
Что такое лексемы в программировании
Важно отметить, что препроцессор не знает синтаксиса С.
2.3.2. Пространство между лексемами
Пространство между лексемами определим как множество символов (пробелы, вертикальные и горизонтальные табуляции, символы перевода строки, комментарии), которые игнорируются при трансляции. Эти символы могут служить для определения начала или конца лексемы, но в процессе трансляции они удаляются.
Например, рассмотрим две последовательности: int i; int j;
и
int i;
int j;
2.3.3. Запись длинных строк
Для записи длинных строк символов используется обратная косая черта (\). Она ставится в конце строки. Обратная косая черта и символ перевода строки игнорируются, две строки (и более) воспринимаются как одно целое. Например: “Томский государственный\ университет систем управления\ и радиоэлектроники”
Здесь записана одна длинная строка символов.
2.3.4. Комментарии
Комментарии представляют собой фрагменты текста, предназначенные для записи пояснений. Комментарии предназначены для программистов, которые будут читать исходный текст. Комментарии в процессе трансляции программы игнорируются. Комментарии можно записать двумя способами. В первом способе комментарий открывается парой символов /*, а закрывается символами */. Например: int /* объявить */ i /* счетчик */ ;
В процессе трансляции будет получено всего три лексемы: int, i, ;
Второй способ записи комментария в С++ состоит в записи двух подряд символов «косой черты» (//). Комментарий начинается от этих символов (//) и заканчивается символом перевода строки. Например: class X // это комментарий;
. ;
Следует быть осторожным в использовании /* и // одновременно. Это может привести к нежелательным последствиям. Например: int i = j //* разделить на k */k;
+m;
Пишем свой язык программирования без мам, пап и бизонов. Часть 0: теория
Тема написания своего ЯПа не дает мне покоя уже около полугода. Я не ставил перед собой цель «убить» CoffeeScript, TypeScript, ELM, тысячи их, я просто хотел понять кухню и как они вообще пишутся.
К моему неприятному удивлению, большинство из этих языков используют Jison (Bison для JavaScript), а это не совсем попадало под мою задачу — «понять», так как по сути дела Jison делает все за вас, собирает AST по заданным вами правилам (Jison как таковой отличный инструмент, который делает за вас львиную долю работы, но сейчас не о нем).
В конечном итоге я методом проб и ошибок (а если сказать точнее, чтения статей и реверс инжиниринга) научился писать свои полноценные языки программирования от разбития исходного текста на лексемы до его трансляции в JS код.
Стоит заметить, что данное руководство не привязано к JavaScript, он выбран исключительно из соображений скорости разработки и читаемости, так что вы можете написать свой «лисп»/»питон»/»ваш абсолютно новый синтаксис» на любом знакомом вам языке.
Также до момента написании компилятора (в нашем случае транслятора), процесс написания языка не отличается от процессов создания языков компилируемых в ASM/JVM bitcode/LLVM bitcode/etc, а это значит, что данное руководство не ограничивается созданием языка трансляцируемого в JavaScript.
Весь код, который будет написан в данной (и последующих статьях), лежит на Github’е. Тегами обозначены начало и концы статей для удобства.
Немного теории
Не углубляясь в википедийность, процесс трансляции исходного кода в конечный JS код протекает следующим образом:
Что тут происходит:
1) Lexer
Исходный код нашей программы разбивается на лексемы. По-простому это нахождение в исходном тексте ключевых слов, литералов, символов, идентификаторов и т.д.
Т.е. на выходе из этого (CoffeeScript):
Мы получаем это (сокращенная запись):
Так-как CoffeeScript отступо-чувствительный и не имеет явного выделения блока скобками < и >, блоки отделяются отступами ( INDENT ом и OUTDENT ом), которые по сути заменяет скобки.
2) Parser
Парсер составляет AST из токенов (лексем). Он обходит весь массив и рекурсивно подбирает подходящие паттерны, основываясь на типи токена или их последовательности.
Из полученных токенов в пункте 1, parser составит, примерно такое дерево (сокращенная запись):
Не стоит пугаться объема дерева, на деле он генерируется рекурсивно и его создание не вызывает трудностей.
3) Compiler
Построение конечного кода по AST. Этот пункт можно заменить на компиляцию в байткод, или даже рантайм, но в рамках данной серии статей мы рассмотрим реализацию транслятора в другой язык программирования.
Компилятор (читай транслятор) преобразует Абстрактно-Синтаксическое Дерево в JavaScript код:
Вот и все. Большинство компиляторов работают именно по такому принципу (с незначительными изменениями. Иногда добавляют процесс стримминга исходного текста в поток символов, иногда напротив объединяют парсинг и компиляцию в один этап, но не нам их судить).
Habrlang
Итак, разобравшись с теорией, нам предстоит собрать свой язык программирования, у которого будет примерно следующий синтаксис (что-бы не особо париться, мы будем делать смесь из Ruby, Python и CoffeeScript):
В следующей главе вы реализуем все основные классы нашего транслятора, и научим его транслировать комментарии Habrlang‘а в JavaScript.
