или другими сервисами\библиотеками, которые живут своей жизнью. И ещё хорошо, если они предоставляют возможность переопределить свой стандартный логер хотя бы глобально, а вот выставить контекст для логера в рамках запроса зачастую не реально. Данная проблема в основном актуальна для многопоточной обработки, когда один процесс обслуживает множество запросов. Но например в фрэймворке Rails имеется очень тесная интеграция между всеми компонентами и запросы ActiveRecord могут писаться в лог вместе с глобальным контекстом для текущего сетевого запроса. А в языке Go некоторые библиотеки логирования позволяют динамически создавать новый объект логера с нужным контекстом, выглядит это примерно так:
После этого такой экземпляр логера можно передать как зависимость в другие объекты. Но отсутствие стандартизированного интерфейса логирования (например как psr-3 в php) провоцирует создателей библиотек хардкодить малосовместимые реализации логеров. Поэтому если вы пишите свою библиотеку на Go и в ней есть компонент логирования, не забудьте предусмотреть интерфейс для замены логера на пользовательский.
Архитектура логирования
Мой опыт разработки в основном строится вокруг разнообразных сетевых cервисов под Windows и Linux. Я обычно стремлюсь добиться максимальной кроссплатформенности вплоть до бинарной совместимости. И конечно, накопилось некоторое количество стабильных решений связанных с логированием.
Топик написан как продолжение к этой статье и будет полезен в первую очередь начинающим программистам.
Итак, начну со своих дополнений к предыдущей статье.
Я как и автор пользуюсь NLog’ом и разумеется широко использую его особенности. Конечно, после
их реализации в любом другом логгере, нижеописанную практику можно применять и у них.
Кстати, log4net продолжает развиваться.
Под капотом NLog
Сразу обсудим полезность второй фичи.
Часто, при разработке кода, возникает необходимость посмотреть значение какой либо переменной в процессе выполнения. Обычно, используют дебаггер и останавливают программу в интересующем месте. Для меня же, это явный признак, что этом месте будет полезен Trace вывод. В комплекте с юнит-тестами мы сразу получаем развертку этой переменной во времени и протокол для сравнения с тестами в других условиях. Таким образом, дебаггером я практически не пользуюсь.
Очевидно, что в боевом применении, даже выключенное подробное логирование, может мешать как скорости выполнения так и параллельности.
Исходный код класса можно посмотреть тут.
Отлично! Для NLog можно быть уверенным, что ваши сколь угодно детальные сообщения могут быть отключены и это минимально скажется на производительности. Но, это не повод посвящать логированию половину кода.
Что и как логировать
Следует придерживаться правил:
В целом, при выводе в лог, всегда отмечайте, то количество потенциально лишних вычислений, которые потребуются для случая когда лог отключен.
Простой пример (фрагмент некоторого класса):
private static Logger Log = LogManager. GetCurrentClassLogger ( ) ;
public string Request ( string cmd, string getParams )
Uri uri = new Uri ( _baseUri, cmd + «?» + getParams ) ;
HttpWebRequest webReq = ( HttpWebRequest ) WebRequest. Create ( uri ) ;
webReq. Method = «GET» ;
webReq. Timeout = _to ;
using ( WebResponse resp = webReq. GetResponse ( ) )
using ( Stream respS = resp. GetResponseStream ( ) )
using ( StreamReader sr = new StreamReader ( respS ) )
page = sr. ReadToEnd ( ) ;
catch ( Exception err )
Все аргументы логирования требовались для логики. Сообщение Debug отмечает аргументы с которыми мы пришли в функцию. В обработчике ошибки мы дублируем входные параметры на случай отключения Debug уровня. А это уже даст информацию при необходимости написать юнит-тест. Стек исключения не выводим, так как остается возможность сделать это вышестоящим обработчиком.
Вообще, в текущем обработчике ошибок полезно детализировать контекст который к привел к исключению и специфичные особенности исключения. В примере было бы полезно вывести поле Status для случая WebException.