Лексика языка
Кодировка
Анализ программы
Пробелы
можно записать и в таком виде:
В обоих случаях компилятор сгенерирует абсолютно одинаковый код. Единственное соображение, которым должен руководствоваться разработчик,— легкость чтения при дальнейшей поддержке такого кода.
Разбиение на строки важно для корректного разбиения на лексемы (как уже говорилось, завершение строки также служит разделителем между лексемами), для правильной работы со строковыми комментариями (см. следующую тему «Комментарии»), а также для вывода отладочной информации (при выводе ошибок компиляции и времени исполнения указывается, на какой строке исходного кода они возникли). Итак, пробелами в Java считаются:
Комментарии
Комментарии не влияют на результирующий бинарный код и используются только для ввода пояснений к программе.
В Java комментарии бывают двух видов:
Часто блочные комментарии оформляют следующим образом (каждая строка начинается с * ):
Блочный комментарий не обязательно должен располагаться на нескольких строках, он может даже находиться в середине оператора:
А такой код допустим:
В последней строке между названием типа данных int и названием переменной x обязательно должен быть пробел или, как в данном примере, комментарий.
описан только один блочный комментарий. А в следующем примере (строки кода пронумерованы для удобства)
Первое предложение должно содержать краткое резюме всего комментария. В дальнейшем оно будет использовано как пояснение этой функции в списке всех методов класса (ниже будут описаны все конструкции языка, для которых применяется комментарий разработчика).
Поскольку в результате создается HTML-документация, то и комментарий необходимо писать по правилам HTML. Допускается применение тегов, таких как и
. Однако теги заголовков с
и использовать нельзя, так как они активно применяются javadoc для создания структуры документации.
Символ * в начале каждой строки и предшествующие ему пробелы и знаки табуляции игнорируются. Их можно не использовать вообще, но они удобны, когда необходимо форматирование, скажем, в примерах кода.
Из этого комментария будет сгенерирован HTML-код, выглядящий примерно так:
Основные понятия языка
Предисловие
Этот курс лекций построен на основе учебника автора «C/C++. Программирование на языке высокого уровня » [18], который выпускается издательством ПИТЕР с 2001 года по настоящее время. Учебнику был присвоен гриф Министерства образования Российской Федерации, он входит в списки рекомендуемой литературы во многих вузах России и ближнего зарубежья. Материалы учебника, вошедшие в этот курс, подверглись частичному обновлению и переработке. В 2010 году учебник был удостоен премии Правительства Санкт-Петербурга «За выдающиеся достижения в сфере высшего и профессионального образования» в составе учебно-методического комплекса по языкам программирования.
В этот комплекс входят также практикум по C/C++ [19] и учебники по языкам C# и Паскаль [20, построенные по единому принципу. Соответствующие учебные курсы можно найти на этом сайте. В комплекс входит более 250 индивидуальных вариантов заданий на лабораторные работы в расчете на учебную группу из 20 человек (все варианты можно найти в учебнике [18]) и более 1000 тестовых вопросов. Преподавателям будут полезны презентации лекций. На сайте интернет-школы программирования http://ips.ifmo.ru можно проверить правильность выполнения некоторых лабораторных работ с помощью системы автоматического тестирования программ.
Доброжелательную и конструктивную критику, а также предложения по улучшению курса направляйте автору по адресу pta- ipm @yandex.ru.
Состав языка
Презентацию к лекции Вы можете скачать здесь.
Алфавит языка
Все тексты на языке пишутся с помощью его алфавита. Алфавит C++ включает:
Из символов базового набора составляются лексемы языка и директивы препроцессора. Символы из набора реализации используются для написания комментариев. Компилятор комментарии игнорирует.
Лексемы
Существуют следующие виды лексем:
Объединенная единым алгоритмом совокупность описаний и операторов образует программу.
Путь от текста программы к исполняемому коду
Описание синтаксических конструкций
Для описания языка здесь используется неформальный способ, при котором необязательные части синтаксических конструкций заключаются в квадратные скобки, текст, который необходимо заменить конкретным значением, пишется по-русски, а выбор одного из нескольких элементов обозначается вертикальной чертой. Например:
Фигурные скобки используются для группировки элементов, из которых требуется выбрать только один.
Имена (идентификаторы)
Основы структуры программ
3.6. Абстрактные синтаксические деревья
Непустое дерево имеет в точности один корень (структура, представленная нулем, одним или несколькими раздельными деревьями, имеющая произвольное число корней, называется лесом).
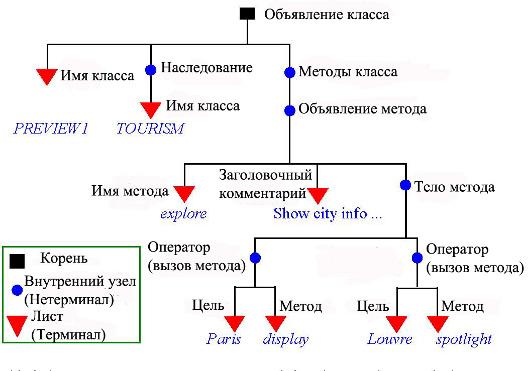
Листья абстрактного синтаксического дерева называются также терминалами, а корень и внутренние узлы – нетерминалами.