Гарантии сохранности лога
Несмотря на некоторые возможности NLog по авто записи логов, нет гарантии сохранности лога при завершении процесса.
Первое, что следует сделать, это обработать событие AppDomain.UnhandledException. В нем следует записать в лог полную информацию об ошибке и вызвать LogManager.Flush(). Обработчик этого события использует тот же поток, который и вызвал исключение, а по окончании, немедленно выгружает приложение.
private static readonly Logger Log = LogManager. GetCurrentClassLogger ( ) ;
public static void Main ( string [ ] args )
static void OnUnhandledException ( object sender, UnhandledExceptionEventArgs e )
Кроме того, следует вызывать LogManager.Flush() везде, где потенциально возможно завершение процесса. В конце всех не фоновых потоков.
Если ваше приложение представляет собой win-service или Asp.Net, то следует обработать соответствующие события начала и завершения кода.
Сколько логировать
Серьезная проблема для разработчика. Всегда хочется получать больше информации, но код начинает выглядеть очень плохо. Я руководствуюсь следующими соображениями.
Вывод в лог это по сути комментарий. Логирование уровня Trace по большей части их и заменяет.
Уровни Trace и Debug читают разработчики, а все что выше — техподдержка и админы. Поэтому до уровня Info сообщения должны точно отвечать на вопросы: «Что произошло?», «Почему?» и по возможности «Как исправить?». Особенно это касается ошибок в файлах конфигурации.
Боевое развертывание
Предположим, разработка дошла до внедрения.
Отложим вопросы ротации логов, размера файлов и глубины истории. Это все очень специфично для каждого проекта и настраивается в зависимости от реальной работы сервиса.
Остановлюсь только на смысловой организации файлов. Их следует разделить на 3 группы. Может потребуется развести логи модулей в разные файлы, но дальше я все равно буду говорить об одном файле для каждой группы.
Если приложение успешно внедрено, то в работе остаются только первые две группы.
Расследование сбоев
Когда работающий сервис подает признаки ошибки, то не следует его пытаться сразу перезагружать. Возможно нам «повезло» поймать ошибки связанные с неверной синхронизацией потоков. И не известно сколько в следующий раз ждать ее повторения.
В первую очередь следует подключить заготовленные заранее конфиги для группы наблюдения. Как раз это и должен позволять делать приличный логгер. Когда мы получили подтверждение о том, что новая конфигурация успешно применена, то пытаемся опять спровоцировать сбой. Желательно несколько раз. Это обеспечит возможность для его воспроизведения в «лабораторных» условиях. Дальше уже работа программистов. А пока можно и перезагрузиться.
name = «fileInfo» type = «AsyncWrapper» queueLimit = «5000» overflowAction = «Block» >
type = «File» fileName = «$
name = «fileWarn» type = «AsyncWrapper» queueLimit = «5000» overflowAction = «Block» >
type = «File» fileName = «$
name = «*» minlevel = «Info» writeTo = «fileInfo»/>
name = «*» minlevel = «Warn» writeTo = «fileWarn»/>
При настройке фильтров следует учитывать относительность уровней логирования для каждой из подсистем. Например, некоторый модуль, имея Info сообщение об инициализации, может быть создан для каждого подключенного пользователя. Разумеется, его вывод в Info группу следует ограничить уровнем Warn.
Чего с логгером делать не следует
Логгер должен быть простым и надежным как молоток. И у него должна быть четко очерчена область применения в конкретном проекте. К сожалению, разработчиков часто трудно удержать. Паттерны проектирования, это в основном полезно, но не этом случае. Достаточно часто стал замечать предложения выделить для логгера обобщенный интерфейс (пример) или реализовать обертку в проекте, чтобы отложить муки выбора NLog vs log4net на потом.
Что бы ни было тому причиной, надо точно помнить, что в первую очередь, такие удобства напрочь убивают компилятору возможность оптимизации.
Не стоит напрямую выводить информацию логгера пользователю, даже с фильтрами. Проблема в том, что эта информация зависит от внутренней структуры программы. Вряд ли вы в процессе рефакторинга пытаетесь сохранить вывод логгера. Наверное, здесь стоит просто задуматься и разделить функционал. Возможно, в проекте просто требуется еще один уровень логирования. В этом случае как раз и уместна будет обертка над логгером.
Чего же мне еще не хватает в NLog?
NLog, Log4Net, Enterprise Library, SmartInspect.
Разнообразные сравнения логгеров между собой, упускают одну важную деталь.
Важно сравнивать не только ограничения/возможности, но и возможность быстро добавить свои «хотелки».
Поэтому, буду пока дружить с NLog.
Чего и Вам желаю.
Логирование это в программировании что
Логирование в Java
Хотя правильнее было бы говорить наверное журналирование/протоколирование и вести журнал/протокол соответственно.
Но так никто никогда не говорит, конечно ¯\(ツ)/¯
Поэтому «логи всякие нужны, логи всякие важны».
Все ли нужно логировать?
Если вы вдруг залогируете в общий файл-лога пароль и логин пользователя, то никто такому рад не будет, что подводит нас к мысли, что логировать надо тоже с умом.
Т.е возникает требование управления информацией, которая нам нужна в данный момент, а также форматом ее вывода.
При этом, логично, что изменения этого формата и того, что мы хотим видеть в логе не должны требовать перекомпиляции всего проекта или изменения кода.
| Уровень логирования | Описание |
|---|---|
| ALL | Все сообщения |
| TRACE | Сообщение для более точной отладки |
| DEBUG | Дебаг-сообщение, для отладки |
| INFO | Обычное сообщение |
| WARN | Предупреждение, не фатально, но что-то не идеально |
| ERROR | Ошибка |
| FATAL | Фатальная ошибка, дело совсем плохо |
| OFF | Без сообщения |
Если проиллюстрировать это:

Принципы и понятия
Логер создается с помощью фабрики и на этапе создания ему присваивается имя. Имя может быть любым, но по стандарту имя должно быть сопряжено с именем класса, в котором вы собираетесь что-то логировать:
Почему так рекомендуется делать?
Получается выстраивается следующая иерархия логеров:
И каждому логеру можно выставить свой уровень. Установленный логгеру уровень вывода распространяется на все его дочерние логгеры, для которых явно не выставлен уровень.
При этом во главе иерархии логеров всегда стоит некотрый дефолтный рутовый(корневой) логер.
Поэтому у всех логеров будет уровень логирования, даже если явно мы не прописали для ru.aarexer.example.SomeClass его, то он унаследуется от рутового.
Вопрос:
| Логер | Назначенный уровень |
|---|---|
| root | INFO |
| ru | Не назначен |
| ru.aarexer | DEBUG |
| ru.aarexer.example | Не назначен |
Какой у какого логера будет уровень логирования?
Ответ:
Вспоминаем, что, если уровень логирования не назначен для логера, то он унаследует его от родительского, смотрим на иерархию:
| Logger | Назначенный уровень | Уровень, который будет |
|---|---|---|
| root | Все сообщения | INFO |
| ru | Не назначен | INFO |
| ru.aarexer | DEBUG | DEBUG |
| ru.aarexer.example | Не назначен | DEBUG |
Это событие по сути состоит из двух полей:
Аппендер – это та точка, куда события приходят в конечном итоге. Это может быть файл, БД, консоль, сокет и т.д.
У одного логгера может быть несколько аппендеров, а к одному аппендеру может быть привязано несколько логгеров.
Логеры при этому наследуют от родительских не только уровни логирования, но и аппендеры.
Например, если к root-логгеру привязан аппендер A1, а к логгеру ru.aarexer – A2, то вывод в логгер ru.aarexer попадет в A2 и A1, а вывод в ru – только в A1.