Категория определяет общее синтаксическое понятие. Синтаксис языка программирования определяется множеством категорий и их структурой.
3.7. Лексемы и лексическая структура
Лексемы подобны словам и символам обычного языка. Предложение «Ах, ох – это восклицания!» содержит четыре слова и три символа.
Виды лексем
Лексемы бывают двух видов.
Уровни описания языка
Форма лексем определяет лексическую структуру языка. Синтаксический уровень является надстройкой – более высоким уровнем по отношению к лексическому, а семантический уровень выше синтаксического.
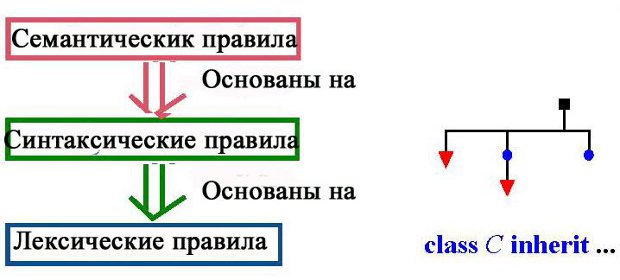
Важной особенностью этой иерархии является то, что свойства любого уровня определены только при условии выполнения ограничений на предыдущих уровнях. Синтаксис определен только для лексически корректных текстов, а семантика существует только для синтаксически корректных программ.
Мы встретимся с еще одним специальным уровнем, лежащим между синтаксисом и семантикой : обоснованием (validity), на котором рассматриваются правила, не относящиеся к синтаксису, например, ограничения типа.
Идентификаторы
На данный момент нам необходимо только одно лексическое правило для идентификаторов.
Идентификатор начинается с буквы, за которой следует ноль или более символов, каждый из которых может быть:
Примером идентификатора, содержащего цифры, является Route1
Действует одно исключение: нельзя использовать в роли идентификаторов ключевые слова, зарезервированные для специальных целей (на данный момент нам известно лишь несколько ключевых слов, но, если ошибочно мы попытаемся использовать в роли идентификатора ключевое слово, появится сообщение об ошибке).
Для повышения читабельности программ выбирайте идентификаторы, четко идентифицирующие предполагаемую роль, за исключением специальных случаев, которые вскоре рассмотрим. Используйте полные имена, а не аббревиатуры: Route1, а не R1 или Rte1.
Нет налога на нажатие клавиш. Те несколько секунд, которые вы, возможно, сэкономите, опустив несколько символов, ничего не стоят в сравнении с тем временем, когда вам или кому-либо другому понадобится понять, что же делается в вашей программе.
В идентификаторах, обозначающих сложные понятия, используйте подчеркивание для разделения последовательности слов, как в My_route или bus_station. Это относится и к именам классов, записываемых в верхнем регистре: PUBLIC_TRANSPORT. Не переусердствуйте: для большинства идентификаторов достаточно одного слова или двух слов, соединенных подчеркиванием. Ясность не означает многословие.
В некоторых программах, хотя для программ на Eiffel это не так, можно встретиться с многословными идентификаторами, в которых каждое следующее слово начинается с заглавной буквы: myRoute, PublicTransport. Это соглашение называется верблюжьим стилем (camel style) из-за возникающего горба. Лучше не следовать этому стилю, поскольку «онНамногоХужеЧитается», чем стиль с подчеркиванием, «остающийся_совершенно_ясным_даже_для _длинных_идентификаторов».
Уровни описания языка
Лексическая структура состоит из последовательности лексем. Для разделения соседствующих лексем можно использовать «белый пробел» (break), который может быть:
3.8. Ключевые концепции, изученные в этой лекции
Новый словарь
| Abstract syntax tree (AST) | Абстрактное синтаксическое дерево (АСД) | Break | Белый пробел | Carriage return? | Возврат каретки |
| Code | Код | Construct | Категория | Delimiter | Ограничитель |
| Expression | Выражение | Free format language | Свободный формат языка | Grammar | Грамматика |
| Identifier | Идентификатор | Instruction | Оператор | Internal node | Внутренний узел |
| Leaf | Лист | Lexical | Лексический | Natural language | Естественный язык |
| Nesting | Вложенность | New line | Новая строка | Node | Узел |
| Nonterminal | Нетерминал | Operator | Знак операции | Root | Корень |
| Semantics | Семантика | Special symbol | Специальный символ | Specimen | Образец |
| Syntax | Синтаксис | Terminal | Терминал | Token | Лексема |
| Tree | Дерево | Value | Значение |
3-У. Упражнения
3-У.1. Словарь
Дайте точные определения терминам словаря.
3-У.2. Карта концепций
Добавьте новые термины в карту концепций, спроектированную в предыдущей лекции.