Вопрос:
Пусть у нас есть несколько аппендеров и логеров
| Logger | Appender |
|---|---|
| root | А1 |
| ru.aarexer | А2 |
| ru.aarexer.example.SomeClass | А3 |
В какой аппендер попадет лог-сообщение:
Ответ:
Это говорит о том, что логер-наследник будет свои события передавать логеру-родителю.
Смотрим на иерархию:
Из всего вышесказанного делаем вывод, что событие «hello» с уровнем Level.INFO попадет во все три аппендера.
Но такое наследование аппендеров можно отключить через конфигурацию, для этого стоит посмотреть в сторону выставления флага additivity=»false» на логгерах.
Т.е как лог-сообщения будут отформативарованы, соответственно тут у каждой библиотеки свой набор доступных форматов.
Библиотеки логирования в Java
Однако он не отвечает всем тем требованиям, которые мы сформулировали выше, поэтому рассмотрим альтернативы.
Наиболее популярные библиотеки логирования в Java :
И поэтому появились еще две библиотеки:
Это самая первая библиотека логирования, появилась еще в 1999 году.
Поддерживает большое количество способов вывода логов: от консоли и файла до записи в БД.
Благодаря подобной иерархии лишнее отсекается и поэтому логер работает быстро.

Проект сейчас не развивается и по сути заброшен, с версией Java 9 уже не совместим.
Вклад log4j в мир логирования настолько велик, что многие идеи были взяты в библиотеки логирования для других языков.

Чувствуете насколько все переосложнено?
Так как стандартных средств форматирования логов недостаточно, то все сводилось к тому, что писались свои. Это при том, что log4j предоставлял больший функционал, работал как минимум не медленнее и в целом себя чувствовал хорошо.
Уровни логгирования у JCL совпадают с log4j, а в случае взаимодействия с JUL происходит следующее сопоставление:
| JCL | JUL |
|---|---|
| ALL | Все сообщения |
| TRACE | Level.FINEST |
| DEBUG | Level.FINE |
| INFO | Level.INFO |
| WARN | Level.WARNING |
| ERROR | Level.SEVERE |
| FATAL | Level.SEVERE |
| OFF | Без сообщения |
С уверенностю можно сказать сейчас, что в эту сторону даже смотреть не стоит. Пациент мертв.
| Лицензия | Apache License Version 2.0 |
| Последняя версия | 1.2 |
| Дата выпуска последней версии | июль 2014 |
Но добавили много нового, парочка из них:
Правда перестали поддерживать properties конфигурации и конфигурации от log4j на xml надо было переписывать заново.
| Лицензия | Apache License Version 2.0 |
| Последняя версия | 2.11.2 |
| Дата выпуска последней версии | февраль 2019 |
| Лицензия | MIT License |
| Последняя версия | 2.0.0-alpha0 |
| Дата выпуска последней версии | июнь 2019 |
При этом, logback не является частью Apache или еще какой-то компании и независим.
| Лицензия | EPL/LGPL 2.1 |
| Последняя версия | 1.3.0-alpha4 |
| Дата выпуска последней версии | февраль 2018 |
Так как из адаптеров это по сути единственный выбор, да и встречается slf4j все чаще, то стоит рассмотреть его устройство.
Вопрос:
Ответ:
Вроде все проблемы решены, пусть и такими радикальными способоами.

Таким образом, чтобы работать со Spring получается надо сделать CLASSPATH подобным образом:
Если конфигурация сделана программно, то bridge не будет работать.

Бесконтрольно подтягиваемые транзитивные зависимости библиотек, которые вы используете в своем проекте, рано или поздно принесут какие-то свои библиотеки логирования, отчего могут открыться врата прямиком в ад.
При этом, если вы разрабатываете библиотеку, то:
Очень важно также не забывать о том, что такое логирование и для чего оно нужно.
Поэтому нельзя скатываться в бесмысленные записи в лог, вывод личных данных и так далее.
Думайте о том что вы пишите в лог!